Корреляция — определение и вычисление с примерами решения
Содержание:
Понятие о корреляции:
Марксистская философия учит, что каждое явление природы и общества не возникает само по себе, отдельно от других, а находится в связи с другими явлениями, причем каждое из них представляет собой единство составляющих его частей и свойств. Для того чтобы познать какое-либо явление, необходимо изучить его не только во всех сложных взаимоотношениях с окружающими явлениями-факторами, но также во взаимосвязи всех его сторон.
Если всеобщая связь и взаимозависимость явлений составляют один из наиболее общих законов, то основной задачей науки является изучение этой взаимосвязи.
В математической статистике взаимосвязь явлений изучается методом корреляции. Термин корреляция происходит от английского слова correlation — соотношение, соответствие. Особенность изучения связи явлений методом корреляции состоит в том, что нельзя изолировать влияние посторонних факторов либо потому, что эти факторы неизвестны, либо потому, что их изоляция невозможна. Поэтому метод корреляции применяется для того, чтобы при сложном взаимодействии посторонних влияний выяснить, какова была бы зависимость между результатом фактором, если бы посторонние факторы не изменялись и своим изменением не искажали основную зависимость. При этом небольшое число наблюдений не дает возможности обнаружить закономерность связи.
Первая задача корреляции заключается в выявлении на основе наблюдения над большим количеством фактов того, как изменяется в среднем результативный признак в связи с изменением данного фактора. Это изменение предполагает условие неизменности ряда других факторов, хотя искажающее влияние этих других факторов на самом деле имеет место. Вторая задача заключается в определении степени влияния искажающих факторов.
Первая задача решается нахождением уравнения связи.
Вторая задача решается при помощи различных показателей тесноты связи.
Такими показателями являются меры тесноты связи, найденные разными исследователями, а также коэффициент корреляции и корреляционное отношение.
Результативный и факториальный признаки
При изучении влияния одних признаков явлений на другие из цепи признаков, характеризующих данное явление, выделяются два признака — факториальный и результативный. Необходимо установить, какой из признаков является факториальным и какой результативным. В этом помогает прежде всего логический анализ.
Пример. Себестоимость промышленной продукции отдельного предприятия зависит от многих факторов, в том числе от объема продукции на данном предприятии. Себестоимость продукции выступает в этом случае как результативный признак, а объем продукции — как факториальный.
Другой пример. Чтобы судить о преимуществах крупных предприятий перед мелкими, рассмотрим, как увеличивается производительность труда рабочих крупных предприятий, и выявим зависимость производительности труда от увеличения размеров предприятия.
Таблица!
Группировка магазинов Министерства торговли по числу рабочих мест на 1 января 1960 г.1
Группы магазинов по числу рабочих мест Число магазинов Товарооборот в расчете на одного работника за квартал (в тыс. руб.)
Всего 68 375 117
Из них
с числом рабочих мест:
- с 1 19 893 109
- с 2 18 030 108
- с 3—4 16 508 108
- с 5—7 8 321 111
- с 8—10 2 868 118
- с 11 — 15 1 559 122
- с 16 и более 1 196 139
- J
Группировка показывает прямую зависимость производительности труда торговых работников, выражающуюся в товарообороте, приходящегося на одного работника, от размера магазина. Признак группировки — число рабочих мест — является факториальным, товарооборот — результативным признаком.
От размеров производства зависит также производительность оборудования, о чем свидетельствует следующая таблица: 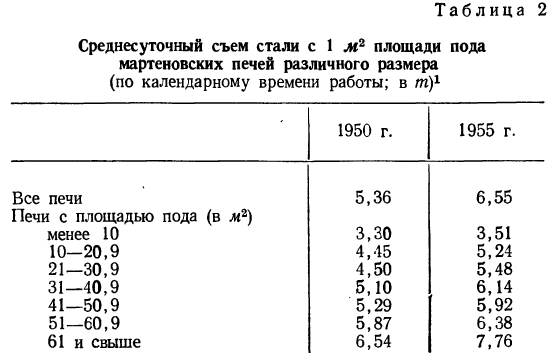
Из таблицы ясно видна связь между размерами печей и их производительностью. Эта связь прямая: чем крупнее печь, тем она производительнее.
Однако зависимость результативного признака (суточного съема стали) от факториального носит не обязательный характер. Если в общей массе мы наблюдаем эту связь, то в отдельных группах бывают и отступления от общей закономерности. Такие отступления—характерная особенность статистической связи вообще, о которой будет рассказано ниже.
Группировки позволяют выявить и зависимость нескольких результативных признаков от одного факториального. Рассмотрим табл. 3.
В этой таблице мы видим зависимость двух результативных признаков: товарооборота на одного работника и товарных запасов—от размеров магазинов. Зависимость товарооборота от размеров магазина прямая, а зависимость товарных остатков от размеров магазина — обратная. В первом случае она растет с ростом размеров магазина, во втором уменьшается. Однако то и другое благоприятно.
Графическое изображение связи
Графическое изображение изучаемых явлений позволяет не только установить наличие или отсутствие связи между ними, но и изучить характер этой связи, иначе говоря изучить форму связи и ее тесноту. 
Имея перед собой числовые характеристики факториального и результативного признаков одного и того же явления, можно каждую пару чисел изобразить в виде точки на плоскости. Для этого на плоскости берем две взаимно перпендикулярные линии и образуем систему координат. В этой системе по оси абсцисс откладываем значения факториального признака, а по оси ординат— значения результативного признака. Каждая пара чисел дает при этом точку на плоскости координатного поля.
Возьмем, например, группировку магазинов по числу рабочих мест, данную на стр. 239, и будем откладывать число рабочих мест по горизонтальной оси (оси Ох), а товарооборот в расчете на одного работника — по вертикальной оси (оси Оу). Будем иметь ряд точек, соединив которые получим ломаную линию, которая называется ломаной регрессии (см. график 1).
Как видно из графика, с ростом числа рабочих мест в магазине растет и товарооборот, приходящийся на одного работника, что говорит о связи между этими признаками, причем связи прямой. График подчеркивает эту зависимость ходом ломаной линии из нижнего угла в верхний правый угол.
Такого же рода зависимость будем наблюдать на графике 2, изучая связь между величиной мартеновских печей по площади пода и среднесуточным съемом стали с 1 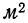 пода. Как и в предыдущем примере, факториальный признак — величину площади пода — будем откладывать на оси абсцисс, а результативный — среднесуточный съем стали с 1
пода. Как и в предыдущем примере, факториальный признак — величину площади пода — будем откладывать на оси абсцисс, а результативный — среднесуточный съем стали с 1 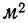 пода — на оси ординат.
пода — на оси ординат.
Здесь также ясно выраженная прямая зависимость между результативным и факториальным признаками. 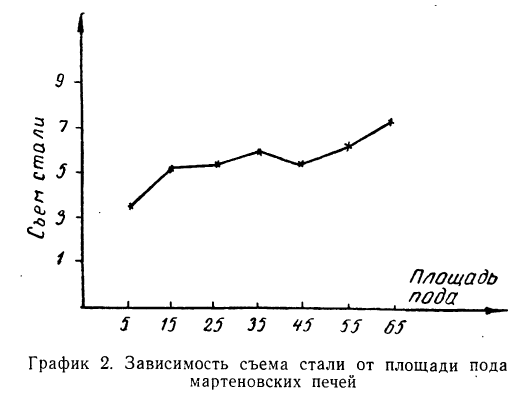
По-другому будет выглядеть график зависимости товарных запасов от размера товарооборота магазина.
Здесь мы наблюдаем ярко выраженную обратную связь между признаками: падение товарных запасов сопровождается ростом размера магазина по товарообороту. 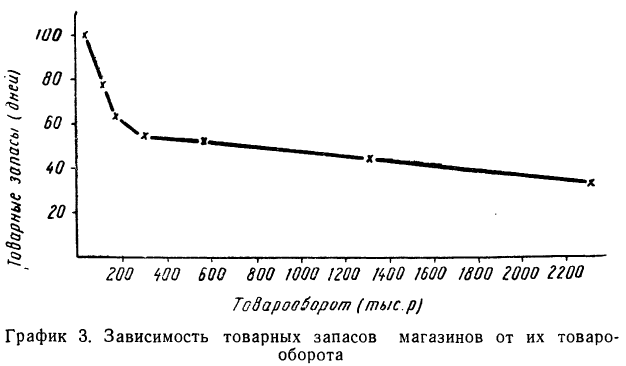
Графический метод наглядно иллюстрирует зависимость, выявленную группировкой. Недостаток графического метода изучения связи заключается в том, что он позволяет выявить связь лишь между двумя признаками.
Функциональные и статистические связи
До сих пор говорилось о связях между явлениями и их признаками без объяснения формы и степени этих связей. В приведенных примерах связи носят логически обоснованный характер, но числовое выражение этих связей говорит о том, что они проявляются не всегда одинаково. В определенных случаях имеются отступления от наблюдаемых общих закономерностей. В приведенной на стр. 240 таблице о среднесуточном съеме стали с 1  пода печи наблюдается зависимость съема стали от размера печи по площади пода, но эта зависимость за 1955 г. искажена показателями 5-й группы, где съем стали значительно ниже, чем в 4-й группе. Если бы рассматривалась при этом каждая печь в отдельности, то это несоответствие установленному правилу зависимости проявлялось бы неоднократно. Но средние величины съема стали, вычисленные на основании данных довольно большого числа печей в группе, говорят о явно выраженной зависимости. Связи между явлениями, или их признаками. проявляющиеся в изменении в зависимости от одного признака характеристик распределения (из которых главная — средняя) другого признака, называются связями статистическими.
пода печи наблюдается зависимость съема стали от размера печи по площади пода, но эта зависимость за 1955 г. искажена показателями 5-й группы, где съем стали значительно ниже, чем в 4-й группе. Если бы рассматривалась при этом каждая печь в отдельности, то это несоответствие установленному правилу зависимости проявлялось бы неоднократно. Но средние величины съема стали, вычисленные на основании данных довольно большого числа печей в группе, говорят о явно выраженной зависимости. Связи между явлениями, или их признаками. проявляющиеся в изменении в зависимости от одного признака характеристик распределения (из которых главная — средняя) другого признака, называются связями статистическими.
Статистические связи характеризуются тем, что в них результативный признак не полностью определяется влиянием признака факториального. Это влияние проявляется лишь в среднем, а в отдельных случаях получаются результаты, даже противоречащие установленной связи.
В отличие от статистических связей связи функциональные характеризуются тем, что при таких связях факториальный признак полностью определяет величину результативного признака.
Функциональные связи почти не встречаются в явлениях общественной жизни, отличающихся сложностью и многообразием существующих и проявляющихся взаимосвязей. Но во многих явлениях в основе статистических связей лежат функциональные связи. Связь функциональная может показывать зависимость между результативным признаком и несколькими аргументами. Так, площадь прямоугольника зависит от длины его двух сторон, путь, проходимый телом, зависит от скорости его движения и времени движения и т. д.
Уравнение связи
Наблюдая статистическую связь между двумя признаками, математическая статистика стремится придать этой связи форму функциональной, т. е. связи, выражаемой при помощи математической функции.
На помощь приходит ее графическое изображение при отыскании нужной функции связи. При этом необходимо стремиться найти такую функцию, которая давала бы наименьшее отклонение от полученных при наблюдении значений их признаков, которая выражала бы основную зависимость, проявляющуюся в эмпирическом материале. Уравнение этой функции будет уравнением связи между результативным и факториальным признаками.
Уравнение связи находится с помощью способа наименьших квадратов, который требует, чтобы сумма квадратов отклонений эмпирических значений от значений, получаемых на основании уравнения связи, была минимальной.
Применение способа наименьших квадратов позволяет находить параметры уравнения связи при помощи решения системы так называемых нормальных уравнений, различных для связи каждого вида.
Чтобы отметить, что зависимость между двумя признаками выражается в среднем, значения результативного признака, найденные по уравнению связи, обозначаются 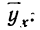
Зная уравнение связи, можно вычислить заранее среднее значение результативного признака, когда значение факториального признака известно. Таким образом, уравнение связи является методом обобщения наблюдаемых статистических связей, методом их изучения.
Применение той или иной функции в качестве уравнения связи разграничивает связи по их форме: линейную связь и криволинейную связь (параболическую, гиперболическую и др.).
Рассмотрим уравнения связи для зависимостей от одного признака при разных формах связи (линейной, криволинейной параболической, гиперболической) и для множественной связи.
Линейная зависимость
Уравнение связи как уравнение прямой 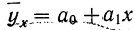 применяется в случае равномерного нарастания результативного признака с увеличением признака факториального. Такая зависимость будет зависимостью линейной (прямолинейной).
применяется в случае равномерного нарастания результативного признака с увеличением признака факториального. Такая зависимость будет зависимостью линейной (прямолинейной).
Параметры уравнения прямой линии 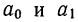 находятся путем решения системы нормальных уравнений, получаемых по способу наименьших квадратов:
находятся путем решения системы нормальных уравнений, получаемых по способу наименьших квадратов:
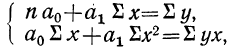
где n — число полученных при наблюдении пар взаимосвязанных величин; 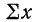 — сумма значений факториального признака;
— сумма значений факториального признака;
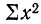 — сумма квадратов значений факториального признака;
— сумма квадратов значений факториального признака;
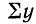 — сумма значений результативного признака;
— сумма значений результативного признака; 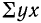 — сумма произведений значений факториального признака на значения результативного признака.
— сумма произведений значений факториального признака на значения результативного признака.
Примером расчета параметров уравнения и средних значений результативного признака 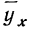 может служить следующая таблица, являющаяся результатом группировки по факториальному признаку и подсчета средних по результативному признаку.
может служить следующая таблица, являющаяся результатом группировки по факториальному признаку и подсчета средних по результативному признаку.
Группировка предприятий по стоимости основных средств и подсчет сумм необходимы для уравнения связи.
Из таблицы находим:  132,0. Строим систему двух уравнений с двумя неизвестными:
132,0. Строим систему двух уравнений с двумя неизвестными:
Поделив каждый член в обоих уравнениях на коэффициенты при 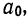 получим:
получим:
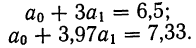
Вычтем из второго уравнения первое: 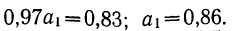 Подставив значения
Подставив значения 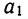 в первое уравнение
в первое уравнение 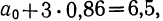 найдем
найдем 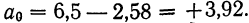
Уравнение связи примет вид: 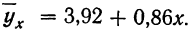 Подставив в это уравнение соответствующие х, получим значения результативного признака, отражающие среднюю зависимость у от х в виде корреляционной зависимости.
Подставив в это уравнение соответствующие х, получим значения результативного признака, отражающие среднюю зависимость у от х в виде корреляционной зависимости. 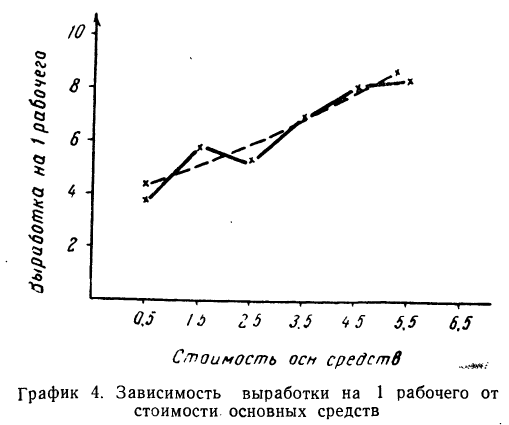
Заметим, что суммы, исчисленные по уравнению и фактические, равны между собой. Изображение фактических и вычисленных значений на графике 4 показывает, что уравнение связи отображает наблюденную зависимость в среднем.
Параболическая зависимость
Параболическая зависимость, выражаемая уравнением параболы 2-го порядка 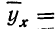
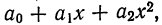 имеет место при ускоренном возрастании или убывании результативного признака в сочетании с равномерным возрастанием факториального признака.
имеет место при ускоренном возрастании или убывании результативного признака в сочетании с равномерным возрастанием факториального признака.
Параметры уравнения параболы 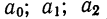 вычисляются путем решения системы 3 нормальных уравнений:
вычисляются путем решения системы 3 нормальных уравнений:
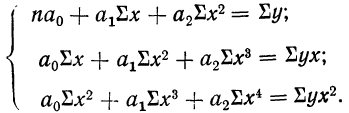
Возьмем для примера зависимость месячного выпуска продукции (у) от величины стоимости основных средств (х). Оба показателя округлены до миллионов рублей. Расчеты необходимых сумм приведем в таблице 5.
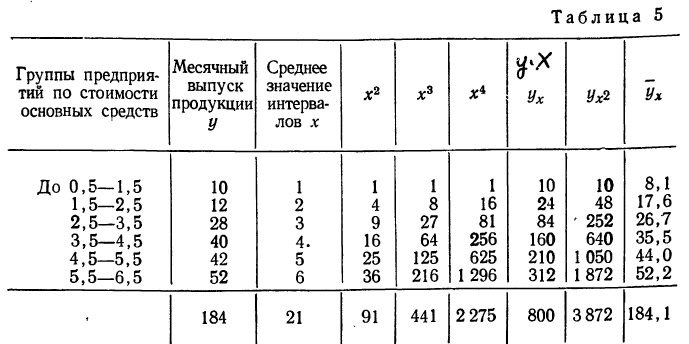
По данным таблицы, составляем систему уравнений:
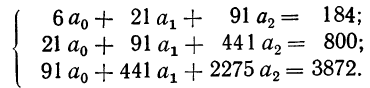
После деления всех уравнений на коэффициенты при  получим:
получим:
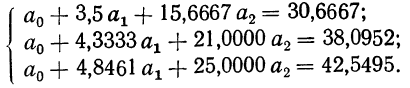
Вычтя из второго уравнения первое и из третьего второе, получим два новых уравнения с двумя неизвестными:
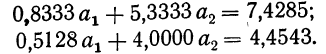
Полученные уравнения снова разделим на коэффициенты при 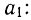
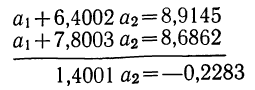
Следовательно, 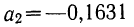
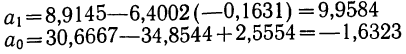
Запишем уравнение параболы, выражающей связь между х и у.
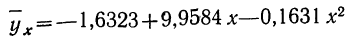
Графическое сопоставление опытных данных и данных расчета (см. график 5) показывает почти полное совпадение хода обеих линий, что говорит о хорошем воспроизведении опытных данных расчетными средними значениями результативного признака. 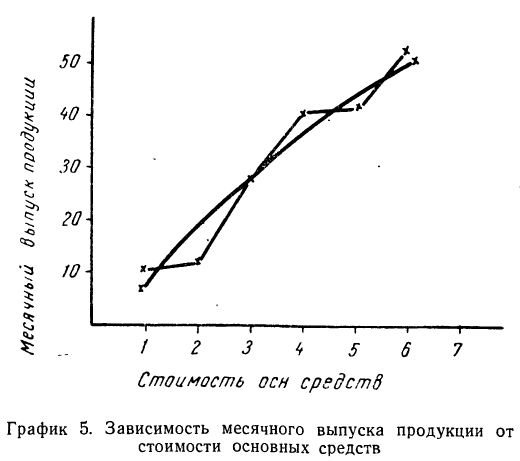
В практике изучения связи между признаками, кроме параболы 2-го порядка, применяются параболы и более высоких порядков. Чем выше порядок параболы, тем точнее он воспроизводит опытные данные.
Если уравнение связи представляет собой параболу 3-го порядка 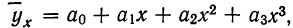 то система нормальных уравнений примет вид:
то система нормальных уравнений примет вид:
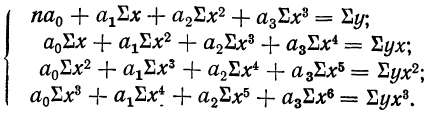
Имея соответствующие хну, можем составить Дополнительную расчетную таблицу по следующей схеме: 
которая используется для нахождения нужных сумм. Решив систему 4 уравнений, найдем параметры 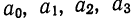 и, следовательно, уравнение связи.
и, следовательно, уравнение связи.
Уравнение гиперболы
Обратная связь указывает на убывание результативного признака при возрастании факториального. Такова линейная связь при отрицательном значении 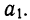 В ряде других случаев обратная связь может быть выражена уравнением гиперболы
В ряде других случаев обратная связь может быть выражена уравнением гиперболы 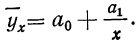
Параметры уравнения гиперболы 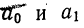 находятся из системы нормальных уравнений:
находятся из системы нормальных уравнений:
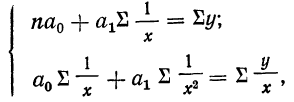
где 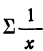 — сумма величин, обратных значениям факториального признака, а
— сумма величин, обратных значениям факториального признака, а 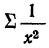 — сумма их квадратов.
— сумма их квадратов.
Примером расчета обратной связи по гиперболе может служить следующая таблица:
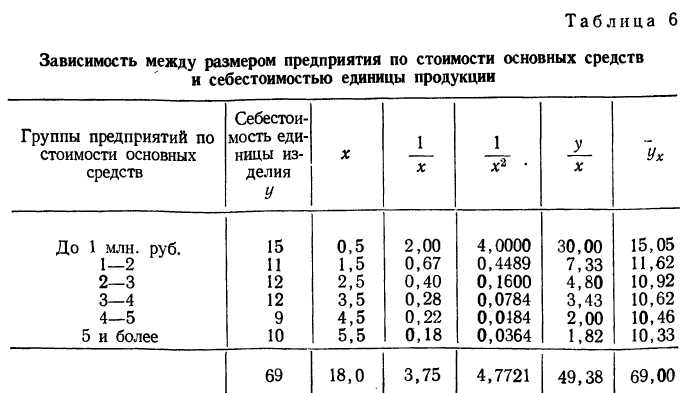
Составив по данным таблицы систему уравнений и разделив каждый член обоих уравнений на коэффициенты при а, получим:
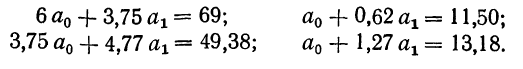
Находим вычитанием из второго уравнения первого величину 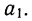
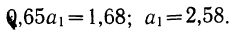
Подставив вместо 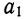 его значение, получим
его значение, получим 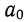
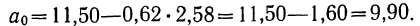
Запишем уравнение связи в общем виде 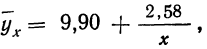 затем, подставив каждое значение х в уравнение, находим
затем, подставив каждое значение х в уравнение, находим 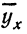 по любой строке таблицы. Строим ломаную по парам х и у и кривую по х и
по любой строке таблицы. Строим ломаную по парам х и у и кривую по х и 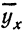 . Ломаная и кривая очень близки друг к другу.
. Ломаная и кривая очень близки друг к другу. 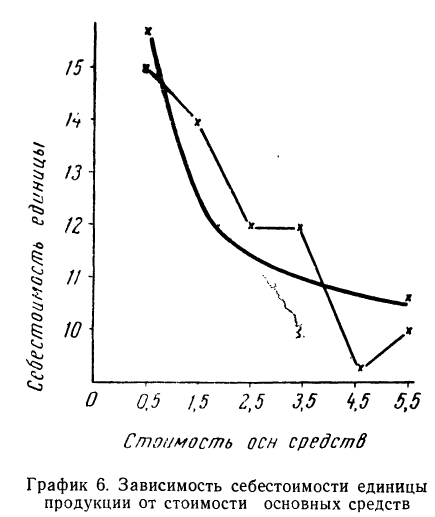
Корреляционная таблица
При большом объеме наблюдений, когда число взаимосвязанных пар велико, парные данные легко могут быть расположены в корреляционной таблице, являющейся наиболее удобной формой представления значительного количества пар чисел.
В корреляционной таблице один признак располагается в строках, а другой — в колонка таблицы. Число, расположенное в клетке на пересечении графы и колонки, показывает, как часто встречается данное значение результативного признака в сочетании с данным значением факториального признака.
Для простоты расчета возьмем небольшое число наблюдений на 20 предприятиях за средней месячной выработкой продукции на одного рабочего (тыс. руб. — у) и за стоимостью основных производственных средств (млн. руб. — х).
В обычной парной таблице эти сведения располагаются так: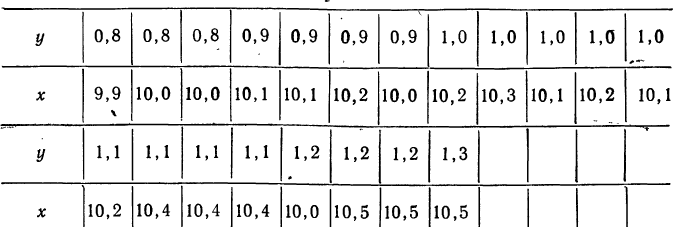
Сведем эти данные в корреляционную таблицу.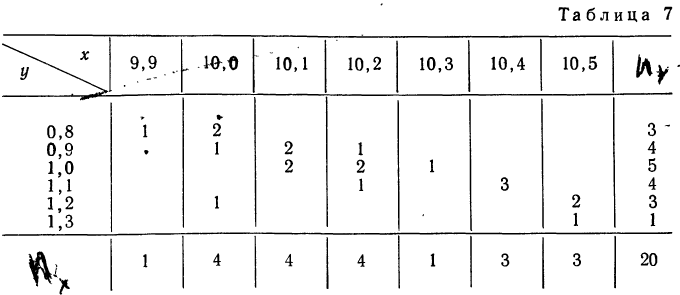
Итоги строк у показывают частоту признака 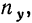 итоги граф х — частоту признака
итоги граф х — частоту признака 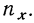 Числа, стоящие в клетках корреляционной таблицы, являются частотами, относящимися к обоим признакам и обозначаются
Числа, стоящие в клетках корреляционной таблицы, являются частотами, относящимися к обоим признакам и обозначаются 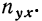
Корреляционная таблица даже при поверхностном знакомстве дает общее представление о прямой и обратной связи. Если частоты расположены по диагонали вниз направо, то связь между признаками прямая (при увеличивающихся значениях признака в строках и графах). Если же частоты расположены по диагонали вверх направо, то связь обратная.
Для предварительного суждения о связи по корреляционной таблице можно для каждого столбца рассчитать средние значения 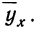 Так, в первом столбце х = 9,9, а
Так, в первом столбце х = 9,9, а 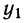 имеет лишь одно значение, равное 0,8. Найдем среднее значение для второго столбца. Оно будет равно:
имеет лишь одно значение, равное 0,8. Найдем среднее значение для второго столбца. Оно будет равно:
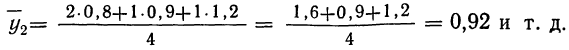
Следовательно, при 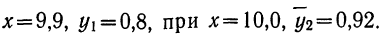 Выпишем все значения х и соответствующие им
Выпишем все значения х и соответствующие им 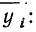

Зависимость, выраженная в таблице, более ярко и убедительно выступит в «ломаной регрессии», когда каждую пару чисел нанесем на график (см. график 7).
По корреляционной таблице можно вести расчеты параметров уравнения связи, как уравнения прямой, так и уравнений параболы и гиперболы. При этом необходимо учитывать, что сочетание каждой пары значений может встречаться не один, а несколько раз. Сами значения хну необходимо взвешивать, т. е. умножать на соответствующие частоты. Для самого признака х частота будет обозначаться 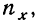 для признака
для признака 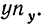 Частоту сочетаний обозначим
Частоту сочетаний обозначим 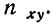
Ввиду сказанного мы можем систему нормальных уравнений написать так, чтобы были учтены веса. Тогда для линейной зависимости система нормальных уравнений примет вид:
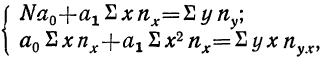
где N — число произведенных наблюдений (число пар). В приведенной корреляционной таблице N = 20. 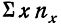 будет суммой произведений соответствующих х на их частоты. В данной таблице эта сумма составит:
будет суммой произведений соответствующих х на их частоты. В данной таблице эта сумма составит:
9,9 +10,0 • 4 +10,1 • 4 + 10,2 • 4 +10,3 • 1 +10,4 • 3 +10,5 • 3 = 204.
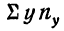 —сумма произведений у на соответствующие частоты. В нашем примере она равна:
—сумма произведений у на соответствующие частоты. В нашем примере она равна:
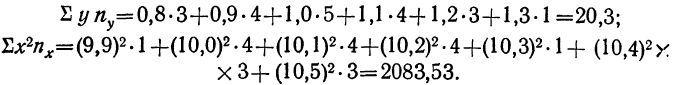
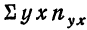 включает сумму произведений всех х на у и на
включает сумму произведений всех х на у и на 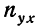 для тех клеток корреляционной таблицы, в которых записаны частоты. Рассчитаем суммы произведений для 1-й и 2-й строки
для тех клеток корреляционной таблицы, в которых записаны частоты. Рассчитаем суммы произведений для 1-й и 2-й строки
- Для 1 -и строки:

- Для 2-й строки:
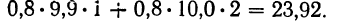
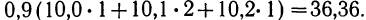
Нетрудно заметить, что в каждой строке у повторяется столько раз, сколько раз мы его суммируем, а, следовательно, у можно вынести за скобку.
- Для 1-й строки: 0,8 (9,9 • 1 +10,0 • 2) =23,92.
- Для 2-й строки:
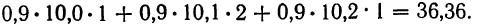
Следовательно, сумма произведений 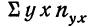 может быть записана при постоянном у, как
может быть записана при постоянном у, как 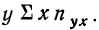 Заметим, что сумма произведений может быть записана и рассчитана как произведение
Заметим, что сумма произведений может быть записана и рассчитана как произведение 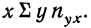
Продолжим расчет для последующих строк.
- Для 3-й строки
- Для 4-й строки
- Для 5-й строки
- Для 6-й строки
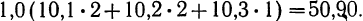
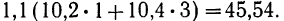
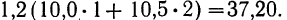
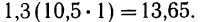
Общая сумма по всем строкам 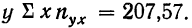
Система нормальных уравнений может быть записана по результатам подсчета в таком виде:
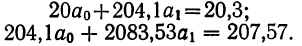
Для расчета параметров уравнения линейной связи делим каждое из уравнений на коэффициенты при 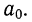
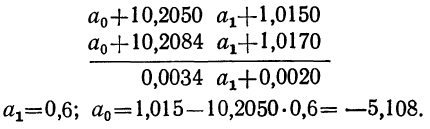
Уравнение связи 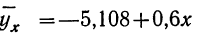 определяет среднюю зависимость выработки рабочего от стоимости основных средств. Вычислительная работа облегчается, если в самой корреляционной таблице путем записи дополнительных граф и строк производить нужные подсчеты для решения системы уравнений.
определяет среднюю зависимость выработки рабочего от стоимости основных средств. Вычислительная работа облегчается, если в самой корреляционной таблице путем записи дополнительных граф и строк производить нужные подсчеты для решения системы уравнений.
Число наблюдений N может быть подсчитано и по столбцу  как его сумма. Она равна итогу по строке
как его сумма. Она равна итогу по строке  Для определения
Для определения  необходимо ввести новую строку
необходимо ввести новую строку 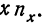 Итог этой строки и дает искомую сумму.
Итог этой строки и дает искомую сумму.
Следующая дополнительная строка 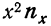 представляет возможность определить
представляет возможность определить 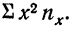 Далее,
Далее, 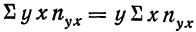 и может быть определена на основе расчета двух дополнительных граф:
и может быть определена на основе расчета двух дополнительных граф:
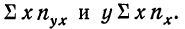
В корреляционной таблице (см. табл. 8) в последних строках дается расчет 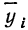 для построения ломаной регрессии
для построения ломаной регрессии 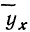 — для построения прямой (см. график 7).
— для построения прямой (см. график 7). 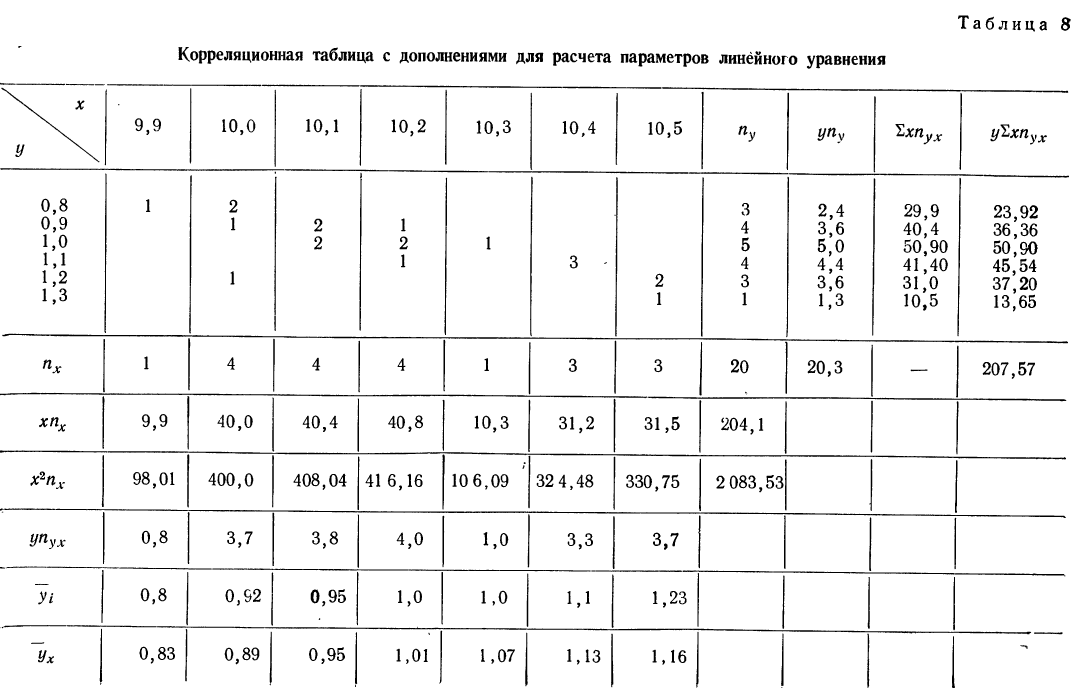
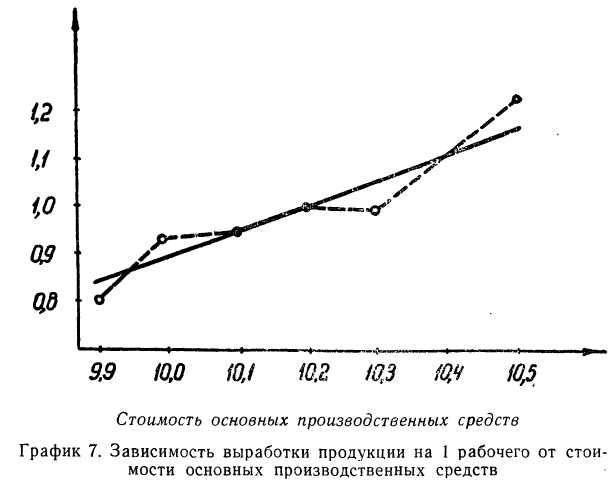
Корреляционная таблица позволяет вычислять уравнение связи для любой формы: прямой, параболы, гиперболы и др. Однако в подобной таблице видна зависимость результативного признака лишь от одного факториального.
Зависимость результативного признака от двух или более факториальных признаков носит название множественной связи.
Множественная связь
Исследование зависимости результативного признака от двух или нескольких факториальных признаков возможно при помощи уравнения множественной связи.
В простейшем уравнении множественной связи предполагается, что зависимость между признаками линейная. Сначала рассмотрим линейную зависимость результативного признака (у) от двух факториальных (х, z). Уравнение связи в этом случае выразится формулой 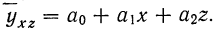 Параметры этого уравнения находятся при решении системы нормальных уравнений, получаемых для способа наименьших квадратов
Параметры этого уравнения находятся при решении системы нормальных уравнений, получаемых для способа наименьших квадратов
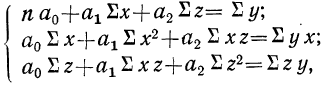
где п — число одновременных наблюдений по трем признакам;
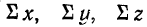 —суммы соответствующих значений по этим признакам.
—суммы соответствующих значений по этим признакам.
Все расчеты удобно сосредоточить в специальной таблице, как это делается в приводимом ниже примере.
Рассмотрим зависимость средней урожайности ячменя (у) на равных участках от количества внесенных минеральных удобрений (х) и количества выпавших в период цветения осадков (z).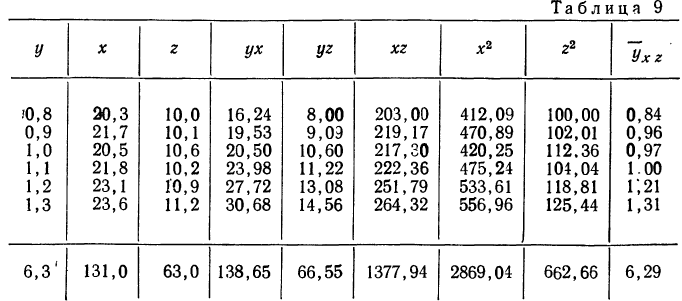
Средняя урожайность исчислялась по участкам с равным количеством внесенных удобрений и с равным количеством выпавших осадков.
Пользуясь данными таблицы, составляем систему трех уравнений:
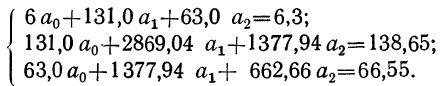
Поделив все члены уравнений на коэффициенты при 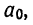 получим:
получим:
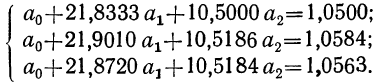
Вычитая из второго уравнения сначала первое, а затем третье, получим 2 уравнения с двумя неизвестными:
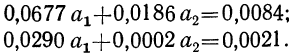
Делим каждый член обоих уравнений на коэффициенты при 
Уравнение связи, определяющее зависимость результативного признака (у) от двух факториальных
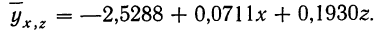
Вычислив по этому уравнению при соответствующих х и z величины 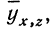 замечаем, что суммы опытных данных (y) и расчетных данных
замечаем, что суммы опытных данных (y) и расчетных данных 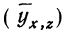 совпадают, а отдельные значения их мало отличаются друг от друга.
совпадают, а отдельные значения их мало отличаются друг от друга.
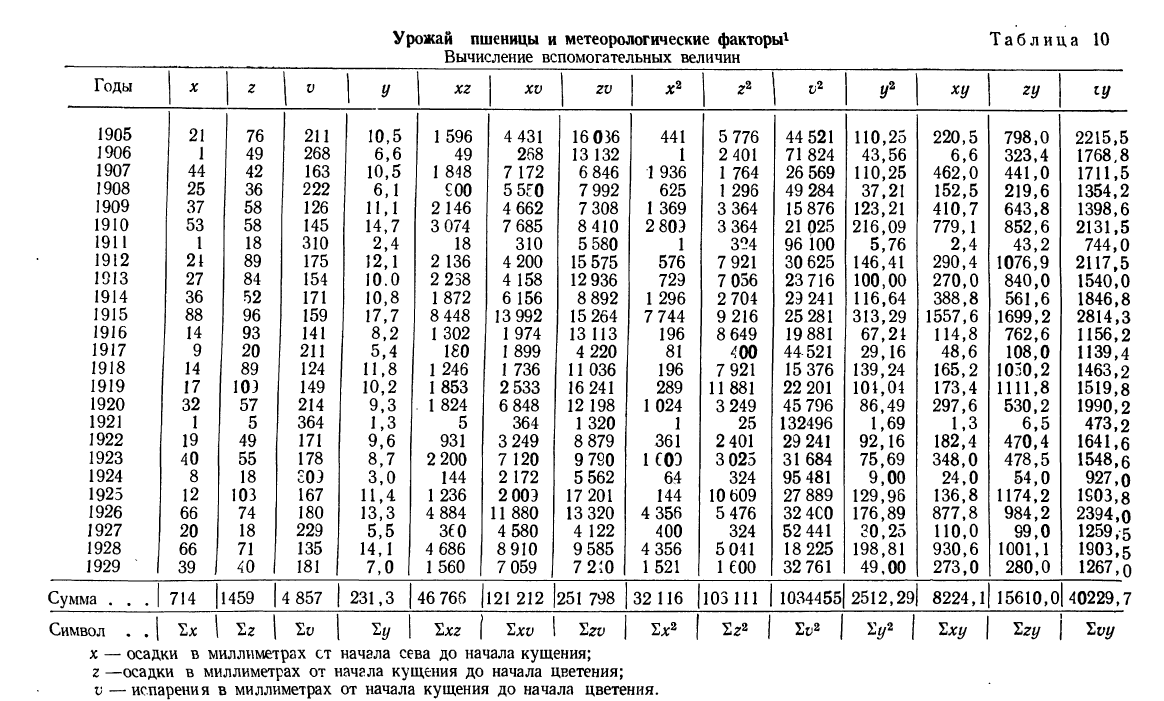
Найдем уравнение связи между урожайностью пшеницы на Безенчукской опытной станции и тремя факторами (х, z, v).
Статистические данные, полученные в результате наблюдения, и расчеты представлены в табл. 10, откуда возьмем необходимые данные для составления системы нормальных уравнений:

Следовательно,, корреляционное уравнение будет:
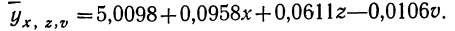
Расширив число факториальных признаков, можно найти уравнение множественной связи для 4, 5, 6 и т. д. признаков. При этом необходимо брать только такие признаки, которые оказывают существенное влияние на величину результативного признака, ибо учет несущественных, второстепенных признаков лишь увеличивает расчетную работу при нахождении уравнения связи, а не приближает к более полному изучению связи.
Если число факториальных признаков возрастает, возрастает и число членов уравнения связи. Так, для трех факториальных признаков линейное уравнение связи будет записано формулой:
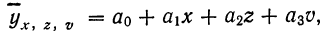
где параметры уравнения 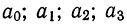 находятся путем решения системы четырех нормальных уравнений:
находятся путем решения системы четырех нормальных уравнений:
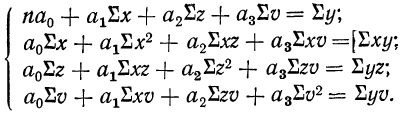
Построив соответствующую таблицу, получим в ней необходимые суммарные данные для приведенной системы уравнений (см. табл. 10).
Мерой существенности влияния того или иного факториального признака на результативный являются показатели тесноты связи.
В настоящем издании мы рассмотрим эмпирические меры тесноты связи, полученные разными исследователями, и меры тесноты связи, основанные на измерении вариации.
Эмпирические меры тесноты связи
Эмпирические меры тесноты связи позволяют оценить степень связи между явлениями или факторами, находящимися в зависимости один от другого. Эмпирические меры получены различными исследователями, занимавшимися статистической обработкой фактического материала. Они получены ранее, чем был открыт метод корреляции. Практическое пользование эмпирическими показателями довольно удобно.
К эмпирическим мерам тесноты относятся:
- а) коэффициент ассоциации:
- б) коэффициенты взаимной напряженности;
- в) коэффициент Фехнера;
- Г) коэффициент корреляции рангов;
Рассмотрим каждый из них.
а) Коэффициент ассоциации. Коэффициент ассоциации как мера тесноты связи применяется для изучения связи двух качественных признаков, состоящих только из двух групп. Для его вычисления строится четырехклеточная таблица корреляции, которая выражает связь между двумя явлениями, каждое из которых, в свою очередь, должно быть альтернативным, т. е. состоящим только из двух видов, качественно отличных друг от друга. Например, при изучении зависимости урожая от количества внесенных в почву удобрений выделяем по урожайности и по количеству внесенных удобрений лишь по две группы. При этом условии можно построить следующую четырехклеточную таблицу.
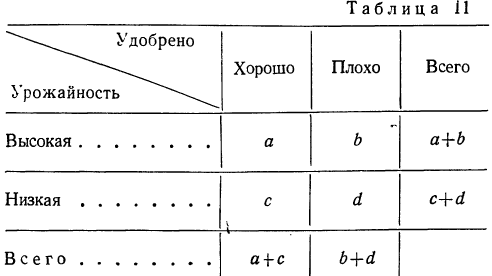
Числа, стоящие на пересечении строк и граф — a,b,c,d, показывают, сколько участков встречается с тем и другим количеством удобрений, внесенным в почву, с той и другой урожайностью.
Мера тесноты связи — коэффициент ассоциации — исчисляется по формуле:
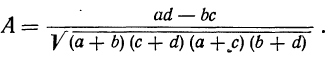
Заполнив клетки конкретными числовыми данными, получим следующую четырехклеточную таблицу, где числа, стоящие в клетках, — гектары посевов.

Коэффициент ассоциации равен: 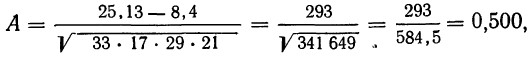
что говорит о достаточно тесной прямой связи между урожайностью и степенью удобрения почв.
Коэффициент ассоциации может иметь и отрицательные значения, когда ad
При копировании любых материалов с сайта evkova.org обязательна активная ссылка на сайт www.evkova.org
Сайт создан коллективом преподавателей на некоммерческой основе для дополнительного образования молодежи
Сайт пишется, поддерживается и управляется коллективом преподавателей
Whatsapp и логотип whatsapp являются товарными знаками корпорации WhatsApp LLC.
Cайт носит информационный характер и ни при каких условиях не является публичной офертой, которая определяется положениями статьи 437 Гражданского кодекса РФ. Анна Евкова не оказывает никаких услуг.
Методы выявления и оценки корреляционной связи
Поможем написать любую работу на аналогичную тему
Для выявления наличия и характера корреляционной связи между двумя признаками в статистике используется ряд методов.
1. Рассмотрение параллельных данных (значений x и y в каждой из n единиц). Единицы наблюдения необходимо расположить по возрастанию значений факторного признака х (как в таблице справа) и затем сравнить с ним (визуально) поведение результативного признака у.
В нашей задаче в 6 случаях по мере увеличения значений x увеличиваются и значения y, а в 5 случаях этого не происходит, поэтому затруднительно говорить о прямой связи между х и у.
2. Графический метод – это графическое изображение корреляционной зависимости. Для этого, имея n взаимосвязанных пар значений x и y и пользуясь прямоугольной системой координат, каждую такую пару изображают в виде точки на плоскости с координатами x и y. Совокупность полученных точек представляет собой корреляционное поле (рис. 20), а соединяя последовательно нанесенные точки отрезками, получают ломаную линию, именуемую эмпирической линией регрессии (рис. 21).

 Рис. 20. Корреляционное поле Рис. 21. Эмпирическая линия регрессии
Рис. 20. Корреляционное поле Рис. 21. Эмпирическая линия регрессии
Визуально анализируя график, можно предположить характер зависимости между признаками x и y. В нашей задаче эмпирическая линия регрессии (рис.21) похожа на восходящую прямую, что позволяет выдвинуть гипотезу о наличии прямой зависимости между величиной стоимостного внешнеторгового товарооборота и величиной таможенных платежей в федеральный бюджет.
3. Метод аналитических группировок используется при большом числе наблюдений для выявления корреляционной связи между двумя количественными признаками. Чтобы выявить наличие корреляционной связи между двумя признаками, проводится группировка единиц совокупности по факторному признаку х и для каждой выделенной группы рассчитывается среднее значение результативного признака  . Если результативный признак у зависит от факторного х, то в изменении среднего значения будет прослеживаться определенная закономерность. Примером такой группировки могут служить данные об издержках обращения предприятий оптовой торговли с различным товарооборотом (см. табл. 40).
. Если результативный признак у зависит от факторного х, то в изменении среднего значения будет прослеживаться определенная закономерность. Примером такой группировки могут служить данные об издержках обращения предприятий оптовой торговли с различным товарооборотом (см. табл. 40).
Таблица 40. Условные пример аналитической группировки
В последнем столбце табл. 40 приведены средние величины, рассчитанные на основе индивидуальных данных об издержках отдельных предприятий каждой группы. Данные таблицы 40 свидетельствуют, что чем крупнее товарооборот, тем меньше издержки обращения. Таким образом, с помощью простой аналитической группировки можно выявить наличие зависимости между рассматриваемыми показателями: объемом товарооборота как показателем размера предприятий и средним уровнем издержек обращения.
4. Метод корреляционных таблиц предполагает комбинационное распределение единиц совокупности по двум количественным признакам. Такая таблица строится по типу «шахматной», т.е. в подлежащем (строках) таблицы выделяются группы по факторному признаку х, а в сказуемом (столбцах) – по результативному у (или наоборот), а в клетках таблицы на пересечении х и у показано число случаев совпадения каждого значения х с соответствующим значением у. Общий вид такой таблицы показан на условном распределении 40 единиц по признакам х и у, где х – стаж работы, у – производительность труда (число изделий, вырабатываемых в час одним рабочим) – таблица 41. Среднее значение по группам определяется по средней арифметической взвешенной по серединам группировочных интервалов.
Таблица 41. Условные корреляционной таблицы
Значение признака уi
Как видно из таблицы 41, по мере увеличения значений х итоговые групповые средние тоже увеличиваются от группы к группе, что свидетельствует о том, что между х и у существует корреляционная связь. О наличии и направлении связи можно судить и по «внешнему виду» таблицы, т.е. по расположению в ней частот: если частоты расположены в клетках таблицы беспорядочно, то это чаще всего свидетельствует об отсутствии связи между группировочными признаками (или о незначительной зависимости); если частоты сконцентрированы ближе к одной из диагоналей и центру таблицы, образуя своего рода эллипс, то это почти всегда свидетельствует о наличии зависимости между х и у, близкой к линейной. Расположение по диагонали из верхнего левого угла в нижний правый свидетельствует о прямой линейной связи, а из нижнего левого угла в верхний правый – об обратной.
На основе аналитических группировок и корреляционных таблиц можно не только выявить наличие зависимости между двумя коррелируемыми показателями, но и измерить тесноту этой связи, в частности, с помощью эмпирического корреляционного отношения.
 ,
,
 ,
,
 .
.
где m – число групп по факторному признаку х;
k – число групп по результативному признаку у;
– средние значения результативного признака по группам;
 – общее среднее значение результативного признака;
– общее среднее значение результативного признака;
 – индивидуальные значения результативного признака;
– индивидуальные значения результативного признака;
 – частота в j-й группе х;
– частота в j-й группе х;
 – частота в i-й группе у.
– частота в i-й группе у.
Рассчитаем это отношение для нашего примера (таблица 41):
 =(5*3+10*9+15*21+20*7)/40=14
=(5*3+10*9+15*21+20*7)/40=14
 =6,19599;
=6,19599;
 =16,5;
=16,5;  =0,613.
=0,613.
Полученное значение  =0,613 позволяет утверждать, что существует заметная связь между стажем работы и производительностью труда.
=0,613 позволяет утверждать, что существует заметная связь между стажем работы и производительностью труда.
5. Коэффициент корреляции знаков (Фехнера) – простейший показатель тесноты связи, основанный на сравнении поведения отклонений индивидуальных значений каждого признака (x и y) от своей средней величины. При этом во внимание принимаются не величины отклонений ( ) и (
) и ( ), а их знаки («+» или «–»). Определив знаки отклонений от средней величины в каждом ряду, рассматривают все пары знаков и подсчитывают число их совпадений (С) и несовпадений (Н). Тогда коэффициент Фехнера рассчитывается как отношение разности чисел пар совпадений и несовпадений знаков к их сумме, т.е. к общему числу наблюдаемых единиц:
), а их знаки («+» или «–»). Определив знаки отклонений от средней величины в каждом ряду, рассматривают все пары знаков и подсчитывают число их совпадений (С) и несовпадений (Н). Тогда коэффициент Фехнера рассчитывается как отношение разности чисел пар совпадений и несовпадений знаков к их сумме, т.е. к общему числу наблюдаемых единиц:
 . (121)
. (121)
Очевидно, что если знаки всех отклонений по каждому признаку совпадут, то КФ=1, что характеризует наличие прямой связи. Если все знаки не совпадут, то КФ=–1 (обратная связь). Если же åС=åН, то КФ=0. Итак, как и любой показатель тесноты связи, коэффициент Фехнера может принимать значения от 0 до  1. Однако, если КФ=1, то это ни в коей мере нельзя воспринимать как свидетельство функциональной зависимости между х и у.
1. Однако, если КФ=1, то это ни в коей мере нельзя воспринимать как свидетельство функциональной зависимости между х и у.
Средние значения факторного и результативного признаков определяем по формуле средней арифметической простой (10):
 ;
;  .
.
В двух последних столбцах таблицы 42 приведены знаки отклонений каждого х и у от своей средней величины. Число совпадений знаков – 10, а несовпадений – 2, тогда определяем коэффициент корреляции знаков (Фехнера) по формуле (121):
КФ=
Таблица 42. Вспомогательная таблица для расчета коэффициента Фехнера
x –
y – 
Обычно такое значение показателя тесноты связи характеризует заметную прямую зависимость между x и y, однако, следует иметь в виду, что поскольку КФ зависит только от знаков и не учитывает величину самих отклонений х и у от их средних величин, то он практически характеризует не столько тесноту связи, сколько ее наличие и направление.
6. Линейный коэффициент корреляции – самый популярный измеритель тесноты линейной связи между двумя количественными признаками x и y. Он основан на предположении, что при полной независимости[43] признаков x и у отклонения значений факторного признака от средней ( ) носят случайный характер и должны случайно сочетаться с различными отклонениями (
) носят случайный характер и должны случайно сочетаться с различными отклонениями ( ). При наличии значительного перевеса совпадений или несовпадений таких отклонений делается предположение о наличии связи между x и y.
). При наличии значительного перевеса совпадений или несовпадений таких отклонений делается предположение о наличии связи между x и y.
В отличие от КФ в линейном коэффициенте корреляции учитываются не только знаки отклонений от средних величин, но и значения самих отклонений, выраженные для сопоставимости в единицах среднего квадратического отклонения t:
 и
и  .
.
Линейный коэффициент корреляции r представляет собой среднюю величину из произведений нормированных отклонений для x и у:
 , (122) или
, (122) или  . (123)
. (123)
Числитель формулы (123), деленный на n, представляющий собой среднее произведение отклонений значений двух признаков от их средних значений, называется коэффициентом ковариации – это мера совместной вариации факторного x и результативного y признаков:
 (124)
(124)
Недостатком коэффициента ковариации является то, что он не нормирован, в отличие от линейного коэффициента корреляции. Очевидно, что линейный коэффициент корреляции представляет собой частное от деления ковариации между х и у на произведение их средних квадратических отклонений:
 . (125)
. (125)
Путем несложных математических преобразований[44] можно получить и другие модификации формулы линейного коэффициента корреляции, например:
 , (126)
, (126)  , (127)
, (127)
 , (128)
, (128)  . (129)
. (129)
Линейный коэффициент корреляции может принимать значения от –1 до +1, причем знак определяется в ходе решения. Например, если  , то r по формуле (126) будет положительным, что характеризует прямую зависимость между х и у, в противном случае (r 30), то σr рассчитывается по формуле (130):
, то r по формуле (126) будет положительным, что характеризует прямую зависимость между х и у, в противном случае (r 30), то σr рассчитывается по формуле (130):
 . (130)
. (130)
Обычно, если  >3, то r считается значимым (существенным), а связь – реальной. Задавшись определенной вероятностью, можно определить доверительные пределы (границы) r = (
>3, то r считается значимым (существенным), а связь – реальной. Задавшись определенной вероятностью, можно определить доверительные пределы (границы) r = ( ), где t – коэффициент доверия, рассчитываемый по интегралу Лапласа (см. Приложение 1).
), где t – коэффициент доверия, рассчитываемый по интегралу Лапласа (см. Приложение 1).
2. Если число наблюдений небольшое (n tТАБЛ , то r считается значимым, а связь между х и у – реальной. В противном случае (tРАСЧ tТАБЛ, что дает возможность считать линейный коэффициент корреляции r = 0,937 значимым.
7. Подбор уравнения регрессии[45] представляет собой математическое описание изменения взаимно коррелируемых величин по эмпирическим (фактическим) данным. Уравнение регрессии должно определить, каким будет среднее значение результативного признака у при том или ином значении факторного признака х, если остальные факторы, влияющие на у и не связанные с х, не учитывать, т.е. абстрагироваться от них. Другими словами, уравнение регрессии можно рассматривать как вероятностную гипотетическую функциональную связь величины результативного признака у со значениями факторного признака х.
Уравнение регрессии можно также назвать теоретической линией регрессии. Рассчитанные по уравнению регрессии значения результативного признака называются теоретическими. Они обычно обозначаются  или
или  (читается: «игрек, выравненный по х») и рассматриваются как функция от х, т.е. = f(x).
(читается: «игрек, выравненный по х») и рассматриваются как функция от х, т.е. = f(x).
Найти в каждом конкретном случае тип функции, с помощью которой можно наиболее адекватно отразить ту или иную зависимость между признаками х и у, — одна из основных задач регрессионного анализа. Выбор теоретической линии регрессии часто обусловлен формой эмпирической линии регрессии; теоретическая линия как бы сглаживает изломы эмпирической линии регрессии. Кроме того, необходимо учитывать природу изучаемых показателей и специфику их взаимосвязей.
Для аналитической связи между х и у могут использоваться виды уравнений, приведенные в таблице 30 (при условии замены t на x). Обычно зависимость, выражаемую уравнением прямой, называют линейной (или прямолинейной), а все остальные — криволинейными зависимостями.
Выбрав тип функции (таблица 30), по эмпирическим данным определяют параметры уравнения. При этом отыскиваемые параметры должны быть такими, при которых рассчитанные по уравнению теоретические значения результативного признака были бы максимально близки к эмпирическим данным.
Существует несколько методов нахождения параметров уравнения регрессии. Наиболее часто используется метод наименьших квадратов (МНК). Его суть заключается в следующем требовании: искомые теоретические значения результативного признака должны быть такими, при которых бы обеспечивалась минимальная сумма квадратов их отклонений от эмпирических значений, т.е.
 .
.
Поставив данное условие, легко определить, при каких значениях a0, a1 и т.д. для каждой аналитической кривой эта сумма квадратов отклонений будет минимальной. Данный метод уже использовался нами в теме 6 «Статистическое изучение динамики ВЭД», поэтому, воспользуемся формулой (100) для нахождения параметров теоретической линии регрессии, заменив параметр t на x:
 (133)
(133)
Выразив из первого уравнения системы (133) a0, получим[46]:
 . (134)
. (134)
Подставив (134) во второе уравнение системы (133), затем разделив обе его части на n, получим:
 . (135)
. (135)
Применяя 3 раза формулу средней арифметической, получим:
 . (136)
. (136)
Раскрыв скобки и перенеся члены без a1 в правую часть уравнения, выразим a1:
 . (137)
. (137)
Параметр a1 в уравнении линейной регрессии называется коэффициентом регрессии, который показывает на сколько изменяется значение результативного признака y при изменении факторного признака x на единицу.
Исходные данные и расчеты для нашего примера представим в таблице 45.
Таблица 45. Вспомогательные расчеты для нахождения уравнения регрессии
Корреляции для начинающих
Апдейт для тех, кто сочтет статью полезной и занесет в избранное. Есть приличный шанс, что пост уйдет в минуса, и я буду вынужден унести его в черновики. Сохраняйте копию!
Краткий и несложный материал для неспециалистов, рассказывающий в наглядной форме о различных методах поиска регрессионных зависимостей. Это все и близко не академично, зато надеюсь что понятно. Прокатит как мини-методичка по обработке данных для студентов естественнонаучных специальностей, которые математику знают плохо, впрочем как и автор. Расчеты в Матлабе, подготовка данных в Экселе — так уж повелось в нашей местности 
Введение
Зачем это вообще надо? В науке и около нее очень часто возникает задача предсказания какого-то неизвестного параметра объекта исходя из известных параметров этого объекта (предикторов) и большого набора похожих объектов, так называемой учебной выборки. Пример. Вот мы выбираем на базаре яблоко. Его можно описать такими предикторами: красность, вес, количество червяков. Но как потребителей нас интересует вкус, измеренный в попугаях по пятибалльной шкале. Из жизненного опыта нам известно, что вкус с приличной точностью равен 5*красность+2*вес-7*количество червяков. Вот про поиск такого рода зависимостей мы и побеседуем. Чтобы обучение пошло легче, попробуем предсказать вес девушки исходя из ее 90/60/90 и роста.
Исходные данные
В качестве объекта исследования возьму данные о параметрах фигуры девушек месяца Плейбоя. Источник — www.wired.com/special_multimedia/2009/st_infoporn_1702, слегка облагородил и перевел из дюймов в сантиметры. Вспоминается анекдот про то, что 34 дюйма — это как два семнадцатидюймовых монитора. Также отделил записи с неполной информацией. При работе с реальными объектами их можно использовать, но сейчас они нам только мешают. Зато их можно использовать для проверки адекватности полученных результатов. Все данные у нас непрерывные, то есть грубо говоря типа float. Они приведены к целым числам только чтобы не загромождать экран. Есть способы работы и с дискретными данными — в нашем примере это например может быть цвет кожи или национальность, которые принимают одно из фиксированного набора значений. Это больше имеет отношение к методам классификации и принятия решений, что тянет еще на один мануал. Data.xls В файле два листа. На первом собственно данные, на втором — отсеянные неполные данные и набор для проверки нашей модели.
Обозначения
W — вес реальный
W_p — вес, предсказанный нашей моделью
S — бюст
T — талия
B — бедра
L — рост
E — ошибка модели
Как оценить качество модели?
Задача нашего упражнения — получить некую модель, которая описывает какой-либо объект. Способ получения и принцип работы конкретной модели нас пока не волнует. Это просто функция f(S, T, B, L), которая выдает вес девушки. Как понять, какая функция хорошая и качественная, а какая не очень? Для этого используется так называемая fitness function. Самая классическая и часто используемая — это сумма квадратов разницы предсказанного и реального значения. В нашем случае это будет сумма (W_p — W)^2 для всех точек. Собственно, отсюда и пошло название «метод наименьших квадратов». Критерий не лучший и не единственный, но вполне приемлемый как метод по умолчанию. Его особенность в том, что он чувствителен по отношению к выбросам и тем самым, считает такие модели менее качественными. Есть еще всякие методы наименьших модулей итд, но сейчас нам это пока не надо.
Простая линейная регрессия
Самый простой случай. У нас одна переменная-предиктор и одна зависимая переменная. В нашем случае это может быть например рост и вес. Нам надо построить уравнение W_p = a*L+b, т.е. найти коэффициенты a и b. Если мы проведем этот расчет для каждого образца, то W_p будет максимально совпадать с W для того же образца. То есть у нас для каждой девушки будет такое уравнение:
W_p_i = a*L_i+b
E_i = (W_p-W)^2
Общая ошибка в таком случае составит sum(E_i). В результате, для оптимальных значений a и b sum(E_i) будет минимальным. Как же найти уравнение?
Матлаб
Для упрощения очень рекомендую поставить плагин для Excel под названием Exlink. Он в папке matlab/toolbox/exlink. Очень облегчает пересылку данных между программами. После установки плагина появляется еще одно меню с очевидным названием, и автоматически запускается Матлаб. Переброс информации из Экселя в Матлаб запускается командой «Send data to MATLAB», обратно, соответственно, — «Get data from MATLAB». Пересылаем в Матлаб числа из столбца L и отдельно из W, без заголовков. Переменные назовем так же. Функция расчета линейной регрессии — polyfit(x,y,1). Единица показывает степень аппроксимационного полинома. У нас он линейный, поэтому единица. Получаем наконец-то коэффициенты регрессии: regr=polyfit(L,W,1) . a мы можем получить как regr(1), b — как regr(2). То есть мы можем получить наши значения W_p: W_p=L*repr(1)+repr(2) . Вернем их назад в Эксель.
Графичек
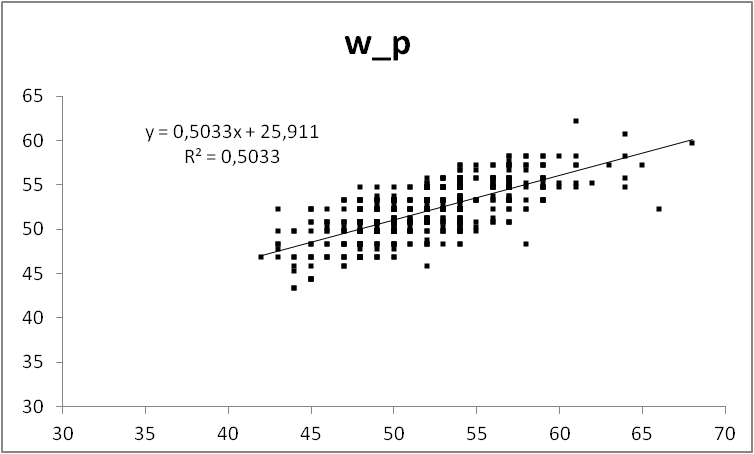
Мда, негусто. Это график W_p(W). Формула на графике показывает связь W_p и W. В идеале там будет W_p = W*1 + 0. Вылезла дискретизация исходных данных — облако точек клетчатое. Коэффициент корреляции ни в дугу — данные слабо коррелированы между собой, т.е. наша модель плохо описывает связь веса и роста. По графику это видно как точки, расположенные в форме слабо вытянутого вдоль прямой облака. Хорошая модель даст облако растянутое в узкую полосу, еще более плохая — просто хаотичный набор точек или круглое облако. Модель необходимо дополнить. Про коэффициент корреляции стоит рассказать отдельно, потому что его часто используют абсолютно неправильно.
Расчет в матричном виде
Можно и без всяких полифитов справиться с построением регрессии, если слегка дополнить столбец с величинами роста еще одним столбцом, заполненным единицами: L(:,2)=1 . Двойка показывает номер столбца, в который пишутся единицы. Тогда коэффициенты регрессии можно будет найти по такой формуле: repr=inv(L’*L)*L’*W . И обратно, найти W_p: W_p=L*repr . Когда осознаешь магию матриц, пользоваться функциями становится неприкольно. Единичный столбец нужен для расчета свободного члена регрессии, то есть просто слагаемого без умножения на параметр. Если его не добавлять, то в регрессии будет всего один член: W_p=a*L. Достаточно очевидно, что она будет хуже по качеству, чем регрессия с двумя слагаемыми. В целом, избавляться от свободного члена надо только в том случае, если он точно не нужен. По умолчанию он все-таки присутствует.
Мультилинейная регрессия
В русскоязычной литературе прошлых лет упоминается как ММНК — метод множественных наименьших квадратов. Это расширение метода наименьших квадратов для нескольких предикторов. То есть у нас в дело идет не только рост, но и все остальные, так сказать, горизонтальные размеры. Подготовка данных точно такая же: обе матрицы в матлаб, добавление столбца единиц, расчет по той же самой формуле. Для любителей функций есть b = regress(y,X) . Эта функция также требует добавления столбца единиц. Повторяем расчет по формуле из раздела про матрицы, пересылаем в Эксель, смотрим.
Попытка номер два
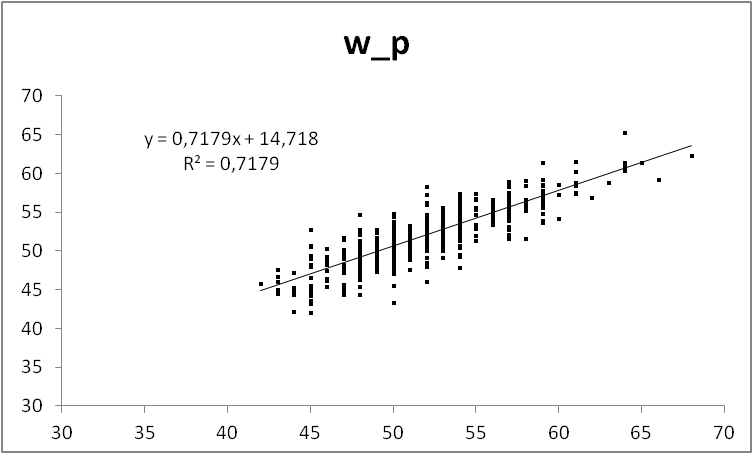
А так получше, но все равно не очень. Как видим, клетчатость осталась только по горизонтали. Никуда не денешься, исходные веса были целыми числами в фунтах. То есть после конверсии в килограммы они ложатся на сетку с шагом около 0.5. Итого финальный вид нашей модели:
W_p = 0.2271*S + 0.1851*T + 0.3125*B + 0.3949*L — 72.9132
Объемы в сантиметрах, вес в кг. Поскольку у нас все величины кроме роста в одних единицах измерения и примерно одного порядка по величине (кроме талии), то мы можем оценить их вклады в общий вес. Рассуждения примерно в таком духе: коэффициент при талии самый маленький, равно как и сами величины в сантиметрах. Значит, вклад этого параметра в вес минимален. У бюста и особенно у бедер он больше, т.е. сантиметр на талии дает меньшую прибавку к массе, чем на груди. А больше всего на вес влияет объем задницы. Впрочем, это знает любой интересующийся вопросом мужчина. То есть как минимум, наша модель реальной жизни не противоречит.
Валидация модели
Название громкое, но попробуем получить хотя бы ориентировочные веса тех девушек, для которых есть полный набор размеров, но нет веса. Их 7: с мая по июнь 1956 года, июль 1957, март 1987, август 1988. Находим предсказанные по модели веса: W_p=X*repr 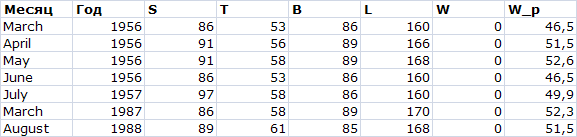
Что ж, по крайней мере в текстовом виде выглядит правдоподобно. А насколько это соответствует реальности — решать вам
Применимость
Если вкратце — полученная модель годится для объектов, подобных нашему набору данных. То есть по полученным корреляциям не стоит считать параметры фигур женщин с весом 80+, возрастом, сильно отличающимся от среднего по больнице итд. В реальных применениях можно считать, что модель пригодна, если параметры изучаемого объекта не слишком отличаются от средних значений этих же параметров для исходного набора данных. Могут возникнуть (и возникнут) проблемы, если у нас предикторы сильно коррелированы между собой. То есть, например это рост и длина ног. Тогда коэффициенты для соответствующих величин в уравнении регрессии будут определены с малой точностью. В таком случае надо выбросить один из параметров, или воспользоваться методом главных компонент для снижения количества предикторов. Если у нас малая выборка и/или много предикторов, то мы рискуем попасть в переопределенность модели. То есть если мы возьмем 604 параметра для нашей выборки (а в таблице всего 604 девушки), то сможем аналитически получить уравнение с 604+1 слагаемым, которое абсолютно точно опишет то, что мы в него забросили. Но предсказательная сила у него будет весьма невелика. Наконец, далеко не все объекты можно описать мультилинейной зависимостью. Бывают и логарифмические, и степенные, и всякие сложные. Их поиск — это уже совсем другой вопрос.
http://www.ekonomstat.ru/kurs-lektsij-po-teorii-statistiki/421-metody-vyjavlenija-i-ocenki-korreljacionnoj-svjazi.html
http://habr.com/ru/post/172043/