Степени свободы (Degrees of Freedom)

Степени свободы (Df, C) – это количество параметров (точек контроля) Модели (Model). Они указывают количество независимых значений, которые могут изменяться в ходе анализа без нарушения каких-либо ограничений.
- Рассмотрим Выборку (Sample) данных, состоящую для простоты из пяти положительных целых чисел. Значения могут быть любыми числами без известной связи между ними. Эта выборка данных теоретически должна иметь пять степеней свободы.
- Четыре числа в выборке — это <3, 8, 5 и 4>, а среднее значение всей выборки данных равно 6.
- Это должно означать, что пятое число равно 10. Иначе быть не может. У пятого значения нет свободы варьироваться.
- Таким образом, степень свободы для этой выборки данных равна 4.
Формула степени свободы выглядит следующим образом:
D_f – степень свободы
N – количество значений
Математически степени свободы часто представляют, используя греческую букву «ню», которая выглядит так: ν. Вы наверняка встретите и такие сокращения: ‘d.o.f.’, ‘dof’, ‘d.f.’ или просто ‘df’.
Степени свободы в статистике
Степени свободы в статистике – это количество значений, используемых при вычислении переменной.
Степени свободы = Количество независимых значений — Количество статистик
Пример. У нас есть 50 независимых значений, и мы хотим вычислить одну-единственную статистику «среднее». Согласно формуле, степеней свободы будет 50 — 1 = 49.
Степени свободы в Машинном обучении
В прогностическом моделировании, степени свободы часто относятся к количеству параметров, включая данные, используемые при вычислении ошибки модели. Наилучший способ понять это – рассмотреть модель линейной регрессии.
Рассмотрим модель линейной регрессии для Датасета (Dataset) с двумя входными переменными. Нам потребуется один коэффициент в модели для каждой входной переменной, то есть модель будет иметь еще и два параметра.
$$\hat
y – целевая переменная
x_1, x_2 – входные переменные
β_1, β_2 – параметры модели
Эта модель линейной регрессии имеет две степени свободы, потому что есть два параметра модели, которые должны быть оценены на основе обучающего датасета. Добавление еще одного столбца к данным (еще одной входной переменной) добавит модели еще одну степень свободы. Сложность обучения модели линейной регрессии описывается степенью свободы, например, «модель четвертой степени сложности» означает наличие четырех входных переменных, а также степень свободы, равную четырем.
Степени свободы для ошибки линейной регрессии
Количество обучающих примеров имеет значение и влияет на количество степеней свободы регрессионной модели. Представьте, что мы создаем модель линейной регрессии на базе датасета, состоящего из ста строк.
Сравнивая предсказания модели с реальными выходными значениями, мы минимизируем ошибку. Итоговая ошибка модели имеет одну степень свободы для каждого ряда за вычетом количества параметров. В нашем случае ошибка модели 98 степеней свободы (100 рядов — 2 параметра).
Итоговые степени свободы для линейной регрессии
Конечные степени свободы для модели линейной регрессии рассчитываются как сумма степеней свободы модели плюс степени свободы ошибки модели. В нашем примере это 100 (2 степени свободы модели + 98 степеней свободы ошибки). Как вы уже заметили, степеней свободы столько, сколько рядов в датасете.
Теперь рассмотрим набор данных из 100 строк, но теперь у нас есть 70 входных переменных. Это означает, что модель имеет еще и 70 коэффициентов, что дает нам d.o.f. ошибки, равной 30 (100 строк — 70 коэффициентов). d.o.f. самой модели по-прежнему равен ста.
Отрицательные степени свободы
Что происходит, когда у нас больше столбцов, чем строк данных? Отрицательные значения вполне допустимы здесь. Например, у нас может быть 100 строк данных и 10 000 переменных, к примеру, маркеры генов для 100 пациентов. Следовательно, модель линейной регрессии будет иметь 10 000 параметров, то есть модель будет иметь 10 000 степеней свободы.
Тогда степени свободы рассчитываются следующим образом:
Степень свободы модели = Количество независимых значение — Количество параметров = 100 — 10 000 = -9 900
В свою очередь, степени свободы модели линейной регрессии будут следующими:
Степени свободы модели линейной регрессии = Степени свободы модели — Степени свободы ошибки модели = 10 000 — 9 900 = 100
Степени свободы (физика)
- Сте́пени свобо́ды — характеристики движения механической системы. Число степеней свободы определяет минимальное количество независимых переменных (обобщённых координат), необходимых для полного описания состояния механической системы. Строгое теоретико-механическое определение: число степеней свободы механической системы есть размерность пространства её состояний с учётом наложенных связей.
Также число степеней свободы равно полному числу независимых уравнений второго порядка (таких, как уравнения Лагранжа) или половине числа уравнений первого порядка (таких, как канонические уравнения Гамильтона), полностью описывающих динамику системы.
Связанные понятия
Упоминания в литературе
Связанные понятия (продолжение)
В квантовой механике импульс, как и все другие наблюдаемые физические величины, определяется как оператор, который действует на волновую функцию.
Эта статья о физическом понятии. О более общем значении термина, см. статью СкалярСкалярная величина (от лат. scalaris — ступенчатый) в физике — величина, каждое значение которой может быть выражено одним действительным числом. То есть скалярная величина определяется только значением, в отличие от вектора, который кроме значения имеет направление. К скалярным величинам относятся длина, площадь, время, температура и т. д.Скалярная величина, или скаляр согласно математическому энциклопедическому словарю.
Статистическим ансамблем физической системы называется набор всевозможных состояний данной системы, отвечающих определённым критериям. Примерами статистического ансамбля являются.
Ниже приведены примеры уравнений непрерывности, которые выражают одинаковую идею непрерывного изменения некоторой величины. Уравнения непрерывности — (сильная) локальная форма законов сохранения.
ХИ2ОБР (вероятность; число степеней свободы)
Федеральное агентство по образованию
Государственное образовательное учреждение высшего профессионального образования
Санкт-Петербургский государственный горный институт им Г.В. Плеханова
(технический университет)
Кафедра информатики и компьютерных технологий
Эконометрика
ЭЛЕМЕНТЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ И МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
Часть 2
Методические указания для выполнения лабораторных работ
для студентов специальности 080109
«Бухгалтерский учет, анализ и аудит»
САНКТ-ПЕТЕРБУРГ
УДК 519.86:622.3.012 (075.83)
ЭКОНОМЕТРИКА. Ч2. Элементы теории вероятностей и математической статистики:Методические указания для выполнения лабораторных работ / СПГГИ(ТУ). Сост.: В.В. Беляев, Т.А. Виноградова, Т.Р. Косовцева. СПб, 2008. 64 с.
Методические указания содержат теоретические сведения по выполнению лабораторных работ по эконометрике. Приведены необходимые теоретические сведения и примеры выполнения заданий по некоторым разделам теории вероятностей и математической статистики, которые являются теоретической основой применения эконометрических методов. Все решения выполнены с использованием электронных таблиц MS Excel, в том числе с применением надстройки «Пакет анализа».
Методические указания предназначены для студентов специальности «Бухгалтерский учет, анализ и аудит» дневной формы обучения.
Табл.5. Рис.37. Библиогр.: 3 назв.
Научный редактор: доц. Н.Я. Головенчиц.
© Санкт-Петербургский государственный горный институт им. Г.В.Плеханова, 2008 г.
Эконометрика – наука о применении статистических методов в экономическом анализе для проверки правильности экономических теоретических моделей и способов решения экономических проблем.
Основной целью эконометрики является модельное описание конкретных количественных взаимосвязей, обусловленных общими качественными закономерностями, изученными в экономической теории.
Области применения эконометрических моделей напрямую связаны с целями эконометрического моделирования, основными из которых являются:
1) анализ экономических и социально-экономических показателей, характеризующих состояние и развитие анализируемой системы;
2) прогноз различных возможных сценариев социально-экономического развития анализируемой системы.
В качестве анализируемой экономической системы могут выступать страна в целом, регионы, отрасли и корпорации, а также предприятия, фирмы и домохозяйства.
Основными типами экономических моделей являются регрессионные модели с одним уравнением, модели временных рядов и системы одновременных уравнений.
Для изучения эконометрики необходимы базовые знания по теории вероятностей, математической статистике и экономической теории.
Вторая часть настоящих методических указаний посвящена методам анализа и проверки статистических гипотез. Методы эти имеют огромное прикладное значение.
Лабораторная работа 3:
ИЗУЧЕНИЕ БАЗОВЫХ ПОНЯТИЙ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
Цель: Освоить на практике с помощью MS Excel построение вариационного и интервального рядов, вычисление выборочных характеристик (описательных статистик), получение статистических оценок и определение их свойств.
3.1. Базовые понятия
При исследовании реальных экономических процессов приходится обрабатывать большие объёмы статистических данных, которые по своей сути являются случайными величинами (СВ). На практике количество реализаций СВ ограничено, что не позволяет применять напрямую теоретические методы анализа. Поэтому при обработке данных в первую очередь используют методы и модели математической статистики, позволяющие получить необходимые знания об исследуемом объекте.
3.1.1. Генеральная совокупность и выборка
Статистической совокупностью называется множество предметов или явлений, объединённых в нечто целое и однородное по некоторым определенным признакам. Отдельные элементы, входящие в совокупность, называются членами статистической совокупности, а общее число членов совокупности – её объёмом.
Изменение признака при переходе от одного члена совокупности к другому называют его вариацией, а значение признака у отдельного члена статистической совокупности – его вариантой.
Выборочной совокупностью (или выборкой) называется совокупность случайно отобранных однородных элементов. Генеральной совокупностью называется совокупность всех однородных элементов, из которых произведена выборка.
Выборочная и генеральная совокупности, как правило, различаются объемами. Выборка называется репрезентативной, если она достаточно хорошо представляет исследуемый признак генеральной совокупности. Для обеспечения репрезентативности выборки применяют следующие способы отбора: простой отбор (последовательно отбираются последовательно случайно попавшиеся объекты), типический отбор (объекты отбираются пропорционально представительству различных типов объектов в генеральной совокупности), случайный отбор, например, с помощью таблицы случайных чисел, и т.д.
Одной из основных задач статистического анализа является получение по полученной выборке достоверных сведений об интересующих исследователя свойствах и параметрах генеральной совокупности.
Основным типом значений переменных в математической статистике являются количественные переменные.
3.1.2. Вычисление выборочных характеристик
Значения количественных переменных являются числовыми, могут быть упорядочены и для них имеют смысл различные вычисления (например, вычисление среднего значения). На обработку количественных переменных ориентировано подавляющее большинство статистических методов.
Первый раздел математической статистики – описательная статистика – предназначен для представления исследуемых данных в удобном виде и для получения информации о них в терминах математической статистики и теории вероятностей. Для этого используются описательные или дескриптивные характеристики: минимум, максимум, размах, среднее, дисперсия, стандартное отклонение, медиана, квартили, мода.
При анализе конкретного показателя Х все элементы выборки  объемом n обычно упорядочивают по неубыванию:
объемом n обычно упорядочивают по неубыванию:  . Выборка, упорядоченная по возрастанию наблюдаемых значений, называется вариационным рядом. Разность между максимальным и минимальным значениями ряда Х называется размахом выборки.
. Выборка, упорядоченная по возрастанию наблюдаемых значений, называется вариационным рядом. Разность между максимальным и минимальным значениями ряда Х называется размахом выборки.
Если значение xi встречается в выборке ni раз, то число ni называется частотой (частостью) значения xi, а величина  — относительной частотой значения xi.
— относительной частотой значения xi.
Пусть объем генеральной совокупности равен N. Тогда величина 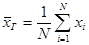 является генеральной средней. Генеральной дисперсией является величина
является генеральной средней. Генеральной дисперсией является величина  .
.
Генеральным средним квадратическим отклонением является величина  .
.
Так как реально чаще всего приходится работать с выборками из генеральной совокупности, то находят выборочные характеристики:
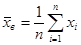 (3.1)
(3.1)
 (3.2)
(3.2)
— выборочное среднее квадратическое отклонение:
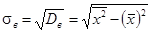 (3.3)
(3.3)
— выборочный коэффициент вариации Vв:
 . (3.4)
. (3.4)
Мода  – это наиболее часто встречающееся значение признака в данном ряду распределения. Для дискретных вариационных рядов мода определяется как значение признака с наибольшей частотой. В случае непрерывной вариации мода может быть определена как значение признака, которому отвечает наибольшая плотность распределения частости.
– это наиболее часто встречающееся значение признака в данном ряду распределения. Для дискретных вариационных рядов мода определяется как значение признака с наибольшей частотой. В случае непрерывной вариации мода может быть определена как значение признака, которому отвечает наибольшая плотность распределения частости.
Медианой называется такое значение варьирующего признака, которое делит ряд распределения на две равные части по объему частот. Медиана рассчитывается по-разному в дискретных и интервальных рядах.
Медианой МеХ называется значение признака, относительно которого статистическая совокупность делится на две равные по объему части, причем в одной из них содержатся члены, у которых значения признака не больше, а в другой – члены со значениями признака не меньше, чем МеХ. Другими словами, медианой называется число, разделяющее выборку пополам: 50% элементов меньше медианы, а 50% -больше медианы.
Если в дискретном ряду распределения нечетное число уровней, то медианой будет серединное значение упорядоченного ряда признака, т.е. это элемент с номером  вариационного ряда.
вариационного ряда.
Если ряд распределения дискретный и состоит из четного числа членов, то медиана определяется как средняя величина из двух серединных значений вариационного ряда.
Квартили – это показатели, которые чаще всего используются для оценки распределения данных при описании свойств больших числовых выборок. В то время, как медиана разделяет упорядоченный массив пополам, квартили разбивают упорядоченный массив данных на четыре части.
Первый квартиль Q1 – это число, разделяющее выборку на две части: 25% элементов меньше, а 75% — больше первого квартиля (3.5).
 (3.5)
(3.5)
Третий квартиль Q3 – это число, разделяющее выборку на две части: 75% элементов меньше, а 25% — больше третьего квартиля(3.6).
 (3.6)
(3.6)
Для вычисления квартилей применяются следующие правила.
1. Если индекс квартиля задается целым числом, значением квартиля считается элемент выборки с указанным индексом.
2. Если индекс квартиля задается величиной, представляющей собой среднее значение, вычисляемое по двум целым числам, квартиль равен среднему арифметическому, вычисленному по элементам, индексы которых равны эти двум числам.
3. Если индекс квартиля задается числом, которое не является целым и не кратно ½, он просто округляется до ближайшего целого. Квартилем является элемент выборки с указанным индексом.
Асимметрия – это свойство распределения выборки, которое характеризует несимметричность распределения СВ. На практике симметричные распределения встречаются редко, и чтобы выявить и оценить степень асимметрии, вводят следующую меру:
 . . | (3.7) |
Пределы значений  от
от  до
до  При
При  распределение симметрично:
распределение симметрично:  . При положительной асимметрии
. При положительной асимметрии  ; при отрицательной —
; при отрицательной —  .
.
Эксцесс – это мера крутости кривой распределения. Эксцесс вычисляется по формуле:
 . . | (3.8) |
Значения  лежат в открытом интервале
лежат в открытом интервале  . Если
. Если  , то кривая распределения имеет более острую вершину, чем нормальное распределение с параметрами
, то кривая распределения имеет более острую вершину, чем нормальное распределение с параметрами  и
и  , и распределение называется островершинным. Если
, и распределение называется островершинным. Если 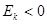 , то кривая распределения имеет более плоскую вершину, чем нормальное, и распределение называется плосковершинным.
, то кривая распределения имеет более плоскую вершину, чем нормальное, и распределение называется плосковершинным.
Для нормального распределения ,  .
.
3.1.3. Эмпирическая функция распределения
Эмпирической функцией распределения называется следующая функция:
 . (3.9)
. (3.9)
Эта формула справедлива, когда все xk различны.
3.1.4. Интервальный вариационный ряд
Чтобы получить первое впечатление о распределении генеральной совокупности, необходимо провести некоторую обработку выборочных данных. Простейшей операцией является построение интервального ряда.
Если произвести группировку вариант по интервалам изменения признака (интервальная группировка) и результат представить рядом интервалов вариант, расположенных в порядке их возрастания, и рядом соответствующих частот, то получим интервальный вариационный ряд.
Под частотой значения признака или интервала понимают число членов совокупности, варианты которых лежат в данном интервале. Отношение частоты к объему совокупности называется относительной частотой или частостью.
Число равных интервалов k, на которые следует разбить весь диапазон значений признака  , может быть найдено по формуле:
, может быть найдено по формуле:
 , , | (3.10) |
где n – объем статистической совокупности.
Число интервалов должно быть не меньше 8-10 и не больше 20-25.
Размах выборки определяется по формуле:
 , , | (3.11) |
а длина интервала — по формуле:
 . . | (3.12) |
Формулы 3.10 и 3.12 дают оценочное значение количества интервалов и их размеров. При практическом построении рекомендуется брать значения k и h, которые соответствуют здравому смыслу.
В дальнейшем будем использовать следующие обозначения: ai, bi — левая и правая границы i-гоинтервала соответственно; xi – середина этого интервала; mi – частота интервала.
3.1.5. Графическое представление интервальных вариационных рядов
Для наглядного представления статистического распределения пользуются графическим изображением интервальных вариационных рядов. К числу таких графических изображений относятся гистограмма, полигон, кумулята.
Построение гистограммы.
Для построения гистограммы нужно составить таблицу, в которой необходимо указать границы интервалов, найти их середины и частоту значений признака для каждого интервала.
Пример выполнения см. в файле Лаб_раб3.xls,(Лист Пример1)
Пусть объем выборки равен n=60; х1 =-2,18; х60 =12,04; h=2; k=9. В табл.3.1 представлен соответствующий интервальный вариационный ряд.
| № (разряд) | Границы интервала | Середина интервала x[i] | Частота mi |
| левая a[i] | правая b[i] | ||
| -4 | -2 | -3,00 | |
| -2 | -1,00 | ||
| 1,00 | |||
| 3,00 | |||
| 5,00 | |||
| 7,00 | |||
| 9,00 | |||
| 11,00 | |||
| 13,00 | |||
| sum |
По оси абсцисс откладывают интервалы значений признака, и на каждом из них, как на основании, строят прямоугольник с высотой, пропорциональной частоте интервала.
Гистограмма, построенная с помощью Мастера диаграмм программы MS Excel, приводится на рис. 3.1.

Рис.3.1 Гистограмма, построенная с помощью Мастера диаграмм Excel
Построение полигона
Для построения полигона на оси абсцисс откладывают интервалы значений признака, в серединах интервалов восстанавливают перпендикуляры, длины которых пропорциональны соответствующим частотам, затем концы соседних перпендикуляров соединяют отрезками прямых, а концы крайних перпендикуляров соединяют с серединами соседних интервалов, частоты которых равны нулю. В результате получим замкнутую фигуру в виде многоугольника.
Полигон для интервального ряда приведен на рис.3.2.

Рис.3.2. Полигон интервального ряда
Построение кумуляты
Накопленной частостью (частотой) в точке х называют суммарную частость (частоту) членов статистической совокупности со значениями признака меньшими, чем х.
Если в вариационном ряду вместо частот или частостей записать соответственно накопленные частоты или частости, то получится кумулятивный ряд. Для графического построения кумулятивных рядов пользуются кумулятами.
Кумулята строится следующим образом: на оси абсцисс отмечают точки, соответствующие границам интервалов или значениям признака. В каждой такой точке восстанавливают перпендикуляр, длина которого пропорциональна накопленной частоте. Концы соседних перпендикуляров соединяют отрезками. Полученная ломаная линия называется кумулятой.
Эмпирическая функция распределения отличается от кумуляты только масштабом.

Рис.3.3. Кумулята интервального ряда
Используя полученный интервальный ряд, можно вычислить все описательные характеристики, полагая, что все варианты выборки, лежащие внутри i-го интервала, принимают значения равные xi с частотой mi .Тогдавыборочное среднее  и выборочная дисперсия
и выборочная дисперсия  вычисляются по формулам:
вычисляются по формулам:
 , , | (3.13) |
 . . | (3.14) |
Если  — модальный интервал, т.е. интервал, которому соответствует наибольшая частота mj , а интервалы вариационного ряда имеют постоянную ширину h, то мода признака вычисляется по формуле
— модальный интервал, т.е. интервал, которому соответствует наибольшая частота mj , а интервалы вариационного ряда имеют постоянную ширину h, то мода признака вычисляется по формуле
 , , | (3.15) |
где mj-1, mj+1 – частоты интервалов, предшествующих модальному и следующего за модальным, соответственно.
Для интервального распределения сначала находят так называемый медианный интервал  , номер которого вычисляют из неравенств
, номер которого вычисляют из неравенств
 ; ;  ; ; | (3.16) |
где  — накопленная частота в точке х. В предположении, что в медианном интервале признак распределен равномерно, медиана признака Х определяется по формуле:
— накопленная частота в точке х. В предположении, что в медианном интервале признак распределен равномерно, медиана признака Х определяется по формуле:
 , , | (3.17) |
где h – ширина интервала с номером s; ms – частота этого интервала.
3.2. Диаграмма типа “ящик с усами”
3.2.1. Общие сведения
Диаграмма типа “ящик с усами” изображает важные характеристики описательной статистики на одном компактном рисунке. Она предложена Джоном Тьюки (John Tukey) в 1977 г. в основополагающей книге Exploratory Data Analysis. Диаграмма типа “ящик с усами” отображает следующие характеристики СВ:
1. Первый квартиль, медиана, третий квартиль и интерквантильный диапазон;
2. Минимальное и максимальное значения;
3. Умеренные и экстремальные выбросы.
Диаграмма типа “ящик с усами” дает хорошее визуальное представление изменчивости данных, а также асимметрии распределения. Типичный вид диаграммы типа “ящик с усами” приведен на рис.3.4.

Рис. 3.4. Диаграмма типа “ящик с усами”
Первый компонент диаграммы типа “ящик с усами” называется интерквартиль или интерквартильный диапазон (interquartile range — IQR), который простирается от первого до третьего квартиля.
Интерквартиль (IQR) — одна из мер разброса или рассеяния данных. Он равен разности между верхним и нижним (первым и третьим) квартилями. Другими словами IQR — это ширина интервала, содержащего средние 50% выборки. Таким образом, чем меньше IQR, тем меньше рассеяние. Положительной чертой этого показателя является его устойчивость (робастность), т.е. на него слабо влияют выбросы.
Пример.
Пусть дана выборка (уже в виде вариационного ряда):
2 3 4 5 6 6 6 7 7 8 9.
Ее верхний квартиль равен 7, ее нижний квартиль равен 4, следовательно, IQR равняется 7 — 4 = 3.
Для создания интерквартиля строят прямоугольник (“ящик”) от первого до третьего квартиля. Внутри ящика проводят горизонтальную линию на уровне медианы (второго квартиля) (рис. 3.5).
После построения интерквартильного диапазона можно приступать к вычислению внутреннего и внешнего ограждений. Внутренние ограждения (inner fences) располагаются в области, большей третьего квартиля + 1,5´ IQR или меньшей первого квартиля –1,5´ IQR. Внешние ограждения (outer fences) располагаются в области большей третьей квартили +3´ IQR или меньшей первой квартили – 3´ IQR (рис. 3.5).

Рис.3.5. Расположение ограждений при построении диаграммы «ящик с усами»
Замечание. Диаграммы на рис.3.5-3.8 нарисованы без точного соответствия масштабу.
Все значения выборки, которые лежат в промежутке между внутренним и внешним ограждениями, называются умеренными выбросами (moderate outlier) и обозначаются символами l. Все значения, которые лежат за пределами внешних ограждений, называются экстремальными выбросами (extreme outlier) и обозначаются символами ¡ (рис. 3.6).

Рис.3.6. Выбросы при построении диаграммы «ящик с усами»
Усы — вертикальные линии, проведенные от «ящика» до максимального и минимального значения СВ внутри внутреннего ограждения (рис. 3.7), такие значения не считаются выбросами.
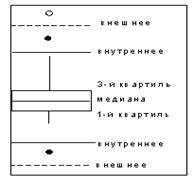
Рис.3.7. Расположение усов при построении диаграммы «ящик с усами»
3.2.5. Окончательный вид диаграммы
Обычно в окончательном виде статистической диаграммы типа “ящик с усами” внутреннее и внешнее ограждения не отображаются. Обычно эта диаграмма выглядит так, как показано на рис.3.8. Как видите, в этих данных имеются три выброса, причем один из них является экстремальным, а распределение в целом асимметрично.

Рис.3.8. Окончательный вид статистической диаграммы типа “ящик с усами”
3.2.6. “Ящики с усами” и распределения
“Ящик с усами” дает уникальное представление данных и широко используется в представлении экономической и технической информации. На рис.3.9 приведен пример использования диаграммы типа “ящик с усами” для иллюстрации изменения количества процессоров, используемых в течение ряда лет в одной из сетей суперкомпьютеров [2].
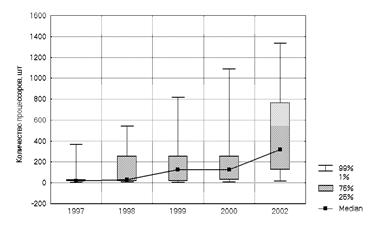
Рис.3.9. Диаграмма размаха значений количества процессоров суперкомпьютеров вычислительных центров коллективного пользования сети DREN по годам
3.3. Статистические выводы: оценки и проверка гипотез
Статистические выводы — это заключения о свойствах генеральной совокупности, полученные на основе исследования выборки, случайно отобранной из генеральной совокупности. Например, анализируется доход (  ) населения некоторого достаточно большого города. Этот анализ может быть осуществлен на основе выборки определенного объема (пусть n=1000).
) населения некоторого достаточно большого города. Этот анализ может быть осуществлен на основе выборки определенного объема (пусть n=1000).
Для выборочных данных определяем средний доход  и разброс данных
и разброс данных  . Далее возникает естественный вопрос: можно ли ожидать, что аналогичные значения будут такими же для всего города? И можно ли обобщить результаты, полученные по выборке, на генеральную совокупность? В этом назначение статистических выводов.
. Далее возникает естественный вопрос: можно ли ожидать, что аналогичные значения будут такими же для всего города? И можно ли обобщить результаты, полученные по выборке, на генеральную совокупность? В этом назначение статистических выводов.
На основе выборки можно получить лишь оценки параметров генеральной совокупности, так как эти оценки строятся на основе ограниченного набора данных; эти значения оценок могут изменяться от выборки к выборке. Процесс нахождения оценок параметров генеральной совокупности по определенному правилу называется оцениванием.
Выделяют два типа оценивания:
· оценивание вида распределения;
· оценивание параметров распределения.
В качестве оценки вида распределения можно взять выборочное распределение, а в качестве оценок параметров распределения генеральной совокупности используют выборочные оценки этих параметров.
Различают два вида оценок параметров – точечные и интервальные. После определения оценок обычно встает вопрос об их качестве и статистической значимости.
Пусть рассматривается генеральная совокупность наблюдаемой СВ . Для оценки её параметра Θ из генеральной совокупности извлекается выборка объема n: x1,x2,…,xn.
На основе этой выборки может быть найдена оценка Θ * параметра Θ.
Точечной оценкой Θ * параметра Θ называется числовое значение этого параметра, полученное по выборке объема n.
Например, для нормального распределения  параметрами являются математическое ожидание m и среднее квадратическое отклонение σ.
параметрами являются математическое ожидание m и среднее квадратическое отклонение σ.
Точечными оценками m и σ могут быть значения  и
и  , соответственно.
, соответственно.
Очевидно, что оценка Θ * является функцией от выборки, то есть Θ * =Θ * (х1,х2,…,хп). А так как выборка носит случайный характер, то оценка Θ * является случайной величиной, принимающей различные значения для различных выборок. Любую оценку Θ * =Θ * (х1,х2,…,хп) называют статистической оценкой параметра Θ.
Качество оценок характеризуется следующими основными свойствами: несмещенность, эффективность и состоятельность.
Оценка Θ * называется несмещенной оценкой параметра Θ, если ее математическое ожидание равно оцениваемому параметру:
| M(Θ * )=Θ. | (3.18) |
Оценка Θ * называется эффективной оценкой параметра Θ, если ее дисперсия D(Θ * ) меньше дисперсии любой другой оценки, полученной по выборке объемом n.
Оценка параметра Θ называется асимптотически эффективной, если с увеличением объема выборки ее дисперсия стремится к нулю, то есть
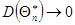 при при   | (3.19) |
Оценка Qn называется состоятельной оценкой параметра Θ, если Qn сходится по вероятности к Θ при n®¥, т.е. для любого e > 0 при n®¥
 | (3.20) |
Иными словами, если оценка состоятельна, то событие, состоящее в том, что разница между истинным значением параметра и его оценкой сколь угодно мала при достаточно большом объеме выборки, становится достоверным.
Некоторые свойства выборочных оценок
Доказано [1], что выборочное среднее является несмещенной и состоятельной оценкой математического ожидания 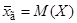 генеральной совокупности.
генеральной совокупности.
Выборочная дисперсия  является смещенной оценкой дисперсии генеральной совокупности
является смещенной оценкой дисперсии генеральной совокупности  и, как следствие, выборочная дисперсия оценивает генеральную дисперсию неточно.
и, как следствие, выборочная дисперсия оценивает генеральную дисперсию неточно.
Для таких случаев следует использовать исправленную дисперсию
 . . | (3.21) |
Исправленная дисперсия  является несмещенной и состоятельной оценкой дисперсии
является несмещенной и состоятельной оценкой дисперсии 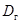 СВ X.
СВ X.
Необходимо отметить, что при n>30 различие между  и практически незначимо.
и практически незначимо.
Точечная оценка по данным выборки дает оценочное значение соответствующего параметра генеральной совокупности и выражается одним числом. Чтобы оценить точность и достоверность оценки находят интервальные оценки параметров. Интервальная оценка определяется двумя числами — концами интервала.Пусть для оценки параметра Θгенеральной совокупности используется выборка х1 , х2, …, хn., ΘL и ΘU—такие значения, что выполняется равенство
В этом случае для некоторого ε выполняется соотношение P(Θ * -e * +e)=  , следовательно доверительный интервал можно представить в виде ]Θ * -e, Θ * +e[, и для его построения необходимо определить ширину 2 ε или полуширину — величину ε. Вид выражения (формулы) для вычисления полуширины доверительного интервала ε для оценки параметра Θ зависит от того, какая предварительная информация о распределении СВ известна.
, следовательно доверительный интервал можно представить в виде ]Θ * -e, Θ * +e[, и для его построения необходимо определить ширину 2 ε или полуширину — величину ε. Вид выражения (формулы) для вычисления полуширины доверительного интервала ε для оценки параметра Θ зависит от того, какая предварительная информация о распределении СВ известна.
Пусть случайная величина распределена нормально с параметрами  ,
,  (
(  ). Для оценкипараметра генеральной совокупностипри неизвестном значении σ, в качестве точечной оценки
). Для оценкипараметра генеральной совокупностипри неизвестном значении σ, в качестве точечной оценки  используют
используют 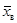 , а доверительный интервалимеет вид:
, а доверительный интервалимеет вид:
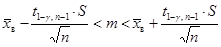 , , | (3.22) |
где S – исправленное среднее квадратическое отклонение случайной величины Х, вычисленное по выборке (х1, х2, …, хn),  .
.
Таким образом, полуширина равна
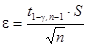 , , | (3.23) |
где  — критическое значение распределения Стьюдента с n-1 степенями свободы для р-значения, равного
— критическое значение распределения Стьюдента с n-1 степенями свободы для р-значения, равного 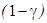 .
.
3.4. Надстройка «Пакет анализа» MS Excel
Надстройка (модуль) «Пакет анализа» MS Excel предназначен для выполнения базовых операций статистического анализа. Полученные с его помощью результаты не обновляются при изменении исходных данных, поэтому после их изменения для обновления результатов требуется снова выполнить соответствующую команду.
Для активизации надстройки Пакет анализа выберите пункт меню Сервис →Анализ данных.Если этот пункт меню недоступен, загрузите Пакет анализа(Сервис→ Надстройки).
3.4.1. Описательная статистика
Это средство анализа (рис.3.10) служит для создания таблицы с точечными оценками одномерной выборки

Рис.3.10 Диалоговое окно «Описательная статистика»
Раздел Входные данные
Поле Входной интервал используется для ввода диапазона смежных ячеек с анализируемыми данными.
Группа переключателей Группирование используется для указания способа расположения анализируемых данных по столбцам или по строкам.
Флажок Метки в первой строке устанавливают для обозначения того, что первая строка анализируемых данных содержит заголовки столбцов.
Раздел Параметры вывода
Выходной интервал — переключатель, используемый для указания начальной ячейки в верхнем левом углу диапазона ячеек, в которых будут располагаться полученные результаты.
Переключатель Новый рабочий лист используется для указания того, что результаты будут располагаться на новом рабочем листе с указанным именем.
Флажок Итоговая статистика используется для вывода статистических параметров.
3.4.2. Ранг и персентиль
Инструмент «Ранг и персентиль» — средство анализа, которое используется для вывода таблицы, содержащей порядковый и процентный ранги для каждого значения в наборе данных (рис.3.11).

Рис.3.11. Диалоговое окно «Ранг и персентиль»
Данная процедура может быть применена для анализа относительного взаиморасположения данных в наборе и для приближенного построения функции распределения.
«Гистограмма» — один из инструментов пакета анализа. Используется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений (рис.3.12).

Рис.3.12 Диалоговое окно «Гистограмма»
Параметры диалогового окна «Гистограмма«:
Входной интервал. Используют для ввода диапазона смежных ячеек с исследуемыми данными.
Интервал карманов (необязательный).Используют для ввода диапазона ячеек и необязательного набора граничных значений, определяющих отрезки (карманы). Эти значения должны быть введены в возрастающем порядке. В Microsoft Excel вычисляется число попаданий данных в интервал, ограниченный началом отрезка и соседним большим по порядку, если такой есть. При этом в интервал включаются значения, принадлежащие нижней границе отрезка и не включаются значения, соответствующие верхней границе.
Если диапазон карманов не был введен, то набор отрезков, равномерно распределенных между минимальным и максимальным значениями данных, будет создан автоматически.
Метки.Флажок устанавливают, когда первая строка анализируемых данных содержит заголовки столбцов. Если заголовки отсутствуют; в этом случае подходящие названия для данных выходного диапазона будут созданы автоматически.
Выходной интервал.Используют для указания ссылки на левую верхнюю ячейку выходного диапазона. Размер выходного диапазона будет определен автоматически, и на экран будет выведено сообщение в случае возможного наложения выходного диапазона на исходные данные.
Из генеральной совокупности извлечена выборка объема n. Изучить распределение непрерывного признака Х некоторой генеральной совокупности.
Требуется:
1. Построить вариационный ряд.
2. Найти точечные оценки математического ожидания, дисперсии, среднего квадратического отклонения, моды, медианы, размаха, асимметрии и эксцесса.
3. Вычислить первый, второй и третий квартили, используя встроенную функцию КВАРТИЛЬ();
4. Вычислить 5-ый, 50-ый и 95-ый персентили, используя встроенную функцию ПЕРСЕНТИЛЬ().
5. Построить (приближенно) эмпирическую функцию распределения данного вариационного ряда. С помощью графика этой функции проиллюстрировать результаты, полученные в п.3 и 4.
6. Построить диаграмму типа «Ящик с усами».
7. Построить интервальный вариационный ряд.
8. Построить полигон, гистограмму, кумуляту и эмпирическую функцию распределения для полученного интервального вариационного ряда.
9. Найти точечные оценки числовых характеристик mX, DX, sX используя интервальный ряд. Сравнить результаты с п.2 (объяснить различия).
10. Считать, что выборка получена из генеральной совокупности нормально распределенной с неизвестным σ. Построить доверительный интервал для оценки математического ожидания генеральной совокупности (параметра m). Вычисления провести по формулам (3.22)-(3.23). Используя последнюю формулу, проанализировать зависимость ширины доверительного интервала от объема выборки, однородности выборки и меры надежности .
Указания по выполнению лабораторной работы.
Исходные данные приведены в виде таблиц Excel (файл Лаб_раб_3.xls), в интервале ячеек А5:А64 (Рис.3.13).

Рис.3.13. Рабочий лист MS Excel в режиме отображения данных.
Для упорядочивания признака Х по возрастанию следуетвоспользоваться командой Данные→Сортировка, результат сортировки расположить в этом же интервале.
Для выполнения п.2. точечные оценки можно найти двумя способами:
· с помощью встроенных функций: СРЗНАЧ(), ДИСП(), МЕДИАНА() и т.д. (рис.3.13 и рис.3.14);
· с помощью надстройки Excel «Пакет Анализа – Описательные статистики». Для этого следует заполнить диалоговое окно, приведенное на рис.3.11 и получить результат в интервале ячеек Н8:I20. (рис.3.14).
 .
.

Рис.3.14. Фрагмент рабочего листа MS Excel в режиме отображения формул
При выполнении п.5 следует учесть, что функция распределения в данном случае должна быть разрывной. Поскольку наблюдений много (n=60), то ступени мелкие (1/n=1/60), поэтому будем считать функцию распределения непрерывной (при том, что Excel не умеет строить разрывные функции).
Построение графика функции распределения проведем в два этапа:
· с помощью надстройки MS Excel «Пакет Анализа — Ранг и персентиль» получим таблицу с накопленными частотами. Результат работы надстройки приведен на рис.3.15 (интервал ячеек К4:N64);

Рис.3.15 Фрагмент рабочего листа MS Excel с результатами работы надстройки «Пакет Анализа — Ранг и перcентиль»
· полученные значения отсортировать по возрастанию значений вариант в другом диапазоне рабочего листа – в интервале ячеек B132:C194 (рис.3.16);

Рис.3.16 Построение функции распределения
Назначить числовой формат данных в ячейках С135:С194, построить график эмпирической функции распределения. Результат представлен на рис. 3.16.
Для выполнения п.6 строим диаграмму «Ящик с усами» самостоятельно любым удобным способом (карандаш + линейка + бумага или Excel или средства типа AutoCAD и т.д).
Перед построением заполним таблицу (рис.3.17), предварительно выполнив соответствующие расчеты:
| Характеристики «ящика с усами» | |
| Параметр | Значение |
| Внешнее верхнее ограждение | |
| Внутреннее верхнее ограждение | |
| Верхний ус | |
| Максимальное значение | |
| Третья квартиль | |
| Медиана | |
| Первая квартиль | |
| Минимальное значение | |
| Нижний ус | |
| Внутреннее нижнее ограждение | |
| Внешнее нижнее ограждение | |
| Интерквартильный диапазо |
Рис.3.17. Таблица для построения диаграммы «Ящик с усами»
Для заполнения таблицы следует использовать результаты, полученные в п.4, остальные значения (интерквартильный диапазон; внешнее и внутреннее верхнее и нижнее ограждения) вычисляем самостоятельно.
Для выполнения п.7 по формулам (3.10 – 3.12) найдем размах, количество и длину интервалов. Результаты вычислений приведены на рис.3.18. Сам интервальный ряд приведен в ячейках С67:G78 на рис.3.19. При построении интервального ряда ширина интервала округлена до 2.0, в качестве левой границы первого интервала взято значение –4, что привело к увеличению числа интервалов до 9.

Рис.3.18 Фрагмент рабочего листа MS Excel. Определение параметров
интервального вариационного ряда
При выполнении п.8 гистограмму построим двумя способами: с помощью «Мастера Диаграмм» и с помощью надстройки Excel «Сервис®Пакет Анализа®Гистограмма» (рис.3.19).

Рис.3.19 Фрагмент рабочего листа MS Excel. Построение интервального вариационного ряда
Обратим внимание, что это средство позволяет получить значения частот, не обращаясь к их непосредственному подсчету.

Рис.3.20 Диаграмма MS Excel, полученная с помощью надстройки «Пакет Анализа — Гистограмма»
При выполнении п.9 для вычисления значений mX, DX, sX заполним интервал ячеек K70:L78. Результаты вычислений представлены в ячейках K80, L80-L81.
При выполнении п.10 доверительный интервал вычислим по формулам (3.22)-(3.23).
Результаты вычислений приведены на рис.3.21-3.22.

Рис.3.21. Построение доверительного интервала
(режим отображения данных)
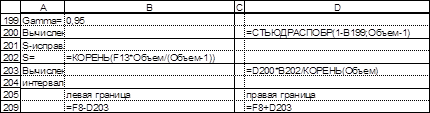
Рис.3.22. Построение доверительного интервала
(режим отображения формул)
Таким образом, доверительным интервалом для оценки среднего генеральной совокупности с надежностью, равной 0.95, будет интервал [3.89; 5.40].
Лабораторная работа 4:
ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Цель: Получить понятия о проверке статистических гипотез о виде распределения, о равенстве средних значений и дисперсий двух нормально распределенных совокупностей.
4.1. БАЗОВЫЕ ПОНЯТИЯ
Часто в процессе исследований требуется по выборочным данным определить закон распределения генеральной совокупности. При этом есть основания предполагать, что этот закон распределения имеет определенный вид. В других случаях закон распределения совокупности известен, и нужно оценить величину параметров. При этом предполагают, что неизвестные параметры распределения равны некоторым определенным значениям.
Пусть H0 (нулевая гипотеза) – выдвинутая гипотеза о виде распределения или о значении параметров распределения. Вместе с гипотезой H0 всегда рассматривается альтернативная (конкурирующая) гипотеза H1, которая является противоположной проверяемой гипотезе H0.
Статистическим критерием называют случайную величину Т, которая используется для проверки нулевой гипотезы. Множество возможных значений Т разбито на два непересекающихся подмножества. Одно из них содержит значения критерия, при которых нулевая гипотеза принимается, другое – при которых H0 отвергается и принимается альтернативная гипотеза H1. Критической областью называется совокупность значений критерия, при которых гипотезу отвергают. Область принятия гипотезы H0 — совокупность значений критерия, при которых гипотезу H0 принимают. Критическая точка Tкрит. отделяет критическую область от области принятия гипотезы.
Уровень значимости α -достаточно малая вероятность (0.05; 0.01). Значение Tкрит. вычисляется таким образом, чтобы при справедливостигипотезы H0 вероятность того, что значение T превзойдет значение Tкрит была равна α. Таким образом, если найденное значение T меньше Tкрит ( T 2 (хи–квадрат));
· о равенстве дисперсий двух нормально распределенных генеральных совокупностей (критерий Фишера);
· о равенстве двух средних нормально распределенных генеральных совокупностей (критерий Стьюдента (t – критерий)).
Критерием согласия называют критерий для проверки гипотезы о предполагаемом законе неизвестного распределения. Наиболее распространен критерий согласия Пирсона χ 2 («хи–квадрат»). При использовании критерия «хи–квадрат» предполагают, что выборочные данные получены из генеральной совокупности с известным законом распределения (гипотеза H0). Альтернативной гипотезой является H1: выборочные данные получены из генеральной совокупности с другим законом распределения.
При проверке по этому критерию находят теоретические частоты, сравнивают их с эмпирическими частотами. Если расхождение случайно, то гипотезу H0 принимают, иначе принимают гипотезу H1 .
Пусть  наблюдений распределены по k разрядам, mi – количество наблюдений в i-том разряде. Пусть известен закон распределения генеральной совокупности, из которой предположительно получена выборка, и
наблюдений распределены по k разрядам, mi – количество наблюдений в i-том разряде. Пусть известен закон распределения генеральной совокупности, из которой предположительно получена выборка, и  — вероятность попадания в i-ый разряд. Тогда
— вероятность попадания в i-ый разряд. Тогда  — теоретическая частота i-го разряда.
— теоретическая частота i-го разряда.
Меру расхождения между эмпирическими (фактическими) частотами и предполагаемыми теоретическими определяют как:
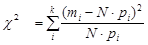 , , | (4.1) |
где k – количество разрядов, в которые сведены результаты опытов; mi – количество наблюдений в i-том разряде; рi – теоретическая вероятность (в соответствии с предполагаемым законом распределения) i-го разряда.
Далее определяется число степеней свободы r:
 , (4.2)
, (4.2)
где: с – число параметров теоретического распределения. Для закона распределения Пуассона и показательного закона распределения с = 1; для нормального, непрерывного равномерного − с = 2; для непрерывного дискретного − с = 0.
По заданным значениям α и r с помощью специальной таблицы находят χ 2 крит. В случае отсутствия таблиц можно использовать встроенную функцию Excel ХИ2ОБР, которая имеет следующий формат:
ХИ2ОБР (вероятность; число степеней свободы)
например: ХИ2ОБР(0.05; 5).
Сравнивают найденное значение χ 2 с значением χ 2 крит. Если χ 2 ≤ χ 2 крит, то гипотезу H0 о совпадении эмпирического распределения с теоретическим принимают. В противном случае (χ 2 > χ 2 крит), гипотезу H0 отвергают, принимают гипотезу H1.
Практически mi должны быть больше или равны 5, если в некотором интервале это условие нарушается, то интервал объединяется с соседним.
Пример 4.1.В результате 300 бросков кости (кубика с 6 гранями) были получены следующие результаты (табл.4.2):
| Число очков |
| Кол-во повторений |
Проверить гипотезу о том, что кость «правильная».
Решение.
Если кость «правильная», то в таблице количество повторений числа выпавших очков должно быть почти одинаково. В этом случае имеет место равномерный закон распределения числа выпавших очков, и каждый из шести возможных исходов (число выпавших очков) равновероятен, т.е. Pi=1/6 для всех i=1,2…6. Таким образом, задача оценки «правильности» кости сводиться к проверке гипотезы H0, состоящей в том, что выборка, приведенная в табл.4.2, является равномерно распределенной. Альтернативной является гипотеза H1 – данная выборка не является равномерно распределенной. Все расчеты сведены в табл.4.3.
| Xi | mi | Pi | N*Pi | (mi-N*Pi)^2/N*Pi |
| 0,1667 | 2,88 | |||
| 0,1667 | 2,88 | |||
| 0,1667 | 0,00 | |||
| 0,1667 | 0,08 | |||
| 0,1667 | 0,98 | |||
| 0,1667 | 4,50 | |||
| N= | 11,32 | Xi-квадрат |
Получено значение χ 2 =11,320. В нашем случае r = 6-1= 5, и при α=0.05 находим значение χ 2 крит = 11,07. Поэтому гипотеза H0 о равномерном распределении отвергается и принимается альтернативная гипотеза H1. Приходим к выводу, что кость «неправильная». На рис.4.1. представлено сравнение экспериментального и теоретического распределений числа выпавших очков при бросании игральной кости.
Пример 4.2.
Проверить гипотезу о том, что распределение, представленное в таблице 4.4, является частным случаем нормального распределения (уровень значимости α = 0,05) (см. материалы лабораторной работы №3, табл.3.1).

Рис.4.1. Сравнение экспериментального и теоретического распределений числа выпавших очков при бросании игральной кости.
Таблица 4.4
| Интервал | Частота mi |
| [-4;-2] | |
| [-2;0] | |
| [0;2] | |
| [2;4] | |
| [4;6] | |
| [6;8] | |
| [8;10] | |
| [10;12] | |
| [12;14] |
Решение.
Построим полигон распределения (рис.3.2). Кривая имеет колоколообразную форму и симметрична, поэтому можно сделать предположение, что выборка получена из нормально распределенной генеральной совокупности. Выдвигаем гипотезу Но: данное эмпирическое распределение следует нормальному закону распределения. Альтернативная гипотеза – Н1: эмпирическое распределение не следует нормальному закону распределения.
Воспользуемся результатами, полученными в лаб.раб. 3 (рис.3.19). Будем считать, что диапазон ячеек C67:L81 уже заполнен, т.е. уже вычислены среднее значение  , равное 4.77, и стандартное отклонение s, равное 3.03:
, равное 4.77, и стандартное отклонение s, равное 3.03:
· в интервале ячеек D70:E78 указаны значения левой и правой границ интервала;
· в интервале ячеек F70:F78 – середины интервалов;
· в интервале ячеек G70:G78 — наблюдаемые значения частот mi .
http://kartaslov.ru/%D0%BA%D0%B0%D1%80%D1%82%D0%B0-%D0%B7%D0%BD%D0%B0%D0%BD%D0%B8%D0%B9/%D0%A1%D1%82%D0%B5%D0%BF%D0%B5%D0%BD%D0%B8+%D1%81%D0%B2%D0%BE%D0%B1%D0%BE%D0%B4%D1%8B+(%D1%84%D0%B8%D0%B7%D0%B8%D0%BA%D0%B0)
http://megapredmet.ru/1-71722.html