Алгоритмы решения уравнений параллельными методами
В данном разделе приводятся примеры параллельных алгоритмов решения следующих задач: умножения матрицы на матрицу, задача Дирихле, решение систем линейных уравнений (СЛАУ) методом Гаусса и методом простой итерации. Здесь рассматривается простой вариант сеточной задачи (задача Дирихле), когда шаг сетки в пространстве вычислений одинаков и не меняется в процессе вычислений. При динамически изменяющемся шаге сетки потребовалось бы решать такую задачу параллельного программирования, как перебалансировка вычислительного пространства между компьютерами, для выравнивания вычислительной нагрузки компьютеров, а эта задача здесь не рассматривается.
В этой главе приводятся только общие схемы решения указанных задач, а тексты программ приведены в следующих разделах, т.к. для понимания общих схем решения знать MPI не обязательно. Приведенные здесь параллельные алгоритмы решения задач являются иллюстрационными, демонстрирующими применение и возможности функций MPI , а не универсальными, предназначенными для библиотек алгоритмов.
Рассматриваемые задачи распараллеливаются крупнозернистыми методами. Для представления алгоритмов используется SPMD — модель вычислений ( распараллеливание по данным). Однородное распределение данных по компьютерам – основа для хорошего баланса времени, затрачиваемого на вычисления, и времени, затрачиваемого на взаимодействия ветвей параллельной программы. При таком распределении преследуется цель: равенство объёмов распределяемых частей данных и соответствие нумерации распределяемых частей данных нумерации компьютеров в системе. Исходными данными рассматриваемых здесь алгоритмов являются матрицы, векторы и 2 D (двумерное) пространство вычислений. В этих алгоритмах применяются следующие способы однородного распределения данных: горизонтальными полосами, вертикальными полосами и циклическими горизонтальными полосами. При распределении горизонтальными полосами матрица, вектор или 2 D пространство «разрезается» на полосы по строкам (далее слово «разрезанная» будем писать без кавычек и матрицу, вектор или 2 D пространство обозначать для краткости словом — данные). Пусть M – количество строк матрицы, количество элементов вектора или количество строк узлов 2 D пространства, P – количество виртуальных компьютеров в системе, С1 = М / Р – целая часть от деления, С2 = М % Р – дробная часть. Данные разрезаются на Р полос. Первые (Р–С2) полос имеют по С1 строки, а остальные С2 полосы имеют по С1+1 строки. Полосы данных распределяются по компьютерам следующим образом. Первая полоса помещается в компьютер с номером 0, вторая полоса – в компьютер 1, и т. д. Такое распределение полос по компьютерам учитывается в параллельном алгоритме. Распределение вертикальными полосами аналогично предыдущему, только в распределении участвуют столбцы матрицы или столбцы узлов 2 D пространства. И, наконец, распределение циклическими горизонтальными полосами. При таком распределении данные разрезаются на количество полос значительно большее, чем количество компьютеров. И чаще всего полоса состоит из одной строки. Первая полоса загружается в компьютер 0, вторая – в компьютер 1, и т.д., затем, Р-1-я полоса снова в компьютер 0, Р-я полоса в компьютер 1, и т.д.
Приведенные два алгоритма решения СЛАУ методом Гаусса показывают, что однородность распределения данных сама по себе еще недостаточна для эффективности алгоритма. Эффективность алгоритмов зависит еще и от способа распределения данных. Разный способ представления данных влечет, соответственно, и разную организацию алгоритмов, обрабатывающих эти данные.
2.1 Запуск параллельной программы
Под виртуальным компьютером понимается программно реализуемый компьютер. Виртуальный компьютер работает в режиме интерпретации его физическим процессором. В одном физическом компьютере, в общем случае, может находиться и работать одновременно виртуальных компьютеров — столько, сколько позволяет память физического компьютера. На системе МВС1000 в одном физическом компьютере создается только один виртуальный. Под виртуальной топологией здесь понимается программно реализуемая топология связей между виртуальными компьютерами на физической системе.
Создаваемая пользователем виртуальная среда позволяет обеспечивать хорошую переносимость параллельных программ, а значит и независимость от конкретных вычислительных систем. Для пользователя очень удобно решать свою задачу в рамках виртуальной среды, использовать столько компьютеров, сколько необходимо для решения его задачи и задавать такую топологию связей между компьютерами, какая необходима.
Запуск параллельной программы продемонстрируем на примере. Допустим, требуется решить задачу program.c . Алгоритм задачи распараллелен на N процессов, независимо выполняющихся и взаимодействующих друг с другом. Задана нужная для решения задачи топология связей между этими процессами: — top (например, двумерная решетка). Для решения этой задачи было бы оптимально иметь вычислительную систему из N компьютеров (Для МВС1000 должно быть N ), с той же структурой связей, что и top . Далее в каждый компьютер необходимо загрузить по одному исполняемому модулю, реализующему ветвь параллельной программы, и стартовать эти модули. Ветви параллельной программы могут реализовываться копиями одной и той же программы (для МВС1000), а могут реализовываться разными программами (в общем случае). Опции и подробности загрузки нужно смотреть в соответствующих инструкциях.
Программа предварительно компилируется:
mpicc [ ] -o program.exe program.c
В квадратных скобках стоят опции нужной оптимизации. Для разных программ, разных компьютеров в вычислительной системе, для одинаковых компьютеров, но с разными операционными системами, нужно осуществлять отдельную компиляцию.
Здесь рассматривается команда запуска параллельной программы на системе МВС1000. Предполагается, что ветви параллельной программы реализуются копиями одной и той же программы. Необходимое количество физических компьютеров и виртуальных компьютеров задаются пользователем в командной строке:
mpirun -np N program.exe
N = <1,2,3,…>— указывает количество виртуальных компьютеров, необходимых для решения рассматриваемой программы с именем — program.exe . По этой команде система MPI создает (в оперативной памяти системы из N физических компьютеров) N виртуальных компьютеров, объединенных виртуальными каналами связи со структурой полный граф. И этой группе виртуальных компьютеров присваивается стандартное системное имя MPI_COMM_WORLD . После чего пользовательская программа program.exe загружается в память каждого из созданных виртуальных компьютеров и стартует.
Отображение виртуальных компьютеров и структуры их связи на конкретную физическую систему осуществляется системой MPI автоматически, т.е. пользователю не нужно переделывать свою программу для разных физических систем (с другими компьютерами и другой архитектурой). (Рассматриваемая версия MPI не позволяет пользователю осуществлять это отображение, либо осуществлять пересылку виртуальных компьютеров в другие физические компьютеры, т.е. не позволяет перераспределять виртуальные компьютеры по физическим компьютерам).
2.2 Умножение матрицы на матрицу
Умножение матрицы на вектор и матрицы на матрицу являются базовыми макрооперациями для многих задач линейной алгебры, например итерационных методов решения систем линейных уравнений и т. п. Поэтому приведенные алгоритмы можно рассматривать как фрагменты в алгоритмах этих методов. В этой секции приведено три алгоритма умножения матрицы на матрицу. Разнообразие вариантов алгоритмов проистекает от разнообразия вычислительных систем и размеров задач. Рассматриваются и разные варианты загрузки данных в систему: загрузка данных через один компьютер; и загрузка данных непосредственно каждым компьютером с дисковой памяти. Если загрузка данных осуществляется через один компьютер, то данные считываются этим компьютером с дисковой памяти, разрезаются и части рассылаются по остальным компьютерам. Но данные могут быть подготовлены и заранее, т.е. заранее разрезаны по частям и каждая часть записана на диск в виде отдельного файла со своим именем; затем каждый компьютер непосредственно считывает с диска, предназначенный для него файл.
2.2.1 Алгоритм 1
Заданы две исходные матрицы A и B . В ычисляется произведение C = А х B , где А — матрица n1 х n2 , и B — матрица n2 х n3 . Матрица результатов C имеет размер n1 х n3 . Исходные матрицы предварительно разрезаны на полосы, полосы записаны на дисковую память отдельными файлами со своими именами и доступны всем компьютерам. Матрица результатов возвращается в нулевой процесс.
Реализация алгоритма выполняется на кольце из p1 компьютеров. Матрицы разрезаны как показано на рисунке 2.1: матрица А разрезана на p1 горизонтальных полос, матрица B разрезана на p1 вертикальных полос, и матрица результата C разрезана на p1 полосы. Здесь предполагается, что в память каждого компьютера загружается и может находиться только одна полоса матрицы А и одна полоса матрицы B .
Глава 7. Параллельные алгоритмы

Объединение нескольких вычислительных систем в общую систему распределенной обработки данных позволяет реализовать эффективные алгоритмы решения трудных задач (с экспоненциальной, факториальной сложностью). При этом возникают две проблемы:
1) управление и планирование вычислений по нескольким задачам для мультипроцессорных систем с различной архитектурой
2) построение быстрого алгоритма решения одной задачи на мультипроцессорной ЭВМ, что подразумевает распараллеливание исходного последовательного алгоритма её решения.
Если задачу нельзя решить с помощью последовательного алгоритма, разработанного одним из эффективных методов, то прибегают к распараллеливанию алгоритма с целью увеличения его быстродействия.
Распараллеливание (десеквенция) – преобразование последовательного алгоритма в эквивалентный ему параллельный алгоритм, соответствующий архитектуре какой-либо мультипроцессорной ЭВМ.
Примеры задач, в которых используется распараллеливание:
1) Одновременное выполнение операций ввода/вывода.
2) Формирование и обнуление массива.
3) Арифметические и логические операции над векторами и матрицами.
4) Одновременное отслеживание ветвей в различных узлах дерева.
5) Конвейерная обработка.
6) Решение СЛАУ большого порядка.
7) Параллельная сортировка.
8) Поиск максимума/минимума функции.
Наиболее желательными (даже скорее обязательными) признаками параллельных алгоритмов и программ являются:
- параллелизм, маштабируемость, локальность, модульность.
Параллелизм указывает на способность выполнения множества действий одновременно, что существенно для программ выполняющихся на нескольких процессорах.
Маштабируемость — другой важнейший признак параллельной программы, который требует гибкости программы по отношению к изменению числа процессоров, поскольку наиболее вероятно, что их число будет постоянно увеличиваться в большинстве параллельных сред и систем.
Локальность характеризует необходимость того, чтобы доступ к локальным данным был более частым, чем доступ к удаленным данным. Важность этого свойства определяется отношением стоимостей удаленного и локального обращений к памяти. Оно является ключом к повышению эффективности программ на архитектурах с распределенной памятью.
Модульность отражает степепь разложения сложных объектов на более простые компоненты. В параллельных вычислениях это такой же важный аспект разработки программ, как и в последовательных вычислениях.
Процессы и нити. Будем понимать под процессом последовательность действий, составляющих некоторое вычисление, которая характеризуется:
- сопоставленной ему программой/подпрограммой, то есть упорядоченной последовательностью операций, реализующих действия, которые должны осуществляться процессом; содержимым соответствующей ему памяти, то есть множеством данных, которыми этот процесс может манипулировать; дескриптором процесса, то есть совокупностью сведений, определяющих состояние ресурсов, предоставленных процессу.
Имеется так же большое число уточнений вида процесса, режима и условий работы процесса: последовательный процесс, параллельный процесс, пакетный процесс, интерактивный процесс, независимый процесс, взаимодействующий процесс и т. д.
Будем различать, где это необходимо, полновесные и легковесные процессы.
Полновесные процессы (tasks — задачи) — это процессы, выполняющиеся внутри защищенных участков памяти операционной системы, то есть имеющие собственные виртуальные адресные пространства для статических и динамических данных. В мультипрограммной среде управление такими процессами тесно связанно с управлением и защитой памяти, поэтому переключение процессора с выполнения одного процесса на выполнение другого является дорогой операцией.
Легковесные процессы (threads — нити), называемые еще сопроцессами, не имеют собственных защищенных областей памяти. Они работают в мультипрограммном режиме одновременно с активировавшей их задачей и используют ее виртуальное адресное пространство, в котором им при создании выделяется участок памяти под динамические данные (стек), то есть они могут обладать собственными локальными данными. Сопроцесс описывается как обычная функция, которая может использовать статические данные программы.
Каналы. Понятие канала используется для описания событий, называемых взаимодействиями, которые состоят в передаче сообщений между процессами. Каналы используются для передачи сообщений в одном направлении и только между двумя процессами. Канал, используемый процессом только для вывода сообщений, называется выходным каналом этого процесса, а используемый только для ввода — входным каналом.
Итак, канал — это однонаправленная двухточечная (соединяющая только два процесса) «коммуникационная линия», позволяющая процессам обмениваться данными. Операции обмена сообщениями достаточно продолжительные по времени операции, поэтому в разных моделях, системах используются разные типы поведения операций приема/передачи сообщений. Различают следующие виды каналов:
- Синхронные.
Отправив сообщение, передающий процесс ожидает от принимающего подтверждение о приеме сообщения прежде, чем послать следующее сообщение, т. е. принимающий процесс не выполняется, пока не получит данные, а передающий — пока не получит подтверждение о приеме данных. Асинхронно/синхронные.
Операция передачи сообщения асинхронная — она завершается сразу (сообщение копируется в некоторый буфер, а затем пересылается одновременно с работой процесса-отправителя), не ожидая того, когда данные будут получены приемником.
Операция приема сообщения синхронная: она блокирует процесс до момента поступления сообщения. Асинхронные.
Обе операция асинхронные, то есть они завершаются сразу. Операция передачи сообщения работает, как и в предыдущем случае. Операция приема сообщения, обычно, возвращает некоторые значения, указывающие на то, как завершилась операция — было или нет принято сообщение.
В некоторых реализациях операции обмена сообщениями активируют сопроцессы, которые принимают/отправляют сообщения, используя временные буфера и соответствующие синхронные операции. В этом случае имеется ещї синхронизирующая операции, которая блокирует процесс до тех пор, пока не завершатся все инициированные операции канала.
При работе с каналами необходимо следить за тем, чтобы не случилась блокировка взаимодействующих процессов (дедлок). Например, процесс A не может передать сообщение процессу B, поскольку процесс B ждет, когда процесс A примет сообщение от него. Это одна из простейших ситуаций, в более сложных случаях циклические зависимости могут охватывать много процессов, причем появление дедлока может завесить от данных.
Семафоры — средство управления процессами. Семафоры традиционно использовались для синхронизации процессов, обращающихся к разделяемым данным. Каждый процесс должен исключать для всех других процессов возможность одновременно с ним обращаться к этим данным (взаимоисключение). Когда процесс обращается к разделяемым данным, говорят, что он находится в своем критическом участке.
Для решения задачи синхронизации необходимо, в случае если один процесс находится в критическом участке, исключить возможность вхождения для других процессов в их критические участки. Хотя бы для тех, которые обращаются к тем же самым разделяемым данным. Когда процесс выходит из своего критического участка, то одному из остальных процессов, ожидающих входа в свои критические участки, должно быть разрешено продолжить работу.
Процессы должны как можно быстрее проходить свои критические участки и не должны в этот период блокироваться. Если процесс, находящийся в своем критическом участке, завершается (возможно, аварийно), то необходимо, чтобы некоторый другой процесс мог отменить режим взаимоисключения, предоставляя другим процессам возможность продолжить выполнение и войти в свои критические участки.
Семафор — это защищенная переменная, значение которой можно опрашивать и менять только при помощи специальных операций wait и signal и операции инициализации init. Двоичные семафоры могут принимать только значения 0 и 1. Семафоры со счетчиками могут принимать неотрицательные целые значения.
Операция wait(s) над семафором s состоит в следующем: если s > 0 то s:=s-1 иначе (ожидать на s), а операция signal(s) заключается в том, что: если (имеются процессы, которые ожидают на s), то (разрешить одному из них продолжить работу), иначе s:=s+1.
Операции являются неделимыми. Критические участки процессов обрамляются операциями wait(s) и signal(s). Если одновременно несколько процессов попытаются выполнить операцию wait(s), то это будет разрешено только одному из них, а остальным придется ждать.
Семафоры со счетчиками используются, если некоторые ресурс выделяется из множества идентичных ресурсов. При инициализации такого семафора в его счетчике указывается число элементов множества. Каждая операция wait(s) уменьшает значения счетчика семафора s на 1, показывая, что некоторому процессу выделен один ресурс из множества. Каждая операция signal(s) увеличивает значение счетчика на 1, показывая, что процесс возвратил ресурс во множество. Если операция wait(s) выполняется, когда в счетчике содержится нуль (больше нет ресурсов), то соответствующий процесс ожидает, пока во множество не будет возвращен освободившийся ресурс, то есть пока не будет выполнена операция signal.
Сложность ПА оценивается гипотезой Минского: параллельные вычислительные системы, выполняющие последовательную программу под множеством исходных данных размера N, дают прирост производительности по крайней мере на показатель 1/log(N). Сложность полученного параллельного алгоритма (ПА) дает выигрыш как минимум на порядок по сравнению с последовательным алгоритмом.
Однако при распараллеливании задач есть ряд «подводных камней»:
1) Во многих случаях ПА дает малый прирост производительности (быстродействия), поэтому проще применить эффективные методы построения быстрых последовательных алгоритмов для однопроцессорных универсальных ЭВМ, чем распараллеливать задачу для многопроцессорных специальных ЭВМ.
Кроме того, выбор средств разработки ПА весьма ограничен, а полученный параллельный код менее оптимизирован, чем для последовательных ЭВМ на этапе компиляции.
2) Быстрые последовательные алгоритмы во многих случаях дают более высокое быстродействие, чем ПА, построенные на основе прямого алгоритма решения задачи, а распараллеливание быстрого последовательного алгоритма является сложной задачей.
3) Для разработки ПА необходимо разбить задачу на независимые подзадачи с объединением результатов подзадач на последнем этапе. Этот процесс не поддается отладке, и быстродействие всего алгоритма сильно зависит от размеров подзадач и последнего этапа. В лучшем случае подзадачи должны быть маленьких и одинаковых размеров.
В качестве рекомендаций при построении параллельных алгоритмов следует учитывать:
· Распараллеливание полезно только в том случае, если все попытки создать быстрый последовательный алгоритм решения задачи оказались неудачными.
· При распараллеливании используйте балансировку при разбиении задачи на подзадачи и избегайте рекурсий.
Рассмотрим примеры параллельных алгоритмов.
ПА отыскания минимального остовного дерева.
 Если одновременно выбрать для каждой вершины связанное с ней ребро с минимальным весом, то в остовном дереве возникнут замкнутые циклы, а это недопустимо.
Если одновременно выбрать для каждой вершины связанное с ней ребро с минимальным весом, то в остовном дереве возникнут замкнутые циклы, а это недопустимо.
 Однако если выбрать для каждой вершины Vi ребро наименьшего веса, которое идентично вершине Vj (j¹i) с наименьшим индексом j, то исключается возможность циклов.
Однако если выбрать для каждой вершины Vi ребро наименьшего веса, которое идентично вершине Vj (j¹i) с наименьшим индексом j, то исключается возможность циклов.
Это условие позволяет найти остовное дерево минимального веса за один шаг ПА. Однако при большом числе вершин рассмотренный алгоритм не настолько быстрый. Модификация этого алгоритма, предложенная Соллином, более эффективна. При этом сложность задачи уменьшается с O(N2) до O(log2N).
Задача сортировки массива из N целых чисел.
Есть ли параллелизм в произвольном алгоритме и как его использовать лучшим образом
Параллелизации обработки данных в настоящее время применяется в основном для сокращения времени вычислений путем одновременной обработки данных по частям на множестве различных вычислительных устройств с последующим объединением полученных результатов. Параллельное выполнение позволяет “обойти” сформулированный лордом Рэлеем в 1871 г. фундаментальный закон, согласно которому (в применимости к тепловыделению процессоров) мощность их тепловыделения пропорциональна четвертой степени тактовой частоты процессора (увеличение частоты вдвое повышает тепловыделение в 16 раз) и фактически заменить его линейным от числа параллельных вычислителей – при сохранении тактовой частоты). Ничто не дается даром – задача выявления (обычно скрытого для непосвящённого наблюдателя, [1]) потенциала параллелизма в алгоритмах не является «лежащей на поверхности«, а уж эффективность его (параллелизма) использования – тем более.
Ниже приведена иллюстрация процесса выявления параллелизма для простейшего случая вычисления выражения axb+a/c (a, b, c – входные данные).

а) – “облако операторов” (последовательность выполнения не определена), б) – полностью последовательное выполнение, не определена), б) – полностью последовательное выполнение, в) – параллельное исполнение
Даже в таком примитивном алгоритме параллельное выполнение ускорило вычисления в полтора раза, но потребовало двух вычислителей вместо одного. Обычно с увеличением числа операторов (усложнением алгоритма) ускорение вычислений возрастает (хотя имеются и полностью нераспараллеливаемые на уровне арифметических действий алгоритмы – напр., вычисление чисел Фибоначчи). Для приведенного на рис.1 алгоритма все выкладки легко выполняются “в уме”, но для реальных (много более сложных алгоритмов) требуется машинная обработка.
Параллельная вычислительная система включает несколько вычислителей (арифметико-логических устройств), объединённых общей или локальной оперативной памятями и кэшами. Современные параллельные системы часто имеют не только гомогенное, но и гетерогенное вычислительное поле. Задача распределения вычислений между отдельными вычислителями приводит к разработке расписания (плана) вычислений. Проблемой является многозначность расписаний параллельного выполнения алгоритма в общем случае это NP-полная задача [2], точное решение (при заданных оптимизационных требованиях) которой можно получить только методом полного перебора (что нереально при числе операторов уже более сотен-тысяч). Выходом является использование эвристических методов, исходя из сложности данную область знания можно обоснованно отнести к наиболее сложным случаям “Науки о данных” (Data Science).
Параметрам выполнения распространенных алгоритмов в параллельном варианте посвящен известный ресурс AlgoWiki [3].
Фактические рассмотренные действия соответствуют схеме, приведённой ниже. Здесь в верхней части показан поток последовательно выполнявшихся операций (вектор времени направлен сверху вниз – как показано стрелкой), в нижней части рисунка – результат распараллеливания (считаем, что поле параллельных вычислителей гетерогенно и включает два вычислителя одного типа и три другого — что показано квадратами разного размера). Т.о. параллельное выполнение исходно последовательного потока команд разбивается на 5 потоков, причём каждый выполняется на определённом вычислителе из заданного поля параллельных вычислителей.

Часть операций в параллельных потоках показана иным цветом – не всегда удаётся полностью заполнить цепочку команд в каждом из потоков (принято говорить, что это снижает плотность кода), что определяется ограничениями, являющимися следствием внутренних свойств алгоритмов. Проблемой является определение принципа функционирования устройства преобразования последовательного потока команд в ряд параллельных (собственно операция распараллеливания), показанного в виде облака с вопросительными знаками внутри. Такие устройства могут функционировать как на аппаратном так и на программном уровнях и выполнять свои действия как в RealTime (во время выполнения программы, чаще относится к первому уровню) так и в DesignTime (во время трансляции, чаще ко второму).
Особенно интересен, с точки зрения автора, вариант параллелизации для языков программирования высокого уровня без явного указания распараллеливания и в системах c концепцией ILP (Instruction-Level Parallelism, параллелизм на уровне команд, с реализацией посредством вычислительной архитектуры EPIC (Explicitly Parallel Instruction Computing, явный параллелизм выполнения команд). При этом аппаратное обеспечение вычислительных систем сильно упрощается и все проблемы выявления параллелизма и построение собственно расписания выполнения программы для заданной конфигурации параллельной вычислительной системы ложатся на компилятор, что ведет к его усложнению и снижению скорости компиляции.
Одним из эффективных способов решения задачи определения рациональных планов выполнения параллельной задачи является представление алгоритма в виде графа с последующей его (графа) обработкой (при этом собственно граф остается неизменным, а меняется лишь его представление). Часто применяется Информационный Граф Алгоритма (ИГА). ИГА отображает зависимость вида “операторы — операнды”, при этом вершины графа ассоциируются с операторами (группами операторов) программы, а дуги – с линиями передачи (хранения) данных). ИГА обладает свойствами направленности, ацикличности и параметризован по размеру обрабатываемых данных (из-за последнего приходится исследовать один и тот же алгоритм с конкретным набором исходных данных).
Одной из важных процедур выявления параллелизма по заданному ИГА является получения его исходной (обладающей свойством каноничности) Ярусно-Параллельной Формы (ЯПФ), [4]. При этом условием расположением операторов на едином ярусе является независимость их друг от друга по информационным связям (необходимое условие их параллельного выполнения).
Получение такой (без условия ограниченности количества операторов на ярусах) ЯПФ требует O(N 2 ) действий, где N – число операторов (вершин графа), ее высота (общее число ярусов) равна увеличенной на единицу длине критического пути в ИГА. Напрямую использовать такую ЯПФ в качестве основы для построения расписания выполнения параллельной программы обычно затруднительно (ширина некоторых ярусов часто сильно превышает число имеющихся параллельных вычислителей). Но т.к. вычисление такой ЯПФ вычислительно малозатратно, во многих случаях целесообразно начинать анализ именно с ее получения и в дальнейшем проводить модификацию этой ЯПФ с учетом конкретных задач. При этом при каждой модификации ЯПФ получаем новую форму, полностью соответствующую исходному ИГА.
Определенным недостатком использования метода построения ЯПФ для получения расписания является невозможность учета времени исполнения операторов, однако для современных микроархитектур характерно всемерное стремление к одинаковости времен выполнения всех операторов, что как раз повышает удобство использования ЯПФ.
Разберём процедуру получения несложного алгоритма вычисления вещественных корней полного квадратного уравнения ax 2 +bx+c=0. На рис. ниже показана таблица всех арифметических действий, необходимых для решения этой задачи (всего 11 операторов, не считая исходных данных).
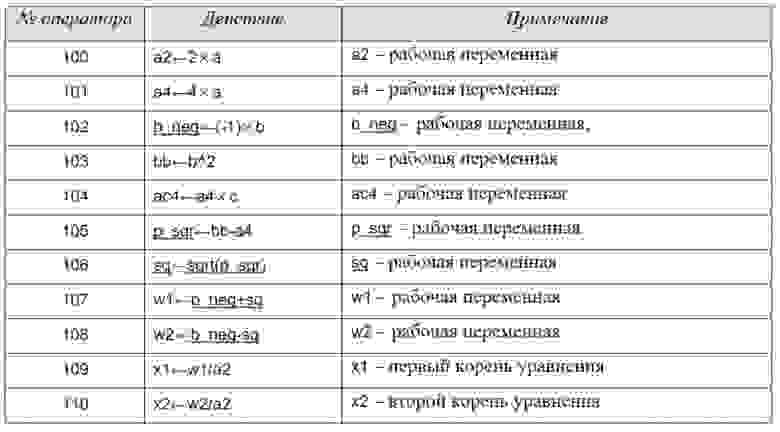 Таблица — список арифметических действий (операторов) для решения задачи о нахождении действительных корней полного квадратного уравнения
Таблица — список арифметических действий (операторов) для решения задачи о нахождении действительных корней полного квадратного уравнения
Следующий шаг – получение информационного графа рассматриваемого алгоритма по (вышеприведённому) списку операторов (рис. ниже). Здесь окружности – операторы, направленные стрелки соответствуют передаваемым данным. Вводные данные представлены тремя переменными (а,b,с) и константами (2,4,-1), выходные данные – корни уравнения х1 и х2. Обратите внимание – в структуре графа нет никаких («лежащих на поверхности») намёков на наличие параллелизма в алгоритме!
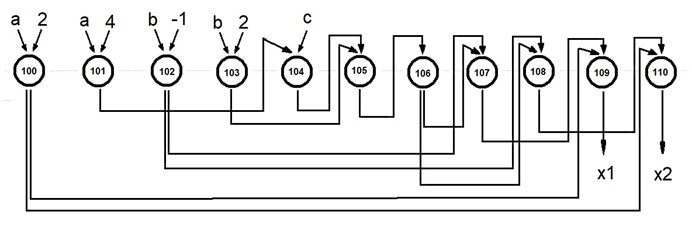 Информационный граф алгоритма нахождения вещественных корней полного квадратного уравнения
Информационный граф алгоритма нахождения вещественных корней полного квадратного уравнения
Полученная ЯПФ этого алгоритма – внизу (можно проверить – все информационные связи операторов остались неизменными, изменилась лишь форма представления графа).
 На рисунке — ярусно-параллельная форма алгоритма решения полного квадратного уравнения в вещественных числах в канонической форме (номера ярусов ЯПФ расположены справа)
На рисунке — ярусно-параллельная форма алгоритма решения полного квадратного уравнения в вещественных числах в канонической форме (номера ярусов ЯПФ расположены справа)
Показанная ЯПФ уже является расписание выполнения параллельной программы (выполнение начинается “сверху вниз”, требует 6 относительных единиц времени и 4-х параллельных вычислителей). При этом число задействованных вычислителей по ярусам крайне неравномерно (важно при однозадачном режиме работы вычислительной системы) – на 1-м ярусе задействованы все 4, на 2,3,4 — только один и по два на 5- и 6 ярусах. Однако легко видеть, что простейшее преобразование (показанные красным пунктиром допустимые перестановки операторов с яруса на ярус) позволяют выполнить тот же алгоритм за то же (минимальное из возможных) время всего на двух вычислителях! Не для любого алгоритма получается столь идеально – часто для снижения требуемого числа параллельных вычислителей единственным путем является увеличение времени выполнения алгоритма (возрастание числа ярусов ЯПФ).
Для решения задач определения рационального (на основе заданных критериев) расписания выполнения произвольных алгоритмов создан инструментальный программный комплекс, включающая два модуля — D-F и SPF@home. Свободная выгрузка инсталляционных файлов доступна с ресурсов http://vbakanov.ru/dataflow/content/install_df.exe и http://vbakanov.ru/spf@home/content/install_spf.exe соответственно (дополнительная информация по теме — http://vbakanov.ru/dataflow/dataflow.htm и http://vbakanov.ru/spf@home/spf@home.htm).
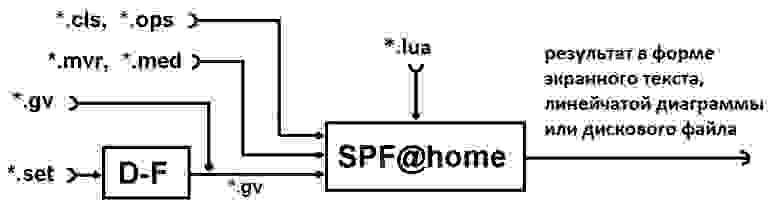 На рисунке — схема инструментального комплекса (*.set и *.gv – программный файл и файл информационного графа анализируемой программы соответственно, *.mvr, *.med – файлы метрик вершин и дуг графа алгоритма соответственно, *.cls, *.ops – файлы параметров вычислителей и операторов программы соответственно, *.lua – текстовый файл на языке Lua, содержащий методы реорганизации ЯПФ)
На рисунке — схема инструментального комплекса (*.set и *.gv – программный файл и файл информационного графа анализируемой программы соответственно, *.mvr, *.med – файлы метрик вершин и дуг графа алгоритма соответственно, *.cls, *.ops – файлы параметров вычислителей и операторов программы соответственно, *.lua – текстовый файл на языке Lua, содержащий методы реорганизации ЯПФ)
На вход комплекса поступает описание анализируемого алгоритма в форме традиционной программы (set-файлы) или формального описания в виде ориентированного ациклического информационного графа алгоритма – ИГА в форме gv-файов (зависимость вида “операторы — операнды”, при этом вершины графа ассоциируются с операторами (группами операторов) программы, а дуги – с линиями передачи (хранения) данных). ИГА обладает свойствами направленности, ацикличности и параметризован по размеру обрабатываемых данных (из-за последнего приходится исследовать один и тот же алгоритм с конкретным набором исходных данных).
В данном случае исследования по разработке и совершенствованию методов решения вопроса создания эффективных эвристик генерации обобщенного расписания (каркаса) выполнения параллельных программ проводились с помощью нижеописанного специализированного программного комплекса. Термин “каркас” здесь обоснован вследствие абстрагирования в данной работе от конкретных технологий параллельного программирования.
Для управления созданием расписания используется встроенный скриптовый язык Lua (Lua написан на «чистом C», обеспечивает неявную динамическую типизацию, поддерживает прототипную модель объектно-ориентированного программирования и был выбран на основе свойств его компактности, полной открытости исходных кодов и близости синтаксиса к распространенному С).
Родительское приложение создано с использованием языка программирования С++, является GUI Win’32-программой и доступно для свободной выгрузки и использования (как и исходные тексты) через GIT-репозиторий. Вывод данных осуществляется на экран в текстовом и графическом форматах и в файлы (также в структурированной текстовой форме).
Сочетание компилируемой родительской программы и встроенного интерпретатора скриптового языка позволило обеспечить высокую производительность и гибкость (Lua-вызовы фактически являются “обёртками” для API-функций модуля SPF@home).
Копии экранов обсуждаемого комплекса приведены на изображениях ниже (программные модули D-F и SPF@home соответственно).
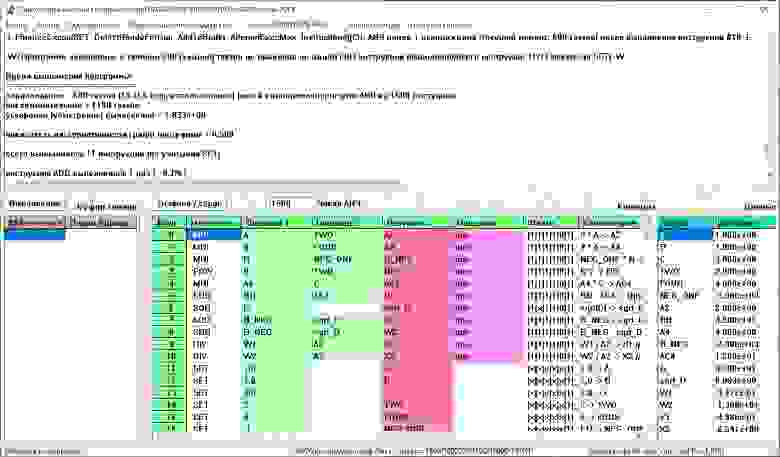
Модуль D-F (Data-Flow) является фактически универсальным вычислителем, выполняющим программу на ассемблероподобном языке на заданном числе параллельных вычислителей. При их числе большем 1 вычисления ведутся по принципу “Data-Flow” (реализуется статическая потоковая архитектура), операторы выполняются по условию готовности их к выполнению (ГКВ), что является следствием присвоенности значений все операндам данного оператора; при единичном вычислителе реализуется обычное последовательное выполнение. В случае превышения числа ГКВ-операторов числа свободных вычислители используется задаваемая система приоритетов их выполнения, условное выполнение реализуется предикатным выполнением, для реализации циклов используется система макросов, “разворачивающая” циклические структуры. Модуль D-F имеет встроенную систему проверку корректности ИГА, для контроля выполнения используется динамическая цветовая индикация выполненности операторов.
Программы для D-F составляются в императивном стиле, каждый оператор по уровню сложности сопоставим с уровнем ассемблера, порядок расположения операторов в программе несущественен. Нижеприведен пример записи программы вычисления вещественных корней полного квадратного уравнения (входной set-файл для модуля D-F, механизм предикатов в приведенном варианте не используется):
Такая программа может рассматриваться как результат компиляции с языков программирования высокого уровня, не содержащих явных указаний на параллелизацию вычислений. В модуле D-F программа отлаживается, результат выдается в файл ИГА-формата для обработки в модуле SPF@home. В модуле SPF@home для получения ЯПФ из gv-файла (стандартный формат текстовых файлов описаний графов), запоминания его во внутреннем представлении системы, создание ЯПФ и запоминание его в Lua-массиве для дальнейшей обработки может быть выполнен следующий код (двойной дефис означает начало комментария до конца строки):
Для удобства данные метрик операторов и дуг графа выведены из gv-файлов и расположены в текстовых mvr и med-файлах, для моделирования выполнения программ на гетерогенном поле параллельных вычислителей служат cls и ops-файлы сопоставления возможностей выполнения определенных операторов на конкретных вычислителях. Преимуществом такого подхода является возможность задания нужных параметров целой группе объектов (списком типа “от-до”, причём список может быть и вырожденным) одной строкой файла. Задавать параметры можно по практически неограниченному количеству тегов, определяемых разработчиком.
Модуль SPF@home также позволяет определять “время жизни данных” между ярусами ЯПФ, что необходимо для определения/оптимизации параметров устройств временного хранения данных (быстродействующей разделяемой памяти — регистров общего назначения или низкоуровневого кэша). Собственно размер данных при этом берётся из med-файлов.
Система нацелена в основном на анализ программ, созданных с использованием языков программирования высокого уровня без явного указания распараллеливания и в системах c концепцией ILP (Instruction-Level Parallelism, параллелизм на уровне команд), хотя возможности модуля SPF@home позволяют использовать в качестве неделимых блоков последовательности команд любого размера.
Т.о. процедура составления расписания параллельного выполнения программы заключается в составлении Lua-программы, реализующей процедуры реорганизации ЯПФ в соответствие с заданными требованиями. Тремя типовыми встречающимися подзадачами (в реальном случае обычно требуется выполнение нескольких из этих подзадач одновременно) являются:
I. “Балансировка” числа операторов по всем ярусам заданной ЯПФ без увеличения ее высоты (минимизируется требуемое для решения задачи число параллельных вычислителей).
II. Получение расписания выполнения программы на заданном числе параллельных вычислителей с возможным увеличением высоты ЯПФ (фактически временем выполнения программы).
III. Получение расписания выполнения программы на гетерогенном поле параллельных вычислителей.
Моделирования проводилось на часто используемых при расчётах алгоритмах (в основном из области линейной алгебры) относительно небольшой размерности по входным данным; автор искренне надеется на сохранение выявленных тенденций и для много больших размерностей (во многих случаях требуемый эффект с большей вероятностью достигается при возрастании размерности).
Кроме того, из общих соображений нет смысла оптимизировать всю (возможно, содержащую многие миллионы машинных команд) программу, рационально оптимизировать только участки, выполнение которых занимает максимум времени (выявление таких участков – самостоятельная задача и здесь не рассматривается).
Собственно последовательность получения рационального расписания выполнения параллельной задачи будут следующей:
1) Получение исходной (не имеющей ограничений по ширине ярусов) ЯПФ.
2) Модификация этой ЯПФ в нужном направлении путем целенаправленной перестановки операторов с яруса на ярус при сохранении исходных связей в информационном графе алгоритма.
Описанная процедура итеративна и является естественно-последовательной для решения поставленной задачи. Второй параграф последовательности выполнятся в зависимости от выбранных исследователя критериев оптимизации метода разработки расписания (получение ЯПФ минимальной ширины, заданное ограничение ширины ЯПФ, минимизация числа регистров временного хранения данных, комбинированная функция цели). При этом сначала выполняются “информационные” API-вызовы и на основе полученных данных реализуются “акционные” вызовы (дающие информацию о состоянии ЯПФ и осуществляющие реальную перестановку операторов соответственно, причем перед выполнением вторых всегда проверяется условие неизменности исходных информационных связей в графе после совершения действия).
При необходимости в любой момент можно “откатить” сделанные изменения (пользуясь данными файла протокола) и начать новый цикл реорганизации ЯПФ (графическая интерпретация ЯПФ в виде линейчатой диаграммы позволяет визуально отслеживать изменения ЯПФ). По желанию исследователя исходная ЯПФ может быть получена в “верхней” или “нижней” форме (все операторы расположены на ярусах с минимальными или максимальными номерами соответственно; при этом тенденции перемещения операторов по ярусам будут в основном “вниз” или ”вверх”).
Методы достижения цели могут быть собственно разработанными эвристиками (обычно ограниченной сложности для возможности использования в режиме реального времени) или стандартными — метод “ветвей и границ”, генетические, “муравьиные” и др. (чаще используются при исследовательской работе). Возможности системы включают использование “оберток” многофункциональных системных Windows-вызовов WinExec, ShellExecute и CreateProcess, так что исследователь имеет возможность вызова и управления любыми внешними программами (например, использовать тот же METIS в качестве процесса-потомка), файловое обслуживание при этом осуществляется средствами Lua.
В качестве примера на рис.6 приведены (в форме линейчатых диаграмм распределения ширин ярусов ЯПФ) результаты вычислительных экспериментов с общим символическим названием “Bulldozer”, возникшим по аналогии с отвалом бульдозера, перемещающим грунт с “возвышенностей” во “впадины”.
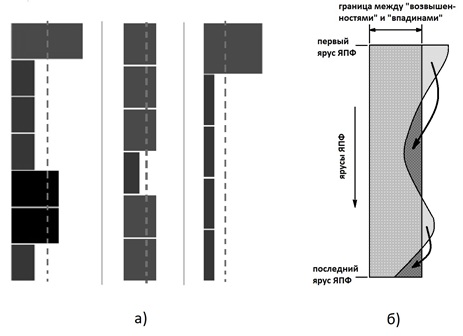 На рис. показаны линейчатые диаграммы ширин ярусов реальных ЯПФ из копий экранов при работе системы SPF@home (средне-арифметическое значение ширин показано пунктиром, a) и символическая схема действия метода “Bulldozer” — б)
На рис. показаны линейчатые диаграммы ширин ярусов реальных ЯПФ из копий экранов при работе системы SPF@home (средне-арифметическое значение ширин показано пунктиром, a) и символическая схема действия метода “Bulldozer” — б)
Многочисленные вычислительные эксперименты показывают, что во многих случаях удается значительно (до 1,5-2 раз) снизить ширину ЯПФ без увеличения высоты, но почти никогда до минимальной величины (средне-арифметическое значение ширин ярусов).
Т.о. истинной ценностью данного исследования являются именно эвристические методы (реализованные на языке Lua) создания расписаний выполнения параллельных программ при определённых ограничениях (напр., c учетом заданного поля параллельных вычислителей, максимума скорости выполнения, минимизации или ограничения размеров временного хранения данных и др.).
В систему SPF@home включена возможность расчёта времени жизни локальных (для данного алгоритма) данных. Интересно, что даже при полностью последовательном выполнении алгоритма имеется возможность оптимизировать последовательность выполнения отдельных операторов с целью минимизации размера локальных данных. Выявленная возможность экономии устройств для хранения временных данных (в первую очередь дорогостоящих регистров общего назначения) прямо ведет к экономии вычислительных ресурсов (это может быть важно, например, для программируемых контроллеров и специализированных управляющих компьютеров). Полученные данные верны не только для однозадачного режима выполнения программ, но и применимы для многозадачности с перегрузкой контекстов процессов при многозадачности.
Целевыми потребителями разработанных методов генерации расписаний являются разработчики компиляторов, исследователи свойств алгоритмов (в первую очередь в направлении нахождения и использования потенциала скрытого параллелизма) и преподаватели соответствующих дисциплин.
Разрабатываемые с помощью вышеописанных систем методы являются необходимым этапом в реализации распараллеливающих блоков компиляторов для заданной системы команд процессора (на практике придётся учесть немало особенностей конкретной системы команд, однако без наличия общего подхода конкретная реализация практически всегда оказывается малоэффективной).
Список литературы
1. Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. — СПб.: БХВ-етербург, 2002. — 608 c.
2. Гери М., Джонсон Д. Вычислительные машины и труднорешаемые задачи. : — Мир, Книга по Требованию, 2012. — 420 c.
3. AlgoWiki. Открытая энциклопедия свойств алгоритмов. URL: http://algowiki-project.org (дата обращения 31.07.2020).
4. Федотов И.Е. Параллельное программирование. Модели и приёмы. — М.: СОЛОН-Пресс, 2018. — 390 с.
5. Roberto Ierusalimschy. Programming in Lua. Third Edition. PUC-Rio, Brasil, Rio de Janeiro, 2013. — 348 p.
Предыдущие публикации на тему исследования параметров функционирования вычислительных систем методами математического моделирования:
http://pandia.ru/text/78/076/92563.php
http://habr.com/ru/post/530078/