Парная линейная регрессия. Задачи регрессионного анализа
Будут и задачи для самостоятельного решения, к которым можно посмотреть ответы.
Понятие линейной регрессии. Парная линейная регрессия
Линейная регрессия — выраженная в виде прямой зависимость среднего значения какой-либо величины от некоторой другой величины. В отличие от функциональной зависимости y = f(x) , когда каждому значению независимой переменной x соответствует одно определённое значение величины y, при линейной регрессии одному и тому же значению x могут соответствовать в зависимости от случая различные значения величины y.
Если в результате наблюдения установлено, что при каждом определённом значении x существует сколько-то (n) значений переменной y, то зависимость средних арифметических значений y от x и является регрессией в статистическом понимании.
Если установленная зависимость может быть записана в виде уравнения прямой
то эта регрессионная зависимость называется линейной регрессией.
О парной линейной регрессии говорят, когда установлена зависимость между двумя переменными величинами (x и y). Парная линейная регрессия называется также однофакторной линейной регрессией, так как один фактор (независимая переменная x) влияет на результирующую переменную (зависимую переменную y).
В уроке о корреляционной зависимости были разобраны примеры того, как цена на квартиры зависит от общей площади квартиры и от площади кухни (две различные независимые переменные) и о том, что результаты наблюдений расположены в некотором приближении к прямой, хотя и не на самой прямой. Если точки корреляционной диаграммы соединить ломанной линией, то будет получена линия эмпирической регрессии. А если эта линия будет выровнена в прямую, то полученная прямая будет прямой теоретической регрессии. На рисунке ниже она красного цвета (для увеличения рисунка щёлкнуть по нему левой кнопкой мыши).

По этой прямой теоретической регрессии может быть сделан прогноз или восстановление неизвестных значений зависимой переменной по заданным значениям независимой переменной.
В случае парной линейной регрессии для данных генеральной совокупности связь между независимой переменной (факториальным признаком) X и зависимой переменной (результативным признаком) Y описывает модель
 ,
,
 — свободный член прямой парной линейной регрессии,
— свободный член прямой парной линейной регрессии,
 — коэффициент направления прямой парной линейной регрессии,
— коэффициент направления прямой парной линейной регрессии,
 — случайная погрешность,
— случайная погрешность,
N — число элементов генеральной совокупности.
Уравнение парной линейной регрессии для генеральной совокупности можно построить, если доступны данные обо всех элементах генеральной совокупности. На практике данные всей генеральной совокупности недоступны, но доступны данные об элементах некоторой выборки.
Поэтому параметры генеральной совокупности оценивают при помощи соответствующих параметров соответствующей выборки: свободный член прямой парной линейной регрессии генеральной совокупности заменяют на свободный член прямой парной линейной регрессии выборки  , а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки
, а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки  .
.
В результате получаем уравнение парной линейной регрессии выборки


 — оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
— оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
 — погрешность,
— погрешность,
n — размер выборки.
Чтобы уравнение парной линейной регрессии было более похоже на привычное уравнение прямой, его часто также записывают в виде
 .
.
Уравнение парной линейной регрессии и метод наименьших квадратов
Определение коэффициентов уравнения парной линейной регрессии
Если заранее известно, что зависимость между факториальным признаком x и результативным признаком y должна быть линейной, выражающейся в виде уравнения типа , задача сводится к нахождению по некоторой группе точек наилучшей прямой, называемой прямой парной линейной регрессии. Следует найти такие значения коэффициентов a и b , чтобы сумма квадратов отклонений  была наименьшей:
была наименьшей:
 .
.
Если через  и
и  обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
- прямая парной линейной регрессии проходит через точку
 ;
; - среднее значение отклонений равна нулю: ;
- значения и не связаны: .
 ;
; ;
; и
и  не связаны:
не связаны:  .
.Условие метода наименьших квадратов выполняется, если значения коэффициентов равны:
 ,
,
 .
.
Пример 1. Найти уравнение парной линейной регрессии зависимости между валовым внутренним продуктом (ВВП) и частным потреблением на основе данных примера урока о корреляционной зависимости (эта ссылка, которая откроется в новом окне, потребуется и при разборе следующих примеров).
Решение. Используем рассчитанные в решении названного выше примера суммы:




Используя эти суммы, вычислим коэффициенты:


Таким образом получили уравнение прямой парной линейной регрессии:

Составить уравнение парной линейной регрессии самостоятельно, а затем посмотреть решение
Пример 2. Найти уравнение парной линейной регрессии для выборки из 6 наблюдений, если уже вычислены следующие промежуточные результаты:
 ;
;
 ;
;
 ;
;
 ;
;
Анализ качества модели линейной регрессии
Метод наименьших квадратов имеет по меньшей мере один существенный недостаток: с его помощью можно найти уравнение линейной регрессии и в тех случаях, когда данные наблюдений значительно рассеяны вокруг прямой регрессии, то есть находятся на значительном расстоянии от этой прямой. В таких случаях за точность прогноза значений зависимой переменной ручаться нельзя. Существуют показатели, которые позволяют оценить качество уравнения линейной регрессии прежде чем использовать модели линейной регрессии для практических целей. Разберём важнейшие из этих показателей.
Коэффициент детерминации
Коэффициент детерминации  принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
 ,
,
 — сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
— сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
 — общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
— общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
 — сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
— сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
Пример 3. Даны сумма квадратов отклонений, объясняемых моделью линейной регрессии (3500), общая сумма квадратов отклонений (5000) и сумма квадратов отклонений ошибки (1500). Найти коэффициент детерминации двумя способами.
F-статистика (статистика Фишера) для проверки качества модели линейной регрессии
Минимальное возможное значение F-статистики — 0. Чем выше значение статистики Фишера, тем качественнее модель линейной регрессии. Этот показатель представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы):

где m — число объясняющих переменных.
Сумма квадратов остатков
Сумма квадратов остатков (RSS) измеряет необъясненную часть дисперсии зависимой переменной:

 —
—
остатки — разности между реальными значениями зависимой переменной и значениями, оценёнными уравнением линейной регрессии.
В случае качественной модели линейной регрессии сумма квадратов остатков стремится к нулю.
Стандартная ошибка регрессии
Стандартная ошибка регрессии (SEE) измеряет величину квадрата ошибки, приходящейся на одну степень свободы модели:

Чем меньше значение SEE, тем качественнее модель.
Пример 4. Рассчитать коэффициент детерминации для данных из примера 1.
Решение. На основании данных таблицы (она была приведена в примере урока о корреляционной зависимости) получаем, что SST = 63 770,593 , SSE = 10 459,587 , SSR = 53 311,007 .
Можем убедиться, что выполняется закономерность SSR = SST — SSE :
Получаем коэффициент детерминации:
 .
.
Таким образом, 83,6% изменений частного потребления можно объяснить моделью линейной регресии.
Интерпретация коэффициентов уравнения парной линейной регрессии и прогноз значений зависимой переменной
Итак, уравнение парной линейной регрессии:
 .
.
В этом уравнении a — свободный член, b — коэффициент при независимой переменной.
Интерпретация свободного члена: a показывает, на сколько единиц график регрессии смещён вверх при x=0, то есть значение переменной y при нулевом значении переменной x.
Интерпретация коэффициента при независимой переменной: b показывает, на сколько единиц изменится значение зависимой переменной y при изменении x на одну единицу.
Пример 5. Зависимость частного потребления граждан от ВВП (истолкуем это просто: от дохода) описывается уравнением парной линейной регрессии  . Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
. Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
Решение. Подставляем в уравнение парной линейной регрессии x i = 20000 и получаем прогноз потребления при доходе в 20 000 у.е. y i = 17036,4662 .
Подставляем в уравнение парной линейной регрессии x i = 5000 и получаем прогноз увеличения потребления при увеличении дохода на 5000 у.е. y i = 4161,9662 .
Если доход не меняется, то x i = 0 и получаем, что потребление уменьшается на 129,5338 у.е.
Задачи регрессионного анализа
Регрессионный анализ — раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным.
Наиболее частые задачи регрессионного анализа:
- установление факта наличия или отсутствия статистических зависимостей между переменными величинами;
- выявление причинных связей между переменными величинами;
- прогноз или восстановление неизвестных значений зависимых переменных по заданным значениям независимых переменных.
Также делаются проверки статистических гипотез о регрессии. Кроме того, при изучении связи между двумя величинами по результатам наблюдений в соответствии с теорией регрессии предполагается, что зависимая переменная имеет некоторое распределение вероятностей при фиксированном значении независимой переменной.
В исследованиях поведения человека, чтобы они претендовали на объективность, важно не только установить зависимость между факторами, но и получить все необходимые статистические показатели для результата проверки соответствующей гипотезы.
Проверка гипотезы о равенстве нулю коэффициента направления прямой парной линейной регрессии
Одна из важнейших гипотез в регрессионном анализе — гипотеза о том, что коэффициент направления прямой регрессии генеральной совокупности равен нулю.
Если это предположение верно, то изменения независимой переменной X не влияют на изменения зависимой переменной Y: переменные X и Y не коррелированы, то есть линейной зависимости Y от X нет.

рассматривают во взаимосвязи с альтернативной гипотезой
 .
.
Статистика коэффициента направления

соответствует распределению Стьюдента с числом степеней свободы v = n — 2 ,
где  — стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
— стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
Доверительный интервал коэффициента направления прямой линейной регрессии:
 .
.
Критическая область, в которой с вероятностью P = 1 — α отвергают нулевую гипотезу и принимают альтернативную гипотезу:

Пример 6. На основе данных из предыдущих примеров (о ВВП и частном потреблении) определить доверительный интервал коэффициента направления прямой линейной регресии 95% и проверить гипотезу о равенстве нулю коэффициента направления прямой парной линейной регрессии.
Можем рассчитать, что  , а стандартная погрешность регрессии
, а стандартная погрешность регрессии  .
.
Таким образом, стандартная погрешность коэффициента направления прямой линейной регресии b 1 :
 .
.
Так как  и
и  (находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
(находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
 .
.
Так как гипотетическое значение коэффициента — нуль — не принадлежит доверительному интервалу, с вероятностью 95% можем отвергнуть основную гипотезу и принять альтернативную гипотезу, то есть считать, что зависимая переменная Y линейно зависит от независимой переменной X.
Проверка значимости регрессии с помощью дисперсионного анализа (F-тест)
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Проведем проверку значимости простой линейной регрессии с помощью процедуры F -тест.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Проверку значимости взаимосвязи переменных в рамках модели простой линейной регрессии можно провести разными, но эквивалентными между собой, способами:
Проверку значимости взаимосвязи переменных в рамках модели простой линейной регрессии можно провести разными, но эквивалентными между собой, способами:
Процедуру F -теста рассмотрим на примере простой линейной регрессии , когда прогнозируемая переменная Y зависит только от одной переменной Х.
Чтобы определить может ли предложенная модель линейной регрессии быть использована для адекватного описания значений переменной Y, дисперсию наблюдаемых данных анализируют методом Дисперсионного анализа (ANOVA for Simple Regression) . Дисперсия данных разбивается на компоненты, которые затем используются в F -тесте для определения значимости регрессии.
F -тест для проверки значимости регрессии НЕ относится к простым и интуитивно понятным процедурам. Вероятно, это связано с тем, что для проведения F -теста требуется быть знакомым с определенным количеством статистических понятий и нужно неплохо разбираться в связанных с ними статистических методах. Нам потребуются понятия из следующих разделов статистики:
Можно, конечно, рассмотреть F -тест формально:
- вычислить на основании выборки значение тестовойFстатистики;
- сравнить полученное значение со значением, соответствующему заданному уровню значимости ;
- в зависимости от соотношения этих величин принять решение о значимости вычисленной линейной регрессии
В этой статье ставится более амбициозная задача – разобраться в самом подходе, на котором основан F -тест . Сначала введем несколько определений, которые используются в процедуре F -теста , затем рассмотрим саму процедуру.
Примечание : Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части .
Определения, необходимые для F -теста
Согласно определению дисперсии , дисперсия выборки прогнозируемой переменной Y определяется формулой:
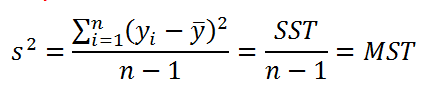
В формуле используется ряд сокращений:
- SST (Total Sum of Squares) – это просто компактное обозначение Суммы Квадратов отклонений от среднего (такое сокращение часто используется в зарубежной литературе).
- MST (Total Mean Square) – Среднее Суммы Квадратов отклонений (еще одно общеупотребительное сокращение).
Примечание : Необходимо иметь в виду, что с одной стороны величины MST и SST являются случайными величинами, вычисленными на основании выборки, т.е. статистиками . Однако с другой стороны, при проведении регрессионного анализа по данным имеющейся выборки вычисляются их конкретные значения. В этом случае величины MST и SST являются просто числами.
Значение n-1 в вышеуказанной формуле равно числу степеней свободы ( DF ) , которое относится к дисперсии выборки (одна степень свободы у n величин yi потеряна в результате наличия ограничения  , связывающего все значения выборки). Число степеней свободы у величины SST также имеет специальное обозначение: DFT (DF Total).
, связывающего все значения выборки). Число степеней свободы у величины SST также имеет специальное обозначение: DFT (DF Total).
Как видно из формулы, отношение величин SST и DFT обозначается как MST. Эти 3 величины обычно выдаются в таблице результатов дисперсионного анализа в различных прикладных статистических программах (в том числе и в надстройке Пакет анализа, инструмент Регрессия ).
Значение SST, характеризующую общую изменчивость переменной Y, можно разбить на 2 компоненты:
- Изменчивость объясненную моделью (Explained variation), обозначается SSR
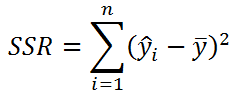
- Необъясненную изменчивость (Unexplained variation), обозначается SSЕ
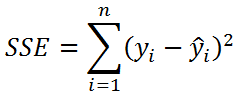
Известно , что справедливо равенство:
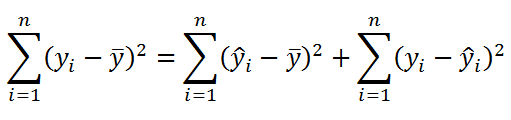
Величинам SSR и SSE также сопоставлены степени свободы . У SSR одна степень свободы , т.к. она однозначно определяется одним параметром – наклоном линии регрессии a (напомним, что мы рассматриваем простую линейную регрессию ). Это очевидно из формулы:
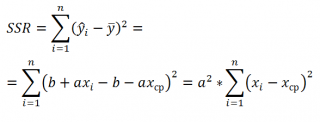
Примечание: Очевидность наличия только одной степени свободы проистекает из факта, что переменная Х – контролируемая (не является случайной величиной).
Число степеней свободы величины SSR имеет специальное обозначение: DFR (для простой регрессии DFR=1, т.к. число независимых переменных Х равно 1) . По аналогии с MST, отношение этих величин также часто обозначают MSR = SSR / DFR .
У SSE число степеней свободы равно n -2 , которое обозначается как DFE (или DFRES — residual degrees of freedom). Двойка вычитается, т.к. изменчивость переменной yi имеет 2 ограничения, связанные с оценкой 2-х параметров линейной модели ( а и b ): ŷi=a*xi+b
Отношение этих величин также часто обозначают MSE = SSE / DFE .
MSR и MSE имеют размерность дисперсий, хотя корректней их называть средними значениями квадратов отклонений. Тем не менее, ниже мы их будем «дисперсиями», т.к. они отображают меру разброса: MSE – меру разброса точек наблюдений относительно линии регрессии, MSR показывает насколько линия регрессии совпадает с горизонтальной линией среднего значения Y.
Примечание : Напомним, что MSE (Mean Square of Errors) является оценкой дисперсии s 2 ошибки, подробнее см. статью про линейную регрессию , раздел Стандартная ошибка регрессии .
Число степеней свободы обладает свойством аддитивности: DFT = DFR + DFE . В этом можно убедиться, составив соответствующее равенство n -1=1+( n -2)
Наконец, определившись с определениями, переходим к рассмотрению самой процедуры F -тест .
Процедура F -теста
Сущность F -теста при проверке значимости регрессии заключается в том, чтобы сравнить 2 дисперсии : объясненную моделью (MSR) и необъясненную (MSE). Если эти дисперсии «примерно равны», то регрессия незначима (построенная модель не позволяет объяснить поведение прогнозируемой Y в зависимости от значений переменной Х). Если дисперсия, объясненная моделью (MSR) «существенно больше», чем необъясненная, то регрессия значимая .
Примечание : Чтобы быстрее разобраться с процедурой F -теста рекомендуется вспомнить процедуру проверки статистических гипотез о равенстве дисперсий 2-х нормальных распределений (т.е. двухвыборочный F-тест для дисперсий ).
Чтобы пояснить вышесказанное изобразим на диаграммах рассеяния 2 случая:
- регрессия значима (в этом случае имеем значительный наклон прямой) и
- регрессия незначима (линия регрессии близка к горизонтальной прямой).
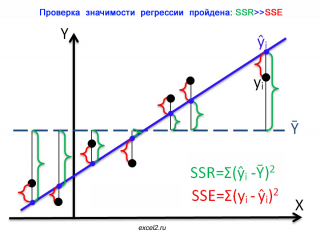
На первой диаграмме показан случай, когда регрессия значима:
- Зеленым цветом выделены расстояния от среднего значения до линии регрессии , вычисленные для каждого хi. Сумма квадратов этих расстояний равна SSR;
- Красным цветом выделены расстояния от линии регрессии до соответствующих точек наблюдений . Сумма квадратов этих расстояний равна SSЕ.
Из диаграммы видно, что в случае значимой регрессии, сумма квадратов «зеленых» расстояний, гораздо больше суммы квадратов «красных». Понятно, что их отношение будет гораздо больше 1. Следовательно, и отношение дисперсий MSR и MSE будет гораздо больше 1 (не забываем, что SSE нужно разделить еще на соответствующее количество степеней свободы n-2).
В случае значимой регрессии точки наблюдений будут находиться вдоль линии регрессии. Их разброс вокруг этой линии описываются ошибками регрессии, которые были минимизированы посредством процедуры МНК . Очевидно, что разброс точек относительно линии регрессии значительно меньше, чем относительно горизонтальной линии, соответствующей среднему значению Y.
Совершенно другую картину мы можем наблюдать в случае незначимой регрессии.
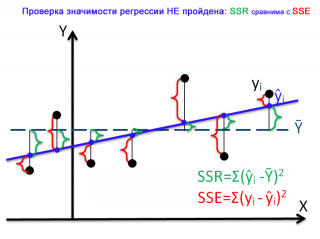
Очевидно, что в этом случае, сумма квадратов «зеленых» расстояний, примерно соответствует сумме квадратов «красных». Это означает, что объясненная дисперсия примерно соответствует величине необъясненной дисперсии (MSR/MSE будет близко к 1).
Если ответ о значимости регрессии практически очевиден для 2-х вышеуказанных крайних ситуаций, то как сделать правильное заключение для промежуточных углов наклона линии регрессии?
Понятно, что если вычисленное на основании выборки значение MSR/MSE будет существенно больше некоторого критического значения, то регрессия значима, если нет, то не значима. Очевидно, что это значение должно быть больше 1, но как определить это критическое значение статистически обоснованным методом ?
Вспомним, что для формулирования статистического вывода (т.е. значима регрессия или нет) используют проверку гипотез . Для этого формулируют 2 гипотезы: нулевую Н 0 и альтернативную Н 1 . Для проверки значимости регрессии в качестве нулевой гипотезы Н 0 принимают, что связи нет, т.е. наклон прямой a=0. В качестве альтернативной гипотезы Н 1 принимают, что a <>0.
Примечание : Даже если связи между переменными нет (a=0), то вычисленная на основании данных выборки оценка наклона — величина а , из-за случайности выборки будет близка, но все же отлична от 0.
По умолчанию принимается, что нулевая гипотеза верна – связи между переменными нет. Если это так, то:
- MSR/MSE будет близко к 1;
- Случайная величина F = MSR/MSE будет иметь F-распределениесо степенями свободы 1 (в числителе) и n-2 (знаменателе). F является тестовой статистикой для проверки значимости регрессии.
Примечание : MSR и MSE являются случайными величинами (т.к. они получены на основе случайной выборки). Соответственно, выражение F=MSR/MSE, также является случайной величиной, которая имеет свое распределение, среднее значение и дисперсию .
Ниже приведен график плотности вероятности F-распределения со степенями свободы 1 (в числителе) и 59 (знаменателе). 59=61-2, 61 наблюдение минус 2 степени свободы.
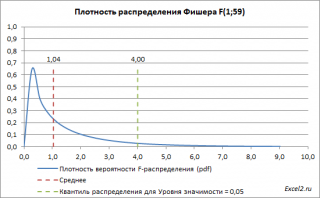
Если нулевая гипотеза верна, то значение F 0 =MSR/MSE, вычисленное на основании выборки, должно быть около ее среднего значения (т.е. около 1,04). Если F 0 будет существенно больше 1 (чем больше F0 отклоняется в сторону больших значений, тем это маловероятней), то это будет означать, что F не имеет F-распределение , а, следовательно, нулевую гипотезу нужно отклонить и принять альтернативную, утверждающую, что связь между переменными есть (значима).
Обычно предполагают, что если вероятность, того что F -статистика приняла значение F0 составляет менее 5%, то это событие маловероятно и нулевую гипотезу необходимо отклонить. 5% — это заданный исследователем уровень значимости , который может быть, например, 1% или 10%.
Значение статистики F0 может быть вычислено на основании выборки:
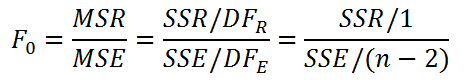
Вычисления в MS EXCEL
В MS EXCEL критическое значение для заданного уровня значимости F1-альфа, 1, n-2 можно вычислить по формуле = F.ОБР(1- альфа;1; n-2) или = F.ОБР.ПХ(альфа;1; n-2) . Другими словами требуется вычислить верхний альфа-квантиль F-распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F0> F1-альфа, 1, n-2 мы имеем основание для отклонения нулевой гипотезы.
Значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В случае простой регрессии значение F0 также равно квадрату t-статистики, которую мы использовали при проверке двусторонней гипотезе о равенстве 0 коэффициента регрессии .
Проверку значимости регрессии можно также осуществить через вычисление p-значения. В этом случае вычисляют вероятность того, что случайная величина F примет значение F0 (это и есть p-значение), затем сравнивают p-значение с заданным уровнем значимости . Если p-значение больше уровня значимости, то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL для проверки гипотезы используя p -значение используйте формулу = F.РАСП.ПХ(F0;1;n-2) файл примера , где показано эквивалентность всех подходов проверки значимости регрессии).
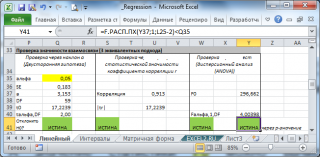
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Таблица, которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .
Дисперсионный анализ уравнения парной регрессии проверяет значимость
Проверить значимость уравнения регрессии — значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной. [c.70]
Проверка значимости уравнения регрессии производится на основе дисперсионного анализа. [c.70]
По данным табл. 3.1 оценить на уровне а=0,05 значимость уравнения регрессии У по X. [c.74]
По данным примера 3.7 а) найти уравнение регрессии Y по X б) найти коэффициент детерминации R2 и пояснить его смысл в) проверить значимость уравнения регрессии на 5%-ном уровне по F-критерию г) оценить среднюю производительность труда на предприятиях с уровнем механизации работ 60% и построить для нее 95%-ный доверительный интервал аналогичный доверительный интервал найти для индивидуальных значений производительности труда на тех же предприятиях. [c.81]
Зная / 2=0,811, проверим значимость уравнения регрессии. Фактическое значение критерия по (4.35) [c.106]
Постройте таблицу дисперсионного анализа для оценки значимости уравнения регрессии в целом. [c.35]
Сделайте вывод о значимости уравнения регрессии. [c.37]
Оцените значимость уравнений регрессии в целом и их параметров. Сравните полученные результаты, выберите лучшее уравнение регрессии. [c.48]
Общий F-критерий проверяет гипотезу Яо о статистической значимости уравнения регрессии и показателя тесноты связи (Л2 = 0) [c.59]
Оцените значимость уравнения регрессии в целом с помощью F-критерия Фишера. [c.86]
Найдите скорректированный коэффициент корреляции, оцените значимость уравнения регрессии в целом. [c.86]
Оцените значимость уравнения регрессии, учитывая, что оно построено по 30 наблюдениям. [c.87]
Оценка значимости уравнения регрессии обычно дается в виде таблицы дисперсионного анализа (табл. 2.2). [c.53]
Величина /»-критерия, оценивая значимость уравнения регрессии в целом, характеризует одновременно и значимость коэффициента (индекса) множественной корреляции. Вместе с тем оценку существенности коэффициента множественной корреляции можно дать и через сравнение скорректированного коэффициента корреляции с его табличным значением при соответствующем уровне вероятности и числе степеней свободы п — т — 1. Так, при п = 30 и т = 2 фактическое значение R должно превышать 0,368 при 5 %-ном уровне значимости, чтобы можно было считать его значение отличным от нуля с вероятностью 0,95. [c.139]
Пример. Проверить значимость уравнения регрессии [c.90]
Для проверки значимости уравнения регрессии необходимо при заданных значениях (хр х2) провести несколько экспериментов, чтобы для данного значения (, , х2) получить некоторое среднее значение функции у. В этом случае экспериментальный материал представляется, например, в виде табл. 3.19. [c.111]
Критерий Фишера F Математический критерий, характеризующий значимость уравнения регрессии. Применяется для выбора модели Больше табличного значения, установленного для различных размеров матрицы и вероятностей [c.322]
Для выявления существенности факторов х,- в уравнениях (20) — (22) были рассчитаны значения -критерия Стьюдента для всех коэффициентов уравнения регрессии, которые затем были сопоставлены с табличными значениями. Как видно из табл. 37, расчетные значения -критерия Стьюдента для всех коэффициентов полученных уравнений регрессий (20) — (22) выше табличных, что свидетельствует о их значимости. [c.86]
Отбор значимых факторов приведенных выше уравнений регрессии осуществлялся на основе применения критерия Фишера, а коэффициенты регрессии найдены с точностью, определяемой функцией Стьюдента (3). [c.54]
Выбор математической формы связи при моделировании себестоимости добычи нефти, как показывает практика, целесообразно проводить методом перебора известных уравнений регрессий с переходом от менее сложных форм к более сложным. Часто случается так, что одна часть факторов связана с себестоимостью добычи нефти линейной зависимостью, другая — нелинейной. Поэтому удобнее поиск искомой формы связи начинать с линейной зависимости, затем проверить нелинейную зависимость, а потом перейти к более сложным формам связи (приложение 1). При выборе формы связи необходимо стремиться к получению достаточно простой по решению и удобной для экономической интерпретации модели. Модель себестоимости добычи нефти должна также отвечать условиям адекватности при включении в нее возможно меньшего числа факторов. Последнее обстоятельство указывает на то, что оценка значимости факторов с последующим отсевом менее существенных из них не утрачивает своей актуальности и на этом этапе исследования. [c.18]
Далее следует оценить параметры уравнения регрессии на их значимость и показатели тесноты на их существенность. [c.329]
На основе F-критерия принимаются решения о форме уравнения регрессии, о статистической значимости той или иной объясняющей переменной при построении многофакторного уравнения регрессии (см. гл. 8) и др. [c.217]
После построения уравнения регрессии необходимо сделать проверку его значимости с помощью специальных критериев установить, не является ли полученная зависимость, выраженная уравнением регрессии, случайной, т.е. можно ли ее использовать в прогнозных целях и для факторного анализа. В статистике разработаны методики строгой проверки значимости коэффициентов регрессии с помощью дисперсионного анализа и расчета специальных критериев (например, F-критерия). Нестрогая проверка может быть выполнена путем расчета среднего относительного линейного отклонения (ё), называемого средней ошибкой аппроксимации [c.123]
Коэффициенты регрессии в (4.14) несопоставимы между собой, а / -коэффициенты уже сопоставимы. Поэтому для аналитика именно стандартизованное представление уравнения регрессии имеет особую значимость, поскольку позволяет дать сравнительную характеристику значимости факторов чем больше значение / -коэффициента, тем более существен фактор с позиции влияния его на результативный показатель. Бета-коэффициенты могут использоваться для установления нормативов, разработки весовых коэффициентов при конструировании различных сложных аналитических показателей (например, уровень научно-технического прогресса). [c.125]
В определенных обстоятельствах можно использовать коэффициент ранговой корреляции в качестве альтернативного показателя оценки зависимости между двумя наборами значений. Так, часто трудно получить точные показатели некоторых значений, и поэтому единственный надежный метод состоит в расстановке переменных по порядку, иначе говоря — в ранжировании значений. Коэффициент корреляции ранжированных значений называется коэффициентом ранговой корреляции, и он вычисляется по упрощенной формуле, которая приведена в этой главе. Значимая корреляция между двумя переменными подразумевает наличие линейной зависимости между ними. Методы регрессии можно использовать для определения уравнения наилучшей прямой линии, линии регрессии. Уравнение регрессии записывается в виде у = а + Ьх. Это уравнение можно использовать для оценки значения у при заданном значении х. Так, например, объем выручки от реализации можно рассчитать исходя из заданной суммы расходов на рекламу. Нелинейная зависимость между переменными должна быть преобразована в линейную, и только потом следует проводить базовый анализ регрессии. [c.128]
Проблема отбора факторных признаков для построения моделей взаимосвязи может быть решена с помощью эвристических или многомерных статистических методов анализа. Наиболее приемлемым методом отбора факторных признаков является шаговая регрессия (шаговый регрессионный анализ). Сущность данного метода заключается в последовательном включении факторов в уравнение регрессии и последующей проверке их значимости. Факторы поочередно вводятся в уравнение так называемым прямым методом . При проверке значимости введенного фактора определяется, насколько уменьшается сумма квадратов остатков и увеличивается величина множественного коэффициента корреляции (R). Одновременно используется и обратный метод, т.е. исключение факторов, ставших незначимыми на основе -крите-рия Стьюдента. Фактор является незначимым, если его включение в уравнение регрессии только изменяет значение коэффициентов регрессии, не уменьшая суммы квадратов остатков и не увеличивая их значения. Если при включении в модель соответствующего факторного признака величина множественного коэффициента корреляции увеличивается, а коэффициент регрессии не изменяется (или меняется несущественно), то данный признак существен и его включение в уравнение регрессии необходимо. [c.118]
Проверка адекватности моделей, построенных на основе уравнений регрессии, начинается с проверки значимости каждого коэффициента регрессии с помощью Г-критерия Стьюдента [c.120]
Блок 7—проверка значимости уравнения регрессии. Критерием оценки уравнения регрессии выбран коэффициент множественной корреляции, оценка значимости которого проводится с использованием модуля Mill. [c.53]
Оцените статистическую значимость уравнения регрессии и его параметров с помощью критериеэ Фишера и Стьюдента. [c.97]
Оценка значимости уравнения регрессии в целом дается с помощью /-«-критерия Фишера. При этом выдвигается нулевая гипотеза, что коэффициент регрессии равен нулю, т. е. b = 0, и, следовательно, факторх не оказывает влияния на результату. [c.48]
Поскольку кт > Рта6л как при 1%-ном, так и при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана). [c.52]
Оцените статистическую значимость уравнений регрессии и их параметров при помощи F-критерия Фишера-Снедекора, частных F-критериев и t-критерия Стьюдента. [c.10]
Определение взаимосвязи вида У/ / связано как с проведением большого количества вычислительных операций, так и с рпределением большого количества статистических парамет— ров позволяющих производить анализ и отбор наиболее значимых факторов и уравнений регрессии. Поэтому расчеты целесообразно проводить на ЭВМ. [c.22]
После всесторонней и детальной оценки значимости факторов необходимо перейти к выбору формы связи, т. е. требуется подобрать такое уравнение регрессии, которое будет служить аналогом и более полно отражать экономическую сущнрсть исследуемого явления. Первой в поиске искомой модели участвует простая форма линейной связи. Решение этого уравнения на ЭВМ приводит к виду [c.29]
Такого рода характеристика явлений, влияющих на уровень и динамику валютного курса, является непременным этапом, предшествующим самостоятельному статистическому анализу факторов на основе конкретного цифрового материала. Дальнейший анализ выглядит чаще как моделирование взаимосвязей и оценка тесноты взаимозависимости (корреляционно-регрессионный анализ). Напомним, что выбор функции осуществляется исходя из показателей значимости уравнения и ошибок аппроксимации. Это относительная ошибка аппроксимации, средняя квадратическая ошибка аппроксимации (6ОСТ) (чем они меньше, тем лучше уравнение) и коэффициент множественной детерминации (R2) или коэффициент множественной корреляции (R) (чем ближе он к 1, тем более вероятность, что уравнение регрессии носит совершенно случайный характер). Для проверки значимости используют F-критерий с распределением Фишера. [c.670]
Увеличение абсолютной величины — свободного члена уравнения регрессии параметра а — является следствием снижения тесноты прямолинейной связи между мощностью пласта и среднесменной добычей угля на одного подземного рабочего. Данные табл. 10.15 позволяют определить значимость изменения мощности пласта и [c.421]
http://excel2.ru/articles/proverka-znachimosti-regressii-s-pomoshchyu-dispersionnogo-analiza-f-test
http://economy-ru.info/info/15181/