Решения задач: линейная регрессия и коэффициент корреляции
Парная линейная регрессия — это зависимость между одной переменной и средним значением другой переменной. Чаще всего модель записывается как $y=ax+b+e$, где $x$ — факторная переменная, $y$ — результативная (зависимая), $e$ — случайная компонента (остаток, отклонение).
В учебных задачах по математической статистике обычно используется следующий алгоритм для нахождения уравнения регрессии.
- Выбор модели (уравнения). Часто модель задана заранее (найти линейную регрессию) или для подбора используют графический метод: строят диаграмму рассеяния и анализируют ее форму.
- Вычисление коэффициентов (параметров) уравнения регрессии. Часто для этого используют метод наименьших квадратов.
- Проверка значимости коэффициента корреляции и параметров модели (также для них можно построить доверительные интервалы), оценка качества модели по критерию Фишера.
- Анализ остатков, вычисление стандартной ошибки регрессии, прогноз по модели (опционально).
Ниже вы найдете решения для парной регрессии (по рядам данных или корреляционной таблице, с разными дополнительными заданиями) и пару задач на определение и исследование коэффициента корреляции.
Примеры решений онлайн: линейная регрессия
Простая выборка
Пример 1. Имеются данные средней выработки на одного рабочего Y (тыс. руб.) и товарооборота X (тыс. руб.) в 20 магазинах за квартал. На основе указанных данных требуется:
1) определить зависимость (коэффициент корреляции) средней выработки на одного рабочего от товарооборота,
2) составить уравнение прямой регрессии этой зависимости.
Пример 2. С целью анализа взаимного влияния зарплаты и текучести рабочей силы на пяти однотипных фирмах с одинаковым числом работников проведены измерения уровня месячной зарплаты Х и числа уволившихся за год рабочих Y:
X 100 150 200 250 300
Y 60 35 20 20 15
Найти линейную регрессию Y на X, выборочный коэффициент корреляции.
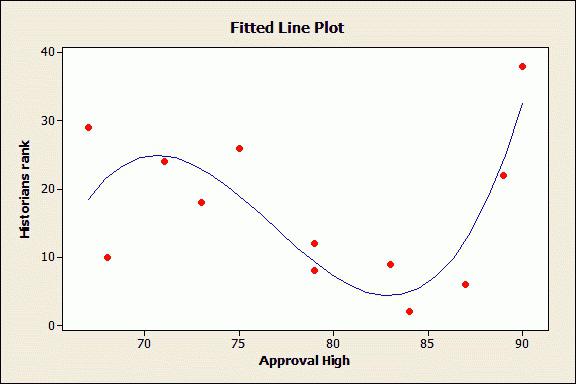
Пример 3. Найти выборочные числовые характеристики и выборочное уравнение линейной регрессии $y_x=ax+b$. Построить прямую регрессии и изобразить на плоскости точки $(x,y)$ из таблицы. Вычислить остаточную дисперсию. Проверить адекватность линейной регрессионной модели по коэффициенту детерминации.
Пример 4. Вычислить коэффициенты уравнения регрессии. Определить выборочный коэффициент корреляции между плотностью древесины маньчжурского ясеня и его прочностью.
Решая задачу необходимо построить поле корреляции, по виду поля определить вид зависимости, написать общий вид уравнения регрессии Y на Х, определить коэффициенты уравнения регрессии и вычислить коэффициенты корреляции между двумя заданными величинами.
Пример 5. Компанию по прокату автомобилей интересует зависимость между пробегом автомобилей X и стоимостью ежемесячного технического обслуживания Y. Для выяснения характера этой связи было отобрано 15 автомобилей. Постройте график исходных данных и определите по нему характер зависимости. Рассчитайте выборочный коэффициент линейной корреляции Пирсона, проверьте его значимость при 0,05. Постройте уравнение регрессии и дайте интерпретацию полученных результатов.
Корреляционная таблица
Пример 6. Найти выборочное уравнение прямой регрессии Y на X по заданной корреляционной таблице
Пример 7. В таблице 2 приведены данные зависимости потребления Y (усл. ед.) от дохода X (усл. ед.) для некоторых домашних хозяйств.
1. В предположении, что между X и Y существует линейная зависимость, найдите точечные оценки коэффициентов линейной регрессии.
2. Найдите стандартное отклонение $s$ и коэффициент детерминации $R^2$.
3. В предположении нормальности случайной составляющей регрессионной модели проверьте гипотезу об отсутствии линейной зависимости между Y и X.
4. Каково ожидаемое потребление домашнего хозяйства с доходом $x_n=7$ усл. ед.? Найдите доверительный интервал для прогноза.
Дайте интерпретацию полученных результатов. Уровень значимости во всех случаях считать равным 0,05.
Пример 8. Распределение 100 новых видов тарифов на сотовую связь всех известных мобильных систем X (ден. ед.) и выручка от них Y (ден.ед.) приводится в таблице:
Необходимо:
1) Вычислить групповые средние и построить эмпирические линии регрессии;
2) Предполагая, что между переменными X и Y существует линейная корреляционная зависимость:
А) найти уравнения прямых регрессии, построить их графики на одном чертеже с эмпирическими линиями регрессии и дать экономическую интерпретацию полученных уравнений;
Б) вычислить коэффициент корреляции, на уровне значимости 0,05 оценить его значимость и сделать вывод о тесноте и направлении связи между переменными X и Y;
В) используя соответствующее уравнение регрессии, оценить среднюю выручку от мобильных систем с 20 новыми видами тарифов.
Коэффициент корреляции
Пример 9. На основании 18 наблюдений установлено, что на 64% вес X кондитерских изделий зависит от их объема Y. Можно ли на уровне значимости 0,05 утверждать, что между X и Y существует зависимость?
Пример 10. Исследование 27 семей по среднедушевому доходу (Х) и сбережениям (Y) дало результаты: $\overline
Парная линейная регрессия. Задачи регрессионного анализа
Будут и задачи для самостоятельного решения, к которым можно посмотреть ответы.
Понятие линейной регрессии. Парная линейная регрессия
Линейная регрессия — выраженная в виде прямой зависимость среднего значения какой-либо величины от некоторой другой величины. В отличие от функциональной зависимости y = f(x) , когда каждому значению независимой переменной x соответствует одно определённое значение величины y, при линейной регрессии одному и тому же значению x могут соответствовать в зависимости от случая различные значения величины y.
Если в результате наблюдения установлено, что при каждом определённом значении x существует сколько-то (n) значений переменной y, то зависимость средних арифметических значений y от x и является регрессией в статистическом понимании.
Если установленная зависимость может быть записана в виде уравнения прямой
то эта регрессионная зависимость называется линейной регрессией.
О парной линейной регрессии говорят, когда установлена зависимость между двумя переменными величинами (x и y). Парная линейная регрессия называется также однофакторной линейной регрессией, так как один фактор (независимая переменная x) влияет на результирующую переменную (зависимую переменную y).
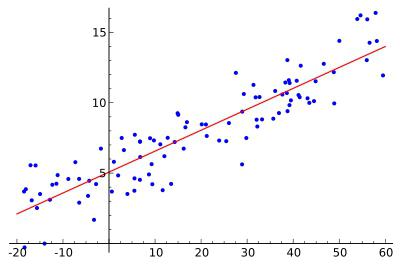
В уроке о корреляционной зависимости были разобраны примеры того, как цена на квартиры зависит от общей площади квартиры и от площади кухни (две различные независимые переменные) и о том, что результаты наблюдений расположены в некотором приближении к прямой, хотя и не на самой прямой. Если точки корреляционной диаграммы соединить ломанной линией, то будет получена линия эмпирической регрессии. А если эта линия будет выровнена в прямую, то полученная прямая будет прямой теоретической регрессии. На рисунке ниже она красного цвета (для увеличения рисунка щёлкнуть по нему левой кнопкой мыши).

По этой прямой теоретической регрессии может быть сделан прогноз или восстановление неизвестных значений зависимой переменной по заданным значениям независимой переменной.
В случае парной линейной регрессии для данных генеральной совокупности связь между независимой переменной (факториальным признаком) X и зависимой переменной (результативным признаком) Y описывает модель
 ,
,
 — свободный член прямой парной линейной регрессии,
— свободный член прямой парной линейной регрессии,
 — коэффициент направления прямой парной линейной регрессии,
— коэффициент направления прямой парной линейной регрессии,
 — случайная погрешность,
— случайная погрешность,
N — число элементов генеральной совокупности.
Уравнение парной линейной регрессии для генеральной совокупности можно построить, если доступны данные обо всех элементах генеральной совокупности. На практике данные всей генеральной совокупности недоступны, но доступны данные об элементах некоторой выборки.
Поэтому параметры генеральной совокупности оценивают при помощи соответствующих параметров соответствующей выборки: свободный член прямой парной линейной регрессии генеральной совокупности заменяют на свободный член прямой парной линейной регрессии выборки  , а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки
, а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки  .
.
В результате получаем уравнение парной линейной регрессии выборки


 — оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
— оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
 — погрешность,
— погрешность,
n — размер выборки.
Чтобы уравнение парной линейной регрессии было более похоже на привычное уравнение прямой, его часто также записывают в виде
 .
.
Уравнение парной линейной регрессии и метод наименьших квадратов
Определение коэффициентов уравнения парной линейной регрессии
Если заранее известно, что зависимость между факториальным признаком x и результативным признаком y должна быть линейной, выражающейся в виде уравнения типа , задача сводится к нахождению по некоторой группе точек наилучшей прямой, называемой прямой парной линейной регрессии. Следует найти такие значения коэффициентов a и b , чтобы сумма квадратов отклонений  была наименьшей:
была наименьшей:
 .
.
Если через  и
и  обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
- прямая парной линейной регрессии проходит через точку
 ;
; - среднее значение отклонений равна нулю: ;
- значения и не связаны: .
 ;
; ;
; и
и  не связаны:
не связаны:  .
.Условие метода наименьших квадратов выполняется, если значения коэффициентов равны:
 ,
,
 .
.
Пример 1. Найти уравнение парной линейной регрессии зависимости между валовым внутренним продуктом (ВВП) и частным потреблением на основе данных примера урока о корреляционной зависимости (эта ссылка, которая откроется в новом окне, потребуется и при разборе следующих примеров).
Решение. Используем рассчитанные в решении названного выше примера суммы:




Используя эти суммы, вычислим коэффициенты:


Таким образом получили уравнение прямой парной линейной регрессии:

Составить уравнение парной линейной регрессии самостоятельно, а затем посмотреть решение
Пример 2. Найти уравнение парной линейной регрессии для выборки из 6 наблюдений, если уже вычислены следующие промежуточные результаты:
 ;
;
 ;
;
 ;
;
 ;
;
Анализ качества модели линейной регрессии
Метод наименьших квадратов имеет по меньшей мере один существенный недостаток: с его помощью можно найти уравнение линейной регрессии и в тех случаях, когда данные наблюдений значительно рассеяны вокруг прямой регрессии, то есть находятся на значительном расстоянии от этой прямой. В таких случаях за точность прогноза значений зависимой переменной ручаться нельзя. Существуют показатели, которые позволяют оценить качество уравнения линейной регрессии прежде чем использовать модели линейной регрессии для практических целей. Разберём важнейшие из этих показателей.
Коэффициент детерминации
Коэффициент детерминации  принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
 ,
,
 — сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
— сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
 — общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
— общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
 — сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
— сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
Пример 3. Даны сумма квадратов отклонений, объясняемых моделью линейной регрессии (3500), общая сумма квадратов отклонений (5000) и сумма квадратов отклонений ошибки (1500). Найти коэффициент детерминации двумя способами.
F-статистика (статистика Фишера) для проверки качества модели линейной регрессии
Минимальное возможное значение F-статистики — 0. Чем выше значение статистики Фишера, тем качественнее модель линейной регрессии. Этот показатель представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы):

где m — число объясняющих переменных.
Сумма квадратов остатков
Сумма квадратов остатков (RSS) измеряет необъясненную часть дисперсии зависимой переменной:

 —
—
остатки — разности между реальными значениями зависимой переменной и значениями, оценёнными уравнением линейной регрессии.
В случае качественной модели линейной регрессии сумма квадратов остатков стремится к нулю.
Стандартная ошибка регрессии
Стандартная ошибка регрессии (SEE) измеряет величину квадрата ошибки, приходящейся на одну степень свободы модели:

Чем меньше значение SEE, тем качественнее модель.
Пример 4. Рассчитать коэффициент детерминации для данных из примера 1.
Решение. На основании данных таблицы (она была приведена в примере урока о корреляционной зависимости) получаем, что SST = 63 770,593 , SSE = 10 459,587 , SSR = 53 311,007 .
Можем убедиться, что выполняется закономерность SSR = SST — SSE :
Получаем коэффициент детерминации:
 .
.
Таким образом, 83,6% изменений частного потребления можно объяснить моделью линейной регресии.
Интерпретация коэффициентов уравнения парной линейной регрессии и прогноз значений зависимой переменной
Итак, уравнение парной линейной регрессии:
 .
.
В этом уравнении a — свободный член, b — коэффициент при независимой переменной.
Интерпретация свободного члена: a показывает, на сколько единиц график регрессии смещён вверх при x=0, то есть значение переменной y при нулевом значении переменной x.
Интерпретация коэффициента при независимой переменной: b показывает, на сколько единиц изменится значение зависимой переменной y при изменении x на одну единицу.
Пример 5. Зависимость частного потребления граждан от ВВП (истолкуем это просто: от дохода) описывается уравнением парной линейной регрессии  . Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
. Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
Решение. Подставляем в уравнение парной линейной регрессии x i = 20000 и получаем прогноз потребления при доходе в 20 000 у.е. y i = 17036,4662 .
Подставляем в уравнение парной линейной регрессии x i = 5000 и получаем прогноз увеличения потребления при увеличении дохода на 5000 у.е. y i = 4161,9662 .
Если доход не меняется, то x i = 0 и получаем, что потребление уменьшается на 129,5338 у.е.
Задачи регрессионного анализа
Регрессионный анализ — раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным.
Наиболее частые задачи регрессионного анализа:
- установление факта наличия или отсутствия статистических зависимостей между переменными величинами;
- выявление причинных связей между переменными величинами;
- прогноз или восстановление неизвестных значений зависимых переменных по заданным значениям независимых переменных.
Также делаются проверки статистических гипотез о регрессии. Кроме того, при изучении связи между двумя величинами по результатам наблюдений в соответствии с теорией регрессии предполагается, что зависимая переменная имеет некоторое распределение вероятностей при фиксированном значении независимой переменной.
В исследованиях поведения человека, чтобы они претендовали на объективность, важно не только установить зависимость между факторами, но и получить все необходимые статистические показатели для результата проверки соответствующей гипотезы.
Проверка гипотезы о равенстве нулю коэффициента направления прямой парной линейной регрессии
Одна из важнейших гипотез в регрессионном анализе — гипотеза о том, что коэффициент направления прямой регрессии генеральной совокупности равен нулю.
Если это предположение верно, то изменения независимой переменной X не влияют на изменения зависимой переменной Y: переменные X и Y не коррелированы, то есть линейной зависимости Y от X нет.

рассматривают во взаимосвязи с альтернативной гипотезой
 .
.
Статистика коэффициента направления

соответствует распределению Стьюдента с числом степеней свободы v = n — 2 ,
где  — стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
— стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
Доверительный интервал коэффициента направления прямой линейной регрессии:
 .
.
Критическая область, в которой с вероятностью P = 1 — α отвергают нулевую гипотезу и принимают альтернативную гипотезу:

Пример 6. На основе данных из предыдущих примеров (о ВВП и частном потреблении) определить доверительный интервал коэффициента направления прямой линейной регресии 95% и проверить гипотезу о равенстве нулю коэффициента направления прямой парной линейной регрессии.
Можем рассчитать, что  , а стандартная погрешность регрессии
, а стандартная погрешность регрессии  .
.
Таким образом, стандартная погрешность коэффициента направления прямой линейной регресии b 1 :
 .
.
Так как  и
и  (находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
(находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
 .
.
Так как гипотетическое значение коэффициента — нуль — не принадлежит доверительному интервалу, с вероятностью 95% можем отвергнуть основную гипотезу и принять альтернативную гипотезу, то есть считать, что зависимая переменная Y линейно зависит от независимой переменной X.
Уравнение регрессии. Уравнение множественной регрессии
Во время учебы студенты очень часто сталкиваются с разнообразными уравнениями. Одно из них – уравнение регрессии — рассмотрено в данной статье. Такой тип уравнения применяется специально для описания характеристики связи между математическими параметрами. Данный вид равенств используют в статистике и эконометрике.
Определение понятия регрессии
В математике под регрессией подразумевается некая величина, описывающая зависимость среднего значения совокупности данных от значений другой величины. Уравнение регрессии показывает в качестве функции определенного признака среднее значение другого признака. Функция регрессии имеет вид простого уравнения у = х, в котором у выступает зависимой переменной, а х – независимой (признак-фактор). Фактически регрессия выражаться как у = f (x).
Какие бывают типы связей между переменными
В общем, выделяется два противоположных типа взаимосвязи: корреляционная и регрессионная.
Первая характеризуется равноправностью условных переменных. В данном случае достоверно не известно, какая переменная зависит от другой.
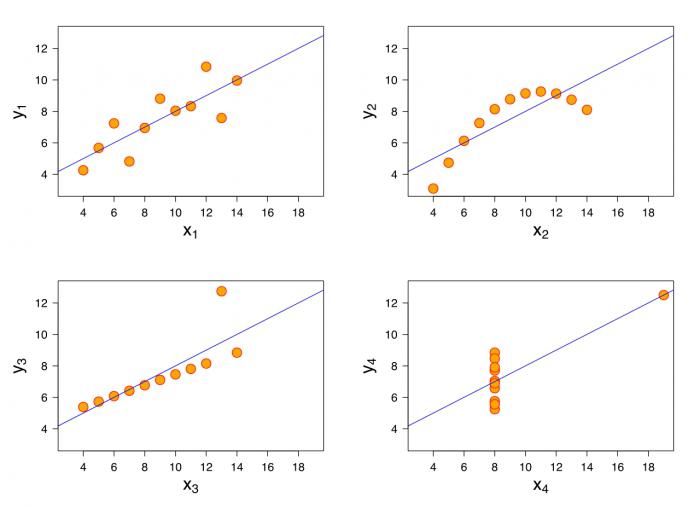
Если же между переменными не наблюдается равноправности и в условиях сказано, какая переменная объясняющая, а какая – зависимая, то можно говорить о наличии связи второго типа. Для того чтобы построить уравнение линейной регрессии, необходимо будет выяснить, какой тип связи наблюдается.
Виды регрессий
На сегодняшний день выделяют 7 разнообразных видов регрессии: гиперболическая, линейная, множественная, нелинейная, парная, обратная, логарифмически линейная.
Гиперболическая, линейная и логарифмическая
Уравнение линейной регрессии применяют в статистике для четкого объяснения параметров уравнения. Оно выглядит как у = с+т*х+Е. Гиперболическое уравнение имеет вид правильной гиперболы у = с + т / х + Е. Логарифмически линейное уравнение выражает взаимосвязь с помощью логарифмической функции: In у = In с + т* In x + In E.
Множественная и нелинейная
Два более сложных вида регрессии – это множественная и нелинейная. Уравнение множественной регрессии выражается функцией у = f(х1 , х2 . хс)+E. В данной ситуации у выступает зависимой переменной, а х – объясняющей. Переменная Е — стохастическая, она включает влияние других факторов в уравнении. Нелинейное уравнение регрессии немного противоречиво. С одной стороны, относительно учтенных показателей оно не линейное, а с другой стороны, в роли оценки показателей оно линейное.
Обратные и парные виды регрессий
Обратная – это такой вид функции, который необходимо преобразовать в линейный вид. В самых традиционных прикладных программах она имеет вид функции у = 1/с + т*х+Е. Парное уравнение регрессии демонстрирует взаимосвязь между данными в качестве функции у = f (x) + Е. Точно так же, как и в других уравнениях, у зависит от х, а Е — стохастический параметр.
Понятие корреляции
Это показатель, демонстрирующий существование взаимосвязи двух явлений или процессов. Сила взаимосвязи выражается в качестве коэффициента корреляции. Его значение колеблется в рамках интервала [-1;+1]. Отрицательный показатель говорит о наличии обратной связи, положительный – о прямой. Если коэффициент принимает значение, равное 0, то взаимосвязи нет. Чем ближе значение к 1 – тем сильнее связь между параметрами, чем ближе к 0 – тем слабее.
Методы
Корреляционные параметрические методы могут оценить тесноту взаимосвязи. Их используют на базе оценки распределения для изучения параметров, подчиняющихся закону нормального распределения.
Параметры уравнения линейной регрессии необходимы для идентификации вида зависимости, функции регрессионного уравнения и оценивания показателей избранной формулы взаимосвязи. В качестве метода идентификации связи используется поле корреляции. Для этого все существующие данные необходимо изобразить графически. В прямоугольной двухмерной системе координат необходимо нанести все известные данные. Так образуется поле корреляции. Значение описывающего фактора отмечаются вдоль оси абсцисс, в то время как значения зависимого – вдоль оси ординат. Если между параметрами есть функциональная зависимость, они выстраиваются в форме линии.
В случае если коэффициент корреляции таких данных будет менее 30 %, можно говорить о практически полном отсутствии связи. Если он находится между 30 % и 70 %, то это говорит о наличии связей средней тесноты. 100 % показатель – свидетельство функциональной связи.
Нелинейное уравнение регрессии так же, как и линейное, необходимо дополнять индексом корреляции (R).
Корреляция для множественной регрессии
Коэффициент детерминации является показателем квадрата множественной корреляции. Он говорит о тесноте взаимосвязи представленного комплекса показателей с исследуемым признаком. Он также может говорить о характере влияния параметров на результат. Уравнение множественной регрессии оценивают с помощью этого показателя.
Для того чтобы вычислить показатель множественной корреляции, необходимо рассчитать его индекс.
Метод наименьших квадратов
Данный метод является способом оценивания факторов регрессии. Его суть заключается в минимизировании суммы отклонений в квадрате, полученных вследствие зависимости фактора от функции.
Парное линейное уравнение регрессии можно оценить с помощью такого метода. Этот тип уравнений используют в случае обнаружения между показателями парной линейной зависимости.
Параметры уравнений
Каждый параметр функции линейной регрессии несет определенный смысл. Парное линейное уравнение регрессии содержит два параметра: с и т. Параметр т демонстрирует среднее изменение конечного показателя функции у, при условии уменьшения (увеличения) переменной х на одну условную единицу. Если переменная х – нулевая, то функция равняется параметру с. Если же переменная х не нулевая, то фактор с не несет в себе экономический смысл. Единственное влияние на функцию оказывает знак перед фактором с. Если там минус, то можно сказать о замедленном изменении результата по сравнению с фактором. Если там плюс, то это свидетельствует об ускоренном изменении результата.
Каждый параметр, изменяющий значение уравнения регрессии, можно выразить через уравнение. Например, фактор с имеет вид с = y – тх.
Сгруппированные данные
Бывают такие условия задачи, в которых вся информация группируется по признаку x, но при этом для определенной группы указываются соответствующие средние значения зависимого показателя. В таком случае средние значения характеризуют, каким образом изменяется показатель, зависящий от х. Таким образом, сгруппированная информация помогает найти уравнение регрессии. Ее используют в качестве анализа взаимосвязей. Однако у такого метода есть свои недостатки. К сожалению, средние показатели достаточно часто подвергаются внешним колебаниям. Данные колебания не являются отображением закономерности взаимосвязи, они всего лишь маскируют ее «шум». Средние показатели демонстрируют закономерности взаимосвязи намного хуже, чем уравнение линейной регрессии. Однако их можно применять в виде базы для поиска уравнения. Перемножая численность отдельной совокупности на соответствующую среднюю можно получить сумму у в пределах группы. Далее необходимо подбить все полученные суммы и найти конечный показатель у. Чуть сложнее производить расчеты с показателем суммы ху. В том случае если интервалы малы, можно условно взять показатель х для всех единиц (в пределах группы) одинаковым. Следует перемножить его с суммой у, чтобы узнать сумму произведений x на у. Далее все суммы подбиваются вместе и получается общая сумма ху.
Множественное парное уравнение регрессии: оценка важности связи
Как рассматривалось ранее, множественная регрессия имеет функцию вида у = f (x1,x2,…,xm)+E. Чаще всего такое уравнение используют для решения проблемы спроса и предложения на товар, процентного дохода по выкупленным акциям, изучения причин и вида функции издержек производства. Ее также активно применяют в самых разнообразным макроэкономических исследованиях и расчетах, а вот на уровне микроэкономики такое уравнение применяют немного реже.
Основной задачей множественной регрессии является построение модели данных, содержащих огромное количество информации, для того чтобы в дальнейшем определить, какое влияние имеет каждый из факторов по отдельности и в их общей совокупности на показатель, который необходимо смоделировать, и его коэффициенты. Уравнение регрессии может принимать самые разнообразные значения. При этом для оценки взаимосвязи обычно используется два типа функций: линейная и нелинейная.
Линейная функция изображается в форме такой взаимосвязи: у = а0 + a1х1 + а2х2,+ . + amxm. При этом а2, am, считаются коэффициентами «чистой» регрессии. Они необходимы для характеристики среднего изменения параметра у с изменением (уменьшением или увеличением) каждого соответствующего параметра х на одну единицу, с условием стабильного значения других показателей.
Нелинейные уравнения имеют, к примеру, вид степенной функции у=ах1 b1 х2 b2 . xm bm . В данном случае показатели b1, b2. bm – называются коэффициентами эластичности, они демонстрируют, каким образом изменится результат (на сколько %) при увеличении (уменьшении) соответствующего показателя х на 1 % и при стабильном показателе остальных факторов.
Какие факторы необходимо учитывать при построении множественной регрессии
Для того чтобы правильно построить множественную регрессию, необходимо выяснить, на какие именно факторы следует обратить особое внимание.
Необходимо иметь определенное понимание природы взаимосвязей между экономическими факторами и моделируемым. Факторы, которые необходимо будет включать, обязаны отвечать следующим признакам:
- Должны быть подвластны количественному измерению. Для того чтобы использовать фактор, описывающий качество предмета, в любом случае следует придать ему количественную форму.
- Не должна присутствовать интеркорреляция факторов, или функциональная взаимосвязь. Такие действия чаще всего приводят к необратимым последствиям – система обыкновенных уравнений становится не обусловленной, а это влечет за собой ее ненадежность и нечеткость оценок.
- В случае существования огромного показателя корреляции не существует способа для выяснения изолированного влияния факторов на окончательный результат показателя, следовательно, коэффициенты становятся неинтерпретируемыми.
Методы построения
Существует огромное количество методов и способов, объясняющих, каким образом можно выбрать факторы для уравнения. Однако все эти методы строятся на отборе коэффициентов с помощью показателя корреляции. Среди них выделяют:
- Способ исключения.
- Способ включения.
- Пошаговый анализ регрессии.
Первый метод подразумевает отсев всех коэффициентов из совокупного набора. Второй метод включает введение множества дополнительных факторов. Ну а третий – отсев факторов, которые были ранее применены для уравнения. Каждый из этих методов имеет право на существование. У них есть свои плюсы и минусы, но они все по-своему могут решить вопрос отсева ненужных показателей. Как правило, результаты, полученные каждым отдельным методом, достаточно близки.
Методы многомерного анализа
Такие способы определения факторов базируются на рассмотрении отдельных сочетаний взаимосвязанных признаков. Они включают в себя дискриминантный анализ, распознание обликов, способ главных компонент и анализ кластеров. Кроме того, существует также факторный анализ, однако он появился вследствие развития способа компонент. Все они применяются в определенных обстоятельствах, при наличии определенных условий и факторов.
http://function-x.ru/statistics_regression1.html
http://www.syl.ru/article/178055/new_uravnenie-regressii-uravnenie-mnojestvennoy-regressii