Уравнение регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
В сервисе для нахождения параметров регрессии используется МНК. Система нормальных уравнений для линейной регрессии: 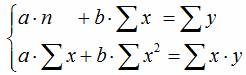 . Также можно получить ответ, используя матричный метод. см. также Статистические функции в Excel
. Также можно получить ответ, используя матричный метод. см. также Статистические функции в Excel
Уравнение парной регрессии относится к уравнению регрессии первого порядка. Если эконометрическая модель содержит только одну объясняющую переменную, то она имеет название парной регрессии. Уравнение регрессии второго порядка и уравнение регрессии третьего порядка относятся к нелинейным уравнениям регрессии.
Пример . Осуществите выбор зависимой (объясняемой) и объясняющей переменной для построения парной регрессионной модели. Дайте графическое изображение регрессионной зависимости. Определите теоретическое уравнение парной регрессии. Оцените адекватность построенной модели (интерпретируйте R-квадрат, показатели t-статистики, F-статистики).
Решение будем проводить на основе процесса эконометрического моделирования.
1-й этап (постановочный) – определение конечных целей моделирования, набора участвующих в модели факторов и показателей, их роли.
Спецификация модели — определение цели исследования и выбор экономических переменных модели.
Ситуационная (практическая) задача. По 10 предприятиям региона изучается зависимость выработки продукции на одного работника y (тыс. руб.) от удельного веса рабочих высокой квалификации в общей численности рабочих x (в %).
2-й этап (априорный) – предмодельный анализ экономической сущности изучаемого явления, формирование и формализация априорной информации и исходных допущений, в частности относящейся к природе и генезису исходных статистических данных и случайных остаточных составляющих в виде ряда гипотез.
Уже на этом этапе можно говорить о явной зависимости уровня квалификации рабочего и его выработкой, ведь чем опытней работник, тем выше его производительность. Но как эту зависимость оценить?
Парная регрессия представляет собой регрессию между двумя переменными – y и x , т. е. модель вида:
Построение эмпирического уравнения прямой регрессии.
Критерий согласия Пирсона.
Достоинствоуниверсальность: проверяет гипотезы о различных законах распределения.
1. Проверка гипотезы о нормальном распределении.
Пусть получена выборка объема, разделим интервал на s равных частей и будем считать, что значения вариант, попавших в каждый интервал, приближенно равны числу, задающему середину интервала. Подсчитав число вариант, попавших в каждый интервал, составим сгруппированную выборку: х1 х2 … хs; n1 n2 … ns , где хi – значения середин интервалов, а ni – число вариант, попавших в i-й интервал (эмпи-рические частоты). По полученным данным вычисляем  и σВ. Проверим что ген. совокупность распределена по норм. закону с параметрами M(X) =
и σВ. Проверим что ген. совокупность распределена по норм. закону с параметрами M(X) =  , D(X) =
, D(X) =  . можно найти количество чисел из n, которое должно оказаться в каждом интервале при этом предположении. по табл значений функции Лапласа найдем вер. попадания в i-й интервал:
. можно найти количество чисел из n, которое должно оказаться в каждом интервале при этом предположении. по табл значений функции Лапласа найдем вер. попадания в i-й интервал:  ,где аi и bi — границы i-го интервала. Умножив полученные вероятности на n, найдем теоретические частоты: ni=n·pi. цель – сравнить эмпир и теоретич частоты, которые, отличаются друг от друга, и выяснить, являются ли эти различия несущественными, не опровергающими гипотезу о нормальном распределении исследуемой случайной величины, или они противоречат этой гипотезе. Для этого используется критерий в виде случайной величины
,где аi и bi — границы i-го интервала. Умножив полученные вероятности на n, найдем теоретические частоты: ni=n·pi. цель – сравнить эмпир и теоретич частоты, которые, отличаются друг от друга, и выяснить, являются ли эти различия несущественными, не опровергающими гипотезу о нормальном распределении исследуемой случайной величины, или они противоречат этой гипотезе. Для этого используется критерий в виде случайной величины  (1) для проверки нулевой гипотезы Н0: генеральная совокупность распределена нормально – нужно вычислить по выборке наблюдаемое значение критерия:
(1) для проверки нулевой гипотезы Н0: генеральная совокупность распределена нормально – нужно вычислить по выборке наблюдаемое значение критерия:  , а по таблице критических точек распределения χ 2 найти критическую точку
, а по таблице критических точек распределения χ 2 найти критическую точку  , используя известные значения α и k=s–3. Если
, используя известные значения α и k=s–3. Если  — Н0 принимают, при
— Н0 принимают, при  ее отвергают.
ее отвергают.
Проверка гипотезы о равномерном распределении.
При использовании критерия Пирсона для проверки гипотезы о равномерном распределении генеральной совокупности с предполагаемой плотностью вероятности
 (2)необходимо, вычислив по имеющейся выборке значение
(2)необходимо, вычислив по имеющейся выборке значение  , оценить параметры а и b по формулам:
, оценить параметры а и b по формулам:
 , где а* и b* — оценки а и b. для равномерного распределения М(Х) =
, где а* и b* — оценки а и b. для равномерного распределения М(Х) =  ,
,  , откуда можно получить систему для определения а* и b*:
, откуда можно получить систему для определения а* и b*:  , решением которой являются выражения (2). Предполагая, что
, решением которой являются выражения (2). Предполагая, что  , можно найти теоретические частоты по формулам
, можно найти теоретические частоты по формулам 

 Здесь s – число интервалов, на которые разбита выборка.
Здесь s – число интервалов, на которые разбита выборка.
Наблюдаемое значение крит П. вычисл по форм (1), а критическое – по таблице с учетом числа степеней свободы k=s–3. границы критической области определяются, как и для проверки гипотезы о нормальном распределении.
3. Проверка гипотезы о показательном распределении. разбив выборку на интервалы, рассмотрим последовательность вариант  , равноотстоящих друг от друга (считаем, что все варианты, попавшие в i – й интервал, принимают значение, совпадающее с его серединой), и соответствующих им частот ni (число вариант выборки, попавших в i – й интервал). Вычислим по этим данным и примем в качестве оценки параметра λ величину
, равноотстоящих друг от друга (считаем, что все варианты, попавшие в i – й интервал, принимают значение, совпадающее с его серединой), и соответствующих им частот ni (число вариант выборки, попавших в i – й интервал). Вычислим по этим данным и примем в качестве оценки параметра λ величину  . Тогда теоретические частоты вычисляются по формуле
. Тогда теоретические частоты вычисляются по формуле

сравниваются наблюдаемое и критическое значение крит П с учетом число степеней свободы k=s–2.
Критерий Колмогорова
применяется для проверки простой гипотезы Н0 независимые одинаково распределенные случайные величины Х1, Х2, …, Хп имеют заданную непрерывную функцию распределения F(x). Найдем функцию эмпирического распределения Fn(x) и будем искать границы двусторонней критической области, определяемой условием  (1). Он доказал, что в случае справедливости гипотезы Н0 распределение статистики Dn не зависит от функции F(x), и при
(1). Он доказал, что в случае справедливости гипотезы Н0 распределение статистики Dn не зависит от функции F(x), и при 
 где
где  — (2)- критерий Колмогорова, значения можно найти в соответствующих таблицах. Критическое значение критерия λп(α) вычисляется по заданному уровню значимости α как корень уравнения
— (2)- критерий Колмогорова, значения можно найти в соответствующих таблицах. Критическое значение критерия λп(α) вычисляется по заданному уровню значимости α как корень уравнения  . Можно показать, что приближенное значение вычисляется по формуле
. Можно показать, что приближенное значение вычисляется по формуле  , где z – корень уравнения
, где z – корень уравнения  . На практике для вычисления значения статистики Dn используется то, что
. На практике для вычисления значения статистики Dn используется то, что  , где
, где  а
а  — вариационный ряд, построенный по выборке Х1, Х2, …, Хп. Можно дать следующее геометрическое истолкование критерия Колмогорова: если изобразить на плоскости Оху графики функций Fn(x), Fn(x) ±λn(α) (рис. 1), то гипотеза Н0 верна, если график функции F(x) не выходит за пределы области, лежащей между графиками функций Fn(x) -λn(α) и Fn(x) +λn(α). х Приближенный метод проверки нормальности распределения, связанный с оценками коэффициентов асимметрии и эксцесса. Определим по аналогии с соответствующими понятиями для теоретического распределения асимметрию и эксцесс эмпирического распределения. Определение асимметрия эмпирического распределения определяется
— вариационный ряд, построенный по выборке Х1, Х2, …, Хп. Можно дать следующее геометрическое истолкование критерия Колмогорова: если изобразить на плоскости Оху графики функций Fn(x), Fn(x) ±λn(α) (рис. 1), то гипотеза Н0 верна, если график функции F(x) не выходит за пределы области, лежащей между графиками функций Fn(x) -λn(α) и Fn(x) +λn(α). х Приближенный метод проверки нормальности распределения, связанный с оценками коэффициентов асимметрии и эксцесса. Определим по аналогии с соответствующими понятиями для теоретического распределения асимметрию и эксцесс эмпирического распределения. Определение асимметрия эмпирического распределения определяется  , (3) где m3 – центральный эмпирический момент третьего порядка. Эксцесс эмпирического распределения определяется
, (3) где m3 – центральный эмпирический момент третьего порядка. Эксцесс эмпирического распределения определяется  , (4) где m4 – центральный эмпирический момент четвертого порядка. Для нормально распределенной случайной величины асимметрия и эксцесс=0. Поэтому, если соответствующие эмпирические величины достаточно малы, можно предположить, что ген совокупность распределена по нормальному закону.
, (4) где m4 – центральный эмпирический момент четвертого порядка. Для нормально распределенной случайной величины асимметрия и эксцесс=0. Поэтому, если соответствующие эмпирические величины достаточно малы, можно предположить, что ген совокупность распределена по нормальному закону.
45. Основные понятия корреляционного и регрессионного анализа. Для выявления наличия связи, ее характера и направления используются методы приведения параллельных данных, аналитических группировок, графический, корреляции и регрессии.
Метод проведения параллельных данных основан на сопоставлении двух или нескольких рядов статистических величин. Данное сопоставление позоляет установить наличие связи и получить представление о ее характере.
Графический метод
Графическая взаимосвязь двух признаков изображается с помощью поля корреляции.
Корреляция – это статистическая зависимость между случайными величинами, не имеющими строго функционального характера, при которой изменение одной из случайных величин приводит к изменению математического ожидания другой.
1) парная корреляция – связь между двумя признаками (между двумя факторными либо между факторным и результативным признаком)
2) частная корреляция – зависимость между результативным и одним факторным признаком при фиксированном значении других факторных признаков
3) множественная корреляция – зависимость результативного и двух и более факторных признаков.
Корреляционный анализ имеет своей задачей количественное определение тесноты связи между двумя признаками.
Теснота связи количественно выражается величиной коэффициентов корреляции.
Теснота связи при линейной зависимости измеряется с помощью линейного коэффициента корреляции:

Теснота связи при криволинейной зависимости измеряется с помощью корреляционного отношения. Различают эмпирическое и теоретическое корреляционное отношение.
Регрессионный анализ заключается в определении аналитического выражения связи, в котором изменение одной величины обусловлено влиянием одной или нескольких независимых величин (факторов).
По направлению связи различают:
А) прямую регрессию (положительную), возникающую при условии, если с увеличением или уменьшением независимой величины значения зависимой также соответственно увеличиваются или уменьшаются;
Б) обратную (отрицательную) регрессию, появляющуюся при условии, что с увеличением или уменьшением независимой величины зависимая соответственно уменьшается или увеличивается.
Построение эмпирического уравнения прямой регрессии.
Часто приходится рассматривать такие системы (Х, Y), для которых обе линии регрессии представляют собой прямые. Тогда говорят о линейной корреляции между Х и Y. В этом случае уравнения прямых регрессии имеют следующий вид:
 , (1)
, (1)  . (2) Уравнение (1) определяет уравнение прямой регрессии Y на Х, а уравнение (2) – прямой регрессии X на Y. Здесь r = r[X,Y] – коэффициент корреляции между Х и Y. При r = ±1 обе прямые сливаются в одну – ту самую прямую у = ах + b, на которой лежат все точки (Х,Y). Предположим, что между случайными величинами Х и Y имеет место линейная корреляция. Возникает задача о приближенном построении прямых регрессий по данным наблюдений над системой (Х, Y). Подход к решению этой задачи указывают сами формулы (1) и (2). Если входящие в них параметры mX, mY, σX, σY, r
. (2) Уравнение (1) определяет уравнение прямой регрессии Y на Х, а уравнение (2) – прямой регрессии X на Y. Здесь r = r[X,Y] – коэффициент корреляции между Х и Y. При r = ±1 обе прямые сливаются в одну – ту самую прямую у = ах + b, на которой лежат все точки (Х,Y). Предположим, что между случайными величинами Х и Y имеет место линейная корреляция. Возникает задача о приближенном построении прямых регрессий по данным наблюдений над системой (Х, Y). Подход к решению этой задачи указывают сами формулы (1) и (2). Если входящие в них параметры mX, mY, σX, σY, r
заменить их эмпирическими оценками, то получим  , и две прямые
, и две прямые  ; (1*)
; (1*)  , (2*)
, (2*)
которые естественно рассматривать как эмпирические прямые регрессии. Для нахождения эмпирических прямых регрессий нужно располагать пятью оценками . Они находятся по данным наблюдений над системой (Х,Y). Если в результате n независимых наблюдений получены точки (х1, у1), (х2, у2), …, (хn, yn), то требуемые оценки вычисляем по формулам:

 ;
;  , где
, где  . Эмпирические прямые регрессии по смыслу служат для «выравнивания» приблизительно линейной вероятностной зависимости. Мы записали уравнения этих прямых, руководствуясь аналогией с уравнениями «теоретических» прямых регрессий (1) и (2). Можно, однако, привести более глубокие соображения, обосновывающие роль эмпирических прямых (1*) и (2*). Эти соображения связаны с так называемым методом наименьших квадратов
. Эмпирические прямые регрессии по смыслу служат для «выравнивания» приблизительно линейной вероятностной зависимости. Мы записали уравнения этих прямых, руководствуясь аналогией с уравнениями «теоретических» прямых регрессий (1) и (2). Можно, однако, привести более глубокие соображения, обосновывающие роль эмпирических прямых (1*) и (2*). Эти соображения связаны с так называемым методом наименьших квадратов
Регрессионный анализ в Microsoft Excel

Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Подключение пакета анализа
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.
- Перемещаемся во вкладку «Файл».


Открывается окно параметров Excel. Переходим в подраздел «Надстройки».

В самой нижней части открывшегося окна переставляем переключатель в блоке «Управление» в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «Перейти».


Теперь, когда мы перейдем во вкладку «Данные», на ленте в блоке инструментов «Анализ» мы увидим новую кнопку – «Анализ данных».

Виды регрессионного анализа
Существует несколько видов регрессий:
- параболическая;
- степенная;
- логарифмическая;
- экспоненциальная;
- показательная;
- гиперболическая;
- линейная регрессия.
О выполнении последнего вида регрессионного анализа в Экселе мы подробнее поговорим далее.
Линейная регрессия в программе Excel
Внизу, в качестве примера, представлена таблица, в которой указана среднесуточная температура воздуха на улице, и количество покупателей магазина за соответствующий рабочий день. Давайте выясним при помощи регрессионного анализа, как именно погодные условия в виде температуры воздуха могут повлиять на посещаемость торгового заведения.
Общее уравнение регрессии линейного вида выглядит следующим образом: У = а0 + а1х1 +…+акхк . В этой формуле Y означает переменную, влияние факторов на которую мы пытаемся изучить. В нашем случае, это количество покупателей. Значение x – это различные факторы, влияющие на переменную. Параметры a являются коэффициентами регрессии. То есть, именно они определяют значимость того или иного фактора. Индекс k обозначает общее количество этих самых факторов.
- Кликаем по кнопке «Анализ данных». Она размещена во вкладке «Главная» в блоке инструментов «Анализ».

Открывается небольшое окошко. В нём выбираем пункт «Регрессия». Жмем на кнопку «OK».

Открывается окно настроек регрессии. В нём обязательными для заполнения полями являются «Входной интервал Y» и «Входной интервал X». Все остальные настройки можно оставить по умолчанию.
В поле «Входной интервал Y» указываем адрес диапазона ячеек, где расположены переменные данные, влияние факторов на которые мы пытаемся установить. В нашем случае это будут ячейки столбца «Количество покупателей». Адрес можно вписать вручную с клавиатуры, а можно, просто выделить требуемый столбец. Последний вариант намного проще и удобнее.
В поле «Входной интервал X» вводим адрес диапазона ячеек, где находятся данные того фактора, влияние которого на переменную мы хотим установить. Как говорилось выше, нам нужно установить влияние температуры на количество покупателей магазина, а поэтому вводим адрес ячеек в столбце «Температура». Это можно сделать теми же способами, что и в поле «Количество покупателей».

С помощью других настроек можно установить метки, уровень надёжности, константу-ноль, отобразить график нормальной вероятности, и выполнить другие действия. Но, в большинстве случаев, эти настройки изменять не нужно. Единственное на что следует обратить внимание, так это на параметры вывода. По умолчанию вывод результатов анализа осуществляется на другом листе, но переставив переключатель, вы можете установить вывод в указанном диапазоне на том же листе, где расположена таблица с исходными данными, или в отдельной книге, то есть в новом файле.

После того, как все настройки установлены, жмем на кнопку «OK».

Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Помимо этой статьи, на сайте еще 12698 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
http://poisk-ru.ru/s5978t9.html
http://lumpics.ru/regression-analysis-in-excel/