Генетические алгоритмы в задачах оптимизации
Введение
На практике подчас сложно, а порой и невозможно, зафиксировать свойства функциональной зависимости выходных параметров от входных величин, еще сложнее привести аналитическое описание такой зависимости. Это обстоятельство значительно затрудняет применение на стадии проектирования классических методов оптимизации, поскольку большинство из них основывается на использовании априорной информации о характере поведения целевой функции, а задача определения принадлежности функции тому или другому классу сопоставима по сложности с исходной. В связи с этим встает задача построения таких методов оптимизации, которые были бы способны отыскивать решения практически при полном отсутствии предположений о характере исследуемой функции. Одними из таких методов являются так называемые эволюционные методы поиска и, в частности, генетические алгоритмы (ГА), моделирующие процессы природной эволюции.
В данной работе рассматривается один из таких генетических алгоритмов для решения многопараметрической непрерывной задачи оптимизации.
Нами использована отличная от традиционной символьная модель, позволяющая манипулировать более короткими хромосомными наборами. Предлагаются новые генетические операторы, использующие специфику такой модели. Обсуждаются вопросы, связанные с влиянием операторов и значений параметров на поведение генетического алгоритма. Проведен вычислительный эксперимент с использованием традиционных для генетических алгоритмов задач.
Постановка задачи
Рассматривается непрерывная многопараметрическая задача оптимизации

В этой задаче дифференцируемость, непрерывности, удовлетворение условию Гельдера (в том числе липшицируемость функции) не являются необходимым свойством рассматриваемого класса задач, кроме того, целевая функция может быть вовсе не определена вне допустимой области, а внутри допустимой области иметь несколько глобальных экстремумов.
Можно выделить, по крайней мере, три класса задач, которые могут быть решены представленным алгоритмом. Во-первых, это задача быстрой локализации одного оптимального решения; во-вторых, при определенных условиях, возможно отыскание нескольких (или всех) глобальных экстремумов; и в-третьих, это возможность использования алгоритма для отображения ландшафта исследуемой функции.
Эволюционный поиск
Генетические алгоритмы являются одними из эволюционных алгоритмов, применяемых для поиска глобального экстремума функции многих переменных. Принцип работы генетических алгоритмов основан на моделировании некоторых механизмов популяционной генетики: манипулирование хромосомным набором при формировании генотипа новой биологической особи путем наследования участков хромосомных наборов родителей (кроссинговер), случайное изменения генотипа, известное в природе как мутация. Другим важным механизмом, заимствованным у природы, является процедура естественного отбора, направленная на улучшение от поколения к поколению приспособленности членов популяции путем большей способности к «выживанию» особей, обладающих определенными признаками.
Реализацию базового генетического алгоритма можно представить как итерационный процесс, включающий несколько этапов:
- генерация начальной популяции
- воспроизводство «потомков»:
- выбор родительской пары
- выбор и реализация одного из операторов кроссовера
- выбор и реализация одного из операторов мутации
- создание репродукционной группы
- процедура отбора и формирование на его основе нового поколения
- если не выполнено условие останова, то перейти к п.2
Тестовые задачи
Оценка качества предлагаемого алгоритма и частных генетических операторов проводилась по нескольким направлениям: во-первых, сравнение эффективности поиска в зависимости от выбранной символьной модели, в том числе от длины хромосомного набора; во-вторых, зависимость улучшения значения приспособленностей особей популяции от параметров ГА, прежде всего метода выбора родительских пар и реализации механизма отбора. Кроме того, помимо количественных оценок приводится качественное описание поведения популяции, управляемой ГА при тех или иных параметрах.
Оценка предлагаемого алгоритма проводилась на ряде тестовых функций. Это прежде всего несколько тестовых функций De Jong’а, которые часто используются для проверки эффективности новых генетических алгоритмов , кроме того, были использованы сложные многоэкстремальные функции высокой размерности, практически нерешаемые классическими методами.
| № п/п | Тестовая задача | Размерность | Свойства |
|---|---|---|---|
| 1 | De Jong 2 | 2 | Овражная функция, один глобальный экстремум |
| 2 | De Jong 3 | 5 | Разрывы типа «скачек», максимум достигается на гиперкубе |
| 3 | De Jong 5 | 2 | Один глобальный на гиперкубе, 24 локальных максимума |
| 4 | Растригина | 2 | 96 локальных экстремумов и 4 глобальных |
| 5 | Griewank | 2 | Один глобальный и множество локальных максимумов |
| 6 | Растригина | 10 | Один глобальный экстремум и 10 10 -1 локальных |
| 7 | Griewank | 10 | Один глобальный и множество локальных максимумов |
Более подробно используемые тестовые функции представлены в приложении.
Символьная модель
При построении символьной модели множество допустимых решений представляется в виде конечной популяции особей. Каждая особь в популяции обладает мерой приспособленности к окружающей среде. Процесс поиска оптимального решения описывается процессом моделируемой «эволюции», целью которой является нахождение особи (или множества особей), имеющей максимальную приспособленность, т.е. особи, соответствующей оптимальному значению управляемых параметров.
Каждая особь представлена в виде набора некоторого числа генов (битовых строк заданной длины) называемого хромосомой. Число генов в хромосоме соответствует размерности решаемой задачи; каждый ген используется для кодирования небольшого интервала значений одного из управляемых параметров проектируемой системы. По существу, такая кодировка соответствует разбиению пространства параметров на гиперкубы, которым соответствуют уникальные комбинации битов в хромосоме (генотип).
Для установления соответствия между гиперкубами разбиения области и бинарными строками, описывающими номера таких гиперкубов, использовался рефлексивный код Грея.
При взаимодействии особи с внешней средой ее генотип порождает внешне наблюдаемые количественные признаки: фенотип и оценку приспособленности. Фенотип особи определяется как точка, принадлежащая гиперкубу пространства поиска соответствующего генотипа. В рассматриваемом алгоритме применялся равномерный закон распределения точек фенотипа в соответствующем гиперкубе. (Более подробно предлагаемая символьнаямодель представлена в [6]).
Важно отметить, что в этом и состоит основное отличие предлагаемого способа формирования фенотипа от традиционного (см. [1,2]). Символьная модель, предлагаемых ранее генетических алгоритмов, предусматривала дискретизацию пространства параметров с шагом, соответствующим требуемой точности. При этом фенотип определялся как узел такой пространственной решетки, так что между генотипом и фенотипом особи существовало взаимно однозначное соответствие. Предлагаемая же нами модель не предусматривает однозначности, поскольку каждому генотипу может соответствовать целое множество фенотипов (что, вообще говоря, имеет место в природе). Это позволяет использовать более крупное разбиение пространства параметров, делая при этом длину хромосомного набора короче.
Для поиска оптимального разбиения пространства параметров на гиперкубы, кодируемые хромосомными наборами соответствующей длины NL ( N — размерность задачи, L — длина кодировки одного гена), проводились испытания на четырех тестовых функция: De Jong 2, De Jong 3, De Jong 5 и функция Griewank’а. В качестве рассматриваемых вариантов были выбраны L 1 =4 , L 2 =6 , L 3 =8 , L 4 =16 . Эффективность поиска определялась по отношению к среднему (усредн. по 50 запускам) значению приспособленности популяции к максимальному значению после 1000 вычислений функции, что соответствует порядка 23-25 поколениям, при численности популяции 50 и формировании 20 брачных пар на каждом поколении, вероятность мутации была около 0.001. Результаты эксперимента приведены на рисунке 1.
Как видно из представленной диаграммы уже после L 2 =6 для представленных функций не происходит значительного улучшения эффективности поиска. Вообще, длина кодировки в значительной мере сказывается на функциях, ландшафту которых присущи скачкообразные изменения, как например у De Jong 3 или 5, и наоборот непрерывная функция De Jong 2, а тем более функция Griewank’а, слабо чувствительны к длине кодировки. Очевидно, такая особенность объясняется разбросом значений приспособленностей особей, имеющих одинаковые генотипы, этот разброс тем больше, чем крупнее гиперкубы разбиения пространства. Поэтому в процессе поиска для таких функций сложнее определить хромосомные наборы, которые бы соответствовали оптимальному решению.
Однако, увеличение длины кодировки ускоряет процесс сходимости всех членов популяции к лучшему найденному решению (см. рисунок 3). Зачастую такой эффект не желателен, поскольку при этом большая часть пространства поиска остается неисследованной — преждевременная сходимость может не привести к оптимальному решению, кроме того, быстрая сходимость к одной области не гарантирует обнаружения нескольких равных экстремумов. Поэтому в вопросе выбора оптимальной длины кодировки нужно достичь некоторого компромиссного решения — с одной стороны L должно быть достаточно большим, чтобы все-таки обеспечить быстрый поиск, с другой стороны — по возможности малым, чтобы не допускать преждевременной сходимости и оставить алгоритму шанс отыскать несколько оптимальных значений. Мы предлагаем использовать хромосомные наборы длины 6N — 8N , где N — размерность задачи.
Формирование генотипов особей начальной популяции проводилось по принципу максимального побитого разнообразия (см. [6]). Максимальное побитовое разнообразие призвано обеспечить максимальное богатство генетического материала в начальной популяции.
Влияние параметров генетического алгоритма на эффективность поиска
Операторы кроссовера и мутации
Одной из особенностей предлагаемого ГА является отход от традиционной схемы «размножения», используемой в большинстве реализованных ГА [3] и повторяющих классическую схему, предложенную Голландом [1]. Классическая схема предполагает ограничение численности потомков путем использования так называемой вероятности кроссовера. Такая модель придает величине, соответствующей численности потомков, вообще говоря, недетерминированный характер. Мы предлагаем отойти от вероятности кроссовера и использовать фиксированное число брачных пар на каждом поколении, при этом каждая брачная пара «дает» двух потомков. Такой подход хорош тем, что делает процесс поиска более управляемым и предсказуемым в смысле вычислительных затрат.
В качестве генетических операторов получения новых генотипов «потомков», используя генетическую информацию хромосомных наборов родителей мы применяли два типа кроссоверов — одно- и двухточечный. Вычислительные эксперименты показали, что даже для простых функций нельзя говорить о преимуществе того или иного оператора. Более того, было показано, что использование механизма случайного выбора одно- или двух точечного кроссовера для каждой конкретной брачной пары подчас оказывается более эффективным, чем детерминированный подход к выбору кроссоверов, поскольку достаточно трудно априорно определить который из двух операторов более подходит для каждого конкретного ландшафта приспособленности. Из диаграмм, представленных на рисунке 4 видно, что нельзя однозначно отдавать предпочтение одно- или двухточечному кроссоверу. Одноточечный оказался более эффективным на тестовых функциях De Jong’а 2 и 5, на двумерной функции Griewank’а и на двумерной функции Растригина, однако для функции De Jong’а 3, функции Griewank’а и Растригина от 10 переменных можно говорить о преимуществе выбора двухточечного оператора. Использование же случайного выбора преследовало целью прежде всего сгладить различия этих двух подходов и улучшить показатели среднего ожидаемого результата. Для всех представленных тестовых функций так и произошло, — случайный выбор оказался эффективнее худшего. Кроме того, в ряде случаев (функции Griewank’а, 10-мерная функция Растригина) применение случайного механизма в выборе кроссовера дало лучшие результаты по сравнению с детерминированными подходами.
Повышение эффективности поиска при использовании случайного выбора операторов кроссовера повлияло на то, чтобы применить аналогичный подход при реализации процесса мутагинеза новых особей, однако в этом случае преимущество перед детерминированным подходом не так очевидно в силу традиционно малой вероятности мутации (в наших экспериментах вероятность мутации составляла 0.001 — 0.01).
Выбор родительской пары
Как уже отмечалось, мы решили не использовать вероятность кроссовера в качестве одного из параметров алгоритма, ограничивая число воспроизводимых потомков фиксированным числом брачных пар. В связи с этим встал вопрос о том, каким образом из всего многообразия всех возможных пар выбрать лишь несколько. Предлагалось несколько подходов, однако мы рассмотрим здесь несколько показавшихся нам наиболее интересными.
Первый подход самый простой — это случайный выбор родительской пары («панмиксия»), когда обе особи, которые составят родительскую пару, случайным образом выбираются из всей популяции, причем любая особь может стать членом нескольких пар. Несмотря на простоту, такой подход универсален для решения различных классов задач. Однако он достаточно критичен к численности популяции, поскольку эффективность алгоритма, реализующего такой подход, снижается с ростом численности популяции.
Второй способ выбора особей в родительскую пару — так называемый селективный. Его суть состоит в том, что «родителями» могут стать только те особи, значение приспособленности которых не меньше среднего значения приспособленности по популяции, при равной вероятности таких кандидатов составить брачную пару. Такой подход обеспечивает более быструю сходимость алгоритма. Однако из-за быстрой сходимости селективный выбор родительской пары не подходит тогда, когда ставиться задача определения нескольких экстремумов, поскольку для таких задач алгоритм, как правило, быстро сходится к одному из решений. Кроме того, для некоторого класса задач со сложным ландшафтом приспособленности быстрая сходимость может превратиться в преждевременную сходимость к квазиоптимальному решению. Этот недостаток может быть отчасти компенсирован использованием подходящего механизма отбора (о чем будет сказано ниже), который бы «тормозил» слишком быструю сходимость алгоритма.
Другие два способа формирования родительской пары, на которые хотелось бы обратить внимание, это инбридинг и аутбридинг. Оба эти метода построены на формировании пары на основе близкого и дальнего «родства» соответственно. Под «родством» здесь понимается расстояние между членами популяции как в смысле геометрического расстояния особей в пространстве параметров (для фенотипов), так и в смысле хэмминингого расстояния между хромосомными наборами особей (для генотипов). В связи с этим будем различать генотипный и фенотипный (или географический) инбридинг и аутбридинг. Под инбридингом понимается такой метод, когда первый член пары выбирается случайно, а вторым с большей вероятностью будет максимально близкая к нему особь. Аутбридинг же, наоборот, формирует брачные пары из максимально далеких особей. Использование генетических инбридинга и аутбридинга оказалось более эффективным по сравнению с географическим для всех тестовых функций при различных параметрах алгоритма. Наиболее полезно применение обоих представленных методов для многоэкстремальных задач. Однако два этих способа по-разному влияют на поведение ГА. Так инбридинг можно охарактеризовать свойством концентрации поиска в локальных узлах, что фактически приводит к разбиению популяции на отдельные локальные группы вокруг подозрительных на экстремум участков ландшафта, а аутбридинг как раз направлен на предупреждение сходимости алгоритма к уже найденным решениям, заставляя алгоритм просматривать новые, неисследованные области.
Механизм отбора
Обсуждение вопроса о влиянии метода создания родительских пар на поведение ГА невозможно вести в отрыве от реализуемого механизма отбора при формировании нового поколения. Сразу же отметим, что метод пропорционального отбора, как и другие методы, основанные на включение особи в новую популяцию по вероятностному принципу, давали настолько плохие результаты, что здесь даже не рассматриваются. В своих экспериментах мы использовали другие механизмы отбора, из которых выделим два: элитный и отбор с вытеснением.
Идея элитного отбора, в общем, не нова, этот метод основан на построении новой популяции только из лучших особей репродукционной группы, объединяющей в себе родителей, их потомков и мутантов. В литературе, посвященной ГА, например в [3], элитному отбору отводят место как достаточно слабому с точки зрения эффективности поиска. В основном это объясняют потенциальной опасностью преждевременной сходимости, отдавая предпочтение пропорциональному отбору. Однако наш опыт говорит о напрасности таких опасений. Быстрая сходимость, обеспечиваемая элитным отбором, может быть, когда это необходимо, с успехом компенсирована подходящим методом выбора родительских пар, например аутбридингом. Как видно из результатов, приведенных в таблице 1, именно такая комбинация «аутбридинг–элитный отбор» является одной из наиболее эффективных для рассматриваемых тестовых функций.
Второй метод, на котором хотелось бы остановиться, это отбор вытеснением. Отбор, построенный на таком принципе, носит бикритериальный характер — то, будет ли особь из репродукционной группы заноситься в популяцию нового поколения, определяется не только величиной ее приспособленности, но и тем, есть ли уже в формируемой популяции следующего поколения особь с аналогичным хромосомным набором. Из всех особей с одинаковыми генотипами предпочтение сначала, конечно же, отдается тем, чья приспособленность выше. Таким образом, достигаются две цели: во-первых, не теряются лучшие найденные решения, обладающие различными хромосомными наборами, а во-вторых, в популяции постоянно поддерживается достаточное генетическое разнообразие. Вытеснение в данном случае формирует новую популяцию скорее из далеко расположенных особей, вместо особей, группирующихся около текущего найденного решения. Этот метод особенно хорошо себя показал при решении многоэкстремальных задач, при этом помимо определения глобальных экстремумов появляется возможность выделить и те локальные максимумы, значения которых близки к глобальным.
Три задачи генетического алгоритма
Представленный алгоритм обладает достаточно широкими возможностями, — настроив соответствующим образом параметры системы, можно управлять процессом поиска в зависимости от поставленной задачи. Как уже отмечалось, существует, по крайней мере, три класса задач, которые могут быть решены представленным алгоритмом:
- задача быстрой локализации одного оптимального значения
- задача определения нескольких (или всех) глобальных экстремумов
- задача описания ландшафта исследуемой функции, которая может сопровождаться выделением не только глобальных, но и локальных максимумов
Основное различие в методах решения этих трех задач лежит в реализации различных уровней соотношения, которое в теории генетических алгоритмов называется как соотношение «исследование–использование».
Быстрый поиск одного экстремума, как правило, достигается использованием параметров, которые способствуют максимально быстрой сходимости за счет манипулирования только особями, обладающими лучшей приспособленностью, при этом более «слабые» члены популяции не участвуют в формировании родительских пар и не выживают после процедуры отбора. Этого можно достичь путем применения селективного выбора пар и элитного метода отбора. Понятно, что больший акцент в паре «исследование–использование» при этом делается именно на «использование».
Для решения второй задачи, очевидно, вопросу «исследования» пространства поиска должно уделяться гораздо большее внимание. Оно достигается за счет другого сочетания параметров и достаточно большой численности популяции, при этом ГА сможет выделить несколько (или даже все) глобальные экстремумы. В качестве примера решения такой задачи приведем экспериментальные данные, полученные при поиске максимумов двумерной функции Растригина. Параметры генетического алгоритма, использовавшиеся для максимизации этой функции, такие же, как и для решения других тестовых задач (см. комментарий к таблице 1.) Итак, средние показатели процесса поиска по 50 испытаниям, в скобках для сравнения приведены результаты, опубликованные в [6]:
- среднее значение приспособленности — 80.694
- число вычислений функции — 652 (1282), что составляет порядка 15 поколений
- частота локализации всех 4 точек глобального экстремума равна 1 (в [6] локализовывался один максимум)
Для выделения нескольких глобальных максимумов, лучше использовать такую комбинацию: аутбридинг в сочетании с инбридингом, в качестве естественного отбора достаточно использовать элитный отбор или отбор с вытеснение (последний более надежный). Максимальная эффективность поиска достигается в сочетании аутбридинга и инбридинга, причем аутбридинг рекомендуется использовать в начале поиска, достигая максимально широкого «исследовании», а завершать поиск лучше уточнением решения в локальных группах, используя инбридинг.
И наконец третья задача. Особенность ее решения состоит в том, что при достаточно большом размере популяции и небольшом заданном количестве брачных пар проявляется интересное свойство поведения генетического алгоритма: в процессе поиска проявляются черты рельефа ландшафта функции приспособленности (овраги, холмы, долины). На рисунке 5 видно, что оставляя области, которым соответствуют меньшая приспособленность, ГА группирует особи ближе к вершинам холмов, в область притяжения которых они попали. Это эквивалентно определению локальных экстремумов, значения которых близки к оптимальным. Продолжение поиска ведет к тому, что особи, сгруппировавшиеся вокруг локальных экстремумов, постепенно «вымирают», а их место в популяции начинают занимать особи с лучшей приспособленностью близкие к глобальным максимумам. Использование же отбора с вытеснение в какой-то мере может препятствовать этому процессу, давая шанс «выжить» особям около локальных экстремумов.
Приложение А
Тестовая функция De Jong 2
 , -1.28 1,2 * =F(1.00, 1.00) = 100.00
, -1.28 1,2 * =F(1.00, 1.00) = 100.00
Тестовая функция De Jong 3
 , -5.12 1,2,3,4,5 * =30 на гиперплоскости 5.00 1,2,3,4,5
, -5.12 1,2,3,4,5 * =30 на гиперплоскости 5.00 1,2,3,4,5
Тестовая функция De Jong 5
 , где a 1j =16[(j mod 5)-2], a 2j =16[(j % 5)-2].
, где a 1j =16[(j mod 5)-2], a 2j =16[(j % 5)-2].
F * =F(-16,-32)=1.002 при 1,2
Тестовая функция Растригина
 , -5.12 1,2 * =F(4.52299, 4.52299)=F(-4.52299, 4.52299)=F(-4.52299, -4.52299)=F(4.52299, -4.52299)=80.7065
, -5.12 1,2 * =F(4.52299, 4.52299)=F(-4.52299, 4.52299)=F(-4.52299, -4.52299)=F(4.52299, -4.52299)=80.7065
Тестовая функция Griewank
 , -20.0 1,2 * =F(0.00, 0.00)=1.0
, -20.0 1,2 * =F(0.00, 0.00)=1.0
Тестовая фанкция Растригина
 . F * =F(0.00, 0.00:0.00)=0.00 при -5.12 1,2,…,10
. F * =F(0.00, 0.00:0.00)=0.00 при -5.12 1,2,…,10
Тестовая функция Griewank
 , -5.12 1,2,…,10 * =F(0.00, 0.00:0.00)=10.00
, -5.12 1,2,…,10 * =F(0.00, 0.00:0.00)=10.00
Приложение Б
Рисунок 1

Отношение найденного максимального значения к реальному максимуму при различной длине кодировки гена для 4 тестовых функций.
Рисунок 2
 |  |
 |  |
На рисунке представлены графики изменения приспособленности лучшей особи в популяции при различной длине кодировки (непрерывная линия — L = 10, разрывная — L = 6, пунктирная —— L = 4).
Рисунок 3
| De Jong 2 (L=4) |  |
| De Jong 2 (L=10) |  |
| De Jong 5 (L=4) |  |
| De Jong 5 (L=10) |  |
На диаграммах представлены изменение лучшей, средней и худшей приспособленностей особей в популяции. Нетрудно видеть, что увеличение длины хромосомного набора не столько ускоряет процесс поиска наилучшего значения приспособленности, сколько влияет на улучшение приспособленностей наихудших особей в популяции, что приводит к более быстрой сходимости алгоритма в ущерб исследованию пространства поиска.
Рисунок 4
| De Jong 2 | De Jong 3 | Griewank (n=10) |
 |  |  |
Эффективность ГА при использовании различных операторов кроссовера. На диаграммах представлены результаты, усредненные по 50 запускам (каждый запуск — около 5000 вычислений для 10-мерных функций или 1000 для остальных).
Рисунок 5
| De Jong 2 | De Jong 5 | ||
| Быстрый поиск | Описание ландшафта | Быстрый поиск | Описание ландшафта |
 |  |  |  |
| Griewank n=2 | Растригин n=2 | ||
| Быстрый поиск | Описание ландшафта | Быстрый поиск | Описание ландшафта |
 |  |  |  |
На рисунке представлены популяции особей в пространстве поиска для тестовых функций на 25-ом поколении генетического алгоритма при параметрах, настроенных на быстрый поиск одного максимума и для задачи описания ландшафта.
Таблица 1
| панм-элит | панм-выт | селек-элит | селект-выт | инбр-элит | инбр-выт | аутбр-элит | аутбр-выт | |
| De Jong 2 | ||||||||
| Макс | 99,999 | 99,964 | 99,998 | 99,982 | 99,999 | 99,983 | 99,986 | 99,980 |
| Мин | 92,254 | 90,735 | 83,529 | 80,211 | 83,725 | 88,445 | 91,754 | 94,843 |
| Cр.знач | 98,038 | 98,666 | 96,595 | 96,903 | 98,464 | 98,833 | 98,811 | 98,639 |
| De Jong 3 | ||||||||
| Макс | 29,000 | 29,000 | 30,000 | 30,000 | 28,000 | 29,000 | 30,000 | 30,000 |
| Мин | 27,000 | 27,000 | 27,000 | 29,000 | 24,000 | 25,000 | 28,000 | 28,000 |
| Cр.знач | 28,320 | 28,160 | 29,280 | 29,180 | 26,880 | 27,180 | 28,780 | 28,620 |
| De Jong 5 | ||||||||
| Макс | 1,002 | 1,002 | 1,002 | 1,002 | 1,002 | 1,002 | 1,002 | 1,002 |
| Мин | 0,502 | 0,550 | 0,202 | 0,966 | 0,202 | 0,715 | 0,988 | 0,910 |
| Ср.знач | 0,982 | 0,981 | 0,985 | 1,000 | 0,962 | 0,978 | 1,001 | 0,991 |
| Griewank n=2 | ||||||||
| Макс | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 | 1,000 |
| Мин | 0,836 | 0,871 | 0,871 | 0,871 | 0,871 | 0,869 | 0,872 | 0,906 |
| Ср.знач | 0,963 | 0,977 | 0,953 | 0,960 | 0,946 | 0,970 | 0,993 | 0,988 |
| Растригин n=10 | ||||||||
| Макс | ||||||||
| Мин | ||||||||
| Ср.знач | ||||||||
| Griewank n=10 | ||||||||
| Макс | 9,356 | 9,479 | 9,476 | 9,396 | 9,260 | 9,255 | 9,586 | 9,467 |
| Мин | 9,027 | 9,034 | 9,051 | 9,078 | 8,708 | 8,445 | 9,069 | 9,069 |
| Ср.знач | 9,158 | 9,173 | 9,198 | 9,203 | 8,936 | 8,912 | 9,235 | 9,212 |
В таблице приведены результаты поиска по 50 запускам при различных параметрах генетического алгоритма. Для всех примеров: L =6, численность популяции 50, число брачных пар 20, вероятность мутации 0.01. Число вычислений функции: для первых четырех около1000, для двух последних около 5000.
II. ПРАКТИЧЕСКОЕ ПРИМЕНЕНИЕ ГЕНЕТИЧЕСКОГО АЛГРИТМА
Генетические алгоритмы достаточно универсальны и используются для решения большого числа задач, связанных с оптимизацией. Несмотря на то, что многие из таких задач имеют другие, возможно более быстрые и точные, способы решения применение генетических алгоритмов не теряет свой смысл. Это связано с тем, что в некоторых случаях, особенно при правильном применении различных технологий программирования (параллельное программирование), генетические алгоритмы могут быть более эффективны при решении поставленных задач.
Оптимизация запросов в базах данных
Разнообразные задачи на графах (задача коммивояжера, раскраска)
Настройка и обучение искусственной нейронной сети
Задачей оптимизации в математике, информатике и исследовании операций называется задача на хождения экстремума (минимума или максимума) целевой функции в некоторой области, конечно, мерного векторного пространства, ограниченной набором линейных и/или нелинейных равенств и/или неравенств [9].
Рассмотрим решение одной из задач на графах (задачи коммивояжера).
Задача коммивояжёра — одна из самых известных задач комбинаторной оптимизации, заключающаяся в поиске самого выгодного маршрута, проходящего через указанные города хотя бы по одному разу с последующим возвратом в исходный город [8].
Алгоритм решения задачи коммивояжёра с помощью генетического алгоритма:
1. Генерация первого поколения
5. Итоговое тело.
Рассмотрим решение данной задачи с помощью генетического алгоритма, предложенное В.А. Моровым [9].
Постановка задачи коммивояжера
Рассмотрим метрическую задачу коммивояжера, когда расстояния между городами можно вычислить (аналог точек на плоскости). При данной постановке задачи имеем: число городов, координаты каждого города на плоскости:
Таким образом, расстояние между городами можно находить как расстояние между двумя точками:
Необходимо найти такой путь через города g i , чтобы суммарное расстояние были минимальным/
Построение генетического алгоритма для задачи коммивояжера
Для применения генетического алгоритма необходимо определить основные структурные элементы: вид элемента популяции, процесс скрещивания, мутации и вид фитнесс-функции.
За элемент популяции (одно возможное решение) принимаем маршрут через все города. Каждый такой маршрут является возможным решением и не противоречит условиям задачи, хотя может быть совсем не оптимальным. Предполагаем, что все элементы популяции корректны, т.е. все они – потенциальные решения поставленной задачи и не являются противоречивыми.
В качестве фитнесс-функции мы принимаем функцию вида:
где Р – множество всех связей в маршруте.
Данная функция определяет минимизируемый параметр и позволяет оценивать получаемые решения. Метод мутации реализуется следующим образом: выбираем случайный город; находим связи, соответствующие этому городу; соединяем соседние города прямой связью (исключаем выбранный город из этой связи); вставляем город в случайное место.
Пример. Предположим, что решение до мутации имеет вид, представленный на рис. 2.
Решение до мутации
Применяя к нему алгоритм мутации, можем получить решение в виде представленном на рис. 3.
Решение, но после мутации
Метод скрещивания реализуется сложнее, так как требует дополнительных проверок на корректность получаемого маршрута.
Алгоритм метода скрещивания:
выбираем два маршрута из популяции, которые будут выступать в роли родителей;
в образуемые маршруты переносим связи, которые существуют в обоих маршрутах-родителях;
при несовпадающих связях предпочтение отдается связи в первом родителе для городов с четными номерами; если ее применить невозможно, то берем связи из второго родителя, если это также невозможно, то берем из первого маршрута.
При таком задании скрещивания для получения двух решений можно применять данный метод дважды, меняя маршруты-родители местами. Тогда второй потомок будет получен при условии, что при несовпадении связей предпочтение будет отдаваться второму маршруту. Пример. На рис. 4 представлен пример применения данного алгоритма скрещивания к двум решениям:
2.2 Описание программы решения линейного уравнения с помощью генетического алгоритма.
Опишем полную программу решения уравнения xa+yb+zc+rd=k, где a, b, c, d, k – переменные, x, y, z, r – угловые коэффициенты при них.
Для примера возьмем уравнение 2a+4b+5c+6d=30. Представим собственную программу его решения.
При выполнении работы были изучены генетические алгоритмы для решения различных классов оптимизационных задач и написана программа на языке Паскаль, реализующая алгоритм решения тестовой математической задачи. В качестве такой задачи было выбрано решение в натуральных числах уравнения xa+yb+zc+rd=e с четырьмя неизвестными x , y, z, r. В принципе можно легко заменить тестовое линейное уравнение на гораздо более сложное, при этом в программе придется изменять только алгоритм начального формирования популяции и функцию приспособленности.
Алгоритм существенно зависит от трех параметров: количества особей в поколении n , количества скрещиваний m , необходимых для получения следующего поколения, и вероятности мутаций ver . Так как решения тестового примера можно получить обычным перебором, есть возможность сравнивать получаемые генетическим алгоритмом решения с известным ответом. Автором работы был проделан ряд вычислительных экспериментов с целью подбора параметров алгоритма, обеспечивающих быстрое получение всех натуральных решений тестового уравнения.
Будем назвать особью набор из четырех генов ( x , y, z, r). В качестве функции приспособленности особи нами была взята функция 1/ (| xa+yb+zc+rd-e | + 1). Легко видеть, что она является неотрицательной и достигает максимума на решениях нашего уравнения.
На рисунке 5 показан процесс создания начальной популяции. Как уже было замечено выше, можно стартовать с более-менее любой начальной популяции, все равно эволюционный процесс приведет к правильным решениям. Как видно из текста программы, для создания первого поколения мы просто делаем все гены случайными числами, равномерно распределенными на промежутке [1; 20]. Попутно для каждой особи вычисляется ее функция приспособленности.
Создание массива первого поколения
Для проведения процесса скрещивания необходимо задавать вероятности каждой особи стать родителем. Логично данные вероятности делать пропорциональными функциям приспособленности, чтобы более приспособленная особь чаще становилась родителем. На рисунке 6 показан процесс вычисления данных вероятностей. Для получения вероятности i -й особи стать родителем ее функция приспособленности делится на сумму функций приспособленности всех особей. Таким образом, сумма всех вероятностей становится равной 1, а сами вероятности остаются пропорциональными функциям приспособленности. В дальнейшем единичный отрезок разбивается на отрезки, длины которых равны нашим вероятностям. Точки разбиения лежат в массиве WW .
Вычисление вероятностей скрещивания
Теперь приступаем к процессу скрещивания. Сначала выбираем двух родителей. Для этого генерируем два случайных числа, равномерно распределенных на [0;1]. Как мы помним, программа разбила единичный отрезок на отрезки, длины которых равны вероятностям особей стать родителями. Наше случайное число попадает в один из таких отрезков. Особь, которой он соответствует, делаем родителем.
Далее осуществляем скрещивание. Для этого используем метод одноточечного кроссовера. Он заключается в том, что внутри особи ставится черта. Гены, расположенные левее черты, потомок получает от одного родителя, правее – от другого. В нашем случае черту можно поставить тремя способами (отделив 1,2 или 3 гена). Таким образом, в результате одного скрещивания получаем 6 потомков.
Далее проводим мутации. Для каждого потомка генерируем случайное число, равномерно распределенное на [0;1]. Если число меньше пороговой вероятности ver , то один из генов потомка заменяем на случайное число от 1 до 20.
После этого проводим отбор. Если среди потомков есть решения уравнения, то переписываем их в массив решений и уничтожаем. Остальных потомков сортируем в порядке убывания функции приспособленности. Первые n потомков в этом списке будут образовывать следующее поколение. Соответствующий код изображен на рисунке 7.
Создание будущего поколения, определение для будущих особей функции приспособленности
В какой момент прекращать эволюционный процесс? На тестовом примере с известным ответом можно добиться появления всех решений. В реальной задаче необходимо прекращать процесс, если в течение нескольких поколений не появляются новые решения.
В ходе исследования были изучены генетические алгоритмы для разных задач оптимизации. В результате решения первой задачи исследования уточнили понятие генетического алгоритма. В своей работе, генетические алгоритмы мы рассматриваем, как поисковые алгоритмы, основанные на механизмах натуральной селекции и генетики, которые реализуют «выживание сильнейших» среди рассмотренных структур, формируя и изменяя поисковый алгоритм на основе моделирования эволюции поиска. Генетический алгоритм — это метод перебора решений для тех задач, в которых невозможно найти решение с помощью математических формул. Однако простой перебор решений в сложной многомерной задаче – это бесконечно долго. Поэтому генетический алгоритм перебирает не все решения, а только лучшие. Алгоритм берёт группу решений и ищет среди них наиболее подходящие. Затем немного изменяет их – получает новые решения, среди которых снова отбирает лучшие, а худшие отбрасывает. Таким образом, на каждом шаге работы алгоритм отбирает наиболее подходящие решения (проводит селекцию), считая, что они на следующем шаге дадут ещё более лучшие решения (эволюционируют).
В при решении второй задачи: «Рассмотреть схему генетического алгоритма» было выявлено, что существует несколько схем Генетического Алгоритма, но в основном он делится на четыре следующих этапа: создание популяции (инициализация); размножение (скрещивание); мутации; отбор (селекция).
Генетические алгоритмы достаточно универсальны и используются для решения большого числа задач, связанных с оптимизацией. В результате решения третьей задачи исследования были проанализированы возможности генетических алгоритмов для решения различных задач оптимизации: оптимизация функций; оптимизация запросов в базах данных; разнообразные задачи на графах (задача коммивояжера, раскраска); задачи компоновки; игровые стратегии и др. Более подобно в работе рассмотрено решение одной из задач на графах (задачи коммивояжера).
В результате решения четвертой задачи написана программа на языке Паскаль, реализующая разработанный алгоритм, подходящий для решения широкого класса уравнений в целых числах, данная программа проверена на тестовом примере линейного уравнения.
Таким образом, в результате работы изучены генетические алгоритмы для разных задач оптимизации и реализован алгоритм, подходящий для решения широкого класса уравнений в целых числах. Алгоритм проверен на тестовом примере линейного уравнения. Проведен ряд вычислительных экспериментов с целью подбора оптимальных параметров алгоритма. В дальнейшем планируется реализация модификаций алгоритма для задачи коммивояжера, задачи поиска локальных минимумов функции, а также некоторых других задач.
Батищев Д.И. Генетические алгоритмы решения экстремальных задач: Учебное пособие / Под ред. Львовича Я.Е. — Воронеж, 1995.
Васильев В.И., Ильясов Б.Г. Интеллектуальные системы управления с использованием генетических алгоритмов: Учебное пособие. — Уфа: УГАТУ, 1999.
Гладков Л.А., Курейчик В.В., Курейчик В.М. Генетические алгоритмы: Учебное пособие. – 2-е изд. – М: Физматлит, 2016.
Емельянов В.В., Курейчик В.В., Курейчик В.М. Теория и практика эволюционного моделирования. — М: Физматлит, 2014.
Зенович А. В., Должикова Н. Ю., Черевичная Н. В. Применение генетических алгоритмов для решения математических уравнений // Поиск (Волгоград). 2021. № 1 (11). С. 74-78.
Котлярова В.В., Бабаев А.М. Применение генетических алгоритмов для поиска решений оптимизационных задач // Сборник статей Международной научно-практической конференции : в 6 ч.. 2017. С. 20-25.
Курейчик В.М. Генетические алгоритмы. Обзор и состояние. // Новости искусственного интеллекта. 2008. №3. С. 23-26.
Курейчик, В.М. Поисковая адаптация: теория и практика / В.М. Курейчик, Б.К. Лебедев, О.К. Лебедев. – М.: Физматлит, 2006. – С. 272.
Морозов А.В. Применение генетического алгоритма к задачам оптимизации. Реализация генетического алгоритма для задачи коммивояжера // http://docplayer.ru/395699-Primenenie-geneticheskogo-algoritma-k-zadacham-optimizacii-realizaciya-geneticheskogo-algoritma-dlya-zadachi-kommivoyazhera.html (дата обращения: 12.02.2021).
Муксимова Р.Р., Кострицкая А.В. Применение генетических алгоритмов при моделирование транспортных задач (на примере задачи Коммивояжера) // Proceedings of the 4 th International Conference . 2016. С. 79-83.
Мунасыпов Р.А., Ахмеров К.А., Ахмеров К.А. Методика оптимизации нечеткого регулятора с помощью генетических алгоритмов // Фундаментальные исследования. – 2015. – № 2-15. – С. 3275-3280; URL: http://fundamental-research.ru/ru/article/view?id=37767 (дата обращения: 06.04.2021).
Панченко Т.В. Генетические алгоритмы: учебно-методическое пособие / Т.В. Панченко. – Астрахань: Изд. дом «Астраханский университет», 2007.
Полупанов А.А. Адаптивная архитектура генетического поиска. // Перспективные информационные технологии и интеллектуальные системы, 2003.
Федоров Е.А. Исследование скорости работы генетического алгоритма и алгоритма полного перебора // Сборник избранных статей научной сессии ТУСУР. 2019. № 1-2. С. 107-109.
Генетические алгоритмы при решении уравнении

Ознакомительный материал о о генетических алгоритмах. Суть явления, виды, место в общем массиве торговых алгоритмов. Особое внимание уделено связи между естественными и искусственными генетическими процессами. Для широкого круга читателей.
СОДЕРЖАНИЕ:
Если путешествия во времени станут возможны, возникнет новая развлекательная индустрия. Назовем ее «Хронотуризм», а ее клиентов – «хронотуристами».
Представим хронотуриста, отправившегося на машине времени в Чехию 1860-х, точнее в город Брно (тогда Брюнне) в год, эдак, 1863-ий.
Что интересного можно было увидеть в провинциальном городке Австрийской империи, пусть и носившим гордый титул «столицы Моравии»?
Кто-то скажет: «Ничего, что там смотреть?» Конечно, если сравнивать Брно-1863 с античными Афинами, древним Римом и Египтом эпохи расцвета Фараонов, «кто-то» будет прав. Ратуша, несколько соборов, оперный театр… Готика, ренессанс и барокко. Кого этим удивишь. Вся старая Европа такая. С севера на юг и с запада на восток.
Проследим за нашим путешественником. Куда он пойдет? Быстрым шагом, нигде не останавливаясь, хронотурист минует «достопримечательности» чинного Брюнне и подходит к Августинскому аббатству Святого Томаша [1] .
Устремляется к ограде, прижимается к ней лбом, костяшки пальцев, сжимающие кованые прутья, побелели от напряжения, дыхание учащается. Напряженный взгляд прикован к монастырскому саду.

Вид на монастырский сад Августинского аббатства Святого Томаша [1]
Что пытается разглядеть путешественник во времени? Заглянем из-за его спины.
Монастырский сад. В дальнем углу фигура в черном склонилась над кустом. Вроде, горох, если вы что-то понимаете в ботанике.
Глаза хронотуриста расширились, в них запылало пламя. Такой взгляд у человека, одержимого наукой. Наш странник грезит биологией, точнее генетикой.
Перед ним – внешне ничем не примечательный монах Августинского аббатства Святого Томаша по имени Грегор.
Ученый-самоучка, автор прохладно принятых современниками «Опытов над растительными гибридами» 1866 г., послуживших основой Законов наследования моногенных признаков, впоследствии получивших его имя.
Отец классической генетики Грегор Иоганн Мендель разогнулся, поправил очки, подобрал рясу и перешел к следующему кусту.
Монах и горох, монастырь в Брно, далекий 1863 год…

Грегор Иоганн Мендель (1822-1884) [2]
1. ГЕНЕТИКА И ЕСТЕСТВЕННЫЙ ОТБОР, НАСЛЕДСТВЕННОСТЬ И ИЗМЕНЧИВОСТЬ
1.1. Понятие генетики и естественного отбора
Генетика – «наука о законах наследственности и изменчивости организмов» [3] . По объектам исследования различают генетику человека, животных, растений и микроорганизмов. По применяемым методам – молекулярную, экологическую, медицинскую, биохимическую генетику и т.д.
Генетика тесно связана с естественным отбором (эволюцией). По сути, это одно и то же природное явление, последовательные этапы которого описываются отдельными разделами биологической науки.
Под естественным отбором понимают магистральный эволюционный процесс, при котором количество особей с максимально благоприятными признаками (наиболее приспособленных, живучих) увеличивается, тогда как число особей с неблагоприятными или менее благоприятными признаками сокращается [4] . Достигается это через механизм генетического наследования.
1.2. Генетическая информация. ДНК и хромосомы
Каждая клетка живого организма содержит о нем закодированную информацию. Наследственный материал получил название «геном» [5] . Подавляющее большинство геномов, в том числе, геном человека, состоят из ДНК [6] , у ряда вирусов геном формируется из РНК [7] .
Генетическая информация генома комплектуется из генов. «Ген — единица передачи наследственной информации и участок ДНК, влияющий на определенную характеристику организма» [8] . Совокупность генов именуют генотипом [9] .
ДНК в разных формах [8]
С точки зрения химии, ДНК – длинная полимерная молекула в виде двойной спирали, состоящая из различных комбинаций четырех блоков, нуклеотидов. Каждому нуклеотиду присвоена латинская буква: A, G, T, C. За генетическую информацию отвечает порядок следования, чередования нуклеотидов в ДНК – генетический код. Генетические сведения, в конечном итоге, должны быть прочитаны и использованы клеткой при синтезе биополимеров, ее кирпичиков.
Каждая молекула ДНК окружена оболочкой – хромосомой и находится в ядре клетки. Для сохранения целостности генетической информации, хромосомы в ядре отделены друг от друга.
Человеческий геном состоит из 23 пар хромосом и одной отдельной ДНК [10] . В них зашито 28 тыс. генов.
1.3. Скрещивание, мутация и селекция
При размножении происходит слияние родительских половых клеток, их ДНК образуют ДНК потомства. Синтезируется дочерняя молекула ДНК. Процесс, названый репликацией ДНК [11] , заключается в разделении родительских ДНК на две части, с их последующим обменом и сшиванием в новую, дочернюю ДНК. Исходя из перекрестного характера, он известен, как скрещивание, кроссовер или кроссинговер (cross-over, crossing over).
Репликацию можно рассматривать, как часть более общего биомеханизма: рекомбинации. Рекомбинация – «перераспределение генетического материала (ДНК или РНК) путем разрыва и соединения разных молекул, приводящее к появлению новых комбинаций генов или других нуклеотидных последовательностей» [12] .
Таким образом, генетическая информация от родителей точно передается детям. Обеспечивается наследственность и изменчивость.
При нестандартных внешних условиях (радиация, окисление и пр.) ДНК способны мутировать (изменяться, повреждаться). Потомство будет наследовать иной, смещенный набор генов. Если мутация приводит к получению полезных свойств, они могут закрепиться и обеспечить скачок в развитии вида.
Процедура естественного отбора интенсифицируется и подправляется селекцией. Селекция пришла на смену простому искусственному отбору и позволяет «воздействовать на растения и животных с целью изменения их наследственных качеств в нужном для человека направлении» [13] . Мощный импульс современной селекции придала генная инженерия.
2. ГЕНЕТИЧЕСКИЙ АЛГОРИТМ. ОПРЕДЕЛЕНИЕ И ПРИНЦИП ДЕЙСТВИЯ
Под генетическим алгоритмом (далее по тексту ГА) понимают «алгоритм решения задач по оптимизации и моделированию путем случайного подбора с привлечением механизмов естественной эволюции» [14] . В ГА встроены такие понятия классической генетики как, наследование, изменчивость, мутация и скрещивание.
Почином в области симуляции природного отбора стали исследования Нильса Баричелли, выполненные им в 1954 г. на компьютерах Принстонского института перспективных исследований. Отцом генетических алгоритмов считают американца Джона Генри Холланда, автора книги «Адаптация в естественных и искусственных системах», Adaptation in Natural and Artificial Systems (1975).

Упрощенно алгоритм создания и функционирования ГА выглядит так:
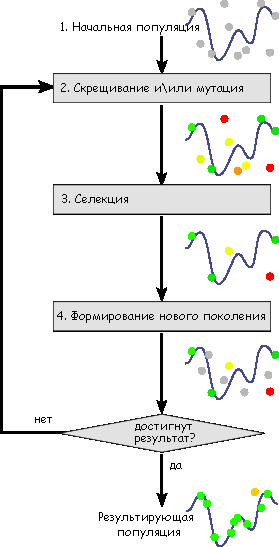
Схема работы генетического алгоритма [14]
ЭТАП 1. НАЧАЛЬНАЯ ПОПУЛЯЦИЯ И ФУНКЦИЯ ПРИСПОСОБЛЕННОСТИ
Создатель генетического алгоритма, «беря на себя функцию» природы или, высказываясь с пафосом, Создателя, формирует стартовую группу виртуальных, искусственных особей. Группа заточена под решение, оптимизацию выбранной задачи. Каждая особь – некий вектор, строка или, говоря генетически, генотип, хромосома или ДНК, включающая определенный комплект формализованных элементов. Ими могут быть число, единица информации (бит), иной объект. Аналог гена в традиционной генетике.
Например, для уравнения, решение которого аналитически не всегда выполнимо, подобным вектором (хромосомой) станет набор из его приблизительных корней, подстановка которых даст возможность решить уравнение с той или иной степенью точности. Для инвестиционного проекта генотипом выступит вариант или стратегия инвестирования, содержащий строку из нескольких бюджетов (расходов на проект) или иных элементов, выполняющих роль генов.
К сожалению, в «генно-алгоритмической» литературе присутствует известная путаница в использовании приведенных терминов. Так, иногда геном называют хромосому, что не совсем корректно и с точки зрения биогенетики, и пр. Надо быть внимательным и ориентироваться по ходу изложения.
Отобранные особи оцениваются, как хорошо они решают поставленную задачу, насколько «жизнеспособны». Делается это через функцию приспособленности (ФП), fitness function.
Функция приспособленности — «вещественная или целочисленная функция одной или нескольких переменных, подлежащая оптимизации в результате работы генетического алгоритма, направляет эволюцию в сторону оптимального решения» [16] .
ФП проверяет представителей нулевого и следующих поколений. Исходя из приведенных выше сценариев для ГА, в качестве ФП могут выступать погрешность в решении уравнения или критерий успеха инвестпроекта (чистая начальная стоимость, внутренняя норма доходности, срок окупаемости, рентабельность).
Особенно стараться при выборе кандидатов в стартовую популяцию не стоит – в процессе работы алгоритм все подправит. Главные требования – соответствие требуемому формату данных, способность размножаться и возможность корректного расчета ФП.
ЭТАП 2. РАЗМНОЖЕНИЕ. СКРЕЩИВАНИЕ И МУТАЦИЯ
После тестирования начальной популяции посредством ФП, для размножения отбираются особи с лучшими параметрами выживаемости и жизнеспособности. Они подвергаются процедуре скрещивания (кроссовера): искусственные родительские ДНК (хромосомы) разрываются и обмениваются фрагментами. Цель – улучшить потомство. При необходимости, используется внешнее вмешательство в генотип – мутация.
Преимущественное направление выбора родителей – случайная сортировка, результат работы генератора случайных чисел.
Для того, чтобы и здесь была некая система, применяют три пути формирования пары:
1) Панмиксия – «папа» и «мама» подбираются случайно.
2) Инбридинг – «папа» (первый родитель) выбирается случайно, а «маму» (второго родителя) ищут максимально похожую на «папу».
3) Аутбридинг – «папа», по-прежнему, случаен, но предпочтение отдают той «маме», которая меньше всех напоминает «сильную половину».
Все очень подобно человеческим судьбам, вы не находите?
Основной посыл – «сильное», «здоровое», если хотите, «красивое» потомство, в свою очередь, способное при скрещивании произвести «хороших и симпатичных» детей.
ЭТАП 3. СЕЛЕКЦИЯ
Согласно установленным критериям, функция приспособленности отбирает лучших из «родившегося» потомства. Они формируют очередное новое поколение, готовое к размножению. Прочим – «дорога на кладбище».
У селекции в генетическом алгоритме есть одна тонкость. Несмотря, на фазы отбора, размножаться должно максимальное число участников. Идеально – все. На практике, после каждой стадии сильные должны тянуть с собой какую-то колонию слабых и скрещиваться не только в парах сильный-сильный, но и в дуэтах сильный-слабый. Здесь особенно эффективны и востребованы мутации.
В противном случае, по меткому выражению автора одной из статей о ГА [17] , уже сразу, на двух-трех первых циклах, создатель генетического алгоритма получит «альфа-самца», супермена (или супервумен), который/которая подомнет под себя всю популяцию, «взгромоздится на трон», окружит себя копиями-подражателями, и о дальнейшем плавном улучшении детей речь уже не пойдет.
Простейший принцип отбора – «турнирная селекция». После кроссовера случайным образом выбираются пары особей. Победитель в паре. тот у кого значение ФП лучше. Среди других подходов можно отметить вероятностные методы рулетки, ранжирования, равномерного ранжирования и сигма-отсечения [14] .
ЭТАП 4. ФОРМИРОВАНИЕ НОВОГО ПОКОЛЕНИЯ.
Логическое завершение третьего этапа.
Далее, племя генотипов гоняется генетическим алгоритмом по этапам 2-4. И так – до остановки.
Остановка имеет место в трех случаях.
1) Результат достигнут и решение найдено.
2) Количество поколений, предусмотренных ГА на эволюцию, исчерпано.
3) Закончилось время отбора.
3. ПРИМЕР. ГЕНЕТИЧЕСКИЙ АЛГОРИТМ И ДИОФАНТОВО УРАВНЕНИЕ
Суть алгоритмической генетики будет проиллюстрирована на линейном Диофантовом уравнении (ДУ).
Использование генетического алгоритма для поиска корней линейного ДУ – излюбленное рунетовское объяснение смысла ГА для новичков (смотрите, в частности [17] ). Не претендуя на оригинальность, покажем и мы, как работает ГА для этой задачи. Образец привлекает доступностью и наглядностью, и красив математически, что немаловажно.
3.1. Диофантово уравнение и немного истории
Прежде всего, что такое Диофантово уравнение?
Где P – целочисленная функция, обычно полином с целыми коэффициентами, переменные xi также принимают целые значения [18] . Названо по имени древнегреческого математика Диофанта Александрийского.
Линейное ДУ представляется так:
где d – некоторое целое число.
К понятию ДУ примыкает знаменитая «Великая теорема Ферма» [19] , гласящая, что для любого натурального n>2, уравнение x n +y n =z n не имеет целых решений. Другими словами, подобное ДУ неразрешимо. Для n=2, решение лежит на поверхности: x=3, y=4, z=5.
Ироничный французский математик (на то, он и француз) Пьер Ферма в 1637 году на полях книги «Арифметика», все того же Диофанта, написал: «Наоборот, невозможно разложить куб на два куба, биквадрат на два биквадрата, и вообще никакую степень, большую квадрата, на две степени с тем же показателем. Я нашел этому поистине чудесное доказательство, но поля книги слишком узки для него».
Узость полей «Арифметика» Диофанта заставили лучших (и не только) математиков почти 360 лет искать доказательство теоремы Ферма. Только в 1995 году профессор Принстонского университета Эндрю Джон Уайлс публикует наиболее полное (на сегодня) корректное доказательство Великой теоремы Ферма.
3.2. Постановка задачи
Конечно, задание, которое будет стоять перед нашим генетическим алгоритмом, не идет ни в какое сравнение с проблемой Ферма и Уайлса.
ГА должен наметить путь поиска корней линейного ДУ с четырьмя переменными:
3.3. Начальная популяция (родители)
Предположив, что корни уравнения лежат на отрезке [1;30], выберем начальную популяцию из пяти особей (генотипов) – строк, включающих четыре случайных числа (гена) от 1 до 30, потенциальных корней решаемого ДУ:
Особь 1 – (1,28,15,3);
Особь 4 – (23,8,16,19);
Подставим поочередно данный массив чисел в левую часть уравнения и сравним полученные значения с правой частью, числом 30. По сути, применим функцию приспособленности к каждому генотипу.
Результаты обработки сведем в Таблицу 1:
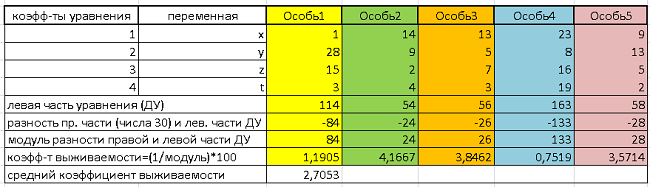
В первой и второй колонках обозначены коэффициенты и переменные ДУ. В следующих – заданные генотипы. Каждая особь отражена четырьмя числами (генами), обозначенными по тексту выше.
Далее, для каждой особи считается левая часть уравнения. Затем, для каждой особи берется модуль разности правой части ДУ (числа 30) и получившегося значения левой части. Таким образом, начинает работать функция приспособленности. Для формализации итоговых данных ФП, вычисляется величина, обратная найденному модулю, и умножается на 100. Полученный показатель назовем «коэффициентом выживания» (кратко, КВ). Чем он выше, тем исследуемый генотип имеет большее право идти дальше.
КВ лежит в диапазоне от 0,75 (Особь 4), худший результат, до 4,17 (Особь2) – «победитель соревнования». Среднее арифметическое значение КВ равно 2,71.
3.4. Скрещивание, первые дети
Переходим к размножению, через скрещивание, к кроссоверу.
Отберем случайным образом пять пар родителей (особей). Генератор случайных чисел настроим так, чтобы он учитывал коэффициенты выживания. Вероятность выпадения особи должна быть пропорциональна ее КВ. Вообразим многомерный куб со ста гранями. На 31-ой грани нанесен значок лучшей Особи2, на 28-ми гранях – значок Особи3, у которой результаты чуть похуже и т.д. Наименьшее количество граней заслужила Особь4 – 6. Число граней пропорционально весу КВ каждой особи.
Кидаем «сто-сторонний кубик» десять раз (пять раз по два). Пары для скрещивания вполне могут иметь следующий вид:
Главный лузер, Особь4, вообще не выпала. Победитель (Особь2) появляется дважды. Остальные участники – крепкие середняки.
Для краткости, рассмотрим потомство одной, первой пары: Особь3-Особь1.
Кроссовер происходит путем разрывов строк (ДНК) каждой особи и соединения получившихся кусочков в ДНК ребенка.
Процесс скрещивания отображен в Таблице 2:
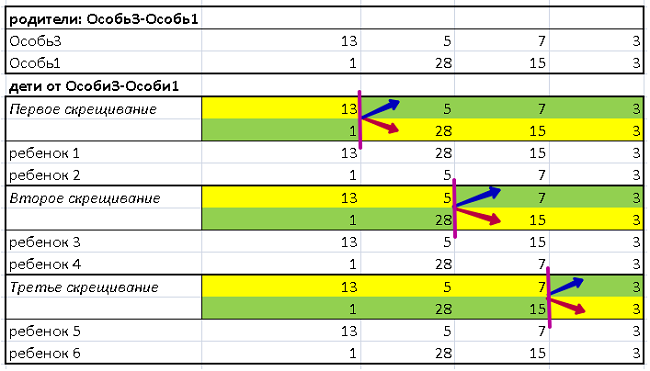
В верхней части представлен генотип родителей. В нижней – детей после трех скрещиваний. Разрыв цепочки родительской ДНК проходит по границе смены цветов, с желтого на зеленый и с зеленого на желтый (вертикальный отрезок розового цвета)
При первом скрещивании, часть ДНК Особи3 с одним геном «13» (желтое поле) по красной стрелке сшивается с фрагментом ДНК Особи 1, строка (28,15,3) на желтом поле. Рождается ребенок1 (13, 28, 15, 3).
Здесь же, кусочек ДНК Особи1 с одним геном «1» (зеленое поле) по синей стрелке сшивается с фрагментом ДНК Особи 3, строка (5,7,3) на зеленом поле. Рождается ребенок2 (1, 5, 7, 3).
Алгоритм второго и третьего кросссовера работает также. Розовая граница разрыва строки перемещается вправо.
Итог – от пары родителей Особь3-Особь1 рождаются 6 детей: ребенок1, ребенок2…ребенок6.
Настало время проверить потомство от первой пары на функцию выживаемости и сравнить результат с достижениями «пап и мам».
Строим Таблицу 3, аналогичную Таблице 1:
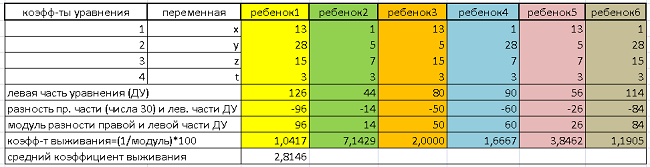
Средний коэффициент выживания повысился до 2,81 (у родителей КВ=2,70). Лучшее дитя – Ребенок2 существенно превзошло лучшего родителя (Особь2). По КВ: 7,14 против 4,17. Что уж говорить о «родных папах и мамах» (Особей 3 и 1) с КВ 3,84 и 1,19 соответственно.
3.5. Продолжение процесса и остановка
Далее – стандартные этапы ГА.
Скрещиваются 4 оставшиеся пары. К детям применяется функция приспособленности. Отбираются лучшие индивидуумы, по определенной системе «разбавляются» не очень удачными ровесниками и вновь – скрещивание, селекция и формирование нового поколения. Вплоть до остановки алгоритма согласно условиям, описанными в общем виде выше.
Результат может считаться достигнутым, когда левая часть уравнения будет отличаться от правой (числа 30), допустим, не более, чем на 0,00001 или, предположим, когда КВ преодолеет отметку 10000. Все решает разработчик.
Так интересно соединяются биогенетика гороха и алгогенетика уравнения.
ПРИМЕЧАНИЯ И ССЫЛКИ
(источник – Википедия, если не оговорено иное)
- ↑ «Старобрненский монастырь»
- ↑ «Мендель, Грегор Иоганн»
- ↑ «Генетика»
- ↑ «Естественный отбор»
- ↑ «Геном»
- ↑ДНК – дезоксирибонуклеиновая кислота — одна из трех макромолекул (две другие – РНК и белки), обеспечивающая хранение, передачу из поколения в поколение и реализацию генетической программы развития и функционирования живых организмов
- ↑ РНК – одна из трех макромолекул (две другие – ДНК и белки), которые содержатся в клетках всех живых организмов и играют важную роль в кодировании, прочтении, регуляции и выражении генов
- ↑ «Дезоксирибонуклеиновая кислота»
- ↑ «Генотип»
- ↑ «Геном человека»
- ↑ «Репликация ДНК»
- ↑ «Рекомбинация (биология)»
- ↑ «Селекция»
- ↑ «Генетический алгоритм»
- ↑ «Холланд, Джон Генри»
- ↑ «Функция приспособленности»
- ↑ «Генетический алгоритм. Просто о сложном», Habr, 20.09.2011
- ↑ «Диофантово уравнение»
- ↑ «Великая теорема Ферма»
ИСПОЛЬЗУЕМЫЕ СОКРАЩЕНИЯ
ДНК – дезоксирибонуклеиновая кислота
ГА – генетический алгоритм
ФП – функция приспособленности
ДУ – Диофантово уравнение
КВ – коэффициент выживания (для раздела 3 текста)
http://school-science.ru/12/7/48343
http://rusforexclub.com/articles/18-algo-trading/90-geneticheskie-algoritmy