Уравнение нелинейной регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Виды нелинейной регрессии
| Вид | Класс нелинейных моделей |
| Нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам |
| Нелинейные по оцениваемым параметрам |
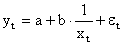
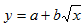
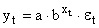
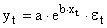

Здесь ε — случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.
Уравнению регрессии первого порядка — это уравнение парной линейной регрессии.
Уравнение регрессии второго порядка это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
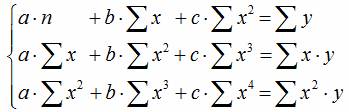
Уравнение регрессии третьего порядка соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
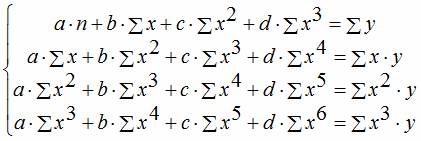
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания):
- Замена переменных.
- Логарифмирование обеих частей уравнения.
- Комбинированный.
| y = f(x) | Преобразование | Метод линеаризации |
| y = b x a | Y = ln(y); X = ln(x) | Логарифмирование |
| y = b e ax | Y = ln(y); X = x | Комбинированный |
| y = 1/(ax+b) | Y = 1/y; X = x | Замена переменных |
| y = x/(ax+b) | Y = x/y; X = x | Замена переменных. Пример |
| y = aln(x)+b | Y = y; X = ln(x) | Комбинированный |
| y = a + bx + cx 2 | x1 = x; x2 = x 2 | Замена переменных |
| y = a + bx + cx 2 + dx 3 | x1 = x; x2 = x 2 ; x3 = x 3 | Замена переменных |
| y = a + b/x | x1 = 1/x | Замена переменных |
| y = a + sqrt(x)b | x1 = sqrt(x) | Замена переменных |
Пример . По данным, взятым из соответствующей таблицы, выполнить следующие действия:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессии.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью F-критерия Фишера статистическую надежность результатов регрессионного моделирования. По значениям характеристик, рассчитанных в пп. 4, 5 и данном пункте, выбрать лучшее уравнение регрессии и дать его обоснование.
- Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 15% от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости α=0,05 .
- Оценить полученные результаты, выводы оформить в аналитической записке.
| Год | Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. — трлн. руб.), y | Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. — тыс. руб.), х |
| 1995 | 872 | 515,9 |
| 2000 | 3813 | 2281,1 |
| 2001 | 5014 | 3062 |
| 2002 | 6400 | 3947,2 |
| 2003 | 7708 | 5170,4 |
| 2004 | 9848 | 6410,3 |
| 2005 | 12455 | 8111,9 |
| 2006 | 15284 | 10196 |
| 2007 | 18928 | 12602,7 |
| 2008 | 23695 | 14940,6 |
| 2009 | 25151 | 16856,9 |
Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии. Получим таблицу следующего вида.
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
Степенное уравнение регрессии имеет вид y = a x b
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) — 49694.9535
В линейной регрессии, когда уместно использовать лог независимой переменной вместо фактических значений?
Я ищу лучшее распределение для рассматриваемой независимой переменной, или чтобы уменьшить влияние выбросов или что-то еще?
Я всегда стесняюсь заходить в цепочку с таким большим количеством превосходных ответов, как это, но мне кажется, что лишь немногие из ответов дают какую-либо причину предпочесть логарифм другим преобразованиям, которые «сдавливают» данные, такие как корень или ответ.
Прежде чем перейти к этому, давайте подведем итоги мудрости в существующих ответах в более общем виде. Некоторое нелинейное повторное выражение зависимой переменной указывается, когда применимо любое из следующего:
Остатки имеют перекошенное распределение. Целью преобразования является получение остатков, которые приблизительно симметрично распределены (конечно, около нуля).
Разброс остатков систематически изменяется со значениями зависимой переменной («гетероскедастичность»). Цель трансформации состоит в том, чтобы устранить это систематическое изменение в распространении, достигнув приблизительной «гомоскедастичности».
Чтобы линеаризовать отношения.
Когда научная теория указывает. Например, химия часто предлагает выражать концентрации в виде логарифмов (давая активность или даже общеизвестный pH).
Когда более туманная статистическая теория предлагает, остатки отражают «случайные ошибки», которые не накапливаются аддитивно.
Упростить модель. Например, иногда логарифм может упростить количество и сложность терминов «взаимодействие».
(Эти признаки могут противоречить друг другу; в таких случаях требуется суждение.)
Итак, когда конкретно указывается логарифм вместо какого-либо другого преобразования?
Остатки имеют «сильно» положительно перекошенное распределение. В своей книге об EDA Джон Тьюки предоставляет количественные способы оценки трансформации (в пределах семейства Бокса-Кокса, или силовых трансформаций) на основе ранговых статистик невязок. Это действительно сводится к тому факту, что если взятие логарифма симметрирует остатки, это, вероятно, была правильная форма повторного выражения; в противном случае необходимо другое выражение.
Когда SD остатков прямо пропорционально установленным значениям (а не какой-то степени установленных значений).
Когда отношения близки к экспоненциальным.
Когда считается, что остатки отражают мультипликативно накапливающиеся ошибки.
Вы действительно хотите модель, в которой предельные изменения в объясняющих переменных интерпретируются как мультипликативные (процентные) изменения в зависимой переменной.
И, наконец, некоторые не- причины использовать повторное выражение :
Создание выбросов не похоже на выбросы. Выделение — это элемент данных, который не вписывается в какое-то скупое, относительно простое описание данных. Изменение своего описания, чтобы улучшить внешний вид выбросов, обычно является неправильным изменением приоритетов: сначала получите научно обоснованное, статистически хорошее описание данных, а затем изучите любые выбросы. Не позволяйте случайным выбросам определять, как описать остальные данные!
Потому что программное обеспечение автоматически сделало это. (Достаточно сказано!)
Потому что все данные положительные. (Позитивность часто подразумевает положительную асимметрию, но это не обязательно. Более того, другие преобразования могут работать лучше. Например, корень часто лучше всего работает с подсчитанными данными.)
Чтобы «плохие» данные (возможно, низкого качества) выглядели хорошо.
Чтобы иметь возможность построить данные. (Если преобразование необходимо для построения графика данных, возможно, оно необходимо по одной или нескольким веским причинам, которые уже упоминались. Если единственная причина преобразования действительно заключается в построении графика, продолжайте и сделайте это — но только для построения графика данные. Оставьте данные без преобразования для анализа.)
Я всегда говорю студентам, что есть три причины для преобразования переменной, взяв натуральный логарифм. Причина регистрации переменной будет определять, хотите ли вы зарегистрировать независимую переменную (переменные), зависимую или обе. Чтобы было ясно, я говорю о натуральном логарифме.
Во-первых, для улучшения подгонки модели, как отмечали другие постеры. Например, если ваши остатки обычно не распределяются, то взятие логарифма перекошенной переменной может улучшить подгонку, изменив масштаб и сделав переменную более «нормально» распределенной. Например, доход усекается до нуля и часто демонстрирует положительный перекос. Если переменная имеет отрицательный перекос, вы можете сначала инвертировать переменную, прежде чем брать логарифм. Я имею в виду, в частности, шкалы Лайкерта, которые вводятся как непрерывные переменные. Хотя это обычно относится к зависимой переменной, иногда возникают проблемы с остатками (например, гетероскедастичностью), вызванными независимой переменной, которые иногда можно исправить, взяв логарифм этой переменной. Например, при запуске модели, объясняющей оценки лектора на наборе лектора и класса, переменная «размер класса» (т. Е. Количество студентов в лекции) имела выбросы, которые вызывали гетероскедастичность, потому что дисперсия в оценках лектора была меньше в большем когорты, чем меньшие когорты. Регистрация переменной студента может помочь, хотя в этом примере либо расчет робастных стандартных ошибок, либо использование взвешенных наименьших квадратов может облегчить интерпретацию.
Вторая причина регистрации одной или нескольких переменных в модели — для интерпретации. Я называю это удобной причиной. Если вы зарегистрируете как зависимую (Y), так и независимую (X) переменную (и), ваши коэффициенты регрессии ( ) будут эластичными, и интерпретация будет выглядеть следующим образом: увеличение X на 1% приведет к при прочих равных условиях % увеличение Y (в среднем). Регистрация только одной стороны регрессионного «уравнения» приведет к альтернативным интерпретациям, как показано ниже: β ‘ role=»presentation»> β β ‘ role=»presentation»> β
Y и X — увеличение X на одну единицу приведет к увеличению / уменьшению Y β ‘ role=»presentation»> β
Log Y и Log X — увеличение X на 1% приведет к увеличению / уменьшению Y на % β ‘ role=»presentation»> β
Записать Y и X — увеличение X на одну единицу приведет к % увеличению / уменьшению Y β ∗ 100 ‘ role=»presentation»> β ∗ 100
Y и Log X — увеличение X на 1% приведет к увеличению / уменьшению Y β / 100 ‘ role=»presentation»> β / 100
И, наконец, может быть теоретическая причина для этого. Например, некоторые модели, которые мы хотели бы оценить, являются мультипликативными и, следовательно, нелинейными. Взятие логарифмов позволяет оценивать эти модели с помощью линейной регрессии. Хорошие примеры этого включают производственную функцию Кобба-Дугласа в экономике и уравнение Минцера в образовании. Производственная функция Кобба-Дугласа объясняет, как входы преобразуются в выходы:
Y ‘ role=»presentation»> Y — общий объем производства или продукции некоторой организации, например, фирмы, фермы и т. Д.
A ‘ role=»presentation»> A — общая производительность факторов (изменение объема производства, не вызванное входными данными, например, технологическим изменением или погодой)
L ‘ role=»presentation»> L — трудозатраты
K ‘ role=»presentation»> K — капитал
α ‘ role=»presentation»> α & — выходная эластичность. β ‘ role=»presentation»> β
Принятие логарифмов этого упрощает оценку функции с использованием линейной регрессии OLS как таковой:
Линейная регрессия
Дата публикации Feb 11, 2019
Введение
Недавно я написал об оценке максимального правдоподобия в своей продолжающейся серии статей об основах машинного обучения:
Оценка максимального правдоподобия
Основы машинного обучения (часть 2)
towardsdatascience.com
В этом посте мы узнали, что значит «моделировать» данные, а затем, как использовать MLE, чтобы найти параметры нашей модели. В этом посте мы собираемся погрузиться в линейную регрессию, одну из наиболее важных моделей в статистике, и научимся формировать ее с точки зрения MLE. Решение представляет собой прекрасный математический пример, который, как и большинство моделей MLE, богат интуицией. Я предполагаю, что вы получили представление о словаре, который я рассмотрел в других сериях (плотности вероятностей, условные вероятности, функция вероятности, данные iid и т. Д.). Если вы видите здесь что-то, что вас не устраивает, проверьтеВероятностьа такжеMLEсообщения из этой серии для ясности.
Модель
Мы используем линейную регрессию, когда наши данные имеют линейную связь между независимыми переменными (нашими функциями) и зависимой переменной (нашей целью). В посте MLE мы увидели некоторые данные, которые тоже выглядели примерно так:

Мы заметили, что между x и y существует линейная зависимость, но она не идеальна. Мы думаем об этих недостатках как о результате некоторой ошибки или шумового процесса. Представьте, что проведете линию прямо через облако точек. Ошибка для каждой точки — это расстояние от точки до нашей линии. Мы хотели бы явно включить эти ошибки в нашу модель. Один из способов сделать это — предположить, что ошибки распределены из гауссовского распределения со средним значением 0 и некоторой неизвестной дисперсией σ². Gaussian кажется хорошим выбором, потому что наши ошибки выглядят симметричными относительно линии, и маленькие ошибки более вероятны, чем большие. Мы пишем нашу линейную модель с гауссовым шумом так:

Термин ошибки взят из нашего гауссовского алгоритма, а затем вычисленный нами у вычисляется путем добавления ошибки к выходным данным линейного уравнения. Эта модель имеет три параметра: наклон и пересечение нашей линии и дисперсию распределения шума. Наша главная цель — найти наилучшие параметры для наклона и пересечения нашей линии.
Функция правдоподобия
Чтобы применить максимальное правдоподобие, нам сначала нужно вывести функцию правдоподобия. Во-первых, давайте перепишем нашу модель сверху как единое условное распределение, заданное x:

Это эквивалентно проталкиванию нашего x через уравнение линии, а затем добавлению шума от среднего гауссова 0.
Теперь мы можем записать условное распределение y для заданного x в терминах этого гауссиана. Это просто уравнение функции плотности вероятности распределения Гаусса с нашим линейным уравнением вместо среднего значения:

Точка с запятой в условном распределении действует как запятая, но это полезное обозначение для отделения наших наблюдаемых данных от параметров.
Каждая точка является независимой и одинаково распределенной (iid), поэтому мы можем записать функцию правдоподобия относительно всех наших наблюдаемых точек как произведение каждой отдельной плотности вероятности. Поскольку σ² одинаково для каждой точки данных, мы можем вычленить термин гауссианы, который не включает x или y из произведения:

Log-правдоподобие:
Следующий шаг в MLE — найти параметры, которые максимизируют эту функцию. Чтобы упростить наше уравнение, давайте возьмем журнал нашей вероятности. Напомним, что максимизация логарифмической вероятности такая же, как максимизация вероятности, поскольку логарифм является монотонным. Натуральный логарифм вычитается по экспоненте, превращает произведения в суммы бревен и делится на вычитание бревен; так что наша логарифмическая вероятность выглядит намного проще:

Сумма квадратов ошибок:
Чтобы еще кое-что прояснить, давайте запишем вывод нашей строки как одно значение:

Теперь наша логарифмическая вероятность может быть записана как:

Чтобы убрать отрицательные знаки, давайте вспомним, что максимизация числа — это то же самое, что минимизация отрицания числа. Поэтому вместо того, чтобы максимизировать вероятность, давайте минимизируем отрицательную логарифмическую вероятность:

Наша конечная цель — найти параметры нашей линии. Чтобы минимизировать отрицательное логарифмическое правдоподобие по отношению к линейным параметрам (θs), мы можем представить, что наш дисперсионный член является фиксированной константой.
Удаление любых констант, которые не включают наши θs, не изменит решение Поэтому мы можем выбросить любые постоянные термины и изящно написать то, что мы пытаемся минимизировать, как:

Оценка максимального правдоподобия для нашей линейной модели — это линия, которая минимизирует сумму квадратов ошибок! Это прекрасный результат, и вы увидите, что минимизация квадратичных ошибок повсеместно встречается в машинном обучении и статистике.
Решение для параметров
Мы пришли к выводу, что оценки максимального правдоподобия для нашего наклона и перехвата можно найти путем минимизации суммы квадратов ошибок. Давайте расширим нашу цель минимизации и используемякак наш индекс над нашимNТочки данных:

Квадрат в формуле SSE делает его квадратичным с одним минимумом. Минимум можно найти, взяв производную по каждому из параметров, установив ее равной 0 и решив для параметров по очереди.
Перехват:
Давайте начнем с решения для перехвата. Взятие частной производной по отношению к перехвату и проработка дает нам:

Горизонтальные полосы над переменными показывают среднее значение этих переменных. Мы использовали тот факт, что сумма значений переменных равна среднему значению этих значений, умноженному на количество значений, которые у нас есть. Установка производной равной 0 и решение для перехвата дает нам:

Это довольно аккуратный результат. Это уравнение линии со средствами х и у вместо этих переменных. Перехват по-прежнему зависит от наклона, поэтому нам нужно найти его дальше.
Склон:
Мы начнем с частной производной SSE относительно нашего наклона. Мы включаем наше решение для перехвата и используем алгебру, чтобы изолировать термин наклона:

Установка этого значения равным 0 и решение для наклона дает нам:

Хотя технически мы закончили, мы можем использовать некоторую причудливую алгебру, чтобы переписать это, не используяN:

Собираем все вместе:
Мы можем использовать эти производные уравнения, чтобы написать простую функцию в python для решения параметров для любой линии, заданной как минимум двумя точками:
Используя этот код, мы можем поместить строку в наши исходные данные (см. Ниже). Это максимальная оценка правдоподобия для наших данных. Линия минимизирует сумму квадратов ошибок, поэтому этот метод линейной регрессии часто называют обычными наименьшими квадратами.

Последние мысли
Я хотел написать этот пост главным образом для того, чтобы подчеркнуть связь между минимизацией суммы квадратов ошибок и подходом оценки максимального правдоподобия к линейной регрессии. Большинство людей сначала учатся решать линейную регрессию путем минимизации квадратичной ошибки, но, как правило, не понимают, что это происходит из вероятностной модели с запечатленными в допущениях (например, гауссовых распределенных ошибок).
Существует более элегантное решение для нахождения параметров этой модели, но для этого требуется линейная алгебра. Я планирую вернуться к линейной регрессии после того, как расскажу о линейной алгебре в своей серии основ, и покажу, как ее можно использовать для подбора более сложных кривых, таких как полиномы и экспоненты.
http://qastack.ru/stats/298/in-linear-regression-when-is-it-appropriate-to-use-the-log-of-an-independent-va
http://www.machinelearningmastery.ru/linear-regression-91eeae7d6a2e/