Гипотеза о равенстве коэффициента уравнения нулю
77-1. Как проверить гипотезу о нулевом значении теоретического коэффициента регрессии?
Для проверки нулевой гипотезы H0 о равенстве нулю некоторого коэффициента регрессионного уравнения (H0:β2=0, H0: β2≠0) необходимо сравнить фактическое значение статистики, найденное по формуле с критическим значением t-статистики Стьюдента для выбранного уровня значимости, то есть со значением двусторонней (1-α) квантили t-статистики Стьюдента с n-k степенями свободы. Величина α характеризует допустимый уровень вероятности ошибиться, отвергнув нулевую гипотезу, когда она верна.
Если фактическое значение t-статистики Стьюдента больше критического значения статистики, то нулевая гипотеза отвергается для данного уровня значимости α, иначе нулевая гипотеза не может быть отвергнута для данного уровня значимости α. В случае отвержения нулевой гипотезы для уровня значимости говорят, что коэффициент β регрессионного уравнения значим на уровне значимости α (или, говорят, что оценка коэффициента β значимо отличается от нуля), и соответствующий ему регрессор объясняет вариацию зависимой переменной. В противном случае говорят, что коэффициент незначим на уровне значимости α.
Второй способ проверки гипотезы – сравнить p-значение (фактическую вероятность принятия нулевой гипотезы данного коэффициента регрессии) с выбранным уровнем значимости. Если выполняется условие p |t критич|, то гипотеза H0 отвергается, если меньше, то подтверждается
79. Что такое p-значение (p-value, обозначаемое в программе EViews как Prob.) для
статистического критерия?
Метод p-value («метод значения вероятность») p-value = Prob – вероятность того, что случайно будет получен результат лучше, чем у нас (тот, что рассчитан). Если p-value маленький, то это хорошо, а если большой, то плохо.
80. В чем заключается техника работы с p-значением при проверке гипотез?
Смотрим значение prob. в таблице с результатами регрессии и сравниваем с 0,01 и 0,05.
Иначе коэффициент (уравнение) не значим.
81. Как рассчитать p-значение в случае, если невозможно получить доступ к эконометрической программе, или в ней не предусмотрен его расчет?
Открываем таблицу t-распределения, смотрим ряд для нашего числа степеней свободы. Если в нем есть значение t-статистики для рассматриваемого параметра, то уровень значимости (верх таблицы) будет как раз искомым значением p. Если значение t-статистики располагается между двумя табличными, то на основе значений для двух табличных можно приближенно рассчитать искомое по формуле , где t – значение t-статистики, t1 – первое из табличных значений, t2 – второе (большее, правее первого в ряду), а p1 и p2 – значения p соответственно для первого и второго табличных значений t-статистики.
82. Что такое ошибки первого и второго рода в проверке гипотез о коэффициентах регрессии?
Ошибка I рода состоит в том, что мы отвергаем Н0, когда на самом деле она истина.
Ошибка II рода имеет место в случае, если мы принимаем Н0, когда она ложна.
83. Какова связь ошибок первого и второго рода при проверке гипотез о коэффициентах регрессии?
При уменьшении вероятности ошибки 1ого рода увеличивается вероятность ошибки 2ого рода.
84. Что такое мощность критерия?
Мощность критерия (теста)- это вероятность допустить ошибку II рода (β), то есть принять ложную гипотезу. Вычисляется по формуле (1 − β). Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода. Используя односторонний критерий вместо двустороннего, можно получить большую мощность при любом уровне значимости. Нужно, однако, помнить, что выигрыш в мощности будет получен только в условиях, когда использование одностороннего критерия оправдано.
Пример нахождения статистической значимости коэффициентов регрессии
Числитель в этой формуле может быть рассчитан через коэффициент детерминации и общую дисперсию признака-результата:  .
.
Для параметра a критерий проверки гипотезы о незначимом отличии его от нуля имеет вид:
,
где — оценка параметра регрессии, полученная по наблюдаемым данным;
μa – стандартная ошибка параметра a.
Для линейного парного уравнения регрессии: .
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции в генеральной совокупности используют следующий критерий: , где ryx — оценка коэффициента корреляции, полученная по наблюдаемым данным; mr – стандартная ошибка коэффициента корреляции ryx.
Для линейного парного уравнения регрессии: .
В парной линейной регрессии между наблюдаемыми значениями критериев существует взаимосвязь: t ( b =0) = t (r=0).
Пример №1 . Уравнение имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.73 2 = 0.54, т.е. в 54% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — средняя.
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 69 | 124 | 4761 | 15376 | 8556 | 128.48 | 491.36 | 20.11 | 367.36 |
| 83 | 133 | 6889 | 17689 | 11039 | 141.4 | 173.36 | 70.56 | 26.69 |
| 92 | 146 | 8464 | 21316 | 13432 | 149.7 | 0.03 | 13.71 | 14.69 |
| 97 | 153 | 9409 | 23409 | 14841 | 154.32 | 46.69 | 1.73 | 78.03 |
| 88 | 138 | 7744 | 19044 | 12144 | 146.01 | 66.69 | 64.21 | 0.03 |
| 93 | 159 | 8649 | 25281 | 14787 | 150.63 | 164.69 | 70.13 | 23.36 |
| 74 | 145 | 5476 | 21025 | 10730 | 133.1 | 1.36 | 141.68 | 200.69 |
| 79 | 152 | 6241 | 23104 | 12008 | 137.71 | 34.03 | 204.21 | 84.03 |
| 105 | 168 | 11025 | 28224 | 17640 | 161.7 | 476.69 | 39.74 | 283.36 |
| 99 | 154 | 9801 | 23716 | 15246 | 156.16 | 61.36 | 4.67 | 117.36 |
| 85 | 127 | 7225 | 16129 | 10795 | 143.25 | 367.36 | 263.91 | 10.03 |
| 94 | 155 | 8836 | 24025 | 14570 | 151.55 | 78.03 | 11.91 | 34.03 |
| 1058 | 1754 | 94520 | 258338 | 155788 | 1754 | 1961.67 | 906.57 | 1239.67 |
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.2704
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 88,16
(128.06;163.97)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (3.41>1.812).
Статистическая значимость коэффициента регрессии b подтверждается (2.7>1.812).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.812):
(a — tтабл·S a; a + tтабл·Sa)
(0.4325;1.4126)
(b — tтабл·S b; b + tтабл·Sb)
(21.3389;108.3164)
2) F-статистики
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим.
Пример №2 . По территориям региона приводятся данные за 199Х г.;
| Среднедневная заработная плата, руб., у | ||
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х , составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение находим с помощью калькулятора.
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
12a+1027b=1869
1027a+89907b=161808
Из первого уравнения выражаем а и подставим во второе уравнение. Получаем b = 0.92, a = 76.98
Уравнение регрессии: y = 0.92 x + 76.98 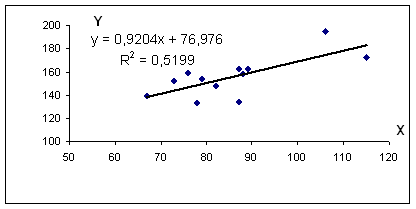
1. Параметры уравнения регрессии.
Выборочные средние.
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%, среднедневная заработная плата изменится менее чем на 1%. Другими словами — влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199, т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами — точность подбора уравнения регрессии — средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| y 2 | x·y | y(x) | (y i — y ) 2 | (y-y(x)) 2 | (x i — x ) 2 | |y-y x |:y | |||
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим tкрит:
tкрит = (10;0.05) = 1.812
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(0.9204 — 1.812·0.2797; 0.9204 + 1.812·0.2797)
(0.4136;1.4273)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a-ta)
(76.9765 — 1.812·24.2116; 76.9765 + 1.812·24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Нулевая гипотеза в статистике: пример. Проверка нулевой гипотезы
Статистика — сложная наука об измерении и анализе различных данных. Как и во многих других дисциплинах, в этой отрасли существует понятие гипотезы. Так, гипотеза в статистике — это какое-либо положение, которое нужно принять или отвергнуть. Причём в данной отрасли есть несколько видов таких допущений, схожих между собой по определению, но отличающихся на практике. Нулевая гипотеза — сегодняшний предмет изучения.
От общего к частному: гипотезы в статистике
От основного определения предположений отходит ещё одно, не менее важное, — статистическая гипотеза есть изучение генеральной совокупности важных для науки объектов, относительно коих учёными делаются выводы. Ее можно проверить с помощью выборки (части генеральной совокупности). Приведём несколько примеров статистических гипотез:
 1. Успеваемость всего класса, возможно, зависит от уровня образования каждого учащегося.
1. Успеваемость всего класса, возможно, зависит от уровня образования каждого учащегося.
2. Начальный курс математики в равной степени усваивается как детьми, пришедшими в школу в 6 лет, так и детьми, пришедшими в 7.
Простой гипотезой в статистике называют такое предположение, которое однозначно характеризует определённый параметр величины, взятой учёным.
Сложная состоит из нескольких или бесконечного множества простых. Указывается некоторая область или нет точного ответа.
Полезно понимать несколько определений гипотез в статистике, чтобы не путать их на практике.
Концепция нулевой гипотезы
Нулевая гипотеза — это теория о том, что есть некие две совокупности, которые не различаются между собой. Однако на научном уровне нет понятия «не различаются», но есть «их сходство равно нулю». От этого определения и было образовано понятие. В статистике нулевая гипотеза обозначается как Н0. Причём крайним значением невозможного (маловероятного) считается от 0.01 до 0.05 или менее.
Лучше разобрать, что такое нулевая гипотеза, пример из жизни поможет. Педагог в университете предположил, что различный уровень подготовки учащихся двух групп к зачётной работе вызван незначительными параметрами, случайными причинами, не влияющими на общий уровень образования (разница в подготовке двух групп студентов равна нулю).
Однако встречно стоит привести пример альтернативной гипотезы — допущения, опровергающего утверждение нулевой теории (Н1). Например: директор университета предположил, что различный уровень в подготовке к зачётной работе у учащихся двух групп вызван применением педагогами разных методик обучения (разница в подготовке двух групп существенна и на то есть объяснение).
 Теперь сразу видна разница между понятиями «нулевая гипотеза» и «альтернативная гипотеза». Примеры иллюстрируют эти понятия.
Теперь сразу видна разница между понятиями «нулевая гипотеза» и «альтернативная гипотеза». Примеры иллюстрируют эти понятия.
Проверка нулевой гипотезы
Создать предположение — это ещё полбеды. Настоящей проблемой для новичков считается проверка нулевой гипотезы. Именно тут многих и ожидают трудности.
Используя метод альтернативной гипотезы, утверждающей нечто обратное нулевой теории, можно сравнить оба варианта и выбрать верный. Так действует статистика.
Пусть нулевая гипотеза Н0, а альтернативная Н1, тогда:
Н0: c = c0;
Н1: c ≠ c0.
Здесь c — это некое среднее значение генеральной совокупности, которое предстоит найти, а c0 — данное изначально значение, по отношению к которому проверяется гипотеза. Также есть некоторое число Х — среднее значение выборки, по которому определяется c0.
Итак, проверка заключается в сравнении Х и c0, если Х=c0 ,то принимается нулевая гипотеза. Если же Х≠c0, то по условию верной считается альтернативная.
«Доверительный» способ проверки
Существует наиболее действенный способ, с помощью которого нулевая статистическая гипотеза легко проверяется на практике. Он заключается в построении диапазона значений до 95% точности.
Для начала понадобится знать формулу расчёта доверительного интервала:
X — t*Sx ≤ c ≤ X + t*Sx,
где Х — данное изначально число на основе альтернативной гипотезы;
t — табличные величины (коэффициент Стьюдента);
Sx — стандартная средняя ошибка, которая рассчитывается как Sx = σ/√n, где в числителе стандартное отклонение, а в знаменателе — объём выборки.
Итак, предположим ситуацию. До ремонта конвейер в день выпускал 32.1 кг конечной продукции, а после ремонта, как утверждает предприниматель, коэффициент полезного действия вырос, и конвейер, по недельной проверке, начал выпускать 39.6 кг в среднем.
 Нулевая гипотеза будет утверждать, что ремонт никак не повлиял на КПД конвейера. Альтернативная гипотеза скажет, что ремонт коренным образом изменил КПД конвейера, поэтому производительность его повысилась.
Нулевая гипотеза будет утверждать, что ремонт никак не повлиял на КПД конвейера. Альтернативная гипотеза скажет, что ремонт коренным образом изменил КПД конвейера, поэтому производительность его повысилась.
По таблице находим n=7, t = 2,447, откуда формула примет следующий вид:
39,6 – 2,447*4,2 ≤ с ≤ 39,6 + 2,447*4,2;
Получается, что значение 32.1 входит в диапазон, а следовательно, значение, предложенное альтернативой — 39.6 — не принимается автоматически. Помните, что сначала проверяется на правильность нулевая гипотеза, а потом — противоположная.
Разновидности отрицания
До этого рассматривался такой вариант построения гипотезы, где Н0 утверждает что-либо, а Н1 это опровергает. Откуда можно было составить подобную систему:
Н0: с = с0;
Н1: с ≠ с0.
Но существует ещё два родственных способа опровержения. К примеру, нулевая гипотеза утверждает, что средняя оценка успеваемости класса больше 4.54, а альтернативная тогда скажет, что средняя успеваемость того же класса менее 4.54. И выглядеть в виде системы это будет так:
http://math.semestr.ru/corel/prim3.php
http://businessman.ru/new-nulevaya-gipoteza-v-statistike-primer-proverka-nulevoj-gipotezy.html