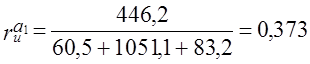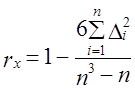5 способов расчета значений линейного тренда в MS Excel
Автор: Алексей Батурин.
Это первая статья из серии «Как самостоятельно рассчитать прогноз продаж с учетом роста и сезонности», из которой вы узнаете о 5 способах расчета значений линейного тренда в Excel.
Для того, чтобы легче было научиться прогнозировать продажи с учетом роста и сезонности, я разбил 1 большую статью о расчете прогноза на 3 части:
Расчет значений тренда (рассмотрим на примере Линейного тренда в этой статье);
Расчет сезонности;
Расчет прогноза;
После изучения данного материала вы сможете выбрать оптимальный способ расчета значений линейного тренда, который будет удобен для решения вашей задачи, а в последствии, и для расчета прогноза наиболее удобным для вас способом.
Линейный тренд хорошо применять для временного ряда, данные которого увеличиваются или убывают с постоянной скоростью.
Рассмотрим линейный тренд на примере расчета прогноза продаж в Excel по месяцам.
Временной ряд продажи по месяцам (см. вложенный файл).
В этом временном ряду у нас есть 2 переменных:
Уравнение линейного тренда y(x)=a+bx, где
y — это объёмы продаж
x — номер периода (порядковый номер месяца)
a – точка пересечения с осью y на графике (минимальный уровень);
b – это значение, на которое увеличивается следующее значение временного ряда;
1-й способ расчета значений линейного тренда в Excel с помощью графика
Выделяем анализируемый объём продаж и строим график, где по оси Х — наш временной ряд (1, 2, 3… — январь, февраль, март …), по оси У — объёмы продаж. Добавляем линию тренда и уравнение тренда на график. Получаем уравнение тренда y=135134x+4594044
Для прогнозирования нам необходимо рассчитать значения линейного тренда, как для анализируемых значений, так и для будущих периодов.
При расчете значений линейного тренде нам будут известны:
Время — значение по оси Х;
Значение «a» и «b» уравнения линейного тренда y(x)=a+bx;
Рассчитываем значения тренда для каждого периода времени от 1 до 25, а также для будущих периодов с 26 месяца до 36.
Например, для 26 месяца значение тренда рассчитывается по следующей схеме: в уравнение подставляем x=26 и получаем y=135134*26+4594044=8107551
27-го y=135134*27+4594044=8242686
2-й способ расчета значений линейного тренда в Excel — функция ЛИНЕЙН
1. Рассчитаем коэффициенты линейного тренда с помощью стандартной функции Excel:
=ЛИНЕЙН(известные значения y, известные значения x, константа, статистика)
Для расчета коэффициентов в формулу вводим
известные значения y (объёмы продаж за периоды),
известные значения x (номера периодов),
вместо константы ставим 1,
вместо статистики 0,
Получаем 135135 — значение (b) линейного тренда y=a+bx;
Для того чтобы Excel рассчитал сразу 2 коэффициента (a) и (b) линейного тренда y=a+bx, необходимо
установить курсор в ячейку с формулой и выделить соседнюю справа, как на рисунке;
нажимаем клавишу F2, а затем одновременно — клавиши CTRL + SHIFT + ВВОД.
Получаем 135135, 4594044 — значение (b) и (a) линейного тренда y=a+bx;
2. Рассчитаем значения линейного тренда с помощью полученных коэффициентов . Подставляем в уравнение y=135134*x+4594044 номера периодов — x, для которых хотим рассчитать значения линейного тренда.
2-й способ точнее, чем первый, т.к. коэффициенты тренда мы получаем без округления, а также быстрее.
3-й способ расчета значений линейного тренда в Excel — функция ТЕНДЕНЦИЯ
Рассчитаем значения линейного тренда с помощью стандартной функции Excel:
=ТЕНДЕНЦИЯ(известные значения y; известные значения x; новые значения x; конста)
Подставляем в формулу
известные значения y — это объёмы продаж за анализируемый период (фиксируем диапазон в формуле, выделяем ссылку и нажимаем F4);
известные значения x — это номера периодов x для известных значений объёмов продаж y;
новые значения x — это номера периодов, для которых мы хотим рассчитать значения линейного тренда;
константа — ставим 1, необходимо для того, чтобы значения тренда рассчитывались с учетом коэффицента (a) для линейного тренда y=a+bx;
Для того чтобы рассчитать значения тренда для всего временного диапазона, в «новые значения x» вводим диапазон значений X, выделяем диапазон ячеек равный диапазону со значениями X с формулой в первой ячейке и нажимаем клавишу F2, а затем — клавиши CTRL + SHIFT + ВВОД.
4-й способ расчета значений линейного тренда в Excel — функция ПРЕДСКАЗ
Рассчитаем значения линейного тренда с помощью стандартной функции Excel:
=ПРЕДСКАЗ(x; известные значения y; известные значения x)
Вместо X поставляем номер периода, для которого рассчитываем значение тренда.
Вместо «известные значения y» — объёмы продаж за анализируемый период (фиксируем диапазон в формуле, выделяем ссылку и нажимаем F4);
«известные значения x» — это номера периодов для каждого выделенного объёма продаж.
3-й и 4-й способ расчета значений линейного тренда быстрее, чем 1 и 2-й, однако с его помощью невозможно управлять коэффициентами тренда, как описано в статье «О линейном тренде».
5-й способ расчета значений линейного тренда в Excel — Forecast4AC PRO
2. Заходим в меню программы и нажимаем «Start_Forecast». Значения линейного тренда рассчитаны.
Для расчета прогноза осталось применить к значениям трендов будущих периодов коэффициенты сезонности, и прогноз продаж с учетом роста и сезонности готов.
В следующих статье «Как самостоятельно сделать прогноз продаж с учетом роста и сезонности» мы:
О том, что еще важно знать о линейном тренде, вы можете узнать в статье «Что важно знать о линейном тренде».
Точных вам прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:
Novo Forecast Lite — автоматический расчет прогноза в Excel .
4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Анализ временных рядов, тренд ряда динамики, точечная оценка прогноза
МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ
Анализ временных рядов
Временной ряд (или ряд динамики) – это упорядоченная по времени последовательность значений некоторой произвольной переменной величины. Тем самым, временной ряд существенным образом отличается от простой выборки данных. Каждое отдельное значение данной переменной называется отсчётом (уровнем элементов) временного ряда.
Временные ряды состоят из двух элементов:
периода времени, за который или по состоянию на который приводятся числовые значения;
числовых значений того или иного показателя, называемых уровнями ряда.
Временные ряды классифицируются по следующим признакам:
по форме представления уровней: ряды абсолютных показателей, относительных показателей, средних величин;
по количеству показателей, когда определяются уровни в каждый момент времени: одномерные и многомерные временные ряды;
по характеру временного параметра: моментные и интервальные временные ряды. В моментных временных рядах уровни характеризуют значения показателя по состоянию на определенные моменты времени. В интервальных рядах уровни характеризуют значение показателя за определенные периоды времени. Важная особенность интервальных временных рядов абсолютных величин заключается в возможности суммирования их уровней. Отдельные же уровни моментного ряда абсолютных величин содержат элементы повторного счета. Это делает бессмысленным суммирование уровней моментных рядов;
по расстоянию между датами и интервалами времени выделяют равноотстоящие – когда даты регистрации или окончания периодов следуют друг за другом с равными интервалами и неполные (неравноотстоящие) – когда принцип равных интервалов не соблюдается;
по наличию пропущенных значений: полные и неполные временные ряды. Временные ряды бывают детерминированными и случайными: первые получают на основе значений некоторой неслучайной функции (ряд последовательных данных о количестве дней в месяцах); вторые есть результат реализации некоторой случайной величины;
в зависимости от наличия основной тенденции выделяют стационарные ряды – в которых среднее значение и дисперсия постоянны и нестационарные – содержащие основную тенденцию развития.
Временные ряды, как правило, возникают в результате измерения некоторого показателя. Это могут быть как показатели (характеристики) технических систем, так и показатели природных, социальных, экономических и других систем (например, погодные данные). Типичным примером временного ряда можно назвать биржевой курс, при анализе которого пытаются определить основное направление развития (тенденцию или тренда).
Анализ временных рядов – совокупность математико-статистических методов анализа, предназначенных для выявления структуры временных рядов и для их прогнозирования. Сюда относятся, в частности, методы регрессионного анализа. Выявление структуры временного ряда необходимо для того, чтобы построить математическую модель того явления, которое является источником анализируемого временного ряда. Прогноз будущих значений временного ряда используется для эффективного принятия решений.
Прогноз, характеристики и параметры прогнозирования
Прогноз (от греч. – предвидение, предсказание) – предсказание будущего с помощью научных методов, а также сам результат предсказания. Прогноз – это научная модель будущего события, явлений и т.п.
Прогнозирование, разработка прогноза; в узком значении – специальное научное исследование конкретных перспектив развития какого-либо процесса.
по срокам: краткосрочные, среднесрочные, долгосрочные;
по масштабу: личные, на уровне предприятия (организации), местные, региональные, отраслевые, мировые (глобальные).
К основным методам прогнозирования относятся:
статистические методы;
экспертные оценки (метод Дельфи);
моделирование.
Прогноз – обоснованное суждение о возможном состоянии объекта в будущем или альтернативных путях и сроках достижения этих состояний. Прогнозирование – процесс разработки прогноза. Этап прогнозирования – часть процесса разработки прогнозов, характеризующаяся своими задачами, методами и результатами. Деление на этапы связано со спецификой построения систематизированного описания объекта прогнозирования, сбора данных, с построением модели, верификацией прогноза.
Прием прогнозирования – одна или несколько математических или логических операций, направленных на получение конкретного результата в процессе разработки прогноза. В качестве приема могут выступать сглаживание динамического ряда, определение компетентности эксперта, вычисление средневзвешенного значения оценок экспертов и т. д.
Модель прогнозирования – модель объекта прогнозирования, исследование которой позволяет получить информацию о возможных состояниях объекта прогнозирования в будущем и (или) путях и сроках их осуществления.
Метод прогнозирования – способ исследования объекта прогнозирования, направленный на разработку прогноза. Методы прогнозирования являются основанием для методик прогнозирования.
Методика прогнозирования – совокупность специальных правил и приемов (одного или нескольких методов) разработки прогнозов.
Прогнозирующая система – система методов и средств их реализации, функционирующая в соответствии с основными принципами прогнозирования. Средствами реализации являются экспертная группа, совокупность программ и т. д. Прогнозирующие системы могут быть автоматизированными и неавтоматизированными.
Прогнозный вариант – один из прогнозов, составляющих группу возможных прогнозов.
Объект прогнозирования – процесс, система, или явление, о состоянии которого даётся прогноз.
Характеристика объекта прогнозирования – качественное или количественное отражение какого-либо свойства объекта прогнозирования.
Переменная объекта прогнозирования – количественная характеристика объекта прогнозирования, которая является или принимается за изменяемую в течение периода основания и (или) периода упреждения прогноза.
Период основания прогноза – промежуток времени, за который используют информацию для разработки прогноза. Этот промежуток времени называют также периодом предыстории.
Период упреждения прогноза – промежуток времени, на который разрабатывается прогноз.
Прогнозный горизонт – максимально возможный период упреждения прогноза заданной точности.
Точность прогноза – оценка доверительного интервала прогноза для заданной вероятности его осуществления.
Ошибка прогноза – апостериорная величина отклонения прогноза от действительного состояния объекта.
Источник ошибки прогноза – фактор, способный привести к появлению ошибки прогноза. Различают источники регулярных и нерегулярных ошибок.
Верификация прогноза – оценка достоверности и точности или обоснованности прогноза.
Статистические методы прогнозирования – научная и учебная дисциплина, к основным задачам которой относятся разработка, изучение и применение современных математико-статистических методов прогнозирования на основе объективных данных; развитие теории и практики вероятностно-статистического моделирования экспертных методов прогнозирования; методов прогнозирования в условиях риска и комбинированных методов прогнозирования с использованием совместно экономико-математических и эконометрических (как математико-статистических, так и экспертных) моделей. Научной базой статистических методов прогнозирования является прикладная статистика и теория принятия решений.
Простейшие методы восстановления используемых для прогнозирования зависимостей исходят из заданного временного ряда, т. е. функции, определённой в конечном числе точек на оси времени. Временной ряд при этом часто рассматривается в рамках той или иной вероятностной модели, вводятся другие факторы (независимые переменные), помимо времени, например, объем денежной массы. Временной ряд может быть многомерным. Основные решаемые задачи – интерполяция и экстраполяция. Метод наименьших квадратов в простейшем случае (линейная функция от одного фактора) был разработан К. Гауссом в 1794–1795 гг. Могут оказаться полезными предварительные преобразования переменных, например, логарифмирование. Наиболее часто используется метод наименьших квадратов при нескольких факторах.
Оценивание точности прогноза (в частности, с помощью доверительных интервалов) – необходимая часть процедуры прогнозирования. Обычно используют вероятностно-статистические модели восстановления зависимости, например, строят наилучший прогноз по методу максимального правдоподобия. Разработаны параметрические (обычно на основе модели нормальных ошибок) и непараметрические оценки точности прогноза и доверительные границы для него (на основе Центральной Предельной Теоремы теории вероятностей). Применяются также эвристические приемы, не основанные на вероятностно-статистической теории: метод скользящих средних, метод экспоненциального сглаживания.
Многомерная регрессия, в том числе с использованием непараметрических оценок плотности распределения – основной на настоящий момент статистический аппарат прогнозирования. Нереалистическое предположение о нормальности погрешностей измерений и отклонений от линии (поверхности) регрессии использовать не обязательно; однако для отказа от предположения нормальности необходимо опереться на иной математический аппарат, основанный на многомерной Центральной Предельной Теореме теории вероятностей, технологии линеаризации и наследования сходимости. Он позволяет проводить точечное и интервальное оценивание параметров, проверять значимость их отличия от 0 в непараметрической постановке, строить доверительные границы для прогноза.
Уравнение тренда временного ряда
Рассматривая временной ряд как множество результатов наблюдений изучаемого процесса, проводимых последовательно во времени, в качестве основных целей исследования временных рядов можно выделить: выявление и анализ характерного изменения параметра у, оценка возможного изменения параметра в будущем (прогноз).
Значения временного ряда можно представить в виде: , где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем, – случайная величина, характеризующая отклонение уровня от f(t ).
Неслучайная функция f (t) называется трендом. Тренд отражает характерное изменение (тенденцию) yt за некоторый промежуток времени. На практике в качестве тренда выбирают несколько возможных теоретических или эмпирических моделей. Могут быть выбраны, например, линейная, параболическая, логарифмическая, показательная функции. Для выявления типа модели на координатную плоскость наносят точки с координатами ( t, yt ) и по характеру расположения точек делают вывод о виде уравнения тренда. Для получения уравнения тренда применяют различные методы: сглаживание с помощью скользящей средней, метод наименьших квадратов и другие.
Уравнение тренда линейного вида будем искать в виде yt=f(t ), где f (t) = a0+a1(t ).
Пример 1. Имеется временной ряд:
ti
1
2
3
4
5
6
7
8
9
10
xti
2
1
4
4
6
8
7
9
12
11
Построим график xti во времени. Добавим на графике линию тренда исходных значений ряда. При этом, щелкнув правой кнопкой мыши по линии тренда, можно вызвать контекстное меню «Формат линии тренда», а в нем поставить флажок «показывать уравнение на диаграмме», тогда на диаграмме высветится уравнение линии тренда, вычисленное встроенными возможностями Excel .
Чтобы определить уравнение тренда, необходимо найти значения коэффициентов а0 и а1. Эти коэффициенты следует определять, исходя из условия минимального отклонения значений функции f (t) в точках ti от значений исходного временного ряда в тех же точках ti . Это условие можно записать в виде (на основе метода наименьших квадратов):
где n – количество значений временного ряда.
Для того, чтобы найти значения а0 и а1, необходимо иметь систему из двух уравнений. Эти уравнения можно получить, используя условие равенства нулю производной функции в точках её экстремума. В нашем случае эта функция имеет вид . Обозначим её через Q . Найдем производные функции Q(а0, а1) по переменным а0 и а1. Получим систему уравнений:
Полученная система может быть преобразована (математически) в систему так называемых нормальных уравнений. При этом уравнения примут вид:
Теперь необходимо решить преобразованную систему уравнений относительно а0 и а1. Однако предварительно следует составить и заполнить вспомогательную таблицу:
t
t 2
хt
хtt
1
1
2
2
2
4
1
2
3
9
4
12
4
16
4
16
5
25
6
30
6
36
8
48
7
49
7
49
8
64
9
72
9
81
12
108
10
100
11
110
Подставив значения n = 10 в систему уравнений (2), получим
Решив систему уравнений относительно а0 и а1, получим а0 = -0,035, а1 = 1,17. Тогда функция тренда заданного временного ряда f (t) имеет вид:
f (t) = -0,035 + 1,17t.
Изобразим полученную функцию на графике.
Временной ряд приведен в таблице. Используя средства MS Excel :
построить график временного ряда;
добавить линию тренда и ее уравнение;
найти уравнение тренда методом наименьших квадратов, сравнить уравнения (выше на графике и полученное);
построить график временного ряда и полученной функции тренда в одной системе координат.
1. Реализация аспирина по аптеке (у.е.) за последние 7 недель приведена в таблице:
t
1
2
3
4
5
6
7
хti
3,2
3,3
2,9
2,2
1,6
1,5
1,2
2. Динамика потребления молочных продуктов (у.е.) по району за последние 7 месяцев:
t
1
2
3
4
5
6
7
хti
30
29
27
24
25
24
23
3. Динамика числа работников, занятых в одной из торговых сетей города за последние 8 лет приведена в таблице:
t
1
2
3
4
5
6
7
8
хti
280
361
384
452
433
401
512
497
4. Динамика потребления сульфаниламидных препаратов в клинике по годам (тыс. упаковок):
t
1
2
3
4
5
6
7
8
хti
14
21
29
33
38
44
46
50
5. Динамика продаж однокомнатных квартир в городе за последние 8 лет (тыс. ед.):
t
1
2
3
4
5
6
7
8
уt
39
40
36
34
36
37
33
35
6. Динамика потребления антибиотиков в клинике (тыс. упаковок):
t
1
2
3
4
5
6
7
8
хti
10
17
18
13
17
21
25
29
7. Динамика производства хлебобулочных изделий на хлебозаводе (тонн):
t
1
2
3
4
5
6
7
8
хti
510
502
564
680
523
642
728
665
8. Динамика потребления противовирусных препаратов по аптечной сети в начале эпидемии гриппа (тыс. единиц):
t
1
2
3
4
5
6
7
8
хti
36
42
34
38
12
32
26
20
9. Динамика потребления противовирусных препаратов по аптечной сети в конце эпидемии гриппа (тыс. единиц):
t
1
2
3
4
5
6
7
8
хti
46
52
44
48
32
42
36
30
10. Динамика потребления витаминов по аптечной сети в весенний период (с марта по апрель) в разные годы (у.е.):
t
1
2
3
4
5
6
7
8
хti
0,9
1,7
1,5
1,7
1,5
2,1
2,5
3,6
Пример 2. Используя данные примера 1, приведенного выше, вычислить точечный прогноз исходного временного ряда на 5 шагов вперед.
Исходя из условия задачи, необходимо определить точечную оценку прогноза для t = 11, 12, 13, 14, 15, где t в данном случае – шаг упреждения.
Рассмотрим решение этой задачи средствами Microsoft Excel . При решении данной задачи следует так же, как и в примере 1, ввести исходные данные. Выделив данные, построить точечный график, щелкнув правой кнопкой мыши по ряду данных, вызвать контекстное меню и выбрать «Добавить линию тренда».
Щелкнув правой кнопкой мыши по линии тренда, вызвать контекстное меню, выбрать «Формат линии тренда», в окне Параметры линии тренда указать прогноз на 5 периодов и поставить флажок в окошке «Показывать уравнение на диаграмме (рис. 14.3 рис. 14.3.). В версии Excel ранее 2007 окно диалога представлено на рисунке 14.4 рис. 14.4.
Итоговый график представлен на рисунке 14.5 рис. 14.5.
Значения прогноза для 11, 12, 13, 14 и 15 уровней получим, используя функцию ПРЕДСКАЗ( ). Данная функция позволяет получить значения прогноза линейного тренда. Вычисленные значения: 12,87, 14,04, 15,22, 16,39, 17,57.
Значения точечного прогноза для исходного временного ряда на 5 шагов вперед можно вычислить и с помощью уравнения функции тренда f(t ), найденного по методу наименьших квадратов. Для этого в полученное для f (t) выражение необходимо подставить значения t = 11, 12, 13, 14, 15. В результате получим (эти значения следует рассчитать, сформировав формулу в табличном процессоре MS Excel ):
Сравнивая результаты точечных прогнозных оценок, полученных разными способами, выявляем, что данные отличаются незначительно, таким образом, в любом из способов расчета присутствует определенная погрешность (ошибка) прогноза ().
Используя значения временного ряда Задания 1 согласно вашего варианта, вычислить точечный прогноз на 4 шага вперед. Продлить линию тренда на 4 прогнозных значения, вывести уравнение тренда, определить эти значения с помощью функции ПРЕДСКАЗ() или ТЕНДЕНЦИЯ(), а также по выражению функции тренда f(t ), полученному по методу наименьших квадратов в Задании 1. Сравнить полученные результаты.
23.01.2012, 17:50
9.6. Методика измерения параметров тренда
Когда тип тренда установлен, необходимо вычислить оптимальные значения параметров тренда исходя из фактических уровней. Для этого обычно используют метод наименьших квадратов (МНК). Его значение уже рассмотрено в предыдущих главах учебного пособия, в данном случае оптимизация состоит в минимизации суммы квадратов отклонений фактических уровней ряда от выравненных уровней (от тренда). Для каждого типа тренда МНК дает систему нормальных уравнений, решая которую вычисляют параметры тренда. Рассмотрим лишь три такие системы: для прямой, для параболы 2-го порядка и для экспоненты. Приемы определения параметров других типов тренда рассматриваются в специальной монографической литературе.
Для линейного тренда нормальные уравнения МНК имеют вид:
Нормальные уравнения МНК для экспоненты имеют следующий вид:
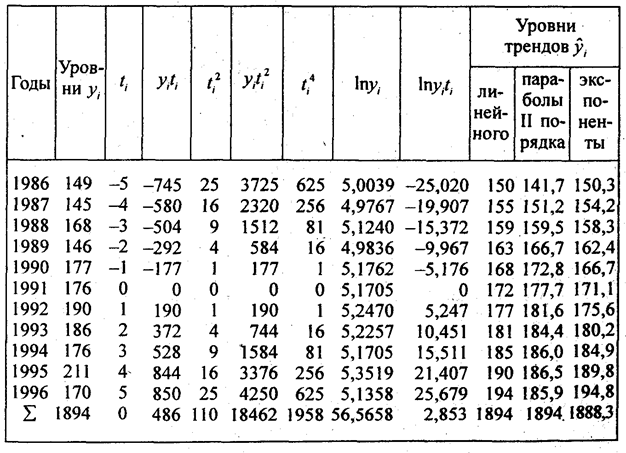
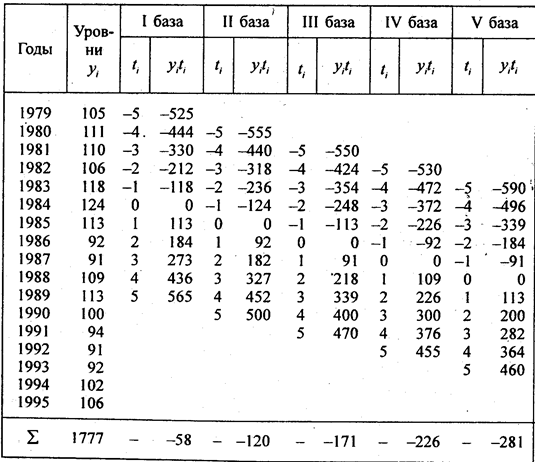
По данным табл. 9.1 рассчитаем все три перечисленных тренда для динамического ряда урожайности картофеля с целью их сравнения (см. табл. 9.5).
Расчет параметров трендов
Согласно формуле (9.29) параметры линейного тренда равны а = 1894/11 = 172,2 ц/га; b = 486/110 = 4,418 ц/га. Уравнение линейного тренда имеет вид:
у̂ = 172,2 + 4,418t, где t= 0 в 1987 г Это означает,что средний фактический и выравненный уровень, отнесенный к середине периода, т.е. к 1991 г., равен 172 ц с 1 ra a среднегодовой прирост составляет 4,418 ц/га в год
Параметры параболического тренда согласно (9.23) равны- b= 4,418; a = 177,75; с = -0,5571. Уравнение параболического тренда имеет вид у̃ = 177,75 + 4,418t — 0.5571t2;t = 0 в 1991 г. Это означает, что абсолютный прирост урожайности замедляется в среднем на 2·0,56 ц/га в год за год. Сам же абсолютный прирост уже не является константой параболического тренда, а является средней величиной за период. В год, принятый за начало отсчета т.е. 1991 г., тренд проходит через точку с ординатой 77,75 ц/га; Свободный член параболического тренда не является средним уровнем за период. Параметры экспоненциального тренда вычисляются по формулам(9.32) и (9.33) lnа = 56,5658/11 = 5,1423; потенцируя, получаем а = 171,1; lnk = 2,853:110 = 0,025936; потенцируя, получаем k = 1,02628.
Уравнение экспоненциального тренда имеет вид: y̅= 171,1·1,02628 t.
Это означает, что среднегодовой темп поста урожайности за период составил 102,63%. В точке принятК начало отсчета, тренд проходит точку с ординатой 171,1 ц/га.
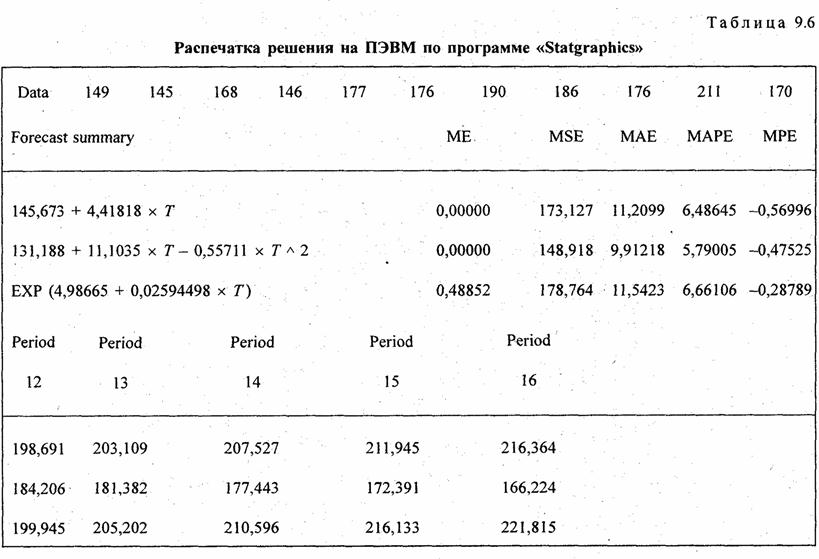
Рассчитанные по уравнениям трендов уровни записаны в трех последних графах табл. 9.5. Как видно по этим данным. расчетные значения уровней по всем трем видам трендов различаются ненамного, так как и ускорение параболы, и темп роста экспоненты невелики. Существенное отличие имеет парабола — рост уровней с 1995 г. прекращается, в то время как при линейном тренде уровни растут и далее, а при экспоненте их ост ускоряется. Поэтому для прогнозов на будущее эти три тренда неравноправны: при экстраполяции параболы на будущие годы уровни резко разойдутся с прямой и экспонентой, что видно из табл. 9.6. В этой таблице представлена распечатка решения на ПЭВМ по программе «Statgraphics» тех же трех трендов. Отличие их свободных членов от приведенных выше объясняется тем, что программа нумерует года не от середины, а от начала, так что свободные члены трендов относятся к 1986 г., для которого t = 0. Уравнение экспоненты на распечатке оставлено в логарифмированном виде. Прогноз сделан на 5 лет вперед, т.е. до 2001 г.. При изменении начала координат (отсчета времени) в уравнении параболы меняется и средний абсолютной прирост, параметр b. так как в результате отрицательного ускорения прирост все время сокращается, а его максимум — в начале периода. Константой параболы является только ускорение.
В строке «Data» приводятся уровни исходного ряда; «Forecast summary» означает сводные данные для прогноза. В следующих строках — уравнения прямой, параболы, экспоненты — в логарифмическом виде. Графа ME означает среднее расхождение между уровнями исходного ряда и уровнями тренда (выравненными). Для прямой и параболы это расхождение всегда равно нулю. Уровни экспоненты в среднем на 0,48852 ниже уровней исходного ряда. Точное совпадение возможно,, если истинный тренд — экспонента; в данном случае совпадения нет, но различие , мало. Графа МАЕ -это дисперсия s2— мера колеблемости фактических уровней относительно тренда, о чем сказано в п. 9.7. Графа МАЕ — среднее линейное отклонение уровней от тренда по модулю (см. параграф 5.8); графа МАРЕ — относительное линейное отклонение в процентах. Здесь они приведены как показатели пригодности выбранного вида тренда. Меньшую дисперсию и модуль отклонения имеет парабола: она за период 1986 — 1996 гг. ближе к фактическим уровням. Но выбор типа тренда нельзя сводить лишь к этому критерию. На самом деле замедление прироста есть результат большого отрицательного отклонения, т. е. неурожая в 1996 г.
Вторая половина таблицы — это прогноз уровней урожайности по трем видам трендов на годы; t = 12, 13, 14, 15 и 16 от начала отсчета (1986 г.). Прогнозируемые уровни по экспоненте вплоть до 16-го года ненамного выше,.чем по прямой. Уровни тренда-параболы — снижаются, все более расходясь с другими трендами.
Как видно в табл. 9.4, при вычислении параметров тренда уровни исходного ряда входят с разными весами — значениями tp и их квадратов. Поэтому влияние колебаний уровней на параметры тренда зависит от того, на какой номер года приходится урожайный либо неурожайный год. Если резкое отклонение приходится на год с нулевым номером (ti= 0), то оно никакого влияния на параметры тренда не окажет, а если попадет на начало и конец ряда, то повлияет сильно. Следовательно, однократное аналитическое выравнивание неполно освобождает параметры тренда от влияния колеблемости, и при сильных колебаниях они могут быть сильно искажены, что в нашем примере случилось с параболой. Для дальнейшего исключения искажающего влияния колебаний на параметры тренда следует применить метод многократного скользящего выравнивания.
Этот прием состоит в том, что параметры тренда вычисляются не сразу по всему ряду, а скользящим методом, сначала за первые т периодов времени или моментов, затем за период от 2-го до т + 1, от 3-го до (т + 2)-го уровня и т.п. Если число исходных уровней ряда равно п, а длина каждой скользящей базы расчета параметров равна т, то число таких скользящих баз t или отдельных значений параметров, которые будут по ним определены, составит:
Применение методики скользящего многократного выравнивания рассматривать, как видно из приведенных расчетов, возможно только при достаточно большом числе уровней ряда, как правило 15 и более. Рассмотрим эту методику на примере данных табл. 9.4 -динамики цен на нетопливные товары развивающихся стран, что опять же дает возможность читателю участвовать в небольшом научном исследовании. На этом же примере продолжим и методику прогнозирования в разделе 9.10.
Если вычислять в нашем ряду параметры по 11 -летним периодам (по 11 уровням), то t = 17 + 1 — 11 = 7. Смысл многократного скользящего выравнивания в том, что при последовательных сдвигах базы расчета параметров на концах ее и в середине окажутся разные уровни с разными по знаку и величине отклонениями от тренда. Поэтому при одних сдвигах базы параметры будут завышаться, при других — занижаться, а при последующем усреднении значений параметров по всем сдвигам базы расчета произойдет дальнейшее взаимопогашение искажений параметров тренда колебаниями уровней.
Многократное скользящее выравнивание не только позволяет получить более точную и надежную оценку параметров тренда, но и осуществить контроль правильности выбора типа уравнения тренда. Если окажется, что ведущий параметр тренда, его константа при расчете по скользящим базам не беспорядочно колеблется, а систематически изменяет свою величину существенным образом, значит, тип тренда был выбран неверно, данный параметр константой не является.
Что касается свободного члена при многократном выравнивании, то нет необходимости и, более того, просто неверно вычислять его величину как среднюю по всем сдвигам базы, ибо при таком способе отдельные уровни исходного ряда входили бы в расчет средней с разными весами, и сумма выравненных уровней разошлась бы с суммой членов исходного ряда. Свободный член тренда — это средняя величина уровня за период, при условии отсчета времени от середины периода. При отсчете от начала, если первый уровень ti = 1, свободный член будет равен: a0=у̅—b((N-1)/2). Рекомендуется длину скользящей базы расчета параметров тренда выбирать не менее 9-11 уровней, чтобы в достаточной мере погасить колебания уровней. Если исходный ряд очень длинный, база может составлять до 0,7 — 0,8 его длины. Для устранения влияния долго-периодических (циклических) колебаний на параметры тренда, число сдвигов базы должно быть равно или кратно длине цикла колебаний. Тогда начало и конец базы будут последовательно «пробегать» все фазы цикла и при усреднении параметра по всем сдвигам его искажения от циклических колебаний будут взаимопогашаться. Другой способ — взять длину скользящей базы, равной длине цикла, чтобы начало базы и конец базы всегда приходились на одну и ту же фазу цикла колебаний.
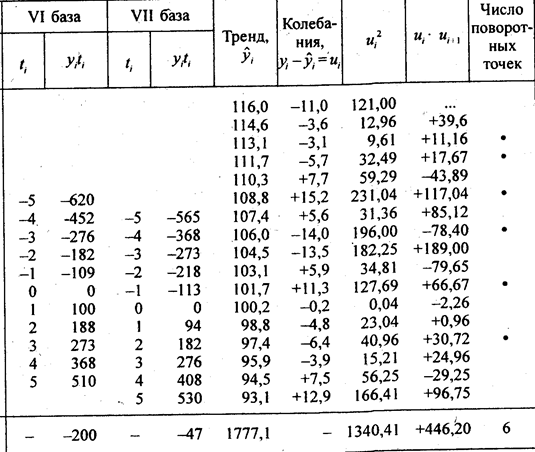
Поскольку по данным табл. 9.4, уже было установлено, что тренд имеет линейную форму, проводим расчет среднегодового абсолютного прироста, т. е. параметра b уравнения линейного тренда скользящим способом по 11-летним базам (см. табл. 9.7). В ней же приведен расчет данных, необходимых для последующего изучения колеблемости в параграфе 9.7. Остановимся подробнее на методике многократного выравнивания по скользящим базам. Рассчитаем параметр b по всем базам:
Многократное скользящее выравнивание по прямой
Уравнение тренда: у̂= 104,53 — 1,433t; t = 0 в 1987 г. Итак, индекс цен в среднем за год снижался на 1,433 пункта. Однократное выравнивание по всем 17 уровням может исказить этот параметр, ибо начальный уровень содержит значительное отрицательное отклонение, а конечный уровень — положительное. В самом деле, однократное выравнивание дает величину среднегодового изменения индекса всего на 0,953 пункта.
9.7. Методика изучения и показатели колеблемости
Если при изучении и измерении тенденции динамики колебания уровней играли лишь роль помех, «информационного шума», от которого следовало по возможности абстрагироваться, то в дальнейшем сама колеблемость становится предметом статистического исследования. Значение изучения колебаний уровней динамического ряда очевидно: колебания урожайности, продуктивности скота, производства мяса экономически нежелательны, так как потребность в продукции агрокомплекса постоянна. Эти колебания следует уменьшать, применяя прогрессивную технологию и другие меры. Напротив, сезонные колебания объемов производства зимней и летней обуви, одежды, мороженого, зонтиков, коньков — необходимы и закономерны, так как спрос на эти товары тоже колеблется по сезонам и равномерное производство требует лишних затрат на хранение запасов. Регулирование рыночной экономики как со стороны государства, так и производителей в значительной мере состоит в регулировании колебаний экономических процессов.
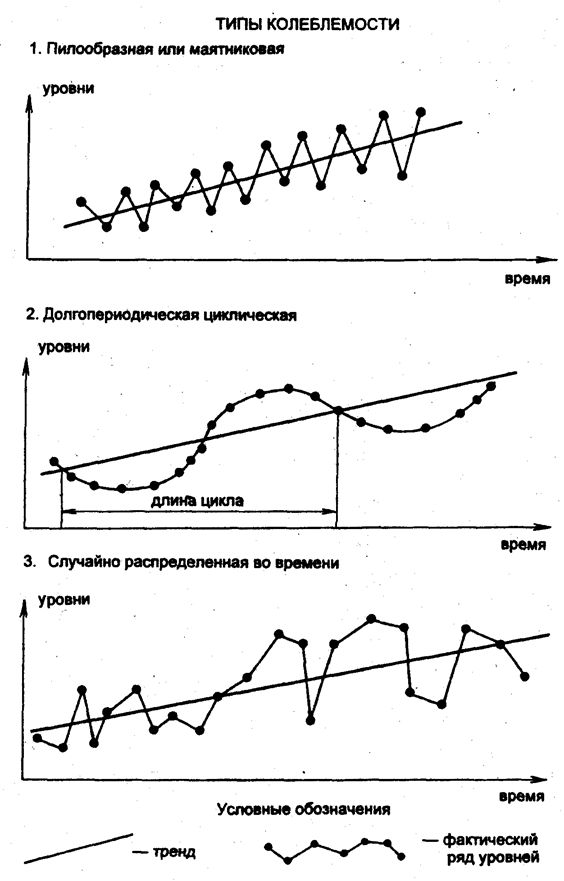
Типы колебаний статистических показателей весьма разнообразны, но все же можно выделить три основных: пилообразную или маятниковую колеблемость, циклическую долгопериодическую и случайно распределенную во времени колеблемость. Их свойства и отличия друг от друга хорошо видны при графическом изображении рис. 9.2.
Пилообразная или маятниковая колеблемость состоит в попеременных отклонениях уровней от тренда в одну и в другую сторону. Таковы автоколебания маятника. Такие автоколебания можно наблюдать в динамике урожайности при невысоком уровне агротехники: высокий урожай при благоприятных условиях погоды выносит из почвы больше питательных веществ, чем их образуется естественным путем за год; почва обедняется, что вызывает снижение следу- ющего урожая ниже тренда, он выносит меньше питательных веществ, чем образуется за год, плодородие возрастает и т.д.
Рис. 9.2. Виды колебаний
Циклическая долгопериодическая колеблемость свойственна, например, солнечной активности (10-11-летние циклы), а значит, и связанным с ней на Земле процессам — полярным сияниям, грозовой деятельности, урожайности отдельных культур в ряде районов, некоторым заболеваниям людей, растений. Для этого типа характерны редкая смена знаков отклонений от тренда и кумулятивный (накапливающийся) эффект отклонений одного знака, который может тяжело отражаться на экономике. Зато колебания хорошо прогнозируются.
Случайно распределенная во времени колеблемость — нерегулярная, хаотическая. Она может возникать при наложении (интерференции) множества колебаний с разными по длительности циклами. Но может возникать в результате столь же хаотической колеблемости главной причины существования колебаний, например суммы осадков за летний период, температуры воздуха в среднем за месяц в разные годы.
Для определения типа колебаний применяются графическое изображение, метод «поворотных точек» М. Кендэла, вычисление коэффициентов автокорреляции отклонений от тренда. Эти методы будут рассмотрены далее.
Основными показателями, характеризующими силу колеблемости уровней, выступают уже известные по главе 5 показатели, характеризующие вариацию значений признака в пространственной совокупности. Однако вариация в пространстве и колеблемость во времени принципиально различны. Прежде всего различны их основные причины. Вариация значений признака у одновременно существующих единиц возникает из-за различий в условиях существования единиц совокупности. Например, разная урожайность картофеля в совхозах области в 1990 г. вызвана различиями в плодородии почв, в качестве семян, в агротехнике. А вот суммы эффективных температур за вегетационный период и осадков не являются причинами пространственной вариации, так как в одном и том же году на территории области эти факторы почти не варьируют. Напротив, главными причинами колебания урожайности картофеля в области за ряд лет как раз являются колебания метеорологических факторов, а качество почв колебаний почти не имеет. Что же касается общего прогресса агротехники, то он является причиной тренда, но не колеблемости.
Второе коренное отличие состоит в том, что значения варьирующего признака в пространственной совокупности можно считать в основном не зависимыми друг от друга, напротив, уровни динамического ряда, как правило, являются зависимыми: это показатели развивающегося процесса, каждая стадия которого связана с предыдущими состояниями.
В-третьих, вариация в пространственной совокупности измеряется отклонениями индивидуальных значений признака от среднего значения, а колеблемость уровней динамического ряда измеряется не их отличиями от среднего уровня (эти отличия включают и тренд, и колебания), а отклонениями уровней от тренда.
Поэтому лучше использовать разные термины: различия признака в пространственной совокупности называть только вариацией, но не колебаниями: никто же не станет называть различия численности населения Москвы, Петербурга, Киева и Ташкента «колебаниями числа жителей»! Отклонения уровней динамического ряда от тренда будем называть всегда колеблемостью. Колебания всегда происходят во времени, не может существовать колебаний вне времени, в фиксированный момент.
На основе качественного содержания понятия колеблемости строится и система ее показателей. Показателями силы колебании уровней являются: амплитуда отклонений уровней отдельных периодов или моментов от тренда (по модулю), среднее абсолютное отклонение уровней от тренда (по модулю), среднее квадратическое откло;-нение уровней от тренда. Относительные меры колеблемости: относительное линейное отклонение от тренда и коэффициент колеблемости — аналог коэффициента вариации.
Особенностью методики вычисления средних отклонений от тренда является необходимость учета потерь степеней свободы колебаний на величину, равную числу параметров уравнения тренда. Например, прямая линия имеет два параметра, и, как известно из геометрии, через любые две точки можно провести прямую линию. Значит, имея лишь два уровня, мы проведем линию тренда точно через эти два уровня, и никаких отклонений уровней от тренда не окажется, хотя на самом деле и эти два уровня включали колебания, не были свободны от действия факторов колеблемости. Парабола второго порядка пройдет точно через любые три точки и т.п.
Учитывая потерю степеней свободы, основные абсолютные показатели колеблемости вычисляются по формулам (9.34) и (9.35):
среднее линейное отклонение
(9.34)
среднее квадратичное отклонение
(9.35)
где yi — фактический уровень;
n — число уровней;
р — число параметров тренда.
Знак времени «t» в скобках после показателя означает, что это показатель не обычной пространственной вариации, как в главе V, а показатель колеблемости во времени.
Относительные показатели колеблемости вычисляются делением абсолютных показателей на средний уровень за весь изучаемый период. Расчет показателей колеблемости проведем по результатам анализа динамики индекса цен (см. табл. 9.7). Тренд примем по результатам многократного скользящего выравнивания, т. е. у̂= 104,53 — 1,433t ; t = 0 в 1987 г.
1. Амплитуда колебаний составила от -14,0 в 1986 г. до +15,2 в 1984 г., т.е. 29,2 пункта.
2. Среднее линейное отклонение по модулю найдем, сложив модули |ui| (их сумма равна 132,3), и разделив на (п — р), согласно формуле (9.34):
=8,82 пункта.
3. Среднее квадратическое отклонение уровней от тренда по формуле (9.35) составило:
= 9,45 пункта.
Небольшое превышение среднего квадратического отклонения над линейным указывает на отсутствие среди отклонений резко выделяющихся по абсолютной величине.
4. Коэффициент колеблемости: или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 — отклонение от линейного тренда:
Для выявления типа колебаний воспользуемся приемом, предложенным М. Кендэлом. Он состоит в подсчете так называемых «поворотных точек» в ряду отклонений от тренда иi т. е. локальных экстремумов. Отклонение, либо большее по алгебраической величине, либо меньшее двух соседних, отмечается точкой. Обратимся к рис. 9.2. При маятниковой колеблемости все отклонения, кроме двух крайних, будут «поворотными», следовательно, их число составит п —1. При долгопериодических циклах на цикл приходятся один минимум и один максимум, а общее число точек составит 2(n:l), где l — длительность цикла. При случайно распределенной во времени колеблемости, как доказал М. Кендэл, число поворотных точек в среднем составит: 2/3 (n — 2). В нашем примере при маятниковой колеблемости было бы 15 точек, при связанной с 11-летним циклом было бы 2-(17 : 11) ≈ 3 точки, при случайно распределенной во времени в среднем было бы (2/3)·(17-2) =10 точек.
Фактическое число точек 6 выходит за границы двукратного среднего квадратического отклонения числа поворотных точек, которое по Кендэлу равно , в нашем случае .
Наличие 6 точек, при 2 точках за цикл, означает, что в ряду могут быть примерно 3 цикла, продолжительность периода которых 5,5 — 6 лет. Возможно сочетание таких циклических колебаний со случайными.
Другой метод анализа типа колеблемости и поиска длины цикла основан на вычислении коэффициентов автокорреляции отклонений от тренда.
Автокорреляция — это корреляция между уровнями ряда или отклонениями от тренда, взятыми со сдвигом во времени: на 1 период (год), на 2, на 3 и т. д., поэтому говорят о коэффициентах автокорреляции разных порядков: первого, второго и т. д. Рассмотрим сначала коэффициент автокорреляции отклонений от тренда первого порядка.
Одна из основных формул для расчета коэффициента автокорреляции отклонений от тренда имеет вид:
(9.36)
Как легко видеть по табл. 9.7, первое и последнее в ряду отклонения участвуют только в одном произведении в числителе, а все прочие отклонения от второго до (п — 1)-го — в двух. Поэтому и в знаменателе квадраты первого и последнего отклонений следует взять с половинным весом, как в хронологической средней. По данным табл. 9.7 имеем:
Теперь обратимся к рис. 9.2. При маятниковой колеблемости все произведения в числителе будут отрицательными величинами, и коэффициент автокорреляции первого порядка будет близок к -1. При долголериодических циклах будут преобладать положительные произведения соседних отклонений, а смена знака происходит лишь дважды за цикл. Чем длиннее Цикл, тем больше перевес положительных произведений в числителе, и коэффициент автокорреляции первого порядка ближе к +1. При случайно распределенной во времени колеблемости знаки отклонений чередуются хаотически, число положительных произведений близко к числу отрицательных, ввиду чего коэффициент автокорреляции близок к нулю. Полученное значение говорит о наличии как случайно распределенных во времени колебаний, так и циклических. Коэффициенты автокорреляции следующих порядков: II = — 0,577; Ш = -0,611; IV == -0,095; V = +0,376; VI = +0,404; VII = +0,044. Следовательно, противофаза цикла ближе всего кЗ годам (наибольший отрицательный коэффициент при сдвиге на 3 года), а совпадающие фазы ближе к б годам, что и дает длину цикла колебаний. Эти максимальные по абсолютной величине коэффициенты не близки к единице. Это означает, что циклическая колеблемость смешана со значительной случайной колеблемостью. Таким образом, подробный автокорреляционный анализ в целом дал те же результаты, что и выводы по автокорреляции первого порядка.
Если динамический ряд достаточно длинен, можно поставить и решить задачу об изменении показателей колеблемости с течением времени. Для этого рассчитывают эти показатели по подпериодам, но длительностью не менее 9-11 лет, иначе измерения колеблемости ненадежны. Кроме того, можно рассчитывать показатели колеблемости скользящим способом, а затем произвести их выравнивание, т. е. вычислить тренд показателей колеблемости. Это полезно, чтобы сделать вывод о действенности мер, применявшихся для уменьшения колебаний урожайности и других нежелательных колебаний, а также для того, чтобы по тренду сделать прогноз ожидаемых в будущем размеров колебаний.
9.8. Измерение устойчивости в динамике
Понятие «устойчивость» используется в весьма различных смыслах. По отношению к статистическому изучению динамики мы рассмотрим два аспекта этого понятия: 1) устойчивость как категория, противоположная колеблемости; 2) устойчивость направленности изменений, т. е. устойчивость тенденции.
В первом понимании показатель устойчивости, который может быть только относительным, должен изменяться от нуля до единицы (100%). Это разность между единицей и относительным показателем колеблемости. Коэффициент колеблемости составил 9,0%. Следовательно, коэффициент устойчивости равен 100% — 9,0% = 91,0%. Этот показатель характеризует близость фактических уровней к тренду и совершенно не зависит от характера последнего. Слабая колеблемость и высокая устойчивость уровней в данном смысле могут существовать даже при полном застое в развитии, когда тренд выражен горизонтальной прямой.
Устойчивость во втором смысле характеризует не сами по себе уровни, а процесс их направленного изменения. Можно узнать, например, насколько устойчив процесс сокращения удельных затрат ресурсов на производство единицы продукции, является ли устойчивой тенденция снижения детской смертности и т. д. С этой точки зрения полной устойчивостью направленного изменения уровней динамического ряда следует считать такое изменение, в процессе которого каждый следующий уровень либо выше всех предшествующих (устойчивый рост), либо ниже всех предшествующих (устойчивое снижение). Всякое нарушение строго ранжированной последовательности уровней свидетельствует о неполной устойчивости изменений.
Из определения понятия устойчивости тенденции вытекает и метод построения ее показателя. В качестве показателя устойчивости можно использовать коэффициент корреляции рангов Ч. Спирмэна (Spearman) — rx.
где п — число уровней;
Δi — разность рангов уровней и номеров периодов времени.
При полном совпадении рангов уровней, начиная с наименьшего, и номеров периодов (моментов) времени по их хронологическому порядку коэффициент корреляции рангов равен +1. Это значение соответствует случаю полной устойчивости возрастания уровней. При полной противоположности рангов уровней рангам лет коэффициент Спирмэна равен -1, что означает полную устойчивость процесса сокращения уровней. При хаотическом чередовании рангов уровней коэффициент близок к нулю, это означает неустойчивость какой-либо тенденции. Приведем расчет коэффициента корреляции Спирмэна по данным о динамике индекса цен (табл. 9.7) в табл. 9.8.
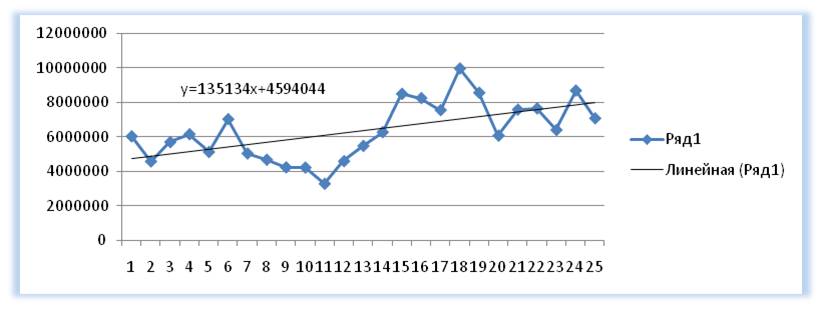 Выделяем анализируемый объём продаж и строим график, где по оси Х — наш временной ряд (1, 2, 3… — январь, февраль, март …), по оси У — объёмы продаж. Добавляем линию тренда и уравнение тренда на график. Получаем уравнение тренда y=135134x+4594044
Выделяем анализируемый объём продаж и строим график, где по оси Х — наш временной ряд (1, 2, 3… — январь, февраль, март …), по оси У — объёмы продаж. Добавляем линию тренда и уравнение тренда на график. Получаем уравнение тренда y=135134x+4594044


 – предвидение, предсказание) – предсказание будущего с помощью научных методов, а также сам результат предсказания. Прогноз – это научная модель будущего события, явлений и т.п.
– предвидение, предсказание) – предсказание будущего с помощью научных методов, а также сам результат предсказания. Прогноз – это научная модель будущего события, явлений и т.п.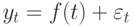 , где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем,
, где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем, 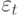 – случайная величина, характеризующая отклонение уровня от f(t ).
– случайная величина, характеризующая отклонение уровня от f(t ).
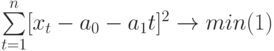
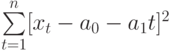 . Обозначим её через Q . Найдем производные функции Q(а0, а1) по переменным а0 и а1. Получим систему уравнений:
. Обозначим её через Q . Найдем производные функции Q(а0, а1) по переменным а0 и а1. Получим систему уравнений: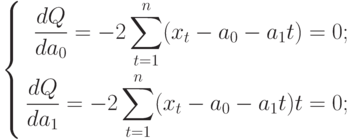
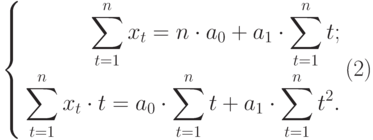
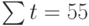
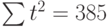
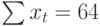
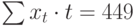
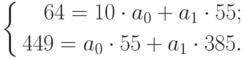




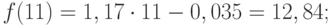
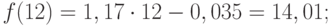
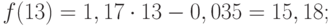
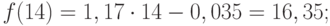
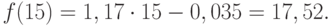

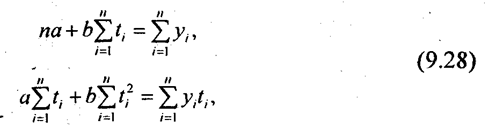



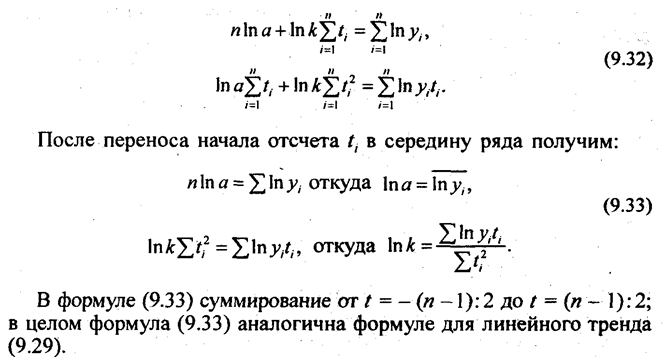
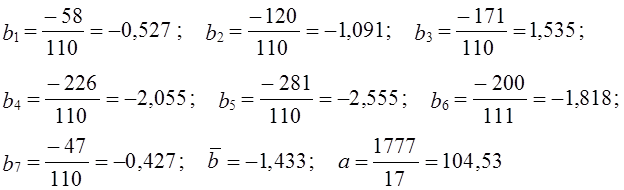
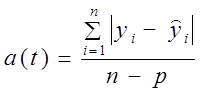 (9.34)
(9.34)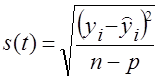 (9.35)
(9.35)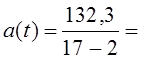 =8,82 пункта.
=8,82 пункта.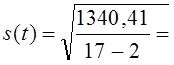 = 9,45 пункта.
= 9,45 пункта.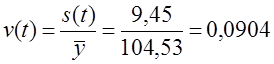 или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 — отклонение от линейного тренда:
или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 — отклонение от линейного тренда: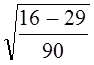 , в нашем случае
, в нашем случае 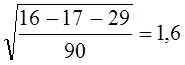 .
.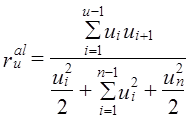 (9.36)
(9.36)