Расчет доверительных интервалов и прогнозов для линейного уравнения регрессии
Как правило, в линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров.Показатели корреляционной связи, вычисленные по ограниченной совокупности (по выборке), являются лишь оценками той или иной статистической закономерности, поскольку в любом параметре сохраняется элемент не полностью погасившейся случайности, присущей индивидуальным значениям признаков. Поэтому необходима статистическая оценка степени точности и надежности параметров корреляции. Под надежностью здесь понимается вероятность того, что значение проверяемого параметра не равно нулю, не включает в себя величины противоположных знаков.
Вероятностная оценка параметров корреляции производится по общим правилам проверки статистических гипотез, разработанным математической статистикой, в частности путем сравнения оцениваемой величины со средней случайной ошибкой оценки. Для коэффициента парной регрессии b средняя ошибка оценки вычисляется как:
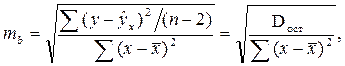
где Dост – остаточная дисперсия на одну степень свободы.
Для нашего примера величина стандартной ошибки коэффициента регрессии составила:
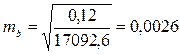 .
.
Для оценки того, насколько точные значения показателей могут отличаться от рассчитанных, осуществляется построение доверительных интервалов. Они определяют пределы, в которых лежат точные значения определяемых показателей с заданной степенью точности, соответствующей заданному уровню значимости α (α – вероятность отвергнуть правильную гипотезу при условии, что она верна, обычно принимается равной 0,05 или 0,01).
Для оценки статистической значимости коэффициента линейной регрессии и линейного коэффициента парной корреляции, а также для расчета доверительных интервалов b, применяется t – критерий Стьюдента.
Для оценки существенности коэффициента регрессии его величина сравнивается с его стандартной ошибкой, т.е. определяется фактическое значение t-критерия Стьюдента: 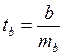 , которое затем сравнивается с табличным значением при определенном уровне значимости а и числе степеней свободы (n — 2).
, которое затем сравнивается с табличным значением при определенном уровне значимости а и числе степеней свободы (n — 2).
В рассматриваемом примере фактическое значение t-критерия для коэффициента регрессии составило:
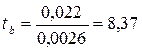 .
.
Этот же результат получим, извлекая квадратный корень из найденного F-критерия, т.е.
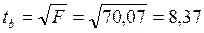 .
.
Действительно, справедливо равенство 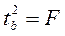 .
.
При 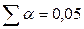 (для двустороннего критерия) и числе степеней свободы 13 табличное значение tb=2,16. Так как фактическое значение t‑критерия превышает табличное, то, следовательно, гипотезу о несущественности коэффициента регрессии можно отклонить.
(для двустороннего критерия) и числе степеней свободы 13 табличное значение tb=2,16. Так как фактическое значение t‑критерия превышает табличное, то, следовательно, гипотезу о несущественности коэффициента регрессии можно отклонить.
Для расчета доверительных интервалов для параметров a и b уравнения линейной регрессии определяем предельную ошибку ∆ для каждого показателя:
Формулы для расчета доверительных интервалов имеют вид:
Если границы интервала имеют разные знаки, т.е. в эти границы попадает ноль, то оцениваемый параметр принимается нулевым.
Доверительный интервал для коэффициента регрессии определяется как 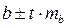 . Для коэффициента регрессии b в примере 95%-ные границы составят:
. Для коэффициента регрессии b в примере 95%-ные границы составят:
0,022 ± 2,16·0,0026 = 0,022 ± 0,0057, т.е.
Поскольку коэффициент регрессии в эконометрических исследованиях имеет четкую экономическую интерпретацию, то доверительные границы интервала для коэффициента регрессии не должны содержать противоречивых результатов, например, -10 ≤ b ≤ 40. Такого рода запись указывает, что истинное значение коэффициента регрессии одновременно содержит положительные и отрицательные величины и даже ноль, чего не может быть.
Стандартная ошибка параметра а определяется по формуле:
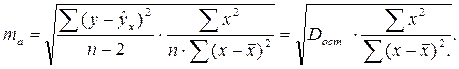
Процедура оценивания существенности данного параметра не отличается от рассмотренной выше для коэффициента регрессии; вычисляется t-критерий: 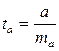 , его величина сравнивается с табличным значением при df = n — 2 степенях свободы. В нашем примере ma составила 0,032.
, его величина сравнивается с табличным значением при df = n — 2 степенях свободы. В нашем примере ma составила 0,032.
Значимость линейного коэффициента корреляции проверяется на основе величины ошибки коэффициента корреляции mr:
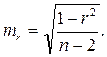
Фактическое значение t-критерия Стьюдента определяется как
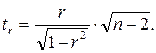
Данная формула свидетельствует, что в парной линейной регрессии 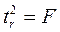 , ибо, как уже указывалось,
, ибо, как уже указывалось, 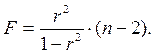 Кроме того,
Кроме того, 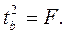 Следовательно,
Следовательно, 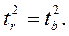
Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
В рассматриваемом примере tr совпало с tb. Величина tr =8,37 значительно превышает табличное значение 2,16 при а=0,05. Следовательно, коэффициент корреляции существенно отличен от нуля и зависимость является достоверной.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения фактора, называют точечным прогнозом. Вероятность точной реализации такого прогноза крайне мала. Необходимо сопроводить его значением средней ошибки прогноза или доверительным интервалом прогноза с достаточно большой вероятностью.
Точечный прогноз заключается в получении прогнозного значения yp, которое определяется путем подстановки в уравнение регрессии
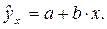 соответствующего прогнозного значения xp:
соответствующего прогнозного значения xp:
Интервальный прогноз заключается в построении доверительного интервала прогноза, т.е. верхней и нижней границы ypmin, ypmax интервала, содержащего точную величину для прогнозного значения 
(ypmin 2 – индекс детерминации;
n – число наблюдений;
m – число параметров при переменных х.
Величина m характеризует число степеней свободы для факторной суммы квадратов, а (n – m — 1) – число степеней свободы для остаточной суммы квадратов.
Для степенной функции 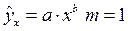 и формула F – критерия примет тот же вид, что и при линейной зависимости:
и формула F – критерия примет тот же вид, что и при линейной зависимости:
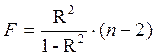
Для параболы второй степени y=a + b·x + c·x 2 + ε m=2 и 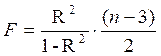 .
.
Для оценки качества построенной модели используется также средняя ошибка аппроксимации. Фактические значения результативного признака отличаются от теоретических, рассчитанных по уравнению регрессии, т.е. у и 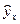 . Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, лучше качество модели. Величина отклонений фактических и расчетных значений результативного признака (у—
. Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, лучше качество модели. Величина отклонений фактических и расчетных значений результативного признака (у— 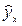 ) по каждому наблюдению представляет собой ошибку аппроксимации. Их число соответствует объему совокупности. В отдельных случаях ошибка аппроксимации может оказаться равной нулю. Для сравнения берутся величины отклонений, выраженные в процентах к фактическим значениям. Так, если для первого наблюдения у=20, а для второго у=50, ошибка аппроксимации составит 25% для первого наблюдения и 20% — для второго.
) по каждому наблюдению представляет собой ошибку аппроксимации. Их число соответствует объему совокупности. В отдельных случаях ошибка аппроксимации может оказаться равной нулю. Для сравнения берутся величины отклонений, выраженные в процентах к фактическим значениям. Так, если для первого наблюдения у=20, а для второго у=50, ошибка аппроксимации составит 25% для первого наблюдения и 20% — для второго.
Поскольку (у— ) может быть как величиной положительной, так и отрицательной, то ошибки аппроксимации для каждого наблюдения принято определять в процентах по модулю.
Чтобы иметь общее суждение о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации как среднюю арифметическую простую:
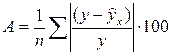 .
.
Для нашего примера представим расчет средней ошибки аппроксимации в таблице 4.
ИНТЕРВАЛЫ ПРОГНОЗА ПО УРАВНЕНИЮ РЕГРЕССИИ
Одной из центральных задач эконометрического моделирования является предсказание (прогнозирование) значений зависимой переменной при определенных значениях объясняющих переменных при определенных значениях объясняющих переменных. Здесь возможен двоякий подход: либо предсказать условное математическое ожидание зависимой переменной (предсказание среднего значения), либо прогнозировать некоторое конкретное значение зависимой переменной (предсказание конкретного значения).
Замечание. Некоторые авторы различают такие понятия, как прогнозирование и предсказание. Если значение объясняющей переменной X известно точно, то оценивание зависимой переменной Y называется предсказанием. Если же значение объясняющей переменной X неизвестно точно, то говорят, что делается прогноз значения Y. Такая ситуация характерна для временных рядов. В данном случае мы не будем различать предсказание и прогноз.
Различают точечное и интервальное прогнозирование. В первом случае оценка – некоторое число, во втором – интервал, в котором находится истинное значение зависимой переменной с заданным уровнем значимости.
а) Предсказание среднего значения. Пусть построено уравнение парной регрессии  , на основе которого необходимо предсказать условное математическое ожидание
, на основе которого необходимо предсказать условное математическое ожидание  . В данном случае значение
. В данном случае значение  является точечной оценкой . Тогда естественно возникает вопрос, как сильно может отклониться модельное значение
является точечной оценкой . Тогда естественно возникает вопрос, как сильно может отклониться модельное значение  , рассчитанное по эмпирическому уравнению, от соответствующего условного математического ожидания. Ответ на этот вопрос даётся на основе интервальных оценок, построенных с заданным уровнем значимости a при любом конкретном значении xp объясняющей переменной.
, рассчитанное по эмпирическому уравнению, от соответствующего условного математического ожидания. Ответ на этот вопрос даётся на основе интервальных оценок, построенных с заданным уровнем значимости a при любом конкретном значении xp объясняющей переменной.
Запишем эмпирическое уравнение регрессии в виде
 .
.
Здесь выделены две независимые составляющие: средняя  и приращение
и приращение  . Отсюда вытекает, что дисперсия
. Отсюда вытекает, что дисперсия  будет равна
будет равна
 . (5.53)
. (5.53)
Из теории выборки известно, что
 .
.
Используя в качестве оценки s 2 остаточную дисперсию S 2 , получим
 . (5.54)
. (5.54)
Дисперсия коэффициента регрессии, как уже было показано
 . (5.55)
. (5.55)
Подставляя найденные дисперсии в (5.41), получим
 . (5.56)
. (5.56)
Таким образом, формула расчета стандартной ошибки предсказываемого по линии регрессии среднего значения Y имеет вид
 . (5.57)
. (5.57)
Величина стандартной ошибки  , как видно из формулы, достигает минимума при
, как видно из формулы, достигает минимума при  , и возрастает по мере удаления от
, и возрастает по мере удаления от  в любом направлении. Иными словами, больше разность между
в любом направлении. Иными словами, больше разность между  и , тем больше ошибка с которой предсказывается среднее значение y для заданного значения xp. Можно ожидать наилучшие результаты прогноза, если значения xp находятся в центре области наблюдений X и нельзя ожидать хороших результатов прогноза по мере удаления от .
и , тем больше ошибка с которой предсказывается среднее значение y для заданного значения xp. Можно ожидать наилучшие результаты прогноза, если значения xp находятся в центре области наблюдений X и нельзя ожидать хороших результатов прогноза по мере удаления от .
 Случайная величина
Случайная величина
 (5.58)
(5.58)
имеет распределение Стьюдента с числом степеней свободы n=n–2 (в рамках нормальной классической модели). Следовательно, по таблице критических точек распределения Стьюдента по требуемому уровню значимости a и числу степеней свободы n=n–2 можно определить критическую точку  , удовлетворяющую условию
, удовлетворяющую условию
 .
.
С учетом (5.46) имеем:
 .
.
Отсюда, после некоторых алгебраических преобразований, получим, что доверительный интервал для  имеет вид:
имеет вид:
 , (5.59)
, (5.59)
где предельная ошибка Dp имеет вид
 . (5.60)
. (5.60)
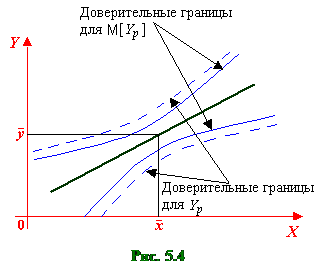
Из формул (5.57) и (5.60) видно, что величина (длина) доверительного интервала зависит от значения объясняющей переменной xp: при она минимальна, а по мере удаления xp от величина доверительного интервала увеличивается (рис. 5.4). Таким образом, прогноз значений зависимой переменной Y по уравнению регрессии оправдан, если значение xp объясняющей переменной X не выходит за диапазон ее значений по выборке (причем более точный, чем ближе xp к ). Другими словами, экстраполяция кривой регрессии, т.е. её использование вне пределов обследованного диапазона значений объясняющей переменной (даже если она оправдана для рассматриваемой переменной исходя из смысла решаемой задачи) может привести к значительным погрешностям.
б) Предсказание индивидуальных значений зависимой переменной. На практике иногда более важно знать дисперсию Y, чем ее средние значения или доверительные интервалы для условных математических ожиданий. Это связано с тем, что фактические значения Y варьируют около среднего значения  . Индивидуальные значения Y могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S 2 . Поэтому ошибка предсказываемого индивидуального значения Y должны включать не только стандартную ошибку
. Индивидуальные значения Y могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S 2 . Поэтому ошибка предсказываемого индивидуального значения Y должны включать не только стандартную ошибку  , но и случайную ошибку S. Это позволяет определять допустимые границы для конкретного значения Y.
, но и случайную ошибку S. Это позволяет определять допустимые границы для конкретного значения Y.
Пусть нас интересует некоторое возможное значение y0 переменной Y при определенном значении xp объясняющей переменной X. Предсказанное по уравнению регрессии значение Y при X=xp составляет yp. Если рассматривать значение y0 как случайную величину Y0, а yp – как случайную величину Yp, то можно отметить, что
 ,
,
 .
.
Случайные величины Y0 и Yp являются независимыми, а следовательно, случайная величина U= Y0–Yp имеет нормальное распределение с
 и
и  . (5.61)
. (5.61)
Используя в качестве s 2 остаточную дисперсию S 2 , получим формулу расчета стандартной ошибки предсказываемого по линии регрессии индивидуального значения Y:
 . (5.63)
. (5.63)
 (5.64)
(5.64)
имеет распределение Стьюдента с числом степеней свободы k=n–2. На основании этого можно построить доверительный интервал для индивидуальных значений Yp:
 , (5.65)
, (5.65)
где предельная ошибка Du имеет вид
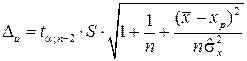 . (5.66)
. (5.66)
Заметим, что данный интервал шире доверительного интервала для условного математического ожидания (см. рис. 5.4).
Пример 5.5. По данным примеров 5.1-5.3 рассчитать 95%-ый доверительный интервал для условного математического ожидания и индивидуального значения при xp=160.
Решение. В примере 5.1 было найдено  . Воспользовавшись формулой (5.48), найдем предельную ошибку для условного математического ожидания
. Воспользовавшись формулой (5.48), найдем предельную ошибку для условного математического ожидания
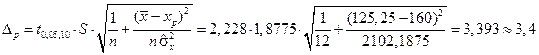 .
.
Тогда доверительный интервал для среднего значения  на уровне значимости a=0,05 будет иметь вид
на уровне значимости a=0,05 будет иметь вид
Другими словами, среднее потребление при доходе 160 с вероятностью 0,95 будет находиться в интервале (149,8; 156,6).
Рассчитаем границы интервала, в котором будет сосредоточено не менее 95% возможных объёмов потребления при уровне дохода xp=160, т.е. доверительный интервал для индивидуального значения . Найдем предельную ошибку для индивидуального значения
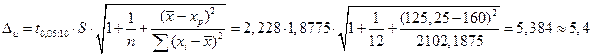 .
.
Тогда интервал, в котором будут находиться , по крайней мере, 95% индивидуальных объёмов потребления при доходе xp=160, имеет вид
Нетрудно заметить, что он включает в себя доверительный интервал для условного среднего потребления. â
ПРИМЕРЫ
Пример 5.65.По территориям региона приводятся данные за 199X г. (таб. 1.1).
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., x | Среднедневная заработная плата, руб., y |
1. Рассчитать линейный коэффициент парной корреляции, оценить его статистическую значимость и построить для него доверительный интервал с уровнем значимости a=0,05.
2. Построить линейное уравнение парной регрессии y на x и оценить статистическую значимость параметров регрессии. Сделать рисунок.
3. Оценить качество уравнения регрессии при помощи коэффициента детерминации. Проверить качество уравнения регрессии при помощи F-критерия Фишера.
4. Выполнить прогноз заработной платы y при прогнозном значении среднедушевого прожиточного минимума x, составляющем 107% от среднего уровня. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал для уровня значимости a=0,05. Сделать выводы.
Решение
1. Для определения степени тесноты связи обычно используют коэффициент корреляции:
 ,
,
где  ,
,  – выборочные дисперсии переменных x и y. Для расчета коэффициента корреляции строим расчетную таблицу (табл. 5.4):
– выборочные дисперсии переменных x и y. Для расчета коэффициента корреляции строим расчетную таблицу (табл. 5.4):
| x | y | xy | x 2 | y 2 |  |  | e 2 | |
| 148,77 | -15,77 | 248,70 | ||||||
| 152,45 | -4,45 | 19,82 | ||||||
| 157,05 | -23,05 | 531,48 | ||||||
| 149,69 | 4,31 | 18,57 | ||||||
| 158,89 | 3,11 | 9,64 | ||||||
| 174,54 | 20,46 | 418,52 | ||||||
| 138,65 | 0,35 | 0,13 | ||||||
| 157,97 | 0,03 | 0,00 | ||||||
| 144,17 | 7,83 | 61,34 | ||||||
| 157,05 | 4,95 | 24,46 | ||||||
| 146,93 | 12,07 | 145,70 | ||||||
| 182,83 | -9,83 | 96,55 | ||||||
| Итого | – | 1574,92 | ||||||
| Среднее значение | 85,58 | 155,75 | 13484,00 | 7492,25 | 24531,42 | – | – | – |
По данным таблицы находим:
 ,
,  ,
,  ,
,  ,
,
 ,
,  ,
,  ,
,  ,
,
 ,
,  .
.
Таким образом, между заработной платой (y) и среднедушевым прожиточным минимумом (x) существует прямая достаточно сильная корреляционная зависимость.
Для оценки статистической значимости коэффициента корреляции рассчитаем двухсторонний t-критерий Стьюдента:
 ,
,
который имеет распределение Стьюдента с k=n–2 и уровнем значимости a. В нашем случае
 и
и  .
.
Поскольку  , то коэффициент корреляции существенно отличается от нуля.
, то коэффициент корреляции существенно отличается от нуля.
Для значимого коэффициента можно построить доверительный интервал, который с заданной вероятностью содержит неизвестный генеральный коэффициент корреляции. Для построения интервальной оценки (для малых выборок n
http://megaobuchalka.ru/9/33835.html