Показатели качества регрессии
Качество модели регрессии связывают с адекватностью модели наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным проводится на основе анализа остатков —  .
.
Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов. Согласно общим предположениям регрессионного анализа, остатки должны вести себя как независимые (в действительности, почти независимые) одинаково распределенные случайные величины.
Качество модели регрессии оценивается по следующим направлениям:
проверка качества всего уравнения регрессии;
проверка значимости всего уравнения регрессии;
проверка статистической значимости коэффициентов уравнения регрессии;
проверка выполнения предпосылок МНК.
При анализе качества модели регрессии, в первую очередь, используется коэффициент детерминации, который определяется следующим образом:

где 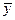 — среднее значение зависимой переменной,
— среднее значение зависимой переменной,
 — предсказанное (расчетное) значение зависимой переменной.
— предсказанное (расчетное) значение зависимой переменной.
Коэффициент детерминации показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, т. е. определяет, какая доля вариации признака Y учтена в модели и обусловлена влиянием на него факторов.
Чем ближе 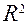 к 1, тем выше качество модели.
к 1, тем выше качество модели.
Для оценки качества регрессионных моделей целесообразно также использовать коэффициент множественной корреляции (индекс корреляции) R
R =  =
= 
Данный коэффициент является универсальным, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных.
Важным моментом является проверка значимости построенного уравнения в целом и отдельных параметров.
Оценить значимость уравнения регрессии – это означает установить, соответствует ли математическая модель, выражающая зависимость между Y и Х, фактическим данным и достаточно ли включенных в уравнение объясняющих переменных Х для описания зависимой переменной Y
Оценка значимости уравнения регрессии производится для того, чтобы узнать, пригодно уравнение регрессии для практического использования (например, для прогноза) или нет.
Для проверки значимости модели регрессии используется F-критерий Фишера. Если расчетное значение с n1= k и n2 = (n — k — 1) степенями свободы, где k – количество факторов, включенных в модель, больше табличного при заданном уровне значимости, то модель считается значимой.

В качестве меры точности применяют несмещенную оценку дисперсии остаточной компоненты, которая представляет собой отношение суммы квадратов уровней остаточной компоненты к величине (n- k -1), где k – количество факторов, включенных в модель. Квадратный корень из этой величины (  ) называется стандартной ошибкой:
) называется стандартной ошибкой:
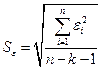
значимость отдельных коэффициентов регрессии проверяется по t-статистике путем проверки гипотезы о равенстве нулю j-го параметра уравнения (кроме свободного члена):
 ,
,
где Saj — это стандартное (среднеквадратическое) отклонение коэффициента уравнения регрессии aj. Величина Saj представляет собой квадратный корень из произведения несмещенной оценки дисперсии  и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.
и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.

где  — диагональный элемент матрицы
— диагональный элемент матрицы 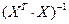 .
.
Если расчетное значение t-критерия с (n — k — 1) степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
Проверка выполнения предпосылок МНК.
Рассмотрим выполнение предпосылки гомоскедастичности, или равноизменчивости случайной составляющей (возмущения).
Невыполнение этой предпосылки, т.е. нарушение условия гомоскедастичности возмущений означает, что дисперсия возмущения зависит от значений факторов. Такие регрессионные модели называются моделями с гетероскедастичностью возмущений.
Обнаружение гетероскедастичности. Для обнаружения гетероскедастичности обычно используют тесты, в которых делаются различные предположения о зависимости между дисперсией случайного члена и объясняющей переменной: тест ранговой корреляции Спирмена, тест Голдфельда — Квандта, тест Глейзера, двусторонний критерий Фишера и другие [2].
При малом объеме выборки для оценки гетероскедастичности может использоваться метод Голдфельда — Квандта. Данный тест используется для проверки такого типа гетероскедастичности, когда дисперсия остатков возрастает пропорционально квадрату фактора. При этом делается предположение, что, случайная составляющая 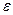 распределена нормально.
распределена нормально.
Чтобы оценить нарушение гомоскедастичности по тесту Голдфельда — Квандта необходимо выполнить следующие шаги.
Упорядочение п наблюдений по мере возрастания переменной х.
Исключение 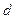 средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
Разделение совокупности на две группы (соответственно с малыми и большими значениями фактора  ) и определение по каждой из групп уравнений регрессии.
) и определение по каждой из групп уравнений регрессии.
Определение остаточной суммы квадратов для первой регрессии  и второй регрессии
и второй регрессии  .
.
Вычисление отношений  (или
(или 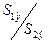 ). В числителе должна быть большая сумма квадратов.
). В числителе должна быть большая сумма квадратов.
Полученное отношение имеет F распределение со степенями свободы k1=n1-k и k2=n-n1-k, (k– число оцениваемых параметров в уравнении регрессии).
Если  , то гетероскедастичность имеет место.
, то гетероскедастичность имеет место.
Чем больше величина F превышает табличное значение F -критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
Оценка влияния отдельных факторов на зависимую переменную на основе модели (коэффициенты эластичности, b — коэффициенты).
Важную роль при оценке влияния факторов играют коэффициенты регрессионной модели. Однако непосредственно с их помощью нельзя сопоставить факторы по степени их влияния на зависимую переменную из-за различия единиц измерения и разной степени колеблемости. Для устранения таких различий при интерпретации применяются средние частные коэффициенты эластичности Э(j) и бета-коэффициенты b(j).
Эластичность Y по отношению к Х(j) определяется как процентное изменение Y, отнесенное к соответствующему процентному изменению Х. В общем случае эластичности не постоянны, они различаются, если измерены для различных точек на линии регрессии. По умолчанию стандартные программы, оценивающие эластичность, вычисляют ее в точках средних значений:
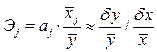
Эластичность ненормирована и может изменяться от —  до + . Важно, что она безразмерна, так что интерпретация эластичности
до + . Важно, что она безразмерна, так что интерпретация эластичности  =2.0 означает, что если
=2.0 означает, что если  изменится на 1%, то это приведет к изменению
изменится на 1%, то это приведет к изменению  на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
Высокий уровень эластичности означает сильное влияние независимой переменной на объясняемую переменную.

где Sxj — среднеквадратическое отклонение фактора j
где 
 .
.
Коэффициент эластичности показывает, на сколько процентов изменяется зависимая переменная при изменении фактора j на один процент. Однако он не учитывает степень колеблемости факторов.
Бета-коэффициент показывает, на какую часть величины среднего квадратического отклонения Sy изменится зависимая переменная Y с изменением соответствующей независимой переменной Хj на величину своего среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных.
Указанные коэффициенты позволяют упорядочить факторы по степени влияния факторов на зависимую переменную.
Долю влияния фактора в суммарном влиянии всех факторов можно оценить по величине дельта — коэффициентов D (j):

где  — коэффициент парной корреляции между фактором j (j = 1. m) и зависимой переменной.
— коэффициент парной корреляции между фактором j (j = 1. m) и зависимой переменной.
В качестве основного литературного источника рекомендуется использовать [4], в качестве дополнительного – [2].
R — значит регрессия
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.

Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.
Введение в регрессионный анализ
Если имеется корреляционная зависимость  между переменными y и x , возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения
между переменными y и x , возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения  называется регрессией y по x .
называется регрессией y по x .
Основу регрессионного анализа составляет метод наименьших квадратов (МНК), в соответствии с которым в качестве уравнения регресии берется функция  такая, что сумма квадратов разностей
такая, что сумма квадратов разностей  минимальна.
минимальна.

Карл Гаусс открыл, или точнее воссоздал, МНК в возрасте 18 лет, однако впервые результаты были опубликованы Лежандром в 1805 г. По непроверенным данным метод был известен еще в древнем Китае, откуда он перекочевал в Японию и только затем попал в Европу. Европейцы не стали делать из этого секрета и успешно запустили в производство, обнаружив с его помощью траекторию карликовой планеты Церес в 1801 г.
Вид функции , как правило, определен заранее, а с помощью МНК подбираются оптимальные значения неизвестных параметров. Метрикой рассеяния значений  вокруг регрессии
вокруг регрессии  является дисперсия.
является дисперсия.

- k — число коэффициентов в системе уравнений регрессии.
Чаще всего используется модель линейной регрессии, а все нелинейные зависимости приводят к линейному виду с помощью алгебраических ухищрений, различных преобразования переменных y и x .
Линейная регрессия
Уравнения линейной регрессии можно записать в виде

В матричном виде это выгладит

- y — зависимая переменная;
- x — независимая переменная;
- β — коэффициенты, которые необходимо найти с помощью МНК;
- ε — погрешность, необъяснимая ошибка и отклонение от линейной зависимости;

Случайная величина может быть интерпретирована как сумма из двух слагаемых:
 — полная дисперсия (TSS).
— полная дисперсия (TSS).- — объясненная часть дисперсии (ESS).
- — остаточная часть дисперсии (RSS).
 — объясненная часть дисперсии (ESS).
— объясненная часть дисперсии (ESS). — остаточная часть дисперсии (RSS).
— остаточная часть дисперсии (RSS).Еще одно ключевое понятие — коэффициент корреляции R 2 .

Ограничения линейной регрессии
Для того, чтобы использовать модель линейной регрессии необходимы некоторые допущения относительно распределения и свойств переменных.
- Линейность, собственно. Увеличение, или уменьшение вектора независимых переменных в k раз, приводит к изменению зависимой переменной также в k раз.
- Матрица коэффициентов обладает полным рангом, то есть векторы независимых переменных линейно независимы.
- Экзогенность независимых переменных — . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
- Однородность дисперсии и отсутствие автокорреляции. Каждая εi обладает одинаковой и конечной дисперсией σ 2 и не коррелирует с другой εi. Это ощутимо ограничивает применимость модели линейной регрессии, необходимо удостовериться в том, что условия соблюдены, иначе обнаруженная взаимосвязь переменных будет неверно интерпретирована.
 . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
. Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.Как обнаружить, что перечисленные выше условия не соблюдены? Ну, во первых довольно часто это видно невооруженным глазом на графике.
Неоднородность дисперсии 
При возрастании дисперсии с ростом независимой переменной имеем график в форме воронки.

Нелинейную регрессии в некоторых случая также модно увидеть на графике довольно наглядно.
Тем не менее есть и вполне строгие формальные способы определить соблюдены ли условия линейной регрессии, или нарушены.
- Автокорреляция проверяется статистикой Дарбина-Уотсона (0 ≤ d ≤ 4). Если автокорреляции нет, то значения критерия d≈2, при позитивной автокорреляции d≈0, при отрицательной — d≈4.
- Неоднородность дисперсии — Тест Уайта, , при \chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же можно еще применить тест Бройша-Пагана.
- Мультиколлинеарность — нарушения условия об отсутствии взаимной линейной зависимости между независимыми переменными. Для проверки часто используют VIF-ы (Variance Inflation Factor).
 , при
, при  \chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же
\chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же  можно еще применить тест Бройша-Пагана.
можно еще применить тест Бройша-Пагана.
В этой формуле  — коэффициент взаимной детерминации между
— коэффициент взаимной детерминации между  и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
Почему нам так важно соблюдение всех выше перечисленных условий? Все дело в Теореме Гаусса-Маркова, согласно которой оценка МНК является точной и эффективной лишь при соблюдении этих ограничений.
Как преодолеть эти ограничения
Нарушения одной или нескольких ограничений еще не приговор.
- Нелинейность регрессии может быть преодолена преобразованием переменных, например через функцию натурального логарифма ln .
- Таким же способом возможно решить проблему неоднородной дисперсии, с помощью ln , или sqrt преобразований зависимой переменной, либо же используя взвешенный МНК.
- Для устранения проблемы мультиколлинеарности применяется метод исключения переменных. Суть его в том, что высоко коррелированные объясняющие переменные устраняются из регрессии, и она заново оценивается. Критерием отбора переменных, подлежащих исключению, является коэффициент корреляции. Есть еще один способ решения данной проблемы, который заключается в замене переменных, которым присуща мультиколлинеарность, их линейной комбинацией. Этим весь список не исчерпывается, есть еще пошаговая регрессия и другие методы.
К сожалению, не все нарушения условий и дефекты линейной регрессии можно устранить с помощью натурального логарифма. Если имеет место автокорреляция возмущений к примеру, то лучше отступить на шаг назад и построить новую и лучшую модель.
Линейная регрессия плюсов на Хабре
Итак, довольно теоретического багажа и можно строить саму модель.
Мне давно было любопытно от чего зависит та самая зелененькая цифра, что указывает на рейтинг поста на Хабре. Собрав всю доступную статистику собственных постов, я решил прогнать ее через модель линейно регрессии.
Загружает данные из tsv файла.
- points — Рейтинг статьи
- reads — Число просмотров.
- comm — Число комментариев.
- faves — Добавлено в закладки.
- fb — Поделились в социальных сетях (fb + vk).
- bytes — Длина в байтах.
Вопреки моим ожиданиям наибольшая отдача не от количества просмотров статьи, а от комментариев и публикаций в социальных сетях. Я также полагал, что число просмотров и комментариев будет иметь более сильную корреляцию, однако зависимость вполне умеренная — нет надобности исключать ни одну из независимых переменных.
Теперь собственно сама модель, используем функцию lm .
В первой строке мы задаем параметры линейной регрессии. Строка points
. определяет зависимую переменную points и все остальные переменные в качестве регрессоров. Можно определить одну единственную независимую переменную через points
reads , набор переменных — points
Перейдем теперь к расшифровке полученных результатов.
- Intercept — Если у нас модель представлена в виде , то тогда — точка пересечения прямой с осью координат, или intercept .
- R-squared — Коэффициент детерминации указывает насколько тесной является связь между факторами регрессии и зависимой переменной, это соотношение объясненных сумм квадратов возмущений, к необъясненным. Чем ближе к 1, тем ярче выражена зависимость.
- Adjusted R-squared — Проблема с в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
- F-statistic — Используется для оценки значимости модели регрессии в целом, является соотношением объяснимой дисперсии, к необъяснимой. Если модель линейной регрессии построена удачно, то она объясняет значительную часть дисперсии, оставляя в знаменателе малую часть. Чем больше значение параметра — тем лучше.
- t value — Критерий, основанный на t распределении Стьюдента . Значение параметра в линейной регрессии указывает на значимость фактора, принято считать, что при t > 2 фактор является значимым для модели.
- p value — Это вероятность истинности нуль гипотезы, которая гласит, что независимые переменные не объясняют динамику зависимой переменной. Если значение p value ниже порогового уровня (.05 или .01 для самых взыскательных), то нуль гипотеза ложная. Чем ниже — тем лучше.
 , то тогда
, то тогда  — точка пересечения прямой с осью координат, или intercept .
— точка пересечения прямой с осью координат, или intercept . в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
Можно попытаться несколько улучшить модель, сглаживая нелинейные факторы: комментарии и посты в социальных сетях. Заменим значения переменных fb и comm их степенями.
Проверим значения параметров линейной регрессии.
Как видим в целом отзывчивость модели возросла, параметры подтянулись и стали более шелковистыми , F-статистика выросла, так же как и скорректированный коэффициент детерминации .
Проверим, соблюдены ли условия применимости модели линейной регрессии? Тест Дарбина-Уотсона проверяет наличие автокорреляции возмущений.
И напоследок проверка неоднородности дисперсии с помощью теста Бройша-Пагана.
В заключение
Конечно наша модель линейной регрессии рейтинга Хабра-топиков получилось не самой удачной. Нам удалось объяснить не более, чем половину вариативности данных. Факторы надо чинить, чтобы избавляться от неоднородной дисперсии, с автокорреляцией тоже непонятно. Вообще данных маловато для сколь-нибудь серьезной оценки.
Но с другой стороны, это и хорошо. Иначе любой наспех написанный тролль-пост на Хабре автоматически набирал бы высокий рейтинг, а это к счастью не так.
Анализ общего качества уравнения регрессии.
Коэффициент детерминации R 2
После проверки точности и статистической значимости каждого коэффициента регрессионной модели обычно проводится анализ общего качества уравнения модели, которое оценивается по тому, как хорошо эмпирическое уравнение регрессии согласуется со статистическими данными. Другими словами, необходимо оценить, насколько широко рассеяны точки наблюдений по их совокупности относительно линии регрессии (линии модели). Поэтому представляется естественным вывод о том, что проверку общего качества регрессионной модели следует проводить на основе дисперсионного анализа, сравнивая дисперсии модельных и реальных значений исследуемой переменной Y.
Рассмотрим для определенного набора наблюдений n дисперсию Dn(y), которая характеризует разброс значений yi вокруг среднего значения. Из дисперсионного анализа следует, что эту дисперсию можно разбить на две части: объясняемую уравнением регрессии и не объясняемую (т. е. связанную со случайными отклонениями ei). Тогда выполняется следующее соотношение:
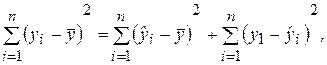 (2.27)
(2.27)
где 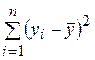 – общая сумма квадратов отклонений зависимой переменной Y от среднего значения;
– общая сумма квадратов отклонений зависимой переменной Y от среднего значения;
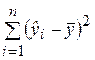 – сумма квадратов, объясняемая уравнением регрессии;
– сумма квадратов, объясняемая уравнением регрессии;
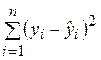 – необъясненная (остаточная) сумма квадратов. Напомним, что
– необъясненная (остаточная) сумма квадратов. Напомним, что 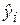 определяется как
определяется как 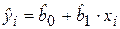 , а
, а 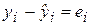 .
.
Разделив выражение (2.27) на его левую часть, получим формулу для оценки характеристики, которая обозначается как R 2 и называется коэффициентом детерминации:
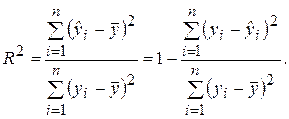 (2.28)
(2.28)
Коэффициент детерминации R 2 является мерой качества уравнения регрессионной модели и определяет долю дисперсии (разброса), объясняемую регрессией Y на Х, в общей дисперсии зависимой переменной Y.
Из проведенных рассуждений следует, что R 2 принимает значения между 0 и 1 (0 £ R 2 £ 1). Чем ближе R 2 к единице, тем теснее линейная связь между Х и Y (экспериментальные точки теснее примыкают к линии регрессии). Чем ближе R 2 к нулю, тем такая связь слабее. Если R 2 = 0, то дисперсия зависимой переменной полностью обусловлена воздействием неучтенных факторов и линия регрессии (модели) должна быть параллельна оси абсцисс (Y = 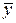 ).
).
Например, если для построенной модели R 2 = 0,7, то согласно (2.28) можно утверждать, что поведение зависимой переменной (результативного признака) Y на 70 % объясняется влиянием фактора Х и на 30 % обусловлено влиянием неучтенных факторов. Доля влияния неучтенных факторов связана со случайными отклонениями ei и определяется отношением 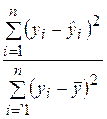 , характеризующим долю разброса зависимой переменной, не объясняемую линейной регрессией Y на Х.
, характеризующим долю разброса зависимой переменной, не объясняемую линейной регрессией Y на Х.
Естественно, что для исследуемого объекта наиболее качественной будет считаться модель с наибольшим значением коэффициента детерминации R 2 .
Заметим, что коэффициент детерминации имеет смысл рассматривать только при наличии параметра 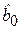 (свободного члена) в уравнении регрессионной модели.
(свободного члена) в уравнении регрессионной модели.
Таким образом, коэффициент детерминации R 2 определяет степень тесноты статистической связи между Y и Х. Но об этом же говорит выборочный коэффициент корреляции rxy. Рассматривая эти характеристики, можно установить, что в случае парной линейной регрессионной модели коэффициент детерминации равен квадрату коэффициента корреляции 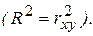
Действительно, учитывая (2.13),
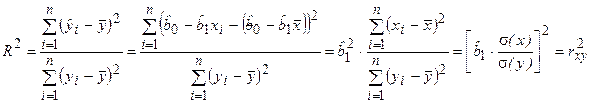 .
.
Естественно, возникает вопрос, какое значение R 2 можно считать удовлетворительным. Ответ на этот вопрос может быть неоднозначным, особенно в случае множественной регрессионной модели и зависит от объема выборки n и постановки задачи, вытекающей из предмодельного анализа.
Более точно проверить значимость уравнения регрессии, т. е. установить, соответствует ли построенная модель реальным данным и достаточно ли включенных в уравнение объясняющих переменных для описания зависимой переменной, позволяет F-тест, который проводится по схеме статистической проверки гипотез. Тестируется гипотеза Н0 о статистической незначимости уравнения регрессии.
Рассмотрим «объясненную» и «необъясненную» дисперсии: 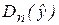 и Dn(e). Отношение этих дисперсий, рассчитанное на одну степень свободы, имеет F-распределение (F-статистику), фактически наблюдаемое значение которой для парной регрессии определяется формулой
и Dn(e). Отношение этих дисперсий, рассчитанное на одну степень свободы, имеет F-распределение (F-статистику), фактически наблюдаемое значение которой для парной регрессии определяется формулой
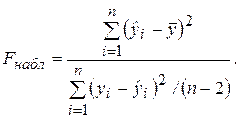 (2.29)
(2.29)
Учитывая смысл дисперсий и Dn(e), можно считать, что значение Fнабл показывает, в какой мере уравнение регрессии лучше оценивает значение зависимой переменной по сравнению с 
Согласно схеме статистической проверки гипотез, гипотеза Н0 отклоняется, т. е. признается статистическая значимость и надежность уравнения регрессии на заданном уровне α, если Fнабл превосходит критическое (табличное) значение F-статистики Фишера (Fнабл > Fкр = Fα, 1, n — 2). Если Fнабл 2 . В этом случае гипотеза Н0 о статистической незначимости регрессионной модели заменяется эквивалентной гипотезой о статистической незначимости R 2 .
Для парной регрессионной модели способы проверки значимости коэффициента 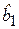 с использованием t-критерия (t-тест) и уравнения регрессии (показателя тесноты связи R 2 ) с использованием F-критерия равносильны, поскольку эти критерии связаны соотношением F = t 2 .
с использованием t-критерия (t-тест) и уравнения регрессии (показателя тесноты связи R 2 ) с использованием F-критерия равносильны, поскольку эти критерии связаны соотношением F = t 2 .
Наряду с коэффициентом детерминации R 2 для оценки качества парной регрессионной модели можно использовать характеристику, называемую средней ошибкой аппроксимации 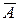 :
:
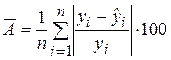 %. (2.31)
%. (2.31)
Средняя ошибка аппроксимации определяет среднее относительное отклонение расчетных данных (оцененных по уравнению модели) от фактических. является безразмерной величиной и обычно выражается в процентах. Принято считать, что качество модели считается удовлетворительным, если средняя ошибка аппроксимации не превышает 8-9 %.
Пример 2.3.Проверить общее качество и статистическую значимость уравнения регрессии для модели, построенной в примере 2.1.
Оценку качества построенной модели дают коэффициент детерминации R 2 и средняя ошибка аппроксимации 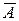 .
.
Вычислим коэффициент детерминации, воспользовавшись данными табл. 2.1.
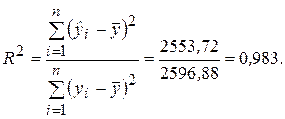
Величина коэффициента детерминации показывает, что поведение результативного признака (недельного потребления) Y на 98,3 % объясняется влиянием фактора Х (изменением недельного дохода), а остальные 1,7 % составляют долю необъясненной вариации, происходящей под действием прочих (неучтенных) факторов.
Расчет средней ошибки аппроксимации представлен в последнем столбце табл. 2.1.
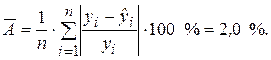
Рассчитанные значения коэффициента детерминации и средней ошибки аппроксимации свидетельствуют о достаточно высоком общем качестве построенной модели.
Проверим статистическую значимость уравнения регрессионной модели с помощью F-теста. Расчетное (наблюдаемое) значение F-статистики Фишера вычисляется по формуле:
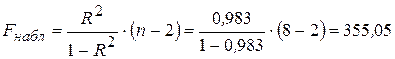 .
.
Табличное значение F-статистики при уровне значимости α = 0,01 и числе степеней свободы ν = n – 2 будет составлять 13,75 (Fкр = 13,75).
Так как Fнабл > Fкр (355,05 > 13,75), то нулевая гипотеза Н0 отклоняется и уравнение регрессионной модели признается статистически значимым и весьма надежным, поскольку наблюдаемое значение F-статистики превосходит табличное значение критерия более чем в 25 раз.
Дата добавления: 2016-06-02 ; просмотров: 2227 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
http://habr.com/ru/post/350668/
http://helpiks.org/8-22676.html