Показатели точности уравнения регрессии и оценок его параметров
При анализе уравнения регрессии сначала проверяется значимость уравнения регрессии в целом. Для решения этой задачи используется процедура дисперсионного анализа, основанная на разложении общей суммы квадратов отклонений зависимой переменной (SST – Sum. Squared total) на две составляющие: одна из которых – за счёт регрессионной зависимости (SSM – Sum. Squared model), другая – за счёт остаточного члена (SSR – Sum. Squared residual):

Следует иметь в виду, что это соотношение верно, если в уравнении регрессии присутствует константа. Разделив суммы квадратов отклонений на соответствующие числа степеней свободы, получим суммы квадратов на одну степень свободы или средние квадраты, которые являются оценками дисперсии  зависимой переменной y или остатков
зависимой переменной y или остатков  в условиях разных предпосылок. Одна из этих оценок (MSM = SSM/m) рассчитывается в предположении, что все коэффициенты в модели регрессии равны нулю (Ho:
в условиях разных предпосылок. Одна из этих оценок (MSM = SSM/m) рассчитывается в предположении, что все коэффициенты в модели регрессии равны нулю (Ho:  =
=  =…=
=…=  =0), а другая (MSR = SSR/(n–m–1)) – в предположении, что не все коэффициенты регрессии равны нулю. Затем эти оценки сравниваются по F-статистике (F =
=0), а другая (MSR = SSR/(n–m–1)) – в предположении, что не все коэффициенты регрессии равны нулю. Затем эти оценки сравниваются по F-статистике (F =  ), которая в случае выполнимости предпосылок МНК и верности нулевой гипотезы имеет распределение Фишера с числом степеней свободы числителя, равным m и знаменателя – (n – m – 1). Расчётное значение F-статистики сравнивается с критическим и если F
), которая в случае выполнимости предпосылок МНК и верности нулевой гипотезы имеет распределение Фишера с числом степеней свободы числителя, равным m и знаменателя – (n – m – 1). Расчётное значение F-статистики сравнивается с критическим и если F  , то нулевая гипотеза отклоняется, и уравнение регрессии признаётся значимым.
, то нулевая гипотеза отклоняется, и уравнение регрессии признаётся значимым.
Вернёмся ещё раз к MSR. Этот показатель является одной из характеристик точности уравнения регрессии. Его называют остаточной дисперсией и обозначают S  . Можно показать, что MSR является несмещённой оценкой дисперсии .
. Можно показать, что MSR является несмещённой оценкой дисперсии .
MSR также используется при вычислении других показателей точности уравнения регрессии. Например, корень квадратный из MSR называется стандартной ошибкой оценки по регрессии(Sy,x) и показывает, какую ошибку в среднем мы будем допускать, если значение зависимой переменной будем оценивать по найденному уравнению регрессии при известных значениях независимых переменных. Имеем
Sy,x = 
Кроме того, этот показатель в неявном виде участвует в определении ещё одного показателя точности уравнения множественной регрессии, а именно – коэффициента множественной детерминации (R–squared или R 2 ). Как известно,

или после преобразований (в случае, если в уравнении регрессии присутствует константа)

Отсюда следует, что коэффициент множественной детерминации показывает долю вариации зависимой переменной, обусловленную вариацией включённых в уравнение регрессии независимых переменных, или, иными словами, долю вариации зависимой переменной, обусловленную регрессионной зависимостью.
Коэффициент множественной детерминации изменяется от нуля до единицы и равен единице, если SSR = 0, (связь линейная, функциональная), и равен нулю, если SST = SSR, (линейная связь отсутствует).
Из определения коэффициента множественной детерминации следует, что он будет увеличиваться при добавлении в уравнение регрессии независимых переменных, как бы слабо не были они связаны с независимой переменной. Следуя этой логике, в уравнение регрессии для увеличения точности отражения изучаемой зависимости может быть включено неоправданно много независимых переменных. Точность уравнения при этом может увеличиться незначительно, а размерность модели возрасти так, что её анализ будет затруднён. Кроме того, при этом уменьшается число степеней свободы модели и ухудшается точность оценок. Для преодоления этого недостатка был разработан исправленный (на число степеней свободы) коэффициент (Adjusted R-squared), имеющий вид

или после преобразования
 .
.
В отличие от  ,
, 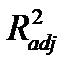 будет убывать, если в уравнение регрессии будут добавляться незначимые независимые переменные (с t-статистикой
будет убывать, если в уравнение регрессии будут добавляться незначимые независимые переменные (с t-статистикой
Такая проверка осуществляется на основе t-статистик, определяемых из соотношений
 , k = 0,1,2,…,m,
, k = 0,1,2,…,m,
где  – выборочные стандартные ошибки соответствующих оценок.
– выборочные стандартные ошибки соответствующих оценок.
 = MSR [(X T X) -1 ] kk , (k = 0,1,…,m). (2.5)
= MSR [(X T X) -1 ] kk , (k = 0,1,…,m). (2.5)
Здесь [(X T X) -1 ]kk – соответствующие диагональные элементы матрицы (X T X) -1 .
При компьютерных расчётах вместе с t-статистикой (t-Statistic) для каждой оценки параметров уравнения регрессии вычисляется выборочный уровень значимости или Prob – это вероятность того, что вычисленное значение t-статистики не превосходит критического значения. По его значению и определяется значимость каждой оценки параметров уравнения регрессии.
Оценка точности уравнения регрессии
Как уже отмечалось, оценки параметров уравнения регрессии
вычисляются по выборочным данным и лишь приближённо равны этим параметрам. В связи с этим появляется необходимость оценить точность как уравнения регрессии в целом, так и его параметров в отдельности. При решении первой задачи используют процедуру дисперсионного анализа, основанную на разложении общей суммы квадратов отклонений зависимой переменной:  на две составляющие, источниками которых являются отклонения за счёт регрессионной зависимости (SSR) и за счёт случайных ошибок (SSE), причём
на две составляющие, источниками которых являются отклонения за счёт регрессионной зависимости (SSR) и за счёт случайных ошибок (SSE), причём
 Из теории статистики известно, что SST = SSR + SSE или
Из теории статистики известно, что SST = SSR + SSE или

Аналогичное разложение имеет место и для числа степеней свободы соответствующих сумм:
где dfT = n – 1 – общее число степеней свободы;
dfR = m – число степеней свободы, соответствующее регрессии (m – число независимых переменных в уравнении регрессии);
dfE = n – m – 1 – число степеней свободы, соответствующее ошибкам.
Разделив соответствующие суммы квадратов на степени свободы, получим средние квадраты или дисперсии, которые сравниваются по критерию Фишера для проверки гипотезы о равенстве нулю одновременно всех коэффициентов регрессии против альтернативной: не все коэффициенты регрессии равны нулю. Если нулевая гипотеза отклоняется, то это означает, что уравнение регрессии значимо, в противном случае оно ничего не отражает и не может быть использовано в анализе.
Итак, процедура дисперсионного анализа регрессии состоит в следующем:
рассчитываются суммы квадратов SSR и SSE;
определяются средние квадраты или дисперсии, соответствующие регрессии и ошибкам: MSR = SSR / m и MSE = SSE / n – m – 1;
сравниваются полученные дисперсии на основе критерия Фишера, причём MSR ³ MSE, следовательно  если F
если F  /2,m,n—m-1 > F, то уравнение регрессии значимо (не все коэффициенты уравнения регрессии равны нулю), в противном случае – не значимо.
/2,m,n—m-1 > F, то уравнение регрессии значимо (не все коэффициенты уравнения регрессии равны нулю), в противном случае – не значимо.
Дисперсионный анализ регрессии удобно проводить в таблице вида:
Таблица 9.1 – Таблица дисперсионного анализа регрессии
| Источник | Сумма квадратов | Степени свободы | Средние квадраты | F-отношение |
| Модель ошибки | SSR SSE | m n – m – 1 | MSR MSE | F= 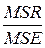 |
| Общая | SST | n – 1 |
Вернёмся к MSE. Это тоже характеристика точности уравнения регрессии. Этот показатель особого самостоятельного значения не имеет, но участвует в вычислении других показателях точности. Например, корень квадратный из MSE называется стандартной ошибкой оценки по регрессии (Sy,x) и показывает, какую ошибку в среднем получим, если значение зависимой переменной оценивать по уравнению регрессии:

Кроме того, этот показатель в неявном виде участвует в определении коэффициента множественной детерминации (R 2 ):

или после преобразований:
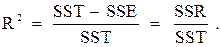
Отсюда следует, что коэффициент множественной детерминации отражает долю вариации изучаемого (результирующего) показателя, обусловленную вариацией за счёт регрессионной зависимости. Коэффициент множественной детерминации иногда выражают в процентах, поэтому, например, если R 2 = 75%, то это означает, что изменение зависимой переменной на 75% объясняется изменением включённых в уравнение регрессии независимых переменных, а остальные 25% – это изменения за счёт неучтённых факторов и случайных отклонений (ошибок).
Корень квадратный из коэффициента множественной детерминации называется коэффициентом множественной корреляции:

который показывает тесноту линейной корреляционной связи между зависимой переменной и всеми независимыми переменными.
Ясно что, R 2 и R изменяются от нуля до единицы и равны единице, если SSE = 0, т.е. связь линейная функциональная и равны нулю, если SST = SSE, т.е. связь отсутствует.
Значимость коэффициента множественной детерминации определяется на основе критерия Фишера:

с m числом степеней свободы числителя и n – m – 1 – знаменателя.
В социально-экономических исследованиях встречается преобразованная формула определения R 2 , имеющая вид:

или в других обозначениях:
 ,
,
где Sy,x 2 – выборочная остаточная дисперсия независимого показателя;
Sy 2 – его общая выборочная дисперсия.
Как уже отмечалось,  – стандартная ошибка оценки по регрессии.
– стандартная ошибка оценки по регрессии.
Из определения коэффициента множественной детерминации следует, что он будет увеличиваться при добавлении в уравнение регрессии независимых переменных, как бы слабо ни были они связаны с независимой переменной. Следуя этой логике, для увеличения точности отражения изучаемой зависимости в уравнение регрессии может быть включено неоправдано много независимых переменных. Точность модели при этом увеличится незначимо, а размерность модели возрастёт так, что её анализ будет затруднён. Кроме того, качество оценок при этом ухудшается. Для исключения такого недостатка рассматривают исправленный (на число степеней свободы) коэффициент множественной детерминации:

Этот коэффициент позволяет избежать переоценки независимой переменной при включении её в уравнение регрессии. Если добавление переменной приводит к увеличению 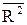 , то включение её в уравнение регрессии оправдано, в противном случае – нет. Исправленный коэффициент детерминации всегда меньше неисправленного и является несмещённой оценкой для коэффициента множественной детерминации, в то время как неисправленный – завышенный, смещённой оценкой.
, то включение её в уравнение регрессии оправдано, в противном случае – нет. Исправленный коэффициент детерминации всегда меньше неисправленного и является несмещённой оценкой для коэффициента множественной детерминации, в то время как неисправленный – завышенный, смещённой оценкой.
Продолжим анализ точности уравнения регрессии. Как уже отмечалось, при проверке значимости уравнения регрессии проверяется гипотеза о том, что все коэффициенты уравнения регрессии равны нулю, против альтернативной – не все коэффициенты регрессии равны нулю. В последнем случае, т.е. если нулевая гипотеза отклонена, встаёт вопрос: какие из коэффициентов равны нулю, а какие значимо отличны от нуля?
Корреляция и регрессия
Линейное уравнение регрессии имеет вид y=bx+a+ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид:
10a + 356b = 49
356a + 2135b = 9485
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 68.16, a = 11.17
Уравнение регрессии:
y = 68.16 x — 11.17
1. Параметры уравнения регрессии.
Выборочные средние.
1.1. Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 Y фактором X весьма высокая и прямая.
1.2. Уравнение регрессии (оценка уравнения регрессии).
Линейное уравнение регрессии имеет вид y = 68.16 x -11.17
Коэффициентам уравнения линейной регрессии можно придать экономический смысл. Коэффициент уравнения регрессии показывает, на сколько ед. изменится результат при изменении фактора на 1 ед.
Коэффициент b = 68.16 показывает среднее изменение результативного показателя (в единицах измерения у ) с повышением или понижением величины фактора х на единицу его измерения. В данном примере с увеличением на 1 единицу y повышается в среднем на 68.16.
Коэффициент a = -11.17 формально показывает прогнозируемый уровень у , но только в том случае, если х=0 находится близко с выборочными значениями.
Но если х=0 находится далеко от выборочных значений x , то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие значения x , можно определить выровненные (предсказанные) значения результативного показателя y(x) для каждого наблюдения.
Связь между у и x определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
1.3. Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
В нашем примере коэффициент эластичности больше 1. Следовательно, при изменении Х на 1%, Y изменится более чем на 1%. Другими словами — Х существенно влияет на Y.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению среднего Y на 0.9796 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве регрессии.
1.6. Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.98 2 = 0.9596, т.е. в 95.96 % случаев изменения x приводят к изменению у . Другими словами — точность подбора уравнения регрессии — высокая. Остальные 4.04 % изменения Y объясняются факторами, не учтенными в модели.
| x | y | x 2 | y 2 | x·y | y(x) | (yi— y ) 2 | (y-y(x)) 2 | (xi— x ) 2 | |y — yx|:y |
| 0.371 | 15.6 | 0.1376 | 243.36 | 5.79 | 14.11 | 780.89 | 2.21 | 0.1864 | 0.0953 |
| 0.399 | 19.9 | 0.1592 | 396.01 | 7.94 | 16.02 | 559.06 | 15.04 | 0.163 | 0.1949 |
| 0.502 | 22.7 | 0.252 | 515.29 | 11.4 | 23.04 | 434.49 | 0.1176 | 0.0905 | 0.0151 |
| 0.572 | 34.2 | 0.3272 | 1169.64 | 19.56 | 27.81 | 87.32 | 40.78 | 0.0533 | 0.1867 |
| 0.607 | 44.5 | .3684 | 1980.25 | 27.01 | 30.2 | 0.9131 | 204.49 | 0.0383 | 0.3214 |
| 0.655 | 26.8 | 0.429 | 718.24 | 17.55 | 33.47 | 280.38 | 44.51 | 0.0218 | 0.2489 |
| 0.763 | 35.7 | 0.5822 | 1274.49 | 27.24 | 40.83 | 61.54 | 26.35 | 0.0016 | 0.1438 |
| 0.873 | 30.6 | 0.7621 | 936.36 | 26.71 | 48.33 | 167.56 | 314.39 | 0.0049 | 0.5794 |
| 2.48 | 161.9 | 6.17 | 26211.61 | 402 | 158.07 | 14008.04 | 14.66 | 2.82 | 0.0236 |
| 7.23 | 391.9 | 9.18 | 33445.25 | 545.2 | 391.9 | 16380.18 | 662.54 | 3.38 | 1.81 |
2. Оценка параметров уравнения регрессии.
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=7 находим tкрит:
tкрит = (7;0.05) = 1.895
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 94.6484 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
Sy = 9.7287 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя. (a + bxp ± ε) где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 1 (-11.17 + 68.16*1 ± 6.4554)
(50.53;63.44)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
Индивидуальные доверительные интервалы для Y при данном значении X.
(a + bx i ± ε)
где
| xi | y = -11.17 + 68.16xi | εi | ymin | ymax |
| 0.371 | 14.11 | 19.91 | -5.8 | 34.02 |
| 0.399 | 16.02 | 19.85 | -3.83 | 35.87 |
| 0.502 | 23.04 | 19.67 | 3.38 | 42.71 |
| 0.572 | 27.81 | 19.57 | 8.24 | 47.38 |
| 0.607 | 30.2 | 19.53 | 10.67 | 49.73 |
| 0.655 | 33.47 | 19.49 | 13.98 | 52.96 |
| 0.763 | 40.83 | 19.44 | 21.4 | 60.27 |
| 0.873 | 48.33 | 19.45 | 28.88 | 67.78 |
| 2.48 | 158.07 | 25.72 | 132.36 | 183.79 |
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (7;0.05) = 1.895
Поскольку 12.8866 > 1.895, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 2.0914 > 1.895, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(68.1618 — 1.895 • 5.2894; 68.1618 + 1.895 • 5.2894)
(58.1385;78.1852)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a — ta)
(-11.1744 — 1.895 • 5.3429; -11.1744 + 1.895 • 5.3429)
(-21.2992;-1.0496)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с lang=EN-US>n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=7, Fkp = 5.59
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Проверка на наличие автокорреляции остатков.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция) определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция, нежели отрицательная автокорреляция. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения ei с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения ei (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скоре всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости ei от ei-1.
http://mydocx.ru/8-21231.html
http://math.semestr.ru/corel/primer.php