Частные уравнения множественной регрессии. Индексы множественной и частной корреляции и их расчет
На основе линейного уравнения множественной регрессии 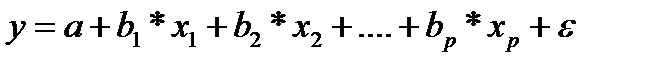
могут быть найдены частные уравнения регрессии:
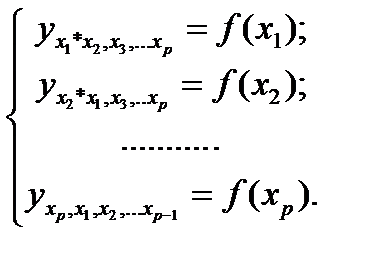 (25.1)
(25.1)
т.е. уравнения регрессии, которые связывают результативный признак с соответствующими факторами хi при закреплении других учитываемых во множественной регрессии факторов на среднем уровне. В случае линейной регрессии частные уравнения имеют следующий вид:
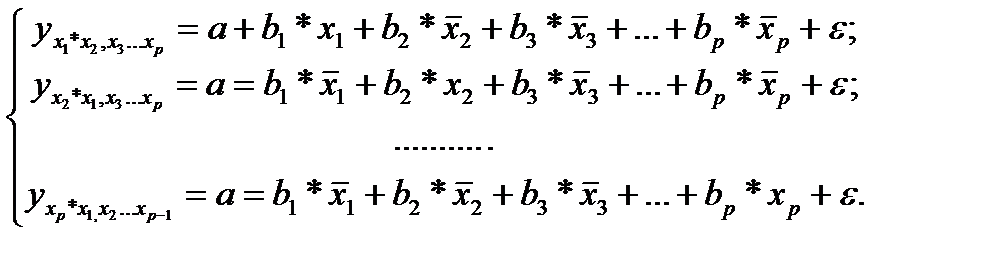 (25.2)
(25.2)
Подставляя в эти уравнения средние значения соответствующих факторов получаем систему уравнений линейной регрессии, т.е. имеем:
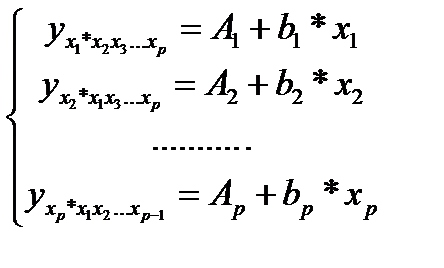 (25.3)
(25.3)
где 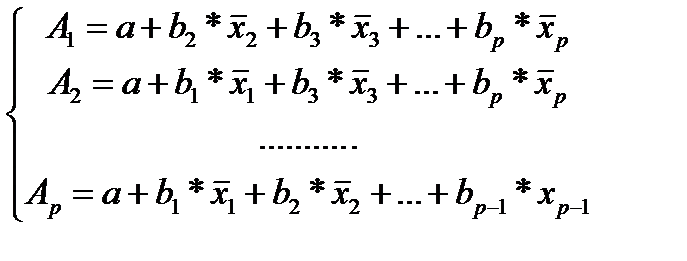 (25.4)
(25.4)
Частные уравнения регрессии характеризуют изолированное влияние фактора на результат, ибо другие факторы закреплены на низменном уровне. Эффекты влияния других факторов присоединены в них к свободному члену уравнения множественной регрессии (Аi).Это позволяет на основе частных уравнений регрессии определять частные коэффициенты эластичности
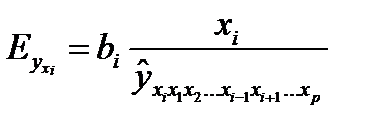 (25.5)
(25.5)
На основании данной информации могут быть найдены средние по совокупности показатели эластичности: 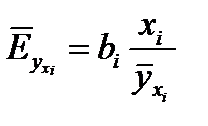 .
.
Практическая значимость уравнения множественной регрессии оценивается с помощью показателя множественной корреляции и его квадрата – коэффициента детерминации. Показатель множественной корреляции характеризует тесноту совместного влияния факторов на результат.
Независимо от вида уравнения индекс множественной корреляции рассчитывается по формуле:
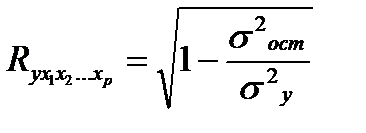 , (25.6)
, (25.6)
где σ 2 y — общая дисперсия результативного признака,
σ 2 ост — остаточная дисперсия .
Чем ближе его значение к 1, тем теснее связь результативного признака со всем набором исследуемых факторов.
Сравнивая индексы множественной регрессии и парной корреляции, можно сделать вывод о целесообразности включения в уравнение регрессии того или иного фактора. В частности, если дополнительно включенные в уравнение множественной регрессии факторы третьестепенны, то индекс множественной корреляции практически совпадает с индексом парной корреляции.
Если оценивается значимость влияния фактора хi в уравнении регрессии, то определяется частный F- критерий:
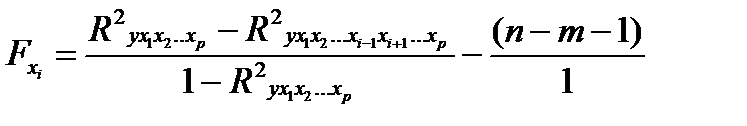 (25.7)
(25.7)
Значимость коэффициентов чистой регрессии производится по t — критерию Стьюдента.
24. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии
Частные коэффициенты (или индексы) корреляции характеризуют тесноту связи между результатом и соответствующим фактором при устранении влияния других факторов, включенных в уравнение регрессии.
Чем больше доля полученной разности в остаточной вариации, тем теснее связь между у и x2 , при неизменности действия фактора x1
Величина, рассчитываемая формулой:
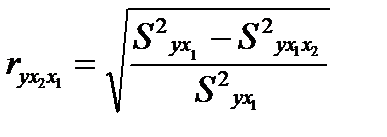 (26.1)
(26.1)
называется индексом частной корреляции для фактора х2:
Аналогично определяется индекс частной корреляции для фактора x1.
Выражая остаточную дисперсию через показатель детерминации
S 2 ост = σ 2 у (1-r 2 ), имеем формулу частной корреляции:
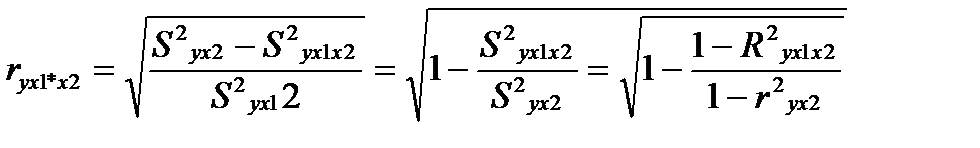 (26.2)
(26.2)
25. Коэффициент множественной корреляции
Практическая значимость уравнения множественной регрессии оценивается показателем множественной корреляции
Показатель множественной корреляции характеризует тесноту связи рассматриваемого набора факторов с исследуемым при знаком, или оценивает тесноту совместного влияния факторов на результат.
Независимо от формы связи показатель множественной корреляции можёт быть найден как индекс множественной корреляции:
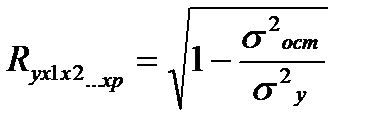 (27.1)
(27.1)
σ 2 ост – остаточная дисперсия для уравнения у=f(x1,x2,… xр)
σ 2 у – общая дисперсия результативного признака
Методика построения индекса множественной корреляции аналогична построению индекса корреляции для парной зависимости. Его пределы от 0 до 1. Чем ближе его значение к 1, тем теснее связь результативного признака со всем I бором исследуемых факторов. Величина индекса множественно корреляции должна быть больше или равна максимальному парному индексу корреляции: —
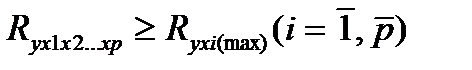 (27.2)
(27.2)
Обоснованность включения факторов в регрессионный анализ приведет к существенному отличию показателя от индекса корреляции парной зависимости. При включении модель маловажных факторов происходит уравнение индекса множественной корреляции с индексом парной корреляции. Сравнивая индексы множественной и парной корреляции делают заключение о возможности включения в уравнение регрессии того или иного фактора.
Расчет индекса множественной Корреляции предполагает определение уравнения множественной регрессии и на его основе остаточной дисперсии:
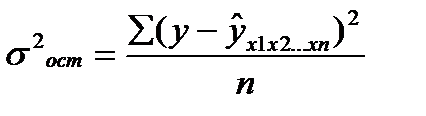 (27.3)
(27.3)
Возможна и такая интерпретация формулы индекса множественной корреляции
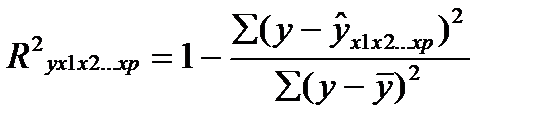 (27.4)
(27.4)
26. Коэффициент множественной детерминации
Коэффициент детерминации –это квадрат показателем множественной корреляции.
Множественный коэффициент детерминации можно рассматривать как меру качества уравнения регрессии, характеристику прогностической силы анализируемой регрессионной модели: чем ближе R 2 к единице, тем лучше регрессия описывает зависимость между объясняющими и зависимой переменными. Недостаток R 2 состоит в том, что его значение не убывает с ростом числа объясняющих переменных. В эконометрическом анализе чаще применяют скорректированный коэффициент детерминации R^ 2 определяемый по формуле
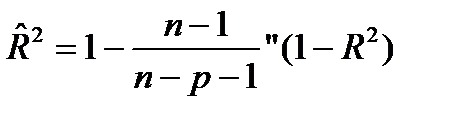 (28.1)
(28.1)
который может уменьшаться при введении в регрессионную модель переменных, не оказывающих существенного влияния на зависимую переменную.
Если известен коэффициент детерминации R 2 то критерий значимости уравнения регрессии может быть записан в виде:
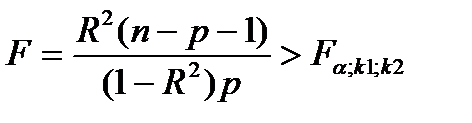 (28.2)
(28.2)
где ‚ к1= р, к2 = n — р — 1, ибо в уравнении множественной регрессии вместе со свободным членом оценивается m = р + 1 параметров.
27. Проверка гипотезы о значимости частного и множественного коэффициентов корреляции
Проверка гипотез используется, когда необходим обоснованный вывод о значимости частного и множественного коэффициентов корреляции. При этом гипотезой называется любое предположение о виде или параметрах неизвестного закона распределения.
Множественный коэффициент корреляции заключен в пре делах 0 до1. Он не меньше, чем абсолютная величина любого парного или частного коэффициента корреляции с таким же первичным индексом.
С помощью множественного коэффициента корреляции (по мере приближения к 1 делается вывод о тесноте взаимосвязи, но не о ее направлении.
Частный коэффициент корреляции. Если переменные коррелируют друг с другом, то на величине парного коэффициента корреляции частично сказывается влияние других переменных. В связи с этим часто возникает необходимость исследовать частную корреляцию между переменными при устранении влияния одной/нескольких переменных
28. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
Основной предпосылкой регрессионного анализа является то, что только результативный признак (У) подчиняется нормальному закону распределения, а факторные признаки х 1 . Х 2 . х n могут иметь произвольный закон распределения. В анализе динамических рядов в качестве факторного признака выступает время t При этом в регрессионном анализе заранее подразумевается наличие причинно-следственных связей между результативным (У) и факторными х 1 . Х 2 . х n признаками. В тех случаях, когда из природы процессов в модели или из данных наблюдений над ней следует вывод о нормальном законе распределения двух СВ — Y и X , из которых одна является независимой, т. е. Y является функцией X , то возникает соблазн определить такую зависимость “формульно”, аналитически.Уравнение регрессии, или статистическая модель связи социально-экономических явлений, выражаемая функцией Y=f( х 1 . Х 2 . х n ) является достаточно адекватным реальному моделируемому явлению или процессу в случае соблюдения следующих требований их построения. 1) Совокупность исследуемых исходных данных должна быть однородной и математически описываться непрерывными функциями. 2) Возможность описания моделируемого явления одним или несколькими уравнениями причинно-следственных связей. 3) Все факторные признаки должны иметь количественное (цифровое) выражение. 4) Наличие достаточно большого объема исследуемой выборочной совокупности. 5) Причинно-следственные связи между явлениями и процессами следует описывать линейной или приводимой к линейной формой зависимости. 6) Отсутствие количественных ограничений на параметры модели связи. 7) Постоянство территориальной и временной структуры изучаемойсовокупности. Соблюдение данных требований позволяет исследователю построить статистическую модель связи, наилучшим образом аппроксимирующую моделируемые социально-экономические явления и процессы. В случае успеха нам будет намного проще вести моделирование. Конечно, наиболее заманчивой является перспектива линейной зависимости типа Y = a + b · X . Подобная задача носит название задачи регрессионного анализа и предполагает следующий способ решения. Выдвигается следующая гипотеза H 0 : случайная величина Y при фиксированном значении величины X распределена нормально с математическим ожиданием М y = a + b · X и дисперсией D y , не зависящей от X . При наличии результатов наблюдений над парами X i и Y i предварительно вычисляются средние значения M y и M x , а затем производится оценка коэффициента b в виде b = = R xy что следует из определениякоэффициента корреляции. После этого вычисляется оценка для a в виде <2 - 16>и производится проверка значимости полученных результатов. Таким образом, регрессионный анализ является мощным, хотя и далеко не всегда допустимым расширением корреляционного анализа, решая всё ту же задачу оценки связей в сложной системе.
29. Определение мультиколлинеарности. Последствия мулыиколлицеарности. Методы обнаружения мультиколлинеарности
Мультиколлинеарность -это процесс, при котором между факторами происходит совокупное воздействие друг на друга
Наличие мультиколлинеарности факторов может означать, что некоторые факторы действуют синхронно. В итоге вариация в исходных данных зависима и невозможно оценить воздействие каждого фактора в отдельности. Чем сильнее мультиколлинеарность факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью метода наименьших квадратов.
Если рассматривается регрессия у = а + b * х + с * z + d * v + ε то для расчета параметров с применением МНК предполагается равенство:
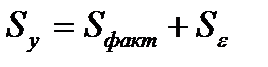 (31.1)
(31.1)
где 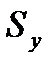 — общая сумма квадратов отклонений Σ(уi-у¯) 2
— общая сумма квадратов отклонений Σ(уi-у¯) 2
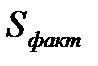 — факторная сумма квадратов отклонений: Σ(у^i-у¯) 2
— факторная сумма квадратов отклонений: Σ(у^i-у¯) 2
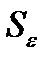 — остаточная сумма квадратов отклонений Σ(у^i-у) 2
— остаточная сумма квадратов отклонений Σ(у^i-у) 2
Если же факторы интеркоррелированы, то данное равенство нарушается.
Включение в модель мультиколлинеарных факторов нежелательно по причинам:
• затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в чистом виде, т.к. факторы коррелированны. При этом параметры линейной регрессии утрачивают экономический смысл;
• оценки параметров ненадежны, появляются стандартные ошибки, которые меняются с изменением объема наблюдений (по величине и знаку), Модель нельзя анализировать и строить на ее основе прогнозы.
Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных Коэффициентов корреляции между факторами.
Если бы факторы не коррелировали между собой, то матрица парных коэффициентов корреляции между ними была бы единичной, т.к. все элементы не находящиеся на диагоналях равны 0. Для уравнения включающее три объясняющих переменных,
у = а + b1 * х1 + b2 * х2 + b3 * х3 +ε, при этом матрица коэффициентов корреляции между факторами имела определитель равный единице.
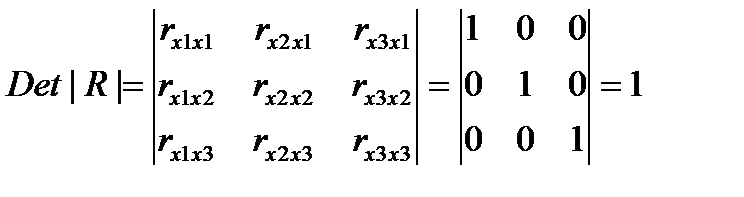 (31.2)
(31.2)
Если же между факторами существует полная линейная зависимость и все Коэффициенты корреляции равны единице, то определитель такой матрицы равен нулю.
 (31.3)
(31.3)
Чем ближе к — нулю определитель матрицы межфакторной корреляции тем сильнее мультиколлинеарность факторов и ненадежнее результаты множествснной регрессии. Наоборот чем ближе к единице определитель матрицы межфакторной корреляции тем меньше мультиколлинеарность факторов.
30. Методы устранения мультиколлинеарности
Устраняя мультиколлинеарность факторов чаще всего используют приведенную форму. Для этого в уравнение регрессии подставляют рассматриваемый фактор, выраженный из другого уравнения.
В двухфакторной регрессии вида
 (32.1)
(32.1)
сделав предобразования получим:
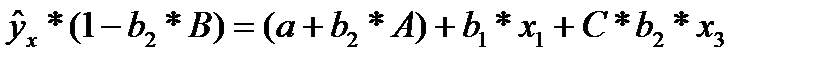 (32.2)
(32.2)
Если исключить один из факторов, то мы придем к уравнению парной регрессии. Вместе с тем, можно оставить факторы в модели, но исследовать данное двух факторное уравнение регрессии совместно с другим уравнением, в котором фактор рассматривается как зависимая переменная. При (1-b2*В) ≠ 0, делим первую и вторую части уравнения на (1-b2*В), получаем:
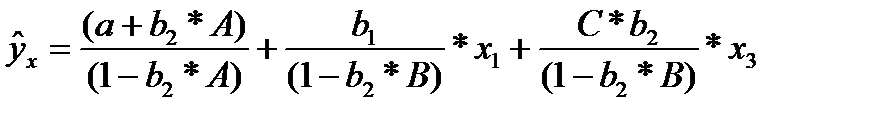 (32.3)
(32.3)
Получили приведенную форму уравнения для определения результативного признака у. Это уравнение может быть представлено в виде (32.4)
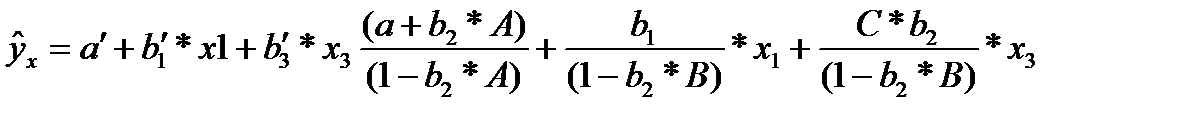
К нему для оценки параметров может быть применен метод наименьших квадратов.
Отбор факторов, включаемых в регрессию -основной этап практического использования методов регрессии. Подходы к отбору факторов на основе показателей корреляции могут различны. Они приводят построение уравнение множественной регрессии соответственно к разным методикам.
Наиболее распространены методы построения уравнения множественной регрессии:
• шаговый регрессионный анализ.
Каждый метод помогает устранить мультиколлинеарность позволяя производить отсев факторов из полного его набора (метод исключения), дополнительное введение фактора (метод включения), исключение ранее введенного фактора (шаговый регрессионный анализ).
На первый Взгляд может показаться, что матрица парных коэффициентов корреляции играет главную роль в отборе факторов. Вместе с тем вследствие взаимодействия факторов парные коэффициенты корреляции не могут полностью решать вопрос целесообразности включения в модель того определенного фактора. Эту роль выполняют показатели частной корреляции, оценивающие в чистом виде тесноту связи фактора с результатом. Матрица частных коэффициентов корреляции наиболее широко используется в процедуре отсева факторов. Отсев факторов можно проводить и по t-критерию Стьюдента для коэффициентов регрессии: из уравнения исключаются факторы с величиной t-критерия меньше табличного.
В заключении следует уточнить: число включаемых факторов обычно в 6—7 раз меньше объема совокупности, по которой строится регрессия. Если это соотношение нарушено, то число степеней свободы остаточной вариации очень мало. Это приводит к тому, что пара метры уравнения регрессии оказываются статистически незначимыми, а Р-критерий меньше табличного значения.
31. Модели регрессии, нелинейные по факторным переменным
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций: например, равносторонней гиперболы 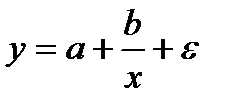 , параболы второй степени
, параболы второй степени 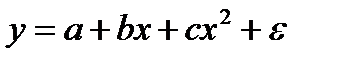 и д.р.
и д.р.
Различают два класса нелинейных регрессий:
• регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам;
• регрессии, нелинейные по оцениваемым параметрам.
Примером нелинейной регрессии по включаемым в нее объясняющим переменным могут служить следующие функции:
• полиномы разных степеней
К нелинейным регрессиям по оцениваемым параметрам относятся функции:
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Между
 и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
 данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.- Остатки нормально распределены с нулевым средним значением;
- Остатки имеют одну и ту же вариабельность (постоянную дисперсию) для всех предсказанных величин Если нанести остатки против предсказанных величин от мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением то это допущение не выполняется;
 Если нанести остатки против предсказанных величин
Если нанести остатки против предсказанных величин  от
от  мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением
мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением  то это допущение не выполняется;
то это допущение не выполняется;Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
Частные уравнения регрессии что это такое
Наряду со средними показателями эластичности в целом по совокупности регионов на основе частных уравнений регрессии могут быть определены частные коэффициенты эластичности для каждого региона. Частные уравнения регрессии в нашем случае составят [c.111]
Частные уравнения регрессии по отдельным видам вспашки составили [c.146]
Частные уравнения регрессии для отдельных типов домов, свидетельствуя о наиболее высоких ценах квартир в панельных домах, будут иметь следующий вид [c.147]
Число степеней свободы 49 Частные уравнения регрессии 109 [c.340]
Частные уравнения регрессии и частные коэффициенты эластичности. [c.15]
Частным уравнением регрессии модели y=a0+ai Xi +а2 х2 +. +ат хт + Е [c.16]
На основе линейного уравнения множественной регрессии постройте частные уравнения регрессии, рассчитайте частные коэффициенты эластичности и охарактеризуйте изолированное влияние каждого из факторов на результирующую переменную (в случае, когда другие факторы закреплены на среднем уровне). [c.11]
Частный коэффициент эластичности показывает, на сколько процентов в среднем изменяется производительность труда при изменении данного фактора на 1%. Для полученного уравнения регрессии коэффициенты эластичности соответственно равны Э2=+4,25 Э3=+0,38 34 = —5,69 Э5=+0,43. [c.201]
Оценка полученного уравнения регрессии по известным критериям показала, что данная модель удовлетворяет условиям адекватности (R — 0,95, t = 62,2, 6 = 8,8%). Частные коэффициенты эластичности и 3-коэффициенты, представленные в табл. 14, показывают, что наибольшее влияние на уровень затрат этой подсистемы оказывает коэффициент падения добычи нефти. Однако значение этого фактора в основном обусловлено природно-геологическими условиями разработки нефтяных месторождений, поэтому возможность его регулирования посредством воздействия извне ограниченна. [c.37]
Прогнозы по регрессионным моделям более надежны, поскольку они позволяют проводить эксперименты на моделях, в которых учитывается большее число факторов, влияющих на развитие процесса. Кроме того, полученные результаты всегда легко объяснить и обосновать. В силу этих причин прогнозы по уравнениям регрессии (иначе их называют производственными функциями) используются практически при экономическом прогнозировании всех видов макро- и микро-, краткосрочном и долгосрочном, частном и общем и т.д. [c.225]
Силу связи между вариациями себестоимости добычи нефти и газа п факторов определяют чистые (частные) коэффициенты корреляции. Они более соответствуют данной цели, чем парные коэффициенты корреляции, которые не свободны от корреляции с зависимой переменной прочих факторов, содержащихся в уравнении регрессии. Ввиду этого целесообразно остановиться на чистых коэффициентах корреляции. Наиболее сильно коррелируют с себестоимостью добычи нефти и газа (пятая строка, табл. 27) фондоемкость ( — 0,55), средний дебит ( — 0,49), время ( — 0,65), а наиболее слабо — удельная численность промышленно-производственного персонала (0,1). [c.92]
Следует усвоить, что коэффициенты частной детерминации — это доли от разных величин, поэтому они несравнимы по этим долям нельзя судить о роли факторов. Их главное практическое значение -определить, имеет ли смысл добавить в уравнение регрессии новый фактор или нет. Если при его включении ранее необъясненная вариация уменьшится на три четверти, как в примере при введении фактора х3, его включение оправдано если же коэффициент частной детерминации мал, то дополнительный фактор включать не следует. Сумма частных коэффициентов детерминации смысла не имеет и растет с ростом числа факторов и ростом R2 без ограничения. [c.282]
Для увязки этих частных индексов следует ввести корректирующий индекс, отражающий изменение свободного члена уравнения регрессии v по М [c.419]
Частный коэффициент детерминации показывает, на сколько процентов вариация результативного признака объясняется вариацией первого признака, входящего в множественное уравнение регрессии. [c.122]
Мера статистической значимости независимой переменной b уравнения регрессии Y = а + Ьх по влиянию на зависимую переменную Y. Рассчитывается как частное оценка коэффициента регрессии/стандартное отклонение. [c.471]
На первый взгляд может показаться, что матрица парных коэффициентов корреляции играет главную роль в отборе факторов. Вместе с тем вследствие взаимодействия факторов парные коэффициенты корреляции не могут в полной мере решать вопрос о целесообразности включения в модель того или иного фактора. Эту роль выполняют показатели частной корреляции, оценивающие в чистом виде тесноту связи фактора с результатом. Матрица частных коэффициентов корреляции наиболее широко используется в процедуре отсева факторов. При отборе факторов рекомендуется пользоваться следующим правилом число включаемых факторов обычно в 6—7 раз меньше объема совокупности, по которой строится регрессия. Если это соотношение нарушено, то число степеней свободы остаточной вариации очень мало. Это приводит к тому, что параметры уравнения регрессии оказываются статистически незначимыми, a F- критерий меньше табличного значения. [c.100]
Частные коэффициенты (или индексы) корреляции характеризуют тесноту связи между результатом и соответствующим фактором при устранении влияния других факторов, включенных в уравнение регрессии. [c.121]
Данный коэффициент частной корреляции позволяет измерить тесноту связи между у и хг при неизменном уровне всех других факторов, включенных в уравнение регрессии. [c.124]
Для уравнения регрессии с тремя факторами частные коэффициенты корреляции второго порядка определяются на основе частных коэффициентов корреляции первого порядка. Так, по уравнению [c.125]
Рассчитанные по рекуррентной формуле частные коэффициенты корреляции изменяются в пределах от —1 до +1, а по формулам через множественные коэффициенты детерминации — от 0 до 1. Сравнение их друг с другом позволяет ранжировать факторы по тесноте их связи с результатом. Частные коэффициенты корреляции, подтверждая ранжировку факторов по их воздействию на результат, на основе стандартизованных коэффициентов регрессии /3-коэффициентов) в отличие от последних дают конкретную меру тесноты связи каждого фактора с результатом в чистом виде. Если из стандартизованного уравнения регрессии Л = Дч q + V 2 + з г з следует, что , > 2 > /3XJ, т. е. по силе влияния на результат порядок факторов таков Х , х2, х3, то этот же порядок факторов определяется и по соотношению частных коэффициентов корреляции, ГуХ] хт > г 2, Х ХЗ > г хт. [c.127]
В табл. 3.2 приведены три значения / -критерия. В первой строке показан общий / -критерий. Он составил 19,3 и характеризует значимость двухфакторного уравнения регрессии в целом. Вторая величина F— 22,0 характеризует значимость парной регрессии у = а + Ь Х при условии, что остаточная дисперсия совпадает с величиной остаточной дисперсии для множественной регрессии. Влияние фактора х, статистически значимо, так как F = 22,0 больше табличного значения /табл = 4,21. Третье значение F = 16,5 — это частный /»-критерий, оценивающий значимость дополнительного включения в модель фактора х2 после введения в нее фактора х,. Его величина совпадает с ранее рассчитанной по формуле частного /»-критерия Fxr [c.134]
Если А является наивысшим порядком расчета частных коэффициентов корреляции для уравнения регрессии, то практически величина к совпадает с числом степеней свободы для остаточной вариации с п — т — 1. Так, в уравнении = а + Ьх х + b2 х2 + Ьъ х х д 3 + е, рассчитанном при п = 30, я — т — 1 = 26. Если же уравнение рефессии дополняется расчетом частных коэффициентов корреляции разных порядков (второго, третьего и т. п.), то [c.140]
Взаимосвязь показателей частного коэффициента корреляции, частного /»-критерия и 7-критерия Стьюдента для коэффициентов чистой регрессии может использоваться в процедуре отбора факторов. Отсев факторов при построении уравнения регрессии методом исключения практически можно осуществлять не только по частным коэффициентам корреляции, исключая на каждом шаге фактор с наименьшим незначимым значением частного коэффициента корреляции, но и по величинам tb. и Fx.. Частный /»-критерий широко используется и при построении модели методом включения переменных и шаговым регрессионным методом. [c.141]
Применение зяблевой вспышки способствует росту урожайности в среднем на 2,9 ц с 1 га при одном и том же количестве внесенного удобрения на 1 га, что в целом соответствует и различию средней урожайности по видам вспашки (15,3 ц с 1 га для зяблевой вспашки и 12,5 ц с 1 га для весенней вспашки). Частный /»-критерий для фактора z составил 16,58, что выше табличного значения при числе степеней свободы 1 и 22 (4,30 при а = 0,05 и 7,94 при а = 0,01). Это подтверждает целесообразность включения фиктивной переменной в уравнение регрессии. [c.145]
Поэтому вполне реально предположить единую меру влияния данного фактора независимо от вида вспашки, что и имеет место в уравнении регрессии с фиктивной переменной. Включив фиктивную переменную, удалось измерить ее влияние на изменение урожайности частный коэффициент корреляции ryz. х, оценивающий в чистом виде влияние данного фактора, составил 0,6555, что несколько выше, чем аналогичный показатель для фактора х, т.е. г = 0,6385. [c.146]
Результаты свидетельствуют о целесообразности построения модели по отдельным частным совокупностям. Ввиду разной зависимости уровня квалификации рабочих от уровня занятости ручным трудом по заводам с традиционной и прогрессивной технологиями производства уравнение регрессии по совокупности в целом не позволило выявить наличие связи. Не улучшился результат модели и с введением фиктивной переменной, ибо этот метод предполагает равенство коэффициентов регрессии при х по частным совокупностям и возможность их замены общим коэффициентом регрессии Ь. [c.149]
Управляемый фактор 371 Управляющая информация 413 Управляющая система 371 Управляющее воздействие 371 Управляющие параметры 258, 371 Уравнение обмена 372 Уравнение отклика 251 Уравнение регрессии 305 Уравнения бюджета потребителей 152 Уравнения в частных производных [c.493]
В частном случае единственного результирующего признака у и F — класса линейных функций получаем линейное уравнение регрессии [c.285]
Для выявления резервов снижения себестоимости более применимы уравнения регрессии, определяющие частные зависимости х от какого-либо фактора [c.227]
Если поверхность отклика локально может быть описана линейным уравнением, то частные производные, очевидно, будут равны коэффициентам уравнения регрессии [c.271]
Имеется три явления А, В и С, связанные между собой необходимо рассчитать силу связи между А и В при условии исключения воздействия явления С (как посредника между А и В). Для этого, зная уравнения регрессии между А и С и между В и С , рассчитываются для каждой пары А и В те их значения (наиболее вероятные), к-рые они принимали бы, если бы значения С оставались постоянными (напр., равными средней величине). Тогда, вычисляя К. к. между преобразованными переменными Ас и Вс, можно уловить ту частную связь между А и В [c.275]
Частный Значимость частного коэффициента регрессии переменной/можно проверить, используя приростную Она основана на приращении в объясняемой сумме квадратов, полученном добавлением независимой переменной в уравнение регрессии после исключения всех других независимых переменных. [c.660]
Логически, зависимость между коэффициентом парной регрессии и частным коэффициентом регрессии можно проиллюстрировать образом. Предположим, что мы исключили эффект от влияния Это можно сделать, установив регрессию по Иначе говоря, можно воспользоваться уравнением а + и вычислить остаточный член = (X, — Тогда частный коэффициент регрессии. станет равным коэффициенту парной регрессии полученному из уравнения 7 =а Таким образом, частный коэффициент регрессии равен/1, коэффициенту парной регрессии между переменной Уи остаточным значением переменной [c.661]
В отличие от парной регрессии частные уравнения регрессии характеризуют изолированное влияние фактора на результат, ибо другие факторы закреплены на неизменном уровне. Эффекты влияния других факторов присоединены в них к свободному члену уравнения множественной регрессии. Это позволяет на основе частных уравнений регрессии определять частные коэффициенты эластичности1 [c.110]
При Т — 1, Тп — 2 при помощи прямого обучения по алгоритму МГУА находится уравнение регрессии для ошибки, например Дх0 — f(Ax l,Ax 2,x l,x 2). Затем строится кривая Ax(t) для каждого частного уравнения регрессии. [c.60]
В эконометрике частные коэффициенты корреляции обычно не имеют самостоятельного значения. В основном их используют на стадии формирования модели, в частности в процедуре отсева факторов. Так, строя многофакторную модель, например, методом исключения переменных, на первом шаге определяется уравнение рефессии с полным набором факторов и рассчитывается матрица частных коэффициентов корреляции. На втором шаге отбирается фактор с наименьшей и несущественной по f-критерию Стьюдента величиной показателя частной корреляции. Исключив его из модели, строится новое уравнение регрессии. Процедура продолжается до тех пор, пока не окажется, что все частные коэффициенты корреляции существенно отличаются от нуля. Если исключен несущественный фактор, то множественные коэффициенты детерминации на двух смежных шагах построения рефессионной модели почти не отличаются друг от друга, т. е. R2p + j R2p где р — число факторов. [c.128]
Оцените статистическую значимость уравнений регрессии и их параметров при помощи F-критерия Фишера-Снедекора, частных F-критериев и t-критерия Стьюдента. [c.10]
Для анализа взаимосвязи или связи экономических показателей приходится обращаться к совокупности статистических параметров средних величин, средних квадрати-ческих отклонений, параметров распределения, парных и частных коэффициентов корреляции, коэффициентов влияния, корреляционных отношений, параметров уравнений регрессии, остаточных дисперсий, множественных коэффициентов корреляции и множественных корреляционных отношений. Для краткости совокупность статистических параметров, описывающих множество экономических показателей и взаимосвязь между ними, мы называем экономико-статистической моделью. [c.12]
http://statistica.ru/theory/osnovy-lineynoy-regressii/
http://economy-ru.info/info/15319/