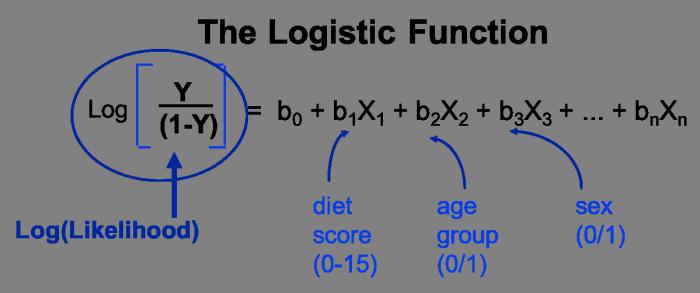
Что является переменными в уравнении множественной регрессии
Вид множественной линейной модели регрессионного анализа: Y = b0 + b1xi1 + . + bjxij + . + bkxik + ei где ei — случайные ошибки наблюдения, независимые между собой, имеют нулевую среднюю и дисперсию s.
Назначение множественной регрессии : анализ связи между несколькими независимыми переменными и зависимой переменной.
Экономический смысл параметров множественной регрессии
Коэффициент множественной регрессии bj показывает, на какую величину в среднем изменится результативный признак Y, если переменную Xj увеличить на единицу измерения, т. е. является нормативным коэффициентом.
Матричная запись множественной линейной модели регрессионного анализа: Y = Xb + e где Y — случайный вектор — столбец размерности (n x 1) наблюдаемых значений результативного признака (y1, y2. yn);
X — матрица размерности [n x (k+1)] наблюдаемых значений аргументов;
b — вектор — столбец размерности [(k+1) x 1] неизвестных, подлежащих оценке параметров (коэффициентов регрессии) модели;
e — случайный вектор — столбец размерности (n x 1) ошибок наблюдений (остатков).
На практике рекомендуется, чтобы n превышало k не менее, чем в три раза.
Задачи регрессионного анализа
Основная задача регрессионного анализа заключается в нахождении по выборке объемом n оценки неизвестных коэффициентов регрессии b0, b1. bk. Задачи регрессионного анализа состоят в том, чтобы по имеющимся статистическим данным для переменных Xi и Y:
- получить наилучшие оценки неизвестных параметров b0, b1. bk;
- проверить статистические гипотезы о параметрах модели;
- проверить, достаточно ли хорошо модель согласуется со статистическими данными (адекватность модели данным наблюдений).
Построение моделей множественной регрессии состоит из следующих этапов:
- выбор формы связи (уравнения регрессии);
- определение параметров выбранного уравнения;
- анализ качества уравнения и поверка адекватности уравнения эмпирическим данным, совершенствование уравнения.
Множественная регрессия:
- Множественная регрессия с одной переменной
- Множественная регрессия с двумя переменными
- Множественная регрессия с тремя переменными
Пример решения нахождения модели множественной регрессии
Модель множественной регрессии вида Y = b 0 +b 1 X 1 + b 2 X 2 ;
1) Найтинеизвестные b 0 , b 1 ,b 2 можно, решим систему трехлинейных уравнений с тремя неизвестными b 0 ,b 1 ,b 2 : 
Для решения системы можете воспользоваться решение системы методом Крамера
2) Или использовав формулы
Для этого строим таблицу вида:
| Y | x 1 | x 2 | (y-y ср ) 2 | (x 1 -x 1ср ) 2 | (x 2 -x 2ср ) 2 | (y-y ср )(x 1 -x 1ср ) | (y-y ср )(x 2 -x 2ср ) | (x 1 -x 1ср )(x 2 -x 2ср ) |
Выборочные дисперсии эмпирических коэффициентов множественной регрессии можно определить следующим образом: 
Здесь z’ jj — j-тый диагональный элемент матрицы Z -1 =(X T X) -1 .

Приэтом:

где m — количество объясняющихпеременных модели.
В частности, для уравнения множественной регрессии Y = b 0 + b 1 X 1 + b 2 X 2 с двумя объясняющими переменными используются следующие формулы:

Или 

или 
 ,
, ,
, .
.
Здесьr 12 — выборочный коэффициент корреляции между объясняющимипеременными X 1 и X 2 ; Sb j — стандартная ошибкакоэффициента регрессии; S — стандартная ошибка множественной регрессии (несмещенная оценка).
По аналогии с парной регрессией после определения точечных оценокb j коэффициентов β j (j=1,2,…,m) теоретического уравнения множественной регрессии могут быть рассчитаны интервальные оценки указанных коэффициентов.
Доверительный интервал, накрывающий с надежностью (1- α ) неизвестное значение параметра β j, определяется как 
Уравнение регрессии. Уравнение множественной регрессии
Во время учебы студенты очень часто сталкиваются с разнообразными уравнениями. Одно из них – уравнение регрессии — рассмотрено в данной статье. Такой тип уравнения применяется специально для описания характеристики связи между математическими параметрами. Данный вид равенств используют в статистике и эконометрике.
Определение понятия регрессии
В математике под регрессией подразумевается некая величина, описывающая зависимость среднего значения совокупности данных от значений другой величины. Уравнение регрессии показывает в качестве функции определенного признака среднее значение другого признака. Функция регрессии имеет вид простого уравнения у = х, в котором у выступает зависимой переменной, а х – независимой (признак-фактор). Фактически регрессия выражаться как у = f (x).
Какие бывают типы связей между переменными
В общем, выделяется два противоположных типа взаимосвязи: корреляционная и регрессионная.
Первая характеризуется равноправностью условных переменных. В данном случае достоверно не известно, какая переменная зависит от другой.
Если же между переменными не наблюдается равноправности и в условиях сказано, какая переменная объясняющая, а какая – зависимая, то можно говорить о наличии связи второго типа. Для того чтобы построить уравнение линейной регрессии, необходимо будет выяснить, какой тип связи наблюдается.
Виды регрессий
На сегодняшний день выделяют 7 разнообразных видов регрессии: гиперболическая, линейная, множественная, нелинейная, парная, обратная, логарифмически линейная.
Гиперболическая, линейная и логарифмическая
Уравнение линейной регрессии применяют в статистике для четкого объяснения параметров уравнения. Оно выглядит как у = с+т*х+Е. Гиперболическое уравнение имеет вид правильной гиперболы у = с + т / х + Е. Логарифмически линейное уравнение выражает взаимосвязь с помощью логарифмической функции: In у = In с + т* In x + In E.
Множественная и нелинейная
Два более сложных вида регрессии – это множественная и нелинейная. Уравнение множественной регрессии выражается функцией у = f(х1 , х2 . хс)+E. В данной ситуации у выступает зависимой переменной, а х – объясняющей. Переменная Е — стохастическая, она включает влияние других факторов в уравнении. Нелинейное уравнение регрессии немного противоречиво. С одной стороны, относительно учтенных показателей оно не линейное, а с другой стороны, в роли оценки показателей оно линейное.
Обратные и парные виды регрессий
Обратная – это такой вид функции, который необходимо преобразовать в линейный вид. В самых традиционных прикладных программах она имеет вид функции у = 1/с + т*х+Е. Парное уравнение регрессии демонстрирует взаимосвязь между данными в качестве функции у = f (x) + Е. Точно так же, как и в других уравнениях, у зависит от х, а Е — стохастический параметр.
Понятие корреляции
Это показатель, демонстрирующий существование взаимосвязи двух явлений или процессов. Сила взаимосвязи выражается в качестве коэффициента корреляции. Его значение колеблется в рамках интервала [-1;+1]. Отрицательный показатель говорит о наличии обратной связи, положительный – о прямой. Если коэффициент принимает значение, равное 0, то взаимосвязи нет. Чем ближе значение к 1 – тем сильнее связь между параметрами, чем ближе к 0 – тем слабее.
Методы
Корреляционные параметрические методы могут оценить тесноту взаимосвязи. Их используют на базе оценки распределения для изучения параметров, подчиняющихся закону нормального распределения.
Параметры уравнения линейной регрессии необходимы для идентификации вида зависимости, функции регрессионного уравнения и оценивания показателей избранной формулы взаимосвязи. В качестве метода идентификации связи используется поле корреляции. Для этого все существующие данные необходимо изобразить графически. В прямоугольной двухмерной системе координат необходимо нанести все известные данные. Так образуется поле корреляции. Значение описывающего фактора отмечаются вдоль оси абсцисс, в то время как значения зависимого – вдоль оси ординат. Если между параметрами есть функциональная зависимость, они выстраиваются в форме линии.
В случае если коэффициент корреляции таких данных будет менее 30 %, можно говорить о практически полном отсутствии связи. Если он находится между 30 % и 70 %, то это говорит о наличии связей средней тесноты. 100 % показатель – свидетельство функциональной связи.
Нелинейное уравнение регрессии так же, как и линейное, необходимо дополнять индексом корреляции (R).
Корреляция для множественной регрессии
Коэффициент детерминации является показателем квадрата множественной корреляции. Он говорит о тесноте взаимосвязи представленного комплекса показателей с исследуемым признаком. Он также может говорить о характере влияния параметров на результат. Уравнение множественной регрессии оценивают с помощью этого показателя.
Для того чтобы вычислить показатель множественной корреляции, необходимо рассчитать его индекс.
Метод наименьших квадратов
Данный метод является способом оценивания факторов регрессии. Его суть заключается в минимизировании суммы отклонений в квадрате, полученных вследствие зависимости фактора от функции.
Парное линейное уравнение регрессии можно оценить с помощью такого метода. Этот тип уравнений используют в случае обнаружения между показателями парной линейной зависимости.
Параметры уравнений
Каждый параметр функции линейной регрессии несет определенный смысл. Парное линейное уравнение регрессии содержит два параметра: с и т. Параметр т демонстрирует среднее изменение конечного показателя функции у, при условии уменьшения (увеличения) переменной х на одну условную единицу. Если переменная х – нулевая, то функция равняется параметру с. Если же переменная х не нулевая, то фактор с не несет в себе экономический смысл. Единственное влияние на функцию оказывает знак перед фактором с. Если там минус, то можно сказать о замедленном изменении результата по сравнению с фактором. Если там плюс, то это свидетельствует об ускоренном изменении результата.
Каждый параметр, изменяющий значение уравнения регрессии, можно выразить через уравнение. Например, фактор с имеет вид с = y – тх.
Сгруппированные данные
Бывают такие условия задачи, в которых вся информация группируется по признаку x, но при этом для определенной группы указываются соответствующие средние значения зависимого показателя. В таком случае средние значения характеризуют, каким образом изменяется показатель, зависящий от х. Таким образом, сгруппированная информация помогает найти уравнение регрессии. Ее используют в качестве анализа взаимосвязей. Однако у такого метода есть свои недостатки. К сожалению, средние показатели достаточно часто подвергаются внешним колебаниям. Данные колебания не являются отображением закономерности взаимосвязи, они всего лишь маскируют ее «шум». Средние показатели демонстрируют закономерности взаимосвязи намного хуже, чем уравнение линейной регрессии. Однако их можно применять в виде базы для поиска уравнения. Перемножая численность отдельной совокупности на соответствующую среднюю можно получить сумму у в пределах группы. Далее необходимо подбить все полученные суммы и найти конечный показатель у. Чуть сложнее производить расчеты с показателем суммы ху. В том случае если интервалы малы, можно условно взять показатель х для всех единиц (в пределах группы) одинаковым. Следует перемножить его с суммой у, чтобы узнать сумму произведений x на у. Далее все суммы подбиваются вместе и получается общая сумма ху.
Множественное парное уравнение регрессии: оценка важности связи
Как рассматривалось ранее, множественная регрессия имеет функцию вида у = f (x1,x2,…,xm)+E. Чаще всего такое уравнение используют для решения проблемы спроса и предложения на товар, процентного дохода по выкупленным акциям, изучения причин и вида функции издержек производства. Ее также активно применяют в самых разнообразным макроэкономических исследованиях и расчетах, а вот на уровне микроэкономики такое уравнение применяют немного реже.
Основной задачей множественной регрессии является построение модели данных, содержащих огромное количество информации, для того чтобы в дальнейшем определить, какое влияние имеет каждый из факторов по отдельности и в их общей совокупности на показатель, который необходимо смоделировать, и его коэффициенты. Уравнение регрессии может принимать самые разнообразные значения. При этом для оценки взаимосвязи обычно используется два типа функций: линейная и нелинейная.
Линейная функция изображается в форме такой взаимосвязи: у = а0 + a1х1 + а2х2,+ . + amxm. При этом а2, am, считаются коэффициентами «чистой» регрессии. Они необходимы для характеристики среднего изменения параметра у с изменением (уменьшением или увеличением) каждого соответствующего параметра х на одну единицу, с условием стабильного значения других показателей.
Нелинейные уравнения имеют, к примеру, вид степенной функции у=ах1 b1 х2 b2 . xm bm . В данном случае показатели b1, b2. bm – называются коэффициентами эластичности, они демонстрируют, каким образом изменится результат (на сколько %) при увеличении (уменьшении) соответствующего показателя х на 1 % и при стабильном показателе остальных факторов.
Какие факторы необходимо учитывать при построении множественной регрессии
Для того чтобы правильно построить множественную регрессию, необходимо выяснить, на какие именно факторы следует обратить особое внимание.
Необходимо иметь определенное понимание природы взаимосвязей между экономическими факторами и моделируемым. Факторы, которые необходимо будет включать, обязаны отвечать следующим признакам:
- Должны быть подвластны количественному измерению. Для того чтобы использовать фактор, описывающий качество предмета, в любом случае следует придать ему количественную форму.
- Не должна присутствовать интеркорреляция факторов, или функциональная взаимосвязь. Такие действия чаще всего приводят к необратимым последствиям – система обыкновенных уравнений становится не обусловленной, а это влечет за собой ее ненадежность и нечеткость оценок.
- В случае существования огромного показателя корреляции не существует способа для выяснения изолированного влияния факторов на окончательный результат показателя, следовательно, коэффициенты становятся неинтерпретируемыми.
Методы построения
Существует огромное количество методов и способов, объясняющих, каким образом можно выбрать факторы для уравнения. Однако все эти методы строятся на отборе коэффициентов с помощью показателя корреляции. Среди них выделяют:
- Способ исключения.
- Способ включения.
- Пошаговый анализ регрессии.
Первый метод подразумевает отсев всех коэффициентов из совокупного набора. Второй метод включает введение множества дополнительных факторов. Ну а третий – отсев факторов, которые были ранее применены для уравнения. Каждый из этих методов имеет право на существование. У них есть свои плюсы и минусы, но они все по-своему могут решить вопрос отсева ненужных показателей. Как правило, результаты, полученные каждым отдельным методом, достаточно близки.
Методы многомерного анализа
Такие способы определения факторов базируются на рассмотрении отдельных сочетаний взаимосвязанных признаков. Они включают в себя дискриминантный анализ, распознание обликов, способ главных компонент и анализ кластеров. Кроме того, существует также факторный анализ, однако он появился вследствие развития способа компонент. Все они применяются в определенных обстоятельствах, при наличии определенных условий и факторов.
Введение в множественную регрессию
Рассматривая простую регрессию, мы сосредоточили внимание на модели, в которой для предсказания значения зависимой переменной, или отклика Y, использовалась лишь одна независимая, или объясняющая, переменная X. Однако во многих случаях можно разработать более точную модель, если учесть не одну, а несколько объясняющих переменных. По этой причине мы рассмотрим в этой заметке модели множественной регрессии, в которых для предсказания значения зависимой переменной используется несколько независимых переменных. [1]
Материал будет проиллюстрирован сквозным примером: прогнозирование объемов продаж компании OmniPower. Представьте себе, что вы — менеджер по маркетингу в крупной национальной сети бакалейных магазинов. В последние годы на рынке появились питательные батончики, содержащие большое количество жиров, углеводов и калорий. Они позволяют быстро восстановить запасы энергии, потраченной бегунами, альпинистами и другими спортсменами на изнурительных тренировках и соревнованиях. За последние годы объем продаж питательных батончиков резко вырос, и руководство компании OmniPower пришло к выводу, что этот сегмент рынка весьма перспективен. Прежде чем предлагать новый вид батончика на общенациональном рынке, компания хотела бы оценить влияние его стоимости и рекламных затрат на объем продаж. Для маркетингового исследования были отобраны 34 магазина. Вам необходимо создать регрессионную модель, позволяющую проанализировать данные, полученные в ходе исследования. Можно ли применить для этого модель простой линейной регрессии, рассмотренную в предыдущей заметке? Как ее следует изменить?
Модель множественной регрессии
Для маркетингового исследования в компании OmniPower была создана выборка, состоящая из 34 магазинов с приблизительно одинаковыми объемами продаж. Рассмотрим две независимые переменные — цена батончика OmniPower в центах (Х1) и месячный бюджет рекламной кампании, проводимой в магазине, выраженный в долларах (Х2). В этот бюджет входят расходы на оформление вывесок и витрин, а также на раздачу купонов и бесплатных образцов. Зависимая переменная Y представляет собой количество батончиков OmniPower, проданных за месяц (рис. 1).

Рис. 1. Месячный объем продажа батончиков OmniPower, их цена и расходы на рекламу
Скачать заметку в формате Word или pdf, примеры в формате Excel2013
Интерпретация регрессионных коэффициентов. Если в задаче исследуются несколько объясняющих переменных, модель простой линейной регрессии можно расширить, предполагая, что между откликом и каждой из независимых переменных существует линейная зависимость. Например, при наличии k объясняющих переменных модель множественной линейной регрессии принимает вид:
где β0 — сдвиг, β1 — наклон прямой Y, зависящей от переменной Х1, если переменные Х2, Х3, … , Хk являются константами, β2 — наклон прямой Y, зависящей от переменной Х2, если переменные Х1, Х3, … , Хk являются константами, βk — наклон прямой Y, зависящей от переменной Хk, если переменные Х1, Х2, … , Хk-1 являются константами, εi — случайная ошибка переменной Y в i-м наблюдении.
В частности, модель множественной регрессии с двумя объясняющими переменными:
где β0 — сдвиг, β1 — наклон прямой Y, зависящей от переменной Х1, если переменная Х2 является константой, β2 — наклон прямой Y, зависящей от переменной Х2, если переменная Х1 является константой, εi — случайная ошибка переменной Y в i-м наблюдении.
Сравним эту модель множественной линейной регрессии и модель простой линейной регрессии: Yi = β0 + β1Xi + εi. В модели простой линейной регрессии наклон β1 представляет собой изменение среднего значения переменной Y при изменении значения переменной X на единицу и не учитывает влияние других факторов. В модели множественной регрессии с двумя независимыми переменными (2) наклон β1 представляет собой изменение среднего значения переменной Y при изменении значения переменной X1 на единицу с учетом влияния переменной Х2. Эта величина называется коэффициентом чистой регрессии (или частной регрессии).
Как и в модели простой линейной регрессии, выборочные регрессионные коэффициенты b0, b1, и b2 представляют собой оценки параметров соответствующей генеральной совокупности β0, β1 и β2.
Уравнение множественной регрессии с двумя независимыми переменными:
(3)  = b0 + b1X1i + b2X2i
= b0 + b1X1i + b2X2i
Для вычисления коэффициентов регрессии используется метод наименьших квадратов. В Excel можно воспользоваться Пакетом анализа, опцией Регрессия. В отличие от построения линейной регрессии, просто задайте в качестве Входного интервала Х область, включающую все независимые переменные (рис. 2). В нашем примере это $C$1:$D$35.

Рис. 2. Окно Регрессия Пакета анализа Excel
Результаты работы Пакета анализа представлены на рис. 3. Как видим, b0 = 5 837,52, b1 = –53,217 и b2 = 3,163. Следовательно, = 5 837,52 –53,217X1i + 3,163X2i , где Ŷi — предсказанный объем продаж питательных батончиков OmniPower в i-м магазине (штук), Х1i — цена батончика (в центах) в i-м магазине, Х2i — ежемесячные затраты на рекламу в i-м магазине (в долларах).

Рис. 3. Множественная регрессия исследования объем продажа батончиков OmniPower
Выборочный наклон b0 равен 5 837,52 и является оценкой среднего количества батончиков OmniPower, проданных за месяц при нулевой цене и отсутствии затрат на рекламу. Поскольку эти условия лишены смысла, в данной ситуации величина наклона b0 не имеет разумной интерпретации.
Выборочный наклон b1 равен –53,217. Это значит, что при заданном ежемесячном объеме затрат на рекламу увеличение цены батончика на один цент приведет к снижению ожидаемого объема продаж на 53,217 штук. Аналогично выборочный наклон b2, равный 3,613, означает, что при фиксированной цене увеличение ежемесячных рекламных затрат на один доллар сопровождается увеличением ожидаемого объема продаж батончиков на 3,613 шт. Эти оценки позволяют лучше понять влияние цены и рекламы на объем продаж. Например, при фиксированном объеме затрат на рекламу уменьшение цены батончика на 10 центов увеличит объем продаж на 532,173 шт., а при фиксированной цене батончика увеличение рекламных затрат на 100 долл. увеличит объем продаж на 361,31 шт.
Интерпретация наклонов в модели множественной регрессии. Коэффициенты в модели множественной регрессии называются коэффициентами чистой регрессии. Они оценивают среднее изменение отклика Y при изменении величины X на единицу, если все остальные объясняющие переменные «заморожены». Например, в задаче о батончиках OmniPower магазин с фиксированным объемом рекламных затрат за месяц продаст на 53,217 батончика меньше, если увеличит их стоимость на один цент. Возможна еще одна интерпретация этих коэффициентов. Представьте себе одинаковые магазины с одинаковым объемом затрат на рекламу. При уменьшении цены батончика на один цент объем продаж в этих магазинах увеличится на 53,217 батончика. Рассмотрим теперь два магазина, в которых батончики стоят одинаково, но затраты на рекламу отличаются. При увеличении этих затрат на один доллар объем продаж в этих магазинах увеличится на 3,613 штук. Как видим, разумная интерпретация наклонов возможна лишь при определенных ограничениях, наложенных на объясняющие переменные.
Предсказание значений зависимой переменной Y. Выяснив, что накопленные данные позволяют использовать модель множественной регрессии, мы можем прогнозировать ежемесячный объем продаж батончиков OmniPower и построить доверительные интервалы для среднего и предсказанного объемов продаж. Для того чтобы предсказать средний ежемесячный объем продаж батончиков OmniPower по цене 79 центов в магазине, расходующем на рекламу 400 долл. в месяц, следует применить уравнение множественной регрессии: Y = 5 837,53 – 53,2173*79 + 3,6131*400 = 3 079. Следовательно, ожидаемый объем продаж в магазинах, торгующих батончиками OmniPower по цене 79 центов и расходующих на рекламу 400 долл. в месяц, равен 3 079 шт.
Вычислив величину Y и оценив остатки, можно построить доверительные интервалы, содержащие математическое ожидание и предсказанное значение отклика. Ранее мы рассмотрели эту процедуру в рамках модели простой линейной регрессии. Однако построение аналогичных оценок для модели множественной регрессии сопряжено с большими вычислительными трудностями и здесь не приводится.
Коэффициент множественной смешанной корреляции. Напомним, что модель регрессии позволяет вычислить коэффициент смешанной корреляции r 2 . Поскольку в модели множественной регрессии существуют по крайней мере две объясняющие переменные, коэффициент множественной смешанной корреляции представляет собой долю вариации переменной Y, объясняемой заданным набором объясняющих переменных:

где SSR – сумма квадратов регрессии, SST – полная сумма квадратов.
Например, в задаче о продажах батончика OmniPower SSR = 39 472 731, SST = 52 093 677 и k = 2. Таким образом,

Это означает, что 75,8% вариации объемов продаж объясняется изменениями цен и колебаниями объемов затрат на рекламу.
Анализ остатков для модели множественной регрессии
Анализ остатков позволяет определить, можно ли применять модель множественной регрессии с двумя (или более) объясняющими переменными. Как правило, проводят следующие виды анализа остатков:
- Распределение остатков по
 (рис. 4).
(рис. 4). - Распределение остатков по Х1i (рис. 5).
- Распределение остатков по Х2i (рис. 5).
- Распределение остатков по времени.
Первый график (рис. 4а) позволяет проанализировать распределение остатков в зависимости от предсказанных значений . Если величина остатков не зависит от предсказанных значений и принимает как положительные так и отрицательные значения (как в нашем пример), условие линейной зависимости переменной Y от обеих объясняющих переменных выполняется. К сожалению, в Пакете анализа этот график почему-то не создается. Можно в окне Регрессия (см. рис. 2) включить Остатки. Это позволит вывести таблицу с остатками, а уже по ней построить точечный график (рис. 4).

Рис. 4. Зависимость остатков от предсказанного значения
Второй и третий график демонстрируют зависимость остатков от объясняющих переменных. Эти графики могут выявить квадратичный эффект. В этой ситуации необходимо добавить в модель множественной регрессии квадрат объясняющей переменной. Эти графики выводятся Пакетом анализа (см. рис. 2), если включить опцию График остатков (рис. 5).

Рис. 5. Зависимость остатков от цены и затрат на рекламу
Четвертый график применяется для проверки независимости данных, собранных в течение определенного времени. Для этого надо наблюдения расположить по времени, и построить зависимость предсказанного значения от времени. Поскольку в примере с OmniPower все измерения делались одновременно, такой график не применим. Для выявления положительной автокорреляции между остатками можно вычислить статистику Дурбина-Уотсона (подробнее см. соответствующий раздел заметки Простая линейная регрессия).
Проверка значимости модели множественной регрессии.
Убедившись с помощью анализа остатков, что модель линейной множественной регрессии является адекватной, можно определить, существует ли статистически значимая взаимосвязь между зависимой переменной и набором объясняющих переменных. Поскольку в модель входит несколько объясняющих переменных, нулевая и альтернативная гипотезы формулируются следующим образом: Н0: β1 = β2 = … = βk = 0 (между откликом и объясняющими переменными нет линейной зависимости), Н1: существует по крайней мере одно значение βj ≠ 0 (мжду откликом и хотя бы одной объясняющей переменной существует линейная зависимость).
Для проверки нулевой гипотезы применяется F-критерий – тестовая F-статистика равна среднему квадрату, обусловленному регрессией (MSR), деленному на дисперсию ошибок (MSE):

где F – тестовая статистика, имеющая F-распределение с k и n – k – 1 степенями свободы, k – количество независимых переменных в регрессионной модели.
Решающее правило выглядит следующим образом: при уровне значимости α нулевая гипотеза Н0 отклоняется, если F > FU(k,n – k – 1), в противном случае гипотеза Н0 не отклоняется (рис. 6).

Рис. 6. Сводная таблица дисперсионного анализа для проверки гипотезы о статистической значимости коэффициентов множественной регрессии
Сводная таблица дисперсионного анализа, заполненная с использованием Пакета анализа Excel при решении задачи о продажах батончиков OmniPower, показана на рис. 3 (см. область А10:F14). Если уровень значимости равен 0,05, критическое значение F-распределения с двумя и 31 степенями свободы FU(2,31) = F.ОБР(1-0,05;2;31) = равно 3,305 (рис. 7).

Рис. 7. Проверка гипотезы о значимости коэффициентов регрессии при уровне значимости α = 0,05, с 2 и 31 степенями свободы
Как показано на рис. 3, F-статистика равна 48,477 > FU(2,31) = 3,305, а p-значение близко к 0,000 2,0395 или р = 0,0000 4,17), гипотеза Н0 отклоняется, следовательно, учет переменной Х1 (цены) значительно улучшает модель регрессии, в которую уже включена переменная Х2 (затраты на рекламу).
Аналогично можно оценить влияние переменной Х2 (затраты на рекламу) на модель, в которую уже включена переменная Х1 (цена). Проведите вычисления самостоятельно. Решающее условие приводит к тому, что 27,8 > 4,17, и следовательно, включение переменной Х2 также приводит к значительному увеличению точности модели, в которой учитывается переменная Х1. Итак, включение каждой из переменных повышает точность модели. Следовательно, в модель множественной регрессии необходимо включить обе переменные: и цену, и затраты на рекламу.
Любопытно, что значение t-статистики, вычисленное по формуле (6), и значение частной F-статистики, заданной формулой (9), однозначно взаимосвязаны:

где а — количество степеней свободы.
Регрессионные модели с фиктивной переменной и эффекты взаимодействия
Обсуждая модели множественной регрессии, мы предполагали, что каждая независимая переменная является числовой. Однако во многих ситуациях в модель необходимо включать категорийные переменные. Например, в задаче о продажах батончиков OmniPower для предсказания среднемесячного объема продаж использовались цена и затраты на рекламу. Кроме этих числовых переменных, можно попытаться учесть в модели расположение товара внутри магазина (например, на витрине или нет). Для того чтобы учесть в регрессионной модели категорийные переменные, следует включить в нее фиктивные переменные. Например, если некая категорийная объясняющая переменная имеет две категории, для их представления достаточно одной фиктивной переменной Xd: Xd = 0, если наблюдение принадлежит первой категории, Xd = 1, если наблюдение принадлежит второй категории.
Для иллюстрации фиктивных переменных рассмотрим модель для предсказания средней оценочной стоимости недвижимости на основе выборки, состоящей из 15 домов. В качестве объясняющих переменных выберем жилую площадь дома (тыс. кв. футов) и наличие камина (рис. 11). Фиктивная переменная Х2 (наличие камина) определена следующим образом: Х2 = 0, если камина в доме нет, Х2 = 1, если в доме есть камин.

Рис. 11. Оценочная стоимость, предсказанная по жилой площади и наличию камина
Предположим, что наклон оценочной стоимости, зависящей от жилой площади, одинаков у домов, имеющих камин и не имеющих его. Тогда модель множественной регрессии выглядит следующим образом:
где Yi — оценочная стоимость i-гo дома, измеренная в тысячах долларов, β0 — сдвиг отклика, X1i,— жилая площадь i-гo дома, измеренная в тыс. кв. футов, β1 — наклон оценочной стоимости, зависящей от жилой площади дома при постоянном значении фиктивной переменной, X1i,— фиктивная переменная, означающая наличие или отсутствие камина, β1 — наклон оценочной стоимости, зависящей от жилой площади дома при постоянном значении фиктивной переменной β2 — эффект увеличения оценочной стоимости дома в зависимости от наличия камина при постоянной величине жилой площади, εi – случайная ошибка оценочной стоимости i-гo дома. Результаты вычисления регрессионой модели представлены на рис. 12.

Рис. 12. Результаты вычисления регрессионой модели для оценочной стоимости домов; получены с помощью Пакета анализа в Excel; для расчета использована таблица, аналогичная рис. 11, с единственным изменением: «Да» заменены единицами, а «Нет» – нулями

В этой модели коэффициенты регрессии интерпретируются следующим образом:
- Если фиктивная переменная имеет постоянное значение, увеличение жилой площади на 1000 кв. футов приводит к увеличению предсказанной средней оценочной стоимости на 16,2 тыс. долл.
- Если жилая площадь постоянна, наличие камина увеличивает среднюю оценочную стоимость дома на 3,9 тыс. долл.
Обратите внимание (рис. 12), t-статистика, соответствующая жилой площади, равна 6,29, а р-значение почти равно нулю. В то же время t-статистика, соответствующая фиктивной переменной, равна 3,1, а p-значение – 0,009. Таким образом, каждая из этих двух переменных вносит существенный вклад в модель, если уровень значимости равен 0,01. Кроме того, коэффициент множественной смешанной корреляции означает, что 81,1% вариации оценочной стоимости объясняется изменчивостью жилой площади дома и наличием камина.
Эффект взаимодействия. Во всех регрессионных моделях, рассмотренных выше, считалось, что влияние отклика на объясняющую переменную является статистически независимым от влияния отклика на другие объясняющие переменные. Если это условие не выполняется, возникает взаимодействие между зависимыми переменными. Например, вполне вероятно, что реклама оказывает большое влияние на объем продаж товаров, имеющих низкую цену. Однако, если цена товара слишком высока, увеличение расходов на рекламу не может существенно повысить объем продаж. В этом случае наблюдается взаимодействие между ценой товара и затратами на его рекламу. Иначе говоря, нельзя делать общих утверждений о зависимости объема продаж от затрат на рекламу. Влияние рекламных расходов на объем продаж зависит от цены. Это влияние учитывается в модели множественной регрессии с помощью эффекта взаимодействия. Для иллюстрации этого понятия вернемся к задаче о стоимости домов.
В разработанной нами регрессионной модели предполагалось, что влияние размера дома на его стоимость не зависит от того, есть ли в доме камин. Иначе говоря, считалось, что наклон оценочной стоимости, зависящей от жилой площади дома, одинаков у домов, имеющих камин и не имеющих его. Если эти наклоны отличаются друг от друга, между размером дома и наличием камина существует взаимодействие.
Проверка гипотезы о равенстве наклонов сводится к оценке вклада, который вносит в модель регрессии произведение объясняющей переменной X1 и фиктивной переменной Х2. Если этот вклад является статистически значимым, исходную модель регрессии применять нельзя. Результаты регрессионного анализа, включающего переменные Х1, Х2 и Х3 = Х1*Х2 приведены на рис. 13.

Рис. 13. Результаты, полученные с помощью Пакета анализа Excel для регрессионной модели, учитывающей жилую площадь, наличие камина и их взаимодействие
Для того чтобы проверить нулевую гипотезу Н0: β3 = 0 и альтернативную гипотезу Н1: β3 ≠ 0, используя результаты, приведенные на рис. 13, обратим внимание на то, что t-статистика, соответствующая эффекту взаимодействия переменных, равна 1,48. Поскольку р-значение равно 0,166 > 0,05, нулевая гипотеза не отклоняется. Следовательно, взаимодействие переменных не имеет существенного влияния на модель регрессии, учитывающую жилую площадь и наличие камина.
Резюме. В заметке показано, как менеджер по маркетингу может применять множественный линейный анализ для предсказания объема продаж, зависящего от цены и затрат на рекламу. Рассмотрены различные модели множественной регрессии, включая квадратичные модели, модели с фиктивными переменными и модели с эффектами взаимодействия (рис. 14).
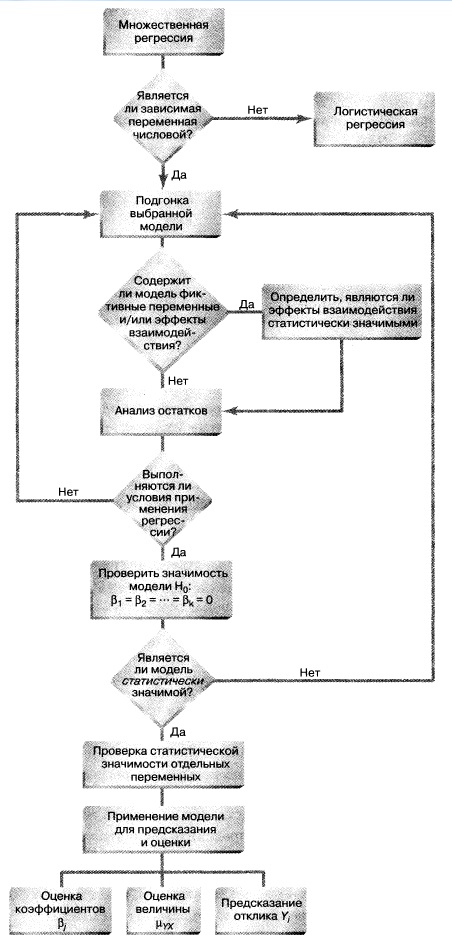
Рис. 14. Структурная схема заметки
[1] Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 873–936
http://www.syl.ru/article/178055/new_uravnenie-regressii-uravnenie-mnojestvennoy-regressii
http://baguzin.ru/wp/vvedenie-v-mnozhestvennuyu-regressiyu/