Пример нахождения статистической значимости коэффициентов регрессии
Числитель в этой формуле может быть рассчитан через коэффициент детерминации и общую дисперсию признака-результата:  .
.
Для параметра a критерий проверки гипотезы о незначимом отличии его от нуля имеет вид:
,
где — оценка параметра регрессии, полученная по наблюдаемым данным;
μa – стандартная ошибка параметра a.
Для линейного парного уравнения регрессии: .
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции в генеральной совокупности используют следующий критерий: , где ryx — оценка коэффициента корреляции, полученная по наблюдаемым данным; mr – стандартная ошибка коэффициента корреляции ryx.
Для линейного парного уравнения регрессии: .
В парной линейной регрессии между наблюдаемыми значениями критериев существует взаимосвязь: t ( b =0) = t (r=0).
Пример №1 . Уравнение имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.73 2 = 0.54, т.е. в 54% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — средняя.
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 69 | 124 | 4761 | 15376 | 8556 | 128.48 | 491.36 | 20.11 | 367.36 |
| 83 | 133 | 6889 | 17689 | 11039 | 141.4 | 173.36 | 70.56 | 26.69 |
| 92 | 146 | 8464 | 21316 | 13432 | 149.7 | 0.03 | 13.71 | 14.69 |
| 97 | 153 | 9409 | 23409 | 14841 | 154.32 | 46.69 | 1.73 | 78.03 |
| 88 | 138 | 7744 | 19044 | 12144 | 146.01 | 66.69 | 64.21 | 0.03 |
| 93 | 159 | 8649 | 25281 | 14787 | 150.63 | 164.69 | 70.13 | 23.36 |
| 74 | 145 | 5476 | 21025 | 10730 | 133.1 | 1.36 | 141.68 | 200.69 |
| 79 | 152 | 6241 | 23104 | 12008 | 137.71 | 34.03 | 204.21 | 84.03 |
| 105 | 168 | 11025 | 28224 | 17640 | 161.7 | 476.69 | 39.74 | 283.36 |
| 99 | 154 | 9801 | 23716 | 15246 | 156.16 | 61.36 | 4.67 | 117.36 |
| 85 | 127 | 7225 | 16129 | 10795 | 143.25 | 367.36 | 263.91 | 10.03 |
| 94 | 155 | 8836 | 24025 | 14570 | 151.55 | 78.03 | 11.91 | 34.03 |
| 1058 | 1754 | 94520 | 258338 | 155788 | 1754 | 1961.67 | 906.57 | 1239.67 |
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.2704
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 88,16
(128.06;163.97)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (3.41>1.812).
Статистическая значимость коэффициента регрессии b подтверждается (2.7>1.812).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.812):
(a — tтабл·S a; a + tтабл·Sa)
(0.4325;1.4126)
(b — tтабл·S b; b + tтабл·Sb)
(21.3389;108.3164)
2) F-статистики
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим.
Пример №2 . По территориям региона приводятся данные за 199Х г.;
| Среднедневная заработная плата, руб., у | ||
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х , составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение находим с помощью калькулятора.
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
12a+1027b=1869
1027a+89907b=161808
Из первого уравнения выражаем а и подставим во второе уравнение. Получаем b = 0.92, a = 76.98
Уравнение регрессии: y = 0.92 x + 76.98 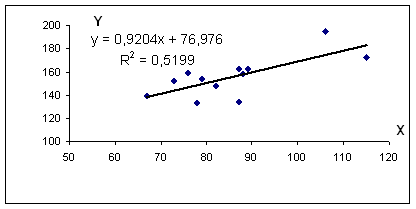
1. Параметры уравнения регрессии.
Выборочные средние.
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%, среднедневная заработная плата изменится менее чем на 1%. Другими словами — влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199, т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами — точность подбора уравнения регрессии — средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| y 2 | x·y | y(x) | (y i — y ) 2 | (y-y(x)) 2 | (x i — x ) 2 | |y-y x |:y | |||
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим tкрит:
tкрит = (10;0.05) = 1.812
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(0.9204 — 1.812·0.2797; 0.9204 + 1.812·0.2797)
(0.4136;1.4273)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a-ta)
(76.9765 — 1.812·24.2116; 76.9765 + 1.812·24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Между
 и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
 данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.- Остатки нормально распределены с нулевым средним значением;
- Остатки имеют одну и ту же вариабельность (постоянную дисперсию) для всех предсказанных величин Если нанести остатки против предсказанных величин от мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением то это допущение не выполняется;
 Если нанести остатки против предсказанных величин
Если нанести остатки против предсказанных величин  от
от  мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением
мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением  то это допущение не выполняется;
то это допущение не выполняется;Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
R — значит регрессия
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.

Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.
Введение в регрессионный анализ
Если имеется корреляционная зависимость  между переменными y и x , возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения
между переменными y и x , возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения  называется регрессией y по x .
называется регрессией y по x .
Основу регрессионного анализа составляет метод наименьших квадратов (МНК), в соответствии с которым в качестве уравнения регресии берется функция  такая, что сумма квадратов разностей
такая, что сумма квадратов разностей  минимальна.
минимальна.

Карл Гаусс открыл, или точнее воссоздал, МНК в возрасте 18 лет, однако впервые результаты были опубликованы Лежандром в 1805 г. По непроверенным данным метод был известен еще в древнем Китае, откуда он перекочевал в Японию и только затем попал в Европу. Европейцы не стали делать из этого секрета и успешно запустили в производство, обнаружив с его помощью траекторию карликовой планеты Церес в 1801 г.
Вид функции , как правило, определен заранее, а с помощью МНК подбираются оптимальные значения неизвестных параметров. Метрикой рассеяния значений  вокруг регрессии
вокруг регрессии  является дисперсия.
является дисперсия.

- k — число коэффициентов в системе уравнений регрессии.
Чаще всего используется модель линейной регрессии, а все нелинейные зависимости приводят к линейному виду с помощью алгебраических ухищрений, различных преобразования переменных y и x .
Линейная регрессия
Уравнения линейной регрессии можно записать в виде

В матричном виде это выгладит

- y — зависимая переменная;
- x — независимая переменная;
- β — коэффициенты, которые необходимо найти с помощью МНК;
- ε — погрешность, необъяснимая ошибка и отклонение от линейной зависимости;

Случайная величина может быть интерпретирована как сумма из двух слагаемых:
- — полная дисперсия (TSS).
- — объясненная часть дисперсии (ESS).
- — остаточная часть дисперсии (RSS).
 — объясненная часть дисперсии (ESS).
— объясненная часть дисперсии (ESS). — остаточная часть дисперсии (RSS).
— остаточная часть дисперсии (RSS).Еще одно ключевое понятие — коэффициент корреляции R 2 .

Ограничения линейной регрессии
Для того, чтобы использовать модель линейной регрессии необходимы некоторые допущения относительно распределения и свойств переменных.
- Линейность, собственно. Увеличение, или уменьшение вектора независимых переменных в k раз, приводит к изменению зависимой переменной также в k раз.
- Матрица коэффициентов обладает полным рангом, то есть векторы независимых переменных линейно независимы.
- Экзогенность независимых переменных — . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
- Однородность дисперсии и отсутствие автокорреляции. Каждая εi обладает одинаковой и конечной дисперсией σ 2 и не коррелирует с другой εi. Это ощутимо ограничивает применимость модели линейной регрессии, необходимо удостовериться в том, что условия соблюдены, иначе обнаруженная взаимосвязь переменных будет неверно интерпретирована.
 . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
. Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.Как обнаружить, что перечисленные выше условия не соблюдены? Ну, во первых довольно часто это видно невооруженным глазом на графике.
Неоднородность дисперсии 
При возрастании дисперсии с ростом независимой переменной имеем график в форме воронки.

Нелинейную регрессии в некоторых случая также модно увидеть на графике довольно наглядно.
Тем не менее есть и вполне строгие формальные способы определить соблюдены ли условия линейной регрессии, или нарушены.
- Автокорреляция проверяется статистикой Дарбина-Уотсона (0 ≤ d ≤ 4). Если автокорреляции нет, то значения критерия d≈2, при позитивной автокорреляции d≈0, при отрицательной — d≈4.
- Неоднородность дисперсии — Тест Уайта, , при \chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же можно еще применить тест Бройша-Пагана.
- Мультиколлинеарность — нарушения условия об отсутствии взаимной линейной зависимости между независимыми переменными. Для проверки часто используют VIF-ы (Variance Inflation Factor).
 , при
, при  \chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же
\chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же  можно еще применить тест Бройша-Пагана.
можно еще применить тест Бройша-Пагана.
В этой формуле  — коэффициент взаимной детерминации между
— коэффициент взаимной детерминации между  и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
Почему нам так важно соблюдение всех выше перечисленных условий? Все дело в Теореме Гаусса-Маркова, согласно которой оценка МНК является точной и эффективной лишь при соблюдении этих ограничений.
Как преодолеть эти ограничения
Нарушения одной или нескольких ограничений еще не приговор.
- Нелинейность регрессии может быть преодолена преобразованием переменных, например через функцию натурального логарифма ln .
- Таким же способом возможно решить проблему неоднородной дисперсии, с помощью ln , или sqrt преобразований зависимой переменной, либо же используя взвешенный МНК.
- Для устранения проблемы мультиколлинеарности применяется метод исключения переменных. Суть его в том, что высоко коррелированные объясняющие переменные устраняются из регрессии, и она заново оценивается. Критерием отбора переменных, подлежащих исключению, является коэффициент корреляции. Есть еще один способ решения данной проблемы, который заключается в замене переменных, которым присуща мультиколлинеарность, их линейной комбинацией. Этим весь список не исчерпывается, есть еще пошаговая регрессия и другие методы.
К сожалению, не все нарушения условий и дефекты линейной регрессии можно устранить с помощью натурального логарифма. Если имеет место автокорреляция возмущений к примеру, то лучше отступить на шаг назад и построить новую и лучшую модель.
Линейная регрессия плюсов на Хабре
Итак, довольно теоретического багажа и можно строить саму модель.
Мне давно было любопытно от чего зависит та самая зелененькая цифра, что указывает на рейтинг поста на Хабре. Собрав всю доступную статистику собственных постов, я решил прогнать ее через модель линейно регрессии.
Загружает данные из tsv файла.
- points — Рейтинг статьи
- reads — Число просмотров.
- comm — Число комментариев.
- faves — Добавлено в закладки.
- fb — Поделились в социальных сетях (fb + vk).
- bytes — Длина в байтах.
Вопреки моим ожиданиям наибольшая отдача не от количества просмотров статьи, а от комментариев и публикаций в социальных сетях. Я также полагал, что число просмотров и комментариев будет иметь более сильную корреляцию, однако зависимость вполне умеренная — нет надобности исключать ни одну из независимых переменных.
Теперь собственно сама модель, используем функцию lm .
В первой строке мы задаем параметры линейной регрессии. Строка points
. определяет зависимую переменную points и все остальные переменные в качестве регрессоров. Можно определить одну единственную независимую переменную через points
reads , набор переменных — points
Перейдем теперь к расшифровке полученных результатов.
- Intercept — Если у нас модель представлена в виде , то тогда — точка пересечения прямой с осью координат, или intercept .
- R-squared — Коэффициент детерминации указывает насколько тесной является связь между факторами регрессии и зависимой переменной, это соотношение объясненных сумм квадратов возмущений, к необъясненным. Чем ближе к 1, тем ярче выражена зависимость.
- Adjusted R-squared — Проблема с в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
- F-statistic — Используется для оценки значимости модели регрессии в целом, является соотношением объяснимой дисперсии, к необъяснимой. Если модель линейной регрессии построена удачно, то она объясняет значительную часть дисперсии, оставляя в знаменателе малую часть. Чем больше значение параметра — тем лучше.
- t value — Критерий, основанный на t распределении Стьюдента . Значение параметра в линейной регрессии указывает на значимость фактора, принято считать, что при t > 2 фактор является значимым для модели.
- p value — Это вероятность истинности нуль гипотезы, которая гласит, что независимые переменные не объясняют динамику зависимой переменной. Если значение p value ниже порогового уровня (.05 или .01 для самых взыскательных), то нуль гипотеза ложная. Чем ниже — тем лучше.
 , то тогда
, то тогда  — точка пересечения прямой с осью координат, или intercept .
— точка пересечения прямой с осью координат, или intercept . в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
Можно попытаться несколько улучшить модель, сглаживая нелинейные факторы: комментарии и посты в социальных сетях. Заменим значения переменных fb и comm их степенями.
Проверим значения параметров линейной регрессии.
Как видим в целом отзывчивость модели возросла, параметры подтянулись и стали более шелковистыми , F-статистика выросла, так же как и скорректированный коэффициент детерминации .
Проверим, соблюдены ли условия применимости модели линейной регрессии? Тест Дарбина-Уотсона проверяет наличие автокорреляции возмущений.
И напоследок проверка неоднородности дисперсии с помощью теста Бройша-Пагана.
В заключение
Конечно наша модель линейной регрессии рейтинга Хабра-топиков получилось не самой удачной. Нам удалось объяснить не более, чем половину вариативности данных. Факторы надо чинить, чтобы избавляться от неоднородной дисперсии, с автокорреляцией тоже непонятно. Вообще данных маловато для сколь-нибудь серьезной оценки.
Но с другой стороны, это и хорошо. Иначе любой наспех написанный тролль-пост на Хабре автоматически набирал бы высокий рейтинг, а это к счастью не так.
http://statistica.ru/theory/osnovy-lineynoy-regressii/
http://habr.com/ru/post/350668/