Множественная регрессия в EXCEL
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Рассмотрим использование MS EXCEL для прогнозирования переменной Y на основании нескольких переменных Х, т.е. множественную регрессию.
Перед прочтением этой статьи рекомендуется освежить в памяти простую линейную регрессию – прогнозирование на основе значений только одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Множественного регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Множественный регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Прогнозирование единственной переменной Y на основании значений 2-х или более переменных Х называется множественной регрессией .
Множественная линейная регрессионная модель (Multiple Linear Regression Model) имеет вид Y=β 0 +β 1 *X 1 +β 2 *X 2 +…+β k *X k +ε. В этом случае переменная Y зависит от k поясняющих переменных Х, т.е. регрессоров . ε — случайная ошибка . Модель является линейной относительно неизвестных параметров β.
Оценка неизвестных параметров
В этой статье рассмотрим модель с 2-мя регрессорами. Сначала введем необходимые обозначения и понятия множественной регрессии.
Для описания зависимости Y от 2-х переменных линейная модель имеет вид:
Параметры этой модели β i нам неизвестны, но их можно оценить, используя случайную выборку (измеренные значения переменной Y от заданных Х). Оценки параметров модели (β 0 , β 1 , β 2 ) обычно вычисляются методом наименьших квадратов (МНК) , который минимизирует сумму квадратов ошибок прогнозирования (критерий минимизации в англоязычной литературе обозначают как SSE – Sum of Squared Errors).
Ошибка ε имеет случайную природу и имеет свою функцию распределения со средним значением =0 и дисперсией σ 2 .
Оценки b 1 и b 2 называются коэффициентами регрессии , они определяют влияние соответствующей переменной X, когда все остальные независимые переменные остаются неизменными .
Сдвиг (intercept) или постоянный член b 0 , определяет прогнозируемое значение Y, когда все поясняющие переменные Х равны 0 (часто сдвиг не имеет физического смысла в рамках модели и обусловлен лишь математическими вычислениями МНК ).
Вычислив оценки, полученные методом МНК, позволяют прогнозировать значения переменной Y:
Примечание : Для случая 2-х регрессоров, все спрогнозированные значения переменной Y будут лежать в плоскости (в плоскости регрессии ).
В качестве примера рассмотрим технологический процесс изготовления нити:
Инженер, на основе имеющегося опыта, предположил, что прочность нити Y зависит от концентрации исходного раствора (Х 1 ) и температуры реакции (Х 2 ), и соответствует модели линейной регрессии. Для нахождения комбинации переменных Х, при которых Y принимает максимальное значение, необходимо определить коэффициенты регрессии, сделав выборку.
В MS EXCEL коэффициенты множественной регрессии удобнее всего вычислить с помощью функции ЛИНЕЙН() . Это сделано в файле примера на листе Коэффициенты . Чтобы вычислить оценки:
- выделите 3 ячейки в одной строке (т.к. мы рассматриваем случай 2-х регрессоров, то будут вычислены 2 коэффициента регрессии + величина сдвига = 3 значения, для вывода которых понадобится 3 ячейки). Пусть это будет диапазон С8:Е8 ;
- в Строке формул введите = ЛИНЕЙН(D20:D50;B20:C50) . Предполагается, что в столбце В содержатся прогнозируемые значения Y (в нашей модели это Прочность нити), в столбцах С и D содержатся значения контролируемых параметров Х (Х1 – Концентрация в столбце С и Х2 – Температура в столбце D).
- нажмите CTRL+SHIFT+ENTER (т.к. это формула массива ).
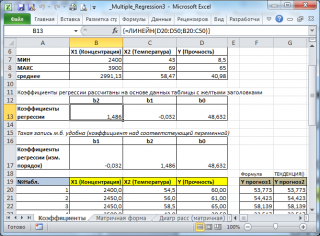
В левой ячейке будет рассчитано значение коэффициента регрессии b 2 для переменной Х2, в средней ячейке — значение коэффициента регрессии b 1 для переменной Х1, в правой – сдвиг . Обратите внимание, что порядок вывода коэффициентов регрессии обратный по отношению к расположению столбцов с данными соответствующих переменных Х (вычисленный коэффициент b 2 располагается левее по отношению к b 1 , тогда как значения переменной Х2 располагаются правее значений переменной Х1). Это может привести к путанице, поэтому лучше разместить коэффициенты над соответствующими столбцами с данными, как это сделано в строке 17 файла примера .
Примечание : В принципе без функции ЛИНЕЙН() можно обойтись, записав альтернативные формулы. Для этого в файле примера на листе Коэффициенты в столбцах I : K вычислены отклонения значений переменных Х 1i , Х 2i , Y i от их средних значений 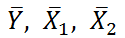 , т.е.:
, т.е.: 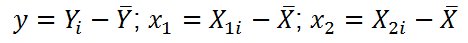
Далее коэффициенты регрессии рассчитываются по следующим формулам (эти формулы справедливы только при прогнозировании по 2-м независимым переменным Х):
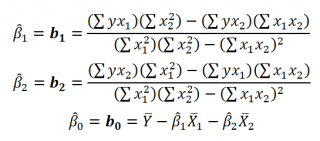
При прогнозировании по 3-м и более независимым переменным Х формулы для вычисления коэффициентов регрессии значительно усложняются, поэтому следует использовать матричный подход.
В файле примера на листе Матричная форма выполнены расчеты коэффициентов регрессии с помощью матричного подхода.
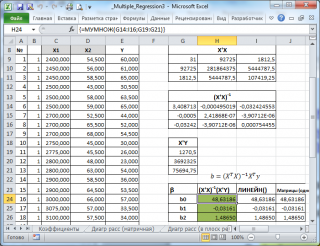
Расчет можно произвести как пошагово, так и одной формулой массива :
Коэффициенты регрессии (вектор b ) в этом случае вычисляются по формуле b =(X T X) -1 (X T Y) или в другом виде записи b =(X ’ X) -1 (X ’ Y)
Под Х подразумевается матрица, состоящая из столбцов значений переменной Х с дополнительным столбцом единиц, а под Y – вектор-столбец значений Y.
Диаграмма рассеяния
В случае простой линейной регрессии (один регрессор, т.е. одна переменная Х) для визуализации связи между прогнозируемым значением Y и переменной Х строят диаграмму рассеяния (двумерную).
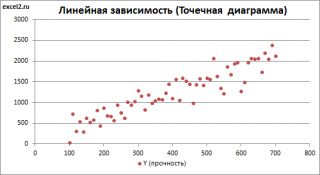
В случае множественной линейной регрессии двумерную диаграмму рассеяния можно построить только для анализа влияния каждого отдельного регрессора на Y (при этом остальные Х не меняются), т.е. так называемую Матричную диаграмму рассеивания (См. файл примера лист Диагр расс (матричная) ).
К сожалению, такую диаграмму трудно интерпретировать.
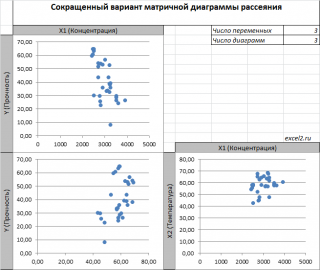
Более того, матричная диаграмма может вводить в заблуждение (см. Introduction to linear regression analysis / D . C . Montgomery , E . A . Peck , G . G . Vining , раздел 3.2.5 ), демонстрируя наличие или отсутствие линейной взаимосвязи между отдельным регрессором X i и Y.
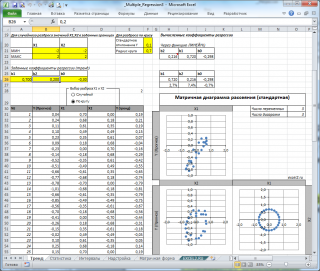
Для случая с 2-мя регрессорами можно предложить альтернативный вид матричной диаграммы рассеяния . В стандартной диаграмме рассеяния строятся проекции на координатные плоскости Х1;Х2, Y;X1 и Y;X2. Однако, если взглянуть на точки относительно плоскости регрессии , то картину, на мой взгляд, будет проще интерпретировать.
Сравним две матричные диаграммы рассеяния (см. файл примера на листе «Диагр расс (в плоск регрессии)» , построенные для одних и тех же наблюдений. Первая – стандартная,

вторая представляет собой вид сверху на плоскость регрессии и 2 вида вдоль плоскости.
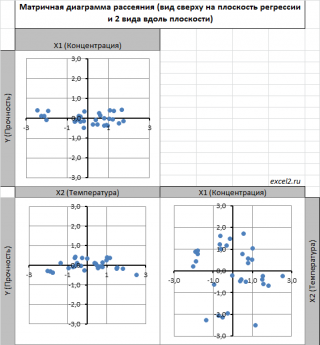
На второй диаграмме становится очевидно, что разброс точек относительно плоскости регрессии совсем не большой и поэтому, скорее всего, построенная модель является полезной, а выбранные 2 переменные Х позволяют прогнозировать Y (конечно, для подтверждения этой гипотезы нужно провести процедуру F-теста ).
Несколько слов о построении альтернативной матричной диаграммы рассеяния:
- Перед построением необходимо нормировать значения наблюдений (для каждой переменной вычесть среднее и разделить на стандартное отклонение ). В этом случае практически все точки на диаграммах будут находится в диапазоне +/-3 (по аналогии со стандартным нормальным распределением , 99% значений которого лежат в пределах +/-3 сигма). В этом случае, на диаграмме можно фиксировать мин/макс значений осей, чтобы EXCEL автоматически не модифицировал масштаб осей при изменении данных (это не всегда удобно);
- Теперь координаты точек необходимо рассчитать в системе отсчета относительно плоскости регрессии (в которой плоскость Оху’ совпадает с плоскостью регрессии). Для этого необходимо найти матрицу вращения , например, через вращение приводящее к совмещению нормали к плоскости регрессии и вектора оси Z (0;0;1);
- Новые координаты позволяют построить альтернативную матричную диаграмму. Кроме того, для удобства можно вращать систему координат вокруг новой оси Z, чтобы нагляднее представить себе распределение точек относительно плоскости регрессии (для этого использована Полоса прокрутки в ячейках Q31:S31 ).
Вычисление прогнозных значений Y (отдельное наблюдение и среднее значение) и построение доверительных интервалов
После того, как нами были найдены тем или иным способом коэффициенты регрессии можно приступать к вычислению прогнозных значений Y на основе заданных значений переменных Х.
Уравнение прогнозирования или уравнение регрессии в случае 2-х независимых переменных (регрессоров) записывается в виде:
Примечание: В MS EXCEL прогнозное значение Y для заданных Х 1 и Х 2 можно также предсказать с помощью функции ТЕНДЕНЦИЯ() . При этом 2-й аргумент будет ссылкой на столбцы, содержащие все значения переменных Х 1 и Х 2 , а 3-й аргумент функции должен быть ссылкой на диапазон ячеек, содержащий 2 значения Х (Х 1i и Х 2i ) для выбранного наблюдения i (см. файл примера, лист Коэффициенты, столбец G ). Функция ПРЕДСКАЗ() , использованная нами в простой регрессии, не работает в случае множественной регрессии .
Найдя прогнозное значение Y, мы, таким образом, вычислим его точечную оценку. Понятно, что фактическое значение Y, полученное при наблюдении, будет, скорее всего, отличаться от этой оценки. Чтобы ответить на вопрос о том, на сколько хорошо мы можем предсказывать новые значения Y, нам потребуется построить доверительный интервал этой оценки, т.е. диапазон в котором с определенной заданной вероятностью, скажем 95%, мы ожидаем новое значение Y.
Доверительные интервалы построим при фиксированном Х для:
- нового наблюдения Y;
- среднего значения Y (интервал будет уже, чем для отдельного нового наблюдения)
Как и в случае простой линейной регрессии , для построения доверительных интервалов нам потребуется сначала вычислить стандартную ошибку модели (standard error of the model) , которая приблизительно показывает насколько велика ошибка предсказания значений переменной Y на основании значений переменных Х.
Для вычисления стандартной ошибки оценивают дисперсию ошибки ε, т.е. сигма^2 (ее часто обозначают как MS Е либо MSres ) . Затем, вычислив из полученной оценки квадратный корень, получим Стандартную ошибку регрессии (часто обозначают как SEy или sey ).
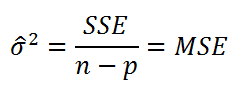
где SSE – сумма квадратов значений ошибок модели ei=yi — ŷi ( Sum of Squared Errors ). MSE означает Mean Square of Errors (среднее квадратов ошибок, точнее остатков).
Величина n-p – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y, р – количество оцениваемых параметров модели). В случае простой множественной регрессии с 2-мя регрессорами число степеней свободы равно n-3, т.к. при построении плоскости регрессии было оценено 3 параметра модели b (т.е. на это было «потрачено» 3 степени свободы ).
В MS EXCEL стандартную ошибку SEy можно вычислить формулы (см. файл примера, лист Статистика ):
Стандартная ошибка нового наблюдения Y при заданных значениях Х (вектор Хi) вычисляется по формуле:
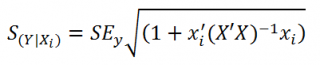
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
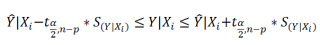
где α (альфа) – уровень значимости (обычно принимают равным 0,05=5%)
р – количество оцениваемых параметров модели (в нашем случае = 3)
n-p – число степеней свободы
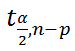 – квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
– квантиль распределения Стьюдента (задает количество стандартных ошибок , в +/- диапазоне которых вероятность обнаружить новое наблюдение равно 1-альфа). Т.е. если квантиль равен 2, то диапазон шириной +/- 2 стандартных ошибок относительно прогнозного значения Y будет с вероятностью 95% содержать новое наблюдение Y (для каждого заданного Хi). В MS EXCEL вычисления квантиля производят по формуле = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) , подробнее см. в статье про распределение Стьюдента .
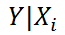 – прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
– прогнозное значение Yi вычисляемое по формуле Yi= b 0+ b 1* Х1i+ b 2* Х2i (точечная оценка).
Стандартная ошибка среднего значения Y при заданных значениях Х (вектор Хi) будет меньше, чем стандартная ошибка отдельного наблюдения. Вычисления производятся по формуле:
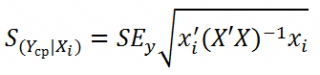
x i — вектор-столбец со значениями переменных Х (с дополнительной 1) для заданного наблюдения i.
Соответствующий доверительный интервал вычисляется по формуле:
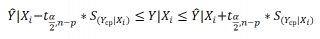
Прогнозное значение Yi (точечная оценка) используется тоже, что и для отдельного наблюдения.
Стандартные ошибки и доверительные интервалы для коэффициентов регрессии
В разделе Оценка неизвестных параметров мы получили точечные оценки коэффициентов регрессии . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ) коэффициентов регрессии .
Стандартная ошибка коэффициента регрессии b j (обозначается se ( b j ) ) вычисляется на основании стандартной ошибки по следующей формуле:
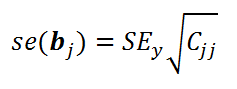
где C jj является диагональным элементом матрицы (X ’ X) -1 . Для коэффициента сдвига b 0 индекс j=1 (верхний левый элемент), для b 1 индекс j=2, b 2 индекс j=3 (нижний правый элемент).
SEy – стандартная ошибка регрессии (см. выше ).
В MS EXCEL стандартные ошибки коэффициентов регрессии можно вычислить с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. статью Функция MS EXCEL ЛИНЕЙН() .
Применяя матричный подход стандартные ошибки можно вычислить и через обычные формулы (точнее через формулу массива , см. файл примера лист Статистика ):
= КОРЕНЬ(СУММКВРАЗН(E13:E43;F13:F43) /(n-p)) *КОРЕНЬ (ИНДЕКС (МОБР (МУМНОЖ(ТРАНСП(B13:D43);(B13:D43)));j;j))
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
где t – это t-значение , которое можно вычислить с помощью формулы = СТЬЮДЕНТ.ОБР.2Х(0,05;n-p) для уровня значимости 0,05.
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии b j . Здесь мы считаем, что коэффициент регрессии b j имеет распределение Стьюдента с n-p степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
Проверка гипотез
Когда мы строим модель, мы предполагаем, что между Y и переменными X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X, возможен, когда все коэффициенты регрессии β равны 0.
Чтобы убедиться, что вычисленная нами оценка коэффициентов регрессии не обусловлена лишь случайностью (они не случайно отличны от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что линейной связи нет, т.е. ВСЕ β=0. В качестве альтернативной гипотезы Н 1 принимают, что ХОТЯ БЫ ОДИН коэффициент β <>0.
Процедура проверки значимости множественной регрессии, приведенная ниже, является обобщением дисперсионного анализа , использованного нами в случае простой линейной регрессии (F-тест) .
Если нулевая гипотеза справедлива, то тестовая F -статистика имеет F-распределение со степенями свободы k и n — k -1 , т.е. F k, n-k-1 :
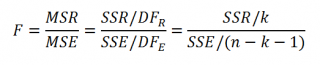
Проверку значимости регрессии можно также осуществить через вычисление p -значения . В этом случае вычисляют вероятность того, что случайная величина F примет значение F 0 (это и есть p-значение ), затем сравнивают p-значение с заданным уровнем значимости α (альфа) . Если p-значение больше уровня значимости , то нулевую гипотезу нет оснований отклонить, и регрессия незначима.
В MS EXCEL значение F 0 можно вычислить на основании значений выборки по вышеуказанной формуле или с помощью функции ЛИНЕЙН() :
В MS EXCEL для проверки гипотезы через p -значение используйте формулу =F.РАСП.ПХ(F 0 ;k;n-k-1) файл примера лист Статистика , где показано эквивалентность обоих подходов проверки значимости регрессии).
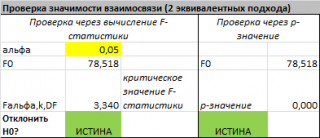
В MS EXCEL критическое значение для заданного уровня значимости F 1-альфа, k, n-k-1 можно вычислить по формуле = F.ОБР(1- альфа;k;n-k-1) или = F.ОБР.ПХ(альфа;k; n-k-1) . Другими словами требуется вычислить верхний альфа- квантиль F -распределения с соответствующими степенями свободы .
Таким образом, при значении статистики F 0 > F 1-альфа, k, n-k-1 мы имеем основание для отклонения нулевой гипотезы.
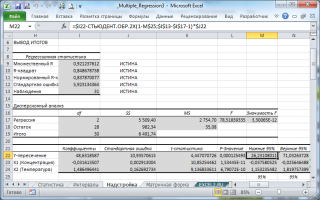
В программах статистики результаты процедуры F -теста выводят с помощью стандартной таблицы дисперсионного анализа . В файле примера такая таблица приведена на листе Надстройка , которая построена на основе результатов, возвращаемых инструментом Регрессия надстройки Пакета анализа MS EXCEL .
Генерация данных для множественной регрессии с помощью заданного тренда
Иногда, бывает удобно сгенерировать значения наблюдений, имея заданный тренд.
Для решения этой задачи нам потребуется:
- задать значения регрессоров в нужном диапазоне (значения переменных Х);
- задать коэффициенты регрессии ( b );
- задать тренд (вычислить значения Y= b0 +b1 * Х 1 + b2 * Х 2 );
- задать величину разброса Y вокруг тренда (варианты: случайный разброс в заданных границах или заданная фигура, например, круг)
Все вычисления выполнены в файле примера, лист Тренд для случая 2-х регрессоров. Там же построены диаграммы рассеяния .
Коэффициент детерминации
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью ( SSR ) / Общая изменчивость ( SST ).
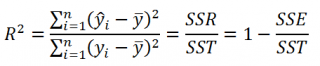
Этот показатель можно вычислить с помощью функции ЛИНЕЙН() :
При добавлении в модель новой объясняющей переменной Х, коэффициент детерминации будет всегда расти. Поэтому, рост коэффициента детерминации не может служить основанием для вывода о том, что новая модель (с дополнительным регрессором) лучше прежней.
Более подходящей статистикой, которая лишена указанного недостатка, является нормированный коэффициент детерминации (Adjusted R-squared):
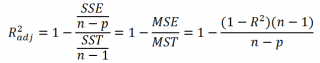
где p – число независимых регрессоров (вычисления см. файл примера лист Статистика ).
Многофакторная линейная регрессия
В многофакторных моделях результативный признак зависит от нескольких факторов. Множественный или многофакторный корреляционно-регрессионный анализ решает три задачи: определяет форму связи результативного признака с факторными, выявляет тесноту этой связи и устанавливает влияние отдельных факторов. Для двухфакторной линейной регрессии эта модель имеет вид:

Параметры модели ao, a1, a2 находятся путем решения системы нормальных уравнений:
 |
Покажем особенности эконометрического многофакторного анализа на рассмотренном выше примере, но введем дополнительный фактор – размер семьи. В таблице 6 представлены статистические данные о расходах на питание, душевом доходе и размере семьи для девяти групп семей. Требуется проанализировать зависимость величины расходов на питание от величины душевого дохода и размера семьи.
Таблица 6
| Номер группы | Расход на питание (у) | Душевой доход (х) | Размер семей (чел) |
| 1 | 1,5 | ||
| 2 | 2.1 | ||
| 3 | 2.7 | ||
| 4. | 3.2 | ||
| 3.4 | |||
| 3.6 | |||
| 3,7 | |||
| 4,0 | |||
| 3.7 |
Рассмотрим двухфакторную линейную модель зависимости расходов на питание (у) от величины душевого дохода семей (x1) и размера семей (x2). Результаты расчетов с использованием электронных таблиц EXCEL представлены в таблице 7.
Таблица 7
| ВЫВОД ИТОГОВ | |||||
| Регрессионная статистика | |||||
| Множественный R | 0,997558 | ||||
| R-квадрат | 0,995121 | ||||
| Нормированный R-квадрат | 0,993495 | ||||
| Стандартная ошибка | 50,84286 | ||||
| Наблюдения | |||||
| df | SS | MS | F | Значимость F | |
| Регрессия | 611,9239 | 1,1612E-07 | |||
| Остаток | 15509,98 | 2584,996 | |||
| Итого | |||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | |
| Y-пересечение | -187,141 | 77,17245 | -2,42498 | 0,051513 | -375,97561 |
| Переменная X 1 | 0,071995 | 0,004463 | 16,13289 | 3,61E-06 | 0,06107576 |
| Переменная X 2 | 343,0222 | 29,40592 | 11,66507 | 2,39E-05 | 271,068413 |
Эконометрическая модель имеет следующий вид

Высокие значения коэффициента детерминации R 2 = 0,995 и значение F – критерия однозначно говорит об адекватности полученной модели исходным данным. Необходимо отметить, что эти значения намного превышают значения R 2 и F – критерия, которые были получены в модели с одним фактором. Таким образом, введение в модель еще одного фактора улучшает качество модели в целом.
В какой степени допустимо использовать критерий R 2 для выбора между несколькими регрессионными уравнениями? Дело в том, что при добавлении очередного фактора R 2 всегда возрастает и, если взять число факторов, равным числу наблюдений, то можно добиться того, что R 2 = 1. Но это вовсе не будет означать, что полученная эконометрическая модель будет иметь экономический смысл.
Попыткой устранить эффект, связанный с ростом R 2 при возрастании числа факторов, является коррекция значения R 2 с учетом используемых факторов в нашей модели.
Скорректированный (adjusted) R 2 имеет следующий вид:
 (2.17)
(2.17)
где n – объем выборки;
k – количество коэффициентов в уравнении регрессии.
Для нашего случая

В определенной степени использование скорректированного коэффициента детерминации R 2 более корректно для сравнения регрессий при изменении количества факторов.
В том случае, когда имеются одна независимая и одна зависимая переменные, естественной мерой зависимости является (выборочный) коэффициент корреляции между ними. Использование множественной регрессии позволяет обобщить это понятие на случай, когда имеется несколько независимых переменных. Корректировка здесь необходима по следующим очевидным соображениям. Высокое значение коэффициента корреляции между исследуемой зависимой и какой-либо независимой переменной может, как и раньше, означать высокую степень зависимости, но может быть обусловлено и другой причиной. Например, может существовать третья переменная, которая оказывает сильное влияние на две первые, что и является, в конечном счете, причиной их высокой коррелированности. Поэтому возникает естественная задача найти «чистую» корреляцию между двумя переменными, исключив (линейное) влияние других факторов. Это можно сделать с помощью коэффициента частной корреляции:


 (2.19)
(2.19)
 (2.20)
(2.20)
 (2.21)
(2.21)
Значения  вычисляются как
вычисляются как


Значения коэффициента частной корреляции лежат в интервале [-1,1], как у обычного коэффициента корреляции. Равенство этого коэффициента нулю означает, говоря нестрого, отсутствие прямого (линейного) влияния переменной X1 на У.
Существует тесная связь между коэффициентом частной корреляции и коэффи-циентом детерминации, а именно
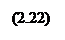


Влияние отдельных факторов в многофакторных моделях может быть охарактеризовано с помощью частных коэффициентов эластичности, которые в случае линейной двухфакторной модели рассчитываются по формулам:

Черта над символом, как и ранее, означает среднюю арифметическую. Частные коэффициенты эластичности показывают, насколько процентов изменится результативный признак, если значение одного из факторных признаков изменится на 1%, а значение другого факторного признака останется неизменным.
Для определения области возможных значений результативного показателя при известных значениях факторов, т.е. доверительного интервала прогноза, необходимо учитывать два возможных источника ошибок. Ошибки первого рода вызываются рассеиванием наблюдений относительно линии регрессии, и их можно учесть, в частности, величиной среднеквадратической ошибки аппроксимации изучаемого показателя с помощью регрессионной модели (Sy)
 (2.23)
(2.23)
Ошибки второго рода обусловлены тем, что в действительности жестко заданные в модели коэффициенты регрессии являются случайными величинами, распределенными по нормальному закону. Эти ошибки учитываются вводом поправочного коэффициента при расчете ширины доверительного интервала; формула для его расчета включает табличное значение t-статистики при заданном уровне значимости и зависит от вида регрессионной модели. Для линейной однофакторной модели величина отклонения от линии регрессии задается выражением (обозначим его R):
 , (2.24)
, (2.24)
где п – число наблюдений,
L – количество шагов вперед,
а – уровень значимости прогноза,
X – наблюдаемое значение факторного признака в момент t,
 – среднее значение наблюдаемого фактора,
– среднее значение наблюдаемого фактора,
 – прогнозное значение фактора на L шагов вперед.
– прогнозное значение фактора на L шагов вперед.
Таким образом, для рассматриваемой модели формула расчета нижней и верхней границ доверительного интервала прогноза имеет вид:

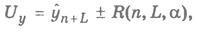
где UL означает точечную прогнозную оценку изучаемого результативного показателя по модели на L шагов вперед.
2.3.Некоторые особенности применения многофакторных
регрессионных моделей в эконометрическом анализе
Мультиколлинеарность
В предыдущих разделах были рассмотрены основные вопросы применения регрессионных моделей в эконометрическом анализе.
На практике исследователю нередко приходится сталкиваться с ситуацией, когда полученная им регрессия является «плохой», т.е. t-статистики большинства оценок малы, что свидетельствует о незначимости соответствующих независимых переменных. В то же время F-статистика может быть достаточно большой, что говорит о значимости регрессии в целом. Одна из возможных причин такого явления носит название мультиколлинеарности и возникает при наличии высокой корреляции между факторами.
Одним из условий классической регрессионной модели является предположение о линейной независимости объясняющих переменных. При нарушении этого условия, т.е. когда одна из переменных является линейной комбинацией их других, это называется полной коллинеарностью. В этой ситуации нельзя использовать метод наименьших квадратов (МНК). На практике полная коллинеарность встречается исключительно редко. Гораздо чаще приходится сталкиваться с ситуацией, когда между факторами имеется высокая степень корреляции. Тогда говорят о наличии мультиколлинеарности. В этом случае МНК-оценка (оценка методом наименьших квадратов) формально существует, но обладает «плохими» свойствами.
Мультиколлинеарность может возникать в силу разных причин. Например, несколько независимых переменных могут иметь общий временной тренд, относительно которого они совершают малые колебания. В частности, так может случиться, когда значения одной независимой переменной являются датированными значениями другой.
Методические основы корреляционно-регрессионного анализа
Понятие о корреляционно-регрессионном анализе
Убедившись при помощи аналитической группировки и расчета показателя эмпирического корреляционного отношения, что теснота связи между исследуемыми явлениями достаточно высока, можно и перейти к корреляционно-регрессионному анализу.
Экономические явления и процессы хозяйственной деятельности предприятий зависят от большого количества взаимодействующих и взаимообусловленных факторов.
В наиболее общем виде задача изучения взаимосвязей факторов состоит в количественной оценке их наличия и направления, а также характеристике силы и формы влияния одних факторов на другие. Для ее решения применяются две группы методов, одна из которых включает в себя методы корреляционного анализа, а другая – методы регрессионного анализа, объединенные в методы корреляционно-регрессионного анализа, что имеет под собой некоторые основания: наличие целого ряда общих вычислительных процедур, взаимодополнение при интерпретации результатов и др.
Задачи корреляционного анализа сводятся к измерению тесноты связи между варьирующими признаками и оценке факторов, оказывающих наибольшее влияние на результативный признак. К показателям, используемым для оценки тесноты связи, относятся эмпирическое корреляционное отношения, теоретическое корреляционное отношение, линейный коэффициент корреляции и т.п.
Задачи регрессионного анализа состоят в установлении формы зависимости между исследуемыми признаками (показателями), определении функции регрессии, использования уравнения регрессии для оценки неизвестных значений зависимой переменной. Найти уравнение регрессии –
значит по эмпирическим (фактическим) данным описать изменения взаимно коррелируемых величин.
Уравнение регрессии должно определить, каким будет среднее значение результативного признака у при том или ином значении факторного признака х, если остальные факторы, влияющие на у и не связанные с х не учитывать, т.е. абстрагироваться от них. Уравнение регрессии называют теоретической линией регрессии, а рассчитанные по нему значения результативного признака – теоретическими. Теоретические значения результативного признака обычно обозначаются y x (читается: «игрек, выровненный по икс») и рассматриваются как функция от х, т.е. y x = f (x). Иногда для простоты записи вместо y x пишут y’ или y.
Для аналитической связи между х и у используются следующие простые виды уравнений: y x = a0 + a1x (прямая); y x = a0 + a1x + a2x 2 (парабола второго порядка); y x = a0 + a1/x (гипербола); y x = a0 × a1 x (показательная или экспоненциальная функция); y x = a0 + b × lg x (логарифмическая функция) и др.
Обычно зависимость, выраженную уравнением прямой, называют линейной (или прямолинейной), а все остальные – криволинейными (см. табл. 7.1). Кроме того, различают парную и множественную (многофакторную) корреляцию (см. там же), а, следовательно, и, парную и множественную регрессии.
Корреляционно-регрессионный анализ, в частности многофакторный корреляционный анализ, состоит из нескольких этапов.
На первом этапе определяются факторы, оказывающие воздействие на изучаемый показатель, и отбираются наиболее существенные. От того, насколько правильно сделан отбор факторов, зависит точность выводов по итогам анализа. При отборе факторов придерживаются требований, представленных на рис. 8.1.
Требования к отбору факторов при корреляционнорегрессионном анализе:
- учитываются причинно-следственные связи между показателями
- отбираются самые значимые факторы, оказывающие решающее воздействие на результативный показатель (факторы, которые имеют критерий надежности по Стьюденту меньше табличного, не рекомендуется принимать в расчет)
- все факторы должны быть количественно измеримы
- не рекомендуется включать в корреляционную модель взаимосвязанные факторы (если парный коэффициент корреляции между двумя факторами больше 0,85, то по правилам корреляционного анализа один из них необходимо исключить, иначе это приведет к искажению результатов анализа)
- нельзя включать в корреляционную модель факторы, связь которых с результативным показателем носит функциональный характер
- в корреляционную модель линейного типа не рекомендуется включать факторы, связь которых с результативным показателем имеет криволинейный характер
Рисунок 8.1 – Перечень основных требований, учитываемых при отборе факторов, при корреляционно-регрессионном анализе
На втором этапе собирается и оценивается исходная информация, необходимая для корреляционного анализа. Собранная исходная информация должна быть проверена на точность (достоверность), однородность и соответствие закону нормального распределения. Критерием однородности информации служит среднеквадратическое отклонение и коэффициент вариации. Если вариация выше 33%, то это говорит о неоднородности информации и ее необходимо исключить или отбросить нетипичные наблюдения.
На третьем этапе изучается характер и моделируется связь между факторами и результативным показателем, т.е. подбирается и обосновывается математическое уравнение, которое наиболее точно выражает сущность исследуемой зависимости. Для обоснования функции используются те же приемы, что и для установления наличия связи: аналитические группировки, линейные графики и др. Если связь всех факторных показателей с результативным носит прямолинейный характер, то для записи этих зависимостей можно использовать линейную функцию: y x = a0 + a1x1 + a2x2 +. + anxn. Если связь между функцией и исследуемыми показателями носит криволинейный характер, то может быть использована степенная функция: y x = b0 × x1 b1 × x2 b2 × . × xn bn .
На четвертом этапе проводится расчет основных показателей связи корреляционного анализа. Рассчитываются матрицы парных и частных коэффициентов корреляции уравнения множественной регрессии, а также показатели, с помощью которых оценивается надежность коэффициентов корреляции и уравнения связи: критерий Стьюдента, критерий Фишера, множественные коэффициенты корреляции и др.
На пятом этапе дается статистическая оценка результатов корреляционного анализа и практическое их применение. Для этого дается оценка коэффициентов регрессии, коэффициентов эластичности и бета-коэффициентов.
Одним из основных условий применения и ограничения корреляционно-регрессионного метода является наличие данных по достаточно большой совокупности явлений. Обычно считают, что число наблюдений должно быть не менее чем в 5-6, а лучше – не менее чем в 10 раз больше числа факторов.
Парная линейная регрессия
Парная линейная зависимость – наиболее часто используемая форма связи между двумя коррелируемыми признаками, выражаемая при парной корреляции уравнением прямой:

где y x – выровненное среднее значение результативного признака;
х – значение факторного признака;
а0 и а1 – параметры уравнения;
а0 – значение у при х = 0;
а1 – коэффициент регрессии.
Коэффициент регрессии а1 показывает, на сколько (в абсолютном выражении) изменится результативный признак у при изменении факторного признака х на единицу.
Если а1 имеет положительный знак, то связь прямая, если отрицательный – связь обратная.
Параметры уравнения связи определяются способом (методом) наименьших квадратов (МНК) с помощью составленной и решенной системы двух уравнений с двумя неизвестными:
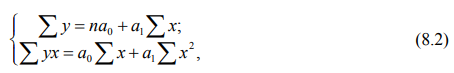
где n – число членов в каждом из двух сравниваемых рядов (число единиц совокупности);
Σx – сумма значений факторного признака;
Σx 2 – сумма квадратов значений факторного признака;
Σy – сумма значений результативного признака;
Σyx – сумма произведений значений факторного признака на значения результативного признака.
Для справки: суть метода наименьших квадратов заключается в следующем требовании: искомые теоретические значения результативного признака должны быть такими, при которых бы обеспечивалась минимальная сумма квадратов их отклонений от эмпирических значений.
Решив систему уравнений, получаем значения параметров уравнения связи, определяемые по формулам:

Если параметры уравнения определены правильно, то Σу = Σ y x.
Пример построения уравнения парной линейной регрессии
По данным таблицы 8.1 необходимо построить линейное уравнение регрессии, характеризующее зависимость выпуска продукции десяти предприятий одной отрасли от стоимости их основных производственных фондов.
| Номер предприятия | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| Стоимость ОПФ, млрд. руб. | 12 | 8 | 10 | 6 | 9 | 15 | 11 | 13 | 14 | 10 |
| Выпуск продукции, млрд. руб. | 5,6 | 4,0 | 4,0 | 2,4 | 3,6 | 5,0 | 4,6 | 6,5 | 7,0 | 4,5 |
Для расчета параметров уравнения регрессии и выровненных по х значений у построим вспомогательную таблицу 8.2.
| № завода (n) | Стоимость ОПФ (х), млрд. руб. | Выпуск продукции (у), млрд. руб. | x 2 | xу | y 2 | y x = 0,167 + 0,421x |
|---|---|---|---|---|---|---|
| 1 | 12 | 5,6 | 144 | 67,2 | 31,36 | 5,2 |
| 2 | 8 | 4 | 64 | 32 | 16 | 3,5 |
| 3 | 10 | 4 | 100 | 40 | 16 | 4,4 |
| 4 | 6 | 2,4 | 36 | 14,4 | 5,76 | 2,7 |
| 5 | 9 | 3,6 | 81 | 32,4 | 12,96 | 4 |
| 6 | 15 | 5 | 225 | 75 | 25 | 6,5 |
| 7 | 11 | 4,6 | 121 | 50,6 | 21,16 | 4,8 |
| 8 | 13 | 6,5 | 169 | 84,5 | 42,25 | 5,6 |
| 9 | 14 | 7 | 196 | 98 | 49 | 6,1 |
| 10 | 10 | 4,5 | 100 | 45 | 20,25 | 4,4 |
| Всего | 108 | 47,2 | 1236 | 539,1 | 239,74 | 47,2 |
| В среднем на 1 завод | 10,8 | 4,72 | 123,6 | 53,91 | 23,974 | х |
По формуле 8.3 параметр уравнения прямой: a0 = 0,167.
По формуле 8.4 коэффициент регрессии: a1 = 0,421.
По формуле 8.1 линейное уравнение связи между стоимостью основных производственных фондов и выпуском продукции имеет вид: y x = 0,167 + 0,421x
Коэффициент регрессии а1 = 0,421 показывает, что при увеличении стоимости основных производственных фондов на 1 млрд. руб. выпуск продукции в среднем увеличится на 0,421 млрд. руб.
Последовательно подставляя в полученное уравнение значения факторного признака х, находим выровненные значения результативного признака y x, показывающие, каким теоретически должен быть средний размер выпущенной продукции при данном размере основных производственных фондов (при прочих равных условиях). Выровненные (теоретические) значения выпуска продукции приведены в последней графе таблицы 8.2.
Правильность расчета параметров уравнения подтверждает равенство Σу = Σ y x (47,2 = 47,2).
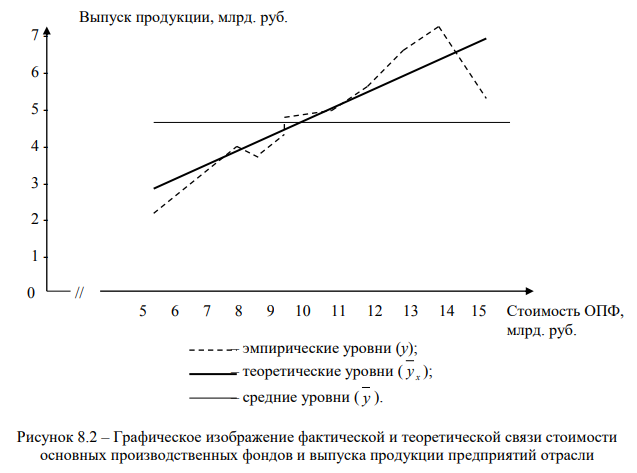
На рис. 8.2 представлены эмпирические, теоретические и средние уровни выпуска продукции предприятий отрасли, отличающихся по стоимости основных производственных фондов.
Для экономической интерпретации линейных и нелинейных связей между двумя исследуемыми явлениями часто используют рассчитанные на основе уравнений регрессии коэффициенты эластичности.
Коэффициент эластичности показывает, на сколько процентов изменится в среднем результативный признак у при изменении факторного признака х на 1%.
Для линейной зависимости коэффициент эластичности (ε) определяется:
– для отдельной единицы совокупности по формуле:

– в целом для совокупности по формуле:

Пример расчета коэффициентов эластичности
По данным таблицы 8.2 необходимо найти коэффициенты эластичности для отдельных предприятий и в среднем по отрасли.
По формуле 8.5 коэффициент эластичности на первом предприятии равен: ε1 = 0,97, т.е. 1% прироста стоимости основных производственных фондов обеспечивает прирост выпуска продукции на этом предприятии на 0,97%; …; на пятом предприятии – на 0,95%; …; на десятом предприятии – на 0,96%.
По формуле 8.6 коэффициент эластичности равен:
ε = 0,963. Это означает, что при увеличении стоимости основных производственных фондов в целом по предприятиям отрасли на 1%, выпуск продукции увеличится в среднем на 0,963%. Определение тесноты связи в корреляционно-регрессионном анализе основывается на правиле сложения дисперсий, как и в методе аналитической группировки. Но в отличие от него, где для оценки линии регрессии используют групповые средние результативного признака, в корреляционно-регрессионном анализе для этой цели используют теоретические значения результативного признака.
Наглядно представить и обосновать корреляционно-регрессионный анализ позволяет график.
На графике на рис. 8.2 проведены три линии: у – ломанная линия фактических данных; y x – прямая наклонная линия теоретических значений у при абстрагировании от влияния всех факторов, кроме фактора х (переменная средняя); y – прямая горизонтальная линия, из среднего значения которой исключено влияние на у всех без исключения факторов (постоянная средняя).
Несовпадение линии переменной средней y x с линией постоянной средней y поясняется влиянием факторного признака х, что, в свою очередь, свидетельствует о наличии между признаками у и х неполной, нефункциональной связи. Для определения тесноты этой связи необходимо рассчитать дисперсию отклонений у и y x, то есть остаточную дисперсию, которая обусловлена влиянием всех факторов, кроме фактора х. Разница между общей и остаточной дисперсиями дает теоретическую (факторную) дисперсию, которая измеряет вариацию, обусловленную фактором х.
На сопоставлении этой разницы с общей дисперсией построен индекс корреляции или теоретическое корреляционное отношение (R), которое определяется по формулам:


где σ 2 общ – общая дисперсия;
σ 2 ост – остаточная дисперсия;
σ 2 y x – факторная (теоретическая) дисперсия.
Факторную дисперсию по теоретическим значениям исчисляют по формуле:

Остаточную дисперсию определяют по формулам:


Коэффициент детерминации (R 2 ) характеризует ту часть вариации результативного признака у, которая соответствует линейному уравнению регрессии (т.е. обусловлена вариацией факторного признака) и исчисляется по формуле:

Индекс корреляции принимает значения от 0 до 1. Когда R = 0, то связи между вариацией признаков х и у нет. Остаточная дисперсия равняется общей, а теоретическая дисперсия равняется нулю. Все теоретические значения y x совпадают со средними значениями y , линия y x на графике совпадает с линией y , то есть принимает горизонтальное положение. При R = 1 теоретическая дисперсия равна общей, а остаточная равна нулю, фактические значения у совпадают с теоретическими y x, следовательно, связь между исследуемыми признаками линейно-функциональная.
Индекс корреляции пригоден для измерения тесноты связи при любой ее форме. Он, как и эмпирическое корреляционное отношение, измеряет только тесноту связи и не показывает ее направление.
Для измерения тесноты связи и определения ее направления при линейной зависимости используется линейный коэффициент корреляции (r), определяемый по формулам:


Значение r колеблется в пределах от -1 до +1. Положительное значение r означает прямую связь между признаками, а отрицательное – обратную.
Оценка тесноты связи между признаками проводится по данным таблицы 8.3.
| Сила связи | Значение r при наличии | |
|---|---|---|
| прямой связи | обратной связи | |
| Слабая | 0,1-0,3 | (-0,1)-(-0,3) |
| Средняя | 0,3-0,7 | (-0,3)-(-0,7) |
| Тесная | 0,7-0,99 | (-0,7)-(-0,99) |
Проверка надежности (существенности) связи в корреляционно-регрессионном анализе осуществляют при помощи тех же самых критериев и процедур, что и в аналитической группировке.
Фактическое значение F-критерия определяют по формуле:

Степени свободы k1 и k2 зависят от числа параметров уравнения регрессии (m) и количества единиц исследуемой совокупности (n) и рассчитываются по формулам:
Надежность связи между признаками, т.е. надежность коэффициента детерминации R 2 проверяют при помощи таблицы по F-критерию для 5%-ного уровня значимости (см. табл. 7.10).
Для установления достоверности рассчитанного линейного коэффициента корреляции используют критерий Стьюдента, рассчитываемый по формуле

где μr – средняя ошибка коэффициента корреляции, рассчитываемая по формуле:

При достаточно большом числе наблюдений (n > 50) коэффициент корреляции можно считать достоверным, если он превышает свою ошибку в 3 и больше раз, а если он меньше 3, то связь между исследуемыми признаками у и х не доказана.
Пример расчета индекса корреляции (теоретического корреляционного отношения), коэффициента детерминации, линейного коэффициента корреляции и критериев Фишера и Стьюдента
По данным таблицы 8.2 необходимо оценить силу и направление связи между стоимостью основных производственных фондов предприятий и выпуском продукции, а также проверить надежность рассчитанного коэффициента детерминации и достоверность линейного коэффициента корреляции.
Для расчета индекса корреляции, используемого для оценки тесноты связи между результативным (выпуском продукции) и факторным (стоимостью ОПФ) признаками рассчитаем ряд вспомогательных показателей.
По формуле 8.9 по данным таблицы 7.15 факторная дисперсия равна: 1,238.
Общую дисперсию исчислим по данным таблицы 8.2, используя способ разности (формула 5.12): = 1,696 – 1,238 = 0,458.
Таким образом, по формулам 8.7 и 8.8 индекс корреляции равен: R = 0,854, что свидетельствует о тесной связи между выпуском продукции и стоимостью основных производственных фондов предприятий (см. табл. 5.10).
По формуле 8.12 коэффициент детерминации равен: 0,730. Это говорит о том, что в обследуемой совокупности предприятий 73,0% вариации выпуска продукции объясняется разным уровнем их оснащенности основными производственными фондами, т.е. вариация выпуска продукции на 73,0% обусловлена вариацией стоимости основных производственных фондов.
Для расчета линейного коэффициента корреляции, позволяющего оценить не только силу, но и направление связи между исследуемыми признаками, найдем ряд промежуточных показателей.
Преобразовав формулу 5.12 и используя данные таблицы 8.2, получим среднее квадратическое отклонение факторного признака: 2,638и среднее квадратическое отклонение результативного признака 1,302.
Таким образом, по формуле 8.13 (8.14) и данным таблицы 8.2 линейный коэффициент корреляции равен: 0,854, что подтверждает наличие тесной (сильной) прямой связи между стоимостью основных производственных фондов и выпуском продукции предприятий. Абсолютная величина линейного коэффициента корреляции практически совпадает с индексом корреляции (отклонение составляет 0,01).
Для оценки надежности связи между выпуском продукции и стоимостью основных производственных фондов предприятий найдем фактическое значение F-критерия.
Так как линейное уравнение имеет только два параметра, то по формуле 8.16 степень свободы k1 = 2 – 1 = 1, а потому, что обследованием было охвачено 10 предприятий по формуле 8.17 степень свободы k2 = 10 – 2 = 8.
По формуле 8.15 фактическое значение F-критерия равно: 19,68.
По данным таблицы 7.10 с вероятностью 0,95 критическое значение Fт = 5,32, что значительно меньше полученного фактического значения F-критерия. Это подтверждает надежность корреляционной связи между исследуемыми признаками.
Для установления достоверности рассчитанного линейного коэффициента корреляции найдем значение критерия Стьюдента. Для этого по формуле 8.19 исчислим среднюю ошибку коэффициента корреляции: 0,092.
По формуле 8.18 критерий Стьюдента равен: 9,27. Так как 9,27 > 3, то это дает основание считать, что рассчитанный линейный коэффициент корреляции достаточно точно характеризует тесноту связи между исследуемыми признаками.
Множественная регрессия
На практике на результативный признак, как правило, влияет не один, а несколько факторов.
Между факторами существуют сложные взаимосвязи, поэтому их влияние на результативный признак комплексное и его нельзя рассматривать как простую сумму изолированных влияний.
Многофакторный корреляционно-регрессионный анализ позволяет оценить степень влияния на исследуемый результативный показатель каждого из введенных в модель факторов при фиксированных на среднем уровне других факторах. При этом важным условием является отсутствие функциональной связи между факторами.
Математически задача корреляционно-регрессионного анализа сводится к поиску аналитического выражения, которое как можно лучше отражало бы связь факторных признаков с результативным признаком, т.е. к нахождению функции: y x = f(x1,x2,x3. xn).
Множественная регрессия – это уравнение статистической связи результативного признака (зависимой переменной) с несколькими факторами (независимыми переменными).
Наиболее сложной проблемой является выбор формы связи, выражающейся аналитическим уравнением, на основе которого по существующим факторам определяются значения результативного признака – функции. Эта функция должна лучше других отражать реально существующие связи между исследуемым показателем и факторами. Эмпирическое обоснование типа функции при помощи графического анализа связей для многофакторных моделей практически непригодно.
Форму связи можно определить путем перебора функций разных типов, но это связано с большим количеством лишних расчетов. Принимая во внимание, что любую функцию нескольких переменных можно путем логарифмирования или замены переменных привести к линейному виду, уравнение множественной регрессии можно выразить в линейной форме:
Параметры уравнения находят методом наименьших квадратов.
Так, для расчета параметров уравнения линейной двухфакторной регрессии, представленного формулой:
где y x – расчетные значения результативного признака-функции;
х1 и х2 – факторные признаки;
а0, а1 и а2 — параметры уравнения, методом наименьших квадратов необходимо решить систему нормальных уравнений:
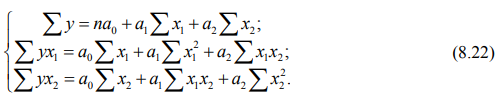
Каждый коэффициент уравнения (а1, а2, …, аn) показывает степень влияния соответствующего фактора на результативный показатель при фиксированном положении остальных факторов, т.е., как изменится результативный показатель при изменении отдельного факторного показателя на единицу. Свободный член уравнения множественной регрессии экономического содержания не имеет.
Если, подставляя в уравнение регрессии значения х1 и х2, получаем соответствующие значения переменной средней, достаточно близко воссоздающие значения фактических уровней результативного признака, то выбор формы математического выражения корреляционной связи между тремя исследуемыми факторами сделан правильно.
Однако на основе коэффициентов регрессии нельзя судить, какой из факторных признаков больше влияет на результативный признак, поскольку коэффициенты регрессии между собой не сравнимы, ибо не сопоставимы по сути отражаемые ими явления, и они выражены разными единицами измерения.
С целью выявления сравнимой силы влияния отдельных факторов и резервов, заложенных в них, статистика рассчитывает частные коэффициенты эластичности, а также бета-коэффициенты.
Частные коэффициенты эластичности (εi) рассчитываются по формуле:

где аi – коэффициент регрессии при i-ом факторе;
x i – среднее значение i-го фактора;
y – среднее значение результативного фактора.
Бета-коэффициенты (βi) рассчитываются по формуле:

где σxi – среднее квадратическое отклонение i-го фактора;
σy – среднее квадратическое отклонение результативного признака.
Частные коэффициенты эластичности показывают, на сколько процентов в среднем изменится результативный признак при изменении на 1% каждого фактора и при фиксированном положении других факторов.
Для определения факторов, имеющих наибольшие резервы улучшения исследуемого признака, с учетом степени вариации факторов, положенных в уравнение множественной регрессии, рассчитывают частные β-коэффициенты, показывающие на какую часть среднего квадратического отклонения изменяется результативный признак при изменении соответствующего факторного признака на величину его среднего квадратического отклонения.
Для характеристики тесноты связи при множественной линейной корреляции используют множественный коэффициент корреляции (R), рассчитываемый по формуле:
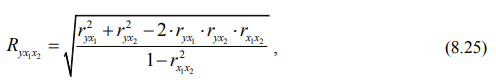
где ryx1, ryx2, rx1x2 – парные коэффициенты линейной корреляции, позволяющие оценить влияние каждого фактора отдельно на результативный показатель, и определяемые по формулам:
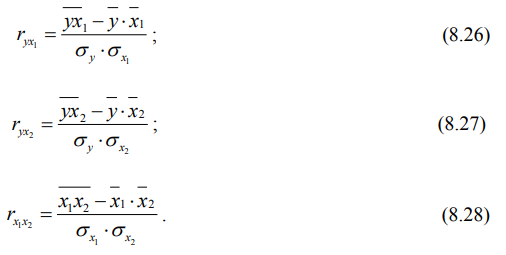
Множественный коэффициент корреляции колеблется в пределах от 0 до + 1 и интерпретируется так же, как и теоретическое корреляционное отношение.
Совокупный коэффициент множественной детерминации показывает, какую часть общей корреляции составляют колебания под влиянием факторов х1, х2, …, хn, положенных в многофакторную модель для исследования.
На основе парных коэффициентов корреляции находятся частные коэффициенты корреляции первого порядка, показывающие связь каждого фактора с исследуемым показателем в условиях комплексного взаимодействия факторов, рассчитываемые по формулам
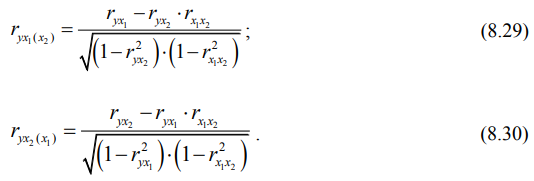
С целью более глубокого анализа взаимосвязи общественных явлений и их признаков увеличивают количество существенных факторов, включаемых в модель исследуемого показателя, и строят многофакторные уравнения регрессии. Их рассчитывают при помощи персональных компьютеров. Современнон программное обеспечение позволяет за относительно короткое время получить достаточно много вариантов уравнений. В ЭВМ вводятся значения зависимой переменной у и матрица независимых переменных х, принимается форма уравнения, например линейная. Ставится задача включить в уравнение k наиболее значимых х. В результате получим уравнение регрессии с k наиболее значимыми факторами. Аналогично можно выбрать наилучшую форму связи. Этот традиционный прием, называемый пошаговой регрессией, позволяет быстро и достаточно точно определиться с уравнением множественной регрессии.
Пример расчета параметров уравнения множественной регрессии, частных коэффициентов эластичности и бета-коэффициентов, множественного коэффициента корреляции и частных коэффициентов корреляции первого порядка
В таблице 8.4 представлены данные о производительности труда (выработке продукции на одного работающего), доле бракованной продукции в общем объеме ее производства и средней себестоимости 1 т продукции по двадцати пяти предприятиям, специализирующимся на выпуске кондитерских изделий (печенья в ассортименте).
Необходимо установить зависимость средней себестоимости 1 т продукции от двух факторов: выработки продукции на одного работающего и доли бракованной продукции в общем объеме ее производства. С целью выявления сравнимой силы влияния этих факторов, а также резервов повышения средней себестоимости 1 т продукции, заложенных в производительности труда и удельном весе брака, нужно рассчитать частные коэффициенты эластичности и бетакоэффициенты. Кроме того, следует оценить силу влияния обозначенных факторов, как по отдельности, так и вместе на заданный результативный признак, определить какую долю вариации средней себестоимости 1 т продукции обусловливают только выработка и только процент брака; охарактеризовать связь каждого фактора с исследуемым показателем в условиях комплексного взаимодействия факторов.
| № предприятия | Выработка продукции на одного работающего, т | Удельный вес брака, % | Средняя себестоимость 1 т продукции, руб. |
|---|---|---|---|
| n | х1 | х2 | у |
| 1 | 2 | 3 | 4 |
| 1 | 14,6 | 4,2 | 2398 |
| 2 | 13,5 | 6,7 | 2546 |
| 3 | 21,6 | 5,5 | 2620 |
| 4 | 17,4 | 7,7 | 2514 |
| 5 | 44,8 | 1,2 | 1589 |
| 6 | 111,9 | 2,2 | 1011 |
| 7 | 20,1 | 8,4 | 2598 |
| 8 | 28,1 | 1,4 | 1864 |
| 9 | 22,3 | 4,2 | 2041 |
| 10 | 25,3 | 0,9 | 1986 |
| 11 | 56,0 | 1,3 | 1701 |
| 12 | 40,2 | 1,8 | 1736 |
| 13 | 40,6 | 3,3 | 1974 |
| 14 | 75,8 | 3,4 | 1721 |
| 15 | 27,6 | 1,1 | 2018 |
| 16 | 88,4 | 0,1 | 1300 |
| 17 | 16,6 | 4,1 | 2513 |
| 18 | 33,4 | 2,3 | 1952 |
| 19 | 17,0 | 9,3 | 2820 |
| 20 | 33,1 | 3,3 | 1964 |
| 21 | 30,1 | 3,5 | 1865 |
| 22 | 65,2 | 1,0 | 1752 |
| 23 | 22,6 | 5,2 | 2386 |
| 24 | 33,4 | 2,3 | 2043 |
| 25 | 19,7 | 2,7 | 2050 |
Для расчета параметров уравнения линейной двухфакторной регрессии и теоретических значений результативного признака (средней себестоимости 1 т продукции) составим вспомогательную таблицу 8.5.
| n | х1 | х2 | у | у×х1 | у×х2 | х1 2 | х2 2 | y 2 | х1×х2 | y x |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 1 | 14,6 | 4,2 | 2398 | 35010,8 | 10071,6 | 213,16 | 17,6 | 5750404 | 61,32 | 2330 |
| 2 | 13,5 | 6,7 | 2546 | 34371,0 | 17058,2 | 182,25 | 44,9 | 6482116 | 90,45 | 2559 |
| 3 | 21,6 | 5,5 | 2620 | 56592,0 | 14410,0 | 466,56 | 30,3 | 6864400 | 118,80 | 2371 |
| 4 | 17,4 | 7,7 | 2514 | 43743,6 | 19357,8 | 302,76 | 59,3 | 6320196 | 133,98 | 2607 |
| 5 | 44,8 | 1,2 | 1589 | 71187,2 | 1906,8 | 2007,04 | 1,4 | 2524921 | 53,76 | 1756 |
| 6 | 111,9 | 2,2 | 1011 | 113130,9 | 2224,2 | 12521,61 | 4,8 | 1022121 | 246,18 | 1152 |
| 7 | 20,1 | 8,4 | 2598 | 52219,8 | 21823,2 | 404,01 | 70,6 | 6749604 | 168,84 | 2640 |
| 8 | 28,1 | 1,4 | 1864 | 52378,4 | 2609,6 | 789,61 | 2,0 | 3474496 | 39,34 | 1946 |
| 9 | 22,3 | 4,2 | 2041 | 45514,3 | 8572,2 | 497,29 | 17,6 | 4165681 | 93,66 | 2250 |
| 10 | 25,3 | 0,9 | 1986 | 50245,8 | 1787,4 | 640,09 | 0,8 | 3944196 | 22,77 | 1931 |
| 11 | 56,0 | 1,3 | 1701 | 95256,0 | 2211,3 | 3136,00 | 1,7 | 2893401 | 72,80 | 1649 |
| 12 | 40,2 | 1,8 | 1736 | 69787,2 | 3124,8 | 1616,04 | 3,2 | 3013696 | 72,36 | 1856 |
| 13 | 40,6 | 3,3 | 1974 | 80144,4 | 6514,2 | 1648,36 | 10,9 | 3896676 | 133,98 | 1983 |
| 14 | 75,8 | 3,4 | 1721 | 130451,8 | 5851,4 | 5745,64 | 11,6 | 2961841 | 257,72 | 1629 |
| 15 | 27,6 | 1,1 | 2018 | 55696,8 | 2219,8 | 761,76 | 1,2 | 4072324 | 30,36 | 1925 |
| 16 | 88,4 | 0,1 | 1300 | 114920,0 | 130,0 | 7814,56 | 0,0 | 1690000 | 8,84 | 1211 |
| 17 | 16,6 | 4,1 | 2513 | 41715,8 | 10303,3 | 275,56 | 16,8 | 6315169 | 68,06 | 2300 |
| 18 | 33,4 | 2,3 | 1952 | 65196,8 | 4489,6 | 1115,56 | 5,3 | 3810304 | 76,82 | 1970 |
| 19 | 17,0 | 9,3 | 2820 | 47940,0 | 26226,0 | 289,00 | 86,5 | 7952400 | 158,10 | 2751 |
| 20 | 33,1 | 3,3 | 1964 | 65008,4 | 6481,2 | 1095,61 | 10,9 | 3857296 | 109,23 | 2060 |
| 21 | 30,1 | 3,5 | 1865 | 56136,5 | 6527,5 | 906,01 | 12,3 | 3478225 | 105,35 | 2109 |
| 22 | 65,2 | 1,0 | 1752 | 114230,4 | 1752,0 | 4251,04 | 1,0 | 3069504 | 65,20 | 1528 |
| 23 | 22,6 | 5,2 | 2386 | 53923,6 | 12407,2 | 510,76 | 27,0 | 5692996 | 117,52 | 2335 |
| 24 | 33,4 | 2,3 | 2043 | 68236,2 | 4698,9 | 1115,56 | 5,3 | 4173849 | 76,82 | 1970 |
| 25 | 19,7 | 2,7 | 2050 | 40385,0 | 5535,0 | 388,09 | 7,3 | 4202500 | 53,19 | 2146 |
| Всего | 919,3 | 87,1 | 50962 | 1653422,7 | 198293,2 | 48693,93 | 450,3 | 108378316 | 2435,45 | 50962 |
В среднем на 1 предприятие х 36,8 3,5 2038 66136,9 7931,7 1947,76 18,01 4335133 97,42 2038
Подставим данные таблицы 8.5 в систему нормальных уравнений 8.22 и получим систему уравнений:
⌈ 50962 = 25 a0 + 919,3 a1 + 87,1 a2 ;
〈 165322,7 = 919.3 a0 + 48693.93 a1 + 2435,45 a2 ;
⌊ 198293,2 = 87,1 a0 + 2435,45 a1 + 450,3 a2 .
Таким образом, уравнение связи, определяющее зависимость средней себестоимости 1 т продукции предприятий (результативного признака) от производительности труда их работников и удельного веса брака (двух факторных признаков), имеет вид (формула 8.21):
Подставляя в полученное уравнение значения х1 и х2, получаем соответствующие значения переменной средней (последняя графа таблицы 7.18), которые достаточно близко воссоздают значения фактических уровней себестоимости продукции. Это свидетельствует про правильный выбор формы математического выражения корреляционной связи между тремя исследуемыми факторами.
Значения параметров уравнения линейной двухфакторной регрессии показывают, что с увеличением выработки одного работника на 1 т, средняя себестоимость 1 т продукции снижается на 10,31 руб., а при увеличении процента брака на 1, средняя себестоимость 1 т продукции возрастает на 87,40 руб.
Вместе с тем полученные значения коэффициентов регрессии не позволяют сделать вывод о том, какой из двух факторных признаков оказывает большее влияние на результативный признак, поскольку между собой эти факторные признаки несравнимы.
По формуле 8.23 на основании данных таблицы 8.5 и полученных значений коэффициентов регрессии рассчитаем частные коэффициенты эластичности:
Анализ частных коэффициентов эластичности показывает, что в абсолютном выражении наибольшее влияние на среднюю себестоимость 1 т продукции оказывает выработка работников предприятий – фактор х1, с увеличением которой на 1% средняя себестоимость 1 т продукции снижается на 0,19%. При увеличении удельного веса бракованной продукции на 1% средняя себестоимость 1 т продукции повышается на 0,15%.
Для расчета β–коэффициентов необходимо рассчитать соответствующие средние квадратические отклонения.
Преобразовав формулу 5.12 и используя данные таблицы 8.5, получим средние квадратические отклонения факторных признаков, а также среднее квадратическое отклонение результативного признака:
Тогда по формуле 8.24 значения β–коэффициентов равны:
Анализ β-коэффициентов показывает, что на среднюю себестоимость продукции наибольшее влияние (а значит и наибольшие резервы ее снижения) из двух исследуемых факторов с учетом их вариации имеет фактор х1 – выработка работников, ибо ему соответствует большее по модулю значение β-коэффициента.
Для характеристики тесноты связи между себестоимостью 1 т продукции, выработкой работников и удельным весом бракованной продукции используется множественный коэффициент корреляции, для расчета которого предварительно нужно получить парные коэффициенты корреляции.
По формулам 8.26-8.28 на основе данных таблицы 8.5 и значений средних квадратических отклонений факторных и результативного признаков парные коэффициенты корреляции соответственно равны:
Высокие значения парных коэффициентов корреляции свидетельствуют о сильном влиянии (отдельно) выработки работников и уровня брака на среднюю себестоимость 1 т продукции.
Отметим, что отрицательное значение парного коэффициента корреляции между факторными признаками свидетельствует об обратной зависимости между выработкой и количеством бракованной продукции. Тот факт, что парный коэффициент корреляции между выработкой работников и уровнем бракованной продукции равный -0,519, по модулю меньше 0,85 (см. рис. 8.1), говорит о правильном включении этих факторов в одну корреляционную модель.
По формуле 8.25 множественный коэффициент корреляции равен: Ryx1x2 = 0,822. Он показывает, что между двумя факторными и результативным признаками существует тесная связь.
Совокупный коэффициент множественной детерминации (0,676) свидетельствует про то, что вариация средней себестоимости 1 т продукции на 67,6% обусловлена двумя факторами, введенными в корреляционную модель: изменением выработки работников и уровня брака. Это означает, что выбранные факторы существенно влияют на исследуемый показатель.
На основе парных коэффициентов корреляции по формулам 8.29 и 8.30 рассчитаем частные коэффициенты корреляции первого порядка, отражающие связь каждого фактора с исследуемым показателем (средней себестоимостью 1 т продукции) в условиях комплексного взаимодействия факторов:
http://poisk-ru.ru/s54907t1.html
http://be5.biz/ekonomika/s015/8.html