Метод наименьших квадратов
Начнем статью сразу с примера. У нас есть некие экспериментальные данные о значениях двух переменных – x и y . Занесем их в таблицу.
| i = 1 | i = 2 | i = 3 | i = 4 | i = 5 | |
| x i | 0 | 1 | 2 | 4 | 5 |
| y i | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 , 0 |
После выравнивания получим функцию следующего вида: g ( x ) = x + 1 3 + 1 .
Мы можем аппроксимировать эти данные с помощью линейной зависимости y = a x + b , вычислив соответствующие параметры. Для этого нам нужно будет применить так называемый метод наименьших квадратов. Также потребуется сделать чертеж, чтобы проверить, какая линия будет лучше выравнивать экспериментальные данные.
В чем именно заключается МНК (метод наименьших квадратов)
Главное, что нам нужно сделать, – это найти такие коэффициенты линейной зависимости, при которых значение функции двух переменных F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 будет наименьшим. Иначе говоря, при определенных значениях a и b сумма квадратов отклонений представленных данных от получившейся прямой будет иметь минимальное значение. В этом и состоит смысл метода наименьших квадратов. Все, что нам надо сделать для решения примера – это найти экстремум функции двух переменных.
Как вывести формулы для вычисления коэффициентов
Для того чтобы вывести формулы для вычисления коэффициентов, нужно составить и решить систему уравнений с двумя переменными. Для этого мы вычисляем частные производные выражения F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 по a и b и приравниваем их к 0 .
δ F ( a , b ) δ a = 0 δ F ( a , b ) δ b = 0 ⇔ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) x i = 0 — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) = 0 ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + ∑ i = 1 n b = ∑ i = 1 n y i ⇔ a ∑ i = 1 n x i 2 + b ∑ i = 1 n x i = ∑ i = 1 n x i y i a ∑ i = 1 n x i + n b = ∑ i = 1 n y i
Для решения системы уравнений можно использовать любые методы, например, подстановку или метод Крамера. В результате у нас должны получиться формулы, с помощью которых вычисляются коэффициенты по методу наименьших квадратов.
n ∑ i = 1 n x i y i — ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n — ∑ i = 1 n x i 2 b = ∑ i = 1 n y i — a ∑ i = 1 n x i n
Мы вычислили значения переменных, при который функция
F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 примет минимальное значение. В третьем пункте мы докажем, почему оно является именно таким.
Это и есть применение метода наименьших квадратов на практике. Его формула, которая применяется для поиска параметра a , включает в себя ∑ i = 1 n x i , ∑ i = 1 n y i , ∑ i = 1 n x i y i , ∑ i = 1 n x i 2 , а также параметр
n – им обозначено количество экспериментальных данных. Советуем вам вычислять каждую сумму отдельно. Значение коэффициента b вычисляется сразу после a .
Обратимся вновь к исходному примеру.
Здесь у нас n равен пяти. Чтобы было удобнее вычислять нужные суммы, входящие в формулы коэффициентов, заполним таблицу.
| i = 1 | i = 2 | i = 3 | i = 4 | i = 5 | ∑ i = 1 5 | |
| x i | 0 | 1 | 2 | 4 | 5 | 12 |
| y i | 2 , 1 | 2 , 4 | 2 , 6 | 2 , 8 | 3 | 12 , 9 |
| x i y i | 0 | 2 , 4 | 5 , 2 | 11 , 2 | 15 | 33 , 8 |
| x i 2 | 0 | 1 | 4 | 16 | 25 | 46 |
Решение
Четвертая строка включает в себя данные, полученные при умножении значений из второй строки на значения третьей для каждого отдельного i . Пятая строка содержит данные из второй, возведенные в квадрат. В последнем столбце приводятся суммы значений отдельных строчек.
Воспользуемся методом наименьших квадратов, чтобы вычислить нужные нам коэффициенты a и b . Для этого подставим нужные значения из последнего столбца и подсчитаем суммы:
n ∑ i = 1 n x i y i — ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n — ∑ i = 1 n x i 2 b = ∑ i = 1 n y i — a ∑ i = 1 n x i n ⇒ a = 5 · 33 , 8 — 12 · 12 , 9 5 · 46 — 12 2 b = 12 , 9 — a · 12 5 ⇒ a ≈ 0 , 165 b ≈ 2 , 184
У нас получилось, что нужная аппроксимирующая прямая будет выглядеть как y = 0 , 165 x + 2 , 184 . Теперь нам надо определить, какая линия будет лучше аппроксимировать данные – g ( x ) = x + 1 3 + 1 или 0 , 165 x + 2 , 184 . Произведем оценку с помощью метода наименьших квадратов.
Чтобы вычислить погрешность, нам надо найти суммы квадратов отклонений данных от прямых σ 1 = ∑ i = 1 n ( y i — ( a x i + b i ) ) 2 и σ 2 = ∑ i = 1 n ( y i — g ( x i ) ) 2 , минимальное значение будет соответствовать более подходящей линии.
σ 1 = ∑ i = 1 n ( y i — ( a x i + b i ) ) 2 = = ∑ i = 1 5 ( y i — ( 0 , 165 x i + 2 , 184 ) ) 2 ≈ 0 , 019 σ 2 = ∑ i = 1 n ( y i — g ( x i ) ) 2 = = ∑ i = 1 5 ( y i — ( x i + 1 3 + 1 ) ) 2 ≈ 0 , 096
Ответ: поскольку σ 1 σ 2 , то прямой, наилучшим образом аппроксимирующей исходные данные, будет
y = 0 , 165 x + 2 , 184 .
Как изобразить МНК на графике функций
Метод наименьших квадратов наглядно показан на графической иллюстрации. С помощью красной линии отмечена прямая g ( x ) = x + 1 3 + 1 , синей – y = 0 , 165 x + 2 , 184 . Исходные данные обозначены розовыми точками.
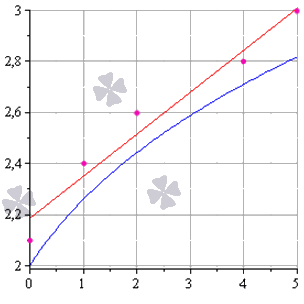
Поясним, для чего именно нужны приближения подобного вида.
Они могут быть использованы в задачах, требующих сглаживания данных, а также в тех, где данные надо интерполировать или экстраполировать. Например, в задаче, разобранной выше, можно было бы найти значение наблюдаемой величины y при x = 3 или при x = 6 . Таким примерам мы посвятили отдельную статью.
Доказательство метода МНК
Чтобы функция приняла минимальное значение при вычисленных a и b , нужно, чтобы в данной точке матрица квадратичной формы дифференциала функции вида F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 была положительно определенной. Покажем, как это должно выглядеть.
У нас есть дифференциал второго порядка следующего вида:
d 2 F ( a ; b ) = δ 2 F ( a ; b ) δ a 2 d 2 a + 2 δ 2 F ( a ; b ) δ a δ b d a d b + δ 2 F ( a ; b ) δ b 2 d 2 b
Решение
δ 2 F ( a ; b ) δ a 2 = δ δ F ( a ; b ) δ a δ a = = δ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) x i δ a = 2 ∑ i = 1 n ( x i ) 2 δ 2 F ( a ; b ) δ a δ b = δ δ F ( a ; b ) δ a δ b = = δ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) x i δ b = 2 ∑ i = 1 n x i δ 2 F ( a ; b ) δ b 2 = δ δ F ( a ; b ) δ b δ b = δ — 2 ∑ i = 1 n ( y i — ( a x i + b ) ) δ b = 2 ∑ i = 1 n ( 1 ) = 2 n
Иначе говоря, можно записать так: d 2 F ( a ; b ) = 2 ∑ i = 1 n ( x i ) 2 d 2 a + 2 · 2 ∑ x i i = 1 n d a d b + ( 2 n ) d 2 b .
Мы получили матрицу квадратичной формы вида M = 2 ∑ i = 1 n ( x i ) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n .
В этом случае значения отдельных элементов не будут меняться в зависимости от a и b . Является ли эта матрица положительно определенной? Чтобы ответить на этот вопрос, проверим, являются ли ее угловые миноры положительными.
Вычисляем угловой минор первого порядка: 2 ∑ i = 1 n ( x i ) 2 > 0 . Поскольку точки x i не совпадают, то неравенство является строгим. Будем иметь это в виду при дальнейших расчетах.
Вычисляем угловой минор второго порядка:
d e t ( M ) = 2 ∑ i = 1 n ( x i ) 2 2 ∑ i = 1 n x i 2 ∑ i = 1 n x i 2 n = 4 n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2
После этого переходим к доказательству неравенства n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 > 0 с помощью математической индукции.
- Проверим, будет ли данное неравенство справедливым при произвольном n . Возьмем 2 и подсчитаем:
2 ∑ i = 1 2 ( x i ) 2 — ∑ i = 1 2 x i 2 = 2 x 1 2 + x 2 2 — x 1 + x 2 2 = = x 1 2 — 2 x 1 x 2 + x 2 2 = x 1 + x 2 2 > 0
У нас получилось верное равенство (если значения x 1 и x 2 не будут совпадать).
- Сделаем предположение, что данное неравенство будет верным для n , т.е. n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 > 0 – справедливо.
- Теперь докажем справедливость при n + 1 , т.е. что ( n + 1 ) ∑ i = 1 n + 1 ( x i ) 2 — ∑ i = 1 n + 1 x i 2 > 0 , если верно n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 > 0 .
( n + 1 ) ∑ i = 1 n + 1 ( x i ) 2 — ∑ i = 1 n + 1 x i 2 = = ( n + 1 ) ∑ i = 1 n ( x i ) 2 + x n + 1 2 — ∑ i = 1 n x i + x n + 1 2 = = n ∑ i = 1 n ( x i ) 2 + n · x n + 1 2 + ∑ i = 1 n ( x i ) 2 + x n + 1 2 — — ∑ i = 1 n x i 2 + 2 x n + 1 ∑ i = 1 n x i + x n + 1 2 = = ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 + n · x n + 1 2 — x n + 1 ∑ i = 1 n x i + ∑ i = 1 n ( x i ) 2 = = ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 + x n + 1 2 — 2 x n + 1 x 1 + x 1 2 + + x n + 1 2 — 2 x n + 1 x 2 + x 2 2 + . . . + x n + 1 2 — 2 x n + 1 x 1 + x n 2 = = n ∑ i = 1 n ( x i ) 2 — ∑ i = 1 n x i 2 + + ( x n + 1 — x 1 ) 2 + ( x n + 1 — x 2 ) 2 + . . . + ( x n — 1 — x n ) 2 > 0
Выражение, заключенное в фигурные скобки, будет больше 0 (исходя из того, что мы предполагали в пункте 2 ), и остальные слагаемые будут больше 0 , поскольку все они являются квадратами чисел. Мы доказали неравенство.
Ответ: найденные a и b будут соответствовать наименьшему значению функции F ( a , b ) = ∑ i = 1 n ( y i — ( a x i + b ) ) 2 , значит, они являются искомыми параметрами метода наименьших квадратов (МНК).
Методы наименьших квадратов: текст, написанный программистом для программистов
Продолжаю публикацию своих лекций, изначально предназначенных для студентов, учащихся по специальности «цифровая геология». На хабре это уже третья публикация из цикла, первая статья была вводной, она необязательна к прочтению. Однако же для понимания этой статьи необходимо прочитать введение в системы линейных уравнений даже в том случае, если вы знаете, что это такое, так как я буду много ссылаться на примеры из этого введения.
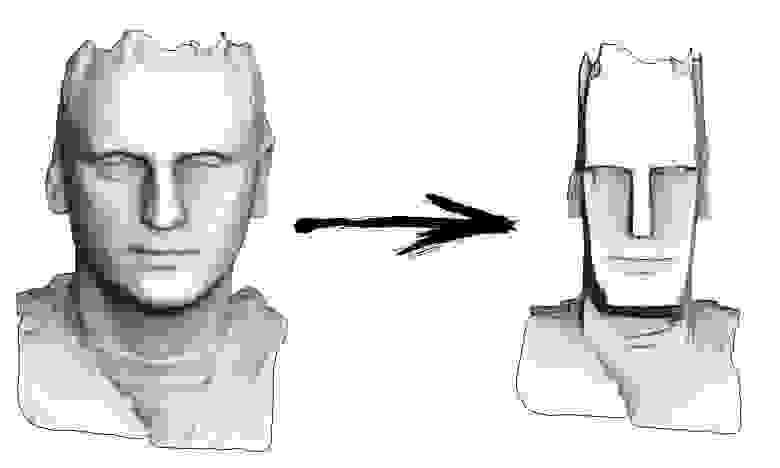
Итак, задача на сегодня: научиться простейшей обработке геометрии, чтобы, например, суметь преобразовать мою голову в истукана с острова Пасхи:
Текущий план лекций:
- Ликбез по теории вероятностей (статья вводная, необязательная)
- Введение в системы линейных уравнений
- Минимизация квадратичных форм и примеры задач МНК
- От наименьших квадратов к нейронным сетям
Официальный репозиторий курса живёт здесь. Книга ещё не окончена, я потихоньку компилирую воедино статьи, опубликованные на Хабре.
В рамках этой статьи моим основным инструментом будет поиск минимума квадратичных функций; но, прежде чем мы начнём этим инструментом пользоваться, нужно хотя бы понять, где у него кнопка вкл/выкл. Для начала освежим память и вспомним, что такое матрицы, что такое положительное число, а также что такое производная.
Матрицы и числа
В этом тексте я буду обильно пользоваться матричными обозначениями, так что давайте вспоминать, что это такое. Не подглядывайте дальше по тексту, сделайте паузу на несколько секунд, и попробуйте сформулировать, что такое матрица.
Различные интерпретации матриц
Ответ очень простой. Матрица это просто шкафчик, в котором хранятся хреновины. Каждая хреновина лежит в своей ячейке, ячейки группируются рядами в строки и столбцы. В нашем конкретном случае хреновинами будут обычные вещественные числа; для программиста проще всего представлять матрицу  как нечто навроде
как нечто навроде
Зачем же такие хранилища нужны? Что они описывают? Может быть, я вас расстрою, но сама по себе матрица не описывает ничего, она хранит. Например, в ней можно хранить коэффициенты всяких функций. Давайте на секунду забудем про матрицы, и представим, что у нас есть число  . Что оно означает? Да чёрт его знает… Например, это может быть коэффициент внутри функции, которая на вход берёт одно число, и на выход даёт другое число:
. Что оно означает? Да чёрт его знает… Например, это может быть коэффициент внутри функции, которая на вход берёт одно число, и на выход даёт другое число:

Одну версию такой функции математик мог бы записать как

Ну а в мире программистов она бы выглядела следующим образом:
С другой стороны, а почему такая функция, а не совсем другая? Давайте возьмём другую!

Раз уж я начал про программистов, я обязан записать её код 🙂
Одна из этих функций линейная, а вторая квадратичная. Какая из них правильная? Да никакая, само по себе число не определяет этого, оно просто хранит какое-то значение! Какую вам надо функцию, такую и стройте.
То же самое происходит и с матрицами, это хранилища, нужные на случай, когда одиночных чисел (скаляров) не хватает, своего рода расширение чисел. Над матрицами, ровно как и над числами, определены операции сложения и умножения.
Давайте представим, что у нас есть матрица , например, размера 2×2:

Эта матрица сама по себе ничего не значит, например, она может быть интерпретирована как функция

Эта функция преобразует двумерный вектор в двумерный вектор. Графически это удобно представлять как преобразование изображения: на вход даём изображение, а на выходе получаем его растянутую и/или повёрнутую (возможно даже зеркально отражённую!) версию. Очень скоро я приведу картинку с различными примерами такой интерпретации матриц.
А можно матрицу представлять себе как функцию, которая двумерный вектор преобразует в скаляр:

Обратите внимание, что с векторами возведение в степень не очень-то определено, поэтому я не могу написать  , как писал в случае с обычными числами. Очень рекомендую тем, кто не привык с лёгкостью жонглировать матричными умножениями, ещё раз вспомнить правило умножения матриц, и проверить, что выражение
, как писал в случае с обычными числами. Очень рекомендую тем, кто не привык с лёгкостью жонглировать матричными умножениями, ещё раз вспомнить правило умножения матриц, и проверить, что выражение  вообще разрешено и действительно даёт скаляр на выходе. Для этого можно, например, явно поставить скобки
вообще разрешено и действительно даёт скаляр на выходе. Для этого можно, например, явно поставить скобки  . Напоминаю, что у нас
. Напоминаю, что у нас  — вектор размерности 2 (сохранённый в матрице размерности 2×1), выпишем явно все размерности:
— вектор размерности 2 (сохранённый в матрице размерности 2×1), выпишем явно все размерности:

Возвращаясь в тёплый и пушистый мир программистов, мы можем записать эту же квадратичную функцию как-то так:
Что такое положительное число?
Теперь я задам очень глупый вопрос: что такое положительное число? У нас есть отличный инструмент, называется предикат больше  $» data-tex=»inline»/>. Но не торопитесь отвечать, что число положительно тогда и только тогда, когда
$» data-tex=»inline»/>. Но не торопитесь отвечать, что число положительно тогда и только тогда, когда  0$» data-tex=»inline»/>, это было бы слишком просто. Давайте определим положительность следущим образом:
0$» data-tex=»inline»/>, это было бы слишком просто. Давайте определим положительность следущим образом:
Определение 1
Число положительно тогда и только тогда, когда для всех ненулевых вещественных  выполняется условие
выполняется условие  0$» data-tex=»inline»/>.
0$» data-tex=»inline»/>.
Выглядит довольно мудрёно, но зато отлично применяется к матрицам:
Определение 2
Квадратная матрица называется положительно определённой, если для любых ненулевых выполняется условие  0$» data-tex=»inline»/>, то есть, соответствующая квадратичная форма строго положительна везде, кроме начала координат.
0$» data-tex=»inline»/>, то есть, соответствующая квадратичная форма строго положительна везде, кроме начала координат.
Для чего мне нужна положительность? Как я уже упоминал в начале статьи, моим основным инструментом будет поиск минимумов квадратичных функций. А ведь для того, чтобы минимум искать, было бы недурно, если бы он существовал! Например, у функции  минимума очевидно не существует, посколькуо число -1 не является положительным, и
минимума очевидно не существует, посколькуо число -1 не является положительным, и  бесконечно убывает с ростом : ветви параболы смотрят вниз. Положительно определённые матрицы хороши тем, что соответствующие квадратичные формы образуют параболоид, имеющие (единственный) минимум. Следующая иллюстрация показывает семь различных примеров матриц
бесконечно убывает с ростом : ветви параболы смотрят вниз. Положительно определённые матрицы хороши тем, что соответствующие квадратичные формы образуют параболоид, имеющие (единственный) минимум. Следующая иллюстрация показывает семь различных примеров матриц  , как положительно определённых и симметричных, так и не очень. Верхний ряд: интерпретация матриц как функций
, как положительно определённых и симметричных, так и не очень. Верхний ряд: интерпретация матриц как функций  . Средний ряд: интерпретация матриц как функций
. Средний ряд: интерпретация матриц как функций  .
.
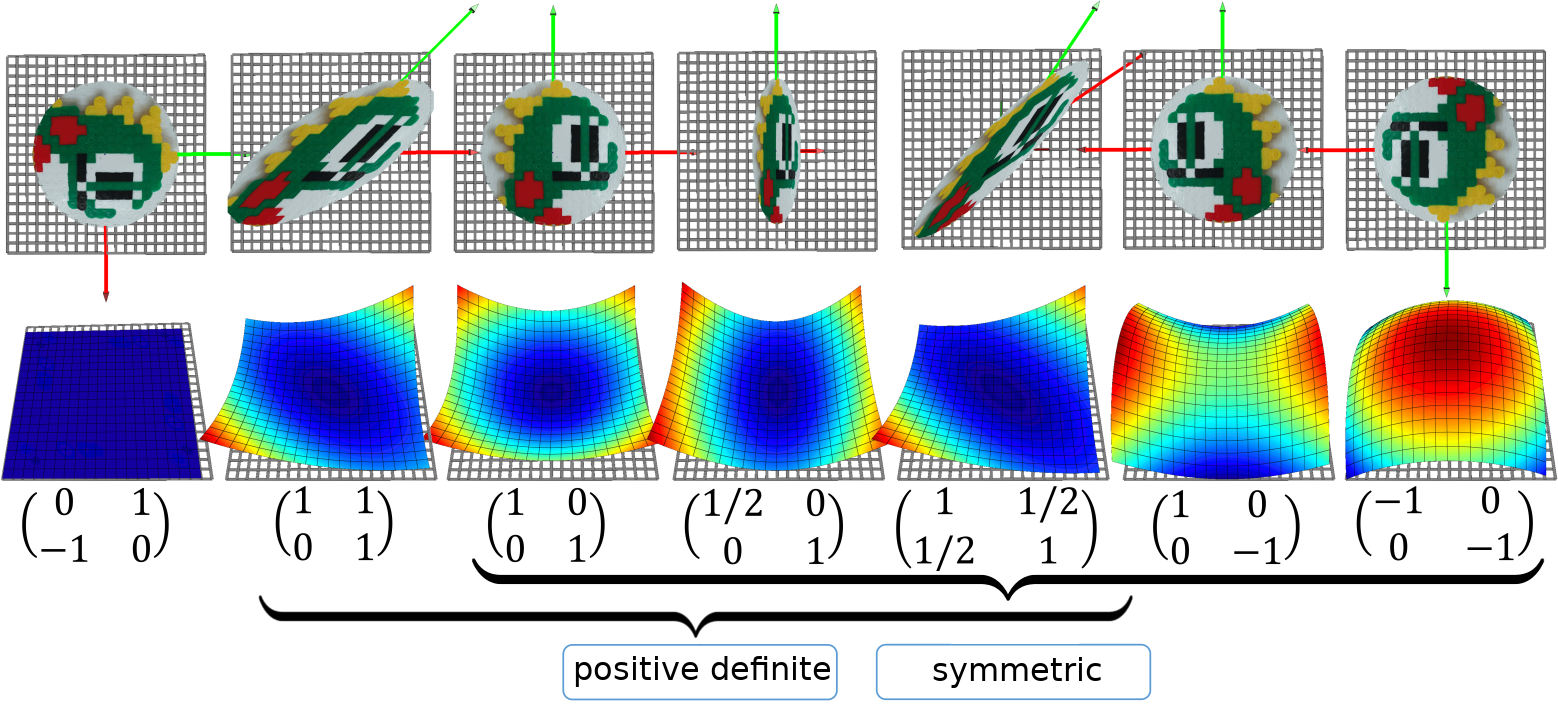
Таким образом, я буду работать с положительно определёнными матрицами, которые являются обобщением положительных чисел. Более того, конкретно в моём случае матрицы будут ещё и симметричными! Любопытно, что довольно часто, когда люди говорят про положительную определённость, они подразумевают ещё и симметричность, что может быть косвенно объяснено следующим (необязательным для понимания последующего текста) наблюдением.
Лирическое отступление о симметричности матриц квадратичных форм

Матрица  симметрична:
симметрична:  ; матрица
; матрица  антисимметрична:
антисимметрична:  . Примечательным фактом является то, что для любой антисимметричной матрицы соответствующая квадратичная форма тождественно равна нулю. Это вытекает из следующего наблюдения:
. Примечательным фактом является то, что для любой антисимметричной матрицы соответствующая квадратичная форма тождественно равна нулю. Это вытекает из следующего наблюдения:

То есть, квадратичная форма  одновременно равна
одновременно равна  и
и  , что возможно только в том случае, когда
, что возможно только в том случае, когда  . Из этого факта вытекает то, что для произвольной матрицы
. Из этого факта вытекает то, что для произвольной матрицы  соответствующая квадратичная форма
соответствующая квадратичная форма  может быть выражена и через симметричную матрицу :
может быть выражена и через симметричную матрицу :

Ищем минимум квадратичной функции
Вернёмся ненадолго в одномерный мир; я хочу найти минимум функции  . Число положительно, поэтому минимум существует; чтобы его найти, приравняем нулю соответствующую производную:
. Число положительно, поэтому минимум существует; чтобы его найти, приравняем нулю соответствующую производную:  . Продифференцировать одномерную квадратичную функцию труда не составляет:
. Продифференцировать одномерную квадратичную функцию труда не составляет:  ; поэтому наша проблема сводится к решению уравнения
; поэтому наша проблема сводится к решению уравнения  , откуда путём страшных усилий получам решение
, откуда путём страшных усилий получам решение  . Следующий рисунок иллюстрирует эквивалентность двух проблем: решение
. Следующий рисунок иллюстрирует эквивалентность двух проблем: решение  уравнения совпадает с решением уравнения
уравнения совпадает с решением уравнения  .
.
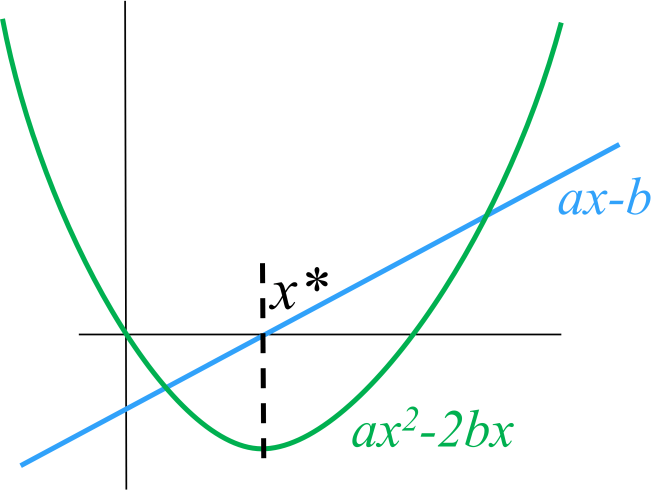
Я клоню к тому, что нашей глобальной целью является минимизация квадратичных функций, мы же про наименьшие квадраты говорим. Но при этом что мы действительно умеем делать хорошо, так это решать линейные уравнения (и системы линейных уравнений). И очень здорово, что одно эквивалентно другому!
Единственное, что нам осталось, так это убедиться, что эта эквивалентность в одномерном мире распространяется и на случай  переменных. Чтобы это проверить, для начала докажем три теоремы.
переменных. Чтобы это проверить, для начала докажем три теоремы.
Три теоремы, или дифференцируем матричные выражения
Первая теорема гласит о том, что матрицы  инварианты относительно транспонирования:
инварианты относительно транспонирования:
Теорема 1

Доказательство настолько сложное, что для краткости я вынужден его опустить, но попробуйте найти его самостоятельно.
Вторая теорема позволяет дифференцировать линейные функции. В случае вещественной функции одной переменной мы знаем, что  , но что происходит в случае вещественной функции переменных?
, но что происходит в случае вещественной функции переменных?
Теорема 2

То есть, никаких сюрпризов, просто матричная запись того же самого школьного результата. Доказательство крайне прямолинейное, достаточно просто записать определение градиента:

Применив первую теорему  , мы завершаем доказательство.
, мы завершаем доказательство.
Теперь переходим к квадратичным формам. Мы знаем, что в случае вещественной функции одной переменной  , а что будет в случае квадратичной формы?
, а что будет в случае квадратичной формы?
Теорема 3

Кстати, обратите внимание, что если матрица симметрична, то теорема гласит, что  .
.
Это доказательство тоже прямолинейно, просто запишем квадратичную форму как двойную сумму:

А затем посмотрим, чему равна частная производная этой двойной суммы по переменной  :
:
\begin
\frac<\partial (x^\top A x)> <\partial x_i>
&= \frac<\partial> <\partial x_i>\left(\sum\limits_
&= \frac<\partial> <\partial x_i>\left(
\underbrace<\sum\limits_
\underbrace <\sum\limits_
\underbrace
& = \sum\limits_
& = \sum\limits_
& = \sum\limits_
\end
Я разбил двойную сумму на четыре случая, которые выделены фигурными скобками. Каждый из этих четырёх случаев дифференцируется тривиально. Осталось сделать последнее действие, собрать частные производные в вектор градиента:

Минимум квадратичной функции и решение линейной системы
Давайте не забывать направление движения. Мы видели, что при положительном числе в случае вещественных функций одной перменной решить уравнение  или минимизировать квадратичную функцию — это одно и то же.
или минимизировать квадратичную функцию — это одно и то же.
Мы хотим показать соответствующую связь в случае симметричной положительно определённой матрицы .
Итак, мы хотим найти минимум квадратичной функции

Ровно как и в школе, приравняем нулю производную:

Оператор Гамильтона линеен, поэтому мы можем переписать наше уравнение в следующем виде:

Теперь применим вторую и третью теоремы о дифференцировании:

Вспомним, что симметрична, и поделим уравнение на два, получаем нужную нам систему линейных уравнений:

Ура-ура, перейдя от одной переменной к многим, мы не потеряли ровным счётом ничего, и можем эффективно минимизировать квадратичные функции!
Переходим к наименьшим квадратам

У нас два уравнения с двумя неизвестными (  и
и  ), остальное известно.
), остальное известно.
В общем случае решение существует и единственно. Для удобства перепишем ту же самую систему в матричном виде:

Получим уравнение типа , которое тривиально решается  .
.
А теперь представим, что у нас есть три точки, через которые нужно провести прямую:
В матричном виде эта система запишется следующим образом:

Теперь у нас матрица прямоугольная, и у неё просто не существует обратной! Это совершенно нормально, так как у нас всего две переменных и три уравнения, и в общем случае эта система не имеет решения. Это соверешенно нормальная ситуация в реальном мире, когда точки — это данные зашумлённых измерений, и нам нужно найти параметры и , которые наилучшим образом приближают данные измерений. Мы этот пример уже рассматривали в первой лекции, когда калибровали безмен. Но тогда у нас решение было чисто алгебраическим и очень громоздким. Давайте попробуем более интуитивный способ.
Нашу систему можно записать в следующем виде:


Векторы  ,
,  и
и  известны, нужно найти скаляры и .
известны, нужно найти скаляры и .
Очевидно, что линейная комбинация  порождает плоскость, и если вектор в этой плоскости не лежит, то точного решения не существует; однако же мы ищем приближённое решение.
порождает плоскость, и если вектор в этой плоскости не лежит, то точного решения не существует; однако же мы ищем приближённое решение.
Давайте определим ошибку решения как  . Нашей зачей является найти такие значения параметров и , которые минимизируют длину вектора
. Нашей зачей является найти такие значения параметров и , которые минимизируют длину вектора  . Иначе говоря, проблема записывается как
. Иначе говоря, проблема записывается как  .
.
Вот иллюстрация:.

Имея заданные векторы , и , мы стараемся минимизировать длину вектора ошибки  . Очевидно, что его длина минимизируется, если он перпендикулярен плоскости, натянутой на векторы и .
. Очевидно, что его длина минимизируется, если он перпендикулярен плоскости, натянутой на векторы и .
Но постойте, где же наименьшие квадраты? Сейчас будут. Функция извлечения корня  монотонна, поэтому =
монотонна, поэтому =  !
!
Вполне очевидно, что длина вектора ошибки минимизируется, если он перпендикулярен плоскости, натянутой на векторы и , что можно записать, приравняв нулю соответствующие скалярные произведения:
В матричном виде эту же самую систему можно записать как


Но мы на этом не остановимся, так как запись можно ещё больше сократить:

И самая последняя трансформация:

Давайте посчитаем размерности. Матрица имеет размер  , поэтому
, поэтому  имеет размер . Матрица
имеет размер . Матрица  имеет размер
имеет размер  , но вектор
, но вектор  имеет размер
имеет размер  . То есть, в общем случае матрица обратима! Более того, имеет ещё пару приятных свойств.
. То есть, в общем случае матрица обратима! Более того, имеет ещё пару приятных свойств.
Теорема 4
симметрична.
Это совсем нетрудно показать:

Теорема 5
положительно полуопределена: 
Это следует из того факта, что  0$» data-tex=»inline»/>.
0$» data-tex=»inline»/>.
Кроме того, положительно определена в том случае, если имеет линейно независимые столбцы (ранг равен количеству переменных в системе).
Итого, для системы с двумя неизвестными мы доказали, что минимизация квадратичной функции эквивалентна решению системы линейных уравнений  . Разумеется, всё это рассуждение применимо и к любому другому количеству переменных, но давайте ещё раз компактно запишем всё вместе простым алгебраическим подсчётом. Мы начнём с проблемы наименьших квадратов, придём к минимизации квадратичной функции знакомого нам вида, и из этого сделаем вывод об эквивалентности решению системы линейных уравнений. Итак, поехали:
. Разумеется, всё это рассуждение применимо и к любому другому количеству переменных, но давайте ещё раз компактно запишем всё вместе простым алгебраическим подсчётом. Мы начнём с проблемы наименьших квадратов, придём к минимизации квадратичной функции знакомого нам вида, и из этого сделаем вывод об эквивалентности решению системы линейных уравнений. Итак, поехали:

Таким образом, проблема наименьших квадратов  эквивалентна минимизации квадратичной функции
эквивалентна минимизации квадратичной функции  с (в общем случае) симметричной положительно определённой матрицей
с (в общем случае) симметричной положительно определённой матрицей  , что, в свою очередь, эквивалентно решению системы линейных уравнений
, что, в свою очередь, эквивалентно решению системы линейных уравнений  . Уфф. Теория закончилась.
. Уфф. Теория закончилась.
Переходим к практике
Пример первый, одномерный
Давайте вспомним один пример из предыдущей статьи:
У нас есть обычный массив x из 32 элементов, инициализированный следующим образом:
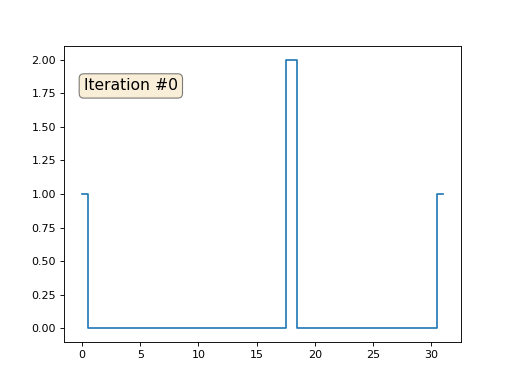
А затем мы тысячу раз выполним следующую процедуру: для каждой ячейки x[i] мы запишем в неё среднее значение соседних ячеек: x[i] = ( x[i-1] + x[i+1] )/2. Единственное исключение: мы не будем переписывать элементы массива под номерами 0, 18 и 31. Вот так выглядит эволюция массива на первых ста пятидесяти итерациях:

Как мы выяснили в предыдущей статье, оказывается, наш питоновский мегакод на четыре строчки решает следующиую систему линейных уравнений методом Гаусса-Зейделя:

Выяснить-то выяснили, но откуда вообще взялась эта система? Что за магия? Давайте отвлечёмся на секунду, и попробуем решить немного другую систему. У меня по-прежнему есть 32 переменных, но теперь я хочу, чтобы они все-все-все были равны одна другой. Это нетрудно записать, достаточно записать систему уравнений, которая гласит, что все соседние элементы попарно равны:
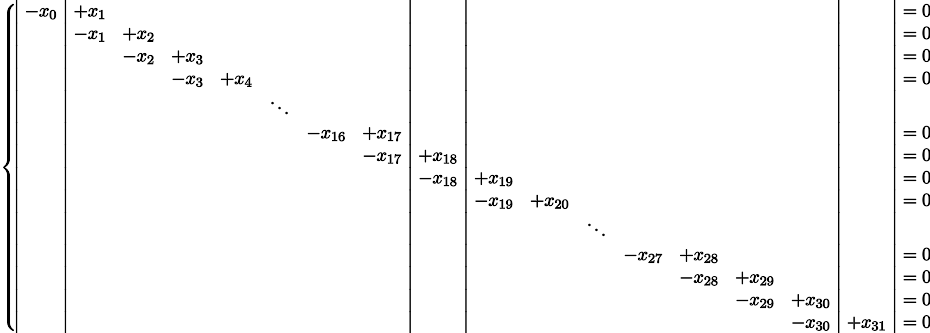
Вышеприведённый питоновский код в принципе не трогает значения трёх переменных: x0, x18, x31, поэтому давайте их перенесём в правую часть системы уравнений, т.е., исключим из множества неизвестных:
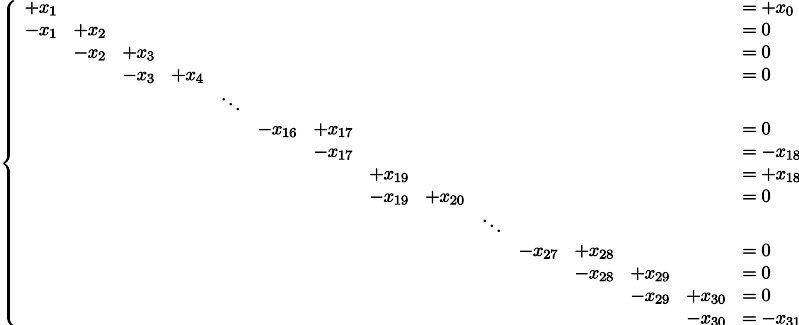
Я фиксирую начальное значение x0=1, первое уравнение говорит, что x1 = x0 = 1, второе уравнение говорит, что x2=x1=x0=1 и так далее, покуда мы не дойдём до уравнения 1 = x0 = x17 = x18 = 2. Ой. А ведь эта система не имеет решения :((
А и пофиг, мы же программисты! Давайте звать на помощь наименьшие квадраты! Наша нерешаемая система может быть записана в матричном виде ; чтобы решить нашу систему приближённо, достаточно решить систему . А тут оказывается, что это ровно, один-в-один та самая система уравнений из предыдущей статьи!
Интуитивно можно представлять себе процесс создания матрицы системы следующим образом: мы соединяем пружинками значения, равенства которых хотим добиться. Например, в нашем случае мы хотим, чтобы был равен  , поэтому мы добавляем уравнение
, поэтому мы добавляем уравнение  , вешая между этими значениями пружинку, которая будет их стягивать. Но поскольку значения x0, x18 и x31 жёстко зафиксированы, свободным значениям не остаётся ничего другого, как равномерно растянуть пружинки, произведя (в данном случае) кусочно-линейное решение.
, вешая между этими значениями пружинку, которая будет их стягивать. Но поскольку значения x0, x18 и x31 жёстко зафиксированы, свободным значениям не остаётся ничего другого, как равномерно растянуть пружинки, произведя (в данном случае) кусочно-линейное решение.
Давайте напишем программу, решающую эту систему уравнений. В прошлой статье мы видели, что метод Гаусса-Зейделя очень прост в программировании, но имеет очень медленную сходимость, поэтому лучше бы использовать настоящие решатели систем линейных уравнений. В самом простейшем случае, для нашего одномерного примера, код может выглядеть как-то так:
Этот код производит список x из 32 элементов, в котором хранится решение. Мы строим матрицу , строим вектор , получаем вектор с решением  , а затем в этот вектор вставляем наши фиксированные значения x0=1, x18=2 и x31=1.
, а затем в этот вектор вставляем наши фиксированные значения x0=1, x18=2 и x31=1.
Этот код выполняет необходимую работу, но довольно неприятно переносить в правую часть значения фиксированных переменных. Нельзя ли схитрить? Можно! Давайте посмотрим на следующий код:
С программистской точки зрения он гораздо приятнее, вектор x получается сразу нужной размерности, да и матрицы A и b заполняются куда как проще. Но в чём же хитрость? Давайте запишем систему уравнений, которую мы решаем:

Посмотрите внимательно на последние три уравнения:
100 x0 = 100 * 1
100 x18 = 100 * 2
100 x31 = 100 * 1
Не проще ли было их записать следующим образом?
x0 = 1
x18 = 2
x31 = 1
Нет, не проще. Как я уже говорил, каждое уравнение навешивает пружинки, в данном случае пружинку между x0 и значением 1, пружинку между x18 и значением 2 и, наконец, переменная x31 тоже будет притягиваться к единице.
Но коэффициент 100 там стоит не просто так. Мы же помним, что эта система просто так не решается, мы решаем её в смысле наименьших квадратов, минимизируя соответствующую квадратичную функцию. Умножив на 100 каждый из коэффициентов последних трёх уравнений, мы вводим штраф за отклонение x0, x18 и x32 от нужных значений, в десять тысяч раз (100^2) превышающий штраф за отклонение от равенства  . Грубо говоря, пружинки на последних трёх уравнениях в десять тысяч раз более жёсткие, нежели на всех остальных. Этот метод квадратичного штрафа — очень удобный инструмент введения ограничений, гораздо проще (хотя и не без недостатков), нежели редуцирование набора переменных.
. Грубо говоря, пружинки на последних трёх уравнениях в десять тысяч раз более жёсткие, нежели на всех остальных. Этот метод квадратичного штрафа — очень удобный инструмент введения ограничений, гораздо проще (хотя и не без недостатков), нежели редуцирование набора переменных.
Пример второй, трёхмерный
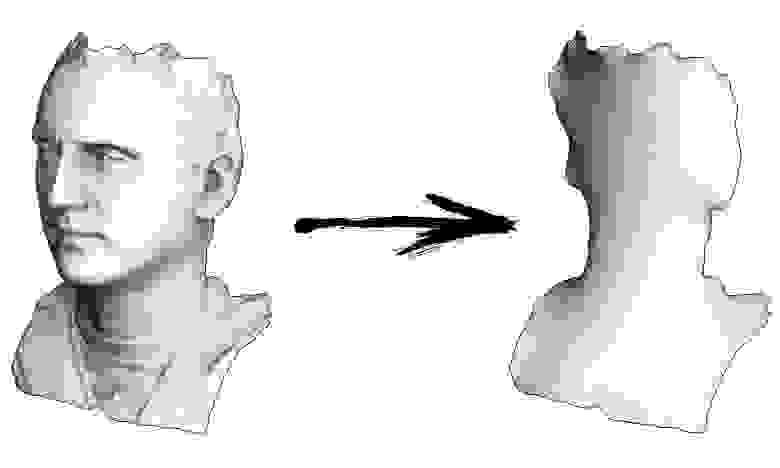
Давайте уже перейдём к чему-нибудь более интересному, нежели сглаживание элементов одномерного массива! Для начала сделаем ровно то же самое, но на более интересных данных и с настоящим инструментарием. Я хочу взять трёхмерную поверхность, зафиксировать её границу, а всю остальную поверхность максимально сгладить:
Код доступен тут, но на всякий случай приведу полный листинг главного файла:
Я написал простейший парсер wavefront .obj файлов, поэтому моделька подгружается в одну строчку. В качестве решателя я буду использовать OpenNL, это очень мощный решатель для проблем наименьших квадратов с разреженными матрицами. Обратите внимание, что размеры матриц у нас могут быть гигантскими: например, если мы хотим получить ч/б картинку размером 1000 x 1000 пикселей, то матрица у нас будет размером миллион на миллион! Однако же на практике чаще всего подавляющее большинство элементов этой матрицы нулевые, поэтому всё не так страшно, но всё же нужно использовать специальные солверы.
Итак, давайте смотреть на код. Для начала я объявляю солверу, что я хочу делать:
Я хочу иметь матрицу размером (колво вершин)x(колво вершин). Внимание, мы солверу даём матрицу , а уж он будет строить сам, что очень удобно! Также обратите внимание на то, что я решаю не одну систему уравнений, а три последовательно для x,y и z (я соврал, что проблема трёхмерная, она по-прежнему одномерная!)
А затем я объявляю строку за строкой нашей матрицы. Для начала я фиксирую вершины, которые находятся на краю поверхности:
Можно видеть, что я использую квадратичный штраф в 100^2 для фиксирования краевых вершин.
Ну а затем для каждой пары смежных вершин я вешаю пружинку жёсткости 1 между ними:
Выполняем код и видим, как лицо сгладилось в поверхность мыльной плёнки на изогнутой проволоке. Мы сейчас только что решили проблему Дирихле, получив поверхность минимальной площади.
Усиляем характеристические черты
Давайте превратим наше лицо в гротескную маску:
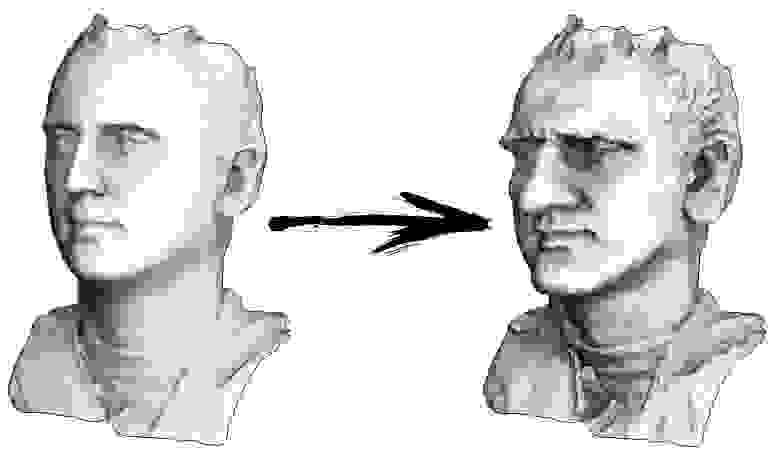
В предыдущей статье я уже показывал, как это сделать на коленке, здесь же я привожу настоящий код, использующий солвер наименьших квадратов:
Полный код доступен тут. Как он работает? Как и в предыдущем примере, я начинаю с того, что фиксирую краевые вершины. Затем для каждого ребра я (тихонечко, с коэффициентом 0.2) говорю, что неплохо было бы, чтобы оно имело ровно ту же форму, что и в изначальной поверхности:
Если больше ничего не делать, и решить проблему прямо как есть, то мы на выходе должны получить ровно то, что было на входе: граница выхода равняется границе входа, плюс перепады на выходе равняются перепадам на входе.
Но мы на этом не останавливемся!
В нашу систему я добавляю ещё уравнений. Для каждой вершины я считаю кривизну поверхности вокруг неё во входной поверхности, и умножаю её на два с половиной, то есть, выходная поверхность должна иметь большую кривизну повсюду.
Затем вызываем наш решатель и получаем неплохую карикатуру.
Последний пример на сегодня
До этого момента мы не видели ни одного нового примера, всё уже было показано в предыдущей статье. Давайте попробуем сделать что-то менее тривиальное, нежели простейшее сглаживание, которое легко можно получить, не используя никаких солверов. Код доступен тут, но давайте я приведу листинг:
Мы по-прежнему работаем с той же поверхностью, что и раньше; мы вызываем функцию snap() для каждого треугольника. Эта функция говорит, к какой оси системы координат ближе всего нормаль этого треугольника. То есть, мы хотим знать, этот треугольник скорее вертикален или горизонтален. Ну а затем мы хотим изменить геометрию нашей поверхности, чтобы то, что близко к горизонтали, стало ещё ближе! Левая часть вот этой картинки показывает результат работы функции snap():

Итак, мы раскрасили нашу поверхность в три цвета, соответствующие трём осям системы координат. Ну а затем для каждого ребра нашей системы мы добавляем следующие уравнения:
То есть, мы предписываем каждому ребру выходной поверхности походить на соответствующее ребро входной поверхности, жёсткость пружинки 1. А затем, если мы разрешаем, например, размерность x, а ребро должно быть вертикально, то просто говорим, что одна вершина равна другой с жёсткостью пружины 2:
Ну а вот и результат работы нашей программы:
Вполне резонный вопрос: истуканы с острова Пасхи, это, конечно, круто, но при чём тут геология? Есть ли примеры реальных задач?
Да, конечно. Давайте возьмём один срез земной коры:
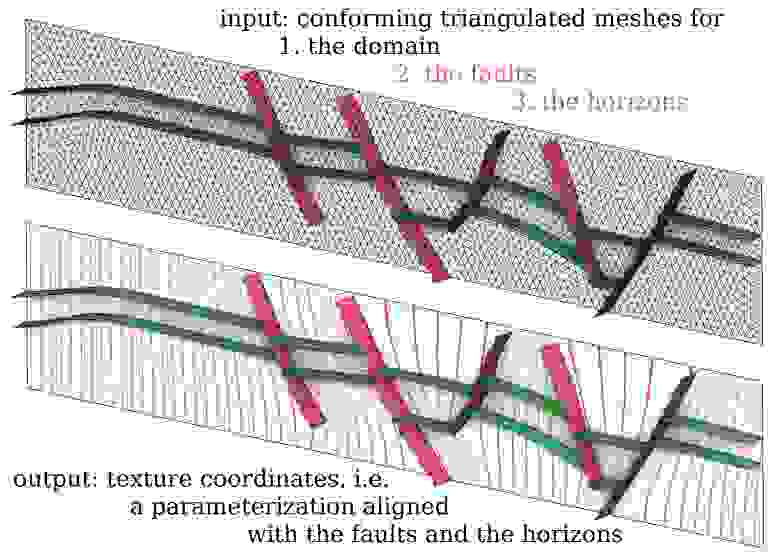
Для геологов очень важны слои разных пород, границы (горизонты) между которыми показаны зелёным, и геологические разломы, которые показаны красным. У нас есть на вход сетка треугольников (тетраэдров в 3д) той области, которая нас интересует, но для моделирования определённых процессов необходимы квады (гексаэдры в 3д). Мы деформируем нашу модель так, чтобы разломы стали вертикальными, а горизонты (сюрприз) горизонтальными:

Затем мы просто возьмём регулярную сетку квадратов, нарежем наш домен на равномерные квадратики, и применим к ним обратное преобразование, получив необходимую сетку квадов.
Заключение
Методы наименьших квадратов — мощнейший инструмент обработки данных, и применяется гораздо шире, нежели статистика в колонках экселя. Эти возможности нам открываются благодаря тому, что минимизация квадратичной функции и решение системы линейных уравнений — это одно и то же, а решать линейные уравнения мы (человечество) научились очень и очень хорошо, даже совершенно нечеловеческих размеров с миллиардами переменных.
Однако же бывают случаи, когда линейных моделей нам может не хватить. И тут на помощь могут прийти, например, нейронные сети. В следующей статье я постараюсь показать, что МНК с отбрасыванием выбросов эквивалентен одной из формулировок нейронных сетей. Оставайтесь на линии!
VMath
Инструменты сайта
Основное
Навигация
Информация
Действия
Содержание
Вспомогательная страница к разделу ☞ ИНТЕРПОЛЯЦИЯ.
Метод наименьших квадратов
Пусть из физических соображений можно считать (предполагать), что величины $ x_<> $ и $ y_<> $ связаны линейной зависимостью вида $ y=kx+b $, а неизвестные коэффициенты $ k_<> $ и $ b_<> $ должны быть оценены экспериментально. Экспериментальные данные представляют собой $ m>1 $ точек на координатной плоскости $ (x_1,y_1), \dots, (x_m,y_m) $. Если бы эти опыты производились без погрешностей, то подстановка данных в уравнение приводила бы нас к системе из $ m_<> $ линейных уравнений для двух неизвестных $ k_<> $ и $ b_<> $: $$ y_1=k\,x_1+b, \dots, y_m=k\,x_m+b \ . $$ Из любой пары уравнений этой системы можно было бы однозначно определить коэффициенты $ k_<> $ и $ b_<> $.
Однако, в реальной жизни опытов без погрешностей не бывает
Дорогая редакция! Формулировку закона Ома следует уточнить следующим образом:«Если использовать тщательно отобранные и безупречно подготовленные исходные материалы, то при наличии некоторого навыка из них можно сконструировать электрическую цепь, для которой измерения отношения тока к напряжению, даже если они проводятся в течение ограниченного времени, дают значения, которые после введения соответствующих поправок оказываются равными постоянной величине».
Источник: А.М.Б.Розен. Физики шутят. М.Мир.1993.
Будем предполагать, что величины $ x_<1>,\dots,x_m $ известны точно, а им соответствующие $ y_1,\dots,y_m $ — приближенно. Если $ m>2 $, то при любых различных $ x_ $ и $ x_j $ пара точек $ (x_,y_i) $ и $ (x_
Часто в задаче удаленность точки от прямой измеряют не расстоянием, а разностью ординат $ k\,x_i+b-y_i $, и выбирают прямую так, чтобы сумма квадратов всех таких разностей была минимальна. Коэффициенты $ k_0 $ и $ b_ <0>$ уравнения этой прямой дают некоторое решение стоящей перед нами задачи, которое отнюдь не является решением системы линейных уравнений $$ k\,x_1+b=y_1,\dots, k\,x_
Рассмотрим теперь обобщение предложенной задачи. Пусть искомая зависимость между величинами $ y_<> $ и $ x_<> $ полиномиальная: $$ y_1=f(x_1),\dots , y_m=f(x_m), \quad npu \quad f(x)=a_0+a_1x+\dots+a_
Предположим что данные интерполяционной таблицы $$ \begin
Задача. Построить полином $ f_<>(x) $ такой, чтобы величина $$ \sum_
В случае $ \deg f_<> =m-1 $ мы возвращаемся к задаче интерполяции в ее классической постановке. Практический интерес, однако, представляет случай $ \deg f_<> n $: $$S=\left(\begin
Осталось недоказанным утверждение, что полученное решение доставляет именно минимум сумме квадратов невязок. Этот факт следует из доказательства более общего утверждения — о псевдорешении системы линейных уравнений. Этот результат приводится ☟ НИЖЕ. ♦
Собственно минимальное значение величины cуммы квадратов невязок, а точнее усреднение по количеству узлов $$ \sigma=\frac<1>

Показать, что линейный полином $ y=a_<0>+a_1x $, построенный по методу наименьших квадратов, определяет на плоскости $ (x_<>,y) $ прямую, проходящую через центроид
Пример. По методу наименьших квадратов построить уравнение прямой, аппроксимирующей множество точек плоскости, заданных координатами из таблицы
$$ \begin
Решение. Имеем $$ s_0=6, s_1=0.5 + 1 + 1.5 + 2 + 2.5 + 3=10.5, $$ $$ s_2=0.5^2 + 1^2 + 1.5^2 + 2^2 + 2.5^2 + 3^2=22.75, $$ $$t_0=0.35 + 0.80 + 1.70 + 1.85 + 3.51 + 1.02=9.23, $$ $$ t_1 =0.5\cdot 0.35 + 1 \cdot 0.80 + 1.5 \cdot 1.70 + 2 \cdot 1.85 + $$ $$ +2.5 \cdot 3.51 + 3 \cdot 1.02=19.06 . $$ Решаем систему нормальных уравнений $$ \left( \begin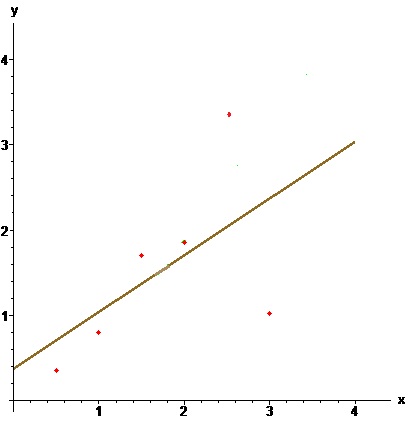 получаем уравнение прямой в виде $$ y= 0.375 + 0.665\, x\ .$$
получаем уравнение прямой в виде $$ y= 0.375 + 0.665\, x\ .$$
Вычислим и полиномы более высоких степеней. $$ f_2(x)=-1.568+3.579\, x-0.833\,x^2 \ , $$ $$ f_3(x)=2.217-5.942\,x+5.475\,x^2-1.201\, x^3 \ , $$ $$ f_4(x)= -4.473+17.101\,x-19.320\,x^2+9.205\, x^3-1.487\,x^4 \ , $$ $$ f_5(x)= 16.390-71.235\,x+111.233\,x^2-77.620\,x^3+25.067\,x^4-3.0347\, x^5 . $$
Среднеквадратичные отклонения: $$ \begin
Возникает естественный вопрос: полином какой степени следует разыскивать в МНК? При увеличении степени точность приближения, очевидно, увеличивается. Вместе с тем, увеличивается сложность решения системы нормальных уравнений и даже при небольших степенях $ n $ (меньших $ 10 $) мы столкнемся с проблемой чувствительности решения к точности представления входных данных.
Влияние систематических ошибок
Пример. Уравнение прямой, аппроксимирующей множество точек плоскости, заданных координатами из таблицы
$$ \begin Теперь заменим значение $ y_5 $ на $ 0.2 $. Уравнение прямой принимает вид: $$ y=0.483+0.383\, x \, . $$ График (зеленый) существенно изменился. Почему это произошло? — Дело в том, что эффективность метода наименьших квадратов зависит от нескольких предположений относительно входных данных: в нашем случае — значений $ y $. Предполагается, что эти величины являлись результатами экспериментов, измерений, и, если они подвержены погрешностям, то эти погрешности носят характер несистематических флуктуаций вокруг истинных значений. Иными словами, изначально предполагается, что в действительности точки плоскости должны лежать на некоторой прямой. И только несовершенство наших методов измерений (наблюдений) демонстрирует смещение их с этой прямой. Ответ для исходной таблицы визуально подтвержает это предположение: экспериментальные точки концентрируются вокруг полученной прямой и величины невязок (отклонений по $ y $-координате) имеют «паритет» по знакам: примерно половина точек лежит выше прямой, а половина — ниже.
Теперь заменим значение $ y_5 $ на $ 0.2 $. Уравнение прямой принимает вид: $$ y=0.483+0.383\, x \, . $$ График (зеленый) существенно изменился. Почему это произошло? — Дело в том, что эффективность метода наименьших квадратов зависит от нескольких предположений относительно входных данных: в нашем случае — значений $ y $. Предполагается, что эти величины являлись результатами экспериментов, измерений, и, если они подвержены погрешностям, то эти погрешности носят характер несистематических флуктуаций вокруг истинных значений. Иными словами, изначально предполагается, что в действительности точки плоскости должны лежать на некоторой прямой. И только несовершенство наших методов измерений (наблюдений) демонстрирует смещение их с этой прямой. Ответ для исходной таблицы визуально подтвержает это предположение: экспериментальные точки концентрируются вокруг полученной прямой и величины невязок (отклонений по $ y $-координате) имеют «паритет» по знакам: примерно половина точек лежит выше прямой, а половина — ниже.
После замены значения $ y_5 $ на новое, значительно отличающееся от исходного, существенно меняется величина $ 5 $-й невязки $ \varepsilon_5= ax_5+b-y_5 $. А поскольку в минимизируемую функцию эта невязка входи еще и в квадрате, то понятно, что изначальная прямая просто не в состоянии правильно приблизить новую точку.
Эта проблема становится актуальной в тех случаях, когда в «истинно случайный» процесс привносятся намеренные коррективы. Данные начинают подвергаться существенным искажениям, возможно, даже имеющим «злой» умысел 3) .
Как бороться с ошибками такого типа? Понятно, что решение возможно в предположении, что число таких — систематических — ошибок должно быть существенно меньшим общего количества экспериментальных данных. Понятно, что каким-то образом эти «выбросы» надо будет исключить из рассмотрения, т.е. очистить «сырые» данные от «мусора» — прежде чем подсовывать их в метод наименьших квадратов (см. ☞ цитату). Как это сделать?
Псевдорешение системы линейных уравнений
Рассмотрим теперь обобщение задачи предыдущего пункта. В практических задачах часто бывает нужно найти решение, удовлетворяющее большому числу возможно противоречивых требований. Если такая задача сводится к системе линейных уравнений $$ \left\<\begin
Псевдорешением системы $ AX= <\mathcal B>$ называется столбец $ X\in \mathbb R^n $, обеспечивающий минимум величины $$ \sum_
Теорема. Существует псевдорешение системы
$$ AX= <\mathcal B>$$ и оно является решением системы $$ \left[A^<\top>A \right]X=A^ <\top> <\mathcal B>\ . $$ Это решение будет единственным тогда и только тогда, когда $ \operatorname
Система $ \left[A^<\top>A \right]X=A^ <\top> <\mathcal B>$ называется нормальной системой по отношению к системе $ AX= <\mathcal B>$. Формально она получается домножением системы $ AX= <\mathcal B>$ слева на матрицу $ A^ <\top>$. Заметим также, что если $ m=n_<> $ и $ \det A \ne 0 $, то псевдорешение системы совпадает с решением в традиционном смысле.
Доказательство ☞ ЗДЕСЬ.
Если нормальная система имеет бесконечное количество решений, то обычно в качестве псевдорешения берут какое-то одно из них — как правило то, у которого минимальна сумма квадратов компонент («длина»).
Пример. Найти псевдорешение системы
$$x_1+x_2 = 2, \ x_1-x_2 = 0,\ 2\, x_1+x_2 = 2 \ .$$
Решение. Имеем: $$A=\left( \begin
Ответ. $ x_1=5/7, x_2 = 6/7 $.
Показать, что матрица $ A^<\top>A $ всегда симметрична.
На дубовой колоде лежит мелкая монетка. К колоде
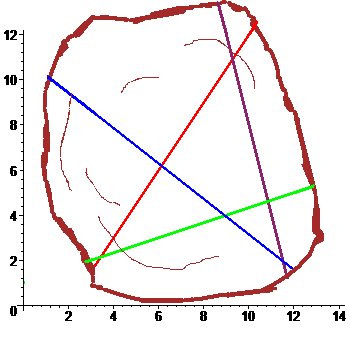
по очереди подходят четыре рыцаря и каждый наносит удар мечом, стараясь попасть по монетке. Все промахиваются. Расстроенные, рыцари уходят в харчевню пропивать злосчастную монетку. Укажите максимально правдоподобное ее расположение, имея перед глазами зарубки: $$ \begin
Геометрическая интерпретация
Псевдообратная матрица
Пусть сначала матрица $ A_<> $ порядка $ m\times n_<> $ — вещественная и $ m \ge n_<> $ (число строк не меньше числа столбцов). Если $ \operatorname
Пример. Найти псевдообратную матрицу к матрице $$ A= \left( \begin
Решение. $$ A^<\top>= \left( \begin
Вычислить псевдообратную матрицу для $$ \mathbf
Концепция псевдообратной матрицы естественным образом возникает из понятия псевдорешения системы линейных уравнений . Если $ A^ <+>$ существует, то псевдорешение (как правило, переопределенной и несовместной!) системы уравнений $ AX=\mathcal B_<> $ находится по формуле $ X= A^ <+>\mathcal B $ при любом столбце $ \mathcal B_<> $. Верно и обратное: если $ E_<[1]>, E_<[2]>,\dots, E_ <[m]>$ – столбцы единичной матрицы $ E_m $: $$ E_<[1]>=\left( \begin
Теорема. Пусть $ A_<> $ вещественная матрица порядка $ m\times n_<> $, $ m \ge n_<> $ и $ \operatorname
$$ \min_
С учетом этого результата понятно как распространить понятие псевдообратной матрицы на случай вещественной матрицы $ A_
Источники
[1]. Беклемишев Д.В. Дополнительные главы линейной алгебры. М.Наука.1983, с.187-234
http://habr.com/ru/post/477192/
http://vmath.ru/vf5/interpolation/mnk