Как построить график в Excel по уравнению
Как предоставить информацию, чтобы она лучше воспринималась. Используйте графики. Это особенно актуально в аналитике. Рассмотрим, как построить график в Excel по уравнению.
Что это такое
График показывает, как одни величины зависят от других. Информация легче воспринимается. Посмотрите визуально, как отображается динамика изменения данных.
А нужно ли это
Графический способ отображения информации востребован в учебных или научных работах, исследованиях, при создании деловых планов, отчетов, презентаций, формул. Разработчики для построения графиков добавили способы визуального представления: диаграммы, пиктограммы.
Как построить график уравнения регрессии в Excel
Регрессионный анализ — статистический метод исследования. Устанавливает, как независимые величины влияют на зависимую переменную. Редактор предлагает инструменты для такого анализа.
Подготовительные работы
Перед использованием функции активируйте Пакет анализа. Перейдите: 
Выберите раздел: 
Далее: 
Прокрутите окно вниз, выберите: 
Отметьте пункт: 
Открыв раздел «Данные», появится кнопка «Анализ». 
Как пользоваться
Рассмотрим на примере. В таблице указана температура воздуха и число покупателей. Данные выводятся за рабочий день. Как температура влияет на посещаемость. Перейдите: 
Выберите: 
Отобразится окно настроек, где входной интервал:
- Y. Ячейки с данными влияние факторов на которые нужно установить. Это число покупателей. Адрес пропишите вручную или выделите соответствующий столбец;
- Х. Данные, влияние на которые нужно установить. В примере, нужно узнать, как температура влияет на количество покупателей. Поэтому выделяем ячейки в столбце «Температура».

Анализ
Нажав кнопку «ОК», отобразится результат. 
Основной показатель — R-квадрат. Обозначает качество. Он равен 0,825 (82,5%). Что это означает? Зависимости, где показатель меньше 0,5 считается плохим. Поэтому в примере это хороший показатель. Y-пересечение. Число покупателей, если другие показатели равны нулю. 62,02 высокий показатель.
Как построить график квадратного уравнения в Excel
График функции имеет вид: y=ax2+bx+c. Рассмотрим диапазон значений: [-4:4].
- Составьте таблицу как на скриншоте;
- В третьей строке указываем коэффициенты и их значения;
- Пятая — диапазон значений;
- В ячейку B6 вписываем формулу =$B3*B5*B5+$D3*B5+$F3;
 Копируем её на весь диапазон значений аргумента вправо.
Копируем её на весь диапазон значений аргумента вправо. 
При вычислении формулы прописывается знак «$». Используется чтобы ссылка была постоянной. Подробнее смотрите в статье: «Как зафиксировать ячейку».
Выделите диапазон значений по ним будем строить график. Перейдите: 
Поместите график в свободное место на листе. 
Как построить график линейного уравнения
Функция имеет вид: y=kx+b. Построим в интервале [-4;4].
- В таблицу прописываем значение постоянных величин. Строка три;
- Строка 5. Вводим диапазон значений;
- Ячейка В6. Прописываем формулу.
 Выделите диапазон ячеек A5:J6. Далее:
Выделите диапазон ячеек A5:J6. Далее: 
График — прямая линия. 
Вывод
Мы рассмотрели, как построить график в Экселе (Excel) по уравнению. Главное — правильно выбрать параметры и диаграмму. Тогда график точно отобразит данные.
Функция ЛИНЕЙН
В этой статье описаны синтаксис формулы и использование функции LINEST в Microsoft Excel. Ссылки на дополнительные сведения о диаграммах и выполнении регрессионного анализа можно найти в разделе См. также.
Описание
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Функцию ЛИНЕЙН также можно объединять с другими функциями для вычисления других видов моделей, являющихся линейными по неизвестным параметрам, включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива. Инструкции приведены в данной статье после примеров.
Уравнение для прямой линии имеет следующий вид:
y = m1x1 + m2x2 +. + b
если существует несколько диапазонов значений x, где зависимые значения y — функции независимых значений x. Значения m — коэффициенты, соответствующие каждому значению x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает массив
Синтаксис
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Аргументы функции ЛИНЕЙН описаны ниже.
Синтаксис
Известные_значения_y. Обязательный аргумент. Множество значений y, которые уже известны для соотношения y = mx + b.
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
Известные_значения_x. Необязательный аргумент. Множество значений x, которые уже известны для соотношения y = mx + b.
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
Если массив известные_значения_x опущен, то предполагается, что это массив <1;2;3;. >, имеющий такой же размер, что и массив известные_значения_y.
Конст. Необязательный аргумент. Логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
Если аргумент конст имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
Если аргумент конст имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y = mx.
Статистика. Необязательный аргумент. Логическое значение, которое указывает, требуется ли вернуть дополнительную регрессионную статистику.
Если статистика имеет true, то LINEST возвращает дополнительную регрессию; в результате возвращается массив .
Если аргумент статистика имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.
Стандартные значения ошибок для коэффициентов m1,m2. mn.
Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент конст имеет значение ЛОЖЬ).
Коэффициент определения. Сравнивает предполагаемые и фактические значения y и диапазоны значений от 0 до 1. Если значение 1, то в выборке будет отличная корреляция— разница между предполагаемым значением y и фактическим значением y не существует. С другой стороны, если коэффициент определения — 0, уравнение регрессии не помогает предсказать значение y. Сведения о том, как вычисляется 2, см. в разделе «Замечания» далее в этой теме.
Стандартная ошибка для оценки y.
F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными.
Степени свободы. Степени свободы используются для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Дополнительные сведения о вычислении величины df см. ниже в разделе «Замечания». Далее в примере 4 показано использование величин F и df.
Регрессионная сумма квадратов.
Остаточная сумма квадратов. Дополнительные сведения о расчете величин ssreg и ssresid см. в подразделе «Замечания» в конце данного раздела.
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.

Замечания
Любую прямую можно описать ее наклоном и пересечением с осью y:
Наклон (m):
Чтобы найти наклон линии, обычно записанной как m, возьмите две точки на строке (x1;y1) и (x2;y2); наклон равен (y2 — y1)/(x2 — x1).
Y-перехват (b):
Y-пересечение строки, обычно записанное как b, — это значение y в точке, в которой линия пересекает ось y.
Уравнение прямой имеет вид y = mx + b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ.
Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами:
Наклон:
=ИНДЕКС( LINEST(known_y,known_x’s);1)
Y-перехват:
=ИНДЕКС( LINEST(known_y,known_x),2)
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель ЛИНЕЙН. Функция ЛИНЕЙН использует для определения наилучшей аппроксимации данных метод наименьших квадратов. Когда имеется только одна независимая переменная x, значения m и b вычисляются по следующим формулам:
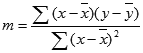
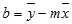
где x и y — выборочные средние значения, например x = СРЗНАЧ(известные_значения_x), а y = СРЗНАЧ( известные_значения_y ).
Функции ЛИННЕСТРОЙ и ЛОГЪЕСТ могут вычислять наилучшие прямые или экспоненциальное кривой, которые подходят для ваших данных. Однако необходимо решить, какой из двух результатов лучше всего подходит для ваших данных. Вы можетевычислить known_y( known_x) для прямой линии или РОСТ( known_y, known_x в ) для экспоненциальной кривой. Эти функции без аргумента new_x возвращают массив значений y, спрогнозируемых вдоль этой линии или кривой в фактических точках данных. Затем можно сравнить спрогнозируемые значения с фактическими значениями. Для наглядного сравнения можно отобразить оба этих диаграммы.
Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем больше значение коэффициента определения r 2 — индикатор того, насколько хорошо уравнение, выданное в результате регрессионного анализа, объясняет связь между переменными. Значение r 2 равно ssreg/sstotal.
В некоторых случаях один или несколько столбцов X (предполагается, что значения Y и X — в столбцах) могут не иметь дополнительного прогнозируемого значения при наличии других столбцов X. Другими словами, удаление одного или более столбцов X может привести к одинаковой точности предсказания значений Y. В этом случае эти избыточные столбцы X следует не использовать в модели регрессии. Этот вариант называется «коллинеарность», так как любой избыточный X-столбец может быть выражен как сумма многих не избыточных X-столбцов. Функция ЛИНЕЙН проверяет коллинеарность и удаляет все избыточные X-столбцы из модели регрессии при их идентификации. Удалены столбцы X распознаются в результатах LINEST как имеющие коэффициенты 0 в дополнение к значениям 0 se. Если один или несколько столбцов будут удалены как избыточные, это влияет на df, поскольку df зависит от числа X столбцов, фактически используемых для прогнозирования. Подробные сведения о вычислении df см. в примере 4. Если значение df изменилось из-за удаления избыточных X-столбцов, это также влияет на значения Sey и F. Коллинеарность должна быть относительно редкой на практике. Однако чаще всего возникают ситуации, когда некоторые столбцы X содержат только значения 0 и 1 в качестве индикаторов того, является ли тема в эксперименте участником определенной группы или не является ее участником. Если конст = ИСТИНА или опущен, функция LYST фактически вставляет дополнительный столбец X из всех 1 значений для моделирования перехвата. Если у вас есть столбец с значением 1 для каждой темы, если мальчик, или 0, а также столбец с 1 для каждой темы, если она является женщиной, или 0, последний столбец является избыточным, так как записи в нем могут быть получены из вычитания записи в столбце «самец» из записи в дополнительном столбце всех 1 значений, добавленных функцией LINEST.
Вычисление значения df для случаев, когда столбцы X удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
При вводе константы массива (например, в качестве аргумента известные_значения_x) следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть другими в зависимости от региональных параметров.
Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
Основной алгоритм, используемый в функции ЛИНЕЙН, отличается от основного алгоритма функций НАКЛОН и ОТРЕЗОК. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
Функция ЛИНЕЙН возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
Наклон и ОТОКП возвращают #DIV/0! ошибка «#ЗНАЧ!». Алгоритм функций НАКЛОН и ОТОКП предназначен для поиска только одного ответа, и в этом случае может быть несколько ответов.
Помимо вычисления статистики для других типов регрессии с помощью функции ЛГРФПРИБЛ, для вычисления диапазонов некоторых других типов регрессий можно использовать функцию ЛИНЕЙН, вводя функции переменных x и y как ряды переменных х и у для ЛИНЕЙН. Например, следующая формула:
работает при наличии одного столбца значений Y и одного столбца значений Х для вычисления аппроксимации куба (многочлен 3-й степени) следующей формы:
y = m1*x + m2*x^2 + m3*x^3 + b
Формула может быть изменена для расчетов других типов регрессии, но в отдельных случаях требуется корректировка выходных значений и других статистических данных.
Значение F-теста, возвращаемое функцией ЛИНЕЙН, отличается от значения, возвращаемого функцией ФТЕСТ. Функция ЛИНЕЙН возвращает F-статистику, в то время как ФТЕСТ возвращает вероятность.
Примеры
Пример 1. Наклон и Y-пересечение
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Функция НАКЛОН для определения наклона линейной регрессии в Excel
Функция НАКЛОН в Excel предназначена для определения угла наклона прямой, используемой для аппроксимации данных методом линейной регрессии, и возвращает значение коэффициента a из уравнения y=ax+b. Для определения наклона используются две любые точки на прямой. При этом вычисляется частное от деления длины отрезка, полученного при проецировании этих двух точек на ось Ординат (OY), на длину отрезка, образованного проекциями этих же двух точек на ось Абсцисс (OX).
Фактически, функция НАКЛОН вычисляет значение, которое характеризует скорость изменения данных вдоль линии регрессии. Зная наклон (коэффициент a) и значение коэффициента b можно рассчитать приближенные будущие значения какого-либо свойства y, которое меняется при изменении характеристики x.
Примеры использования функции НАКЛОН в Excel
Для расчета наклона линии регрессии используется уравнение:
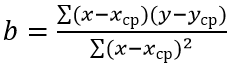
- x_ср – среднее значение для диапазона известных значений независимой переменной;
- y_ср – среднее значение для диапазона известных значений зависимой переменной.
Функция НАКЛОН не может быть использована для анализа коллинеарных данных и будет возвращать код ошибки #ДЕЛ/0! в отличие от функции ЛИНЕЙН, которая использует иной алгоритм расчета и возвращает как минимум одно полученное значение.
Пример 1. Определить наклон аппроксимирующей прямой для показателей средней пенсии на протяжении нескольких лет.
Вид исходной таблицы данных:
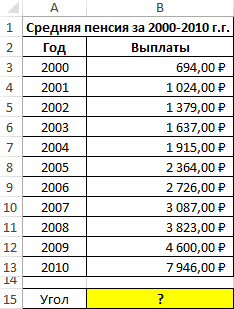
Для нахождения наклона используем следующую формулу:
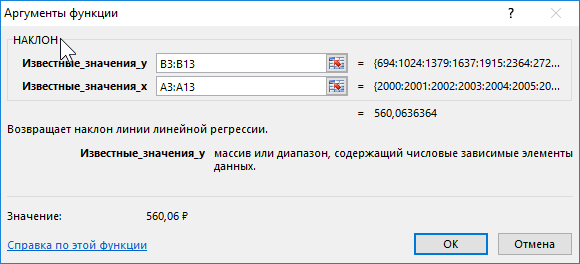
- B3:B13 – ссылка на диапазон ячеек, содержащих данные о средней пенсии, характеризующие зависимую переменную y;
- A3:A13 – диапазон ячеек с данными об отчетных периодах (годах), характеризующие независимую переменную x.
В результате вычислений получим:
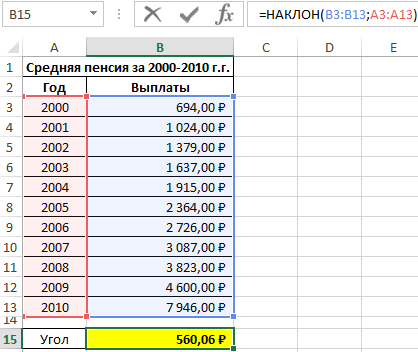
Полученное значение свидетельствует о том, что на протяжении обозначенного периода размер пенсионных выплат в среднем увеличивался примерно на 560 рублей.
Прогноз объема продаж по линейно регрессии в Excel
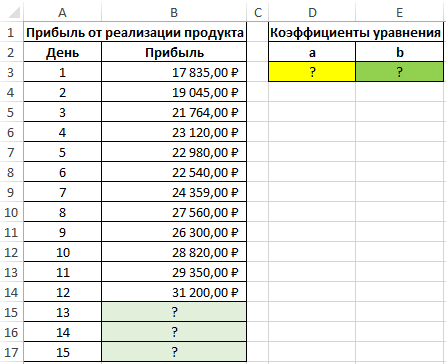
Пример 2. В таблице Excel содержатся данные о прибыли за продажи некоторого продукта компании на протяжении последних нескольких дней. Рассчитать коэффициенты a и b уравнения прямой y=ax+b, аппроксимирующей данные. На основе полученного уравнения спрогнозировать данные о продажах для трех последующих дней.
Вид таблицы с данными:
Для нахождения коэффициента a используем следующую формулу:
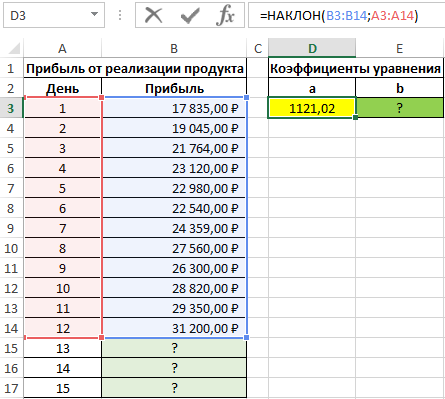
Коэффициент b рассчитывается с помощью следующей функции:
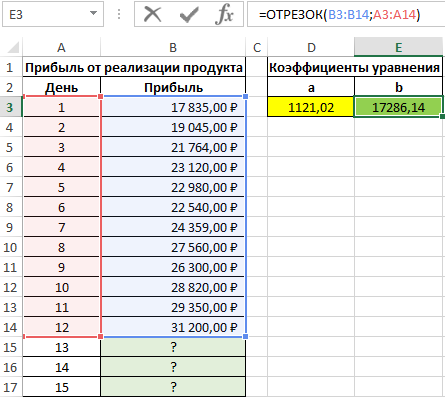
Искомое уравнение имеет вид:
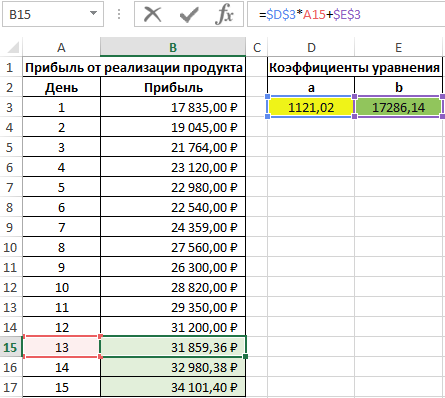
Для определения последующих значений y достаточно лишь подставить требуемое значение x. Выполним расчет предполагаемой прибыли для 13-го дня:
- D3 – полученное значение коэффициента a;
- A15 – новое значение x;
- E3 – значение коэффициента b.
Используем функцию автозаполнения чтобы получить значения для остальных дней:
Анализ корреляции спроса и объема производства в Excel
Пример 3. В таблице содержатся данные о количестве произведенной продукции за месяц, а также о числе приобретенных товаров данной марки покупателями. Отобразить взаимосвязь между данными графически, определить, целесообразно ли использовать уравнение линейно регрессии для описания корреляции между спросом и числом произведенных товаров.
Вид таблицы данных:

Для определения зависимости между двумя рядами числовых данных рассчитаем коэффициент корреляции по формуле:
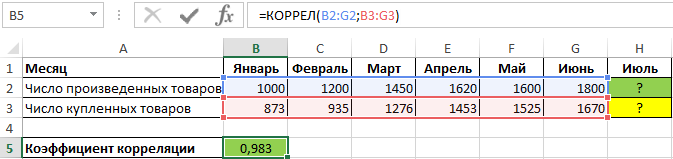
Полученное значение (0,983) свидетельствует о том, что между двумя числовыми диапазонами существует сильная прямая взаимосвязь. Поэтому целесообразно использовать аппроксимирующую прямую, для нахождения коэффициентов уравнения которой используем формулы:
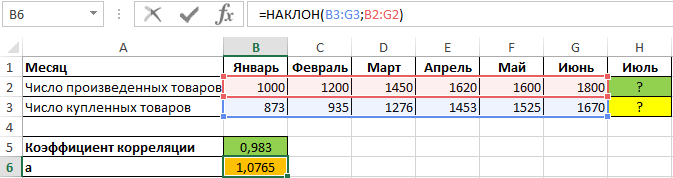
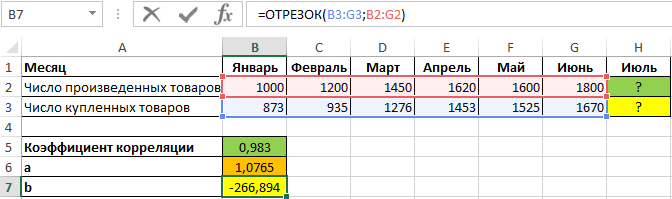
Для нахождения спроса на товары за июль при условии, что будет произведено, например, 2000 единиц продукции, используем полученное уравнение:
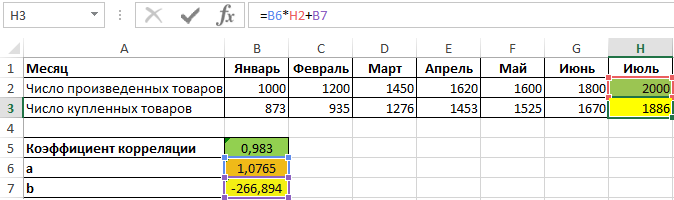
Альтернативным использованию функции НАКЛОН вариантом нахождения наклона в Excel является графический метод. Построим график на основе имеющихся данных, при этом для значений X выберем диапазон ячеек со значениями числа произведенных товаров, а для Y – с числом купленных товаров:
Отобразим на графике линию тренда:
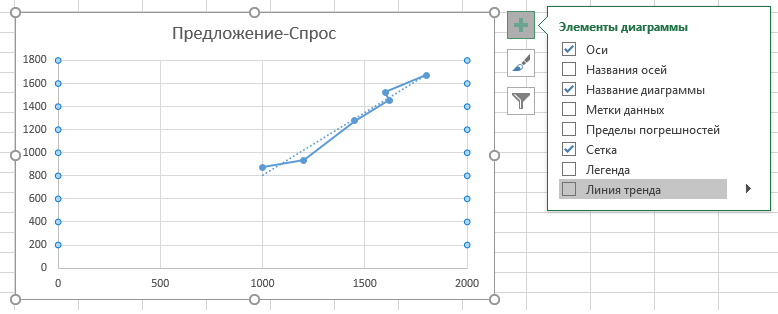
В меню «Формат линии тренда» установим флажок напротив пункта «показывать уравнение на диаграмме»:
График примет следующий вид:
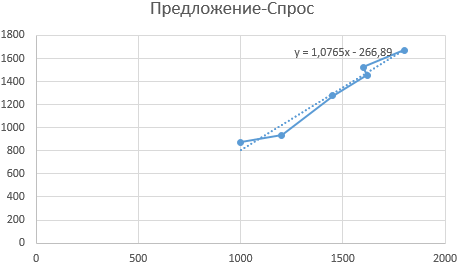
Как видно, найденные коэффициенты a и b соответствуют отображаемым на графике.
Особенности использования функции НАКЛОН в Excel
Функция имеет следующий синтаксис:
Описание аргументов (все являются обязательными для заполнения):
- известные_значения_y – аргумент, принимающий массив числовых значений или ссылку на диапазон ячеек, которые содержат числа, характеризующие значения зависимой переменной y, которые определены для известных значений x;
- известные_значения_x – аргумент, который может быть указан в виде массива чисел или ссылки на диапазон ячеек, содержащих числовые значения, которые характеризуют известные значения независимой переменной x.
- В качестве аргументов должны быть переданы массивы чисел либо ссылки на диапазоны ячеек с числовыми значениями или текстовыми строками, которые могут быть преобразованы к числам. Строки, не являющиеся текстовыми представлениями числовых данных, а также логические ИСТИНА и ЛОЖЬ в расчете не учитываются.
- Если в качестве аргументов были переданы массивы, содержащие разное количество элементов, или ссылки на диапазоны с разным количеством ячеек, функция НАКЛОН вернет код ошибки #Н/Д. Аналогичный код ошибки будет возвращен в случае, если оба аргумента принимают пустые массивы или ссылки на диапазоны пустых ячеек.
- Если оба аргумента ссылаются на нечисловые данные, функция НАКЛОН вернет код ошибки #ДЕЛ/0!.
- Если в диапазоне, переданном в качестве любого из аргументов, содержатся пустые ячейки, они игнорируются в расчете. Однако ячейки, содержащие значение 0 (нуль) будут учтены.
http://support.microsoft.com/ru-ru/office/%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F-%D0%BB%D0%B8%D0%BD%D0%B5%D0%B9%D0%BD-84d7d0d9-6e50-4101-977a-fa7abf772b6d
http://exceltable.com/funkcii-excel/primery-funkcii-naklon