Пример нахождения статистической значимости коэффициентов регрессии
Числитель в этой формуле может быть рассчитан через коэффициент детерминации и общую дисперсию признака-результата:  .
.
Для параметра a критерий проверки гипотезы о незначимом отличии его от нуля имеет вид:
,
где — оценка параметра регрессии, полученная по наблюдаемым данным;
μa – стандартная ошибка параметра a.
Для линейного парного уравнения регрессии: .
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции в генеральной совокупности используют следующий критерий: , где ryx — оценка коэффициента корреляции, полученная по наблюдаемым данным; mr – стандартная ошибка коэффициента корреляции ryx.
Для линейного парного уравнения регрессии: .
В парной линейной регрессии между наблюдаемыми значениями критериев существует взаимосвязь: t ( b =0) = t (r=0).
Пример №1 . Уравнение имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.73 2 = 0.54, т.е. в 54% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — средняя.
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 69 | 124 | 4761 | 15376 | 8556 | 128.48 | 491.36 | 20.11 | 367.36 |
| 83 | 133 | 6889 | 17689 | 11039 | 141.4 | 173.36 | 70.56 | 26.69 |
| 92 | 146 | 8464 | 21316 | 13432 | 149.7 | 0.03 | 13.71 | 14.69 |
| 97 | 153 | 9409 | 23409 | 14841 | 154.32 | 46.69 | 1.73 | 78.03 |
| 88 | 138 | 7744 | 19044 | 12144 | 146.01 | 66.69 | 64.21 | 0.03 |
| 93 | 159 | 8649 | 25281 | 14787 | 150.63 | 164.69 | 70.13 | 23.36 |
| 74 | 145 | 5476 | 21025 | 10730 | 133.1 | 1.36 | 141.68 | 200.69 |
| 79 | 152 | 6241 | 23104 | 12008 | 137.71 | 34.03 | 204.21 | 84.03 |
| 105 | 168 | 11025 | 28224 | 17640 | 161.7 | 476.69 | 39.74 | 283.36 |
| 99 | 154 | 9801 | 23716 | 15246 | 156.16 | 61.36 | 4.67 | 117.36 |
| 85 | 127 | 7225 | 16129 | 10795 | 143.25 | 367.36 | 263.91 | 10.03 |
| 94 | 155 | 8836 | 24025 | 14570 | 151.55 | 78.03 | 11.91 | 34.03 |
| 1058 | 1754 | 94520 | 258338 | 155788 | 1754 | 1961.67 | 906.57 | 1239.67 |
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.2704
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 88,16
(128.06;163.97)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (3.41>1.812).
Статистическая значимость коэффициента регрессии b подтверждается (2.7>1.812).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.812):
(a — tтабл·S a; a + tтабл·Sa)
(0.4325;1.4126)
(b — tтабл·S b; b + tтабл·Sb)
(21.3389;108.3164)
2) F-статистики
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим.
Пример №2 . По территориям региона приводятся данные за 199Х г.;
| Среднедневная заработная плата, руб., у | ||
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х , составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение находим с помощью калькулятора.
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
12a+1027b=1869
1027a+89907b=161808
Из первого уравнения выражаем а и подставим во второе уравнение. Получаем b = 0.92, a = 76.98
Уравнение регрессии: y = 0.92 x + 76.98 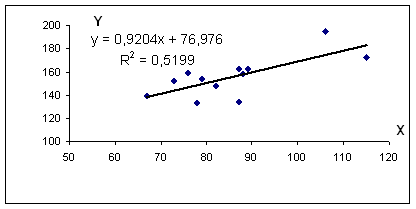
1. Параметры уравнения регрессии.
Выборочные средние.
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%, среднедневная заработная плата изменится менее чем на 1%. Другими словами — влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199, т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами — точность подбора уравнения регрессии — средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| y 2 | x·y | y(x) | (y i — y ) 2 | (y-y(x)) 2 | (x i — x ) 2 | |y-y x |:y | |||
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим tкрит:
tкрит = (10;0.05) = 1.812
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(0.9204 — 1.812·0.2797; 0.9204 + 1.812·0.2797)
(0.4136;1.4273)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a-ta)
(76.9765 — 1.812·24.2116; 76.9765 + 1.812·24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Что означает термин значимость параметров уравнения регрессии
Так как критерии проверки для обоих параметров регрессии находятся в критической области, мы принимаем гипотезу Н]. Это означает, что при заданном уровне значимости параметры регрессии статистически значимо отличаются от нуля. [c.146]
Оценить статистическую значимость параметров регрессии и корреляции. [c.16]
Оценку статистической значимости параметров регрессии проведем с помощью f-статистики Стьюдента и путем расчета доверительного интервала каждого из показателей. [c.18]
Оцените значимость параметров регрессии с помощью f-критерия Стьюдента и сделайте соответствующие выводы о целесообразности включения факторов в модель. [c.86]
При несоблюдении основных предпосылок МНК приходится корректировать модель, изменяя ее спецификацию, добавлять (исключать) некоторые факторы, преобразовывать исходные данные для того, чтобы получить оценки коэффициентов регрессии, которые обладают свойством несмещенности, имеют меньшее значение дисперсии остатков и обеспечивают в связи с этим более эффективную статистическую проверку значимости параметров регрессии. Этой цели, как уже указывалось, служит и применение обобщенного метода наименьших квадратов, к рассмотрению которого мы и переходим в п. 3.11. [c.169]
Перейдем теперь к оценке значимости коэффициентов регрессии bj и построению доверительного интервала для параметров регрессионной модели Ру (J=l,2. р). [c.97]
Когда речь идет о линейной регрессии, необходимо знать, насколько значимо отличаются от нуля величины параметров регрессии. Для проверки этого выдвигаются гипотезы [c.116]
В противном случае мы принимаем гипотезу HI. Это означает, что при заданном уровне значимости соответствующий параметр регрессии статистически значимо отличается от нуля. [c.117]
Необходимо убедиться, что значения параметров регрессии значимо отличаются от нуля. Для проверки этого выдвигаются гипотезы [c.145]
Оцените значимость уравнений регрессии в целом и их параметров. Сравните полученные результаты, выберите лучшее уравнение регрессии. [c.48]
Как оценивается значимость параметров уравнения регрессии [c.89]
Коэффициенты регрессии, найденные исходя из системы нормальных уравнений, представляют собой выборочные оценки характеристики силы связи. Их несмещенность является желательным свойством, так как только в этом случае они могут иметь практическую значимость. Несмещенность оценки означает, что математическое ожидание остатков равно нулю. Следовательно, при большом числе выборочных оцениваний остатки не будут накапливаться и найденный параметр регрессии bt можно рассматривать как среднее значение из возможного большого количества несмещенных оценок. Если оценки обладают свойством несмещенности, то их можно сравнивать по разным исследованиям. [c.156]
Вывод параметры регрессии значимы. [c.11]
В моделях множественной линейной регрессии при увеличении количества параметров регрессии (бета-весов) по отношению к размеру выборки увеличивается степень вредной подгонки и уменьшается достоверность результатов модели. Другими словами, чем выше степень подгонки под исторические данные, тем сложнее добиться статистической значимости. Исключением является случай, когда повышение результативности модели, вызванное подгонкой, компенсирует потерю значимости при добавлении параметров. Оценка степени ожидаемого снижения корреляции при использовании данных вне выборки может производиться напрямую, исходя из объема данных и количества параметров корреляция снижается с увеличением числа параметров и увеличивается с рос- [c.73]
Как показали результаты расчетов, значимые оценки параметров для ожиданий инвесторов получены практически для всех показателей концентрации. Есть значимые оценки параметров ожиданий и в уравнениях регрессии агрегированных показателей концентрации промышленного производства, и в уравнениях отраслевых показателей концентрации. Установлены значимые оценки влияния ожиданий и для абсолютных показателей концентрации, и для индикаторов относительной концентрации. Наконец, обнаружены значимые параметры и для позитивных ожиданий, и для негативных ожиданий инвесторов. Присутствуют значимые оценки параметров как в регрессии с переключением режимов ожиданий, так и в регрессии с переключением режимов ожиданий и дифференциацией по группам регионов (см. табл. 5.1 -5.2). [c.78]
Затем решается вторая задача — определяются параметры регрессии (методом наименьших квадратов). Выбранная кривая проверяется на значимость по критерию Фишера. После окончательного выбора кривой прогнозирование осуществляется на основе экстраполяции тенденции. [c.125]
Коэффициенты регрессии, как и коэффициенты корреляции, — случайные величины, зависящие от объема выборки. Поэтому для проверки надежности коэффициента регрессии выдвигается гипотеза о том, что коэффициент регрессии в генеральной совокупности равен нулю (нулевая гипотеза), т. е. связь, установленная по данным выборки, в генеральной совокупности отсутствует. Простейшая схема проверки этой гипотезы при линейной форме связи сводится к построению доверительного интервала для каждого коэффициента регрессии. Если граничные значения данного коэффициента регрессии в этом интервале имеют противоположные знаки, то принятая гипотеза подтверждается и тогда соответствующий этому параметру уравнения фактор исключается из модели. Для нелинейной формы связи имеются другие методы оценки значимости факторов [c.18]
Далее следует оценить параметры уравнения регрессии на их значимость и показатели тесноты на их существенность. [c.329]
Коэффициент переменной может использоваться в уравнении регрессии, если вычисленная для него величина (1 — Р-значение) близка к 1. Параметр Выпуск продукции и Y-пересечение (свободный член уравнения регрессии) не являются значимыми. Поэтому модельное уравнение регрессии [c.471]
Уравнение парной линейной регрессии или коэффициент регрессии Ь значимы на уровне а (иначе — гипотеза Яо о равенстве параметра Pi нулю, т. е. Яо Pi=0, отвергается), если фактически наблюдаемое значение статистики (3.37) [c.73]
Уравнение множественной регрессии значимо (иначе — гипотеза Щ о равенстве нулю параметров регрессионной модели, т. е. Яо Pi = 02 — Рр= О, отвергается), если (учитывая (3.43) при т = р + 1) [c.103]
К модели (5.13) уже можно применять обычные методы исследования линейной регрессии, изложенные в гл. 4. Однако следует подчеркнуть, что критерии значимости и интервальные оценки параметров, применяемые для нормальной линейной регрессии, требуют, чтобы нормальный закон распределения в моделях (5.11), (5.12) имел логарифм вектора возмущений (т. е. In e Nn (О,
Значимость регрессионной модели
КОРРЕЛЯЦИОННЫЙ И РЕГРЕССИВНЫЙ АНАЛИЗ.
АНАЛИЗ ПАРНЫХ ВЗАИМОСВЯЗЕЙ
Основные понятия
• Связь как синхронность (согласованность) – корреляционный анализ.
• Связь как зависимость (влияние) – регрессионный анализ (причинно-следственные связи).
Основные понятия
• В регрессионном анализе один из признаков зависит от другого.
• Первый (зависимый) признак называется в регрессионном анализе результирующим , второй (независимый) – факторным .
• Не всегда можно однозначно определить, какой из признаков является независимым, а какой – зависимым. Часто связь может рассматриваться как двунаправленная.
Этапы анализа
• Выявление наличия взаимосвязи между признаками;
• Определение формы связи;
• Определение силы (тесноты) и направления связи (dыявление наличия связи между признаками, диаграммы рассеяния)
• Определение формы связи
Поскольку наиболее простой формой зависимости в математике является прямая, то в корреляционном и регрессионном анализе наиболее популярны линейные модели.
Однако иногда расположение точек на диаграмме рассеяния показывает нелинейную зависимость либо вообще отсутствие связи между признаками.
Линия регрессии и уравнение регрессии
Диаграмма рассеяния
Линия регрессии
• Вычисляемая с помощью метода наименьших квадратов прямая линия называется линией регрессии. Она характеризуется тем, что сумма квадратов расстояний от точек на диаграмме до этой линии минимальна (по сравнению со всеми возможными линиями).
• Линия регрессии дает наилучшее приближенное описание линейной зависимости между двумя переменными.
Уравнение парной линейной регрессии
• Как известно, прямая линия описывается уравнением вида:
где Y – результирующий признак, X – факторный признак, k и b – числовые параметры уравнения.
• Коэффициент k в уравнении регрессии называется коэффициентом регрессии.
Смысл коэффициента регрессии
• В общем случае коэффициент регрессии k показывает, как в среднем изменится результативный признак ( Y ), если факторный признак ( X ) увеличится на единицу .
Свойства коэффициента регрессии
• Коэффициент регрессии принимает любые значения.
• Коэффициент регрессии не симметричен , т.е. изменяется, если X и Y поменять местами.
• Единицей измерения коэффициента регрессии является отношение единицы измерения Y к единице измерения X
• Коэффициент регрессии изменяется при изменении единиц измерения X и Y .
Пример единицы измерения коэффициента регрессии
• В уравнении Y = 87610 + 2984 X
коэффициент регрессии равен 2984. В каких единицах он измеряется?
• Поскольку результативный признак Y измеряется, например, в рублях, а факторный признак X, например, в количестве рабочих (чел.), то коэффициент регрессии измеряется в рублях на человека (руб. / чел.)
Сравнение коэффициентов корреляции и регрессии
• Принимает значения в диапазоне от -1 до +1
• Показывает силу связи между признаками
• Знак коэффициента говорит о направлении связи
• Может принимать любые значения
• Привязан к единицам измерения обоих признаков
• Показывает структуру связи между признаками
• Знак коэффициента говорит о направлении связи
МНОЖЕСТВЕННАЯ КОРРЕЛЯЦИЯ И РЕГРЕССИЯ
• Обычно на зависимую переменную действуют сразу несколько факторов, среди которых трудно выделить единственный или главный.
• При этом факторы, влияющие на зависимую переменную, как правило, не являются независимыми друг от друга.
Пример
• Уравнение парной регрессии для зависимости объема производства ( Y ) от числа рабочих ( X 1 ) имеет вид:
Y = 87610 +2984 X 1
• Если построить уравнение парной регрессии для зависимости объема производства ( Y ) от мощности двигателей ( X 2 ), получим:
Y = 265300 +299,7 X 2
Пример
• Итак доход предприятия зависит одновременно от двух факторов производства – числа рабочих и энерговооруженности, однако эти факторы сами не являются независимыми друг от друга.
• Поэтому совокупная зависимость дохода от рабочих и мощности двигателей не есть простая сумма двух парных зависимостей.
• Следовательно, неверно , что суммарное влияние обоих факторов можно записать в виде суммы двух предыдущих уравнений:
Y = 3529 10 + 2 984 X 1 + 299,7 X 2
Уравнение множественной линейной регрессии
Y = a + b 1 X 1 + b 2 X 2 +…+ b k X k
X 1 , X 2 , … , X k независимые переменные (факторы);
b 1 , b 2 , … , b k соответствующие им коэффициенты регрессии
Значимость регрессионной модели
• Если коэффициент множественной корреляции вычислен на основе выборочных данных, то возможно, что его значение не отражает реальной связи между признаками, а получено в данной выборке случайно (при этом в генеральной совокупности признаки независимы).
Значимость регрессионной модели
• В основе проверки значимости регрессии лежит идея разложения дисперсии (разброса) результативного признака на факторную и остаточную дисперсии, т.е. объясненную (за счет независимых факторов) часть дисперсии и часть, оставшуюся необъясненной в рамках данной модели.
Значимость регрессионной модели
• Мерой значимости регрессии служит значение т.н. F- критерия – отношения факторной дисперсии к остаточной .
• Чем лучше регрессионная модель, тем выше доля факторной и ниже доля остаточной дисперсии.
Значимость регрессионной модели
• Для каждого значения F можно вычислить соответствующую вероятность. Если значение этой вероятности меньше принятого уровня значимости p или вероятности ошибки (в программе Statistica это 5% или 0,05), гипотеза об отсутствии линейной связи между результативным и факторными признаками отклоняется и регрессия признается значимой .
http://economy-ru.info/info/15180/
http://megaobuchalka.ru/6/26247.html