Уравнение множественной регрессии
Назначение сервиса . С помощью онлайн-калькулятора можно найти следующие показатели:
- уравнение множественной регрессии, матрица парных коэффициентов корреляции, средние коэффициенты эластичности для линейной регрессии;
- множественный коэффициент детерминации, доверительные интервалы для индивидуального и среднего значения результативного признака;
Кроме этого проводится проверка на автокорреляцию остатков и гетероскедастичность.
- Шаг №1
- Шаг №2
- Видеоинструкция
- Оформление Word
Отбор факторов обычно осуществляется в два этапа:
- теоретический анализ взаимосвязи результата и круга факторов, которые оказывают на него существенное влияние;
- количественная оценка взаимосвязи факторов с результатом. При линейной форме связи между признаками данный этап сводится к анализу корреляционной матрицы (матрицы парных линейных коэффициентов корреляции). Научно обоснованное решение задач подобного вида также осуществляется с помощью дисперсионного анализа — однофакторного, если проверяется существенность влияния того или иного фактора на рассматриваемый признак, или многофакторного в случае изучения влияния на него комбинации факторов.
Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям:
- Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность.
- Каждый фактор должен быть достаточно тесно связан с результатом (т.е. коэффициент парной линейной корреляции между фактором и результатом должен быть существенным).
- Факторы не должны быть сильно коррелированы друг с другом, тем более находиться в строгой функциональной связи (т.е. они не должны быть интеркоррелированы). Разновидностью интеркоррелированности факторов является мультиколлинеарность — тесная линейная связь между факторами.
Пример . Постройте регрессионную модель с 2-мя объясняющими переменными (множественная регрессия). Определите теоретическое уравнение множественной регрессии. Оцените адекватность построенной модели.
Решение.
К исходной матрице X добавим единичный столбец, получив новую матрицу X
| 1 | 5 | 14.5 |
| 1 | 12 | 18 |
| 1 | 6 | 12 |
| 1 | 7 | 13 |
| 1 | 8 | 14 |
Матрица Y
| 9 |
| 13 |
| 16 |
| 14 |
| 21 |
Транспонируем матрицу X, получаем X T :
| 1 | 1 | 1 | 1 | 1 |
| 5 | 12 | 6 | 7 | 8 |
| 14.5 | 18 | 12 | 13 | 14 |
| Умножаем матрицы, X T X = |
|
В матрице, (X T X) число 5, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
| Умножаем матрицы, X T Y = |
|
Находим обратную матрицу (X T X) -1
| 13.99 | 0.64 | -1.3 |
| 0.64 | 0.1 | -0.0988 |
| -1.3 | -0.0988 | 0.14 |
Вектор оценок коэффициентов регрессии равен
| (X T X) -1 X T Y = y(x) = |
| * |
| = |
|
Получили оценку уравнения регрессии: Y = 34.66 + 1.97X1-2.45X2
Оценка значимости уравнения множественной регрессии осуществляется путем проверки гипотезы о равенстве нулю коэффициент детерминации рассчитанного по данным генеральной совокупности. Для ее проверки используют F-критерий Фишера.
R 2 = 1 — s 2 e/∑(yi — yср) 2 = 1 — 33.18/77.2 = 0.57
F = R 2 /(1 — R 2 )*(n — m -1)/m = 0.57/(1 — 0.57)*(5-2-1)/2 = 1.33
Табличное значение при степенях свободы k1 = 2 и k2 = n-m-1 = 5 — 2 -1 = 2, Fkp(2;2) = 19
Поскольку фактическое значение F = 1.33 Пример №2 . Приведены данные за 15 лет по темпам прироста заработной платы Y (%), производительности труда X1 (%), а также по уровню инфляции X2 (%).
| Год | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X1 | 3,5 | 2,8 | 6,3 | 4,5 | 3,1 | 1,5 | 7,6 | 6,7 | 4,2 | 2,7 | 4,5 | 3,5 | 5,0 | 2,3 | 2,8 |
| X2 | 4,5 | 3,0 | 3,1 | 3,8 | 3,8 | 1,1 | 2,3 | 3,6 | 7,5 | 8,0 | 3,9 | 4,7 | 6,1 | 6,9 | 3,5 |
| Y | 9,0 | 6,0 | 8,9 | 9,0 | 7,1 | 3,2 | 6,5 | 9,1 | 14,6 | 11,9 | 9,2 | 8,8 | 12,0 | 12,5 | 5,7 |
Решение. Подготовим данные для вставки из MS Excel (как транспонировать таблицу для сервиса см. Задание №2) .

Включаем в отчет: Проверка общего качества уравнения множественной регрессии (F-статистика. Критерий Фишера, Проверка на наличие автокорреляции),
После нажатия на кнопку Дале получаем готовое решение.
Уравнение регрессии (оценка уравнения регрессии):
Y = 0.2706 + 0.5257X1 + 1.4798X2
Скачать.
Качество построенного уравнения регрессии проверяется с помощью критерия Фишера (п. 6 отчета).
Пример №3 .
В таблице представлены данные о ВВП, объемах потребления и инвестициях некоторых стран.
| ВВП | 16331,97 | 16763,35 | 17492,22 | 18473,83 | 19187,64 | 20066,25 | 21281,78 | 22326,86 | 23125,90 |
| Потребление в текущих ценах | 771,92 | 814,28 | 735,60 | 788,54 | 853,62 | 900,39 | 999,55 | 1076,37 | 1117,51 |
| Инвестиции в текущих ценах | 176,64 | 173,15 | 151,96 | 171,62 | 192,26 | 198,71 | 227,17 | 259,07 | 259,85 |
Решение:
Для проверки полученных расчетов используем инструменты Microsoft Excel «Анализ данных» (см. пример).
Пример №4 . На основе данных, приведенных в Приложении и соответствующих Вашему варианту (таблица 2), требуется:
- Построить уравнение множественной регрессии. При этом признак-результат и один из факторов остаются теми же, что и в первом задании. Выберите дополнительно еще один фактор из приложения 1 (границы наблюдения должны совпадать с границами наблюдения признака-результата, соответствующего Вашему варианту). При выборе фактора нужно руководствоваться его экономическим содержанием или другими подходами. Пояснить смысл параметров уравнения.
- Рассчитать частные коэффициенты эластичности. Сделать вывод.
- Определить стандартизованные коэффициенты регрессии (b-коэффициенты). Сделать вывод.
- Определить парные и частные коэффициенты корреляции, а также множественный коэффициент корреляции; сделать выводы.
- Оценить значимость параметров уравнения регрессии с помощью t-критерия Стьюдента, а также значимость уравнения регрессии в целом с помощью общего F-критерия Фишера. Предложить окончательную модель (уравнение регрессии). Сделать выводы.
Решение. Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор получается из выражения:
s = (X T X) -1 X T Y
Матрица X
| 1 | 3.9 | 10 |
| 1 | 3.9 | 14 |
| 1 | 3.7 | 15 |
| 1 | 4 | 16 |
| 1 | 3.8 | 17 |
| 1 | 4.8 | 19 |
| 1 | 5.4 | 19 |
| 1 | 4.4 | 20 |
| 1 | 5.3 | 20 |
| 1 | 6.8 | 20 |
| 1 | 6 | 21 |
| 1 | 6.4 | 22 |
| 1 | 6.8 | 22 |
| 1 | 7.2 | 25 |
| 1 | 8 | 28 |
| 1 | 8.2 | 29 |
| 1 | 8.1 | 30 |
| 1 | 8.5 | 31 |
| 1 | 9.6 | 32 |
| 1 | 9 | 36 |
Матрица Y
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 8 |
| 8 |
| 8 |
| 10 |
| 9 |
| 11 |
| 9 |
| 11 |
| 12 |
| 12 |
| 12 |
| 12 |
| 14 |
| 14 |
Матрица X T
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3.9 | 3.9 | 3.7 | 4 | 3.8 | 4.8 | 5.4 | 4.4 | 5.3 | 6.8 | 6 | 6.4 | 6.8 | 7.2 | 8 | 8.2 | 8.1 | 8.5 | 9.6 | 9 |
| 10 | 14 | 15 | 16 | 17 | 19 | 19 | 20 | 20 | 20 | 21 | 22 | 22 | 25 | 28 | 29 | 30 | 31 | 32 | 36 |
Умножаем матрицы, (X T X)
Умножаем матрицы, (X T Y)
Находим определитель det(X T X) T = 139940.08
Находим обратную матрицу (X T X) -1
Уравнение регрессии
Y = 1.8353 + 0.9459X 1 + 0.0856X 2
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка e = Y — X*s
| 0.62 |
| 0.28 |
| 0.38 |
| 0.01 |
| 0.11 |
| -1 |
| -0.57 |
| 0.29 |
| -0.56 |
| 0.02 |
| -0.31 |
| 1.23 |
| -1.15 |
| 0.21 |
| 0.2 |
| -0.07 |
| -0.07 |
| -0.53 |
| 0.34 |
| 0.57 |
se 2 = (Y — X*s) T (Y — X*s)
Несмещенная оценка дисперсии равна
Оценка среднеквадратичного отклонения равна
Найдем оценку ковариационной матрицы вектора k = σ*(X T X) -1
| k(x) = 0.36 |
| = |
|
Дисперсии параметров модели определяются соотношением S 2 i = Kii, т.е. это элементы, лежащие на главной диагонали
С целью расширения возможностей содержательного анализа модели регрессии используются частные коэффициенты эластичности, которые определяются по формуле
Тесноту совместного влияния факторов на результат оценивает индекс множественной корреляции (от 0 до 1)
Связь между признаком Y факторами X сильная
Частные коэффициенты (или индексы) корреляции, измеряющие влияние на у фактора хi при неизменном уровне других факторов определяются по стандартной формуле линейного коэффициента корреляции — последовательно берутся пары yx1,yx2. , x1x2, x1x3.. и так далее и для каждой пары находится коэффициент корреляции
Коэффициент детерминации
R 2 = 0.97 2 = 0.95, т.е. в 95% случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — высокая
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл: Tтабл (n-m-1;a) = (17;0.05) = 1.74
Поскольку Tнабл Fkp, то коэффициент детерминации статистически значим и уравнение регрессии статистически надежно
Построение парной регрессионной модели
Рекомендации к решению контрольной работы.
Статистические данные по экономике можно получить на странице Россия в цифрах.
После определения зависимой и объясняющих переменных можно воспользоваться сервисом Множественная регрессия. Регрессионную модель с 2-мя объясняющими переменными можно построить используя матричный метод нахождения параметров уравнения регрессии или метод Крамера для нахождения параметров уравнения регрессии.
Пример №3 . Исследуется зависимость размера дивидендов y акций группы компаний от доходности акций x1, дохода компании x2 и объема инвестиций в расширение и модернизацию производства x3. Исходные данные представлены выборкой объема n=50.
Тема I. Парная линейная регрессия
Постройте парные линейные регрессии — зависимости признака y от факторов x1, x2, x3 взятых по отдельности. Для каждой объясняющей переменной:
- Постройте диаграмму рассеяния (поле корреляции). При построении выберите тип диаграммы «Точечная» (без отрезков, соединяющих точки).
- Вычислите коэффициенты уравнения выборочной парной линейной регрессии (для вычисления коэффициентов регрессии воспользуйтесь встроенной функцией ЛИНЕЙН (функция находится в категории «Статистические») или надстройкой Пакет Анализа), коэффициент детерминации, коэффициент корреляции (функция КОРЕЛЛ), среднюю ошибку аппроксимации
 .
. - Запишите полученное уравнение выборочной регрессии. Дайте интерпретацию найденным в предыдущем пункте значениям.
- Постройте на поле корреляции прямую линию выборочной регрессии по точкам .
- Постройте диаграмму остатков.
- Проверьте статистическую значимость коэффициентов регрессии по критерию Стьюдента (табличное значение определите с помощью функции СТЬЮДРАСПОБР) и всего уравнения в целом по критерию Фишера (табличное значение Fтабл определите с помощью функции FРАСПОБР).
- Постройте доверительные интервалы для коэффициентов регрессии. Дайте им интерпретацию.
- Постройте прогноз для значения фактора, на 50% превышающего его среднее значение.
- Постройте доверительный интервал прогноза. Дайте ему экономическую интерпретацию.
- Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемого фактора на показатель.
Тема II. Множественная линейная регрессия
1. Постройте выборочную множественную линейную регрессию показателя на все указанные факторы. Запишите полученное уравнение, дайте ему экономическую интерпретацию.
2. Определите коэффициент детерминации, дайте ему интерпретацию. Вычислите среднюю абсолютную ошибку аппроксимации и дайте ей интерпретацию.
3. Проверьте статистическую значимость каждого из коэффициентов и всего уравнения в целом.
4. Постройте диаграмму остатков.
5. Постройте доверительные интервалы коэффициентов. Для статистически значимых коэффициентов дайте интерпретации доверительных интервалов.
6. Постройте точечный прогноз значения показателя y при значениях факторов, на 50% превышающих их средние значения.
7. Постройте доверительный интервал прогноза, дайте ему экономическую интерпретацию.
8. Постройте матрицу коэффициентов выборочной корреляции между показателем и факторами. Сделайте вывод о наличии проблемы мультиколлинеарности.
9. Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемых факторов на показатель.
Справка
Набор инструментов Пространственная статистика (Spatial Statistics) предоставляет эффективные инструменты количественного анализа пространственных структурных закономерностей. Инструмент Анализ горячих точек (Hot Spot Analysis) , например, поможет найти ответы на следующие вопросы:
- Есть ли в США места, где постоянно наблюдается высокая смертность среди молодежи?
- Где находятся «горячие точки» по местам преступлений, вызовов 911 (см. рисунок ниже) или пожаров?
- Где находятся места, в которых количество дорожных происшествий превышает обычный городской уровень?
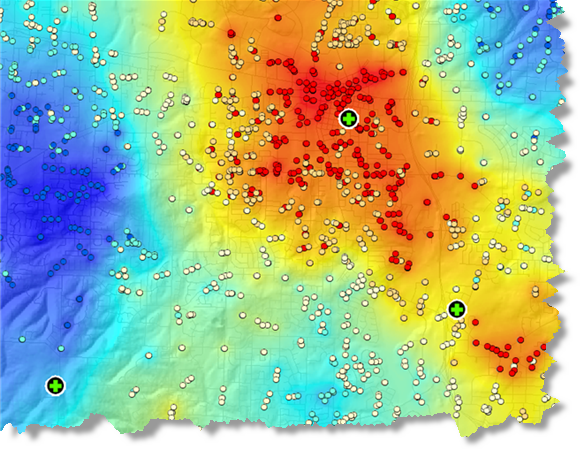 Анализ данных звонков в службу 911, показывающий горячие точки (красным), холодные точки (синим) и локализацию пожарных/полиции, ответственных за реагирование (зеленые круги)
Анализ данных звонков в службу 911, показывающий горячие точки (красным), холодные точки (синим) и локализацию пожарных/полиции, ответственных за реагирование (зеленые круги)
Каждый из вопросов спрашивает «где»? Следующий логический вопрос для такого типа анализа – «почему»?
- Почему в некоторых местах США наблюдается повышенная смертность молодежи? Какова причина этого?
- Можем ли мы промоделировать характеристики мест, на которые приходится больше всего преступлений, звонков в 911, или пожаров, чтобы помочь сократить эти случаи?
- От каких факторов зависит повышенное число дорожных происшествий? Имеются ли какие-либо возможности для снижения числа дорожных происшествий в городе вообще, и в особо неблагополучных районах в частности?
Пространственные отношения
Регрессионный анализ позволяет вам моделировать, проверять и исследовать пространственные отношения и помогает вам объяснить факторы, стоящие за наблюдаемыми пространственными структурными закономерностями. Вы также можете захотеть понять, почему люди постоянно умирают молодыми в некоторых регионах страны, и какие факторы особенно влияют на особенно высокий уровень диабета. При моделирование пространственных отношений, однако, регрессионный анализ также может быть пригоден для прогнозирования. Моделирование факторов, которые влияют на долю выпускников колледжей, на пример, позволяют вам сделать прогноз о потенциальной рабочей силе и их навыках. Вы также можете использовать регрессионный анализ для прогнозирования осадков или качества воздуха в случаях, где интерполяция невозможна из-за малого количества станций наблюдения (к примеру, часто отсутствую измерительные приборы вдоль горных хребтов и в долинах).
МНК (OLS) – наиболее известный метод регрессионного анализа. Это также подходящая отправная точка для всех способов пространственного регрессионного анализа. Данный метод позволяет построить глобальную модель переменной или процесса, которые вы хотите изучить или спрогнозировать (уровень смертности/осадки). Он создает уравнение регрессии, отражающее происходящий процесс. Географически взвешенная регрессия (ГВР) – один из нескольких методов пространственного регрессионного анализа, все чаще использующегося в географии и других дисциплинах. Метод ГВР (географически взвешенная регрессия) создает локальную модель переменной или процесса, которые вы прогнозируете или изучаете, применяя уравнение регрессии к каждому пространственному объекту в наборе данных. При подходящем использовании, эти методы являются мощным и надежным статистическим средством для проверки и оценки линейных взаимосвязей.
Линейные взаимосвязи могут быть положительными или отрицательными. Если вы обнаружили, что количество поисково-спасательных операций увеличивается при возрастании среднесуточной температуры, такое отношение является положительным; имеется положительная корреляция. Другой способ описать эту положительную взаимосвязь – сказать, что количество поисково-спасательных операций уменьшается при уменьшении среднесуточной температуры. Соответственно, если вы установили, что число преступлений уменьшается при увеличении числа полицейских патрулей, данное отношение является отрицательным. Также, можно выразить это отрицательное отношение, сказав, что количество преступлений увеличивается при уменьшении количества патрулей. На рисунке ниже показаны положительные и отрицательные отношения, а также случаи, когда две переменные не связаны отношениями:
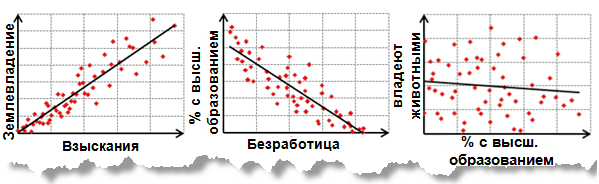 Диаграммы рассеивания: положительная связь, отрицательная связь и пример с 2 не связанными переменными.
Диаграммы рассеивания: положительная связь, отрицательная связь и пример с 2 не связанными переменными.
Корреляционные анализы, и связанные с ними графики, отображенные выше, показывают силу взаимосвязи между двумя переменными. С другой стороны, регрессионные анализы дают больше информации: они пытаются продемонстрировать степень, с которой 1 или более переменных потенциально вызывают положительные или негативные изменения в другой переменной.
Применения регрессионного анализа
Регрессионный анализ может использоваться в большом количестве приложений:
- Моделирование числа поступивших в среднюю школу для лучшего понимания факторов, удерживающих детей в том же учебном заведении.
- Моделирование дорожных аварий как функции скорости, дорожных условий, погоды и т.д., чтобы проинформировать полицию и снизить несчастные случаи.
- Моделирование потерь от пожаров как функции от таких переменных как степень вовлеченности пожарных департаментов, время обработки вызова, или цена собственности. Если вы обнаружили, что время реагирования на вызов является ключевым фактором, возможно, существует необходимость создания новых пожарных станций. Если вы обнаружили, что вовлеченность – главный фактор, возможно, вам нужно увеличить оборудование и количество пожарных, отправляемых на пожар.
Существует три первостепенных причины, по которым обычно используют регрессионный анализ:
- Смоделировать некоторые явления, чтобы лучше понять их и, возможно, использовать это понимание для оказания влияния на политику и принятие решений о наиболее подходящих действиях. Основная цель – измерить экстент, который при изменениях в одной или более переменных связанно вызывает изменения и в другой. Пример. Требуется понять ключевые характеристики ареала обитания некоторых видов птиц (например, осадки, ресурсы питания, растительность, хищники) для разработки законодательства, направленного на защиту этих видов.
- Смоделировать некоторые явления, чтобы предсказать значения в других местах или в другое время. Основная цель – построить прогнозную модель, которая является как устойчивой, так и точной. Пример: Даны прогнозы населения и типичные погодные условия. Каким будет объем потребляемой электроэнергии в следующем году?
- Вы также можете использовать регрессионный анализ для исследования гипотез. Предположим, что вы моделируете бытовые преступления для их лучшего понимания и возможно, вам удается внедрить политические меры, чтобы остановить их. Как только вы начинаете ваш анализ, вы, возможно, имеете вопросы или гипотезы, которые вы хотите проверить:
- «Теория разбитого окна» указывает на то, что испорченная общественная собственность (граффити, разрушенные объекты и т.д.) притягивает иные преступления. Имеется ли положительное отношение между вандализмом и взломами в квартиры?
- Имеется ли связь между нелегальным использованием наркотических средств и взломами в квартиры (могут ли наркоманы воровать, чтобы поддерживать свое существование)?
- Совершаются ли взломы с целью ограбления? Возможно ли, что будет больше случаев в домохозяйствах с большей долей пожилых людей и женщин?
- Люди больше подвержены риску ограбления, если они живут в богатой или бедной местности?
Вы можете использовать регрессионный анализ, чтобы исследовать эти взаимосвязи и ответить на ваши вопросы.
Термины и концепции регрессионного анализа
Невозможно обсуждать регрессионный анализ без предварительного знакомства с основными терминами и концепциями, характерными для регрессионной статистики:
Уравнение регрессии. Это математическая формула, применяемая к независимым переменным, чтобы лучше спрогнозировать зависимую переменную, которую необходимо смоделировать. К сожалению, для тех ученых, кто думает, что х и у это только координаты, независимая переменная в регрессионном анализе всегда обозначается как y, а зависимая – всегда X. Каждая независимая переменная связана с коэффициентами регрессии, описывающими силу и знак взаимосвязи между этими двумя переменными. Уравнение регрессии может выглядеть следующим образом (у – зависимая переменная, Х – независимые переменные, β – коэффициенты регрессии), ниже приводится описание каждого из этих компонентов уравнения регрессии):
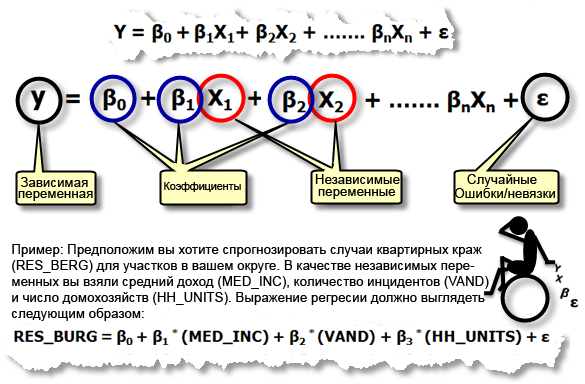 Элементы Уравнения регрессии по методу наименьших квадратов
Элементы Уравнения регрессии по методу наименьших квадратов
- Зависимая переменная (y) – это переменная, описывающая процесс, который вы пытаетесь предсказать или понять (бытовые кражи, осадки). В уравнении регрессии эта переменная всегда находится слева от знака равенства. В то время, как можно использовать регрессию для предсказания зависимой величины, вы всегда начинаете с набора хорошо известных у-значений и используете их для калибровки регрессионной модели. Известные у-значения часто называют наблюдаемыми величинами.
- Независимые переменные (X) это переменные, используемые для моделирования или прогнозирования значений зависимых переменных. В уравнении регрессии они располагаются справа от знака равенства и часто называются независимыми переменными. Зависимая переменная – это функция независимых переменных. Если вас интересует прогнозирование годового оборота определенного магазина, можно включить в модель независимые переменные, отражающие, например, число потенциальных покупателей, расстояние до конкурирующих магазинов, заметность магазина и структуру спроса местных жителей.
- Коэффициенты регрессии (β) – это коэффициенты, которые рассчитываются в результате выполнения регрессионного анализа. Вычисляются величины для каждой независимой переменной, которые представляют силу и тип взаимосвязи независимой переменной по отношению к зависимой. Предположим, что вы моделируете частоту пожаров как функцию от солнечной радиации, растительного покрова, осадков и экспозиции склона. Вы можете ожидать положительную взаимосвязь между частотой пожаров и солнечной радиацией (другими словами, чем больше солнца, тем чаще встречаются пожары). Если отношение положительно, знак связанного коэффициента также положителен. Вы можете ожидать негативную связь между частотой пожаров и осадками (другими словами, для мест с большим количеством осадков характерно меньше лесных пожаров). Коэффициенты отрицательных отношений имеют знак минуса. Когда взаимосвязь сильная, значения коэффициентов достаточно большие (относительно единиц независимой переменной, с которой они связаны). Слабая взаимосвязь описывается коэффициентами с величинами около 0; β0 – это пересечение линии регрессии. Он представляет ожидаемое значение зависимой величины, если все независимые переменные равны 0.
P-значения. Большинство регрессионных методов выполняют статистический тест для расчета вероятности, называемой р-значением, для коэффициентов, связанной с каждой независимой переменной. Нулевая гипотеза данного статистического теста предполагает, что коэффициент незначительно отличается от нуля (другими словами, для всех целей и задач, коэффициент равен нулю, и связанная независимая переменная не может объяснить вашу модель). Маленькие величины р-значений отражают маленькие вероятности и предполагают, что коэффициент действительно важен для вашей модели со значением, существенно отличающимся от 0 (другими словами, маленькие величины р-значений свидетельствуют о том, что коэффициент не равен 0). Вы бы сказали, что коэффициент с р-значением, равным 0,01, например, статистически значимый для 99 % доверительного интервала; связанные переменные являются эффективным предсказателем. Переменные с коэффициентами около 0 не помогают предсказать или смоделировать зависимые величины; они практически всегда удаляются из регрессионного уравнения, если только нет веских причин сохранить их.
R 2 /R-квадрат: Статистические показатели составной R-квадрат и выровненный R-квадрат вычисляются из регрессионного уравнения, чтобы качественно оценить модель. Значение R-квадрат лежит в пределах от 0 до 100 процентов. Если ваша модель описывает наблюдаемые зависимые переменные идеально, R-квадрат равен 1.0 (и вы, несомненно, сделали ошибку; возможно, вы использовали модификацию величины у для предсказания у). Вероятнее всего, вы увидите значения R-квадрат в районе 0,49, например, можно интерпретировать подобный результат как «Это модель объясняет 49 % вариации зависимой величины». Чтобы понять, как работает R-квадрат, постройте график, отражающий наблюдаемые и оцениваемые значения у, отсортированные по оцениваемым величинам. Обратите внимание на количество совпадений. Этот график визуально отображает, насколько хорошо вычисленные значения модели объясняют изменения наблюдаемых значений зависимых переменных. Просмотрите иллюстрацию. Выверенный R-квадрат всегда немного меньше, чем составной R-квадрат, т.к. он отражает всю сложность модели (количество переменных) и связан с набором исходных данных. Следовательно, выверенный R-квадрат является более точной мерой для оценки результатов работы модели.
Невязки. Существует необъяснимое количество зависимых величин, представленных в уравнении регрессии как случайные ошибки ε. Просмотрите иллюстрацию. Известные значения зависимой переменной используются для построения и настройки модели регрессии. Используя известные величины зависимой переменной (Y) и известные значений для всех независимых переменных (Хs), регрессионный инструмент создаст уравнение, которое предскажет те известные у-значения как можно лучше. Однако предсказанные значения редко точно совпадают с наблюдаемыми величинами. Разница между наблюдаемыми и предсказываемыми значениями у называется невязка или отклонение. Величина отклонений регрессионного уравнения – одно из измерений качества работы модели. Большие отклонения говорят о ненадлежащем качестве модели.
Создание регрессионной модели представляет собой итерационный процесс, направленный на поиск эффективных независимых переменных, чтобы объяснить зависимые переменные, которые вы пытаетесь смоделировать или понять, запуская инструмент регрессии, чтобы определить, какие величины являются эффективными предсказателями. Затем пошаговое удаление и/или добавление переменных до тех пор, пока вы не найдете наилучшим образом подходящую регрессионную модель. Т.к. процесс создания модели часто исследовательский, он никогда не должен становиться простым «подгоном» данных. Он должен учитывать теоретические аспекты, мнение экспертов в этой области и здравый смысл. Вы должным быть способны определить ожидаемую взаимосвязь между каждой потенциальной независимой переменной и зависимой величиной до непосредственного анализа, и должны задать себе дополнительные вопросы, когда эти связи не совпадают.
Примечание:
Если вы никогда не выполняли регрессионный анализ раньше, рекомендуем загрузить Руководство о регрессионному анализу и пройти шаги 1-5.
Особенности регрессионного анализа
Регрессия МНК (OLS) – это простой метод анализа с хорошо проработанной теорией, предоставляющий эффективные возможности диагностики, которые помогут вам интерпретировать результаты и устранять неполадки. Однако, МНК надежен и эффективен, если ваши данные и регрессионная модель удовлетворяют всем предположениям, требуемым для этого метода (смотри таблицу внизу). Пространственные данные часто нарушают предположения и требования МНК, поэтому важно использовать инструменты регрессии в союзе с подходящими инструментами диагностики, которые позволяют оценить, является ли регрессия подходящим методом для вашего анализа, а приведенная структура данных и модель может быть применена.
Как регрессионная модель может не работать
Серьезной преградой для многих регрессионных моделей является ошибка спецификации. Модель ошибки спецификации – это такая неполная модель, в которой отсутствуют важные независимые переменные, поэтому она неадекватно представляет то, что мы пытаемся моделировать или предсказывать (зависимую величину, у). Другими словами, регрессионная модель не рассказывает вам всю историю. Ошибка спецификации становится очевидной, когда в отклонениях вашей регрессионной модели наблюдается статистически значимая пространственная автокорреляция , или другими словами, когда отклонения вашей модели кластеризуются в пространстве (недооценки – в одной области изучаемой территории, а переоценки – в другой). Благодаря картографированию невязок регрессии или коэффициентов, связанных с географически взвешенной регрессией , можно обратить внимание на какие-то нюансы, которые вы упустили ранее. Запуск Анализа горячих точек по отклонениям регрессии также может раскрыть разные пространственные режимы, которые можно моделировать при помощи метода наименьших квадратов с региональными показателями или исправлять с использованием географически взвешенной регрессии. Предположим, когда вы картографируете отклонения вашей регрессионной модели, вы видите, что модель всегда заново предсказывает значения в горах, и, наоборот, в долинах, что может значить, что отсутствуют данные о рельефе. Однако может случиться так, что отсутствующие переменные слишком сложны для моделирования или их невозможно подсчитать или слишком трудно измерить. В этих случаях, можно воспользоваться ГВР (географически взвешенной регрессией) или другой пространственной регрессией, чтобы получить хорошую модель.
В следующей таблице перечислены типичные проблемы с регрессионными моделями и инструменты в ArcGIS:
Типичные проблемы с регрессией, последствия и решения
Ошибки спецификации относительно независимых переменных.
Когда ключевые независимые переменные отсутствуют в регрессионном анализе, коэффициентам и связанным с ними р-значениям нельзя доверять.
Создайте карту и проверьте невязки МНК и коэффициенты ГВР или запустите Анализ горячих точек по регрессионным невязкам МНК, чтобы увидеть, насколько это позволяет судить о возможных отсутствующих переменных.
МНК и ГВР – линейные методы. Если взаимосвязи между любыми независимыми величинами и зависимыми – нелинейны, результирующая модель будет работать плохо.
Создайте диаграмму рассеяния, чтобы выявить взаимосвязи между показателями в модели. Уделите особое внимание взаимосвязям, включающим зависимые переменные. Обычно криволинейность может быть устранена трансформированием величин. Просмотрите иллюстрацию. Альтернативно, используйте нелинейный метод регрессии.
Существенные выбросы могут увести результаты взаимоотношений регрессионной модели далеко от реальности, внося ошибку в коэффициенты регрессии.
Создайте диаграмму рассеяния и другие графики (гистограммы), чтобы проверить экстремальные значения данных. Скорректировать или удалить выбросы, если они представляют ошибки. Когда выбросы соответствуют действительности, они не могут быть удалены. Запустить регрессию с и без выбросов, чтобы оценить, как это влияет на результат.
Нестационарность. Вы можете обнаружить, что входящая переменная, может иметь сильную зависимость в регионе А, и в то время быть незначительной или даже поменять знак в регионе B (см. рисунок).
Если взаимосвязь между вашими зависимыми и независимыми величинами противоречит в пределах вашей области изучения, рассчитанные стандартные ошибки будут искусственно раздуты.
Инструмент МНК в ArcGIS автоматически тестирует проблемы, связанные с нестационарностью (региональными вариациями) и вычисляет устойчивые стандартные значения ошибок. Просмотрите иллюстрацию. Когда вероятности, связанные с тестом Koenker, малы (например, Географически взвешенная регрессия .
Мультиколлинеарность. Одна или несколько независимых переменных излишни. Просмотрите иллюстрацию.
Мультиколлинеарность ведет к переоценке и нестабильной/ненадежной модели.
Инструмент МНК в ArcGIS автоматически проверяет избыточность. Каждой независимой переменной присваивается рассчитанная величина фактора, увеличивающего дисперсию. Когда это значение велико (например, > 7,5), избыток является проблемой и излишние показатели должны быть удалены из модели или модифицированы путем создания взаимосвязанных величин или увеличением размера выборки. Просмотрите иллюстрацию.
Противоречивая вариация в отклонениях. Может произойти, что модель хорошо работает для маленьких величин, но становится ненадежна для больших значений. Просмотрите иллюстрацию.
Когда модель плохо предсказывает некоторые группы значений, результаты будут носить ошибочный характер.
Инструмент МНК в ArcGIS автоматически выполняет тест на несистемность вариаций в отклонениях (называемая гетероскедастичность или неоднородность дисперсии) и вычисляет стандартные ошибки, которые устойчивы к этой проблеме. Когда вероятности, связанные с тестом Koenker, малы (например, 0,05), необходимо учитывать устойчивые вероятности, чтобы определить, является ли независимая переменная статистически значимой или нет. Просмотрите иллюстрацию.
Пространственно автокоррелированные отклонения. Просмотрите иллюстрацию.
Когда наблюдается пространственная кластеризация в отклонениях, полученных в результате работы модели, это означает, что имеется переоценённый тип систематических отклонений, модель работает ненадежно.
Запустите инструмент Пространственная автокорреляция (Spatial Autocorrelation) по отклонениям, чтобы убедиться, что в них не наблюдается статистически значимой пространственной автокорреляции. Статистически значимая пространственная автокорреляция практически всегда является симптомом ошибки спецификации (отсутствует ключевой показатель в модели). Просмотрите иллюстрацию.
Нормальное распределение систематической ошибки. Просмотрите иллюстрацию.
Когда невязки регрессионной модели распределены ненормально со средним, близким к 0, р-значения, связанные с коэффициентами, ненадежны.
Инструмент МНК в ArcGIS автоматически выполняет тест на нормальность распределения отклонений. Когда статистический показатель Jarque-Bera является значимым (например, 0,05), скорее всего в вашей модели отсутствует ключевой показатель (ошибка спецификации) или некоторые отношения, которые вы моделируете, являются нелинейными. Проверьте карту отклонений и возможно карту с коэффициентами ГВР, чтобы определить, какие ключевые показатели отсутствуют. Просмотр диаграмм рассеяния и поиск нелинейных отношений.
Типичные проблемы с регрессией и их решения
Важно протестировать модель на каждую из проблем, перечисленных выше. Результаты могут быть на 100 % неправильны, если игнорируются проблемы, упомянутые выше.
Примечание:
Если вы никогда не выполняли регрессионный анализ раньше, рекомендуем загрузить Руководство по регрессионному анализу.
Пространственная регрессия
Для пространственных данных характерно 2 свойства, которые затрудняют (не делают невозможным) применение традиционных (непространственных) методов, таких как МНК:
- Географические объекты довольно часто пространственно автокоррелированы. Это означает, что объекты, расположенные ближе друг к другу более похожи между собой, чем удаленные объекты. Это создает переоцененный тип систематических ошибок для традиционных моделей регрессии.
- География важна, и часто наиболее важные процессы нестационарны. Эти процессы протекают по-разному в разных частях области изучения. Эта характеристика пространственных данных может относиться как к региональным вариациям, так и к нестационарности.
Настоящие методы пространственной регрессии были разработаны, чтобы устойчиво справляться с этими двумя характеристиками пространственных данных и даже использовать эти свойства пространственных данных, чтобы улучшать моделирование взаимосвязей. Некоторые методы пространственной регрессии эффективно имеют дело с 1 характеристикой (пространственная автокорреляция), другие – со второй (нестационарность). В настоящее время, нет методов пространственной регрессии, которые эффективны с обеими характеристиками. Для правильно настроенной модели ГВР пространственная автокорреляция обычно не является проблемой.
Существует большая разница в том, как традиционные и пространственные статистические методы смотрят на пространственную автокорреляцию. Традиционные статистические методы видят ее как плохую вещь, которая должна быть устранена, т.к. пространственная автокорреляция ухудшает предположения многих традиционных статистических методов. Для географа или ГИС-аналитика, однако, пространственная автокорреляция является доказательством важности пространственных процессов; это интегральная компонента данных. Удаляя пространство, мы удаляем пространственный контекст данных; это как только половина истории. Пространственные процессы и доказательство пространственных взаимосвязей в данных представляют собой особый интерес, и поэтому пользователи ГИС с радостью используют инструменты пространственного анализа данных. Однако, чтобы избежать переоцененный тип систематических ошибок в вашей модели, вы должны определить полный набор независимых переменных, которые эффективно опишут структуру ваших данных. Если вы не можете определить все эти переменные, скорее всего, вы увидите существенную пространственную автокорреляцию среди отклонений модели. К сожалению, вы не можете доверять результатам регрессии, пока все не устранено. Используйте инструмент Пространственная автокорреляция , чтобы выполнить тест на статистически значимую пространственную автокорреляцию для отклонений в вашей регрессии.
Как минимум существует 3 направления, как поступать с пространственной автокорреляцией в невязках регрессионных моделей.
- Изменять размер выборки до тех пор, пока не удастся устранить статистически значимую пространственную автокорреляцию. Это не гарантирует, что в анализе будет полностью устранена проблема пространственной автокорреляции, но она значительно меньше, когда пространственная автокорреляция удалена из зависимых и независимых переменных. Это традиционный статистический подход к устранению пространственной автокорреляции и только подходит, если пространственная автокорреляция является результатом избыточности данных.
- Изолируйте пространственные и непространственные компоненты каждой входящей величины, используя методы фильтрации в пространственной регрессии. Пространство удалено из каждой величины, но затем его возвращают обратно в регрессионную модель в качестве новой переменной, отвечающей за пространственные эффекты/пространственную структуру. ArcGIS в настоящее время не предоставляет возможности проведения подобного рода анализа.
- Внедрите пространственную автокорреляцию в регрессионную модель, используя пространственные эконометрические регрессионные модели. Пространственные эконометрические регрессионные модели будут добавлены в ArcGIS в следующем релизе.
Глобальные модели, подобные МНК, создают уравнения, наилучшим образом описывающие общие связи в данных в пределах изучаемой территории. Когда те взаимосвязи противоречивы в пределах территории изучения, МНК хорошо моделирует эти взаимосвязи. Когда те взаимосвязи ведут себя по-разному в разных частях области изучения, регрессионное уравнение представляет средние результаты, и в случае, когда те взаимосвязи представляют 2 экстремальных значения, глобальное среднее не моделирует хорошо эти значения. Когда ваши независимые переменные испытывают нестационарность (региональные вариации), глобальные модели не подходят, а необходимо использовать устойчивые методы регрессионного анализа. Идеально, можно определить полный набор независимых переменных, чтобы справиться с региональными вариациями в ваших зависимых переменных. Если вы не сможете определить все пространственные переменные, вы снова заметите статистически значимую пространственную автокорреляцию в ваших отклонениях и/или более низкие, чем ожидалось, значения R-квадрат . К сожалению, вы не можете доверять результатам регрессии, пока все не устранено.
Существует как минимум 4 способа работы с региональными вариациями в МНК регрессионных моделях:
- Включить переменную в модель, которая объяснит региональные вариации. Если вы видите, что ваша модель всегда «перепредсказывает» на севере и «недопредсказывает» на юге, добавьте набор региональных значений:1 для северных объектов, и 0 для южных объектов.
- Используйте методы, которые включают региональные вариации в регрессионную модель, такие как географически взвешенная регрессия .
- Примите во внимание устойчивые стандартные отклонения регрессии и вероятности, чтобы определить, являются ли коэффициенты статистически значимыми. См. Интерпретация результатов МНК. ГВР рекомендуется
- Изменить/сократить размер области изучения так, чтобы процессы в пределах новой области изучения были стационарными (не испытывали региональные вариации).
Для большей информации по использованию регрессионных инструментов, см.:
Количество коэффициентов в уравнении регрессии
Регрессионный анализ позволяет приближенно определить форму связи между результативным и факторными признаками, а также решить вопрос о том, значима ли эта связь. Вид функции, с помощью которой приближенно выражается форма связи, выбирают заранее, исходя из содержательных соображений или визуального анализа данных. Математическое решение задачи основано на методе наименьших квадратов.
Суть метода наименьших квадратов. Рассмотрим содержание метода на конкретном примере. Пусть имеются данные о сборе хлеба на душу населения по совокупности черноземных губерний. От каких факторов зависит величина этого сбора? Вероятно, определяющее влияние на величину сбора хлеба оказывает величина посева и уровень урожайности. Рассмотрим сначала зависимость величины сбора хлеба на душу населения от размера посева на душу ( столбцы 1 и 2 табл .4 ) Попытаемся представить интересующую нас зависимость с помощью прямой линии. Разумеется, такая линия может дать только приближенное представление о форме реальной статистической связи. Постараемся сделать это приближение наилучшим. Оно будет тем лучше, чем меньше исходные данные будут отличаться от соответствующих точек, лежащих на линии. Степень близости может быть выражена величиной суммы квадратов отклонении, реальных значений от, расположенных на прямой. Использование именно квадратов отклонений (не просто отклонений) позволяет суммировать отклонения различных знаков без их взаимного погашения и дополнительно обеспечивает сравнительно большее внимание, уделяемое большим отклонениям. Именно этот критерий (минимизация суммы квадратов отклонений) положен в основу метода наименьших квадратов.
В вычислительном аспекте метод наименьших квадратов сводится к составлению и решению системы так называемых нормальных уравнений. Исходным этапом для этого является подбор вида функции, отображающей статистическую связь.
Тип функции в каждом конкретном случае можно подобрать путем прикидки на графике исходных данных подходящей, т. е. достаточно хорошо приближающей эти данные, линии. В нашем случае связь между сбором хлеба на душу и величиной посева на душу может быть изображена с помощью прямой линии ( рис. 14 ) и записана в виде
где у—величина сбора хлеба на душу (результативный признак или зависимая переменная); x—величина посева на душу (факторный признак или независимая переменная); a o и a 1 — параметры уравнения, которые могут быть найдены методом наименьших квадратов.
Для нахождения искомых параметров нужно составить систему уравнений, которая в данном случае будет иметь вид
Полученная система может быть решена известным из школьного курса методом Гаусса. Искомые параметры системы из двух нормальных уравнений можно вычислить и непосредственно с помощью последовательного использования нижеприведенных формул:
где y i — i-e значение результативного признака; x i — i-e значение факторного признака; и — средние арифметические результативного и факторного признаков соответственно; n— число значений признака y i , или, что то же самое, число значений признака x i .
Пример 9. Найдем уравнение линейной связи между величиной сбора хлеба (у) и размером посева (х) по данным табл. 4. Проделав необходимые вычисления, получим из (6.17):
Таким образом, уравнение связи, или, как принято говорить, уравнение регрессии, выглядит следующим образом:
Интерпретация коэффициента регрессии. Уравнение регрессии не только определяет форму анализируемой связи, но и показывает, в какой степени изменение одного признака сопровождается изменением другого признака.
Коэффициент при х, называемый коэффициентом регрессии, показывает, на какую величину в среднем изменяется результативный признак у при изменении факторного признака х на единицу.
В примере 9 коэффициент регрессии получился равным 24,58. Следовательно, с увеличением посева, приходящегося на душу, на одну десятину сбор хлеба на душу населения в среднем увеличивается на 24,58 пуда.
Средняя и предельная ошибки коэффициента регрессии. Поскольку уравнения регрессии рассчитываются, как правило, для выборочных данных, обязательно встают вопросы точности и надежности полученных результатов. Вычисленный коэффициент регрессии, будучи выборочным, с некоторой точностью оценивает соответствующий коэффициент регрессии генеральной совокупности. Представление об этой точности дает средняя ошибка коэффициента регрессии ( ), рассчитываемая по формуле
у i , — i-e значение результативного признака; ŷ i — i-e выравненное значение, полученное из уравнения (6.15); x i —i-e значение факторного признака; σ x —среднее квадратическое отклонение х; n — число значений х или, что то же самое, значений у; m—число факгорных признаков (независимых переменных).
В формуле (6.18), в частности, формализовано очевидное положение: чем больше фактические значения отклоняются от выравненных, тем большую ошибку следует ожидать; чем меньше число наблюдений, на основе которых строится уравнение, тем больше будет ошибка.
Средняя ошибка коэффициента регрессии является основой для расчета предельной ошибки. Последняя показывает, в каких пределах находится истинное значение коэффициента регрессии при заданной надежности результатов. Предельная ошибка коэффициента регрессии вычисляется аналогично предельной ошибке средней арифметической (см. гл. 5), т. е. как t где t—величина, числовое значение которой определяется в зависимости от принятого уровня надежности.
Пример 10. Найти среднюю и предельную ошибки коэффициента регрессии, полученного в примере 9.
Для расчета прежде всего подсчитаем выравненные значения ŷ i для чего в уравнение регрессии, полученное в примере 9, подставим конкретные значения x i :
ŷ i = 17,6681 +24,5762*0,91 = 40,04 и т. д.
Затем вычислим отклонения фактических значений у i , от выравненных и их квадраты
Далее, подсчитав средний по черноземным губерниям посев на душу ( =0,98), отклонения фактических значений x i от этой средней, квадраты отклонений и среднее квадратическое отклонение , получим все необходимые составляющие формул (618) и (619):
Таким образом, средняя ошибка коэффициента регрессии равна 2,89, что составляет 12% от вычисленного коэффициента
Задавшись уровнем надежности, равным 0,95, найдем по табл. 1 приложения соответствующее ему значение t=1,96, рассчитаем предельную ошибку 1,96*2,89=5,66 и пределы коэффициента регрессии для принятого уровня надежности ( В случае малых выборок величина t находится из табл. 2 приложения. ). Нижняя граница коэффициента регрессии равна 24,58-5,66=18,92, а верхняя граница 24,58+5,66=30,24
Средняя квадратическая ошибка линии регрессии. Уравнение регрессии представляет собой функциональную связь, при которой по любому значению х можно однозначно определить значение у. Функциональная связь лишь приближенно отражает связь реальную, причем степень этого приближения может быть различной и зависит она как от свойств исходных данных, так и от выбора вида функции, по которой производится выравнивание.
На рис. 15 представлены два различных случая взаимоотношения между двумя признаками. В обоих случаях предполагаемая связь описывается одним и тем же уравнением, но во втором случае соотношение между признаками х и у достаточно четко выражено и уравнение, по-видимому, довольно хорошо описывает это соотношение, тогда как в первом случае сомнительно само наличие сколько-нибудь закономерного соотношения между признаками. И в том, и в другом случаях, несмотря на их существенное различие, метод наименьших квадратов дает одинаковое уравнение, поскольку этот метод нечувствителен к потенциальным возможностям исходного материала вписаться в ту или иную схему. Кроме того, метод наименьших квадратов применяется для расчета неизвестных параметров заранее выбранного вида функции, и вопрос о выборе наиболее подходящего для конкретных данных вида функции в рамках этого метода не ставится и не решается. Таким образом, при пользовании методом наименьших квадратов открытыми остаются два важных вопроса, а именно: существует ли связь и верен ли выбор вида функции, с помощью которой делается попытка описать форму связи.
Чтобы оценить, насколько точно уравнение регрессии описывает реальные соотношения между переменными, нужно ввести меру рассеяния фактических значений относительно вычисленных с помощью уравнения. Такой мерой служит средняя квадратическая ошибка регрессионного уравнения, вычисляемая по приведенной выше формуле (6.19).
Пример 11. Определить среднюю квадратическую ошибку уравнения, полученного в примере 9.
Промежуточные расчеты примера 10 дают нам среднюю квадратическую ошибку уравнения. Она равна 4,6 пуда.
Этот показатель аналогичен среднему квадратическому отклонению для средней. Подобно тому, как по величине среднего квадратического отклонения можно судить о представительности средней арифметической (см. гл. 5), по величине средней квадратической ошибки регрессионного уравнения можно сделать вывод о том, насколько показательна для соотношения между признаками та связь, которая выявлена уравнением. В каждом конкретном случае фактическая ошибка может оказаться либо больше, либо меньше средней. Средняя квадратическая ошибка уравнения показывает, насколько в среднем мы ошибемся, если будем пользоваться уравнением, и тем самым дает представление о точности уравнения. Чем меньше σ y.x , тем точнее предсказание линии регрессии, тем лучше уравнение регрессии описывает существующую связь. Показатель σ y.x позволяет различать случаи, представленные на рис. 15. В случае б) он окажется значительно меньше, чем в случае а). Величина σ y.x зависит как от выбора функции, так и от степени описываемой связи.
Варьируя виды функций для выравнивания и оценивая результаты с помощью средней квадратической ошибки, можно среди рассматриваемых выбрать лучшую функцию, функцию с наименьшей средней ошибкой. Но существует ли связь? Значимо ли уравнение регрессии, используемое для отображения предполагаемой связи? На эти вопросы отвечает определяемый ниже критерий значи-мости регрессии.
Мерой значимости линии регрессии может служить следующее соотношение:
где ŷ i —i-e выравненное значение; —средняя арифметическая значений y i ; σ y.x —средняя квадратическая ошибка регрессионного уравнения, вычисляемая по формуле (6.19); n—число сравниваемых пар значений признаков; m—число факторных признаков.
Действительно, связь тем больше, чем значительнее мера рассеяния признака, обусловленная регрессией, превосходит меру рассеяния отклонений фактических значений от выравненных.
Соотношение (6.20) позволяет решить вопрос о значимости регрессии. Регрессия значима, т. е. между признаками существует линейная связь, если для данного уровня значимости вычисленное значение F ф [m,n-(m+1)] превышает критическое значение F кр [m,n-(m+1)], стоящее на пересечении m-го столбца и [n—(m+1)]-й строки специальной таблицы ( см. табл. 4 приложения ).
Пример 12. Выясним, связаны ли сбор хлеба на душу населения и посев на душу населения линейной зависимостью.
Воспользуемся F-критерием значимости регрессии. Подставив в формулу (6.20) данные табл. 4 и результат примера 10, получим
Обращаясь к таблице F-распределения для Р=0,95 (α=1—Р=0,5) и учитывая, что n=23, m =1, в табл. 4А приложения на пересечения 1-го столбца и 21-й строки находим критическое значение F кр , равное 4,32 при степени надежности Р=0,95. Поскольку вычисленное значение F ф существенно превосходит по величине F кр , то обнаруженная линейная связь существенна, т. е. априорная гипотеза о наличии линейной связи подтвердилась. Вывод сделан при степени надежности P=0,95. Между прочим, вывод в данном случае останется прежним, если надежность повысить до Р=0,99 (соответствующее значение F кр =8,02 по табл. 4Б приложения для уровня значимости α=0,01).
Коэффициент детерминации. С помощью F-критерия мы Установили, что существует линейная зависимость между величиной сбора хлеба и величиной посева на душу. Следовательно, можно утверждать, что величина сбора хлеба, приходящегося на душу, линейно зависит от величины посева на душу. Теперь уместно поставить уточняющий вопрос — в какой степени величина посева на душу определяет величину сбора хлеба на душу? На этот вопрос можно ответить, рассчитав, какая часть вариации результативного признака может быть объяснена влиянием факторного признака.
Оно показывает долю разброса, учитываемого регрессией, в общем разбросе результативного признака и носит название коэффициента детерминации. Этот показатель, равный отношению факторной вариации к полной вариации признака, позволяет судить о том, насколько «удачно» выбран вид функции ( Отметим, что по смыслу коэффициент детерминации в регрессионном анализе соответствует квадрату корреляционного отношения для корреляционной таблицы (см. § 2). ). Проведя расчеты, основанные на одних и тех же исходных данных, для нескольких типов функций, мы можем из них выбрать такую, которая дает наибольшее значение R 2 и, следовательно, в большей степени, чем другие функции, объясняет вариацию результативного признака. Действительно, при расчете R 2 для одних и тех же данных, но разных функций знаменатель выражения (6.21) остается неизменным, а числитель показывает ту часть вариации результативного признака, которая учитывается выбранной функцией. Чем больше R 2 , т. е. чем больше числитель, тем больше изменение факторного признака объясняет изменение результативного признака и тем, следовательно, лучше уравнение регрессии, лучше выбор функции.
Наконец, отметим, что введенный ранее, при изложении методов корреляционного анализа, коэффициент детерминации совпадает с определенным здесь показателем, если выравнивание производится По прямой линии. Но последний показатель (R 2 ) имеет более широкий спектр применения и может использоваться в случае связи, отличной от линейной ( см. § 4 данной главы ).
Пример 13. Рассчитать коэффициент детерминации для уравнения, полученного в примере 9.
Вычислим R 2 , воспользовавшись формулой (6.21) и данными табл. 4:
Итак, уравнение регрессии почти на 78% объясняет колебания сбора хлеба на душу. Это немало, но, По-видимому, можно улучшить модель введением в нее еще одного фактора.
Случай двух независимых переменных. Простейший случай множественной регрессии. В предыдущем изложении регрессионного анализа мы имели дело с двумя признаками — результативным и факторным. Но на результат действует обычно не один фактор, а несколько, что необходимо учитывать для достаточно полного анализа связей.
В математической статистике разработаны методы множественной регрессии ( Регрессия называется множественной, если число независимых переменных, учтенных в ней, больше или равно двум. ), позволяющие анализировать влияние на результативный признак нескольких факторных. К рассмотрению этих методов мы и переходим.
Возвратимся к примеру 9. В нем была определена форма связи между величиной сбора хлеба на душу и размером посева на душу. Введем в анализ еще один фактор — уровень урожайности (см. столбец З табл. 4). Без сомнения, эта переменная влияет на сбор хлеба на душу. Но в какой степени влияет? Насколько обе независимые переменные определяют сбор хлеба на душу в черноземных губерниях? Какая из переменных — посев на душу или урожайность — оказывает определяющее влияние на сбор хлеба? Попытаемся ответить на эти вопросы.
После добавления второй независимой переменной уравнение регрессии будет выглядеть так:
где у—сбор хлеба на душу; х 1 —размер посева на душу; x 2 —урожай с десятины (в пудах); а 0 , а 1 , а 2 —параметры, подлежащие определению.
Для нахождения числовых значений искомых параметров, как и в случае одной независимой переменной, пользуются методом наименьших квадратов. Он сводится к составлению и решению системы нормальных уравнений, которая имеет вид
Когда система состоит из трех и более нормальных уравнений, решение ее усложняется. Существуют стандартные программы расчета неизвестных параметров регрессионного уравнения на ЭВМ. При ручном счете можно воспользоваться известным из школьного курса методом Гаусса.
Пример 14. По данным табл. 4 описанным способом найдем параметры a 0 , а 1 , а 2 уравнения (6.22). Получены следующие результаты: a 2 =0,3288, a 1 =28,7536, a 0 =-0,2495.
Таким образом, уравнение множественной регрессии между величиной сбора хлеба на душу населения (у), размером посева на душу (x 1 ) и уровнем урожайности (х 2 ) имеет вид:
у=-0,2495+28,7536x 1 +0,3288x 2 .
Интерпретация коэффициентов уравнения множественной регрессии. Коэффициент при х 1 в полученном уравнении отличается от аналогичного коэффициента в уравнении примера 9.
Коэффициент при независимой переменной в уравнении простой регрессии отличается от коэффициента при соответствующей переменной в уравнении множественной регрессии тем, что в последнем элиминировано влияние всех учтенных в данном уравнении признаков.
Коэффициенты уравнения множественной регрессии поэтому называются частными или чистыми коэффициентами регрессии.
Частный коэффициент множественной регрессии при х 1 показывает, что с увеличением посева на душу на 1 дес. и при фиксированной урожайности сбор хлеба на душу населения вырастает в среднем на 28,8 пуда. Частный коэффициент при x 2 показывает, что при фиксированном посеве на душу увеличение урожая на единицу, т. е. на 1 пуд с десятины, вызывает в среднем увеличение сбора хлеба на душу на 0,33 пуда. Отсюда можно сделать вывод, что увеличение сбора хлеба в черноземных губерниях России идет, в основном, за счет расширения посева и в значительно меньшей степени—за счет повышения урожайности, т. е. экстенсивная форма развития зернового хозяйства является господствующей.
Введение переменной х 2 в уравнение позволяет уточнить коэффициент при х 1 . Конкретно, коэффициент оказался выше (28,8 против 24,6), когда в изучаемой связи вычленилось влияние урожайности на сбор хлеба.
Однако выводы, полученные в результате анализа коэффициентов регрессии, не являются пока корректными, поскольку, во-первых, не учтена разная масштабность факторов, во-вторых, не выяснен вопрос о значимости коэффициента a 2 .
Величина коэффициентов регрессии изменяется в зависимости от единиц измерения, в которых представлены переменные. Если переменные выражены в разном масштабе измерения, то соответствующие им коэффициенты становятся несравнимыми. Для достижения сопоставимости коэффициенты регрессии исходного уравнения стандартизуют, взяв вместо исходных переменных их отношения к собственным средним квадратическим отклонениям. Тогда уравнение (6.22) приобретает вид
Сравнивая полученное уравнение с уравнением (6.22), определяем стандартизованные частные коэффициенты уравнения, так называемые бета-коэффициенты, по формулам:
где β 1 и β 2 —бета-коэффициенты; а 1 и а 2 —коэффициенты регрессии исходного уравнения; σ у , , и — средние квадратические отклонения переменных у, х 1 и х 2 соответственно.
Вычислив бета-коэффициенты для уравнения, полученного в примере 14:
видим, что вывод о преобладании в черноземной полосе россии экстенсивной формы развития хозяйства над интенсивной остается в силе, так как β 1 значительно больше, чем β 2 .
Оценка точности уравнения множественной регрессии.
Точность уравнения множественной регрессии, как и в случае уравнения с одной независимой переменной, оценивается средней квадратической ошибкой уравнения. Обозначим ее , где подстрочные индексы указывают, что результативным признаком в уравнении является у, а факторными признаками х 1 и x 2 . Для расчета средней квадратической ошибки уравнения множественной регрессии применяется приведенная выше формула (6.19).
Пример 15. Оценим точность полученного в примере 14 уравнения регрессии.
Воспользовавшись формулой (6.19) и данными табл. 4, вычислим среднюю квадратическую ошибку уравнения:
Оценка полезности введения дополнительной переменной. Точность уравнения регрессии тесно связана с вопросом ценности включения дополнительных членов в это уравнение.
Сравним средние квадратические ошибки, рассчитанные для уравнения с одной переменной х 1 (пример 11) и для уравнения с двумя независимыми переменными х 1 и х 2 . Включение в уравнение новой переменной (урожайности) уменьшило среднюю квадратическую ошибку почти вдвое.
Можно провести сравнение ошибок с помощью коэффициентов вариации
где σ f —средняя квадратическая ошибка регрессионного уравнения; —средняя арифметическая результативного признака.
Для уравнения, содержащего одну независимую переменную:
Для уравнения, содержащего две независимые переменные:
Итак, введение независимой переменной «урожайность» уменьшило среднюю квадратическую ошибку до величины порядка 7,95% среднего значения зависимой переменной.
Наконец, по формуле (6.21) рассчитаем коэффициент детерминации
Он показывает, что уравнение регрессии на 81,9% объясняет колебания сбора хлеба на душу населения. Сравнивая полученный результат (81,9%) с величиной R 2 для однофакторного уравнения (77,9%), видим, что включение переменной «урожайность» заметно увеличило точность уравнения.
Таким образом, сравнение средних квадратических ошибок уравнения, коэффициентов вариации, коэффициентов детерминации, рассчитанных до и после введения независимой переменной, позволяет судить о полезности включения этой переменной в уравнение. Однако следует быть осторожными в выводах при подобных сравнениях, поскольку увеличение R 2 или уменьшение σ и V σ не всегда имеют приписываемый им здесь смысл. Так, увеличение R 2 может объясняться тем фактом, что число рассматриваемых параметров в уравнении приближается к числу объектов наблюдения. Скажем, весьма сомнительными будут ссылки на увеличение R 2 или уменьшение σ, если в уравнение вводится третья или четвертая независимая переменная и уравнение строится на данных по шести, семи объектам.
Полезность включения дополнительного фактора можно оценить с помощью F-критерия.
Частный F-критерий показывает степень влияния дополнительной независимой переменной на результативный признак и может использоваться при решении вопроса о добавлении в уравнение или исключении из него этой независимой переменной.
Разброс признака, объясняемый уравнением регрессии (6.22), можно разложить на два вида: 1) разброс признака, обусловленный независимой переменной х 1 , и 2) разброс признака, обусловленный независимой переменной x 2 , когда х 1 уже включена в уравнение. Первой составляющей соответствует разброс признака, объясняемый уравнением (6.15), включающим только переменную х 1 . Разность между разбросом признака, обусловленным уравнением (6.22), и разбросом признака, обусловленным уравнением (6.15), определит ту часть разброса, которая объясняется дополнительной независимой переменной x 2 . Отношение указанной разности к разбросу признака, регрессией не объясняемому, представляет собой значение частного критерия. Частный F-критерий называется также последовательным, если статистические характеристики строятся при последовательном добавлении переменных в регрессионное уравнение.
Пример 16. Оценить полезность включения в уравнение регрессии дополнительной переменной «урожайность» (по данным и результатам примеров 12 и 15).
Разброс признака, объясняемый уравнением множественной регрессии и рассчитываемый как сумма квадратов разностей выравненных значений и их средней, равен 1623,8815. Разброс признака, объясняемый уравнением простой регрессии, составляет 1545,1331.
Разброс признака, регрессией не объясняемый, определяется квадратом средней квадратической ошибки уравнения и равен 10,9948 (см. пример 15).
Воспользовавшись этими характеристиками, рассчитаем частный F-критерий
С уровнем надежности 0,95 (α=0,05) табличное значение F (1,20), т. е. значение, стоящее на пересечении 1-го столбца и 20-й строки табл. 4А приложения, равно 4,35. Рассчитанное значение F ф значительно превосходит табличное, и, следовательно, включение в уравнение переменной «урожайность» имеет смысл.
Таким образом, выводы, сделанные ранее относительно коэффициентов регрессии, вполне правомерны.
Важным условием применения к обработке данных метода множественной регрессии является отсутствие сколько-нибудь значительной взаимосвязи между факторными признаками. При практическом использовании метода множественной регрессии, прежде чем включать факторы в уравнение, необходимо убедиться в том, что они независимы.
Если один из факторов зависит линейно от другого, то система нормальных уравнений, используемая для нахождения параметров уравнения, не разрешима. Содержательно этот факт можно толковать так: если факторы х 1 и x 2 связаны между собой, то они действуют на результативный признак у практически как один фактор, т. е. сливаются воедино и их влияние на изменение у разделить невозможно. Когда между независимыми переменными уравнения множественной регрессии имеется линейная связь, следствием которой является неразрешимость системы нормальных уравнений, то говорят о наличии мультиколлинеарности.
На практике вопрос о наличии или об отсутствии мультиколлинеарности решается с помощью показателей взаимосвязи. В случае двух факторных признаков используется парный коэффициент корреляции между ними: если этот коэффициент по абсолютной величине превышает 0,8, то признаки относят к числу мультиколлинеарных. Если число факторных признаков больше двух, то рассчитываются множественные коэффициенты корреляции. Фактор признается мультиколлинеарным, если множественный коэффициент корреляции, характеризующий совместное влияние на этот фактор остальных факторных признаков, превзойдет по величине коэффициент множественной корреляции между результативным признаком и совокупностью всех независимых переменных.
Самый естественный способ устранения мультиколлинеарности — исключение одного из двух линейно связанных факторных признаков. Этот способ прост, но не всегда приемлем, так как подлежащий исключению фактор может оказывать на зависимую переменную особое влияние. В такой ситуации применяются более сложные методы избавления от мультиколлинеарности ( См.: Мот Ж. Статистические предвидения и решения на предприятии. М., 1966; Ковалева Л. Н. Многофакторное прогнозирование на основе рядов динамики. М., 1980. ).
Выбор «наилучшего» уравнения регрессии. Эта проблема связана с двойственным отношением к вопросу о включении в регрессионное уравнение независимых переменных. С одной стороны, естественно стремление учесть все возможные влияния на результативный признак и, следовательно, включить в модель полный набор выявленных переменных. С другой стороны, возрастает сложность расчетов и затраты, связанные с получением максимума информации, могут оказаться неоправданными. Нельзя забывать и о том, что для построения уравнения регрессии число объектов должно в несколько раз превышать число независимых переменных. Эти противоречивые требования приводят к необходимости компромисса, результатом которого и является «наилучшее» уравнение регрессии. Существует несколько методов, приводящих к цели: метод всех возможных регрессий, метод исключения, метод включения, шаговый регрессионный и ступенчатый регрессионный методы.
Метод всех возможных регрессий заключается в переборе и сравнении всех потенциально возможных уравнений. В качестве критерия сравнения используется коэффициент детерминации R 2 . «Наилучшим» признается уравнение с наибольшей величиной R 2 . Метод весьма трудоемок и предполагает использование вычислительных машин.
Методы исключения и включения являются усовершенствованными вариантами предыдущего метода. В методе исключения в качестве исходного рассматривается регрессионное уравнение, включающее все возможные переменные. Рассчитывается частный F-критерий для каждой из переменных, как будто бы она была последней переменной, введенной в регрессионное уравнение. Минимальная величина частного F-критерия (F min ) сравнивается с критической величиной (F кр ), основанной на заданном исследователем уровне значимости. Если F min >F кр , то уравнение остается без изменения. Если F min кр , то переменная, для которой рассчитывался этот частный F-критерий, исключается. Производится перерасчет уравнения регрессии для оставшихся переменных, и процедура повторяется для нового уравнения регрессии. Исключение из рассмотрения уравнений с незначимыми переменными уменьшает объем вычислений, что является достоинством этого метода по сравнению с предыдущим.
Метод включения состоит в том, что в уравнение включаются переменные по степени их важности до тех пор, пока уравнение не станет достаточно «хорошим». Степень важности определяется линейным коэффициентом корреляции, показывающим тесноту связи между анализируемой независимой переменной и результативным признаком: чем теснее связь, тем больше информации о результирующем признаке содержит данный факторный признак и тем важнее, следовательно, введение этого признака в уравнение.
Процедура начинается с отбора факторного признака, наиболее тесно связанного с результативным признаком, т. е. такого факторного признака, которому соответствует максимальный по величине парный линейный коэффициент корреляции. Далее строится линейное уравнение регрессии, содержащее отобранную независимую переменную. Выбор следующих переменных осуществляется с помощью частных коэффициентов корреляции, в которых исключается влияние вошедших в модель факторов. Для каждой введенной переменной рассчитывается частный F-критерий, по величине которого судят о том, значим ли вклад этой переменной. Как только величина частного F-критерия, относящаяся к очередной переменной, оказывается незначимой, т. е. эффект от введения этой переменной становится малозаметным, процесс включения переменных заканчивается. Метод включения связан с меньшим объемом вычислений, чем предыдущие методы. Но при введении новой переменной нередко значимость включенных ранее переменных изменяется. Метод включения этого не учитывает, что является его недостатком. Модификацией метода включения, исправляющей этот недостаток, является шаговый регрессионный метод.
Шаговый регрессионный метод кроме процедуры метода включения содержит анализ переменных, включенных в уравнение на предыдущей стадии. Потребность в таком анализе возникает в связи с тем, что переменная, обоснованно введенная в уравнение на ранней стадии, может оказаться лишней из-за взаимосвязи ее с переменными, позднее включенными в уравнение. Анализ заключается в расчете на каждом этапе частных F-критериев для каждой переменной уравнения и сравнении их с величиной F кр , точкой F-распределения, соответствующей заданному исследователем уровню значимости. Частный F-критерий показывает вклад переменной в вариацию результативного признака в предположении, что она вошла в модель последней, а сравнение его с F кр позволяет судить о значимости рассматриваемой переменной с учетом влияния позднее включенных факторов. Незначимые переменные из уравнения исключаются.
Рассмотренные методы предполагают довольно большой объем вычислений и практически неосуществимы без ЭВМ. Для реализации ступенчатого регрессионного метода вполне достаточно малой вычислительной техники.
Ступенчатый регрессионный метод включает в себя такую последовательность действий. Сначала выбирается наиболее тесно связанная с результативным признаком переменная и составляется уравнение регрессии. Затем находят разности фактических и выравненных значений и эти разности (остатки) рассматриваются как значения результативной переменной. Для остатков подбирается одна из оставшихся независимых переменных и т. д. На каждой стадии проверяется значимость регрессии. Как только обнаружится незначимость, процесс прекращается и окончательное уравнение получается суммированием уравнений, полученных на каждой стадии за исключением последней.
Ступенчатый регрессионный метод менее точен, чем предыдущие, но не столь громоздок. Он оказывается полезным в случаях, когда необходимо внести содержательные правки в уравнение. Так, для изучения факторов, влияющих на цены угля в Санкт-Петербурге в конце XIX— начале XX в., было получено уравнение множественной регрессии. В него вошли следующие переменные: цены угля в Лондоне, добыча угля в России и экспорт из России. Здесь не обосновано появление в модели такого фактора, как добыча угля, поскольку Санкт-Петербург работал исключительно на импортном угле. Модели легко придать экономический смысл, если независимую переменную «добыча» заменить независимой переменной «импорт». Формально такая замена возможна, поскольку между импортом и добычей существует тесная связь. Пользуясь ступенчатым методом, исследователь может совершить эту замену, если предпочтет содержательно интерпретируемый фактор.
§ 4. Нелинейная регрессия и нелинейная корреляция
Построение уравнений нелинейной регрессии. До сих пор мы, в основном, изучали связи, предполагая их линейность. Но не всегда связь между признаками может быть достаточно хорошо представлена линейной функцией. Иногда для описания существующей связи более пригодными, а порой и единственно возможными являются более сложные нелинейные функции. Ограничимся рассмотрением наиболее простых из них.
Одним из простейших видов нелинейной зависимости является парабола, которая в общем виде может быть представлена функцией (6.2):
Неизвестные параметры а 0 , а 1 , а 2 находятся в результате решения следующей системы уравнений:
Дает ли преимущества описание связи с помощью параболы по сравнению с описанием, построенным по гипотезе линейности? Ответ на этот вопрос можно получить, рассчитав последовательный F-критерий, как это делалось в случае множественной регрессии (см. пример 16).
На практике для изучения связей используются полиномы более высоких порядков (3-го и 4-го порядков). Составление системы, ее решение, а также решение вопроса о полезности повышения порядка функции для этих случаев аналогичны описанным. При этом никаких принципиально новых моментов не возникает, но существенно увеличивается объем расчетов.
Кроме класса парабол для анализа нелинейных связей можно применять и другие виды функций. Для расчета неизвестных параметров этих функций рекомендуется использовать метод наименьших квадратов, как наиболее мощный и широко применяемый.
Однако метод наименьших квадратов не универсален, поскольку он может использоваться только при условии, что выбранные для выравнивания функции линейны по отношению к своим параметрам. Не все функции удовлетворяют этому условию, но большинство применяемых на практике с помощью специальных преобразований могут быть приведены к стандартной форме функции с линейными параметрами.
Рассмотрим некоторые простейшие способы приведения функций с нелинейными параметрами к виду, который позволяет применять к ним метод наименьших квадратов.
Функция не является линейной относительно своих параметров.
Прологарифмировав обе части приведенного равенства
получим функцию, линейную относительно своих новых параметров:
Кроме логарифмирования для приведения функций к нужному виду используют обратные величины.
с помощью следующих переобозначений:
может быть приведена к виду
Подобные преобразования расширяют возможности использования метода наименьших квадратов, увеличивая число функций, к которым этот метод применим.
Измерение тесноты связи при криволинейной зависимости. Рассмотренные ранее линейные коэффициенты корреляции оценивают тесноту взаимосвязи при линейной связи между признаками. При наличии криволинейной связи указанные меры связи не всегда приемлемы. Разберем подобную ситуацию на примере.
Пример 17. В 1-м и 2-м столбцах табл. 5 приведены значения результативного признака у и факторного признака х (данные условные). Поставив вопрос о тесноте связи между ними, рассчитаем парный линейный коэффициент корреляции по формуле (6.3). Он оказался равным нулю, что свидетельствует об отсутствии линейной связи. Тем не менее связь между признаками существует, более того, она является функциональной и имеет вид
Для измерения тесноты связи при криволинейной зависимости используется индекс корреляции, вычисляемый по формуле
где у i —i-e значение результативного признака; ŷ i —i-e выравненное значение этого признака; —среднее арифметическое значение результативного признака.
Числитель формулы (6.27) характеризует разброс выравненных значений результативного признака. Поскольку изменения выравненных, т. е. вычисленных по уравнению регрессии, значений признака происходят только в результате изменения факторного признака х. то числитель измеряет разброс результативного признака, обусловленный влиянием на него факторного признака. Знаменатель же измеряет разброс признака-результата, который определен влиянием на него всех факторов, в том числе и учтенного. Таким образом, индекс корреляции оценивает участие данного факторного признака в общем действии всего комплекса факторов, вызывающих колеблемость результативного признака, тем самым определяя тесноту зависимости признака у от признака х. При этом, если признак х не вызывает никаких изменений признака у, то числитель и, следовательно, индекс корреляции равны 0. Если же линия регрессии полностью совпадает с фактическими данными, т. е. признаки связаны функционально, как в примере 17, то индекс корреляции равен 1. В случае линейной зависимости между х и у индекс корреляции численно равен линейному коэффициенту корреляции г. Квадрат индекса корреляции совпадает с введенным ранее (6.21) коэффициентом детерминации. Если же вопрос о форме связи не ставится, то роль коэффициента детерминации играет квадрат корреляционного отношения η 2 y/x (6.12).
Таковы основные принципы и условия, методика и техника применения корреляционного и регрессионного анализа. Их подробное рассмотрение обусловлено тем, что они являются высокоэффективными и потому очень широко применяемыми методами анализа взаимосвязей в объективном мире природы и общества. Корреляционный и регрессионный анализ широко и успешно применяются и в исторических исследованиях.
http://desktop.arcgis.com/ru/arcmap/10.3/tools/spatial-statistics-toolbox/regression-analysis-basics.htm
http://masters.donntu.org/2005/kita/tokarev/library/linreg.htm