Построение регрессионных моделей с фиктивными переменными

ПОСТРОЕНИЕ РЕГРЕССИОННЫХ МОДЕЛЕЙ С ФИКТИВНЫМИ ПЕРЕМЕННЫМИ
В регрессионных моделях в качестве объясняющих переменных часто приходится использовать не только количественные (определяемые численно), но и качественные переменные. Например, спрос на какое-либо благо может определяться как количественными переменными (цена данного блага), так и качественными (вкусы потребителей). Качественные показатели в численном виде представить нельзя. Возникает проблема отражения в модели влияния таких переменных на исследуемую величину.
Обычно в моделях влияние качественного фактора выражается в виде фиктивной (искусственной) переменной, которая отражает два противоположных состояния качественного фактора. В этом случае фиктивная переменная может выражаться в двоичной форме:

Переменная D называется фиктивной (искусственной, двоичной) переменной (индикатором).
Регрессионные модели, содержащие лишь качественные объясняющие переменные, называются моделями дисперсионного анализа (ANOVA-моделями).

Тогда зависимость можно выразить моделью парной регрессии:
 .
.

Коэффициент  определяет среднюю начальную заработную плату при отсутствии высшего образования. Коэффициент
определяет среднюю начальную заработную плату при отсутствии высшего образования. Коэффициент  указывает, на какую величину отличаются средние начальные заработные платы при наличии и при отсутствии высшего образования у претендента. Проверяя статическую значимость коэффициента с помощью t-статистики, либо значимость коэффициента детерминации
указывает, на какую величину отличаются средние начальные заработные платы при наличии и при отсутствии высшего образования у претендента. Проверяя статическую значимость коэффициента с помощью t-статистики, либо значимость коэффициента детерминации  или F-статистики, можно определить, влияет или нет наличие высшего образования на начальную заработную плату.
или F-статистики, можно определить, влияет или нет наличие высшего образования на начальную заработную плату.
Модели, в которых объясняющие переменные носят как количественный, так и качественный характер, называются моделями ковариационного анализа (ANCOVA-моделями).
Существует несколько разновидностей моделей ковариационного анализа.
1. Модели ковариационного анализа при наличии у фиктивной переменной двух альтернатив.
Рассмотрим простейшую модель с одной количественной и одной качественной переменными, имеющую два альтернативных состояния:
 .
.
Пусть, например, Y – заработная плата сотрудника фирмы, х – стаж сотрудника, D – пол сотрудника, т. е.

Тогда ожидаемое значение заработной платы сотрудников при х годах трудового стажа будет:

Заработная плата в данном случае является линейной функцией от стажа работы.
При составлении моделей с фиктивными переменными необходимо руководствоваться следующим правилом моделирования: если качественная переменная имеет k альтернативных значений, то при моделировании используется (k – 1) фиктивных переменных. Таким образом, если переменная имеет два альтернативных значения (например, пол), то в модель можно ввести только одну фиктивную переменную.
Если не следовать данному правилу, то при моделировании исследователь попадает в ситуацию совершенной мультиколлинеарности или так называемую ловушку фиктивной переменной.
Значение качественной переменной, для которого принимается D = 0, называется базовым или сравнительным. Выбор базового значения обычно диктуется целями исследования, но может быть и произвольным.
Коэффициент в модели иногда называется дифференциальным коэффициентом свободного члена, так как он показывает, на какую величину отличается свободный член модели при значении фиктивной переменной, равном единице, от свободного члена модели при базовом значении фиктивной переменной.
2. Модели ковариационного анализа при наличии у качественных переменных более двух альтернатив.
Рассмотрим модель с двумя объясняющими переменными, одна из которых количественная, а другая – качественная. Причем качественная переменная имеет три альтернативы. Например, расходы на содержание ребенка могут быть связаны с доходами домохозяйства и возрастом ребенка: дошкольный, младший школьный и старший школьный. Так как качественная переменная имеет три альтернативы, то по общему правилу моделирования необходимо использовать две фиктивные переменные. Таким образом, модель может быть представлена в виде:
 ,
,
где Y – расходы, x – доходы домохозяйств.


Образуются следующие зависимости:
1. Средний расход на дошкольника:
 (1)
(1)
2. Средний расход на младшего школьника:
 (2)
(2)
3. Средний расход на старшего школьника:
 (3)
(3)
Здесь γ1, γ2 – дифференциальные свободные члены. Базовым значением качественной переменной является значение «дошкольник». После вычисления коэффициентов уравнений регрессии (1) – (3) определяется статистическая значимость коэффициентов γ1и γ2 на основе обычной t-статистики.
Если коэффициенты γ1 и γ2 оказываются статистически незначимыми, то можно сделать вывод, что возраст ребенка не оказывает влияния на расходы по его содержанию.
3. Регрессия с одной количественной и двумя качественными переменными.
Техника фиктивных переменных может быть распространена на произвольное число качественных факторов. Рассмотрим ситуацию с двумя качественными переменными.
Пусть Y –заработная плата сотрудников фирмы, x – стаж работы, D1 – наличие высшего образования, D2 – пол сотрудника:


Таким образом, получим следующую модель:
 .
.
Из этой модели выводятся следующие регрессионные модели:
1. Средняя зарплата женщины без высшего образования:
2. Средняя зарплата женщины с высшим образованием:

3. Средняя зарплата у мужчины без высшего образования:
4. Средняя зарплата мужчины с высшим образованием:
Очевидно, что все регрессии отличаются только свободными членами. Дальнейшее определение статистической значимости коэффициентов γ1 и γ2 позволяет убедиться, влияют ли образование и пол сотрудника на его заработную плату.
Исследуется зависимость между заработной платой рабочего за месяц у ($), х ‑ возрастом рабочего (лет) и фиктивной переменной D – пол рабочего.

1. Необходимо построить модель  с фиктивной переменной D, которая принимает два значения: 1 ‑ если пол рабочего мужской; 0 ‑ если пол женский.
с фиктивной переменной D, которая принимает два значения: 1 ‑ если пол рабочего мужской; 0 ‑ если пол женский.
2. Проверить статистическую значимость коэффициентов. Сделать выводы.
На предприятии используются станки трех фирм (А, В, С). Исследуется надежность станков. При этом учитывается возраст станка (х, мес.) и время безаварийной работы до последней поломки (y, час). Выборка из 40 станков дала результаты, представленные в таблице.
Фиктивные переменные в регрессионной модели 1 страница
В линейную модель множественной регрессии, как правило, включаются количественные факторы X1, X2, …, Xp, принимающие значения из некоторого интервала, непрерывного либо дискретного. Однако может возникнуть необходимость учесть влияние на зависимую переменную Y и факторов, не измеряемых в числовой шкале (например, формы собственности предприятия, сезонности, региона, климатических условий, пола работника, его уровня образования и т.п.). Такие качественные факторы могут иметь два и более атрибута (градации). Чтобы ввести качественный фактор в регрессионную модель, его необходимо преобразовать в количественную переменную, т.е. присвоить каждому атрибуту те или иные числовые значения. Эту преобразованную переменную называют фиктивной (условной), а модель регрессии, включающую в себя хотя бы одну фиктивную переменную, называют моделью с переменной структурой. Основной целью построения такой модели является учет влияния неоднородности качественной структуры исследуемой совокупности.
В качестве фиктивных обычно используют бинарные переменные, принимающие только два значения (уровня): «0» или «1». Такие переменные также называются двоичными, дихотомическими, альтернативными, или булевыми. К примеру, если необходимо изучить зависимость общей рентабельностипредприятия Y не только от количественных факторов X1, X2, …, Xp, но и от фактора «форма собственности», то в модель вводят фиктивную переменную Z1, принимающую значения: z1=1 — если предприятие негосударственное и z1=0 — если предприятие государственное.
Регрессионная модель рентабельности, в этом случае, примет вид:
 . . | (3.58) |
Параметр регрессии g1 при фиктивной переменной Z1 показывает, на сколько в среднем рентабельность негосударственных предприятий в исследуемой совокупности выше, чем государственных при неизменных значениях остальных факторов X1, X2, …, Xp. Если не учитывать различия, связанные с формой собственности, то они могут либо уйти в остаточную вариацию результата Y, ухудшив модель, либо смешаться с влиянием тех или иных количественных факторов, искажая меру их влияния на Y.
В модель множественной регрессии можно одновременно ввести несколько фиктивных переменных Z1, Z2, …, Zu:
 . . | (3.59) |
Обычно значение, равное единице, присваивают фиктивной переменной для той группы исследуемых объектов, у которых значение результата Y предположительно в среднем выше, чем у объектов альтернативной группы. Положительный знак коэффициента уравнения регрессии при фиктивной переменной и его статистическая значимость в дальнейшем подтверждают это предположение. При отрицательном знаке следует сделать обратный вывод.
Применение фиктивной переменной с другими значениями или с большим числом уровней затрудняет содержательную экономическую интерпретацию соответствующего коэффициента уравнения регрессии. Например, если число k уровней качественного признакаболее двух (  ), то в принципе в регрессионную модель можно было бы ввести дискретную переменную, принимающую такое же количество значений. Так, если расширить трактовку фактора «форма собственности» до трех групп: государственные, кооперативные и частные предприятия, то при построении модели рентабельности можно рассматривать три значения (k=3) фиктивной переменной Z1, например: z1=1 — если предприятие государственное, z1=2 — если кооперативное, и z1=3 — если частное. Однако содержательная интерпретация коэффициента уравнения регрессии при Z1 тогда будет невозможна. Вместо этого в модель следует ввести
), то в принципе в регрессионную модель можно было бы ввести дискретную переменную, принимающую такое же количество значений. Так, если расширить трактовку фактора «форма собственности» до трех групп: государственные, кооперативные и частные предприятия, то при построении модели рентабельности можно рассматривать три значения (k=3) фиктивной переменной Z1, например: z1=1 — если предприятие государственное, z1=2 — если кооперативное, и z1=3 — если частное. Однако содержательная интерпретация коэффициента уравнения регрессии при Z1 тогда будет невозможна. Вместо этого в модель следует ввести  бинарных переменных и для учета влияния формы собственности включают
бинарных переменных и для учета влияния формы собственности включают 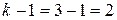 бинарные переменные — Z11 и Z12:
бинарные переменные — Z11 и Z12:
 , , | (3.60) |
где z11=1 — если предприятие частное, z11=0 — во всех остальных случаях; z12=1 — если предприятие кооперативное, z12=0 — во всех остальных случаях.
Третьей бинарной переменной, очевидно, не требуется: еслипредприятие государственное, то это будет отражено парой значений z11=0 и z12=0. Более того, вводить третью бинарную переменную Z13 со значениями z13=1, если предприятие государственное и z13=0 — в остальных случаях, нельзя, так как это приведет к невозможности получения оценок параметров модели при фиктивных переменных методом наименьших квадратов.
Параметры модели при Z11 и Z12 интерпретируются следующим образом. Параметр g11 показывает, на сколько средняя рентабельность частных предприятий при прочих равных условиях выше средней рентабельности государственных предприятий, которые приняты за базу для сравнения. Аналогично параметр g12 показывает превышение средней рентабельности кооперативных предприятий над этим показателем у государственных предприятий.
Модели регрессии (3.58) — (3.60) называются моделями без ограничений. Если значения каких-либо фиктивных переменных равны нулю, то получаются частные модели регрессии. Так, если в модели (3.60) все значения фиктивных переменных равны нулю: z11=0 и z12=0, то получается модель (3.2), которая в этом случае называется базисной моделью, или моделью регрессии с ограничениями. Данная модель является частной моделью государственного предприятия. Частная модель регрессии частного предприятия (z11=1, z12=0) образуется путем добавления параметра g11 к свободному коэффициенту b0:
 . . | (3.61) |
Аналогично частная модель кооперативного предприятия (z11=0, z12=1):
 . . | (3.62) |
На практике могут использоваться регрессионные модели только с фиктивными переменными-факторами. Пусть, например, изучаются различия в средней стоимости квадратного метра общей площади квартиры (переменная Y), в зависимости от района города, типа дома и этажа (фиктивные переменные Z1, Z2 и Z3 соответственно). Модель регрессии в этом случае может иметь вид:
 , , | (3.63) |
где z1=1 — если дом расположен в центральном районе города, z1=0 — если дом расположен в периферийном районе; z2=1 — если дом кирпичный, z2=0 — если дом панельный; z3=1 — если квартира расположена на средних этажах, z3=0 — если квартира расположена на крайних этажах.
Базисной моделью здесь является модель средней стоимости квадратного метра квартиры на крайних этажах (z3=0) в панельном доме (z2=0), расположенном в периферийном районе города (z1=0). Параметр g0 модели (3.63) и показывает среднюю стоимость квадратного метра такой квартиры. Параметр g1 характеризует разницу в средней стоимости квадратного метра квартир, расположенных в центральном и периферийном районах города, параметр g2 — эту разницу в зависимости от типа дома, параметр g3 — в зависимости от этажа.
Параметры модели с фиктивными переменными оцениваются по исходным данным обычным методом наименьших квадратов. Предварительно следует провести проверку на коллинеарность, причем как фиктивных переменных между собой, так и фиктивных переменных с количественными факторами (см. § 3.4).
Уравнение регрессии модели (3.59) выглядит следующим образом:
 , , | (3.64) |
После построения уравнения регрессии проверяется его статистическая значимость в целом и значимость отдельных коэффициентов соответственно по критериям Фишера и Стьюдента. Значимость коэффициента при фиктивной переменной на принятом уровне значимости a свидетельствует о существенном (значимом) различии между значениями результата Y для разных уровней фиктивной переменной и, соответственно, групп исследуемых объектов.
Если значимость коэффициентапри фиктивной переменной не установлена, то разница между градациями соответствующего качественного фактора признается несущественной. Если значение t-статистики при этом превышает по абсолютной величине единицу, то фиктивная переменная все же может считаться в какой-то степени информативной. Однако, если t-статистика по абсолютной величине меньше единицы, то соответствующую фиктивную переменную следует исключить из модели и заново построить уравнение регрессии уже без нее. Следует, однако, учитывать, что незначимость коэффициента при фиктивной переменной может быть вызвана и недостаточным объемом выборки.
Возвратимся к рассмотренным выше примерам. Пусть строится модель с одной фиктивной переменной (3.58) и уравнение регрессии будет иметь вид:
 . . | (3.65) |
Если коэффициент g1 признается статистически значимым на принятом уровне a, то это означает, что разница между рентабельностью частных и государственных предприятий в исследуемой совокупности признается существенной, а фиктивная переменная Z1 введена в модель обоснованно.
Пусть, к примеру, исследуется зависимость рентабельности однородных предприятий (зависимая переменная Y, %) от стоимости основных фондов (фактор X1, млн. руб.) и формы собственности (фиктивная переменная Z1: z1=1— если предприятие негосударственное, z1=0 — если предприятие государственное), и по имеющимся данным было получено уравнение регрессии
 .
.
Базисной моделью здесь является модель рентабельности государственного предприятия (z1=0), уравнение регрессии которой
 .
.
Предположим, что коэффициент при фиктивной переменной Z1 оказался статистически значимым на принятом уровне a=0,05. Тогда можно утверждать, что рентабельность негосударственных предприятий в среднем на 4,34 % выше, чем государственных. Коэффициент регрессии при переменной X1 показывает, что рост стоимости основных фондов на 1 млн. руб. приводит в среднем к снижению рентабельности на 0,032 % как государственных, так и негосударственных предприятий.
Уравнение регрессии модели (3.60) выглядит следующим образом:
 . . | (3.66) |
Пусть, к примеру, коэффициент g11 оказался статистически значимым, а коэффициент g12 — незначимым. Тогда разница между рентабельностью частных и государственных предприятий признается существенной, а разница между рентабельностью кооперативных и государственных предприятий — несущественной. Если t-статистика коэффициента g12 при этом по абсолютной величине меньше единицы, то фиктивную переменную Z12 следует исключить из модели и перейти к построению модели с одной фиктивной переменной (3.58).
Допустим, исследуется зависимость рентабельности однородных предприятий (зависимая переменная Y, %) от стоимости основных фондов (переменная X1, млн. руб.) и формы собственности (бинарные переменные Z11 и Z12: z11=1 — если предприятие частное, z11=0 — во всех остальных случаях; z12=1 — если предприятие кооперативное, z12=0 — во всех остальных случаях), и было построено уравнение регрессии
 .
.
Видно, что рост стоимости основных фондов на 1 млн. руб. приводит к снижению рентабельности всех предприятий в среднем на 0,028 %.
Базисной моделью здесь является модель рентабельности государственного предприятия (z11=0, z12=0), для которой уравнение регрессии
 .
.
Пусть коэффициенты при фиктивных переменных Z11 и Z12 оказались статистически значимыми на принятом уровне a=0,05. Уравнение регрессии частной модели рентабельности частного предприятия (z11=1, z12=0) примет вид:
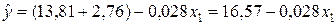 .
.
Таким образом, средняя рентабельность частных предприятий при одинаковой стоимости основных фондов на 2,76 % выше средней рентабельности государственных предприятий.
Аналогично для кооперативных предприятий (z11=0, z12=1) уравнение регрессии частной модели
 .
.
Видно, что рентабельность кооперативных предприятий оказалась в среднем на 1,98 % выше рентабельности государственных предприятий.
Разница между коэффициентами при фиктивных переменных Z11 и Z12 —  %, показывает, на сколько в среднем рентабельность частных предприятий выше рентабельности кооперативных предприятий.
%, показывает, на сколько в среднем рентабельность частных предприятий выше рентабельности кооперативных предприятий.
Уравнение регрессии модели только с фиктивными переменными (3.63) будет иметь вид:
 . . | (3.67) |
Пусть, например, по имеющимся данным было получено уравнение регрессии модели средней стоимости квадратного метра квартиры
 ,
,
и все коэффициенты при фиктивных переменныхоказались статистически значимыми на принятом уровне a. Эти коэффициенты интерпретируются следующим образом: средняя стоимость квадратного метра квартиры на крайних этажах (z3=0) в панельном доме (z2=0), расположенном в периферийном районе города (z1=0), составляет 532,1 у.е.; если дом располагается в центральном районе, то средняя стоимость квадратного метра возрастает на 187,6 у.е.; кирпичный дом дополнительно повышает среднюю стоимость квадратного метра на 142,4 у.е., а расположение квартиры на средних этажах — на 92,3 у.е.
Следует иметь в виду, что надежные оценки параметров модели (3.63) могут быть получены только при построении уравнения регрессии по достаточно большому числу наблюдений. Обычно при построении такой модели объем выборки должен превышать число факторов в шесть и более раз.
Решение типовых задач
Пример 3.1
Изучается зависимость чистой годовой прибылистраховой компании (зависимая переменная Y, тыс. руб.) от следующих факторов:
· X1 — годовой размер собственных средств (тыс. руб.);
· X2 — годовой размер страховых резервов (тыс. руб.);
· X3 — годовой размер страховых премий (тыс. руб.);
· X4 — годовой размер страховых выплат (тыс. руб.);
· X5 — численность страховых агентов;
· X6 — форма собственности (0 — государственная, 1 — частная):
| Компания | Y | X1 | X2 | X3 | X4 | X5 | X6 |
| 1. А | |||||||
| 2. Б | |||||||
| 3. В | |||||||
| 4. Г | |||||||
| 5. Д | |||||||
| 6. Е | |||||||
| 7. Ж | |||||||
| 8. З | |||||||
| 9. И | |||||||
| 10. К | |||||||
| 11. Л | |||||||
| 12. М | |||||||
| 13. Н | |||||||
| 14. О | |||||||
| 15. П | |||||||
| 16. Р | |||||||
| 17. С | |||||||
| 18. Т | |||||||
| 19. У | |||||||
| 20. Ф | |||||||
| 21. Х | |||||||
| 22. Ц | |||||||
| 23. Ч | |||||||
| 24. Ш | |||||||
| 25. Щ | |||||||
| 26. Ю | |||||||
| 27. Я |
1. Составить матрицу парных коэффициентов корреляции между всеми исследуемыми переменными и выявить коллинеарные факторы.
2. Построить уравнение линейной регрессии с полным перечнем факторов. Оценить статистическую значимость уравнения и его коэффициентов с помощью критериев Фишера и Стьюдента.
3. Построить уравнение регрессии, не содержащее коллинеарных факторов. Проверить статистическую значимость уравнения и его коэффициентов.
4. Построить уравнение регрессии, содержащее только информативные факторы. Проверить статистическую значимость уравнения и его коэффициентов.
Пункты 5 — 9 относятся к уравнению регрессии, построенному при выполнении пункта 4.
5. Оценить качество и точность уравнения регрессии.
6. Дать экономическую интерпретацию коэффициентам уравнения регрессии и сравнительную оценку силы связи факторов с результатом.
7. Построить график остатков и проверить выполнение предпосылок обычного метода наименьших квадратов.
8. Рассчитать прогнозное значение годовой прибыли Y, если прогнозные значения факторов составят 75 % от своих максимальных значений.
9. Построить доверительный интервал прогноза фактического значения годовой прибыли Y c надежностью 80 %.
Для решения задачи используем табличный процессор EXCEL.
1. С помощью надстройки «Анализ данных… Корреляция» (см. § 5.2) строим матрицу парных коэффициентов корреляции между всеми исследуемыми переменными (табл. 3.3).
| Таблица | 3.3 |
| Матрица парных коэффициентов корреляции |
| Y | X1 | X2 | X3 | X4 | X5 | X6 |
| Y | ||||||
| X1 | 0,519 | |||||
| X2 | -0,273 | 0,030 | ||||
| X3 | 0,610 | 0,813 | -0,116 | |||
| X4 | -0,572 | -0,013 | -0,022 | -0,091 | ||
| X5 | 0,297 | 0,043 | -0,461 | 0,120 | -0,359 | |
| X6 | 0,118 | -0,366 | -0,061 | -0,329 | -0,100 | -0,290 |
Анализ значений коэффициентов корреляции между парами факторов Х1, Х2, …, Х6 показывает, что только коэффициент корреляции между факторами Х1 и Х3 превышает по абсолютной величине 0,8 (выделен в таблице заливкой). Факторы Х1 и Х3 являются, таким образом, коллинеарными.
2. С помощью надстройки «Анализ данных… Регрессия» (см. § 5.3) строим уравнение линейной регрессии с полным перечнем факторов. Результаты регрессионного анализа в EXCEL приведены в табл. 3.4. Уравнение регрессии с полным перечнем факторов имеет вид:
 .
.
| Таблица | 3.4 |
| Результаты регрессионного анализа модели с полным перечнем факторов |
| Регрессионная статистика | ||||
| Множественный R | 0,887 | |||
| R-квадрат | 0,787 | |||
| Нормированный R-квадрат | 0,723 | |||
| Стандартная ошибка | 230,3 | |||
| Наблюдения | ||||
| Дисперсионный анализ | ||||
| df | SS | MS | F | Значимость F |
| Регрессия | 3921843,8 | 653640,6 | 12,33 | 8,20E-06 |
| Остаток | 1060461,1 | 53023,1 | ||
| Итого | 4982305,0 | |||
| Уравнение регрессии | ||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | |
| Y-пересечение | 541,8 | 610,4 | 0,888 | 0,385 |
| X1 | 0,0680 | 0,0378 | 1,801 | 0,087 |
| X2 | -0,0561 | 0,0359 | -1,562 | 0,134 |
| X3 | 0,0606 | 0,0304 | 1,992 | 0,060 |
| X4 | -0,0998 | 0,0250 | -3,989 | 0,001 |
| X5 | 2,674 | 6,011 | 0,445 | 0,661 |
| X6 | 275,0 | 108,4 | 2,536 | 0,020 |
Проверим статистическую значимость уравнения регрессии. Табличное значение F-критерия Фишера можно определить с помощью встроенной функции EXCEL «FРАСПОБР» (см. § 5.4). Для уровня значимости a=0,05 и чисел степеней свободы числителя (регрессии)  (где p=6 — число факторов в модели) и знаменателя (остатка)
(где p=6 — число факторов в модели) и знаменателя (остатка)  табличное оно составляет Fтаб=2,60.
табличное оно составляет Fтаб=2,60.
Видно, что расчетное значение F-статистики Фишера

превышает табличное (см. «F» втабл. 3.4), что свидетельствует о статистической значимости уравнения регрессии в целом. На этот же факт указывает и то, что вероятность случайного формирования уравнения регрессии в том виде, в котором оно имеется, составляет 8,20×10 -6 (см. «Значимость F» втабл. 3.4), что ниже допустимого уровня значимости a=0,05.
Проверим статистическую значимость коэффициентов уравнения регрессии при факторах Х1, Х2, …, Х6 с помощью t-критерия Стьюдента:
 .
.
Табличное значение t-критерия Стьюдента можно определить с помощью встроенной функции EXCEL «СТЬЮДРАСПОБР» (см. § 5.4). Для уровня значимости a=0,05 и числа степеней свободы остатка df=dfост=20 оно составляет tтаб=2,086. Анализ данных в табл. 3.4показывает, что табличное значение t‑критерия Стьюдента превышают по абсолютной величине t-статистики коэффициентов при факторах Х4, Х6, и эти коэффициенты признаются статистически значимыми. На тот же самый факт указывают и значения вероятности случайного формирования коэффициентов, которые ниже допустимого уровня значимости a=0,05 (см. «P-Значение»втабл. 3.4).
Что касается факторов Х1, Х2, Х3 и Х5 (выделены в табл. 3.4 заливкой), то t‑статистики их коэффициентов меньше по абсолютной величине табличного значения t-критерия Стьюдента, а «P-Значение» выше уровня a=0,05. Данные коэффициенты не признаются статистически значимыми.
Задача №4. Построение регрессионной модели с использованием фиктивной переменной
Исследовать зависимость между результатами зимней (Х) и летней (У) сессий.
В таблице приведена средняя оценка, полученная по итогам сессии, а также указана принадлежность студента к группе А или Б.
| № п/п | х | у | Группа |
|---|---|---|---|
| 1 | 3,7 | 4,8 | Б |
| 2 | 3,5 | 3,5 | Б |
| 3 | 4,3 | 5 | Б |
| 4 | 3 | 4 | Б |
| 5 | 4,6 | 4,2 | Б |
| 6 | 4,6 | 4,1 | Б |
| 7 | 3,8 | 4,8 | А |
| 8 | 3,6 | 3,5 | Б |
| 9 | 3,3 | 4,4 | Б |
| 10 | 3,9 | 3 | Б |
| 11 | 4,7 | 3,7 | Б |
| 12 | 4,6 | 4,4 | Б |
| 13 | 4,6 | 3,8 | Б |
| 14 | 3,3 | 3,1 | Б |
| 15 | 4,3 | 3,6 | Б |
| 16 | 3,1 | 4,8 | А |
| 17 | 3,2 | 3 | А |
| 18 | 4,2 | 4,8 | А |
| 19 | 3,3 | 3,4 | Б |
| 20 | 3,5 | 4,2 | А |
1. Построить линейную регрессионную модель У по Х.
2. Проверить значимость коэффициентов уравнения и самого уравнения регрессии.
3. Построить регрессионную модель У по Х с использованием фиктивной переменной «группа».
4. Проверить значимость коэффициентов уравнения и самого уравнения регрессии.
5. Вычислить коэффициенты детерминации для обычной модели и модели с фиктивной переменной.
Решение:
1. Для расчёта параметров а и b линейной регрессии
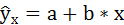
необходимо решить систему нормальных уравнений относительно a и b:
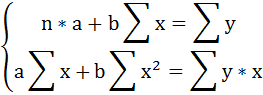
Число наблюдений n = 20.
Построим таблицу исходных и расчётных данных.
Таблица 1 Расчетные данные для оценки линейной регрессии
| № п/п | х | у | х 2 | у 2 | х*у | 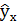 | 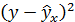 | 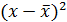 | Группа | z |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3,7 | 4,8 | 13,69 | 23,04 | 17,76 | 3,973 | 0,684 | 0,024 | Б | 1 |
| 2 | 3,5 | 3,5 | 12,25 | 12,25 | 12,25 | 3,931 | 0,186 | 0,126 | Б | 1 |
| 3 | 4,3 | 5 | 18,49 | 25 | 21,5 | 4,098 | 0,814 | 0,198 | Б | 1 |
| 4 | 3 | 4 | 9 | 16 | 12 | 3,827 | 0,030 | 0,731 | Б | 1 |
| 5 | 4,6 | 4,2 | 21,16 | 17,64 | 19,32 | 4,160 | 0,002 | 0,555 | Б | 1 |
| 6 | 4,6 | 4,1 | 21,16 | 16,81 | 18,86 | 4,160 | 0,004 | 0,555 | Б | 1 |
| 7 | 3,8 | 4,8 | 14,44 | 23,04 | 18,24 | 3,994 | 0,650 | 0,003 | А | 0 |
| 8 | 3,6 | 3,5 | 12,96 | 12,25 | 12,6 | 3,952 | 0,204 | 0,065 | Б | 1 |
| 9 | 3,3 | 4,4 | 10,89 | 19,36 | 14,52 | 3,889 | 0,261 | 0,308 | Б | 1 |
| 10 | 3,9 | 3 | 15,21 | 9 | 11,7 | 4,014 | 1,029 | 0,002 | Б | 1 |
| 11 | 4,7 | 3,7 | 22,09 | 13,69 | 17,39 | 4,181 | 0,232 | 0,714 | Б | 1 |
| 12 | 4,6 | 4,4 | 21,16 | 19,36 | 20,24 | 4,160 | 0,057 | 0,555 | Б | 1 |
| 13 | 4,6 | 3,8 | 21,16 | 14,44 | 17,48 | 4,160 | 0,130 | 0,555 | Б | 1 |
| 14 | 3,3 | 3,1 | 10,89 | 9,61 | 10,23 | 3,889 | 0,623 | 0,308 | Б | 1 |
| 15 | 4,3 | 3,6 | 18,49 | 12,96 | 15,48 | 4,098 | 0,248 | 0,198 | Б | 1 |
| 16 | 3,1 | 4,8 | 9,61 | 23,04 | 14,88 | 3,848 | 0,907 | 0,570 | А | 0 |
| 17 | 3,2 | 3 | 10,24 | 9 | 9,6 | 3,868 | 0,754 | 0,429 | А | 0 |
| 18 | 4,2 | 4,8 | 17,64 | 23,4 | 20,16 | 4,077 | 0,523 | 0,119 | А | 0 |
| 19 | 3,3 | 3,4 | 10,89 | 11,56 | 11,22 | 3,889 | 0,239 | 0,308 | Б | 1 |
| 20 | 3,5 | 4,2 | 12,25 | 17,64 | 14,7 | 3,930 | 0,072 | 0,126 | А | 0 |
| Итого: | 77,1 | 80,1 | 303,67 | 328,73 | 310,13 | 80,1 | 7,649 | 6,45 | х | 15 |
| Среднее: | 3,855 | 4,005 | 15,184 | 16,4365 | 15,5065 | х | х | х | х | х |
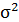 | 0,322 | 0,396 | х | х | х | х | х | х | х | х |
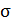 | 0,568 | 0,630 | х | х | х | х | х | х | х | х |
Среднее значение определим по формуле:
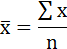
Среднее квадратическое отклонение рассчитаем по формуле:
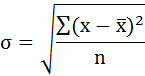
Возведя в квадрат полученное значение, получим дисперсию:
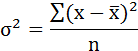
Параметры уравнения можно определить также и по формулам:
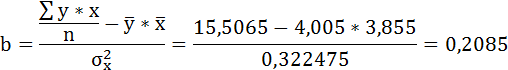
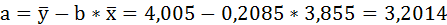
Таким образом, уравнение регрессии имеет вид:
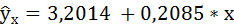
Следовательно, с повышением средней оценки, полученной по итогам зимней сессии, на один балл, средняя оценка по итогам летней сессии увеличивается в среднем на 0,2085.
2. Рассчитаем линейный коэффициент парной корреляции:
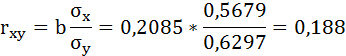
Связь очень слабая, практически отсутствует.
Определим коэффициент детерминации:
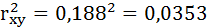
Вариация результата на 3,53% объясняется вариацией фактора х. На долю других, не учтённых в модели факторов, приходится 96,47%. Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчётные) значения .
Так как 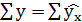 , следовательно, параметры уравнения определены верно.
, следовательно, параметры уравнения определены верно.
3. Проверим значимость коэффициентов уравнения и самого уравнения регрессии.
Оценку качества уравнения регрессии проведём с помощью F-критерия Фишера.
F-критерий состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера.
Fфакт определяется по формуле:
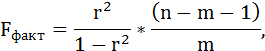
где n – число единиц совокупности;
m – число параметров при переменных х.
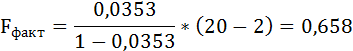
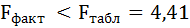
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик принимается и признаётся их статистическая незначимость и ненадёжность.
4. Оценку статистической значимости коэффициентов регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля: a = b = rxy = 0.
tтабл = 2,1 для числа степеней свободы df = n – 2 = 18 и α = 0,05 .
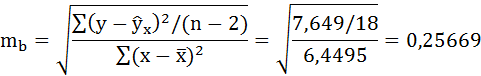
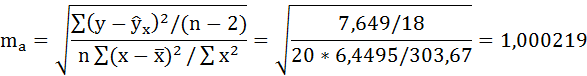
Фактические значения t-статистики определим по формулам:
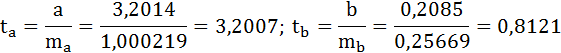
t-критерий для коэффициента корреляции можно рассчитать двумя способами:
1) 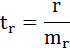
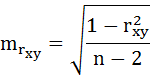 – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
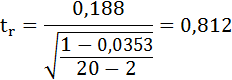
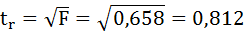
Сравним фактические значения t-статистики с табличными значениями.
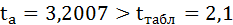
Так как фактическое значение t-критерия для коэффициента а превышает табличное, следовательно, гипотезу о несущественности коэффициента а можно отклонить.
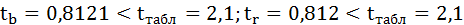
Величина t-критерия для коэффициента регрессии меньше табличного и совпадает с величиной tr.
Следовательно, полученная линейная зависимость является недостоверной.
5. По 20 наблюдениям уравнение линейной регрессии (без учёта принадлежности студента к группе А или Б) составило:
Введём в уравнение регрессии фиктивную переменную z для отражения принадлежности студента к группе, а именно: z = 1, для группы Б и z = 0 для группы А. Уравнение регрессии примет вид:
уxz = a + b*x + c*z + ɛ
Применяя метод наименьших квадратов для оценки параметров данного уравнения, получим следующую систему нормальных уравнений:
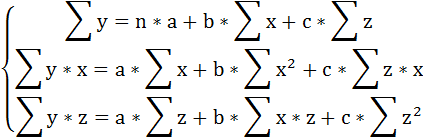
В виду того, что z принимает лишь два значения (1 и 0), Σz = n1 = 15 (число студентов группы Б), Σх*z =Σх1 =59,3 (сумма х по группе Б), Σz2 =Σz =15, Σy*z =Σy1 =58,5 (сумма у по группе Б).
Тогда система нормальных уравнений примет вид:
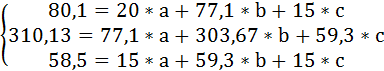
Решая её, получим уравнение регрессии:
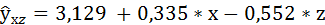
6. Найдём индекс детерминации для данной модели по формуле:
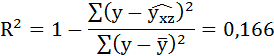
Добавление в регрессию фиктивной переменной существенно улучшило результат модели: доля объяснённой вариации выросла с 3,53% (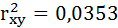 ) до 16,6% ( Rухz 2 = 0,166 ). Но, не смотря на это, связь между признаками остаётся слабой.
) до 16,6% ( Rухz 2 = 0,166 ). Но, не смотря на это, связь между признаками остаётся слабой.
7. Значимость уравнения множественной регрессии в целом, так же как и в парной регрессии, оценивается с помощью F-критерия Фишера:
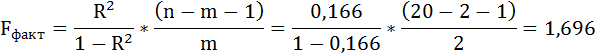
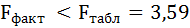
Так как фактическое значение F-критерия меньше табличного, то уравнение статистически не значимо.
8. Оценка значимости коэффициентов регрессии производится, как и в парной регрессии по t-критерию Стьюдента, по формуле:
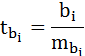
где bi – величина параметра регрессии (в наших обозначениях это a, b и с)
a = 3,129; b = 0,335; с = — 0,5516;
Величина t-статистики коэффициентов регрессии b и c меньше табличного tтабл.=2,1 при уровне значимости α 0,05, что свидетельствует о случайной природе взаимосвязи, о статистической ненадёжности всего уравнения.
Таким образом, уравнение в целом незначимо и ненадёжно и не может использоваться в дальнейшем для анализа и прогноза.
http://lektsii.org/3-35817.html
http://ecson.ru/economics/econometrics/zadacha-4.postroenie-regressionnoy-modeli-s-ispolzovaniem-fiktivnoy-peremennoy.html