Экономическая интерпретация коэффициента регрессии
Федеральное агентство по образованию ГОУ ВПО
Всероссийский заочный финансово-экономический институт
К.ф. – м.н., доцент кафедры: Василенко В.В.
Студент: Чмиль А.А., ФиК, 3 Курс
По предприятиям легкой промышленности региона получена информация, характеризующая зависимость объема выпуска продукции (Y, млн.руб.) от объема капиталовложений (X, млн.руб.).
| Xi | Yi |
| 33 | 43 |
| 17 | 27 |
| 23 | 32 |
| 17 | 29 |
| 36 | 45 |
| 25 | 35 |
| 39 | 47 |
| 20 | 32 |
| 13 | 22 |
| 12 | 24 |
| n | Xi | Yi | Yi*Xi | Xi2 | Yi2 | Y(xi) | Yi — Y(xi) | (Yi — Y(xi))2 | A |
| 1 | 33 | 43 | 1419 | 1089 | 1849 | 42,23428 | 0,765721183 | 0,5863289 | 1,78% |
| 2 | 17 | 27 | 459 | 289 | 729 | 27,69234 | -0,692335546 | 0,4793285 | 2,56% |
| 3 | 23 | 32 | 736 | 529 | 1024 | 33,14556 | -1,145564273 | 1,3123175 | 3,58% |
| 4 | 17 | 29 | 493 | 289 | 841 | 27,69234 | 1,307664454 | 1,7099863 | 4,51% |
| 5 | 36 | 45 | 1620 | 1296 | 2025 | 44,96089 | 0,03910682 | 0,0015293 | 0,09% |
| 6 | 25 | 35 | 875 | 625 | 1225 | 34,96331 | 0,036692818 | 0,0013464 | 0,10% |
| 7 | 39 | 47 | 1833 | 1521 | 2209 | 47,68751 | -0,687507544 | 0,4726666 | 1,46% |
| 8 | 20 | 32 | 640 | 400 | 1024 | 30,41895 | 1,581050091 | 2,4997194 | 4,94% |
| 9 | 13 | 22 | 286 | 169 | 484 | 24,05685 | -2,056849728 | 4,2306308 | 9,35% |
| 10 | 12 | 24 | 288 | 144 | 576 | 23,14798 | 0,852021726 | 0,725941 | 3,55% |
| сумма | 235 | 336 | 8649 | 6351 | 11986 | 336 | 0,00 | 12,019795 | 31,93% |
| средняя | 23,5 | 33,6 | 864,9 | 635,1 | 1198,6 | 33,6 | 0,00 | 1,2019795 | 3,19% |
| δ | 9,102198 | 8,345058 | — | — | — | — | — | — | — |
| δ 2 | 82,85 | 69,64 | — | — | — | — | — | — | — |
Вспомогательная таблица для расчетов параметров линейной регрессии. Табл.2
Найти параметры уравнения линейной регрессии, дать экономическую интерпретацию коэффициента регрессии.
После проведенных расчетов линейная модель имеет вид:
Y = 12,24152 + 0,908871x , коэффициент регрессии составил 0,908871. Экономический смысл параметра регрессии заключается в следующем: с увеличением капиталовложений на 1 единицу выпуск продукции увеличивается на 0,908871 единиц.
Вычислить остатки; найти остаточную сумму квадратов; оценить дисперсию остатков; построить график остатков.
Вычисленные остатки приведены в таблице 2. Остаточная сумма квадратов составила 12,02. Дисперсия остатков составила:
Dост = ((Y- Yср.) 2 — (Y(xi) — Yср.) 2 )/ (n – 2) = 1,502474351.

График остатков. Рис.1
Проверить выполнение предпосылок МНК.
Остатки гомоскедастичны, автокорреляция отсутствует (корреляция остатков и фактора Х равна нулю, рис.1), математическое ожидание остатков равно нулю, остатки нормально распределены.

Корреляция остатков и переменной Х. Рис 2.
Осуществить проверку значимости параметров уравнения регрессии с помощью t – критерия Стьюдента (α = 0,05).
Найдем стандартную ошибку коэффициента регрессии:
mb = (Dост. / ∑(x – xср.) 2 ) ½ = 0,042585061
Теперь проведем оценку значимости коэффициента регрессии:
tb = b / mb= 21,3424949
При α = 0,05 и числе степеней свободы (n – 2) tтабл. = 2,3060. Так как фактическое значение t – критерия больше табличного, то гипотезу о несущественности коэффициента можно отклонить. Доверительный интервал для коэффицента регрессии определяется как b ± t* mb. Для коэффициента регрессии b границы составят: 0,908871 – 2,3060*0,042585061 ≤ b ≤ 0,908871+2,3060*0,042585061
0,81067 ≤ b ≤ 1,0070722
Далее определим стандартную ошибку параметра a:
ma = (Dост.*( ∑x 2 / (n*∑(x – xср.) 2 )) 1/2 = 1,073194241
Мы видим, что фактическое значение параметра а больше, чем табличное, следовательно, гипотезу о несущественности параметра а можно отклонить. Доверительный интервал составит: a± t* ma. Границы параметра составят:
9,766735 ≤ a ≤14,716305
Проверим значимость линейного коэффициента корреляции на основе ошибки коэффициента корреляции:
mr = ((1 – r 2 ) / (n – 2)) 1/2 = 0,046448763
Фактическое значение t – критерия Стьюдента определяется:
tr = (r / (1 – r 2 )) * (n – 2) 1/2 = 21,3424949
Значение tr фактическое больше табличного, следовательно при уровне значимости α = 0,05 и степени свободы (n – 2), коэффициент корреляции существенно отличен от нуля и зависимость является достоверной.
Вычислить коэффициент детерминации, проверить значимость уравнения регрессии с помощью f – критерия Фишера (α = 0,05), найти среднюю относительную ошибку аппроксимации. Сделать вывод о качестве модели.
R 2 = Rxy 2 = 0,98274 – детерминация.
F = (R 2 /(1 – R 2 ))*((n – m – 1)/m) = 455,5020887
Fтабл. 5,32 2 / ∑(x – xср ) 2 ) 1/2 = 1,502474351*(1+(1/10)+ ((31,2 – 23,5) 2 / 828,50)) 1/2 = 1,6262596 млн.руб.
Предельная ошибка прогноза, которая в 90% случаев не будет превышена, составит:
Доверительный интервал прогноза:
γур min = 40,598295 – 3,7501546 = 36,848141 млн.руб.
γур max = 40,598295 + 3,7501546 = 44,348449 млн.руб.
Среднее значение показателя составит:
Yp = (36,848141 + 44,348449) / 2 = 40,598295 млн.руб.
Представить графически фактические и модельные значения Y точки прогноза

График фактических и прогнозируемых параметров. Рис.3
Составить уравнения нелинейной регрессии:
Построить графики построенных уравнений регрессии.
Y(x) = 54,1842 + (-415,755) * 1/x – гиперболическое уравнение регрессии.
Y(x) = 4,746556 * X 0,625215 – степенное уравнение регрессии.
Y(x) = 17,38287 * 1,027093 X показательное уравнение регрессии.
Графикимоделей представлены ниже на рисунках 4,5 и 6.



Для указанных моделей найти коэффициенты детерминации, коэффициент эластичности и средние относительные ошибки аппроксимации. Сравнить модели по этим характеристикам и сделать выводы.
Коэффициенты (индексы) детерминации:
R 2 показ = Rxy = 0,959136358
Эгип = -b / (a * x + b) = 0,484804473
Эстеп = b = 0,625215
Эпоказ = x * lnb = 0,628221
Средние относительные ошибки аппроксимации:
А = 1/n * ∑ |y – yxi | * 100%
Как мы видим, степенная регрессия наиболее интересна в экономическом смысле, потому что у нее самый низкий показатель средней ошибки аппроксимации, самый высокий показатель эластичности и детерминации. Это говорит о том, что у степенной регрессионной модели высокое качество, она предлагает наибольшую прибыль и более зависима от фактора Х (капиталовложений).
Список использованной литературы
1. Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курашева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2001. – 192.: ил.
2. Эконометрика. Учебник для вузов.; Под ред. чл. – кор. РАН И.И. Елисеевой. – М.: Финансы и статистика, 2002. – 344.
Корреляция и регрессия
Линейное уравнение регрессии имеет вид y=bx+a+ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид:
10a + 356b = 49
356a + 2135b = 9485
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 68.16, a = 11.17
Уравнение регрессии:
y = 68.16 x — 11.17
1. Параметры уравнения регрессии.
Выборочные средние.
1.1. Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 Y фактором X весьма высокая и прямая.
1.2. Уравнение регрессии (оценка уравнения регрессии).
Линейное уравнение регрессии имеет вид y = 68.16 x -11.17
Коэффициентам уравнения линейной регрессии можно придать экономический смысл. Коэффициент уравнения регрессии показывает, на сколько ед. изменится результат при изменении фактора на 1 ед.
Коэффициент b = 68.16 показывает среднее изменение результативного показателя (в единицах измерения у ) с повышением или понижением величины фактора х на единицу его измерения. В данном примере с увеличением на 1 единицу y повышается в среднем на 68.16.
Коэффициент a = -11.17 формально показывает прогнозируемый уровень у , но только в том случае, если х=0 находится близко с выборочными значениями.
Но если х=0 находится далеко от выборочных значений x , то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие значения x , можно определить выровненные (предсказанные) значения результативного показателя y(x) для каждого наблюдения.
Связь между у и x определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
1.3. Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
В нашем примере коэффициент эластичности больше 1. Следовательно, при изменении Х на 1%, Y изменится более чем на 1%. Другими словами — Х существенно влияет на Y.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению среднего Y на 0.9796 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве регрессии.
1.6. Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.98 2 = 0.9596, т.е. в 95.96 % случаев изменения x приводят к изменению у . Другими словами — точность подбора уравнения регрессии — высокая. Остальные 4.04 % изменения Y объясняются факторами, не учтенными в модели.
| x | y | x 2 | y 2 | x·y | y(x) | (yi— y ) 2 | (y-y(x)) 2 | (xi— x ) 2 | |y — yx|:y |
| 0.371 | 15.6 | 0.1376 | 243.36 | 5.79 | 14.11 | 780.89 | 2.21 | 0.1864 | 0.0953 |
| 0.399 | 19.9 | 0.1592 | 396.01 | 7.94 | 16.02 | 559.06 | 15.04 | 0.163 | 0.1949 |
| 0.502 | 22.7 | 0.252 | 515.29 | 11.4 | 23.04 | 434.49 | 0.1176 | 0.0905 | 0.0151 |
| 0.572 | 34.2 | 0.3272 | 1169.64 | 19.56 | 27.81 | 87.32 | 40.78 | 0.0533 | 0.1867 |
| 0.607 | 44.5 | .3684 | 1980.25 | 27.01 | 30.2 | 0.9131 | 204.49 | 0.0383 | 0.3214 |
| 0.655 | 26.8 | 0.429 | 718.24 | 17.55 | 33.47 | 280.38 | 44.51 | 0.0218 | 0.2489 |
| 0.763 | 35.7 | 0.5822 | 1274.49 | 27.24 | 40.83 | 61.54 | 26.35 | 0.0016 | 0.1438 |
| 0.873 | 30.6 | 0.7621 | 936.36 | 26.71 | 48.33 | 167.56 | 314.39 | 0.0049 | 0.5794 |
| 2.48 | 161.9 | 6.17 | 26211.61 | 402 | 158.07 | 14008.04 | 14.66 | 2.82 | 0.0236 |
| 7.23 | 391.9 | 9.18 | 33445.25 | 545.2 | 391.9 | 16380.18 | 662.54 | 3.38 | 1.81 |
2. Оценка параметров уравнения регрессии.
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=7 находим tкрит:
tкрит = (7;0.05) = 1.895
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 94.6484 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
Sy = 9.7287 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя. (a + bxp ± ε) где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 1 (-11.17 + 68.16*1 ± 6.4554)
(50.53;63.44)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
Индивидуальные доверительные интервалы для Y при данном значении X.
(a + bx i ± ε)
где
| xi | y = -11.17 + 68.16xi | εi | ymin | ymax |
| 0.371 | 14.11 | 19.91 | -5.8 | 34.02 |
| 0.399 | 16.02 | 19.85 | -3.83 | 35.87 |
| 0.502 | 23.04 | 19.67 | 3.38 | 42.71 |
| 0.572 | 27.81 | 19.57 | 8.24 | 47.38 |
| 0.607 | 30.2 | 19.53 | 10.67 | 49.73 |
| 0.655 | 33.47 | 19.49 | 13.98 | 52.96 |
| 0.763 | 40.83 | 19.44 | 21.4 | 60.27 |
| 0.873 | 48.33 | 19.45 | 28.88 | 67.78 |
| 2.48 | 158.07 | 25.72 | 132.36 | 183.79 |
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (7;0.05) = 1.895
Поскольку 12.8866 > 1.895, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 2.0914 > 1.895, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(68.1618 — 1.895 • 5.2894; 68.1618 + 1.895 • 5.2894)
(58.1385;78.1852)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a — ta)
(-11.1744 — 1.895 • 5.3429; -11.1744 + 1.895 • 5.3429)
(-21.2992;-1.0496)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с lang=EN-US>n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=7, Fkp = 5.59
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Проверка на наличие автокорреляции остатков.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция) определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция, нежели отрицательная автокорреляция. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения ei с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения ei (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скоре всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости ei от ei-1.
Интерпретация уравнения регрессии






Интерпретация уравнения регрессии
- Интерпретация регрессионных уравнений Существует два этапа интерпретации уравнения регрессии. Первый этап Уточнить, потому что уравнения интерпретируются устно Тот, кто не является статистиком. Во вторых это Нет необходимости решать, делать это или больше. Тщательное исследование зависимости. Оба этапа очень важны.
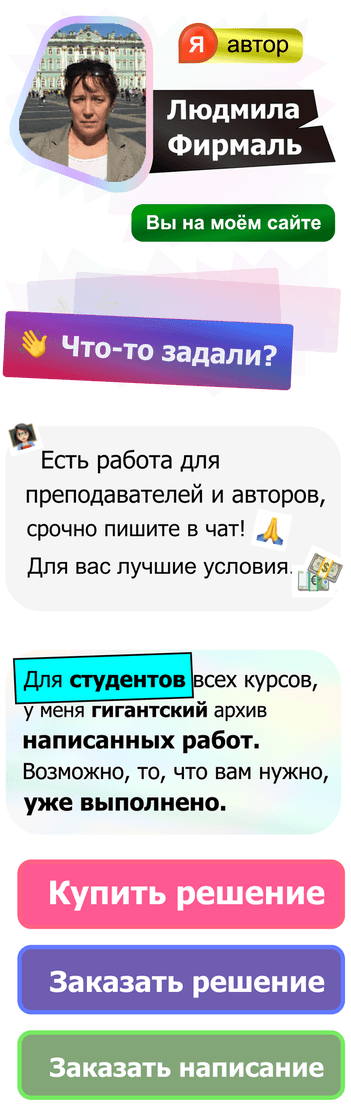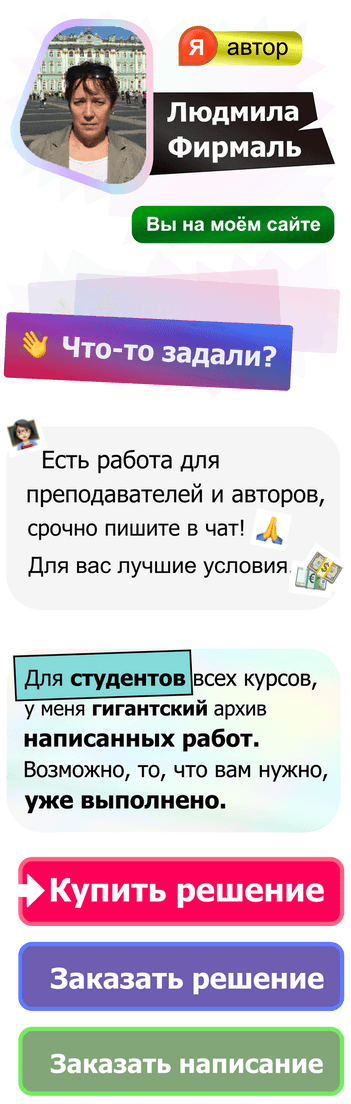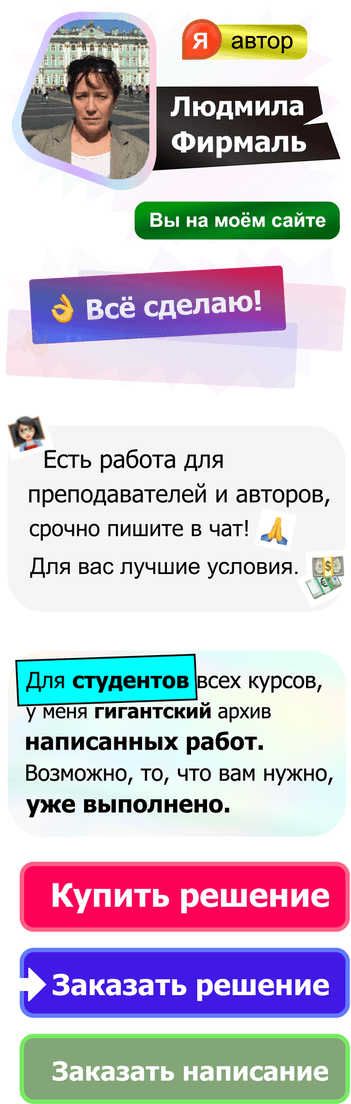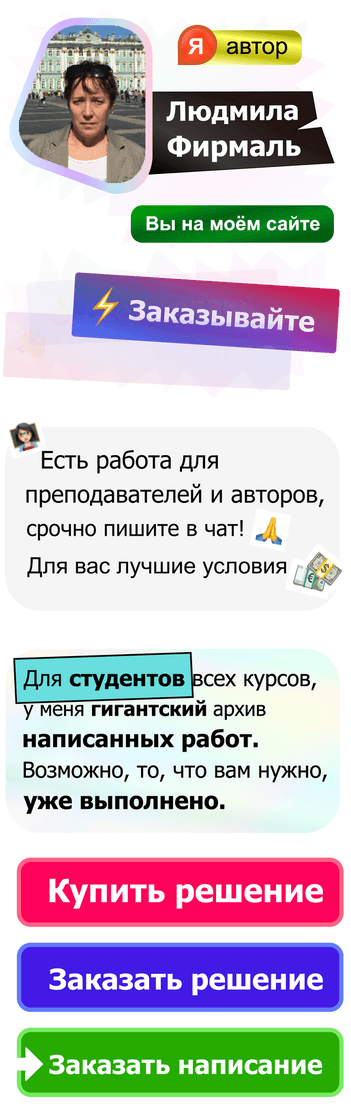
- На втором этапе мы рассмотрим несколько поз А пока давайте обратим основное внимание на первый этап. Это объясняет Определяется регрессионной моделью функции спроса, то есть регрессией между расами Потребители переходят на еду (у) и располагаемый личный доход (х) Данные Отображается в графическом формате (рисунок 2.7). Предположим, что истинная модель описывается y = a + $ x + u, (2,41) И регрессионная оценка £ = 55,3 + 0,093 *. (2,42)
Данные приведены в таблице. Б.1 в США за период с 1959 по 1983 год. Людмила Фирмаль
Полученные результаты можно интерпретировать следующим образом: коэффициент в х (коэффициент градиента) Единица у увеличивается на 0,093 единицы. х и у оба измеряются в мил Миллиарды долларов по фиксированной цене. Поэтому склон Если выручка увеличится на 1 миллиард долларов, 64 Питательные вещества увеличились на 93 миллиона долларов.
Это значит Из реальных долларовых доходов 9,3 цента тратятся на еду. Как насчет констант уравнения? Формально она Если x = 0, указывает уровень прогнозирования ^. Это ясно имеет смысл. Иногда нет. Если х = 0 достаточно далеко от значения выборки х, В этом случае буквальная интерпретация может привести к неверным результатам.
Даже если Линия регрессии является очень точным представлением наблюдаемого значения выборки. Нет гарантии, что то же самое произойдет с экстраполяцией влево или вправо. в 150 грамм 100 грамм 50 Стоимость пища 200 400 600 800 —100 • ”0 120—0 X доходов Рисунок 2.7. Зависимость расходов на питание от дохода (США, 1959-1983).
В рассматриваемом случае путем экстраполяции на вертикальную ось Если доход равен нулю, стоимость еды Сделал бы 55,3 миллиарда долларов. Такое толкование может быть правдоподобным в отношении Лица, которые могут тратить накопления пищи Кредиты или заемные средства. Тем не менее, это не имеет смысла, если По отношению ко всему.
В этом случае константа сделает единственное Функция: может определить положение линии регрессии на графике Поддельный. Примеры констант с ясным значением приведены в упражнении. Институт 2.1. При интерпретации уравнений регрессии очень важно помнить три Вещь. Во-первых, a является только оценкой a, а a b является оценкой (3. Интерпретация на самом деле просто оценка.
Во-вторых Уравнение регрессии отражает только общую тенденцию выборки. В то же время Индивидуальные наблюдения подвержены случайности. третий В этих случаях точность интерпретации зависит от точности спецификации уравнения. По сути, мы построили довольно простую зависимость от функции спроса Мы вернемся к этому в следующем разделе и уточнить.
- Определяя как определения, так и статистические методы, используемые при измерении Коэффициент уравнения. В то же время читателям рекомендуется начать с Упражнение 2.4, определить путем проведения параллельных экспериментов Функция спроса на другие товары приведена в таблице. B.1. После оценки регрессии возникают следующие вопросы:
Есть ли способ определить точность оценки? Это очень важно Рост будет обсуждаться в следующем разделе. Сначала рассмотрим дальше Подробно объясните роль остаточного члена и его влияние на оценки a и p. Интерпретация уравнений линейной регрессии.
Представьте себе простой способ интерпретации линейных коэффициентов. Людмила Фирмаль
Уравнение регрессии у = а + бх Если есть простая естественная единичная переменная Измерение. Сначала увеличим х на 1 единицу ( Единица переменной х) увеличивается у в б (единица переменной у). Второй этап Проверка того, что собой представляет хна на самом деле, Замените слово «единица измерения» на фактическое количество.
Третий этап Проверка возможности более простого выражения результата Это может быть не очень удобно. В примере В этом разделе указана единица измерения для х и у Потому что миллиарды долларов были потрачены, Замечательное упрощение. Константа а дает предсказанное значение у (единица ^). х = 0 Это может иметь или не иметь смысла в зависимости от значения Конкретная ситуация. Упражнение 1 2.1.
Регрессия стоимости продуктов питания (на основе того же Данные, для которых уже описана функция спроса, описанная в тексте) Меню определено как f = 1 в 1959 году, t = 2 в 1960 году и т. Д. Нини: у = 95,3 + 2,53 /. Интерпретация в Сравнение результатов оценки регрессии с аналогом Аналогичные результаты для модели регрессии функции спроса Пожалуйста, смотрите текст.
В этом случае постоянная Есть простая интерпретация. 2.2. Регрессивная зависимость от одноразовой зависимости стоимости жилья 1 Упражнение 2.4 особенно важно в том смысле, что оно запускает серию регрессий для развлечения. Общий спрос. Это оценивается читателем на протяжении всей книги.
Если это упражнение Если это делается группой студентов, учитель должен дать студентам задания Товарные. Более подробная информация о доступных данных доступна в Приложении B.go Личный доход в соответствии с таблицей. B.1, оба количества Можно оформить миллиарды долларов с 1959 по 1983 В следующем формате: j> = -27,6 + 0,178х.
Регрессивная зависимость и определение стоимости жилья с течением времени То же самое, что и упражнение 2.1, можно выразить как: f = 48,9 + 4,84 г. Вот экономическая интерпретация этих регрессий. У них разные предложения Описание тех же данных в переменной y. Сколько они Вы можете согласиться? 2,3.
Создайте уравнение регрессии между p и e из данных упражнения 1.3, сначала используйте все 12 наблюдений, затем исключите наблюдения 1. Дает экономическую интерпретацию для Японии. 2,4. В таблице. B.1 — потребительские расходы США располагаемый личный доход за период 1959-1983 гг. Назовите один продукт — не еду, а не домашнюю Пропустите регрессию между y и x. х — располагаемый личный доход, использующий Данные за 25 лет.
Интерпретация коэффициентов регрессии 2.5. Таким образом, регрессия между характеристиками продукта и временем Мы сделаем это в упражнении 2.1. Правильная интерпретация и сравнение У нее есть интерпретация регрессии, полученная в упражнении 2.4. 2.6. Два человека строят один и тот же набор временных тенденций 25 наблюдений за переменной y с использованием модели: у = а + р / + и
Где t — время (принимает значения непрерывно от 1 до 25), а -case Член чаепития. Получите первое уравнение: j> = 6,70 + 1,79 /. Вторая по ошибке оценивает регрессию между / и у и этим уравнением По мнению: t = -0,25 + 0,44 >>. Из этого уравнения он получает: у = 0,57 + 2,27 /. Объясните это уравнение и несоответствие между уравнениями, Получено первым исследователем. 2,7.
Как изменяется регрессионный балл в упражнении 2.1 Фактическая дата (1959-1983) используется как / вместо числа из 1 до 25? 2,8. Исследователи, 1 Не начинайте сначала вычислять коэффициент регрессии. Заполнены большинство арифметических расчетов в упражнении 1.3. 2 Учителя являются учениками, если это групповое занятие.
Удар, чтобы дать задачу оценки регрессии различных видов товаров в дополнение к еде жилья.люги, основанные на данных АМЕ (у) и общем располагаемом личном доходе (х) Риканская экономика (обе измеряются в миллиардах долларов) Фиксированная цена) с использованием данных и модели временных рядов за год: y = a + px + u. 1.
Исследователь выполняет регрессионный анализ, чтобы получить уравнение. Используйте обычный метод наименьших квадратов. Если предположить, что Обе ценности могут быть значительно недооценены внутренней системой Личные счета за желание людей не платить налоги Правительство, исследователи принимают два альтернативных улучшения Недооцененная оценка. 2.
Исследователи добавляют $ 90 млрд к показателю каждый год >> и Показатель х 200 миллиардов долларов. 3. Исследователь увеличивает x и y на 10% Каждый год. Оценить влияние корректировок (2) и (3) на результаты рег. ressii. 2.9. Исследователи имеют общие годовые данные временных рядов.
Заработная плата (W), валовой доход (P) и валовой доход (Y) Для страны сроком на n лет. По определению Y = W + T1. Получите регулярное уравнение, используя метод наименьших квадратов Рссии: fr = a0 + aiY; ft = Z> 0 + bxY. Указывает, что коэффициент регрессии автоматически удовлетворяет Следующее уравнение: но х + * я = 1; * o + K = 0. Интуитивно объясните, почему так должно быть. 2.10.
Исследователи не имеют нестохастической части истинной модели у пропорционально х. y = $ x + u. Исходя из исходного принципа, выведите формулу b, оценка МНК б. В этом случае (2.31) указывает, что это можно записать следующим образом. S = bj] + b2J, xj -2 £ Xx,. > 7 Для этого b = 2, xiyi / Zxf. 2,11. Выведите оценку наименьших квадратов модели из первого предположения. у = а + у. 68 То есть у это просто сумма констант Случайные участники с нами. Сначала переопределите 5, а затем дифференцируйте Цитирование.



Образовательный сайт для студентов и школьников
Копирование материалов сайта возможно только с указанием активной ссылки «www.lfirmal.com» в качестве источника.
© Фирмаль Людмила Анатольевна — официальный сайт преподавателя математического факультета Дальневосточного государственного физико-технического института
http://math.semestr.ru/corel/primer.php
http://lfirmal.com/interpretaciya-uravneniya-regressii/