Показатели качества регрессии
Качество модели регрессии связывают с адекватностью модели наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным проводится на основе анализа остатков —  .
.
Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов. Согласно общим предположениям регрессионного анализа, остатки должны вести себя как независимые (в действительности, почти независимые) одинаково распределенные случайные величины.
Качество модели регрессии оценивается по следующим направлениям:
проверка качества всего уравнения регрессии;
проверка значимости всего уравнения регрессии;
проверка статистической значимости коэффициентов уравнения регрессии;
проверка выполнения предпосылок МНК.
При анализе качества модели регрессии, в первую очередь, используется коэффициент детерминации, который определяется следующим образом:

где 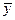 — среднее значение зависимой переменной,
— среднее значение зависимой переменной,
 — предсказанное (расчетное) значение зависимой переменной.
— предсказанное (расчетное) значение зависимой переменной.
Коэффициент детерминации показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, т. е. определяет, какая доля вариации признака Y учтена в модели и обусловлена влиянием на него факторов.
Чем ближе 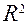 к 1, тем выше качество модели.
к 1, тем выше качество модели.
Для оценки качества регрессионных моделей целесообразно также использовать коэффициент множественной корреляции (индекс корреляции) R
R =  =
= 
Данный коэффициент является универсальным, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных.
Важным моментом является проверка значимости построенного уравнения в целом и отдельных параметров.
Оценить значимость уравнения регрессии – это означает установить, соответствует ли математическая модель, выражающая зависимость между Y и Х, фактическим данным и достаточно ли включенных в уравнение объясняющих переменных Х для описания зависимой переменной Y
Оценка значимости уравнения регрессии производится для того, чтобы узнать, пригодно уравнение регрессии для практического использования (например, для прогноза) или нет.
Для проверки значимости модели регрессии используется F-критерий Фишера. Если расчетное значение с n1= k и n2 = (n — k — 1) степенями свободы, где k – количество факторов, включенных в модель, больше табличного при заданном уровне значимости, то модель считается значимой.

В качестве меры точности применяют несмещенную оценку дисперсии остаточной компоненты, которая представляет собой отношение суммы квадратов уровней остаточной компоненты к величине (n- k -1), где k – количество факторов, включенных в модель. Квадратный корень из этой величины (  ) называется стандартной ошибкой:
) называется стандартной ошибкой:
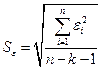
значимость отдельных коэффициентов регрессии проверяется по t-статистике путем проверки гипотезы о равенстве нулю j-го параметра уравнения (кроме свободного члена):
 ,
,
где Saj — это стандартное (среднеквадратическое) отклонение коэффициента уравнения регрессии aj. Величина Saj представляет собой квадратный корень из произведения несмещенной оценки дисперсии  и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.
и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.

где  — диагональный элемент матрицы
— диагональный элемент матрицы 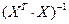 .
.
Если расчетное значение t-критерия с (n — k — 1) степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
Проверка выполнения предпосылок МНК.
Рассмотрим выполнение предпосылки гомоскедастичности, или равноизменчивости случайной составляющей (возмущения).
Невыполнение этой предпосылки, т.е. нарушение условия гомоскедастичности возмущений означает, что дисперсия возмущения зависит от значений факторов. Такие регрессионные модели называются моделями с гетероскедастичностью возмущений.
Обнаружение гетероскедастичности. Для обнаружения гетероскедастичности обычно используют тесты, в которых делаются различные предположения о зависимости между дисперсией случайного члена и объясняющей переменной: тест ранговой корреляции Спирмена, тест Голдфельда — Квандта, тест Глейзера, двусторонний критерий Фишера и другие [2].
При малом объеме выборки для оценки гетероскедастичности может использоваться метод Голдфельда — Квандта. Данный тест используется для проверки такого типа гетероскедастичности, когда дисперсия остатков возрастает пропорционально квадрату фактора. При этом делается предположение, что, случайная составляющая 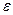 распределена нормально.
распределена нормально.
Чтобы оценить нарушение гомоскедастичности по тесту Голдфельда — Квандта необходимо выполнить следующие шаги.
Упорядочение п наблюдений по мере возрастания переменной х.
Исключение 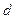 средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
Разделение совокупности на две группы (соответственно с малыми и большими значениями фактора  ) и определение по каждой из групп уравнений регрессии.
) и определение по каждой из групп уравнений регрессии.
Определение остаточной суммы квадратов для первой регрессии  и второй регрессии
и второй регрессии  .
.
Вычисление отношений  (или
(или 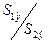 ). В числителе должна быть большая сумма квадратов.
). В числителе должна быть большая сумма квадратов.
Полученное отношение имеет F распределение со степенями свободы k1=n1-k и k2=n-n1-k, (k– число оцениваемых параметров в уравнении регрессии).
Если  , то гетероскедастичность имеет место.
, то гетероскедастичность имеет место.
Чем больше величина F превышает табличное значение F -критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
Оценка влияния отдельных факторов на зависимую переменную на основе модели (коэффициенты эластичности, b — коэффициенты).
Важную роль при оценке влияния факторов играют коэффициенты регрессионной модели. Однако непосредственно с их помощью нельзя сопоставить факторы по степени их влияния на зависимую переменную из-за различия единиц измерения и разной степени колеблемости. Для устранения таких различий при интерпретации применяются средние частные коэффициенты эластичности Э(j) и бета-коэффициенты b(j).
Эластичность Y по отношению к Х(j) определяется как процентное изменение Y, отнесенное к соответствующему процентному изменению Х. В общем случае эластичности не постоянны, они различаются, если измерены для различных точек на линии регрессии. По умолчанию стандартные программы, оценивающие эластичность, вычисляют ее в точках средних значений:
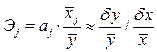
Эластичность ненормирована и может изменяться от —  до + . Важно, что она безразмерна, так что интерпретация эластичности
до + . Важно, что она безразмерна, так что интерпретация эластичности  =2.0 означает, что если
=2.0 означает, что если  изменится на 1%, то это приведет к изменению
изменится на 1%, то это приведет к изменению  на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
Высокий уровень эластичности означает сильное влияние независимой переменной на объясняемую переменную.

где Sxj — среднеквадратическое отклонение фактора j
где 
 .
.
Коэффициент эластичности показывает, на сколько процентов изменяется зависимая переменная при изменении фактора j на один процент. Однако он не учитывает степень колеблемости факторов.
Бета-коэффициент показывает, на какую часть величины среднего квадратического отклонения Sy изменится зависимая переменная Y с изменением соответствующей независимой переменной Хj на величину своего среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных.
Указанные коэффициенты позволяют упорядочить факторы по степени влияния факторов на зависимую переменную.
Долю влияния фактора в суммарном влиянии всех факторов можно оценить по величине дельта — коэффициентов D (j):

где  — коэффициент парной корреляции между фактором j (j = 1. m) и зависимой переменной.
— коэффициент парной корреляции между фактором j (j = 1. m) и зависимой переменной.
В качестве основного литературного источника рекомендуется использовать [4], в качестве дополнительного – [2].
Множественная линейная регрессия. Оценка качества уравнения регрессии
Вы будете перенаправлены на Автор24
Множественная линейная регрессия
Множественная линейная регрессия – это статистическая модель, в которой число переменных составляет две и более.
Математическая статистика широко применяется в экономических исследованиях для того, чтобы приблизить входные и выходные данные на основе линейного уравнения. Она является элементом регрессионного анализа, который используется в статистическом моделировании. Регрессионный анализ базируется на методах моделирования и исследования связей между зависимыми и независимыми переменными, называемыми регрессорами. Цель анализа — формирование представления об изменениях зависимой величины в случае, если другие переменные остаются неизменными. Обычно регрессионный анализ применяется для оценки ожиданий.
Простая линейная регрессия рассматривает зависимость между одной входной и одной выходной величиной выборки. Уравнение выглядит достаточно просто $y = ax + b$. Графически оно отображается как прямая с множеством точек отклонения. Коэффициенты уравнения являются параметрами модели. Отклонение рассчитывается через сумму квадратов.
Метод наименьших квадратов опирается на экспериментальные данные, которые могут содержать случайные отклонения. Знание параметров модели позволяет применять приближенные значения. Если величины уравнения рассчитаны, то разница между реальными и теоретическими значениями снижается.
Параметры множественной регрессии так же вычисляются с помощью метода наименьших квадратов. Ее отличительной особенностью является использование гиперплоскости. Уравнение множественной регрессии удобно тем, что увеличивает количество объясненных отклонений переменных. Результатом становится улучшение соответствия между данными модели. Добавление новых величин или параметров в исследование будет только увеличивать коэффициент его детерминации. Этот коэффициент показывает, насколько уравнение соответствует реальной действительности.
Готовые работы на аналогичную тему
Оценка качества уравнения множественной линейной регрессии
Исследование качества уравнения регрессии заключается в оценке его адекватности и точности. Анализ опирается на изучение следующих величин:
- Коэффициент детерминации.
- Индекс корреляции или коэффициент множественной регрессии.
- Средняя относительная ошибка.
Коэффициент детерминации в уравнении множественной регрессии равен квадрату коэффициента корреляции между зависимой и независимой переменными. Индекс корреляции анализирует тесноту связи переменных. Если он используется для нелинейных уравнений, то применяется критерий Фишера. Множественный коэффициент корреляции применяется для исследования связей между случайной величиной и другими величинами. Средняя относительная ошибка помогает вычислить отклонение расчетных значений уравнения от фактических данных. Если отклонение не превышает 15%, то речь идет о хорошо подобранном уравнении регрессии.
Значимость уравнения проверяется по критерию Фишера. Далее ему присуждается критическое значение, которое сопоставляется с расчетными данными. Качество модели расценивается при помощи ряда остатков. Полученный коэффициент детерминации показывает зависимость величин друг от друга, а так же тесноту этой связи. Уравнение считается значимым в том случае, если значение критерия Фишера будет больше критического. Точность модели считается неудовлетворительной, если процент соответствия будет более 15%. Тогда модель рассматривается как неудовлетворительная, поэтому в дальнейшем она не используется.
Изучение графика остатков позволяет увидеть какие-либо зависимости, которые не были учтены в модели. Он показывает выбросы. Аномалии могут искажать конечный результат и качество анализа. Чтобы устранить выбросы, необходимо их удалить из данных исследования. Этот процесс называется цензурированием.
Таким образом, оценка качества модели регрессии проверяется качеством уравнения, проверкой его значимости, выполнением предпосылок.
Выбор оптимальной модели множественной регрессии
Исследование начинается с создания первоначальной модели множественной регрессии. Ее анализ необходим для последующего улучшения. Качество модели изучается с помощью коэффициентов, применяемых для парной регрессии. Среди них отмечают:
- Коэффициент детерминации.
- Статистику Фишера.
- Стандартную ошибку регрессии.
- Сумму квадратов остатков.
Скорректированный коэффициент детерминации обычно применяется для множественной регрессии. Он исключает или добавляет в уравнение переменные или наблюдения. Качество может определяться с помощью проверки на выполнение требований Маркова-Гаусса. Условия считаются выполненными, если математическое наблюдение остатков равно нулю для каждого значения. Дисперсия постоянна для каждого наблюдения. Системные связи между остатками отсутствуют. Зависимость между остатками и переменными так же отсутствует. Выявление соответствия требованиям Гаусса-Маркова позволяет применять метод наименьших квадратов. Полученная с его помощью модель является несмещенной, эффективной и состоятельной.
Следующий шаг – проверка модели с помощью критерия Стьюдента. Если в уравнении есть резко выделяющиеся наблюдения, то их последовательно исключают. Так же выявляются незначимые переменные, которые исключаются из модели в случае необходимости. Например, при изучении экономического поведения человека устанавливается зависимость между факторами, а так же формируется база статических показателей, которые позволяют проверить гипотезу.
Далее строится две нелинейных модели, которые учитывают квадраты двух наиболее значимых моделей и учитывают их логарифмы. Их сравнивают с линейными уравнениями, которые возникают на разных этапах проверки. Полученные модели сравниваются, из них выбирается наилучший вариант, который принимается за качественную модель.
Таким образом, оценка модели проводится для исключения незначимых событий, ошибочных наблюдений.
Анализ общего качества уравнения регрессии.
Коэффициент детерминации R 2
После проверки точности и статистической значимости каждого коэффициента регрессионной модели обычно проводится анализ общего качества уравнения модели, которое оценивается по тому, как хорошо эмпирическое уравнение регрессии согласуется со статистическими данными. Другими словами, необходимо оценить, насколько широко рассеяны точки наблюдений по их совокупности относительно линии регрессии (линии модели). Поэтому представляется естественным вывод о том, что проверку общего качества регрессионной модели следует проводить на основе дисперсионного анализа, сравнивая дисперсии модельных и реальных значений исследуемой переменной Y.
Рассмотрим для определенного набора наблюдений n дисперсию Dn(y), которая характеризует разброс значений yi вокруг среднего значения. Из дисперсионного анализа следует, что эту дисперсию можно разбить на две части: объясняемую уравнением регрессии и не объясняемую (т. е. связанную со случайными отклонениями ei). Тогда выполняется следующее соотношение:
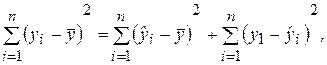 (2.27)
(2.27)
где 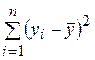 – общая сумма квадратов отклонений зависимой переменной Y от среднего значения;
– общая сумма квадратов отклонений зависимой переменной Y от среднего значения;
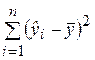 – сумма квадратов, объясняемая уравнением регрессии;
– сумма квадратов, объясняемая уравнением регрессии;
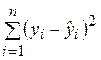 – необъясненная (остаточная) сумма квадратов. Напомним, что
– необъясненная (остаточная) сумма квадратов. Напомним, что 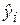 определяется как
определяется как 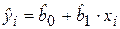 , а
, а 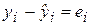 .
.
Разделив выражение (2.27) на его левую часть, получим формулу для оценки характеристики, которая обозначается как R 2 и называется коэффициентом детерминации:
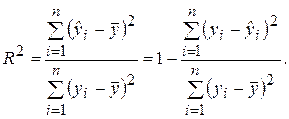 (2.28)
(2.28)
Коэффициент детерминации R 2 является мерой качества уравнения регрессионной модели и определяет долю дисперсии (разброса), объясняемую регрессией Y на Х, в общей дисперсии зависимой переменной Y.
Из проведенных рассуждений следует, что R 2 принимает значения между 0 и 1 (0 £ R 2 £ 1). Чем ближе R 2 к единице, тем теснее линейная связь между Х и Y (экспериментальные точки теснее примыкают к линии регрессии). Чем ближе R 2 к нулю, тем такая связь слабее. Если R 2 = 0, то дисперсия зависимой переменной полностью обусловлена воздействием неучтенных факторов и линия регрессии (модели) должна быть параллельна оси абсцисс (Y = 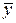 ).
).
Например, если для построенной модели R 2 = 0,7, то согласно (2.28) можно утверждать, что поведение зависимой переменной (результативного признака) Y на 70 % объясняется влиянием фактора Х и на 30 % обусловлено влиянием неучтенных факторов. Доля влияния неучтенных факторов связана со случайными отклонениями ei и определяется отношением 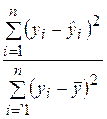 , характеризующим долю разброса зависимой переменной, не объясняемую линейной регрессией Y на Х.
, характеризующим долю разброса зависимой переменной, не объясняемую линейной регрессией Y на Х.
Естественно, что для исследуемого объекта наиболее качественной будет считаться модель с наибольшим значением коэффициента детерминации R 2 .
Заметим, что коэффициент детерминации имеет смысл рассматривать только при наличии параметра 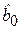 (свободного члена) в уравнении регрессионной модели.
(свободного члена) в уравнении регрессионной модели.
Таким образом, коэффициент детерминации R 2 определяет степень тесноты статистической связи между Y и Х. Но об этом же говорит выборочный коэффициент корреляции rxy. Рассматривая эти характеристики, можно установить, что в случае парной линейной регрессионной модели коэффициент детерминации равен квадрату коэффициента корреляции 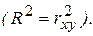
Действительно, учитывая (2.13),
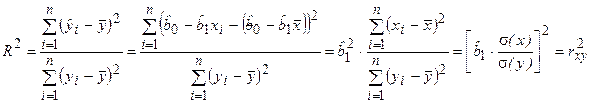 .
.
Естественно, возникает вопрос, какое значение R 2 можно считать удовлетворительным. Ответ на этот вопрос может быть неоднозначным, особенно в случае множественной регрессионной модели и зависит от объема выборки n и постановки задачи, вытекающей из предмодельного анализа.
Более точно проверить значимость уравнения регрессии, т. е. установить, соответствует ли построенная модель реальным данным и достаточно ли включенных в уравнение объясняющих переменных для описания зависимой переменной, позволяет F-тест, который проводится по схеме статистической проверки гипотез. Тестируется гипотеза Н0 о статистической незначимости уравнения регрессии.
Рассмотрим «объясненную» и «необъясненную» дисперсии: 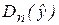 и Dn(e). Отношение этих дисперсий, рассчитанное на одну степень свободы, имеет F-распределение (F-статистику), фактически наблюдаемое значение которой для парной регрессии определяется формулой
и Dn(e). Отношение этих дисперсий, рассчитанное на одну степень свободы, имеет F-распределение (F-статистику), фактически наблюдаемое значение которой для парной регрессии определяется формулой
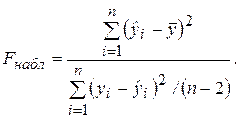 (2.29)
(2.29)
Учитывая смысл дисперсий и Dn(e), можно считать, что значение Fнабл показывает, в какой мере уравнение регрессии лучше оценивает значение зависимой переменной по сравнению с 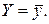
Согласно схеме статистической проверки гипотез, гипотеза Н0 отклоняется, т. е. признается статистическая значимость и надежность уравнения регрессии на заданном уровне α, если Fнабл превосходит критическое (табличное) значение F-статистики Фишера (Fнабл > Fкр = Fα, 1, n — 2). Если Fнабл 2 . В этом случае гипотеза Н0 о статистической незначимости регрессионной модели заменяется эквивалентной гипотезой о статистической незначимости R 2 .
Для парной регрессионной модели способы проверки значимости коэффициента 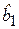 с использованием t-критерия (t-тест) и уравнения регрессии (показателя тесноты связи R 2 ) с использованием F-критерия равносильны, поскольку эти критерии связаны соотношением F = t 2 .
с использованием t-критерия (t-тест) и уравнения регрессии (показателя тесноты связи R 2 ) с использованием F-критерия равносильны, поскольку эти критерии связаны соотношением F = t 2 .
Наряду с коэффициентом детерминации R 2 для оценки качества парной регрессионной модели можно использовать характеристику, называемую средней ошибкой аппроксимации 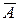 :
:
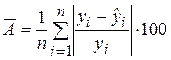 %. (2.31)
%. (2.31)
Средняя ошибка аппроксимации определяет среднее относительное отклонение расчетных данных (оцененных по уравнению модели) от фактических. является безразмерной величиной и обычно выражается в процентах. Принято считать, что качество модели считается удовлетворительным, если средняя ошибка аппроксимации не превышает 8-9 %.
Пример 2.3.Проверить общее качество и статистическую значимость уравнения регрессии для модели, построенной в примере 2.1.
Оценку качества построенной модели дают коэффициент детерминации R 2 и средняя ошибка аппроксимации 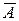 .
.
Вычислим коэффициент детерминации, воспользовавшись данными табл. 2.1.
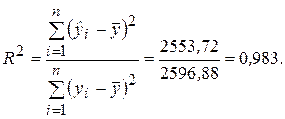
Величина коэффициента детерминации показывает, что поведение результативного признака (недельного потребления) Y на 98,3 % объясняется влиянием фактора Х (изменением недельного дохода), а остальные 1,7 % составляют долю необъясненной вариации, происходящей под действием прочих (неучтенных) факторов.
Расчет средней ошибки аппроксимации представлен в последнем столбце табл. 2.1.
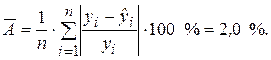
Рассчитанные значения коэффициента детерминации и средней ошибки аппроксимации свидетельствуют о достаточно высоком общем качестве построенной модели.
Проверим статистическую значимость уравнения регрессионной модели с помощью F-теста. Расчетное (наблюдаемое) значение F-статистики Фишера вычисляется по формуле:
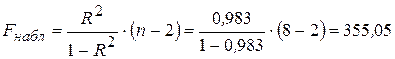 .
.
Табличное значение F-статистики при уровне значимости α = 0,01 и числе степеней свободы ν = n – 2 будет составлять 13,75 (Fкр = 13,75).
Так как Fнабл > Fкр (355,05 > 13,75), то нулевая гипотеза Н0 отклоняется и уравнение регрессионной модели признается статистически значимым и весьма надежным, поскольку наблюдаемое значение F-статистики превосходит табличное значение критерия более чем в 25 раз.
Дата добавления: 2016-06-02 ; просмотров: 2257 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
http://spravochnick.ru/ekonometrika/mnozhestvennaya_lineynaya_regressiya_ocenka_kachestva_uravneniya_regressii/
http://helpiks.org/8-22676.html