Критерий Фишера и критерий Стьюдента в эконометрике
С помощью критерия Фишера оценивают качество регрессионной модели в целом и по параметрам.
Для этого выполняется сравнение полученного значения F и табличного F значения. F-критерия Фишера. F фактический определяется из отношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:
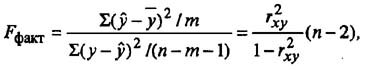
где n — число наблюдений;
m — число параметров при факторе х.
F табличный — это максимальное значение критерия под влиянием случайных факторов при текущих степенях свободы и уровне значимости а.
Уровень значимости а — вероятность не принять гипотезу при условии, что она верна. Как правило а принимается равной 0,05 или 0,01.
Если Fтабл > Fфакт то признается статистическая незначимость модели, ненадежность уравнения регрессии.
Таблицы по нахождению критерия Фишера и Стьюдента
Таблицы значений F-критерия Фишера и t-критерия Стьюдента Вы можете посмотреть здесь.
Табличное значение критерия Фишера вычисляют следующим образом:
- Определяют k1, которое равно количеству факторов (Х). Например, в однофакторной модели (модели парной регрессии) k1=1, в двухфакторной k=2.
- Определяют k2, которое определяется по формуле n — m — 1, где n — число наблюдений, m — количество факторов. Например, в однофакторной модели k2 = n — 2.
- На пересечении столбца k1 и строки k2 находят значение критерия Фишера
Для нахождения табличного значения критерия Стьюдента определяют число степеней свободы, которое определяется по формуле n — m — 1 и находят его значение при определенном уровне значимости (0,10, 0,05, 0,01).
Критерии Стьюдента
Для оценки статистической значимости модели по параметрам рассчитывают t-критерии Стьюдента.
Оценка значимости модели с помощью критерия Стьюдента проводится путем сравнения их значений с величиной случайной ошибки:
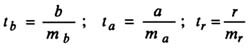
Случайные ошибки коэффициентов линейной регрессии и коэффициента корреляции определяются по формулам:
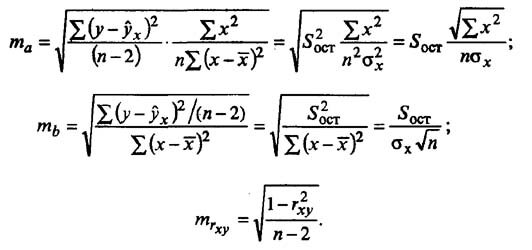
Сравнивая фактическое и табличное значения t-статистики и принимается или отвергается гипотеза о значимости модели по параметрам.
Зависимость между критерием Фишера и значением t-статистики Стьюдента определяется так
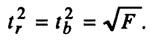
Как и в случае с оценкой значимости уравнения модели в целом, модель считается ненадежной если tтабл > tфакт
Видео лекциий по расчету критериев Фишера и Стьюдента
Для более подробного изучения расчетов критериев Фишера и Стьюдента советуем посмотреть это видео
Лекция 1. Критерии и Гипотезы
Лекция 2. Критерии и Гипотезы
Лекция 3. Критерии и Гипотезы
Определение доверительных интервалов
Для построения доверительного интервала определяется предельная ошибка А для обоих показателей:

Формулы для нахождения доверительных интервалов выглядят так
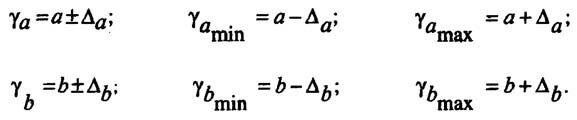
Прогнозное значение у определяется с помощью подстановки в
уравнение регрессии прогнозного значения х. Вычисляется средняя стандартная ошибка прогноза
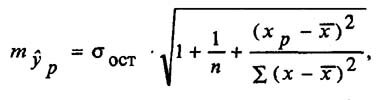
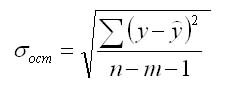
и находится доверительный интервал
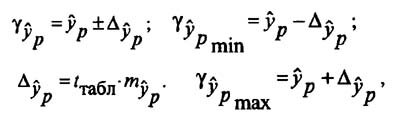
Задача регрессионного анализа в предмете эконометрика состоит в анализе дисперсии изучаемого показателя y:
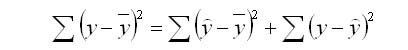
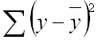 общая сумма квадратов отклонений (TSS)
общая сумма квадратов отклонений (TSS)
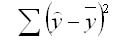 сумма квадратов отклонений, обусловленная регрессией (RSS)
сумма квадратов отклонений, обусловленная регрессией (RSS)
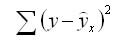 остаточная сумма квадратов отклонений (ESS)
остаточная сумма квадратов отклонений (ESS)
Долю дисперсии, обусловленную регрессией, в общей дисперсии показателя у характеризует коэффициент детерминации R, который должен превышать 50% (R 2 > 0,5). В контрольных по эконометрике в ВУЗах этот показатель рассчитывается всегда.
Использование критерия Стьюдента для проверки значимости параметров регрессионной модели
Проверка статистической значимости параметров регрессионного уравнения (коэффициентов регрессии) выполняется по t-критерию Стьюдента, который рассчитывается по формуле:

где P — значение параметра;
Sp — стандартное отклонение параметра.
Рассчитанное значение критерия Стьюдента сравнивают с его табличным значением при выбранной доверительной вероятности (как правило, 0.95) и числе степеней свободы N—k-1, где N-число точек, k-число переменных в регрессионном уравнении (например, для линейной модели Y=A*X+B подставляем k=1).
Если вычисленное значение tp выше, чем табличное, то коэффициент регрессии является значимым с данной доверительной вероятностью. В противном случае есть основания для исключения соответствующей переменной из регрессионной модели.
Величины параметров и их стандартные отклонения обычно рассчитываются в алгоритмах, реализующих метод наименьших квадратов.
Конспект курса «Основы статистики»
1. Введение
Генеральная совокупность — множество всех объектов, относительно которых предполагается делать выводы при изучении конкретной задачи.
Выборка — часть генеральной совокупности, которая охватывается экспериментом.
Репрезентативная выборка — выборка, в которой все основные признаки генеральной совокупности, из которой извлечена данная выборка, представлены приблизительно в той же пропорции или с той же частотой, с которой данный признак выступает в этой генеральной совокупности.
Унимодальное распределение — распределение, имеющее только одну моду (пример: нормальное распределение)

Способы формирования репрезентативной выборки:
Простая случайная выборка (simple random sample)
Стратифицированная выборка (stratified sample)
Групповая выборка (cluster sample)
Типы переменных:
непрерывные (рост в мм)
дискретные (количество публикаций у учёного)
Ранговые (успеваемость студентов)
Гистограмма частот:
Позволяет сделать первое впечатление о форме распределения некоторого количественного признака.
Описательные статистики:
Меры центральной тенденции (узкий диапазон, высокие значения признака):
Мода (mode) — значение во множестве наблюдений, которое встречается наиболее часто.
Медиана (median) — значение признака, которое делит упорядоченное множество пополам.
Среднее значение (mean, среднее арифметическое) — сумма всех значений измеренного признака, делённая на количество измеренных значений.
(  используется для среднего значения из выборки, а для генеральной совокупности латинская буква
используется для среднего значения из выборки, а для генеральной совокупности латинская буква  )
)
Свойства среднего:

Если к каждому значению выборки прибавить определённое число, то и среднее значение увеличится на это число.

Если каждое значение выборки умножить на определённое число, то и среднее значение увеличится в это число раз.

Если для каждого значения выборки, рассчитать такой показатель как его отклонение от среднего арифметического, то сумма этих отклонений будет равняться нулю.
Меры изменчивости (широкий диапазон, вариативность признака):
Размах (range) — разность максимального и минимального значения.

При добавлении сильно отличающегося значения данные меняются сильно и могут быть некорректные.
Дисперсия (variance) — средний квадрат отклонений индивидуальных значений признака от их средней величины.
Дисперсия генеральной совокупности:

 (среднеквадратическое отклонение генеральной совокупности)
(среднеквадратическое отклонение генеральной совокупности)

 (среднеквадратическое отклонение выборки)
(среднеквадратическое отклонение выборки)
Свойства дисперсии:




Квартили распределения и график box-plot
Квартили — три точки (значения признака), которые делят упорядоченное множество данных на четыре равные части.
Box-plot — такой вид диаграммы в удобной форме показывает медиану (или, если нужно, среднее), нижний и верхний квартили, минимальное и максимальное значение выборки и выбросы.
Нормальное распределение
Отклонения наблюдений от среднего подчиняются определённому вероятностному закону.
Стандартизация
Стандартизация или z-преобразование — преобразование полученных данных в стандартную Z-шкалу (Z-scores) со средним  и
и 




Правило «двух» и «трёх» сигм


Центральная предельная теорема
Центральная предельная теорема — класс теорем в теории вероятностей, утверждающих, что сумма большого количества независимых случайных величин имеет распределение близкое к нормальному. Так как многие случайные величины в приложениях являются суммами нескольких случайных факторов, центральные предельные теоремы обосновывают популярность нормального распределения.
Есть признак, распределенный КАК УГОДНО* с некоторым средним и некоторым стандартным отклонением. Тогда, если выбирать из этой совокупности выборки объема n, то их средние тоже будут распределены нормально со средним равным среднему признака в ГС и стандартным отклонением  .
.
Стандартная ошибка среднего — теоретическое стандартное отклонение всех средних выборки размера , извлекаемое из совокупности.

30″ alt=»SE = \frac
Доверительные интервалы для среднего
Доверительный интервал является показателем точности измерений. Это также показатель того, насколько стабильна полученная величина, то есть насколько близкую величину (к первоначальной величине) вы получите при повторении измерений (эксперимента).
Идея статистического вывода
P-значение (P-value) — величина, используемая при тестировании статистических гипотез. Фактически это вероятность ошибки при отклонении нулевой гипотезы (ошибки первого рода).
2. Сравнение средних
T-распределение
Если число наблюдений невелико и \sigma неизвестно (почти всегда), используется распределение Стьюдента (t-distribution).
Унимодально и симметрично, но: наблюдения с большей вероятностью попадают за пределы  от
от 
«Форма» распределения определяется числом степеней свободы ( ).
).
С увеличением числа  распределение стремится к нормальному.
распределение стремится к нормальному.

t-распределение используется не потому что у нас маленькие выборки, а потому что мы не знаем стандартное отклонение в генеральной совокупности.
Сравнение двух средних; t-критерий Стьюдента
Критерий, который позволяет сравнивать средние значения двух выборок между собой, называется t-критерий Стьюдента.
Условия для корректности использования t-критерия Стьюдента:
Две независимые группы
Формула стандартной ошибки среднего:

Формула числа степеней свободы:

Формула t-критерия Стьюдента:

Переход к p-критерию:
Проверка распределения на нормальность, QQ-Plot
Однофакторный дисперсионный анализ
Часто в исследованиях необходимо сравнить несколько групп между собой. В таком случае применятся однофакторный дисперсионный анализ.
Незвисимая переменная — номинативная перменная с нескольким градациями, разделяющая наблюдения на группы.
Зависимая перемнная — количественная переменная, по степени выраженности которой сравниваются группы.
1
2
3
Группы:
Нулевая гипотеза:

Альтернативная гипотеза:

Среднее значение всех наблюдений:

Общая сумма квадратов (Total sum of sqares):

Показатель, который характеризует насколько высока изменчивость данных, без учёта разделения их на группы.
Число степеней свободы:

 — Межгрупповая сумма квадратов (Sum of sqares between groups)
— Межгрупповая сумма квадратов (Sum of sqares between groups)
 — Внутригрупповая сумма квадратов (Sum of sqares within groups)
— Внутригрупповая сумма квадратов (Sum of sqares within groups)





F-значение (основной статистический показатель дисперсионного анализа):

Межгрупповой средний квадрат — усредненное значение межгрупповой суммы квадратов.
При делении значения межгрупповой суммы квадратов на число степеней свободы, полученный показатель усредняется.

Внутригрупповой средний квадрат — отношение внутригрупповой суммы квадратов к числу степеней свободы.

Поэтому формула F-значения часто записывается:

Множественные сравнения в ANOVA
Проблема множественных сравнений:
Чем больше статистических гипотез проверяется на одних и тех же данных, тем вероятнее ошибка первого рода — заключение о наличии различий между группами, тогда как на самом деле верна нулевая гипотеза об отсутствии различий.
Поправка Бонферрони
Самый простой (и консервативный) метод: P-значения умножаются на число выполненных сравнений.
Критерий Тьюки
Критерий Тьюки используется для проверки нулевой гипотезы  против альтернативной гипотезы
против альтернативной гипотезы  , где индексы
, где индексы  и
и  обозначают любые две сравниваемые группы.
обозначают любые две сравниваемые группы.
Указанные сравнения выполняются при помощи критерия Тьюки, который представляет собой модифицированный критерий Стьюдента:

Отличие от критерия Стьюдента заключается в том, как рассчитывается стандартная ошибка $SE$:

где  — рассчитываемая в ходе дисперсионного анализа внутригрупповая дисперсия.
— рассчитываемая в ходе дисперсионного анализа внутригрупповая дисперсия.
Многофакторный ANOVA
При применении двухфакторного дисперсионного анализа исследователь проверяет влияние двух независимых переменных (факторов) на зависимую переменную. Может быть изучен также эффект взаимодействия двух переменных.
Исследуемые группы называют эффектами обработки. Схема двухфакторного дисперсионного анализа имеет несколько нулевых гипотез: одна для каждой независимой переменной и одна для взаимодействия.
Условия применения двухмерного дисперсионного анализа:
Генеральные совокупности, из которых извлечены выборки, должны быть нормально распределены.
Выборки должны быть независимыми.
Дисперсии генеральных совокупностей, из которых извлекались выборки, должны быть равными.
Группы должны иметь одинаковый объем выборки.
АБ тесты и статистика
АБ тестирование — это проведение экспериментов при помощи статистики, пожалуй, самый яркий пример того, зачем статистика нужна в реальной жизни. Этот метод маркетингового исследования заключается в том, что контрольная группа элементов сравнивается с набором тестовых групп, где один или несколько показателей изменены для того, чтобы выяснить, какие из изменений улучшают целевой показатель. Например, мы можем поменять цвет кнопки для регистрации с красного на синий и сравнить, насколько это будет эффективно.
3. Корреляция и регрессия
Понятие корреляции
Корреляция — статистическая взаимосвязь двух или более случайных величин. При этом изменения значений одной или нескольких из этих величин сопутствуют систематическому изменению значений другой или других величин.
Коэффициент корреляции – это статистическая мера, которая вычисляет силу связи между относительными движениями двух переменных.
Принимает значения [-1, 1]

 — показатель силы и направления взаимосвязи двух количественных переменных.
— показатель силы и направления взаимосвязи двух количественных переменных.
Знак коэффициента корреляции показывает направление взаимосвязи.
Коэффициент детерминации
 — показывает, в какой степени дисперсия одной переменной обусловлена влиянием другой переменной.
— показывает, в какой степени дисперсия одной переменной обусловлена влиянием другой переменной.
Равен квадрату коэффициента корреляции.
Принимает значения [0, 1]
Условия применения коэффициента корреляции
Для применения коэффициента корреляции Пирсона, необходимо соблюдать следующие условия:
Сравниваемые переменные должны быть получены в интервальной шкале или шкале отношений.
Распределения переменных  и
и  должны быть близки к нормальному.
должны быть близки к нормальному.
Число варьирующих признаков в сравниваемых переменных  и
и  должно быть одинаковым.
должно быть одинаковым.
Коэффициент корреляции Спирмена
Коэффициент ранговой корреляции Спирмена — это количественная оценка статистического изучения связи между явлениями, используемая в непараметрических методах.

Регрессия с одной независимой переменной
Уравнение прямой:

 — (intersept) отвечает за то, где прямая пересекает ось y.
— (intersept) отвечает за то, где прямая пересекает ось y.
 — (slope) отвечает за направление и угол наклона, образованный с осью x.
— (slope) отвечает за направление и угол наклона, образованный с осью x.
Метод наименьших квадратов
МНК — метод нахождения оптимальных параметров линейной регрессии, таких, что сумма квадратов остатков была минимальна.
Формула нахождения остатка:

 — остаток
— остаток
 — реальное значение
— реальное значение
 — значение, которое предсказывает регрессионная прямая
— значение, которое предсказывает регрессионная прямая
Сумма квадратов всех остатков:

Параметры линейной регрессии:


Гипотеза о значимости взаимосвязи и коэффициент детерминации
Коэффициенты линейной регрессии
Коэффициенты регрессии (β) — это коэффициенты, которые рассчитываются в результате выполнения регрессионного анализа. Вычисляются величины для каждой независимой переменной, которые представляют силу и тип взаимосвязи независимой переменной по отношению к зависимой.
Коэффициент детерминации
 — доля дисперсии зависимой переменной (Y), объясняем регрессионной моделью.
— доля дисперсии зависимой переменной (Y), объясняем регрессионной моделью.

 — сумма квадратов остатков
— сумма квадратов остатков
 — сумма квадратов общая
— сумма квадратов общая
Условия применения линейной регрессии с одним предиктором
Линейная взаимосвязь  и
и 
Нормальное распределение остатков
Гомоскедастичность — постоянная изменчивость остатков на всех уровнях независимой переменной
Регрессионный анализ с несколькими независимыми переменными
Множественная регрессия (Multiple Regression)
Множественная регрессия позволяет исследовать влияние сразу нескольких независимых переменных на одну зависимую.
Требования к данным
линейная зависимость переменных
нормальное распределение остатков
проверка на мультиколлинеарность
нормальное распределение переменных (желательно)
http://www.chem-astu.ru/science/reference/student.html
http://habr.com/ru/post/591023/