Проверка адекватности линейного уравнения регрессии
Расчет коэффициентов ПФЭ при равном числе параллельных опытов в каждой точке факторного пространства
Коэффициенты находятся по формуле:
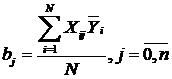 ,
,
где 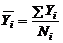 — среднее значение параметра оптимизации, вычисленное по параллельным опытам
— среднее значение параметра оптимизации, вычисленное по параллельным опытам  – ой строки матрицы планирования
– ой строки матрицы планирования  .
.
Проверка значимости коэффициентов ПФЭ
Очевидно, что один фактор больше влияет на параметр оптимизации, другой – меньше. Поэтому можно проверить полученные коэффициенты регрессии на значимость, т.е. оценить величину влияния каждого фактора на значение параметра оптимизации. Если эта величина соизмерима с ошибкой эксперимента, то соответствующий коэффициент не несет дополнительной информации об объекте, и его можно приравнять к нулю, что упрощает математическую модель.
Значимость коэффициентов проверяется с помощью 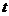 – критерия Стьюдента.
– критерия Стьюдента.
Значения – критерия вычисляются для каждого для каждого фактора по формуле:
 ,
, 
Полученные значения сравнивают с табличным значением критерия Стъюдента 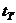 , которое находится по числу степеней свободы
, которое находится по числу степеней свободы  , и уровню значимости α — величина, характеризующая вероятность того, что решение будет неправильным. Обычно принимают, что
, и уровню значимости α — величина, характеризующая вероятность того, что решение будет неправильным. Обычно принимают, что 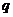 α =0.05.
α =0.05.
 >
> 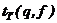 ,
,
то коэффициент значимо отличается от нуля, если же 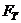 , (1)
, (1)
то линейное уравнение регрессии признается адекватным. Если это условие не выполняется, т.е. 
При расчете F предполагается что 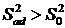 . Если наблюдается обратное, то вывод об адекватности может быть сделан и без проверки условия (1).
. Если наблюдается обратное, то вывод об адекватности может быть сделан и без проверки условия (1).
Если модель адекватна, то ее можно использовать для поиска области оптимума объекта исследования или для предсказания отклика.
При неадекватной линейной модели наиболее часто принимают решение об уменьшении интервалов варьирования факторов и повторении эксперимента.
Итак, алгоритм расчета линейной модели с использованием ПФЭ следующий:
Задают матрицу планирования в кодированной форме для заданного числа факторов
Для каждого фактора задают базовую точку и интервал варьирования
Рассчитывают матрицу планирования в натуральной (размерной) форме
Проводят эксперименты, по матрице планирования, используя случайные числа.
Проводят серию опытов в центре плана, для определения ошибки опыта.
$ AlexLat $
Оценка значимости уравнения регрессии в целом производится на основе F-критерия Фишера, которому предшествует дисперсионный анализ. В математической статистике дисперсионный анализ рассматривается как самостоятельный инструмент статистического анализа. В эконометрике он применяется как вспомогательное средство для изучения качества регрессионной модели. Согласно основной идее дисперсионного анализа, общая сумма квадратов отклонений переменной (y) от среднего значения (y ср. ) раскладывается на две части – «объясненную» и «необъясненную»:
Схема дисперсионного анализа имеет следующий вид (n –число наблюдений, m–число параметров при переменной x):
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F-критерия Фишера. Фактическое значение F -критерия Фишера сравнивается стабличным значением F табл. (α, k 1 , k 2 ) при заданном уровне значимости α и степенях свободы k 1 = m и k 2 =n-m-1. При этом, если фактическое значение F-критерия больше табличного F факт > F теор , то признается статистическая значимость уравнения в целом. Для парной линейной регрессии m=1 , поэтому:
Эта формула в общем виде может выглядеть так:
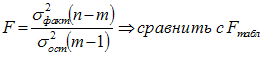
Отношение объясненной части дисперсии переменной (у) к общей дисперсии называют коэффициентом детерминации и используют для характеристики качества уравнения регрессии или соответствующей модели связи. Соотношение между объясненной и необъясненной частями общей дисперсии можно представить в альтернативном варианте:
Коэффициент детерминации R 2 принимает значения в диапазоне от нуля до единицы 0≤ R 2 ≤1. Коэффициент детерминации R 2 показывает, какая часть дисперсии результативного признака (y) объяснена уравнением регрессии.Чем больше R 2 , тем большая часть дисперсии результативного признака (y) объясняется уравнением регрессии и тем лучше уравнение регрессии описывает исходные данные. При отсутствии зависимости между (у) и (x) коэффициент детерминации R 2 будет близок к нулю. Таким образом, коэффициент детерминации R 2 может применяться для оценки качества (точности) уравнения регрессии. Возникает вопрос, при каких значениях R 2 уравнение регрессии следует считать статистически незначимым, что делает необоснованным его использование в анализе? Ответ на этот вопрос дает F — критерий Фишера F факт > F теор — делаем вывод о статистической значимости уравнения регрессии. Величина F — критерия связана с коэффициентом детерминации R 2 xy ( r 2 xy ), и ее можно рассчитать по следующей формуле:
Либо при оценке значимости индекса (аналог коэффициента) детерминации:
 где: i 2 — индекс (коэффициент) детерминации, который рассчитывается:
где: i 2 — индекс (коэффициент) детерминации, который рассчитывается:
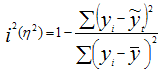
Использование коэффициента множественной детерминации R 2 для оценки качества модели, обладает тем недостатком, что включение в модель нового фактора (даже несущественного) автоматически увеличивает величину R 2 . Поэтому, при большом количестве факторов, предпочтительнее использовать, так называемый, улучшенный, скорректированный коэффициент множественной детерминации R 2 , определяемый соотношением:
где p – число факторов в уравнении регрессии, n – число наблюдений. Чем больше величина p, тем сильнее различия между множественным коэффициентом детерминации R 2 и скорректированным R 2 . При использовании скорректированного R 2 , для оценки целесообразности включения фактора в уравнение регрессии, следует учитывать, что увеличение его величины (значения), при включении нового фактора, не обязательно свидетельствует о его значимости, так как значение увеличивается всегда, когда t-статистика больше единицы (|t|>1). При заданном объеме наблюдений и при прочих равных условиях, с увеличением числа независимых переменных (параметров), скорректированный коэффициент множественной детерминации убывает. При небольшом числе наблюдений, скорректированная величина коэффициента множественной детерминации R 2 имеет тенденцию переоценивать долю вариации результативного признака, связанную с влиянием факторов, включенных в регрессионную модель. Низкое значение коэффициента множественной корреляции и коэффициента множественной детерминации R 2 может быть обусловлено следующими причинами: в регрессионную модель не включены существенные факторы; неверно выбрана форма аналитической зависимости, не реально отражающая соотношения между переменными, включенными в модель.
Для оценки значимости парного коэффициента корреляции (корень квадратный из коэффициента детерминации), при условии линейной формы связи между факторами, можно использовать t-критерий Стьюдента:
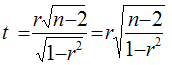
При численности объектов анализа до 30 единиц возникает необходимость проверки значимости (существенности) каждого коэффициента регрессии. При этом выясняют насколько вычисленные параметры характерны для отображения комплекса условий: не являются ли полученные значения параметров результатами действия случайных причин. Значимость коэффициентов простой линейной регрессии (применительно к совокупностям, у которых n t-критерия Стьюдента. При этом вычисляют расчетные (фактические) значения t-критерия для параметров a 0 а 1 :
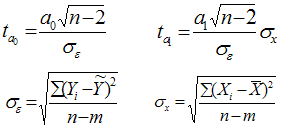
n-число наблюдений, m-число параметров уравнения регрессии, σ ε -(остаточное) среднее квадратическое отклонение результативного признака от выровненных значений ŷ; σ х -среднее квадратическое отклонение факторного признака от общей средней.
Вычисленные, по вышеприведенным формулам, значения сравнивают с критическими t, которые определяют по таблице значений Стьюдента с учетом принятого уровня значимости α и числа степеней свободы вариации k (ν)=n-2. В социально-экономических исследованиях уровень значимости α обычно принимают равным 0,05. Параметр признаётся значимым (существенным) при условии, если t расч. > t табл. В этом случае, практически невероятно, что найденные значения параметров обусловлены только случайными совпадениями.
Показатели качества регрессии
Качество модели регрессии связывают с адекватностью модели наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным проводится на основе анализа остатков —  .
.
Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов. Согласно общим предположениям регрессионного анализа, остатки должны вести себя как независимые (в действительности, почти независимые) одинаково распределенные случайные величины.
Качество модели регрессии оценивается по следующим направлениям:
проверка качества всего уравнения регрессии;
проверка значимости всего уравнения регрессии;
проверка статистической значимости коэффициентов уравнения регрессии;
проверка выполнения предпосылок МНК.
При анализе качества модели регрессии, в первую очередь, используется коэффициент детерминации, который определяется следующим образом:

где 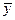 — среднее значение зависимой переменной,
— среднее значение зависимой переменной,
 — предсказанное (расчетное) значение зависимой переменной.
— предсказанное (расчетное) значение зависимой переменной.
Коэффициент детерминации показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, т. е. определяет, какая доля вариации признака Y учтена в модели и обусловлена влиянием на него факторов.
Чем ближе 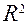 к 1, тем выше качество модели.
к 1, тем выше качество модели.
Для оценки качества регрессионных моделей целесообразно также использовать коэффициент множественной корреляции (индекс корреляции) R
R =  =
= 
Данный коэффициент является универсальным, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных.
Важным моментом является проверка значимости построенного уравнения в целом и отдельных параметров.
Оценить значимость уравнения регрессии – это означает установить, соответствует ли математическая модель, выражающая зависимость между Y и Х, фактическим данным и достаточно ли включенных в уравнение объясняющих переменных Х для описания зависимой переменной Y
Оценка значимости уравнения регрессии производится для того, чтобы узнать, пригодно уравнение регрессии для практического использования (например, для прогноза) или нет.
Для проверки значимости модели регрессии используется F-критерий Фишера. Если расчетное значение с n1= k и n2 = (n — k — 1) степенями свободы, где k – количество факторов, включенных в модель, больше табличного при заданном уровне значимости, то модель считается значимой.

В качестве меры точности применяют несмещенную оценку дисперсии остаточной компоненты, которая представляет собой отношение суммы квадратов уровней остаточной компоненты к величине (n- k -1), где k – количество факторов, включенных в модель. Квадратный корень из этой величины (  ) называется стандартной ошибкой:
) называется стандартной ошибкой:
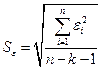
значимость отдельных коэффициентов регрессии проверяется по t-статистике путем проверки гипотезы о равенстве нулю j-го параметра уравнения (кроме свободного члена):
 ,
,
где Saj — это стандартное (среднеквадратическое) отклонение коэффициента уравнения регрессии aj. Величина Saj представляет собой квадратный корень из произведения несмещенной оценки дисперсии  и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.
и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.

где  — диагональный элемент матрицы
— диагональный элемент матрицы 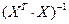 .
.
Если расчетное значение t-критерия с (n — k — 1) степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
Проверка выполнения предпосылок МНК.
Рассмотрим выполнение предпосылки гомоскедастичности, или равноизменчивости случайной составляющей (возмущения).
Невыполнение этой предпосылки, т.е. нарушение условия гомоскедастичности возмущений означает, что дисперсия возмущения зависит от значений факторов. Такие регрессионные модели называются моделями с гетероскедастичностью возмущений.
Обнаружение гетероскедастичности. Для обнаружения гетероскедастичности обычно используют тесты, в которых делаются различные предположения о зависимости между дисперсией случайного члена и объясняющей переменной: тест ранговой корреляции Спирмена, тест Голдфельда — Квандта, тест Глейзера, двусторонний критерий Фишера и другие [2].
При малом объеме выборки для оценки гетероскедастичности может использоваться метод Голдфельда — Квандта. Данный тест используется для проверки такого типа гетероскедастичности, когда дисперсия остатков возрастает пропорционально квадрату фактора. При этом делается предположение, что, случайная составляющая 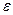 распределена нормально.
распределена нормально.
Чтобы оценить нарушение гомоскедастичности по тесту Голдфельда — Квандта необходимо выполнить следующие шаги.
Упорядочение п наблюдений по мере возрастания переменной х.
Исключение  средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
Разделение совокупности на две группы (соответственно с малыми и большими значениями фактора  ) и определение по каждой из групп уравнений регрессии.
) и определение по каждой из групп уравнений регрессии.
Определение остаточной суммы квадратов для первой регрессии  и второй регрессии
и второй регрессии  .
.
Вычисление отношений  (или
(или 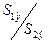 ). В числителе должна быть большая сумма квадратов.
). В числителе должна быть большая сумма квадратов.
Полученное отношение имеет F распределение со степенями свободы k1=n1-k и k2=n-n1-k, (k– число оцениваемых параметров в уравнении регрессии).
Если  , то гетероскедастичность имеет место.
, то гетероскедастичность имеет место.
Чем больше величина F превышает табличное значение F -критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
Оценка влияния отдельных факторов на зависимую переменную на основе модели (коэффициенты эластичности, b — коэффициенты).
Важную роль при оценке влияния факторов играют коэффициенты регрессионной модели. Однако непосредственно с их помощью нельзя сопоставить факторы по степени их влияния на зависимую переменную из-за различия единиц измерения и разной степени колеблемости. Для устранения таких различий при интерпретации применяются средние частные коэффициенты эластичности Э(j) и бета-коэффициенты b(j).
Эластичность Y по отношению к Х(j) определяется как процентное изменение Y, отнесенное к соответствующему процентному изменению Х. В общем случае эластичности не постоянны, они различаются, если измерены для различных точек на линии регрессии. По умолчанию стандартные программы, оценивающие эластичность, вычисляют ее в точках средних значений:
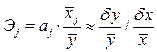
Эластичность ненормирована и может изменяться от —  до + . Важно, что она безразмерна, так что интерпретация эластичности
до + . Важно, что она безразмерна, так что интерпретация эластичности  =2.0 означает, что если
=2.0 означает, что если  изменится на 1%, то это приведет к изменению
изменится на 1%, то это приведет к изменению  на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
Высокий уровень эластичности означает сильное влияние независимой переменной на объясняемую переменную.

где Sxj — среднеквадратическое отклонение фактора j
где 
 .
.
Коэффициент эластичности показывает, на сколько процентов изменяется зависимая переменная при изменении фактора j на один процент. Однако он не учитывает степень колеблемости факторов.
Бета-коэффициент показывает, на какую часть величины среднего квадратического отклонения Sy изменится зависимая переменная Y с изменением соответствующей независимой переменной Хj на величину своего среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных.
Указанные коэффициенты позволяют упорядочить факторы по степени влияния факторов на зависимую переменную.
Долю влияния фактора в суммарном влиянии всех факторов можно оценить по величине дельта — коэффициентов D (j):

где  — коэффициент парной корреляции между фактором j (j = 1. m) и зависимой переменной.
— коэффициент парной корреляции между фактором j (j = 1. m) и зависимой переменной.
В качестве основного литературного источника рекомендуется использовать [4], в качестве дополнительного – [2].
http://alexlat.ucoz.ru/publ/matematika/matematika/proverka_adekvatnosti_regressionnoj_modeli/79-1-0-1418
http://zdamsam.ru/a2541.html