Качество регрессионной модели. Нелинейная регрессия
Значимость уравнения регрессии еще не означает, что выбранная модель достаточно правильно (адекватно) описывает исследуемое экономическое явление. Применение неадекватной модели для целей анализа и прогнозирования может приводить к неоправданно большим ошибкам. Если модель адекватна, то остатки регрессии представляют собой независимые нормально распределенные случайные величины с одинаковой дисперсией. В случае неадекватности модели остатки содержат также и систематическую составляющую, а закон их распределения отличается от нормального. Проверка адекватности регрессионной модели рассматривается в § 3.8.
Обычно в начале исследуется линейная модель, для которой после оценки параметров и проверки значимости уравнения регрессии определяется коэффициент детерминации и оценивается точность.
Коэффициент детерминации R 2 рассчитывается по формуле
 . . | (2.19) |
Его значение показывает долю вариации результата Y, обусловленную вариацией фактора X. К примеру, если R 2 =0,856, то это означает, что 85,6 % вариации результата Y вызвано вариацией фактора X, а соответственно 14,4 % ( 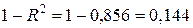 ) — неучтенными и случайными факторами. Коэффициент детерминации принимает значения в интервале от 0 до 1. Чем ближе R 2 к единице, тем лучше модель объясняет вариацию Y, а уравнение регрессии аппроксимирует фактические данные.
) — неучтенными и случайными факторами. Коэффициент детерминации принимает значения в интервале от 0 до 1. Чем ближе R 2 к единице, тем лучше модель объясняет вариацию Y, а уравнение регрессии аппроксимирует фактические данные.
Заметим, что для линейной парной модели коэффициент детерминации равен квадрату коэффициента корреляции: 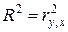 , а стандартная ошибка регрессии Sрег связана с R 2 соотношением
, а стандартная ошибка регрессии Sрег связана с R 2 соотношением
 , , | (2.20) |
где Sy — стандартное отклонение зависимой переменной Y в исходных данных.
Коэффициент детерминации и F–статистика Фишера (см. § 2.3) связаны между собой соотношением
 , , | (2.21) |
где n — число наблюдений; m — число оцениваемых параметров регрессионной модели, включая свободный коэффициент b0.
В случае парной линейной регрессии m=2 и
 . . | (2.22) |
Точность модели, т.е. близость линии регрессии к фактическим данным,характеризует средняя относительная ошибка аппроксимации
 . . | (2.23) |
Если Еотн не превышает 10 %, то считается, что модель имеет высокую точность, при  точность модели хорошая, при
точность модели хорошая, при  — удовлетворительная, а при
— удовлетворительная, а при 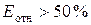 — неудовлетворительная.
— неудовлетворительная.
Средняя относительная ошибка аппроксимации Еотн связана со стандартной ошибкой регрессии Sрег приближенным соотношением
 . . | (2.24) |
Расхождение между формулами (2.23) и (2.24) обычно незначительное, особенно при достаточно большом объеме наблюдений (  ).
).
После анализа качества линейной модели переходят к исследованию нелинейных моделей, коэффициент детерминации и средняя относительная ошибка аппроксимации которых, определяются по тем же самым формулам и имеют тот же смысл, что и для линейной модели. Наиболее часто на практике используются нелинейные модели, приведенные в табл. 2.2.
Значимость нелинейного уравнения регрессии проверяется по F‑критерию Фишера. Лучшей считается модель, имеющая наибольший коэффициент детерминации R 2 . При незначительных расхождениях в значениях R 2 предпочтение отдается более простой модели. Если модель предполагается использовать для целей анализа, то ее параметры должны иметь содержательную экономическую интерпретацию. Интерпретация параметров степенной, показательной и логарифмической регрессий рассматривается в приведенных ниже примерах.
| Таблица | 2.2 |
| Часто используемые на практике нелинейные модели |
| Форма связи | Модель | Уравнение регрессии |
| 1. Степенная | 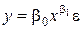 | 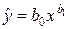 |
| 2. Показательная |  | 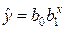 |
| 3. Экспоненциальная (другой вид показательной связи) |  |  |
| 4. Логарифмическая | 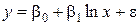 |  |
| 5. Гиперболическая |  |  |
| 6. Полиноминальная разных степеней (q — степень полинома) |  |  |
Решение типовых задач
Пример 2.1
По десяти однородным предприятиям имеется информация, характеризующая зависимость объема выпускаемой продукции (результативная переменная Y, млн. руб.) от объема капиталовложений (фактор X, млн. руб.):
| Предприятие | А | Б | В | Г | Д | Е | Ж | З | И | К |
| Y | ||||||||||
| X |
1. Рассчитать парный коэффициент корреляции между переменными Y и X и проверить его статистическую значимость (уровень значимости a=0,05).
2. Найти параметры уравнения линейной регрессии Y по X и дать их экономическую интерпретацию.
3. Вычислить коэффициент детерминации R 2 и пояснить его смысл.
4. Проверить статистическую значимость уравнения регрессии по F-критерию Фишера (a=0,05).
5. Определить стандартную ошибку регрессии и оценить точность модели с помощью средней относительной ошибки аппроксимации.
6. Построитьдоверительные интервалы для истинных параметров b0 и b1 регрессионной модели и проверить статистическую значимость коэффициентов уравнения регрессии по t-критерию Стьюдента (a=0,05).
7. Спрогнозировать с доверительной вероятностью 0,9 значение показателя Y, если прогнозное значения фактора Х составит 80 % от максимального значения в исходных данных.
8. Изобразить графически результаты моделирования и прогнозирования.
1. Для определения парного коэффициента корреляции ry,x между переменными Y и X в EXCEL может быть использована любая из встроенных функций «КОРРЕЛ» или «ПИРСОН». Использование встроенных функций EXCEL рассмотрено в § 5.4.
Коэффициент корреляции имеет значение
 .
.
Критическое значение коэффициента корреляции для уровня значимости a=0,05 и числа степеней свободы  составляет rкр=0,632, где n=10 — число пар значений переменных. Видно, что коэффициент корреляции превышает по абсолютной величине критическое значение и следовательно является статистически значимым. Положительное значение коэффициента корреляции свидетельствует о прямой связи между переменными Y и X, а превышение им по абсолютной величине 0,8 — о тесной линейной связи.
составляет rкр=0,632, где n=10 — число пар значений переменных. Видно, что коэффициент корреляции превышает по абсолютной величине критическое значение и следовательно является статистически значимым. Положительное значение коэффициента корреляции свидетельствует о прямой связи между переменными Y и X, а превышение им по абсолютной величине 0,8 — о тесной линейной связи.
2. Линейная модель парной регрессии Y по X и уравнение регрессии соответственно имеют вид:
 ;
;
 .
.
Коэффициенты уравнения регрессии определяем с помощью встроенных функций «ОТРЕЗОК» и «НАКЛОН» соответственно. Они имеют значения:
 млн. руб.;
млн. руб.;
 .
.
Окончательно уравнение регрессии —
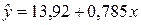 .
.
Значение свободного коэффициента b0 показывает, что при нулевом объеме капиталовложений X объем выпускаемой продукции Y будет составлять в среднем 13,92 млн. руб. Значение углового коэффициента b1=0,785 показывает, что при увеличении объема капиталовложений на 1 млн. руб. объем выпускаемой продукции возрастает в среднем на 0,785 млн. руб.
3. Коэффициент детерминации R 2 парной линейной регрессии определяется с помощью встроенной функции EXCEL «КВПИРСОН». Получим:
 .
.
Значение R 2 показывает, что линейная модель объясняет 86,9 % вариации Y. Другими словами, 86,9 % вариации объема выпускаемой продукции Y обусловлена вариацией объема капиталовложений X.
4. Для проверки статистической значимости уравнения регрессии F‑статистику Фишера определимчерез коэффициент детерминации по формуле (2.22):
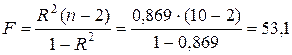 .
.
Табличное значение F-критерия Фишера для уровня значимости a=0,05 и чисел степеней свободы числителя (регрессии)  и знаменателя (остатка)
и знаменателя (остатка)  составляет Fтаб=5,32. Так как F-статистика превышает табличное значение F-критерия, то это свидетельствует о статистической значимости уравнения регрессии в целом.
составляет Fтаб=5,32. Так как F-статистика превышает табличное значение F-критерия, то это свидетельствует о статистической значимости уравнения регрессии в целом.
5. Стандартная ошибка линейной парной регрессии Sрег (см. § 2.2) определяется с помощью встроенной функции EXCEL «СТОШYX». Имеем:
 млн. руб.
млн. руб.
Среднюю относительную ошибку аппроксимации Еотн рассчитаем по приближенной формуле
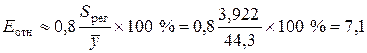 %,
%,
где  млн. руб. — средний объем выпускаемой продукции, определенный с помощью встроенной функции «СРЗНАЧ».
млн. руб. — средний объем выпускаемой продукции, определенный с помощью встроенной функции «СРЗНАЧ».
Значение Еотн показывает, что предсказанные уравнением регрессии значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 7,1 %. Так как средняя относительная ошибка аппроксимации меньше 10 %, то это свидетельствует о высокой точности линейной модели.
6. Для определения интервальных оценок истинных параметров b0 и b1 регрессионной модели рассчитаем стандартные ошибки коэффициентов уравнения регрессии:
 млн. руб.;
млн. руб.;
 ,
,
где  млн. руб. — стандартное отклонение переменной X в исходных данных, определяемое с помощью встроенной функции «СТАНДОТКЛОН»;
млн. руб. — стандартное отклонение переменной X в исходных данных, определяемое с помощью встроенной функции «СТАНДОТКЛОН»;  — сумма квадратов значений переменной X в исходных данных (функция «СУММКВ»).
— сумма квадратов значений переменной X в исходных данных (функция «СУММКВ»).
Доверительный интервал, «накрывающий» с заданной надежностью 0,95 неизвестное значение параметра b0 модели, имеет вид:
 млн. руб.,
млн. руб.,
где tтаб=2,306 — табличное значение t-критерия Стьюдента для уровня значимости a=0,05 и числа степеней свободы остатка линейной парной регрессии  .
.
Таким образом, с доверительной вероятностью 95 % истинное значение параметра b0 будет находиться в интервале от 3,89 до 23,95 млн. руб. Так как нижняя и верхняя границы доверительного интервала имеют одинаковый знак, то коэффициент b0 уравнения регрессии признается статистически значимым на уровне значимости a=0,05.
Доверительный интервал для параметра b1 модели имеет вид:
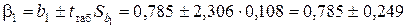 .
.
Это означает, что при увеличении объема капиталовложений X на 1 млн. руб. объем выпускаемой продукции Y с вероятностью 95 % возрастает в среднем на величину, заключенную в интервале от 0,536 до 1,034 млн. руб. Один и тот же знак доверительных границ свидетельствует о статистической значимости коэффициента b1 и уравнения регрессии в целом на уровне a=0,05.
7. Спрогнозируем объем выпускаемой продукции Y, если прогнозное значение x0 объема капиталовложений X составит 80 % от своего максимального значения в исходных данных xmax=59 млн. руб.:
 млн. руб.
млн. руб.
Среднее прогнозируемое значение объема выпускаемой продукции (точечный прогноз) равно
 млн. руб.
млн. руб.
Точечный прогноз можно рассчитать и с помощью встроенной функции «ПРЕДСКАЗ».
Стандартная ошибка прогноза фактического значенияобъема выпускаемой продукции y0 рассчитывается по формуле
 млн. руб.,
млн. руб.,
где  млн. руб. — средний объем капиталовложений, определенный с помощью встроенной функции «СРЗНАЧ».
млн. руб. — средний объем капиталовложений, определенный с помощью встроенной функции «СРЗНАЧ».
Интервальный прогноз фактического значения объема выпускаемой продукции y0 с надежностью g=0,9 (уровень значимости a=0,1) имеет вид:
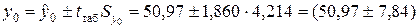 млн. руб.,
млн. руб.,
где tтаб=1,860 — табличное значение t-критерия Стьюдента при уровне значимости a=0,1 и числе степеней свободы .
Объем выпускаемой продукции с вероятностью 90 % будет находиться в интервале от 43,13 до 58,81 млн. руб.
8. График, на котором изображены фактические и предсказанные уравнением регрессии значения Y, строим с помощью надстройки «Мастер диаграмм» EXCEL (рис. 2.5). Данная надстройка позволяет построить линии нескольких видов регрессии (линейной, степенной, логарифмической, экспоненциальной и полиноминальной), определить их уравнение и коэффициент детерминации. Использование «Мастера диаграмм» рассмотрено в § 5.1.

рис. 2.5. Линия линейной парной регрессии и точки прогноза
Пример 2.2
Используя исходные данные предыдущего примера, выполнить следующие действия:
1. С помощью табличного процессора EXCEL построить уравнения линейной, логарифмической, степенной и показательной регрессий Y по X. Для указанных регрессий:
· привести графики их линий;
· дать экономическую интерпретацию параметрам уравнений;
· найти коэффициенты детерминации;
· проверить статистическую значимость уравнений по F-критерию Фишера;
· оценить точность моделей с помощью средней относительной ошибки аппроксимации.
2. Сравнить построенные модели между собой и выбрать лучшую из них для целей анализа и прогнозирования.
1. Линейную, степенную, логарифмическую и показательную регрессии строим с помощью «Мастера диаграмм» EXCEL. Линейная и степенная регрессии показаны на рис. 2.6, логарифмическая и показательная — на рис. 2.7. На графиках приводятся не только линии регрессии, но также их уравнения и коэффициенты детерминации (см. § 5.1).

рис. 2.6. Линии линейной и степенной регрессий

рис. 2.7. Линии логарифмической и показательной регрессий
Рассмотрим последовательно каждую модель.
1) Уравнение линейной регрессии имеет вид:
.
Угловой коэффициент b1=0,785 является показателем среднего абсолютного прироста. Его значение показывает, что при увеличении объема капиталовложений X на 1 млн. руб. объем выпускаемой продукции Y возрастает в среднем на 0,785 млн. руб.
Коэффициент детерминации R 2 =0,869 показывает, что линейная модель объясняет 89,8 % вариации объема выпускаемой продукции Y.
F-статистика Фишера линейной модели определяем через коэффициент детерминации R 2 по формуле
.
Табличное значение F-критерия Фишера для уровня значимости a=0,05 и чисел степеней свободы числителя (регрессии) и знаменателя (остатка)  составляет Fтаб=5,32. Так как F-статистика превышает табличное значение, то это свидетельствует о статистической значимости уравнения линейной регрессии в целом.
составляет Fтаб=5,32. Так как F-статистика превышает табличное значение, то это свидетельствует о статистической значимости уравнения линейной регрессии в целом.
Следует заметить, что табличное значение F-критерия Фишера одинаково как для линейной, так и для всех нелинейных моделей, которые здесь строятся (Fтаб=5,32).
Стандартная ошибка линейной регрессии рассчитывается по формуле
 млн. руб.,
млн. руб.,
где  млн. руб. — стандартное отклонение переменной X в исходных данных, определенное с помощью встроенной функции «СТАНДОТКЛОН».
млн. руб. — стандартное отклонение переменной X в исходных данных, определенное с помощью встроенной функции «СТАНДОТКЛОН».
Среднюю относительную ошибку аппроксимации определяем по приближенной формуле
 %,
%,
где 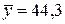 млн. руб. — средний объем выпускаемой продукции, определенный с помощью встроенной функции «СРЗНАЧ».
млн. руб. — средний объем выпускаемой продукции, определенный с помощью встроенной функции «СРЗНАЧ».
Предсказанные уравнением линейной регрессии значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 7,1 %.
2) Уравнение степенной регрессии выглядит следующим образом:
 .
.
Показатель степени b1=0,721 является средним коэффициентом эластичности. Его значение показывает, что при увеличении объема капиталовложений X на 1 % объем выпускаемой продукции Y возрастает в среднем на 0,721 %.
Коэффициент детерминации R 2 =0,873 показывает, что степенная модель объясняет 87,3 % вариации объема выпускаемой продукции Y.
F-статистика степенной модели

также превышает табличное значение F-критерия Фишера (Fтаб=5,32), что указывает на статистическую значимость уравнения степенной регрессии.
Стандартную ошибку и среднюю относительную ошибку аппроксимации нелинейных регрессий будем определять по тем же самым формулам, что и для линейной модели. Для степенной регрессии они равны:
 млн. руб.;
млн. руб.;
 %.
%.
Предсказанные уравнением степенной регрессии значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 7,0 %.
3) Уравнение логарифмической регрессии имеет вид:
 .
.
Значение параметра b1=29,9 показывает, что при увеличении объема капиталовложений X на 1 % объем выпускаемой продукции Y возрастает в среднем на  млн. руб.
млн. руб.
Коэффициент детерминации R 2 =0,898 показывает, что логарифмическая модель объясняет 89,8 % вариации объема выпускаемой продукции Y.
F-статистика Фишера логарифмической модели равна

и превышает табличное значение F-критерия Фишера (Fтаб=5,32). Это свидетельствует о статистической значимости уравнения регрессии.
Стандартная ошибка логарифмической регрессии составляет
 млн. руб.
млн. руб.
Средняя относительная ошибка аппроксимации имеет значение
 %.
%.
Предсказанные уравнением логарифмической регрессии значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 6,2 %.
4) Уравнение показательной регрессии определяется через экспоненциальную регрессию:
 ,
,
где е=2,718… — основание натуральных логарифмов;  — функция экспоненты (в EXCEL встроенная функция «EXP»).
— функция экспоненты (в EXCEL встроенная функция «EXP»).
Параметр b1=1,019 показательной регрессии является средним коэффициентом роста. Его значение показывает, что при увеличении объема капиталовложений X на 1 млн. руб. объем выпуска продукции Y возрастает в среднем в 1,019 раза, т.е. на 1,9 %.
Заметим, что параметр b1 экспоненциальной регрессии  , умноженный на 100, является средним темпом прироста, выраженным в процентах. Данный вывод вытекает из приближенного соотношения
, умноженный на 100, является средним темпом прироста, выраженным в процентах. Данный вывод вытекает из приближенного соотношения  , при относительно малых значениях a (
, при относительно малых значениях a (  ).
).
Уравнения показательной и экспоненциальной регрессии являются эквивалентными.
Коэффициент детерминации R 2 =0,821 показывает, что показательная модель объясняет 82,1 % вариации объема выпускаемой продукции Y.
F-статистика показательной модели

превышает табличное значение F-критерия Фишера (Fтаб=5,32), что свидетельствует о статистической значимости уравнения регрессии.
Стандартная ошибка показательной регрессии
 млн. руб.
млн. руб.
Средняя относительная ошибка аппроксимации
 %.
%.
Предсказанные уравнением показательной регрессии значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 8,3 %.
2. Сравнивая между собой коэффициенты детерминации R 2 четырех моделей, можно придти к выводу, что лучшей из них является логарифмическая модель, так как она имеет самое большое значение R 2 . Эту модель и целесообразно использовать в качестве рабочей для анализа и прогнозирования изменения объема выпускаемой продукции Y в зависимости от изменения объема капиталовложений X.
Заметим, что при выборе лучшей модели из четырех рассмотренных для целей анализа параметр b1 должен иметь содержательную интерпретацию. Так, если бы переменные X и Y были относительными величинами и измерялись в процентах, то корректная интерпретация параметра b1 нелинейных моделей оказалась бы затруднительной. В этом случае для прогнозирования следовало бы выбрать модель с большим R 2 , а для целей анализа — линейную модель.
Пример 2.3
В магазине исследуется зависимость количества реализованных за день упаковок шампуня (Y, шт.) от цены одной упаковки (X, руб.). Имеется информация по одиннадцати наименованиям шампуня:
| Шампунь | А | Б | В | Г | Д | Е | Ж | З | И | К | Л |
| Y | |||||||||||
| X |
Выполнить те же самые действия, что и в предыдущем примере.
1. Линейную, степенную, логарифмическую и показательную регрессии строим с помощью «Мастера диаграмм» EXCEL. Линейная и степенная регрессии показаны на рис. 2.8, логарифмическая и показательная — на рис. 2.9.
Используя формулы предыдущего примера, рассчитаем для каждой модели коэффициент детерминации R 2 , F-статистику Фишера, стандартную ошибку регрессии Sрег и среднюю относительную ошибку аппроксимации Eотн (  шт.; Sy=13,631 шт.). Полученные результаты сведены в табл. 2.3.
шт.; Sy=13,631 шт.). Полученные результаты сведены в табл. 2.3.

рис. 2.8. Линии линейной и степенной регрессий

рис. 2.9. Линии логарифмической и показательной регрессий
| Таблица | 2.3 |
| Сводная таблица результатов моделирования |
| Модель | Уравнение регрессии | R 2 | F | Sрег, шт. | Eотн, % |
| 1. Линейная |  | 0,788 | 33,45 | 6,62 | 11,8 |
| 2. Степенная |  | 0,857 | 53,94 | 5,43 | 9,7 |
| 3. Логарифмическая |  | 0,834 | 45,22 | 5,86 | 10,4 |
| 4. Показательная (экспоненциальная) |  ( (  ) ) | 0,825 | 42,43 | 6,01 | 10,7 |
Очевидно, что между переменными X и Y имеется обратная статистическая связь. На это указывают отрицательные значения параметра b1 линейного, степенного и логарифмического уравнений регрессии, а также меньшее единицы значение параметра b1 показательного уравнения. Все уравнения регрессии статистически значимы на уровне значимости a=0,05 ( ;  ; Fтаб=5,12).
; Fтаб=5,12).
Угловой коэффициент b1=–0,933 линейной регрессии показывает, что при увеличении цены шампуня X на 1 руб. количество проданных упаковок Y уменьшается в среднем на 0,933 шт. Линейная модель объясняет 78,8 % вариации Y (R 2 =0,788). Предсказанные уравнением регрессии значения Y отличаются от фактических значений в среднем на 11,8 %.
Показатель степени b1=–0,888 степенной регрессии показывает, что при увеличении цены X на 1 % число реализованных упаковок Y уменьшается в среднем на 0,888 %. Степенная модель объясняет 85,7 % вариации Y. Предсказанные уравнением регрессии значения Y отличаются от фактических в среднем на 9,7 %.
Значение параметра b1=39,6 логарифмической регрессии показывает, что при увеличении цены единицы продукции X на 1 % количество проданных упаковок Y уменьшается в среднем на  шт. Логарифмическая модель объясняет 83,4 % вариации Y. Средняя погрешность предсказания составляет 10,4 %.
шт. Логарифмическая модель объясняет 83,4 % вариации Y. Средняя погрешность предсказания составляет 10,4 %.
Значение основания степени b1=0,979 показательной регрессии показывает, что при увеличении цены X на 1 руб. объем реализации Y составит в среднем 97,9 % от первоначального значения, или, другими словами, уменьшится на 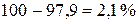 . Это же значение получается, если умножить на 100 параметр «–0,021» экспоненциальной регрессии (см. табл. 2.3). Показательная модель объясняет 82,5 % вариации Y. Предсказанные уравнением регрессии значения Y отличаются от фактических в среднем на 10,7 %.
. Это же значение получается, если умножить на 100 параметр «–0,021» экспоненциальной регрессии (см. табл. 2.3). Показательная модель объясняет 82,5 % вариации Y. Предсказанные уравнением регрессии значения Y отличаются от фактических в среднем на 10,7 %.
2. Сравнивая между собой коэффициенты детерминации R 2 четырех построенных моделей, приходим к выводу, что лучшей является степенная модель, имеющая наибольший R 2 . Эту модель и целесообразно использовать в качестве рабочей для анализа и прогнозирования изменения объема реализации Y от изменения цены единицы продукции X.
Контрольные задания
Используя приведенные ниже данные, выполнить расчеты в соответствии с заданием к примерам 2.1 и 2.2. В вариантах 1 – 5 между переменными присутствует прямая связь, в вариантах 6 – 10 — обратная связь.
Вариант 1(прямая связь)
| Наблюдение |
| Y |
| X |
Вариант 2(прямая связь)
| Наблюдение |
| Y |
| X |
Вариант 3(прямая связь)
| Наблюдение |
| Y |
| X |
Вариант 4(прямая связь)
| Наблюдение |
| Y |
| X |
Вариант 5(прямая связь)
| Наблюдение |
| Y |
| X |
Вариант 6(обратная связь)
| Наблюдение |
| Y |
| X |
Вариант 7(обратная связь)
| Наблюдение |
| Y |
| X |
Вариант 8(обратная связь)
| Наблюдение |
| Y |
| X |
Вариант 9(обратная связь)
| Наблюдение |
| Y |
| X |
Вариант 10(обратная связь)
| Наблюдение |
| Y |
| X |
Тестовые вопросы для самоконтроля
Из перечня предлагаемых ответов на вопрос только один является правильным. Правильные ответы приведены на с. 151. Числовые данные тестов можно использовать как исходные для рассмотренных в § 2.7 примеров.
По десяти интернет-брокерам в секции фондового рынка имеются данные, характеризующие зависимость годового торгового оборота (Y, млрд. руб.) от средней ставки маржинального кредитования (X, % годовых):
| Компания | А | Б | В | Г | Д | Е | Ж | З | И | К |
| Y | 30,82 | 30,8 | 25,14 | 14,1 | 12,73 | 10,8 | 9,74 | 8,42 | 7,65 | |
| X | 16,5 |
Парный коэффициент линейной корреляции между переменными Y и X имеет значение ry,x=–0,451.
Охарактеризовать линейную связь между торговым оборотом Y и средней ставкой маржинального кредитования X, если критическое значение коэффициента корреляции на уровне значимости a=0,05 составляет rкр=0,632.
а) Линейная связь статистически значимая.
б) Линейная связь статистически незначимая.
в) Линейная связь тесная.
г) Линейная связь прямая функциональная.
д) Линейная связь обратная функциональная.
По семи целлюлозно-бумажным компаниям имеются данные, характеризующие зависимость объема выпускаемой продукции (Y, млн. долл. США) от производственной мощности (X, тыс. тонн целлюлозы в год), по итогам года:
| Компания | А | Б | В | Г | Д | Е | Ж |
| Y | |||||||
| X |
Стандартные отклонения переменных Y и X и парный коэффициент корреляции между ними имеют соответственно значения: Sy=344 млн. долл. США, Sx=824 тыс. тонн, ry,x=0,988.
На сколько в среднем увеличивается объем выпускаемой продукции Y при росте производственной мощности X на одну тысячу тонн целлюлозы в год?
а) На 0,344 млн. долл.
б) На 0,824 млн. долл.
в) На 0,412 млн. долл.
г) На 0,988 млн. долл.
д) На 0,280 млн. долл.
Исследуется связь между официальными курсами доллара США (Y, руб./USD) и евро (X, руб./EUR), установленными Центральным банком Российской Федерации. Имеются данные за десять последовательных дней:
| День | ||||||||||
| Y | 28,11 | 27,97 | 27,97 | 28,01 | 27,98 | 28,12 | 28,19 | 28,13 | 28,09 | 28,07 |
| X | 36,59 | 36,46 | 36,56 | 36,47 | 36,28 | 36,13 | 35,98 | 35,97 | 36,00 | 36,13 |
Методом наименьших квадратов было получено уравнение линейной регрессии Y по X:
 .
.
Суммы квадратов отклонений зависимой переменной Y от своего среднего значения составляют:
· обусловленная регрессией — SSрег=0,0240;
Рассчитать F-статистику и проверить статистическую значимость уравнения регрессии, если табличное значение F‑критерия Фишера на уровне значимости a=0,05 составляет Fтаб=5,32.
а) F=6,17; уравнение регрессии статистически значимо.
б) F=0,77; уравнение регрессии статистически незначимо.
в) F=1,77; уравнение регрессии статистически незначимо.
г) F=2,54; уравнение регрессии статистически незначимо.
д) F=14,17; уравнение регрессии статистически значимо.
По девяти из наиболее прибыльных компаний региона имеются данные, характеризующие зависимость чистой прибыли (Y, млн. руб.) от объема реализации (X, млн. руб.) по итогам одного года:
| Компания | А | Б | В | Г | Д | Е | Ж | З | И |
| Y | |||||||||
| X |
Методом наименьших квадратов было получено уравнение линейной регрессии Y по X:
 .
.
Коэффициент детерминациисоставляет R 2 =0,540.
Рассчитать F-статистику и проверить статистическую значимость уравнения регрессии на уровне a=0,05, если табличное значение F‑критерия Фишера составляет Fтаб=5,59.
а) F=0,73; уравнение регрессии статистически незначимо.
б) F=1,17; уравнение регрессии статистически незначимо.
в) F=3,91; уравнение регрессии статистически значимо.
г) F=8,22; уравнение регрессии статистически значимо.
д) F=22,6; уравнение регрессии статистически значимо.
По восьми крупнейшим западным банкам-консультантам на рынке M&A (сопровождение сделок по слияниям и поглощениям) имеются данные, характеризующие зависимость размера комиссионных (Y, млн. долл. США) от объема сделок (X, млрд. долл. США), по итогам трех кварталов года:
| Банк | А | Б | В | Г | Д | Е | Ж | З |
| Y | ||||||||
| X | 305,5 | 265,7 | 240,4 | 149,3 | 101,6 | 114,6 | 122,2 |
Уравнение линейной регрессии Y по X имеет вид:
 .
.
Стандартные ошибки коэффициентов уравнения составляют:
· свободного коэффициента —  млн. долл.;
млн. долл.;
· углового коэффициента —  млн. долл./млрд. долл.
млн. долл./млрд. долл.
Проверить статистическую значимость уравнения регрессии на уровне значимости a=0,05 для чего рассчитать соответствующую t-статистику. Табличное значение t‑критерия Стьюдента составляет tтаб=2,447.
а) t=0,892; уравнение регрессии статистически незначимо.
б) t=2,510; уравнение регрессии статистически значимо.
в) t=1,121; уравнение регрессии статистически незначимо.
г) t=3,404; уравнение регрессии статистически значимо.
д) t=3,816; уравнение регрессии статистически значимо.
По семи оценочным компаниям имеются данные, характеризующие зависимость совокупной выручки за полугодие (Y, тыс. руб.) от количества специалистов-оценщиков (X, чел.):
| Компания | А | Б | В | Г | Д | Е | Ж |
| Y | |||||||
| X |
С помощью «Мастера диаграмм» EXCEL были получены уравнения линейной, степенной, показательной и логарифмической регрессий Y по X, и для каждой модели определен коэффициент детерминации R 2 :
· линейная:  ; R 2 =0,877;
; R 2 =0,877;
· степенная:  ; R 2 =0,858;
; R 2 =0,858;
· показательная:  ; R 2 =0,939;
; R 2 =0,939;
· логарифмическая:  ; R 2 =0,780.
; R 2 =0,780.
Какая из моделей лучше характеризует вариацию совокупной выручки Y?
Исследуется связь между ценой нефти марки Urals (Y, долл. США/баррель) и ценой нефти марки Brent (X, долл./баррель) по итогам торгов на Международной нефтяной бирже за десять торговых дней:
| День | ||||||||||
| Y | 39,91 | 41,18 | 40,38 | 39,4 | 39,44 | 39,54 | 40,04 | 38,42 | 38,49 | 39,81 |
| X | 44,8 | 45,87 | 44,64 | 43,65 | 43,38 | 43,69 | 43,05 | 42,93 | 42,98 | 44,42 |
Было получено уравнение линейной регрессии Y по X:
 .
.
Дать правильную экономическую интерпретацию угловому коэффициенту b1=0,715 уравнения регрессии.
Угловой коэффициент b1=0,715 уравнения регрессии показывает, что …
а) … 71,5 % вариации цены нефти Urals объясняется вариацией цены нефти Brent.
б) … с ростом цены нефти Brent на один процент цена нефти Urals возрастает в среднем на 0,715 %.
в) … с ростом цены нефти Brent на один процент цена нефти Urals возрастает в среднем на 0,715 долл./баррель.
г) … с ростом цены барреля нефти Brent на один доллар цена барреля нефти Urals возрастает в среднем на 0,715 %.
д) … с ростом цены барреля нефти Brent на один доллар цена барреля нефти Urals возрастает в среднем на 0,715 доллара.
Исследуется зависимость месячного торгового оборота универсального магазина (Y, млн. руб.) от размера торговых площадей (X, м 2 ). Имеются данные по восьми универмагам города:
| Магазин | А | Б | В | Г | Д | Е | Ж | З |
| Y | ||||||||
| X |
Было получено уравнение степенной регрессии Y по X:
 .
.
Дать правильную экономическую интерпретацию показателю степени b1=0,552 в уравнении регрессии.
Показатель степени b1=0,552 в уравнении регрессии показывает, что …
а) … 55,2 % вариации торгового оборота объясняется вариацией размера торговых площадей.
б) … с увеличением размера торговых площадей на один процент торговый оборот возрастает в среднем на 0,552 %.
в) … с увеличением размера торговых площадей на один процент торговый оборот возрастает в среднем на 0,552 млн. руб.
г) … с увеличением размера торговых площадей на один квадратный метр торговый оборот возрастает в среднем на 0,552 %.
д) … с увеличением размера торговых площадей на один квадратный метр торговый оборот возрастает в среднем на 0,552 млн. руб.
По девяти туристическим агентствам города исследуется зависимость месячного торгового оборота (Y, тыс. долл. США) от количества менеджеров по туризму (X, чел.):
| Турагентство | А | Б | В | Г | Д | Е | Ж | З | И |
| Y | |||||||||
| X |
Было получено уравнение показательной регрессии Y по X:
 .
.
Дать правильную экономическую интерпретацию основанию степени b1=1,076 в уравнении регрессии.
Основание степени b1=1,076 в уравнении регрессии показывает, что …
а) … с увеличением численности менеджеров по туризму на одного человека торговый оборот возрастает в среднем в 1,076 раз, т.е. на 7,6 %.
б) … с увеличением численности менеджеров по туризму на одного человека торговый оборот возрастает в среднем на 1,076 %.
в) … с увеличением численности менеджеров по туризму на одного человека торговый оборот возрастает в среднем на 1,076 тыс. руб.
г) … с увеличением численности менеджеров по туризму на один процент торговый оборот возрастает в среднем в 1,076 раз, т.е. на 7,6 %.
д) … 1,076 % вариации торгового оборота объясняется вариацией численности менеджеров по туризму.
Исследуется связь между учетной ценой Банка России на аффинированное золото (Y, руб./г) и ценой золота на мировых рынках (X, долл. за тройскую унцию) по данным за десять последовательных дней:
| День | ||||||||||
| Y | 390,38 | 391,74 | 393,61 | 378,8 | 377,01 | 381,28 | 383,09 | 372,84 | 374,48 | 381,19 |
| X | 438,9 | 441,1 | 422,2 | 422,5 | 423,3 | 426,8 | 415,9 | 418,85 | 427,1 |
Методом наименьших квадратов было получено уравнение линейной регрессии Y по X:
 .
.
Построить интервальный прогноз учетной цены Банка России на аффинированное золото y0 с надежностью 90 % при цене золота x0=410 долл. за тройскую унцию, если стандартная ошибка прогноза фактического значения Y при этом составляет  руб./г, а табличное значение t-критерия Стьюдента — tтаб=1,86.
руб./г, а табличное значение t-критерия Стьюдента — tтаб=1,86.
С вероятностью 0,9 учетная цена золота будет находиться в интервале …
Уравнение нелинейной регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Виды нелинейной регрессии
| Вид | Класс нелинейных моделей |
| Нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам |
| Нелинейные по оцениваемым параметрам |
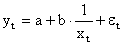
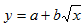
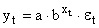
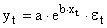

Здесь ε — случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.
Уравнению регрессии первого порядка — это уравнение парной линейной регрессии.
Уравнение регрессии второго порядка это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
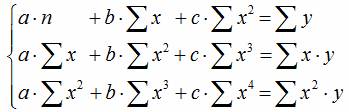
Уравнение регрессии третьего порядка соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
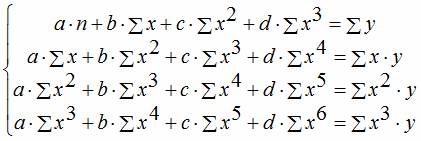
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания):
- Замена переменных.
- Логарифмирование обеих частей уравнения.
- Комбинированный.
| y = f(x) | Преобразование | Метод линеаризации |
| y = b x a | Y = ln(y); X = ln(x) | Логарифмирование |
| y = b e ax | Y = ln(y); X = x | Комбинированный |
| y = 1/(ax+b) | Y = 1/y; X = x | Замена переменных |
| y = x/(ax+b) | Y = x/y; X = x | Замена переменных. Пример |
| y = aln(x)+b | Y = y; X = ln(x) | Комбинированный |
| y = a + bx + cx 2 | x1 = x; x2 = x 2 | Замена переменных |
| y = a + bx + cx 2 + dx 3 | x1 = x; x2 = x 2 ; x3 = x 3 | Замена переменных |
| y = a + b/x | x1 = 1/x | Замена переменных |
| y = a + sqrt(x)b | x1 = sqrt(x) | Замена переменных |
Пример . По данным, взятым из соответствующей таблицы, выполнить следующие действия:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессии.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью F-критерия Фишера статистическую надежность результатов регрессионного моделирования. По значениям характеристик, рассчитанных в пп. 4, 5 и данном пункте, выбрать лучшее уравнение регрессии и дать его обоснование.
- Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 15% от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости α=0,05 .
- Оценить полученные результаты, выводы оформить в аналитической записке.
| Год | Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. — трлн. руб.), y | Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. — тыс. руб.), х |
| 1995 | 872 | 515,9 |
| 2000 | 3813 | 2281,1 |
| 2001 | 5014 | 3062 |
| 2002 | 6400 | 3947,2 |
| 2003 | 7708 | 5170,4 |
| 2004 | 9848 | 6410,3 |
| 2005 | 12455 | 8111,9 |
| 2006 | 15284 | 10196 |
| 2007 | 18928 | 12602,7 |
| 2008 | 23695 | 14940,6 |
| 2009 | 25151 | 16856,9 |
Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии. Получим таблицу следующего вида.
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
Степенное уравнение регрессии имеет вид y = a x b
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) — 49694.9535
Нелинейные модели регрессии. Виды нелинейных уравнений регрессии. Линеаризация нелинейных моделей регрессии. Оценка качества нелинейных уравнений регрессии.
При исследовании социально-экономических явлений и процессов далеко не все зависимости можно описать с помощью линейной связи. Поэтому в эконометрическом моделировании широко используется класс нелинейных моделей регрессии, которые делятся на два класса:
1) модели регрессии, нелинейные относительно включенных в анализ независимых переменных, но линейные по оцениваемым параметрам;
2) модели регрессии, нелинейные по оцениваемым параметрам.
К моделям регрессии, нелинейным относительно включённых в анализ независимых переменных (но линейных по оцениваемым параметрам), относятся полиномы выше второго порядка и гиперболическая функция.
Модели регрессии, нелинейным относительно включённых в анализ независимых переменных, характеризуются тем, что зависимая переменная yi линейно связана с параметрами β0…βn модели.
Полиномы или полиномиальные функции применяются при анализе процессов с монотонным развитием и отсутствием пределов роста. Данному условию отвечают большинство экономических показателей (например, натуральные показатели промышленного производства). Полиномиальные функции характеризуются отсутствием явной зависимости приростов факторных переменных от значений результативной переменной yi.
Общий вид полинома n-го порядка (n-ой степени):
Чаще всего в эконометрическом моделировании применяется полином второго порядка (параболическая функция), характеризующий равноускоренное развитие процесса (равноускоренный рост или снижение уровней):
Полиномы, чей порядок выше четвёртого, в эконометрических исследованиях обычно не применяются, потому что они не способны точно отразить существующую зависимость между результативной и факторными переменными.
Гиперболическая функция характеризует нелинейную зависимость между результативной переменной yi и факторной переменной xi, однако, данная функция является линейной по оцениваемым параметрам β0 и β1.
Гиперболоид или гиперболическая функция имеет вид:
Данная гиперболическая функция является равносторонней.
В качестве примера эконометрической модели в виде гиперболической функции можно привести модель зависимости затрат на единицу продукции от объёма производства.
Неизвестные параметры β0…βn модели регрессии, нелинейной по факторным переменным, можно найти только после того, как модели будет приведена к линейному виду.
Для того чтобы оценить неизвестные параметры β0…βn нелинейной регрессионной модели необходимо привести её к линейному виду. Суть процесс линеаризации нелинейных по факторным переменным моделей регрессии заключается в замене нелинейных факторных переменных на линейные переменные.
Рассмотрим процесс линеаризации полиномиальной функции порядка n:
Заменим все факторные переменные на линейные следующим образом:
Тогда модель множественной регрессии можно записать в виде:
yi=β0+β1c1i+ β2c2i+…+ βncni+εi.
Рассмотрим процесс линеаризации гиперболической функции:
Данная функция может быть приведена к линейному виду путём замены нелинейной факторной переменной 1/x на линейную переменную с. Тогда модель регрессии можно записать в виде:
Следовательно, модели регрессии, нелинейные относительно включенных в анализ независимых переменных, но линейные по оцениваемым параметрам, могут быть преобразованы к линейному виду. Это позволяет применять к линеаризованным моделям регрессии классические методы определения неизвестных параметров модели (метод наименьших квадратов), а также методы проверки различных гипотез
Характеристика временных рядов. Временные ряды данных. Структура временного ряда. Аддитивная и мультипликативная модели временных рядов. Модели стационарных и нестационарных временных рядов и их идентификация.
Система одновременных уравнений. Общие понятие о системах уравнений, используемых эконометрике. Классификация систем уравнений. Идентификация систем эконометрических уравнений. Методы оценки параметров систем одновременных уравнений.
http://math.semestr.ru/corel/noncorel.php
http://helpiks.org/8-19901.html