Прогнозирование с применением уравнения регрессии
Уравнения регрессии применимо и для прогнозирования возможных ожидаемых значений результативного признака. При этом следует учесть, что перенос закономерности связи, измеренной в варьирующей совокупности, в статике на динамику не является, строго говоря, корректным и требует проверки условий допустимости такого переноса (экстраполяции), что выходит за рамки статистики и может быть сделано только специалистом, хорошо знающим объект (систему) и возможности его развития в будущем.
Ограничением прогнозирования на основании регрессионного уравнения, тем более парного, служит условие стабильности или по крайней мере малой изменчивости других факторов и условий изучаемого процесса, не связанных с ними. Если резко изменится “внешняя среда” протекающего процесса, прежнее уравнение регрессии результативного признака на факторный потеряет свое значение. В сильно засушливый год доза удобрений может не оказать влияния на урожайность сельскохозяйственной культуры, так как последнюю лимитирует недостаточная влагообеспеченность.
Прогнозируемое значение переменной У получается при подстановке в уравнение регрессии ожидаемой величины фактора Х:
Следует соблюдать одно ограничение: нельзя подставлять значения факторного признака, значительно отличающиеся от входящих в базисную информацию, по которой вычислено уравнение регрессии. При качественно иных уровнях фактора, если они даже возможны в принципе, были бы другими параметры уравнения. Можно рекомендовать при определении значений факторов не выходить за пределы трети размаха вариации, как за минимальное, так и за максимальное значение признака-фактора, имевшееся в исходной информации.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения фактора, называют точечным прогнозом. Вероятность точной реализации такого прогноза крайне мала. Необходимо сопроводить его расчетом значения средней ошибки прогноза или доверительного интервала прогноза с достаточно большой вероятностью (надежностью).
Доверительные интервалы зависят от следующих параметров:
– отклонение от своего среднего значения ;
В частности для прогноза будущие значения с вероятностью
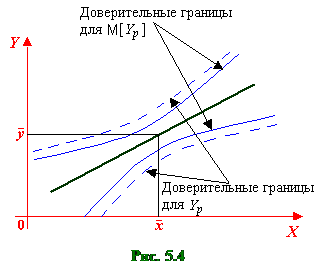
Расположение границ доверительного интервала показывает, что прогноз значений зависимой переменной по уравнению регрессии хорош только в случае, если значение фактора Х не выходит за пределы выборки. Иными словами, экстраполяция по уравнению регрессии может привести к значительным погрешностям.
ИНТЕРВАЛЫ ПРОГНОЗА ПО УРАВНЕНИЮ РЕГРЕССИИ
Одной из центральных задач эконометрического моделирования является предсказание (прогнозирование) значений зависимой переменной при определенных значениях объясняющих переменных при определенных значениях объясняющих переменных. Здесь возможен двоякий подход: либо предсказать условное математическое ожидание зависимой переменной (предсказание среднего значения), либо прогнозировать некоторое конкретное значение зависимой переменной (предсказание конкретного значения).
Замечание. Некоторые авторы различают такие понятия, как прогнозирование и предсказание. Если значение объясняющей переменной X известно точно, то оценивание зависимой переменной Y называется предсказанием. Если же значение объясняющей переменной X неизвестно точно, то говорят, что делается прогноз значения Y. Такая ситуация характерна для временных рядов. В данном случае мы не будем различать предсказание и прогноз.
Различают точечное и интервальное прогнозирование. В первом случае оценка – некоторое число, во втором – интервал, в котором находится истинное значение зависимой переменной с заданным уровнем значимости.
а) Предсказание среднего значения. Пусть построено уравнение парной регрессии  , на основе которого необходимо предсказать условное математическое ожидание
, на основе которого необходимо предсказать условное математическое ожидание  . В данном случае значение
. В данном случае значение  является точечной оценкой . Тогда естественно возникает вопрос, как сильно может отклониться модельное значение
является точечной оценкой . Тогда естественно возникает вопрос, как сильно может отклониться модельное значение  , рассчитанное по эмпирическому уравнению, от соответствующего условного математического ожидания. Ответ на этот вопрос даётся на основе интервальных оценок, построенных с заданным уровнем значимости a при любом конкретном значении xp объясняющей переменной.
, рассчитанное по эмпирическому уравнению, от соответствующего условного математического ожидания. Ответ на этот вопрос даётся на основе интервальных оценок, построенных с заданным уровнем значимости a при любом конкретном значении xp объясняющей переменной.
Запишем эмпирическое уравнение регрессии в виде
 .
.
Здесь выделены две независимые составляющие: средняя  и приращение
и приращение  . Отсюда вытекает, что дисперсия
. Отсюда вытекает, что дисперсия  будет равна
будет равна
 . (5.53)
. (5.53)
Из теории выборки известно, что
 .
.
Используя в качестве оценки s 2 остаточную дисперсию S 2 , получим
 . (5.54)
. (5.54)
Дисперсия коэффициента регрессии, как уже было показано
 . (5.55)
. (5.55)
Подставляя найденные дисперсии в (5.41), получим
 . (5.56)
. (5.56)
Таким образом, формула расчета стандартной ошибки предсказываемого по линии регрессии среднего значения Y имеет вид
 . (5.57)
. (5.57)
Величина стандартной ошибки  , как видно из формулы, достигает минимума при
, как видно из формулы, достигает минимума при  , и возрастает по мере удаления от
, и возрастает по мере удаления от  в любом направлении. Иными словами, больше разность между
в любом направлении. Иными словами, больше разность между  и , тем больше ошибка с которой предсказывается среднее значение y для заданного значения xp. Можно ожидать наилучшие результаты прогноза, если значения xp находятся в центре области наблюдений X и нельзя ожидать хороших результатов прогноза по мере удаления от .
и , тем больше ошибка с которой предсказывается среднее значение y для заданного значения xp. Можно ожидать наилучшие результаты прогноза, если значения xp находятся в центре области наблюдений X и нельзя ожидать хороших результатов прогноза по мере удаления от .
 Случайная величина
Случайная величина
 (5.58)
(5.58)
имеет распределение Стьюдента с числом степеней свободы n=n–2 (в рамках нормальной классической модели). Следовательно, по таблице критических точек распределения Стьюдента по требуемому уровню значимости a и числу степеней свободы n=n–2 можно определить критическую точку  , удовлетворяющую условию
, удовлетворяющую условию
 .
.
С учетом (5.46) имеем:
 .
.
Отсюда, после некоторых алгебраических преобразований, получим, что доверительный интервал для  имеет вид:
имеет вид:
 , (5.59)
, (5.59)
где предельная ошибка Dp имеет вид
 . (5.60)
. (5.60)
Из формул (5.57) и (5.60) видно, что величина (длина) доверительного интервала зависит от значения объясняющей переменной xp: при она минимальна, а по мере удаления xp от величина доверительного интервала увеличивается (рис. 5.4). Таким образом, прогноз значений зависимой переменной Y по уравнению регрессии оправдан, если значение xp объясняющей переменной X не выходит за диапазон ее значений по выборке (причем более точный, чем ближе xp к ). Другими словами, экстраполяция кривой регрессии, т.е. её использование вне пределов обследованного диапазона значений объясняющей переменной (даже если она оправдана для рассматриваемой переменной исходя из смысла решаемой задачи) может привести к значительным погрешностям.
б) Предсказание индивидуальных значений зависимой переменной. На практике иногда более важно знать дисперсию Y, чем ее средние значения или доверительные интервалы для условных математических ожиданий. Это связано с тем, что фактические значения Y варьируют около среднего значения  . Индивидуальные значения Y могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S 2 . Поэтому ошибка предсказываемого индивидуального значения Y должны включать не только стандартную ошибку
. Индивидуальные значения Y могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S 2 . Поэтому ошибка предсказываемого индивидуального значения Y должны включать не только стандартную ошибку  , но и случайную ошибку S. Это позволяет определять допустимые границы для конкретного значения Y.
, но и случайную ошибку S. Это позволяет определять допустимые границы для конкретного значения Y.
Пусть нас интересует некоторое возможное значение y0 переменной Y при определенном значении xp объясняющей переменной X. Предсказанное по уравнению регрессии значение Y при X=xp составляет yp. Если рассматривать значение y0 как случайную величину Y0, а yp – как случайную величину Yp, то можно отметить, что
 ,
,
 .
.
Случайные величины Y0 и Yp являются независимыми, а следовательно, случайная величина U= Y0–Yp имеет нормальное распределение с
 и
и  . (5.61)
. (5.61)
Используя в качестве s 2 остаточную дисперсию S 2 , получим формулу расчета стандартной ошибки предсказываемого по линии регрессии индивидуального значения Y:
 . (5.63)
. (5.63)
 (5.64)
(5.64)
имеет распределение Стьюдента с числом степеней свободы k=n–2. На основании этого можно построить доверительный интервал для индивидуальных значений Yp:
 , (5.65)
, (5.65)
где предельная ошибка Du имеет вид
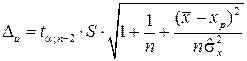 . (5.66)
. (5.66)
Заметим, что данный интервал шире доверительного интервала для условного математического ожидания (см. рис. 5.4).
Пример 5.5. По данным примеров 5.1-5.3 рассчитать 95%-ый доверительный интервал для условного математического ожидания и индивидуального значения при xp=160.
Решение. В примере 5.1 было найдено  . Воспользовавшись формулой (5.48), найдем предельную ошибку для условного математического ожидания
. Воспользовавшись формулой (5.48), найдем предельную ошибку для условного математического ожидания
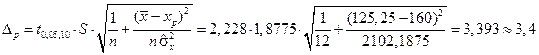 .
.
Тогда доверительный интервал для среднего значения  на уровне значимости a=0,05 будет иметь вид
на уровне значимости a=0,05 будет иметь вид
Другими словами, среднее потребление при доходе 160 с вероятностью 0,95 будет находиться в интервале (149,8; 156,6).
Рассчитаем границы интервала, в котором будет сосредоточено не менее 95% возможных объёмов потребления при уровне дохода xp=160, т.е. доверительный интервал для индивидуального значения . Найдем предельную ошибку для индивидуального значения
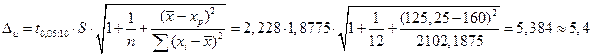 .
.
Тогда интервал, в котором будут находиться , по крайней мере, 95% индивидуальных объёмов потребления при доходе xp=160, имеет вид
Нетрудно заметить, что он включает в себя доверительный интервал для условного среднего потребления. â
ПРИМЕРЫ
Пример 5.65.По территориям региона приводятся данные за 199X г. (таб. 1.1).
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., x | Среднедневная заработная плата, руб., y |
1. Рассчитать линейный коэффициент парной корреляции, оценить его статистическую значимость и построить для него доверительный интервал с уровнем значимости a=0,05.
2. Построить линейное уравнение парной регрессии y на x и оценить статистическую значимость параметров регрессии. Сделать рисунок.
3. Оценить качество уравнения регрессии при помощи коэффициента детерминации. Проверить качество уравнения регрессии при помощи F-критерия Фишера.
4. Выполнить прогноз заработной платы y при прогнозном значении среднедушевого прожиточного минимума x, составляющем 107% от среднего уровня. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал для уровня значимости a=0,05. Сделать выводы.
Решение
1. Для определения степени тесноты связи обычно используют коэффициент корреляции:
 ,
,
где  ,
,  – выборочные дисперсии переменных x и y. Для расчета коэффициента корреляции строим расчетную таблицу (табл. 5.4):
– выборочные дисперсии переменных x и y. Для расчета коэффициента корреляции строим расчетную таблицу (табл. 5.4):
| x | y | xy | x 2 | y 2 |  |  | e 2 | |
| 148,77 | -15,77 | 248,70 | ||||||
| 152,45 | -4,45 | 19,82 | ||||||
| 157,05 | -23,05 | 531,48 | ||||||
| 149,69 | 4,31 | 18,57 | ||||||
| 158,89 | 3,11 | 9,64 | ||||||
| 174,54 | 20,46 | 418,52 | ||||||
| 138,65 | 0,35 | 0,13 | ||||||
| 157,97 | 0,03 | 0,00 | ||||||
| 144,17 | 7,83 | 61,34 | ||||||
| 157,05 | 4,95 | 24,46 | ||||||
| 146,93 | 12,07 | 145,70 | ||||||
| 182,83 | -9,83 | 96,55 | ||||||
| Итого | – | 1574,92 | ||||||
| Среднее значение | 85,58 | 155,75 | 13484,00 | 7492,25 | 24531,42 | – | – | – |
По данным таблицы находим:
 ,
,  ,
,  ,
,  ,
,
 ,
,  ,
,  ,
,  ,
,
 ,
,  .
.
Таким образом, между заработной платой (y) и среднедушевым прожиточным минимумом (x) существует прямая достаточно сильная корреляционная зависимость.
Для оценки статистической значимости коэффициента корреляции рассчитаем двухсторонний t-критерий Стьюдента:
 ,
,
который имеет распределение Стьюдента с k=n–2 и уровнем значимости a. В нашем случае
 и
и  .
.
Поскольку  , то коэффициент корреляции существенно отличается от нуля.
, то коэффициент корреляции существенно отличается от нуля.
Для значимого коэффициента можно построить доверительный интервал, который с заданной вероятностью содержит неизвестный генеральный коэффициент корреляции. Для построения интервальной оценки (для малых выборок n
Парная линейная регрессия. Задачи регрессионного анализа
Будут и задачи для самостоятельного решения, к которым можно посмотреть ответы.
Понятие линейной регрессии. Парная линейная регрессия
Линейная регрессия — выраженная в виде прямой зависимость среднего значения какой-либо величины от некоторой другой величины. В отличие от функциональной зависимости y = f(x) , когда каждому значению независимой переменной x соответствует одно определённое значение величины y, при линейной регрессии одному и тому же значению x могут соответствовать в зависимости от случая различные значения величины y.
Если в результате наблюдения установлено, что при каждом определённом значении x существует сколько-то (n) значений переменной y, то зависимость средних арифметических значений y от x и является регрессией в статистическом понимании.
Если установленная зависимость может быть записана в виде уравнения прямой
то эта регрессионная зависимость называется линейной регрессией.
О парной линейной регрессии говорят, когда установлена зависимость между двумя переменными величинами (x и y). Парная линейная регрессия называется также однофакторной линейной регрессией, так как один фактор (независимая переменная x) влияет на результирующую переменную (зависимую переменную y).
В уроке о корреляционной зависимости были разобраны примеры того, как цена на квартиры зависит от общей площади квартиры и от площади кухни (две различные независимые переменные) и о том, что результаты наблюдений расположены в некотором приближении к прямой, хотя и не на самой прямой. Если точки корреляционной диаграммы соединить ломанной линией, то будет получена линия эмпирической регрессии. А если эта линия будет выровнена в прямую, то полученная прямая будет прямой теоретической регрессии. На рисунке ниже она красного цвета (для увеличения рисунка щёлкнуть по нему левой кнопкой мыши).

По этой прямой теоретической регрессии может быть сделан прогноз или восстановление неизвестных значений зависимой переменной по заданным значениям независимой переменной.
В случае парной линейной регрессии для данных генеральной совокупности связь между независимой переменной (факториальным признаком) X и зависимой переменной (результативным признаком) Y описывает модель
 ,
,
 — свободный член прямой парной линейной регрессии,
— свободный член прямой парной линейной регрессии,
 — коэффициент направления прямой парной линейной регрессии,
— коэффициент направления прямой парной линейной регрессии,
 — случайная погрешность,
— случайная погрешность,
N — число элементов генеральной совокупности.
Уравнение парной линейной регрессии для генеральной совокупности можно построить, если доступны данные обо всех элементах генеральной совокупности. На практике данные всей генеральной совокупности недоступны, но доступны данные об элементах некоторой выборки.
Поэтому параметры генеральной совокупности оценивают при помощи соответствующих параметров соответствующей выборки: свободный член прямой парной линейной регрессии генеральной совокупности заменяют на свободный член прямой парной линейной регрессии выборки  , а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки
, а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки  .
.
В результате получаем уравнение парной линейной регрессии выборки


 — оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
— оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
 — погрешность,
— погрешность,
n — размер выборки.
Чтобы уравнение парной линейной регрессии было более похоже на привычное уравнение прямой, его часто также записывают в виде
 .
.
Уравнение парной линейной регрессии и метод наименьших квадратов
Определение коэффициентов уравнения парной линейной регрессии
Если заранее известно, что зависимость между факториальным признаком x и результативным признаком y должна быть линейной, выражающейся в виде уравнения типа , задача сводится к нахождению по некоторой группе точек наилучшей прямой, называемой прямой парной линейной регрессии. Следует найти такие значения коэффициентов a и b , чтобы сумма квадратов отклонений  была наименьшей:
была наименьшей:
 .
.
Если через  и
и  обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
- прямая парной линейной регрессии проходит через точку
 ;
; - среднее значение отклонений равна нулю: ;
- значения и не связаны: .
 ;
; ;
; и
и  не связаны:
не связаны:  .
.Условие метода наименьших квадратов выполняется, если значения коэффициентов равны:
 ,
,
 .
.
Пример 1. Найти уравнение парной линейной регрессии зависимости между валовым внутренним продуктом (ВВП) и частным потреблением на основе данных примера урока о корреляционной зависимости (эта ссылка, которая откроется в новом окне, потребуется и при разборе следующих примеров).
Решение. Используем рассчитанные в решении названного выше примера суммы:




Используя эти суммы, вычислим коэффициенты:


Таким образом получили уравнение прямой парной линейной регрессии:

Составить уравнение парной линейной регрессии самостоятельно, а затем посмотреть решение
Пример 2. Найти уравнение парной линейной регрессии для выборки из 6 наблюдений, если уже вычислены следующие промежуточные результаты:
 ;
;
 ;
;
 ;
;
 ;
;
Анализ качества модели линейной регрессии
Метод наименьших квадратов имеет по меньшей мере один существенный недостаток: с его помощью можно найти уравнение линейной регрессии и в тех случаях, когда данные наблюдений значительно рассеяны вокруг прямой регрессии, то есть находятся на значительном расстоянии от этой прямой. В таких случаях за точность прогноза значений зависимой переменной ручаться нельзя. Существуют показатели, которые позволяют оценить качество уравнения линейной регрессии прежде чем использовать модели линейной регрессии для практических целей. Разберём важнейшие из этих показателей.
Коэффициент детерминации
Коэффициент детерминации  принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
 ,
,
 — сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
— сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
 — общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
— общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
 — сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
— сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
Пример 3. Даны сумма квадратов отклонений, объясняемых моделью линейной регрессии (3500), общая сумма квадратов отклонений (5000) и сумма квадратов отклонений ошибки (1500). Найти коэффициент детерминации двумя способами.
F-статистика (статистика Фишера) для проверки качества модели линейной регрессии
Минимальное возможное значение F-статистики — 0. Чем выше значение статистики Фишера, тем качественнее модель линейной регрессии. Этот показатель представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы):

где m — число объясняющих переменных.
Сумма квадратов остатков
Сумма квадратов остатков (RSS) измеряет необъясненную часть дисперсии зависимой переменной:

 —
—
остатки — разности между реальными значениями зависимой переменной и значениями, оценёнными уравнением линейной регрессии.
В случае качественной модели линейной регрессии сумма квадратов остатков стремится к нулю.
Стандартная ошибка регрессии
Стандартная ошибка регрессии (SEE) измеряет величину квадрата ошибки, приходящейся на одну степень свободы модели:

Чем меньше значение SEE, тем качественнее модель.
Пример 4. Рассчитать коэффициент детерминации для данных из примера 1.
Решение. На основании данных таблицы (она была приведена в примере урока о корреляционной зависимости) получаем, что SST = 63 770,593 , SSE = 10 459,587 , SSR = 53 311,007 .
Можем убедиться, что выполняется закономерность SSR = SST — SSE :
Получаем коэффициент детерминации:
 .
.
Таким образом, 83,6% изменений частного потребления можно объяснить моделью линейной регресии.
Интерпретация коэффициентов уравнения парной линейной регрессии и прогноз значений зависимой переменной
Итак, уравнение парной линейной регрессии:
 .
.
В этом уравнении a — свободный член, b — коэффициент при независимой переменной.
Интерпретация свободного члена: a показывает, на сколько единиц график регрессии смещён вверх при x=0, то есть значение переменной y при нулевом значении переменной x.
Интерпретация коэффициента при независимой переменной: b показывает, на сколько единиц изменится значение зависимой переменной y при изменении x на одну единицу.
Пример 5. Зависимость частного потребления граждан от ВВП (истолкуем это просто: от дохода) описывается уравнением парной линейной регрессии  . Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
. Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
Решение. Подставляем в уравнение парной линейной регрессии x i = 20000 и получаем прогноз потребления при доходе в 20 000 у.е. y i = 17036,4662 .
Подставляем в уравнение парной линейной регрессии x i = 5000 и получаем прогноз увеличения потребления при увеличении дохода на 5000 у.е. y i = 4161,9662 .
Если доход не меняется, то x i = 0 и получаем, что потребление уменьшается на 129,5338 у.е.
Задачи регрессионного анализа
Регрессионный анализ — раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным.
Наиболее частые задачи регрессионного анализа:
- установление факта наличия или отсутствия статистических зависимостей между переменными величинами;
- выявление причинных связей между переменными величинами;
- прогноз или восстановление неизвестных значений зависимых переменных по заданным значениям независимых переменных.
Также делаются проверки статистических гипотез о регрессии. Кроме того, при изучении связи между двумя величинами по результатам наблюдений в соответствии с теорией регрессии предполагается, что зависимая переменная имеет некоторое распределение вероятностей при фиксированном значении независимой переменной.
В исследованиях поведения человека, чтобы они претендовали на объективность, важно не только установить зависимость между факторами, но и получить все необходимые статистические показатели для результата проверки соответствующей гипотезы.
Проверка гипотезы о равенстве нулю коэффициента направления прямой парной линейной регрессии
Одна из важнейших гипотез в регрессионном анализе — гипотеза о том, что коэффициент направления прямой регрессии генеральной совокупности равен нулю.
Если это предположение верно, то изменения независимой переменной X не влияют на изменения зависимой переменной Y: переменные X и Y не коррелированы, то есть линейной зависимости Y от X нет.

рассматривают во взаимосвязи с альтернативной гипотезой
 .
.
Статистика коэффициента направления

соответствует распределению Стьюдента с числом степеней свободы v = n — 2 ,
где  — стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
— стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
Доверительный интервал коэффициента направления прямой линейной регрессии:
 .
.
Критическая область, в которой с вероятностью P = 1 — α отвергают нулевую гипотезу и принимают альтернативную гипотезу:

Пример 6. На основе данных из предыдущих примеров (о ВВП и частном потреблении) определить доверительный интервал коэффициента направления прямой линейной регресии 95% и проверить гипотезу о равенстве нулю коэффициента направления прямой парной линейной регрессии.
Можем рассчитать, что  , а стандартная погрешность регрессии
, а стандартная погрешность регрессии  .
.
Таким образом, стандартная погрешность коэффициента направления прямой линейной регресии b 1 :
 .
.
Так как  и
и  (находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
(находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
 .
.
Так как гипотетическое значение коэффициента — нуль — не принадлежит доверительному интервалу, с вероятностью 95% можем отвергнуть основную гипотезу и принять альтернативную гипотезу, то есть считать, что зависимая переменная Y линейно зависит от независимой переменной X.
http://megaobuchalka.ru/9/33835.html
http://function-x.ru/statistics_regression1.html