Частные коэффициенты эластичности
Пример . 1. Оценка уравнения регрессии. Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор получается из выражения:
s = (X T X) -1 X T Y
Матрица X
Можно также посмотреть, как было найдено решение аналогичного примера.
Видеоинструкция
Матрица Y
Матрица X T
Умножаем матрицы, (X T X)
| 24 | 4459.4 | 1907.7 | 214.2 | 417.47 |
| 4459.4 | 907391.96 | 353017.36 | 40134.04 | 87383.93 |
| 1907.7 | 353017.36 | 152366.77 | 17041.58 | 33412.82 |
| 214.2 | 40134.04 | 17041.58 | 1921.32 | 3807 |
| 417.47 | 87383.93 | 33412.82 | 3807 | 8907.78 |
В матрице, (X T X) число 24, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
Умножаем матрицы, (X T Y)
| 2743.3 |
| 557558.59 |
| 218286.47 |
| 24740.08 |
| 54488.32 |
Находим обратную матрицу (X T X) -1
| 67.5762 | -0.0883 | -0.4341 | -3.3069 | 0.7404 |
| -0.0883 | 0.0002 | 0.0006 | 0.0037 | -0.0012 |
| -0.4341 | 0.0006 | 0.0036 | 0.0134 | -0.0047 |
| -3.3069 | 0.0037 | 0.0134 | 0.2444 | -0.0358 |
| 0.7404 | -0.0012 | -0.0047 | -0.0358 | 0.01 |
Вектор оценок коэффициентов регрессии равен
s = (X T X) -1 X T Y =
| -55.01 |
| 0.43 |
| 0.86 |
| -1.14 |
| 0.95 |
Уравнение регрессии (оценка уравнения регрессии)
Y = -55.0117 + 0.4315X 1 + 0.8571X 2 -1.1392X 3 + 0.9481X 4
2. Матрица парных коэффициентов корреляции.
Число наблюдений n = 24. Число независимых переменных в модели ровно 4, а число регрессоров с учетом единичного вектора равно числу неизвестных коэффициентов. С учетом признака Y, размерность матрицы становится равным 6. Матрица, независимых переменных Х имеет размерность (24 х 6). Матрица Х T Х определяется непосредственным умножением или по следующим предварительно вычисленным суммам.
Матрица составленная из Y и X
Транспонированная матрица.
Матрица A T A.
| 24 | 2743.3 | 4459.4 | 1907.7 | 214.2 | 417.47 |
| 2743.3 | 344649.05 | 557558.59 | 218286.47 | 24740.08 | 54488.32 |
| 4459.4 | 557558.59 | 907391.96 | 353017.36 | 40134.04 | 87383.93 |
| 1907.7 | 218286.47 | 353017.36 | 152366.77 | 17041.58 | 33412.82 |
| 214.2 | 24740.08 | 40134.04 | 17041.58 | 1921.32 | 3807 |
| 417.47 | 54488.32 | 87383.93 | 33412.82 | 3807 | 8907.78 |
Полученная матрица имеет следующее соответствие:
| ∑n | ∑y | ∑x1 | ∑x2 | ∑x3 | ∑x4 |
| ∑y | ∑y 2 | ∑x1·y | ∑x2·y | ∑x3·y | ∑x4·y |
| ∑x1 | ∑x1·y | ∑x1 2 | ∑x2·x1 | ∑x3·x1 | ∑x4·x1 |
| ∑x2 | ∑x2·y | ∑x2·x1 | ∑x2 2 | ∑x3·x2 | ∑x4·x2 |
| ∑x3 | ∑x3·y | ∑x3·x1 | ∑x3·x2 | ∑x3 2 | ∑x3·x4 |
| ∑x4 | ∑x4·y | ∑x4·x1 | ∑x4·x2 | ∑x4·x3 | ∑x4 2 |
Найдем парные коэффициенты корреляции.
Для y и x 1
Уравнение имеет вид y = ax + b
Средние значения
Для y и x 2
Уравнение имеет вид y = ax + b
Средние значения
Для y и x 3
Уравнение имеет вид y = ax + b
Средние значения
Для y и x 4
Уравнение имеет вид y = ax + b
Средние значения
Для x 1 и x 2
Уравнение имеет вид y = ax + b
Средние значения
Для x 1 и x 3
Уравнение имеет вид y = ax + b
Средние значения
Для x 1 и x 4
Уравнение имеет вид y = ax + b
Средние значения
Для x 2 и x 3
Уравнение имеет вид y = ax + b
Средние значения
Для x 2 и x 4
Уравнение имеет вид y = ax + b
Средние значения
Для x 3 и x 4
Уравнение имеет вид y = ax + b
Средние значения
Матрица парных коэффициентов корреляции.
| — | y | x 1 | x 2 | x 3 | x 4 |
| y | 1 | 0.97 | 0.05 | 0.47 | 0.95 |
| x 1 | 0.97 | 1 | -0.19 | 0.38 | 0.86 |
| x 2 | 0.05 | -0.19 | 1 | 0.18 | 0.21 |
| x 3 | 0.47 | 0.38 | 0.18 | 1 | 0.65 |
| x 4 | 0.95 | 0.86 | 0.21 | 0.65 | 1 |
Анализ первой строки этой матрицы позволяет произвести отбор факторных признаков, которые могут быть включены в модель множественной корреляционной зависимости. Факторные признаки, у которых r yxi j y) > r(x k x j ) ; r(x k y) > r(x k x j ).
Если одно из неравенств не соблюдается, то исключается тот параметр x k или x j , связь которого с результативным показателем Y оказывается наименее тесной.
3. Анализ параметров уравнения регрессии.
Перейдем к статистическому анализу полученного уравнения регрессии: проверке значимости уравнения и его коэффициентов, исследованию абсолютных и относительных ошибок аппроксимации
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка e = Y — X*s (абсолютная ошибка аппроксимации)
| 10.93 |
| 9.67 |
| 9.31 |
| 9.91 |
| 9.05 |
| 7.65 |
| 7.11 |
| 8.68 |
| 12.84 |
| 12.97 |
| 15.56 |
| 22.48 |
| 13.97 |
| 14.04 |
| 15.95 |
| 12.88 |
| 15.87 |
| 15.08 |
| 16.81 |
| 19.89 |
| 22.34 |
| 24.13 |
| 24.08 |
| 21.31 |
s e 2 = (Y — X*s) T (Y — X*s)
Несмещенная оценка дисперсии равна
Оценка среднеквадратичного отклонения равна
Найдем оценку ковариационной матрицы вектора k = σ*(X T X) -1
| 1183.8 | -1.55 | -7.6 | -57.93 | 12.97 |
| -1.55 | 0 | 0.01 | 0.06 | -0.02 |
| -7.6 | 0.01 | 0.06 | 0.23 | -0.08 |
| -57.93 | 0.06 | 0.23 | 4.28 | -0.63 |
| 12.97 | -0.02 | -0.08 | -0.63 | 0.17 |
Дисперсии параметров модели определяются соотношением S 2 i = K ii , т.е. это элементы, лежащие на главной диагонали
С целью расширения возможностей содержательного анализа модели регрессии используются частные коэффициенты эластичности, которые определяются по формуле
Частные коэффициент эластичности E 1 2 3 4 2 = 0.9 2 = 0.81
т.е. в 81.2384 % случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — высокая
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
T табл (n-m-1;a) = (19;0.05) = 1.729
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
4. Оценка значения результативного признака при заданных значениях факторов.
Y(0.0,0.0,0.0,0.0,) = -55.01 + 0.4315 * 0.0 + 0.8571 * 0.0-1.1392 * 0.0 + 0.9481 * 0.0 = -55.01
Доверительные интервалы с вероятностью 0.95 для индивидуального значения результативного признака.
S 2 = X 0 T (X T X) -1 X 0
где
X 0 T = [ 1 0.0 0.0 0.0 0.0]
(X T X) -1
| 67.5762 | -0.0883 | -0.4341 | -3.3069 | 0.7404 |
| -0.0883 | 0.0002 | 0.0006 | 0.0037 | -0.0012 |
| -0.4341 | 0.0006 | 0.0036 | 0.0134 | -0.0047 |
| -3.3069 | 0.0037 | 0.0134 | 0.2444 | -0.0358 |
| 0.7404 | -0.0012 | -0.0047 | -0.0358 | 0.01 |
X 0
| 1 |
| 0 |
| 0 |
| 0 |
| 0 |
S 2 = 67.58
(Y — t*S Y ; Y + t*S Y )
(-55.01 — 1.729*144.01 ; -55.01 + 1.729*144.01)
(-304;193.98)
Доверительные интервалы с вероятностью 0.95 для среднего значения результативного признака.
(-55.01 — 1.729*145.07 ; -55.01 + 1.729*145.07)
(-305.84;195.82)
5. Проверка гипотез относительно коэффициентов уравнения регрессии (проверка значимости параметров множественного уравнения регрессии).
1) t-статистика
Статистическая значимость коэффициента регрессии b 0 не подтверждается
Статистическая значимость коэффициента регрессии b 1 подтверждается
Статистическая значимость коэффициента регрессии b 2 подтверждается
Статистическая значимость коэффициента регрессии b 3 не подтверждается
Статистическая значимость коэффициента регрессии b 4 подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b i — t i S i ; b i + t i S i )
b 0 : (-114.5003;4.477)
b 1 : (0.3419;0.521)
b 2 : (0.4234;1.2908)
b 3 : (-4.7171;2.4386)
b 4 : (0.2255;1.6707)
2) F-статистика. Критерий Фишера
Fkp = 2.74
Поскольку F > Fkp, то коэффициент детерминации статистически значим и уравнение регрессии статистически надежно
6. Проверка на наличие гетероскедастичности методом графического анализа остатков.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X i , а по оси ординат квадраты отклонения e i 2 .
Соизмеримые показатели тесноты связи
К соизмеримым показателям тесноты связи относятся:
- коэффициенты частной эластичности;
- стандартизированные частные коэффициенты регрессии;
- частный коэффициент детерминации.
Если факторные переменные имеют несопоставимые единицы измерения, то связь между ними измеряется с помощью соизмеримых показателей тесноты связи. С помощью соизмеримых показателей тесноты связи характеризуется степень зависимости между факторной и результативной переменными в модели множественной регрессии.
Коэффициент частной эластичности рассчитывается по формуле:
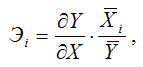
где X i – среднее значение факторной переменной xi по выборочной совокупности, i= 1,n ;
Y – среднее значение результативной переменной у по выборочной совокупности;
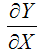 – первая производная результативной переменной у по факторной переменной х.
– первая производная результативной переменной у по факторной переменной х.
Частный коэффициент эластичности измеряется в процентах и характеризует объём изменения результативной переменной у при изменении на 1 % от среднего уровня факторной переменной xi при условии постоянства всех остальных факторных переменных, включённых в модель регрессии.
Для линейной модели регрессии частный коэффициент эластичности рассчитывается по формуле:
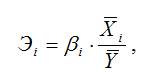
где βi– коэффициент модели множественной регрессии.
Для того чтобы рассчитать стандартизированные частные коэффициенты регрессии, необходимо построить модель множественной регрессии в стандартном (нормированном) масштабе. Это означает, что все переменные, включённые в модель регрессии, стандартизируются с помощью специальных формул. Посредством процесса стандартизации точкой отсчёта для каждой нормированной переменной устанавливается её среднее значение по выборочной совокупности. При этом в качестве единицы измерения стандартизированной переменной принимается её среднеквадратическое отклонение β.
Факторная переменная х переводится в стандартизированный масштаб по формуле:
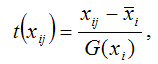
где xij – значение переменной xj в i-том наблюдении;
G(xj) – среднеквадратическое отклонение факторной переменной xi;
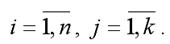
Результативная переменная у переводится в стандартизированный масштаб по формуле:
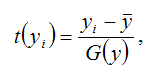
где G(y) – среднеквадратическое отклонение результативной переменной у.
Стандартизированные частные коэффициенты регрессии характеризуют, на какую долю своего среднеквадратического отклонения G(y) изменится результативная переменная у при изменении факторной переменной х на величину своего среднеквадратического отклонения G(x), при условии постоянства всех остальных факторных переменных, включённых в модель регрессии.
Стандартизированный частный коэффициент регрессии характеризует степень непосредственной или прямой зависимости между результативной и факторной переменными. Но в связи с тем, что между факторными переменными, включёнными в модель множественной регрессии, существует зависимость, факторная переменная оказывает не только прямое, но и косвенное влияние на результативную переменную.
Частный коэффициент детерминации используется для характеристики степени косвенного влияния факторной переменной х на результативную переменную у:
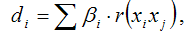
где βi – стандартизированный частный коэффициент регрессии;
r(xixj) – коэффициент частной корреляции между факторными переменными xi и xj.
Частный коэффициент детерминации характеризует, на сколько процентов вариация результативной переменной вызвана вариацией i-ой факторной переменной, включённой в модель множественной регрессии, при условии постоянства всех остальных факторных переменных, включённых в модель регрессии.
Стандартизированные частные коэффициенты регрессии и частные коэффициенты эластичности могут давать различные результаты. Это несовпадение может быть объяснено, например, слишком большой величиной среднеквадратического отклонения одной из факторных переменных или эффектом неоднозначного воздействия одной из факторных переменных на результативную переменную.
Частные уравнения множественной регрессии. Индексы множественной и частной корреляции и их расчет
На основе линейного уравнения множественной регрессии 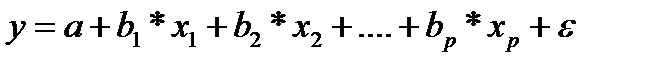
могут быть найдены частные уравнения регрессии:
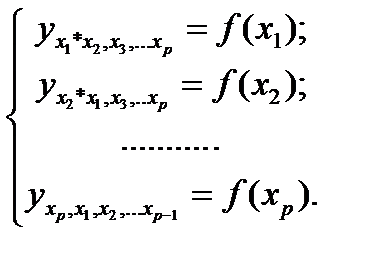 (25.1)
(25.1)
т.е. уравнения регрессии, которые связывают результативный признак с соответствующими факторами хi при закреплении других учитываемых во множественной регрессии факторов на среднем уровне. В случае линейной регрессии частные уравнения имеют следующий вид:
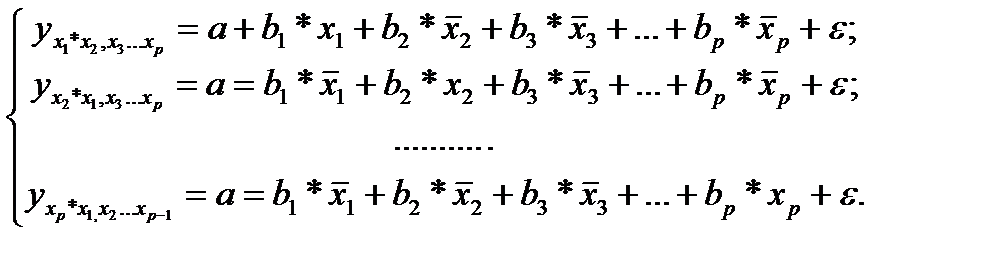 (25.2)
(25.2)
Подставляя в эти уравнения средние значения соответствующих факторов получаем систему уравнений линейной регрессии, т.е. имеем:
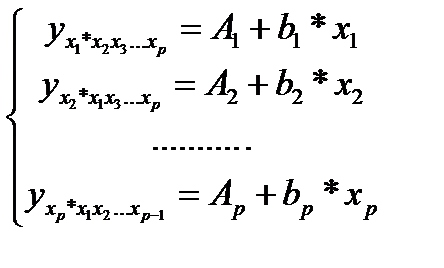 (25.3)
(25.3)
где 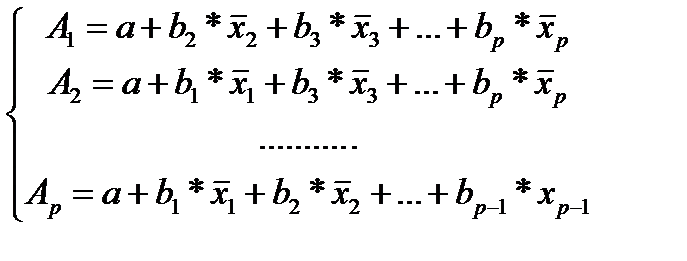 (25.4)
(25.4)
Частные уравнения регрессии характеризуют изолированное влияние фактора на результат, ибо другие факторы закреплены на низменном уровне. Эффекты влияния других факторов присоединены в них к свободному члену уравнения множественной регрессии (Аi).Это позволяет на основе частных уравнений регрессии определять частные коэффициенты эластичности
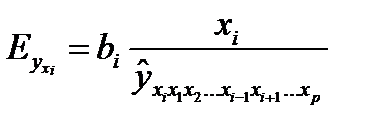 (25.5)
(25.5)
На основании данной информации могут быть найдены средние по совокупности показатели эластичности: 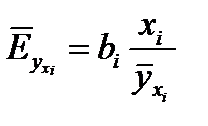 .
.
Практическая значимость уравнения множественной регрессии оценивается с помощью показателя множественной корреляции и его квадрата – коэффициента детерминации. Показатель множественной корреляции характеризует тесноту совместного влияния факторов на результат.
Независимо от вида уравнения индекс множественной корреляции рассчитывается по формуле:
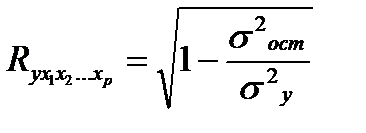 , (25.6)
, (25.6)
где σ 2 y — общая дисперсия результативного признака,
σ 2 ост — остаточная дисперсия .
Чем ближе его значение к 1, тем теснее связь результативного признака со всем набором исследуемых факторов.
Сравнивая индексы множественной регрессии и парной корреляции, можно сделать вывод о целесообразности включения в уравнение регрессии того или иного фактора. В частности, если дополнительно включенные в уравнение множественной регрессии факторы третьестепенны, то индекс множественной корреляции практически совпадает с индексом парной корреляции.
Если оценивается значимость влияния фактора хi в уравнении регрессии, то определяется частный F- критерий:
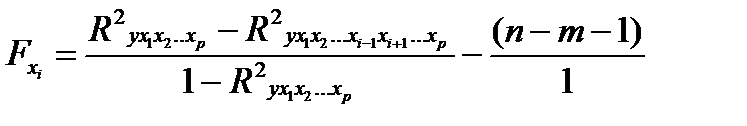 (25.7)
(25.7)
Значимость коэффициентов чистой регрессии производится по t — критерию Стьюдента.
24. Построение частных коэффициентов корреляции для модели множественной регрессии через показатель остаточной дисперсии
Частные коэффициенты (или индексы) корреляции характеризуют тесноту связи между результатом и соответствующим фактором при устранении влияния других факторов, включенных в уравнение регрессии.
Чем больше доля полученной разности в остаточной вариации, тем теснее связь между у и x2 , при неизменности действия фактора x1
Величина, рассчитываемая формулой:
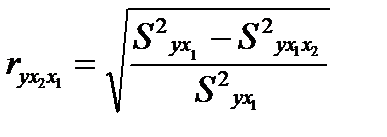 (26.1)
(26.1)
называется индексом частной корреляции для фактора х2:
Аналогично определяется индекс частной корреляции для фактора x1.
Выражая остаточную дисперсию через показатель детерминации
S 2 ост = σ 2 у (1-r 2 ), имеем формулу частной корреляции:
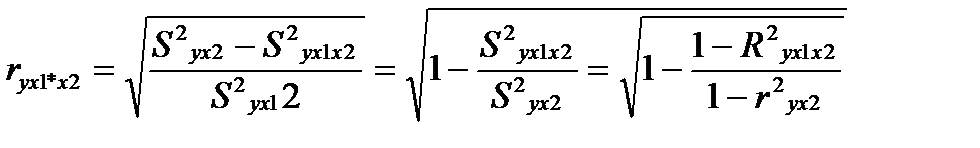 (26.2)
(26.2)
25. Коэффициент множественной корреляции
Практическая значимость уравнения множественной регрессии оценивается показателем множественной корреляции
Показатель множественной корреляции характеризует тесноту связи рассматриваемого набора факторов с исследуемым при знаком, или оценивает тесноту совместного влияния факторов на результат.
Независимо от формы связи показатель множественной корреляции можёт быть найден как индекс множественной корреляции:
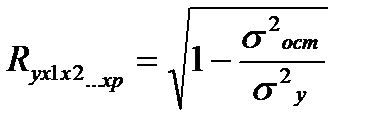 (27.1)
(27.1)
σ 2 ост – остаточная дисперсия для уравнения у=f(x1,x2,… xр)
σ 2 у – общая дисперсия результативного признака
Методика построения индекса множественной корреляции аналогична построению индекса корреляции для парной зависимости. Его пределы от 0 до 1. Чем ближе его значение к 1, тем теснее связь результативного признака со всем I бором исследуемых факторов. Величина индекса множественно корреляции должна быть больше или равна максимальному парному индексу корреляции: —
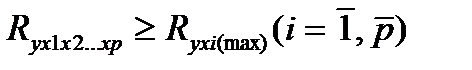 (27.2)
(27.2)
Обоснованность включения факторов в регрессионный анализ приведет к существенному отличию показателя от индекса корреляции парной зависимости. При включении модель маловажных факторов происходит уравнение индекса множественной корреляции с индексом парной корреляции. Сравнивая индексы множественной и парной корреляции делают заключение о возможности включения в уравнение регрессии того или иного фактора.
Расчет индекса множественной Корреляции предполагает определение уравнения множественной регрессии и на его основе остаточной дисперсии:
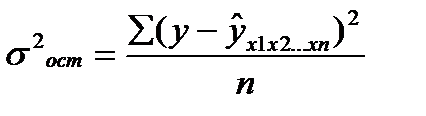 (27.3)
(27.3)
Возможна и такая интерпретация формулы индекса множественной корреляции
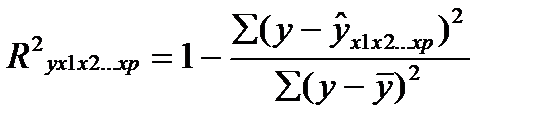 (27.4)
(27.4)
26. Коэффициент множественной детерминации
Коэффициент детерминации –это квадрат показателем множественной корреляции.
Множественный коэффициент детерминации можно рассматривать как меру качества уравнения регрессии, характеристику прогностической силы анализируемой регрессионной модели: чем ближе R 2 к единице, тем лучше регрессия описывает зависимость между объясняющими и зависимой переменными. Недостаток R 2 состоит в том, что его значение не убывает с ростом числа объясняющих переменных. В эконометрическом анализе чаще применяют скорректированный коэффициент детерминации R^ 2 определяемый по формуле
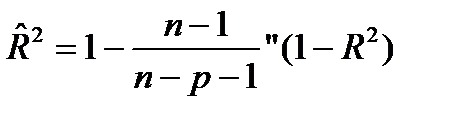 (28.1)
(28.1)
который может уменьшаться при введении в регрессионную модель переменных, не оказывающих существенного влияния на зависимую переменную.
Если известен коэффициент детерминации R 2 то критерий значимости уравнения регрессии может быть записан в виде:
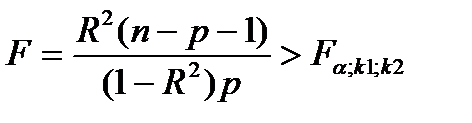 (28.2)
(28.2)
где ‚ к1= р, к2 = n — р — 1, ибо в уравнении множественной регрессии вместе со свободным членом оценивается m = р + 1 параметров.
27. Проверка гипотезы о значимости частного и множественного коэффициентов корреляции
Проверка гипотез используется, когда необходим обоснованный вывод о значимости частного и множественного коэффициентов корреляции. При этом гипотезой называется любое предположение о виде или параметрах неизвестного закона распределения.
Множественный коэффициент корреляции заключен в пре делах 0 до1. Он не меньше, чем абсолютная величина любого парного или частного коэффициента корреляции с таким же первичным индексом.
С помощью множественного коэффициента корреляции (по мере приближения к 1 делается вывод о тесноте взаимосвязи, но не о ее направлении.
Частный коэффициент корреляции. Если переменные коррелируют друг с другом, то на величине парного коэффициента корреляции частично сказывается влияние других переменных. В связи с этим часто возникает необходимость исследовать частную корреляцию между переменными при устранении влияния одной/нескольких переменных
28. Проверка гипотезы о значимости коэффициентов регрессии и модели множественной регрессии в целом
Основной предпосылкой регрессионного анализа является то, что только результативный признак (У) подчиняется нормальному закону распределения, а факторные признаки х 1 . Х 2 . х n могут иметь произвольный закон распределения. В анализе динамических рядов в качестве факторного признака выступает время t При этом в регрессионном анализе заранее подразумевается наличие причинно-следственных связей между результативным (У) и факторными х 1 . Х 2 . х n признаками. В тех случаях, когда из природы процессов в модели или из данных наблюдений над ней следует вывод о нормальном законе распределения двух СВ — Y и X , из которых одна является независимой, т. е. Y является функцией X , то возникает соблазн определить такую зависимость “формульно”, аналитически.Уравнение регрессии, или статистическая модель связи социально-экономических явлений, выражаемая функцией Y=f( х 1 . Х 2 . х n ) является достаточно адекватным реальному моделируемому явлению или процессу в случае соблюдения следующих требований их построения. 1) Совокупность исследуемых исходных данных должна быть однородной и математически описываться непрерывными функциями. 2) Возможность описания моделируемого явления одним или несколькими уравнениями причинно-следственных связей. 3) Все факторные признаки должны иметь количественное (цифровое) выражение. 4) Наличие достаточно большого объема исследуемой выборочной совокупности. 5) Причинно-следственные связи между явлениями и процессами следует описывать линейной или приводимой к линейной формой зависимости. 6) Отсутствие количественных ограничений на параметры модели связи. 7) Постоянство территориальной и временной структуры изучаемойсовокупности. Соблюдение данных требований позволяет исследователю построить статистическую модель связи, наилучшим образом аппроксимирующую моделируемые социально-экономические явления и процессы. В случае успеха нам будет намного проще вести моделирование. Конечно, наиболее заманчивой является перспектива линейной зависимости типа Y = a + b · X . Подобная задача носит название задачи регрессионного анализа и предполагает следующий способ решения. Выдвигается следующая гипотеза H 0 : случайная величина Y при фиксированном значении величины X распределена нормально с математическим ожиданием М y = a + b · X и дисперсией D y , не зависящей от X . При наличии результатов наблюдений над парами X i и Y i предварительно вычисляются средние значения M y и M x , а затем производится оценка коэффициента b в виде b = = R xy что следует из определениякоэффициента корреляции. После этого вычисляется оценка для a в виде <2 - 16>и производится проверка значимости полученных результатов. Таким образом, регрессионный анализ является мощным, хотя и далеко не всегда допустимым расширением корреляционного анализа, решая всё ту же задачу оценки связей в сложной системе.
29. Определение мультиколлинеарности. Последствия мулыиколлицеарности. Методы обнаружения мультиколлинеарности
Мультиколлинеарность -это процесс, при котором между факторами происходит совокупное воздействие друг на друга
Наличие мультиколлинеарности факторов может означать, что некоторые факторы действуют синхронно. В итоге вариация в исходных данных зависима и невозможно оценить воздействие каждого фактора в отдельности. Чем сильнее мультиколлинеарность факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью метода наименьших квадратов.
Если рассматривается регрессия у = а + b * х + с * z + d * v + ε то для расчета параметров с применением МНК предполагается равенство:
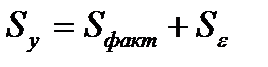 (31.1)
(31.1)
где 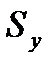 — общая сумма квадратов отклонений Σ(уi-у¯) 2
— общая сумма квадратов отклонений Σ(уi-у¯) 2
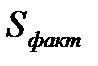 — факторная сумма квадратов отклонений: Σ(у^i-у¯) 2
— факторная сумма квадратов отклонений: Σ(у^i-у¯) 2
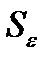 — остаточная сумма квадратов отклонений Σ(у^i-у) 2
— остаточная сумма квадратов отклонений Σ(у^i-у) 2
Если же факторы интеркоррелированы, то данное равенство нарушается.
Включение в модель мультиколлинеарных факторов нежелательно по причинам:
• затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в чистом виде, т.к. факторы коррелированны. При этом параметры линейной регрессии утрачивают экономический смысл;
• оценки параметров ненадежны, появляются стандартные ошибки, которые меняются с изменением объема наблюдений (по величине и знаку), Модель нельзя анализировать и строить на ее основе прогнозы.
Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных Коэффициентов корреляции между факторами.
Если бы факторы не коррелировали между собой, то матрица парных коэффициентов корреляции между ними была бы единичной, т.к. все элементы не находящиеся на диагоналях равны 0. Для уравнения включающее три объясняющих переменных,
у = а + b1 * х1 + b2 * х2 + b3 * х3 +ε, при этом матрица коэффициентов корреляции между факторами имела определитель равный единице.
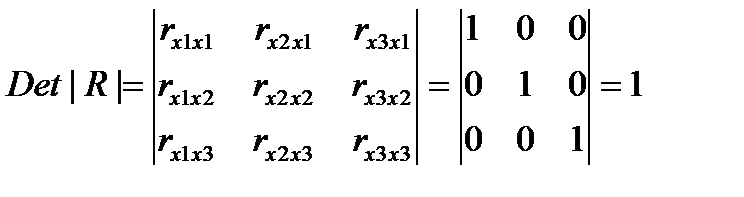 (31.2)
(31.2)
Если же между факторами существует полная линейная зависимость и все Коэффициенты корреляции равны единице, то определитель такой матрицы равен нулю.
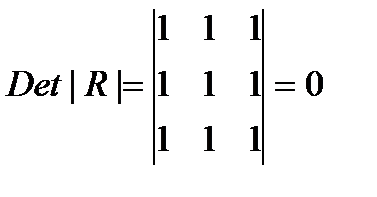 (31.3)
(31.3)
Чем ближе к — нулю определитель матрицы межфакторной корреляции тем сильнее мультиколлинеарность факторов и ненадежнее результаты множествснной регрессии. Наоборот чем ближе к единице определитель матрицы межфакторной корреляции тем меньше мультиколлинеарность факторов.
30. Методы устранения мультиколлинеарности
Устраняя мультиколлинеарность факторов чаще всего используют приведенную форму. Для этого в уравнение регрессии подставляют рассматриваемый фактор, выраженный из другого уравнения.
В двухфакторной регрессии вида
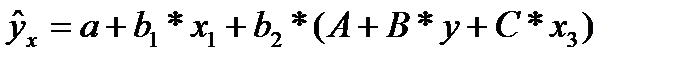 (32.1)
(32.1)
сделав предобразования получим:
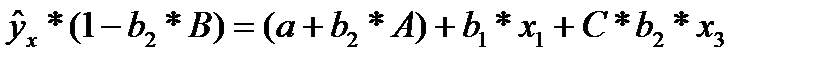 (32.2)
(32.2)
Если исключить один из факторов, то мы придем к уравнению парной регрессии. Вместе с тем, можно оставить факторы в модели, но исследовать данное двух факторное уравнение регрессии совместно с другим уравнением, в котором фактор рассматривается как зависимая переменная. При (1-b2*В) ≠ 0, делим первую и вторую части уравнения на (1-b2*В), получаем:
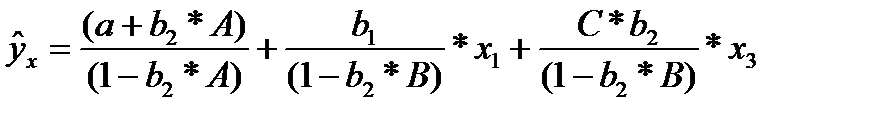 (32.3)
(32.3)
Получили приведенную форму уравнения для определения результативного признака у. Это уравнение может быть представлено в виде (32.4)
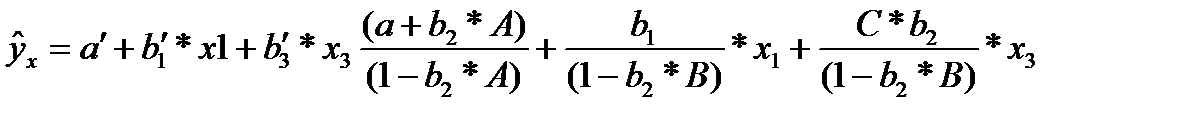
К нему для оценки параметров может быть применен метод наименьших квадратов.
Отбор факторов, включаемых в регрессию -основной этап практического использования методов регрессии. Подходы к отбору факторов на основе показателей корреляции могут различны. Они приводят построение уравнение множественной регрессии соответственно к разным методикам.
Наиболее распространены методы построения уравнения множественной регрессии:
• шаговый регрессионный анализ.
Каждый метод помогает устранить мультиколлинеарность позволяя производить отсев факторов из полного его набора (метод исключения), дополнительное введение фактора (метод включения), исключение ранее введенного фактора (шаговый регрессионный анализ).
На первый Взгляд может показаться, что матрица парных коэффициентов корреляции играет главную роль в отборе факторов. Вместе с тем вследствие взаимодействия факторов парные коэффициенты корреляции не могут полностью решать вопрос целесообразности включения в модель того определенного фактора. Эту роль выполняют показатели частной корреляции, оценивающие в чистом виде тесноту связи фактора с результатом. Матрица частных коэффициентов корреляции наиболее широко используется в процедуре отсева факторов. Отсев факторов можно проводить и по t-критерию Стьюдента для коэффициентов регрессии: из уравнения исключаются факторы с величиной t-критерия меньше табличного.
В заключении следует уточнить: число включаемых факторов обычно в 6—7 раз меньше объема совокупности, по которой строится регрессия. Если это соотношение нарушено, то число степеней свободы остаточной вариации очень мало. Это приводит к тому, что пара метры уравнения регрессии оказываются статистически незначимыми, а Р-критерий меньше табличного значения.
31. Модели регрессии, нелинейные по факторным переменным
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций: например, равносторонней гиперболы 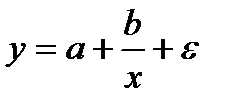 , параболы второй степени
, параболы второй степени 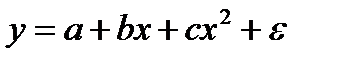 и д.р.
и д.р.
Различают два класса нелинейных регрессий:
• регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам;
• регрессии, нелинейные по оцениваемым параметрам.
Примером нелинейной регрессии по включаемым в нее объясняющим переменным могут служить следующие функции:
• полиномы разных степеней
К нелинейным регрессиям по оцениваемым параметрам относятся функции:
http://be5.biz/ekonomika/e008/29.html
http://helpiks.org/3-55675.html