Анализ временных рядов, тренд ряда динамики, точечная оценка прогноза
МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ
Анализ временных рядов
Временной ряд (или ряд динамики) – это упорядоченная по времени последовательность значений некоторой произвольной переменной величины. Тем самым, временной ряд существенным образом отличается от простой выборки данных. Каждое отдельное значение данной переменной называется отсчётом (уровнем элементов) временного ряда.
Временные ряды состоят из двух элементов:
- периода времени, за который или по состоянию на который приводятся числовые значения;
- числовых значений того или иного показателя, называемых уровнями ряда.
Временные ряды классифицируются по следующим признакам:
- по форме представления уровней: ряды абсолютных показателей, относительных показателей, средних величин;
- по количеству показателей, когда определяются уровни в каждый момент времени: одномерные и многомерные временные ряды;
- по характеру временного параметра: моментные и интервальные временные ряды. В моментных временных рядах уровни характеризуют значения показателя по состоянию на определенные моменты времени. В интервальных рядах уровни характеризуют значение показателя за определенные периоды времени. Важная особенность интервальных временных рядов абсолютных величин заключается в возможности суммирования их уровней. Отдельные же уровни моментного ряда абсолютных величин содержат элементы повторного счета. Это делает бессмысленным суммирование уровней моментных рядов;
- по расстоянию между датами и интервалами времени выделяют равноотстоящие – когда даты регистрации или окончания периодов следуют друг за другом с равными интервалами и неполные (неравноотстоящие) – когда принцип равных интервалов не соблюдается;
- по наличию пропущенных значений: полные и неполные временные ряды. Временные ряды бывают детерминированными и случайными: первые получают на основе значений некоторой неслучайной функции (ряд последовательных данных о количестве дней в месяцах); вторые есть результат реализации некоторой случайной величины;
- в зависимости от наличия основной тенденции выделяют стационарные ряды – в которых среднее значение и дисперсия постоянны и нестационарные – содержащие основную тенденцию развития.
Временные ряды, как правило, возникают в результате измерения некоторого показателя. Это могут быть как показатели (характеристики) технических систем, так и показатели природных, социальных, экономических и других систем (например, погодные данные). Типичным примером временного ряда можно назвать биржевой курс, при анализе которого пытаются определить основное направление развития (тенденцию или тренда).
Анализ временных рядов – совокупность математико-статистических методов анализа, предназначенных для выявления структуры временных рядов и для их прогнозирования. Сюда относятся, в частности, методы регрессионного анализа. Выявление структуры временного ряда необходимо для того, чтобы построить математическую модель того явления, которое является источником анализируемого временного ряда. Прогноз будущих значений временного ряда используется для эффективного принятия решений.
Прогноз, характеристики и параметры прогнозирования
Прогноз (от греч. 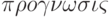 – предвидение, предсказание) – предсказание будущего с помощью научных методов, а также сам результат предсказания. Прогноз – это научная модель будущего события, явлений и т.п.
– предвидение, предсказание) – предсказание будущего с помощью научных методов, а также сам результат предсказания. Прогноз – это научная модель будущего события, явлений и т.п.
Прогнозирование, разработка прогноза; в узком значении – специальное научное исследование конкретных перспектив развития какого-либо процесса.
- по срокам: краткосрочные, среднесрочные, долгосрочные;
- по масштабу: личные, на уровне предприятия (организации), местные, региональные, отраслевые, мировые (глобальные).
К основным методам прогнозирования относятся:
- статистические методы;
- экспертные оценки (метод Дельфи);
- моделирование.
Прогноз – обоснованное суждение о возможном состоянии объекта в будущем или альтернативных путях и сроках достижения этих состояний. Прогнозирование – процесс разработки прогноза. Этап прогнозирования – часть процесса разработки прогнозов, характеризующаяся своими задачами, методами и результатами. Деление на этапы связано со спецификой построения систематизированного описания объекта прогнозирования, сбора данных, с построением модели, верификацией прогноза.
Прием прогнозирования – одна или несколько математических или логических операций, направленных на получение конкретного результата в процессе разработки прогноза. В качестве приема могут выступать сглаживание динамического ряда, определение компетентности эксперта, вычисление средневзвешенного значения оценок экспертов и т. д.
Модель прогнозирования – модель объекта прогнозирования, исследование которой позволяет получить информацию о возможных состояниях объекта прогнозирования в будущем и (или) путях и сроках их осуществления.
Метод прогнозирования – способ исследования объекта прогнозирования, направленный на разработку прогноза. Методы прогнозирования являются основанием для методик прогнозирования.
Методика прогнозирования – совокупность специальных правил и приемов (одного или нескольких методов) разработки прогнозов.
Прогнозирующая система – система методов и средств их реализации, функционирующая в соответствии с основными принципами прогнозирования. Средствами реализации являются экспертная группа, совокупность программ и т. д. Прогнозирующие системы могут быть автоматизированными и неавтоматизированными.
Прогнозный вариант – один из прогнозов, составляющих группу возможных прогнозов.
Объект прогнозирования – процесс, система, или явление, о состоянии которого даётся прогноз.
Характеристика объекта прогнозирования – качественное или количественное отражение какого-либо свойства объекта прогнозирования.
Переменная объекта прогнозирования – количественная характеристика объекта прогнозирования, которая является или принимается за изменяемую в течение периода основания и (или) периода упреждения прогноза.
Период основания прогноза – промежуток времени, за который используют информацию для разработки прогноза. Этот промежуток времени называют также периодом предыстории.
Период упреждения прогноза – промежуток времени, на который разрабатывается прогноз.
Прогнозный горизонт – максимально возможный период упреждения прогноза заданной точности.
Точность прогноза – оценка доверительного интервала прогноза для заданной вероятности его осуществления.
Достоверность прогноза – оценка вероятности осуществления прогноза для заданного доверительного интервала.
Ошибка прогноза – апостериорная величина отклонения прогноза от действительного состояния объекта.
Источник ошибки прогноза – фактор, способный привести к появлению ошибки прогноза. Различают источники регулярных и нерегулярных ошибок.
Верификация прогноза – оценка достоверности и точности или обоснованности прогноза.
Статистические методы прогнозирования – научная и учебная дисциплина, к основным задачам которой относятся разработка, изучение и применение современных математико-статистических методов прогнозирования на основе объективных данных; развитие теории и практики вероятностно-статистического моделирования экспертных методов прогнозирования; методов прогнозирования в условиях риска и комбинированных методов прогнозирования с использованием совместно экономико-математических и эконометрических (как математико-статистических, так и экспертных) моделей. Научной базой статистических методов прогнозирования является прикладная статистика и теория принятия решений.
Простейшие методы восстановления используемых для прогнозирования зависимостей исходят из заданного временного ряда, т. е. функции, определённой в конечном числе точек на оси времени. Временной ряд при этом часто рассматривается в рамках той или иной вероятностной модели, вводятся другие факторы (независимые переменные), помимо времени, например, объем денежной массы. Временной ряд может быть многомерным. Основные решаемые задачи – интерполяция и экстраполяция. Метод наименьших квадратов в простейшем случае (линейная функция от одного фактора) был разработан К. Гауссом в 1794–1795 гг. Могут оказаться полезными предварительные преобразования переменных, например, логарифмирование. Наиболее часто используется метод наименьших квадратов при нескольких факторах.
Оценивание точности прогноза (в частности, с помощью доверительных интервалов) – необходимая часть процедуры прогнозирования. Обычно используют вероятностно-статистические модели восстановления зависимости, например, строят наилучший прогноз по методу максимального правдоподобия. Разработаны параметрические (обычно на основе модели нормальных ошибок) и непараметрические оценки точности прогноза и доверительные границы для него (на основе Центральной Предельной Теоремы теории вероятностей). Применяются также эвристические приемы, не основанные на вероятностно-статистической теории: метод скользящих средних, метод экспоненциального сглаживания.
Многомерная регрессия, в том числе с использованием непараметрических оценок плотности распределения – основной на настоящий момент статистический аппарат прогнозирования. Нереалистическое предположение о нормальности погрешностей измерений и отклонений от линии (поверхности) регрессии использовать не обязательно; однако для отказа от предположения нормальности необходимо опереться на иной математический аппарат, основанный на многомерной Центральной Предельной Теореме теории вероятностей, технологии линеаризации и наследования сходимости. Он позволяет проводить точечное и интервальное оценивание параметров, проверять значимость их отличия от 0 в непараметрической постановке, строить доверительные границы для прогноза.
Уравнение тренда временного ряда
Рассматривая временной ряд как множество результатов наблюдений изучаемого процесса, проводимых последовательно во времени, в качестве основных целей исследования временных рядов можно выделить: выявление и анализ характерного изменения параметра у, оценка возможного изменения параметра в будущем (прогноз).
Значения временного ряда можно представить в виде: 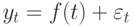 , где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем,
, где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем, 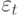 – случайная величина, характеризующая отклонение уровня от f(t ).
– случайная величина, характеризующая отклонение уровня от f(t ).
Неслучайная функция f (t) называется трендом. Тренд отражает характерное изменение (тенденцию) yt за некоторый промежуток времени. На практике в качестве тренда выбирают несколько возможных теоретических или эмпирических моделей. Могут быть выбраны, например, линейная, параболическая, логарифмическая, показательная функции. Для выявления типа модели на координатную плоскость наносят точки с координатами ( t, yt ) и по характеру расположения точек делают вывод о виде уравнения тренда. Для получения уравнения тренда применяют различные методы: сглаживание с помощью скользящей средней, метод наименьших квадратов и другие.
Уравнение тренда линейного вида будем искать в виде yt=f(t ), где f (t) = a0+a1(t ).
Пример 1. Имеется временной ряд:
| ti | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| xti | 2 | 1 | 4 | 4 | 6 | 8 | 7 | 9 | 12 | 11 |
Построим график xti во времени. Добавим на графике линию тренда исходных значений ряда. При этом, щелкнув правой кнопкой мыши по линии тренда, можно вызвать контекстное меню «Формат линии тренда», а в нем поставить флажок «показывать уравнение на диаграмме», тогда на диаграмме высветится уравнение линии тренда, вычисленное встроенными возможностями Excel .

Чтобы определить уравнение тренда, необходимо найти значения коэффициентов а0 и а1. Эти коэффициенты следует определять, исходя из условия минимального отклонения значений функции f (t) в точках ti от значений исходного временного ряда в тех же точках ti . Это условие можно записать в виде (на основе метода наименьших квадратов):
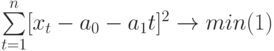
где n – количество значений временного ряда.
Для того, чтобы найти значения а0 и а1, необходимо иметь систему из двух уравнений. Эти уравнения можно получить, используя условие равенства нулю производной функции в точках её экстремума. В нашем случае эта функция имеет вид 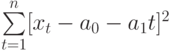 . Обозначим её через Q . Найдем производные функции Q(а0, а1) по переменным а0 и а1. Получим систему уравнений:
. Обозначим её через Q . Найдем производные функции Q(а0, а1) по переменным а0 и а1. Получим систему уравнений:
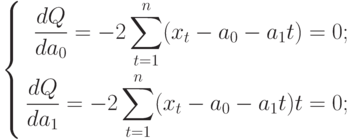
Полученная система может быть преобразована (математически) в систему так называемых нормальных уравнений. При этом уравнения примут вид:
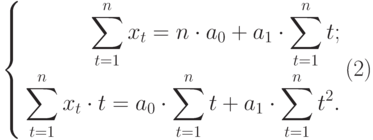
Теперь необходимо решить преобразованную систему уравнений относительно а0 и а1. Однако предварительно следует составить и заполнить вспомогательную таблицу:
| t | t 2 | хt | хtt |
|---|---|---|---|
| 1 | 1 | 2 | 2 |
| 2 | 4 | 1 | 2 |
| 3 | 9 | 4 | 12 |
| 4 | 16 | 4 | 16 |
| 5 | 25 | 6 | 30 |
| 6 | 36 | 8 | 48 |
| 7 | 49 | 7 | 49 |
| 8 | 64 | 9 | 72 |
| 9 | 81 | 12 | 108 |
| 10 | 100 | 11 | 110 |
 | 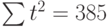 | 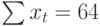 | 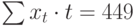 |
Подставив значения n = 10 в систему уравнений (2), получим
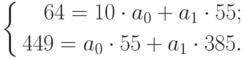
Решив систему уравнений относительно а0 и а1, получим а0 = -0,035, а1 = 1,17. Тогда функция тренда заданного временного ряда f (t) имеет вид:
f (t) = -0,035 + 1,17t.
Изобразим полученную функцию на графике.

Временной ряд приведен в таблице. Используя средства MS Excel :
- построить график временного ряда;
- добавить линию тренда и ее уравнение;
- найти уравнение тренда методом наименьших квадратов, сравнить уравнения (выше на графике и полученное);
- построить график временного ряда и полученной функции тренда в одной системе координат.
1. Реализация аспирина по аптеке (у.е.) за последние 7 недель приведена в таблице:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| хti | 3,2 | 3,3 | 2,9 | 2,2 | 1,6 | 1,5 | 1,2 |
2. Динамика потребления молочных продуктов (у.е.) по району за последние 7 месяцев:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| хti | 30 | 29 | 27 | 24 | 25 | 24 | 23 |
3. Динамика числа работников, занятых в одной из торговых сетей города за последние 8 лет приведена в таблице:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 280 | 361 | 384 | 452 | 433 | 401 | 512 | 497 |
4. Динамика потребления сульфаниламидных препаратов в клинике по годам (тыс. упаковок):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 14 | 21 | 29 | 33 | 38 | 44 | 46 | 50 |
5. Динамика продаж однокомнатных квартир в городе за последние 8 лет (тыс. ед.):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| уt | 39 | 40 | 36 | 34 | 36 | 37 | 33 | 35 |
6. Динамика потребления антибиотиков в клинике (тыс. упаковок):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 10 | 17 | 18 | 13 | 17 | 21 | 25 | 29 |
7. Динамика производства хлебобулочных изделий на хлебозаводе (тонн):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 510 | 502 | 564 | 680 | 523 | 642 | 728 | 665 |
8. Динамика потребления противовирусных препаратов по аптечной сети в начале эпидемии гриппа (тыс. единиц):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 36 | 42 | 34 | 38 | 12 | 32 | 26 | 20 |
9. Динамика потребления противовирусных препаратов по аптечной сети в конце эпидемии гриппа (тыс. единиц):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 46 | 52 | 44 | 48 | 32 | 42 | 36 | 30 |
10. Динамика потребления витаминов по аптечной сети в весенний период (с марта по апрель) в разные годы (у.е.):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 0,9 | 1,7 | 1,5 | 1,7 | 1,5 | 2,1 | 2,5 | 3,6 |
Пример 2. Используя данные примера 1, приведенного выше, вычислить точечный прогноз исходного временного ряда на 5 шагов вперед.
Исходя из условия задачи, необходимо определить точечную оценку прогноза для t = 11, 12, 13, 14, 15, где t в данном случае – шаг упреждения.
Рассмотрим решение этой задачи средствами Microsoft Excel . При решении данной задачи следует так же, как и в примере 1, ввести исходные данные. Выделив данные, построить точечный график, щелкнув правой кнопкой мыши по ряду данных, вызвать контекстное меню и выбрать «Добавить линию тренда».
Щелкнув правой кнопкой мыши по линии тренда, вызвать контекстное меню, выбрать «Формат линии тренда», в окне Параметры линии тренда указать прогноз на 5 периодов и поставить флажок в окошке «Показывать уравнение на диаграмме (рис. 14.3 рис. 14.3.). В версии Excel ранее 2007 окно диалога представлено на рисунке 14.4 рис. 14.4.


Итоговый график представлен на рисунке 14.5 рис. 14.5.

Значения прогноза для 11, 12, 13, 14 и 15 уровней получим, используя функцию ПРЕДСКАЗ( ). Данная функция позволяет получить значения прогноза линейного тренда. Вычисленные значения: 12,87, 14,04, 15,22, 16,39, 17,57.
Значения точечного прогноза для исходного временного ряда на 5 шагов вперед можно вычислить и с помощью уравнения функции тренда f(t ), найденного по методу наименьших квадратов. Для этого в полученное для f (t) выражение необходимо подставить значения t = 11, 12, 13, 14, 15. В результате получим (эти значения следует рассчитать, сформировав формулу в табличном процессоре MS Excel ):
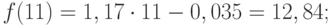
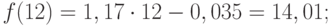
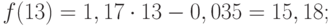
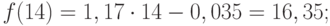
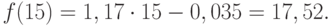
Сравнивая результаты точечных прогнозных оценок, полученных разными способами, выявляем, что данные отличаются незначительно, таким образом, в любом из способов расчета присутствует определенная погрешность (ошибка) прогноза ().
Используя значения временного ряда Задания 1 согласно вашего варианта, вычислить точечный прогноз на 4 шага вперед. Продлить линию тренда на 4 прогнозных значения, вывести уравнение тренда, определить эти значения с помощью функции ПРЕДСКАЗ() или ТЕНДЕНЦИЯ(), а также по выражению функции тренда f(t ), полученному по методу наименьших квадратов в Задании 1. Сравнить полученные результаты.
5 способов расчета значений линейного тренда в MS Excel
Добавление трендовой линии на график
Данный элемент технического анализа позволяет визуально увидеть изменение цены за указанный период времени . Это может быть месяц, год или несколько лет. Информация будет отображать значение средних показателей в виде геометрических фигур . Добавить линию тренда в Excel 2010 можно с помощью встроенных стандартных инструментов.

Построение графика
 Чтобы правильно строить трендовые линии, нужно соблюдать функциональную зависимость y=f(x) . Для получения корректного прогноза в столбец А вносится информация о временном периоде, а в столбец В — цена в указанный промежуток.
Чтобы правильно строить трендовые линии, нужно соблюдать функциональную зависимость y=f(x) . Для получения корректного прогноза в столбец А вносится информация о временном периоде, а в столбец В — цена в указанный промежуток.
 Построение графика выполняется по следующему алгоритму:
Построение графика выполняется по следующему алгоритму:
- Первым действием нужно выделить диапазон данных , например это А1:В9, затем активировать инструмент: «Вставка»-«Диаграммы»-«Точечная»-«Точечная с гладкими кривыми и маркерами».
- После открытия графика пользователю станет доступна еще одна панель управления данными , на которой нужно выбрать следующее: «Работа с диаграммами»-«Макет»-«Линия тренда»-«Линейное приближение».
- Следующим шагом требуется выполнить двойной клик по образовавшейся линии тенденции в Excel . Когда появиться вспомогательное окно, отметить птичкой опцию «показывать уравнение на диаграмме».

Важно помнить, что если на графике имеется 2 или более линий , отображающих анализ данных, то перед выполнением 3 пункта нужно будет выбрать одну из них и включить в тенденцию. Эта короткая инструкция поможет начинающим специалистам разобраться, как строится линия тренда в Экселе.
Создание линии
Дальнейшая работа будет происходить непосредственно с трендовой линией.
Добавление тренда на диаграмму происходит следующим образом:

- Перейти во вкладку «Работа с диаграммами» , затем выбрать раздел «Макет»-«Анализ» и после подпункт «Линия тенденции» . Появится выпадающий список, в котором необходимо активировать строку «Линейное приближение».
- Если все выполнено правильно, в области построения диаграмм появится кривая линия черного цвета . По желанию цветовую гамму можно будет изменить на любую другую.
Этот способ поможет создать и построить тренд в Excel 2016 или более ранних версиях.
 Однако важно помнить, что вставить линию нельзя для диаграмм и графиков следующего типа:
Однако важно помнить, что вставить линию нельзя для диаграмм и графиков следующего типа:
- лепесткового;
- кругового;
- поверхностного;
- кольцевого;
- объемного;
- с накоплением.
Настройка линии
Построение линий тренда имеет ряд вспомогательных настроек , которые помогут придать графику законченный и презентабельный вид.
Необходимо запомнить следующее: 
- Чтобы добавить название диаграмме , нужно дважды кликнуть по ней и в появившемся окне ввести заголовок. Для выбора расположения имени графика необходимо перейти во вкладку «Работа с диаграммами», затем выбрать «Макет» и «Название диаграммы». После этого появится список с возможным расположением заглавия.
- Дополнительно в этом же разделе можно найти пункт, отвечающий за названия осей и их расположение относительно графика. Интересно, что для вертикальной оси разработчики программы продумали возможность повернутого расположения наименования, чтобы диаграмма читалась удобно и выглядела гармонично.
 Чтобы внести изменения непосредственно в построение линий , нужно в разделе «Макет» найти «Анализ», затем «Прямая тренда» и в самом низу списка нажать «Дополнительные параметры…». Здесь можно изменить цвет и формат линии , выбрать один из параметров сглаживания и аппроксимации (степенный, полиноминальный, логарифмический и т.д.).
Чтобы внести изменения непосредственно в построение линий , нужно в разделе «Макет» найти «Анализ», затем «Прямая тренда» и в самом низу списка нажать «Дополнительные параметры…». Здесь можно изменить цвет и формат линии , выбрать один из параметров сглаживания и аппроксимации (степенный, полиноминальный, логарифмический и т.д.).- Еще есть функция определения достоверности построенной модели . Для этого в дополнительных настройках требуется активировать пункт «Разместить на график величину достоверности аппроксимации» и после этого закрыть окно. Наилучшим значением является 1. Чем сильнее полученный показатель отличается от нее, тем ниже достоверность модели.
 Чтобы внести изменения непосредственно в построение линий , нужно в разделе «Макет» найти «Анализ», затем «Прямая тренда» и в самом низу списка нажать «Дополнительные параметры…». Здесь можно изменить цвет и формат линии , выбрать один из параметров сглаживания и аппроксимации (степенный, полиноминальный, логарифмический и т.д.).
Чтобы внести изменения непосредственно в построение линий , нужно в разделе «Макет» найти «Анализ», затем «Прямая тренда» и в самом низу списка нажать «Дополнительные параметры…». Здесь можно изменить цвет и формат линии , выбрать один из параметров сглаживания и аппроксимации (степенный, полиноминальный, логарифмический и т.д.).Прогнозирование
Для получения наиболее точного прогноза необходимо сменить построенный график на гистограмму . Это поможет сравнить уравнения.
 Для этого выполняем последовательность действий:
Для этого выполняем последовательность действий:
- Вызвать для графика контекстное меню и выбрать «Изменить тип диаграммы» .
- Появится новое окно с настройками , в котором требуется найти опцию «Гистограмма» и после выбрать подвид с группировкой.
Теперь пользователю должны быть видны оба графика . Они визуализируют одни и те же данные, но имеют разные уравнения для образования тенденции.
Следующим шагом необходимо сравнить уравнения точки пересечения с осями на разных диаграммах .
Для визуального отображения нужно сделать следующее:

- Перевести гистограмму в простой точечный график с гладкими кривыми и маркерами . Процесс выполняется через пункт контекстного меню «Изменить тип диаграммы…».
- Выполнить двойной клик по прямой образовавшейся тенденции , задать ей параметр прогноза назад на 12,0 и сохранить изменения.
Такая настройка поможет увидеть, что угол наклона тенденции меняется в зависимости от вида графика , но общее направление движения остается неизменным. Это свидетельствует о том, что построить линию тренда в Эксель можно лишь в качестве дополнительного инструмента анализа и брать его в расчет следует только как приближающий параметр. Строить аналитические прогнозы, основываясь лишь на этой прямой, не рекомендуется.
Базовые понятия
Думаю, еще со школы все знакомы с линейной функцией, она как раз и лежит в основе тренда:
Y — это объем продаж, та переменная, которую мы будем объяснять временем и от которого она зависит, то есть Y(t);
t — номер периода (порядковый номер месяца), который объясняет план продаж Y;
a0 — это нулевой коэффициент регрессии, который показывает значение Y(t), при отсутствии влияния объясняющего фактора (t=0);
a1 — коэффициент регрессии, который показывает, на сколько исследуемый показатель продаж Y зависит от влияющего фактора t;
E — случайные возмущения, которые отражают влияния других неучтенных в модели факторов, кроме времени t.
Определение коэффициентов модели
Строим график. По горизонтали видим отложенные месяцы, по вертикали объем продаж:

В Google Sheets выбираем Редактор диаграмм -> Дополнительные и ставим галочку возле Линии тренда. В настройках выбираем Ярлык — Уравнение и Показать R^2.
Если вы делаете все в MS Excel, то правой кнопкой мыши кликаем на график и в выпадающем меню выбираем «Добавить линию тренда».
По умолчанию строится линейная функция. Справа выбираем «Показывать уравнение на диаграмме» и «Величину достоверности аппроксимации R^2».
Вот, что получилось:

На графике мы видим уравнение функции:
y = 4856*x + 105104
Она описывает объем продаж в зависимости от номера месяца, на который мы хотим эти продажи спрогнозировать. Рядом видим коэффициент детерминации R^2, который говорит о качестве модели и на сколько хорошо она описывает наши продажи (Y). Чем ближе к 1, тем лучше.
У меня R^2 = 0,75. Это средний показатель, он говорит о том, что в модели не учтены какие-то другие значимые факторы помимо времени t, например, это может быть сезонность.
Способ расчета значений линейного тренда в Excel с помощью графика
 Выделяем анализируемый объём продаж и строим график, где по оси Х — наш временной ряд (1, 2, 3… — январь, февраль, март …), по оси У – объёмы продаж. Добавляем линию тренда и уравнение тренда на график. Получаем уравнение тренда y=135134x+4594044
Выделяем анализируемый объём продаж и строим график, где по оси Х — наш временной ряд (1, 2, 3… — январь, февраль, март …), по оси У – объёмы продаж. Добавляем линию тренда и уравнение тренда на график. Получаем уравнение тренда y=135134x+4594044
Для прогнозирования нам необходимо рассчитать значения линейного тренда, как для анализируемых значений, так и для будущих периодов.
При расчете значений линейного тренде нам будут известны:
- Время – значение по оси Х;
- Значение “a” и “b” уравнения линейного тренда y(x)=a+bx;
Рассчитываем значения тренда для каждого периода времени от 1 до 25, а также для будущих периодов с 26 месяца до 36.
Например, для 26 месяца значение тренда рассчитывается по следующей схеме: в уравнение подставляем x=26 и получаем y=135134*26+4594044=8107551
27-го y=135134*27+4594044=8242686
Способ расчета значений линейного тренда в Excel — функция ТЕНДЕНЦИЯ
Рассчитаем значения линейного тренда с помощью стандартной функции Excel:
=ТЕНДЕНЦИЯ(известные значения y; известные значения x; новые значения x; конста)
Подставляем в формулу
- известные значения y – это объёмы продаж за анализируемый период (фиксируем диапазон в формуле, выделяем ссылку и нажимаем F4);
- известные значения x – это номера периодов x для известных значений объёмов продаж y;
- новые значения x – это номера периодов, для которых мы хотим рассчитать значения линейного тренда;
- константа – ставим 1, необходимо для того, чтобы значения тренда рассчитывались с учетом коэффицента (a) для линейного тренда y=a+bx;
Для того чтобы рассчитать значения тренда для всего временного диапазона, в “новые значения x” вводим диапазон значений X, выделяем диапазон ячеек равный диапазону со значениями X с формулой в первой ячейке и нажимаем клавишу F2, а затем — клавиши CTRL + SHIFT + ВВОД.
Уравнение линии тренда в Excel
В предложенном выше примере была выбрана линейная аппроксимация только для иллюстрации алгоритма. Как показала величина достоверности, выбор был не совсем удачным.
Следует выбирать тот тип отображения, который наиболее точно проиллюстрирует тенденцию изменений вводимых пользователем данных. Разберемся с вариантами.
Линейная аппроксимация
Ее геометрическое изображение – прямая. Следовательно, линейная аппроксимация применяется для иллюстрации показателя, который растет или уменьшается с постоянной скоростью.
Рассмотрим условное количество заключенных менеджером контрактов на протяжении 10 месяцев:

На основании данных в таблице Excel построим точечную диаграмму (она поможет проиллюстрировать линейный тип):

Выделяем диаграмму – «добавить линию тренда». В параметрах выбираем линейный тип. Добавляем величину достоверности аппроксимации и уравнение линии тренда в Excel (достаточно просто поставить галочки внизу окна «Параметры»).


Обратите внимание! При линейном типе аппроксимации точки данных расположены максимально близко к прямой. Данный вид использует следующее уравнение:
y = 4,503x + 6,1333
- где 4,503 – показатель наклона;
- 6,1333 – смещения;
- y – последовательность значений,
- х – номер периода.
Прямая линия на графике отображает стабильный рост качества работы менеджера. Величина достоверности аппроксимации равняется 0,9929, что указывает на хорошее совпадение расчетной прямой с исходными данными. Прогнозы должны получиться точными.
Чтобы спрогнозировать количество заключенных контрактов, например, в 11 периоде, нужно подставить в уравнение число 11 вместо х. В ходе расчетов узнаем, что в 11 периоде этот менеджер заключит 55-56 контрактов.
Экспоненциальная линия тренда
Данный тип будет полезен, если вводимые значения меняются с непрерывно возрастающей скоростью. Экспоненциальная аппроксимация не применяется при наличии нулевых или отрицательных характеристик.
Построим экспоненциальную линию тренда в Excel. Возьмем для примера условные значения полезного отпуска электроэнергии в регионе Х:

Строим график. Добавляем экспоненциальную линию.

Уравнение имеет следующий вид:
- где 7,6403 и -0,084 – константы;
- е – основание натурального логарифма.
Показатель величины достоверности аппроксимации составил 0,938 – кривая соответствует данным, ошибка минимальна, прогнозы будут точными.
Логарифмическая линия тренда в Excel
Используется при следующих изменениях показателя: сначала быстрый рост или убывание, потом – относительная стабильность. Оптимизированная кривая хорошо адаптируется к подобному «поведению» величины. Логарифмический тренд подходит для прогнозирования продаж нового товара, который только вводится на рынок.
На начальном этапе задача производителя – увеличение клиентской базы. Когда у товара будет свой покупатель, его нужно удержать, обслужить.
Построим график и добавим логарифмическую линию тренда для прогноза продаж условного продукта:

R2 близок по значению к 1 (0,9633), что указывает на минимальную ошибку аппроксимации. Спрогнозируем объемы продаж в последующие периоды. Для этого нужно в уравнение вместо х подставлять номер периода.
| Период | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Прогноз | 1005,4 | 1024,18 | 1041,74 | 1058,24 | 1073,8 | 1088,51 | 1102,47 |
Для расчета прогнозных цифр использовалась формула вида: =272,14*LN(B18)+287,21. Где В18 – номер периода.
Общая информация
Линия тренда – это инструмент статистического анализа, который позволяет спрогнозировать дальнейшее развитие событий. Чтобы построить кривую, необходимо иметь массив данных, который отображает изменение величины во времени. На основании этой информации строится график, а затем применятся специализированная функция. Рассмотрим изменение цены золота за грамм в долларах с 2015 по 2019 год.
- Составляете небольшую таблицу.

- На основании этих данных строите линейный график. Для этого переходите во вкладку Вставка на Панели инструментов и выбираете нужный тип диаграммы.

- Получается некоторая кривая.

- Необходимо отредактировать график при помощи стандартных инструментов, которые находятся во вкладках Конструктор, Макет и Формат. Переименовываете диаграмму, выставляете пределы по вертикальной оси, чтобы изменения величины были более явными, подписываете оси, добавляете контрольные точки, а также подпись данных. После этого проводите окончательное форматирование.

- Чтобы добавить линию тренда, необходимо во вкладке Макет нажать одноименную кнопку и выбрать нужный тип приближения.

На заметку! Если линия тренда не активна, то используется не тот тип диаграммы. Данная функция работает только с диаграммами типа гистограмма, график, линейчатая и точечная.
6. Так выглядит линия тренда на графике.

На заметку! Построение линии приближения идентично для редакторов 2007, 2010 и 2016 годов выпуска.
Возможности инструмента
Рассмотрим подробнее настройки функции. Для перехода в окно параметров из выпадающего списка нужно выбрать последнюю строчку.

Окно содержит четыре настройки, в которые входят цвет, объем и тип линии, а также параметры самого инструмента.

Параметры линии тренда можно условно поделить на четыре блока:
- Тип приближения.
- Название полученной кривой, которое формируется автоматически или может быть задано пользователем.
- Блок прогнозирования, который позволяет продлить линию тренда на заданное количество периодов вперед или назад, на основании имеющихся данных. Что позволяет оценить дальнейшее изменение исследуемой величины.
- Дополнительные опции, которые отражают математическую составляющую кривой. Самой интересной и полезной строчкой здесь является величина достоверности. Если значение коэффициента близко к единице, то ошибка минимальна и дальнейший прогноз будет достаточно точным.

Выведем на исходный график уравнение линии и коэффициент достоверности.

Как видите, значение близко к 0,5, это говорит о низкой достоверности полученной линии тренда, и дальнейший прогноз будет ошибочным.
Разновидности
1 Линейная аппроксимация отлично подойдет для исследования величины, которая стабильно растет или убывает. Тогда кривая будет иметь вид прямой. Формула будет содержать одну переменную. Коэффициент достоверности близок к единице, что говорит о высокой точности совпадения прямой и массива данных. На основании такой линии тренда прогноз будет достаточно точным.

2. Экспоненциальная кривая используется только для массивов с положительными значениями, которые изменяются непрерывно.

3. Логарифмическую линию тренда целесообразнее использовать, если на первоначальном этапе наблюдается резкое увеличение или снижение показателя, а потом наступает период стабильности. Здесь формула содержит логарифм натуральный.

4. Полиномиальная аппроксимация применяется при большом количестве неоднородных данных. В основе лежит степенное уравнение, при этом количество степеней зависит от числа максимумов. Применим этот тип для первоначального примера с золотом.

Уравнение показывает переменные до третьей степени, поскольку график имеет два пика. Также видим, что коэффициент достоверности близок к единице (вместо 0,5 при линейной аппроксимации), значит линия тренда выбрана правильно и дальнейший прогноз будет точным.
Как видите, для статистического анализа данных необходимо правильно выбрать тип математического уравнения, которое максимально точно будет соответствовать характеру изменения величины. На основании полученных кривых можно осуществлять прогноз, подставляя в уравнение необходимое число.
Разбираемся с трендами в MS Excel
Большой ошибкой со стороны владельца сайта будет воспринимать диаграмму как есть. Да, невооруженным взглядом видно, что синий и оранжевый столбики «осени» выросли по сравнению с «весной» и тем более «летом». Однако важны не только цифры и величина столбиков, но и зависимость между ними. То есть в идеале, при общем росте, «оранжевые» столбики просмотров должны расти намного сильнее «синих», что означало бы то, что сайт не только привлекает больше читателей, но и становится больше и интереснее.
Что же мы видим на графике? Оранжевые столбики «осени» как минимум ни чем не больше «весенних», а то и меньше. Это свидетельствует не об успехе, а скорее наоборот — посетители прибывают, но читают в среднем меньше и на сайте не задерживаются!
Самое время бить тревогу и… знакомится с такой штукой как линия тренда .
Зачем нужна линия тренда
Линия тренда «по-простому», это непрерывная линия составленная на основе усредненных на основе специальных алгоритмов значений из которых строится наша диаграмма. Иными словами, если наши данные «прыгают» за три отчетных точки с «-5» на «0», а следом на «+5», в итоге мы получим почти ровную линию: «плюсы» ситуации очевидно уравновешивают «минусы».
Исходя из направления линии тренда гораздо проще увидеть реальное положение дел и видеть те самые тенденции, а следовательно — строить прогнозы на будущее. Ну а теперь, за дело!
Как построить линию тренда в MS Excel

Щелкните правой кнопкой мыши по одному из «синих» столбцов, и в контекстном меню выберите пункт «Добавить линию тренда» .
На листе диаграммы теперь отображается пунктирная линия тренда. Как видите, она не совпадает на 100% со значениями диаграммы — построенная по средневзвешенным значениям, она лишь в общих чертах повторяет её направление. Однако это не мешает нам видеть устойчивый рост числа посещений сайта — на общем результате не сказывается даже «летняя» просадка.

Линия тренда для столбца «Посетители»
Теперь повторим тот же фокус с «оранжевыми» столбцами и построим вторую линию тренда. Как я и говорил раньше: здесь ситуация не так хороша. Тренд явно показывает, что за расчетный период число просмотров не только не увеличилось, но даже начало падать — медленно, но неуклонно.

Ещё одна линия тренда позволяет прояснить ситуацию
Мысленно продолжив линию тренда на будущие месяцы, мы придем к неутешительному выводу — число заинтересованных посетителей продолжит снижаться. Так как пользователи здесь не задерживаются, падение интереса сайта в ближайшем будущем неизбежно вызовет и падение посещаемости.
Следовательно, владельцу проекта нужно срочно вспоминать чего он такого натворил летом («весной» все было вполне нормально, судя по графику), и срочно принимать меры по исправлению ситуации.
С какой целью используется уравнение тренда. Построение линейного тренда

23.Расчет параметров линейного тренда.
Основной тенденцией развития (трендом) называется плавное и устойчивое изменение уровня явления во времени, свободное от случайных колебаний.
Задача состоит в том, чтобы выявить общую тенденцию в изменении уровней ряда, освобожденную от действия различных случайных факторов. С этой целью ряды динамики подвергаются обработке методами укрупнения интервалов, скользящей средней и аналитического выравнивания.
*Одним из наиболее простых методов изучения основной тенденции в рядах динамики является укрупнение интервалов. Он основан на укрупнении периодов времени, к которым относятся уровни ряда динамики (одновременно уменьшается количество интервалов). Например, ряд ежесуточного выпуска продукции заменяется рядом месячного выпуска продукции и т.д. Средняя, исчисленная по укрупненным^ интервалам, позволяет выявлять направление и характер (ускорение или замедление роста) основной тенденции развития.
* Выявление основной тенденции может осуществляться также методом скользящи (подвижной) средней. Сущность его заключается в том, что исчисляется средний уровень из определенного числа, обычно нечетного (3, 5, 7 и т.д.), первыхтю счету уровней ряда, затем — из такого же числа уровней, но начиная со второго по счету, далее — начиная с третьего и т.д. Таким образом, средняя как бы «скользит» по ряду динамики, передвигаясь на один срок.
на два члена в начале и конце ряда. Он меньше, чем фактический подвержен колебаниям из-за случайных причин, и четче, в виде некоторой плавной линии на графике, выражает основную тенденцию роста урожайности за изучаемый период, связанную с действием долговременно существующих причин и условий развития.
Недостатком сглаживания ряда является «укорачивание» сглаженного ряда по сравнению с фактическим, а следовательно, потеря информации.
Рассмотренные приемы сглаживания динамических рядов (укрупнение интервалов и метод скользящей средней) дают возможность определить лишь общую тенденцию развития явления, более или менее освобожденную от случайных и волнообразных колебаний. Однако получить обобщенную статистическую модель тренда посредством этих методов нельзя.
*Для того чтобы дать количественную модель, выражающую основную тенденцию изменения уровней динамического ряда во времени, используется аналитическое выравнивание ряда динамики.
где yt — уровни динамического ряда, вычисленные по соответствующему аналитическому уравнению на момент времени t.
Определение теоретических (расчетных) уровней yt производится на основе так называемой адекватной математической модели, которая наилучшим образом отображает (аппроксимирует) основную тенденцию ряда динамики. Выбор типа модели зависит от цели исследования и должен быть основан на теоретическом анализе, выявляющем характер развития явления, а также на графическом изображении ряда динамики (линейной диаграмме).
Например, простейшими моделями (формулами), выражающими тенденцию развития, являются:
линейная функция — прямая yt = a0 + a1t,
где a0,a1 — параметры уравнения; t — время;
показательная функция yt = A0A1t
степенная функция — кривая второго порядка (парабола)
В тех случаях, когда требуется особо точное изучение тенденции развития (например, модели тренда для прогнозирования), при выборе вида адекватной функции можно использовать специальные критерии математической статистики.
Расчет параметров функции обычно производится методом наименьших квадратов, в котором в качестве решения принимается точка минимума суммы квадратов отклонений между теоретическими и эмпиричесими уровнями:
где yt — выравненные (расчетные) уровни; yt — фактические уровни.
Параметры уравнения а,-, удовлетворяющие этому условию, могут быть найдены решением системы нормальных уравнений. На основе найденного уравнения тренда вычисляются выравненные уровни. Таким образом, выравнивание ряда динамики заключается в замене фактических уровней у,- плавно изменяющимися уровнями У(, наилучшим образом аппроксимирующилми статистические данные.
Выравнивание по прямой используется, как правило, в тех случаях, когда абсолютные приросты практически постоянны, т. е. когда уровни изменяются в арифметической прогрессии (или близко к ней).
Выравнивание по показательной функции используется в тех случаях, когда ряд отражает развитие в геометрической прогрессии, т. е. когда цепные коэффициенты роста практически постоянны.
Рассмотрим «технику» выравнивания ряда динамики по прямой: yt=a0+a1t
Параметры а0, а1 согласно методу наименьших квадратов находятся решением следующей системы нормальных уравнений, полученной путем алгебраического преобразования условия
где у — фактические (эмпирические) уровни ряда; t — время (порядковый номеа периода или момента времени).

Покажем пример подробного расчета параметров уравнения тренда на основе следующих данных (см. таблицу) с использованием калькулятора .
Линейное уравнение тренда имеет вид y = at + b.
1. Находим параметры уравнения методом наименьших квадратов .
Система уравнений МНК:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y | y(t) | (y-y cp) 2 | (y-y(t)) 2 | (t-t p) 2 | (y-y(t)) : y |
| 1 | 17.4 | 1 | 302.76 | 17.4 | 12.26 | 895.01 | 26.47 | 30.25 | 0.3 |
| 2 | 26.9 | 4 | 723.61 | 53.8 | 18.63 | 416.84 | 68.39 | 20.25 | 0.31 |
| 3 | 23 | 9 | 529 | 69 | 25 | 591.3 | 4.02 | 12.25 | 0.0872 |
| 4 | 23.7 | 16 | 561.69 | 94.8 | 31.38 | 557.75 | 58.98 | 6.25 | 0.32 |
| 5 | 27.2 | 25 | 739.84 | 136 | 37.75 | 404.68 | 111.4 | 2.25 | 0.39 |
| 6 | 34.5 | 36 | 1190.25 | 207 | 44.13 | 164.27 | 92.72 | 0.25 | 0.28 |
| 7 | 50.7 | 49 | 2570.49 | 354.9 | 50.5 | 11.45 | 0.0383 | 0.25 | 0.0039 |
| 8 | 61.4 | 64 | 3769.96 | 491.2 | 56.88 | 198.34 | 20.44 | 2.25 | 0.0736 |
| 9 | 69.3 | 81 | 4802.49 | 623.7 | 63.25 | 483.27 | 36.56 | 6.25 | 0.0872 |
| 10 | 94.4 | 100 | 8911.36 | 944 | 69.63 | 2216.84 | 613.62 | 12.25 | 0.26 |
| 11 | 61.1 | 121 | 3733.21 | 672.1 | 76 | 189.98 | 222.11 | 20.25 | 0.24 |
| 12 | 78.2 | 144 | 6115.24 | 938.4 | 82.38 | 953.78 | 17.46 | 30.25 | 0.0534 |
| 78 | 567.8 | 650 | 33949.9 | 4602.3 | 567.8 | 7083.5 | 1272.21 | 143 | 2.41 |
Для наших данных система уравнений имеет вид:
12a 0 + 78a 1 = 567.8
78a 0 + 650a 1 = 4602.3
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = 6.37, a 1 = 5.88
Примечание: значения столбца №6 y(t) рассчитываются на основе полученного уравнения тренда. Например, t = 1: y(1) = 6.37*1 + 5.88 = 12.26
Уравнение тренда
Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.

Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве тренда.
Средние значения: 
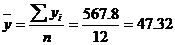

Дисперсия 

Коэффициент эластичности меньше 1. Следовательно, при изменении Х на 1%, Y изменится менее чем на 1%. Другими словами — влияние Х на Y не существенно.
Коэффициент детерминации 
т.е. в 82.04 % случаев влияет на изменение данных. Другими словами — точность подбора уравнения тренда — высокая
2. Анализ точности определения оценок параметров уравнения тренда .
Дисперсия ошибки уравнения.
где m = 1 — количество влияющих факторов в модели тренда.
Стандартная ошибка уравнения.
3. Проверка гипотез относительно коэффициентов линейного уравнения тренда .
1) t-статистика. Критерий Стьюдента.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (10;0.025) = 2.228
>
Статистическая значимость коэффициента a 0 подтверждается. Оценка параметра a 0 является значимой и тренд у временного ряда существует..
Статистическая значимость коэффициента a 1 не подтверждается.
Доверительный интервал для коэффициентов уравнения тренда .
Определим доверительные интервалы коэффициентов тренда, которые с надежность 95% будут следующими:
(a 1 — t набл S a 1 ;a 1 + t набл S a 1)
(6.375 — 2.228*0.943; 6.375 + 2.228*0.943)
(4.27;8.48)
(a 0 — t набл S a 0 ;a 0 + t набл S a 0)
(5.88 — 2.228*6.942; 5.88 + 2.228*6.942)
(-9.59;21.35)
Так как точка 0 (ноль) лежит внутри доверительного интервала, то интервальная оценка коэффициента a 0 статистически незначима.
2) F-статистика. Критерий Фишера. 
Fkp = 4.84
Поскольку F > Fkp, то коэффициент детерминации статистически значим
Проверка на наличие автокорреляции остатков .
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция) определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция , нежели отрицательная автокорреляция . В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию , можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности : выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения e i с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения e i (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости e i от e i-1
Критерий Дарбина-Уотсона .
Этот критерий является наиболее известным для обнаружения автокорреляции.
При статистическом анализе уравнения регрессии на начальном этапе часто проверяют выполнимость одной предпосылки: условия статистической независимости отклонений между собой. При этом проверяется некоррелированность соседних величин e i .
| y | y(x) | e i = y-y(x) | e 2 | (e i — e i-1) 2 |
| 17.4 | 12.26 | 5.14 | 26.47 | 0 |
| 26.9 | 18.63 | 8.27 | 68.39 | 9.77 |
| 23 | 25 | -2 | 4.02 | 105.57 |
| 23.7 | 31.38 | -7.68 | 58.98 | 32.2 |
| 27.2 | 37.75 | -10.55 | 111.4 | 8.26 |
| 34.5 | 44.13 | -9.63 | 92.72 | 0.86 |
| 50.7 | 50.5 | 0.2 | 0.0384 | 96.53 |
| 61.4 | 56.88 | 4.52 | 20.44 | 18.71 |
| 69.3 | 63.25 | 6.05 | 36.56 | 2.33 |
| 94.4 | 69.63 | 24.77 | 613.62 | 350.63 |
| 61.1 | 76 | -14.9 | 222.11 | 1574.09 |
| 78.2 | 82.38 | -4.18 | 17.46 | 115.03 |
| 1272.21 | 2313.98 |
Для анализа коррелированности отклонений используют статистику Дарбина-Уотсона : 

Критические значения d 1 и d 2 определяются на основе специальных таблиц для требуемого уровня значимости α, числа наблюдений n = 12 и количества объясняющих переменных m=1.
Автокорреляция отсутствует, если выполняется следующее условие:
d 1 0.45, то гипотеза об отсутствии гетероскедастичности принимается.
Наиболее часто тренд представляется линейной зависимостью исследуемой величины вида
где y – исследуемая переменная (например, производительность) или зависимая переменная;
x – число, определяющее позицию (второй, третий и т.д.) года в периоде прогнозирования или независимая переменная.
При линейной аппроксимации связи между двумя параметрами для нахождения эмпирических коэффициентов линейной функции используется наиболее часто метод наименьших квадратов. Суть метода состоит в том, что линейная функция «наилучшего соответствия» проходит через точки графика, соответствующие минимуму суммы квадратов отклонений измеряемого параметра. Такое условие имеет вид:

где n – объем исследуемой совокупности (число единиц наблюдений).

Рис. 5.3. Построение тренда методом наименьших квадратов
Значения констант b и a или коэффициента при переменной Х и свободного члена уравнения определяются по формуле:

В табл. 5.1 приведен пример вычисления линейного тренда по данным .
Таблица 5.1. Вычисление линейного тренда

Методы сглаживания колебаний.
При сильных расхождениях между соседними значениями тренд, полученный методом регрессии, трудно поддается анализу. При прогнозировании, когда ряд содержит данные с большим разбросом колебаний соседних значений, следует их сгладить по определенным правилам, а потом искать смысл в прогнозе. К методу сглаживания колебаний
относят: метод скользящих средних (рассчитывается n-точечное среднее), метод экспоненциального сглаживания. Рассмотрим их.
Метод «скользящих средних» (МСС).
МСС позволяет сгладить ряд значений с тем, чтобы выделить тренд. При использовании этого метода берется среднее (обычно среднеарифметическое) фиксированного числа значений. Например, трехточечное скользящее среднее. Берется первая тройка значений, составленная из данных за январь, февраль и март (10 + 12 + 13), и определяется среднее, равное 35: 3 = 11,67.
Полученное значение 11,67 ставится в центре диапазона, т.е. по строке февраля. Затем «скользим на один месяц» и берется вторая тройка чисел, начиная с февраля по апрель (12 + 13 + 16), и рассчитывается среднее, равное 41: 3 = 13,67, и таким приемом обрабатываем данные по всему ряду. Полученные средние представляют новый ряд данных для построения тренда и его аппроксимации. Чем больше берется точек для вычисления скользящей средней, тем сильнее происходит сглаживание колебаний. Пример из МВА построения тренда дан в табл. 5.2 и на рис. 5.4.
Таблица 5.2 Расчет тренда методом трехточечного скользящего среднего

Характер колебаний исходных данных и данных, полученных методом скользящего среднего, иллюстрирован на рис. 5.4. Из сравнения графиков рядов исходных значений (ряд 3) и трехточечных скользящих средних (ряд 4), видно, что колебания удается сгладить. Чем большее число точек будет вовлекаться в диапазон вычисления скользящей средней, тем нагляднее будет вырисовываться тренд (ряд 1). Но процедура укрупнения диапазона приводит к сокращению числа конечных значений и это снижает точность прогноза.
Прогнозы следует делать исходя из оценок линии регрессии, составленной по значениям исходных данных или скользящих средних.

Рис. 5.4. Характер изменения объема продаж по месяцам года:
исходные данные (ряд 3); скользящие средние (ряд 4); экспоненциальное сглаживание (ряд 2); тренд, построенный методом регрессии (ряд 1)
Метод экспоненциального сглаживания.
Альтернативный подход к сокращению разброса значений ряда состоит в использовании метода экспоненциального сглаживания. Метод получил название «экспоненциальное сглаживание» в связи с тем, что каждое значение периодов, уходящих в прошлое, уменьшается на множитель (1 – α).
Каждое сглаженное значение рассчитывается по формуле вида:
где St – текущее сглаженное значение;
Yt – текущее значение временного ряда; St – 1 – предыдущее сглаженное значение; α – сглаживающая константа, 0 ≤ α ≤ 1.
Чем меньше значение константы α , тем менее оно чувствительно к изменениям тренда в данном временном ряду.
Линейный тренд выражает собой функцию: y=ax+b, гдеa – значение, на которое будет увеличено следующее значение во временном ряду;x – номер периода в определенном временном ряду (к примеру, номер месяца, дня или квартала);y – последовательность анализируемых значений (это могут быть продажи за месяц);b – точка пересечения, которая на графике будет с осью y (минимальный уровень).При этом, если значение a является больше нуля, то роста будет положительной. В свою очередь, если а меньше нуля, то динамика линейного тренда будет отрицательной.
Используйте линейный тренд для прогнозирования отдельных временных рядов, у которых данные увеличиваются или снижаются с постоянной скоростью. При построении линейного тренда можете использовать программу Excel. Например, если вам необходим линейный тренд для построения прогноза продаж по месяцам, тогда сделайте 2 переменных во временном ряду (время — месяцы и объем продаж).
Уравнение линейного тренда у вас будет же: y=ax+b, где y — объемы продаж, x — это месяцы.Постройте график в Excel. По оси x у вас получится ваш временной промежуток (1, 2, 3 — по месяцам: январь, февраль и т.д.), по оси y изменения объема продаж. После этого добавьте на графике линию тренда .
Продлите линию тренда для прогнозирования и определите ее значения. При этом вам должны быть известны только значения времени по оси X, а прогнозные значения вам необходимо рассчитать с помощью ранее указанной формулы.
Сопоставьте полученные прогнозные значения линейного тренда с фактическими данными. Таким образом вы сможете определить рост объема продаж в процентном соотношении.
Можете скорректировать прогнозируемые значения линейного тренда в том случае, если вас не устраивает рост, т.е. вы понимаете, что есть компоненты, которые на него могут повлиять. Если вы измените значение «a» в линейном тренде y=ax+b, тогда вы сможете увеличить наклон тренда . Так вы можете изменять наклон тренда , уровень тренда , или одновременно эти два показателя.
- уравнение линейного тренда
Числовая последовательность представлена функцией вида an=f(n), которая задана на множестве натуральных чисел. В большинстве случаев в числовых последовательностях f(n) заменяется на an. Числа a1, a2, …, an – члены последовательности, причем a1 – первый, a2 – второй, аk – k-ый. На основании данных функции числовой последовательности строится график.
- — справочник по математике;
- — линейка;
- — тетрадь;
- — простой карандаш;
- — исходные данные.
Прежде чем приступать к построению , определите, функцией является числовая последовательность. Различают невозрастающую или неубывающую последовательность (an), для которой при любом значении n справедливым является неравенство вида: an≥an+1 или an≤an+1. При условии, что an>an+1 или an
При построении числовой последовательности обратите внимание на то, что последовательность (an) может быть ограничена снизу или сверху: для этого должно существовать
Приняв в качестве гипотетической функции теоретических уровней прямую , определим параметры последней:


Решение этой системы можно осуществить по формулам:
Отсюда искомое уравнение тренда:  . Подставляя в полученное уравнении значения 1, 2, 3, 4, 5, определяем теоретические уровни ряда (см. предпоследнюю графу табл. 4.3). Сравнивая значения эмпирических и теоретических уровней, видим, что они близки, т.е. можно сказать, что найденное уравнение весьма удачно характеризует основную тенденцию изменения уровней именно как линейную функцию.
. Подставляя в полученное уравнении значения 1, 2, 3, 4, 5, определяем теоретические уровни ряда (см. предпоследнюю графу табл. 4.3). Сравнивая значения эмпирических и теоретических уровней, видим, что они близки, т.е. можно сказать, что найденное уравнение весьма удачно характеризует основную тенденцию изменения уровней именно как линейную функцию.
Система нормальных уравнений упрощается, если отсчет времени ведется от середины ряда. Например, при нечетном числе уровней серединная точка (год, месяц) принимается за нуль. Тогда предшествующие периоды обозначаются соответственно -1, -2, -3 и т.д., а следующие за средним – соответственно +1, +2, +3 и т.д. При четном числе уровней два срединных момента (периода) времени обозначают −1 и +1, а все последующие и предыдущие, соответственно, через два интервала:  и т.д.
и т.д.
При таком порядке отсчета времени (от середины ряда) , система нормальных уравнений упрощается до следующих двух уравнений, каждое из которых решается самостоятельно:

Важное значение при построении модели временного ряда имеет учет сезонных и циклических колебаний. Простейшим подходом, позволяющим учесть в модели сезонные и циклические колебания, является расчет значений сезонной/циклической компоненты и построение аддитивной и мультипликативной модели временного ряда.
Общий вид аддитивной модели следующий: Y=T+S+E . Эта модель предполагает, что каждый уровень временного уровня ряда может быть представлен как сумма трендовой T , сезонной S и случайной компонент. Общий вид мультипликативной модели выглядит как: Y=T∙S∙E .
Выбор одной из двух моделей проводится на основе анализа структуры сезонных колебаний. Если амплитуда колебаний приблизительно постоянна, строят аддитивную модель временного ряда, в которой значения сезонной компоненты предполагаются постоянными для различных циклов. Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
Построение аддитивной и мультипликативной моделей сводится к расчету T, S, E для каждого уровня ряда. Этапы построения модели включают в себя следующие шаги:
1. Выравнивание исходного ряда методом скользящей средней
2. Расчет значений сезонной компоненты S .
3. Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных в аддитивной (T+E) или мультипликативной (T∙E) модели.
4. Аналитическое выравнивание уровней (T+E) или (T∙E) и расчет значений T с использованием полученного уравнения тренда.
5. Расчет полученных по модели значений (T+E) или (T∙E) .
6. Расчет абсолютных и/или относительных ошибок. Если полученные значения не содержат автокорреляции, ими можно заменить исходные уровни ряда и в дальнейшем использовать временной ряд ошибок E для анализа взаимосвязи исходного ряда и других временных рядов.
Рассмотрим другие методы анализа взаимосвязи, предположив что изучаемые временные ряды не содержат периодических колебаний. Допустим, что изучается зависимость между рядами х и у . Для количественной характеристики этой зависимости используется линейный коэффициент корреляции. Если рассматриваемые временные ряды имеют тенденцию, коэффициент корреляции по абсолютной величине будет высоким. Однако это не говорит о том, что х причина у . Высокий коэффициент корреляции в данном случае – это результат того, что х и у зависят от времени, или содержат тенденцию. При этом одинаковую или противоположную тенденцию могут иметь ряды, совершенно не связанные друг с другом причинно-следственной зависимостью. Например, коэффициент корреляции между численностью выпускников вузов и числом домов отдыха в РФ в период с 1970-1990 г. составил 0,8. Однако, это не говорит о том, что количество домов отдыха способствует росту числа выпускников или наоборот.
Для того чтобы получить коэффициенты корреляции, характеризующие причинно-следственную связь между изучаемыми рядами, следует избавиться от так называемой ложной корреляции, вызванной наличием тенденции в каждом ряду, которую устраняют одним из методов.
Предположим, что по двум временным рядам х t и у t строится уравнение парной регрессии линейной регрессии вида:  . наличие тенденции в каждом из этих временных рядов означает, что на зависимую у t и независимую х t переменные модели оказывает воздействие фактор времени, который непосредственно в модели не учтен. Влияние фактора времени будет выражено в корреляционной зависимости между значениями остатков за текущий и предыдущие моменты времени, которая получила название автокорреляции в остатках.
. наличие тенденции в каждом из этих временных рядов означает, что на зависимую у t и независимую х t переменные модели оказывает воздействие фактор времени, который непосредственно в модели не учтен. Влияние фактора времени будет выражено в корреляционной зависимости между значениями остатков за текущий и предыдущие моменты времени, которая получила название автокорреляции в остатках.
Автокорреляция в остатках – это нарушение одной из основных предпосылок МНК – предпосылки о случайности остатков, полученных по уравнению регрессии. Один из возможных путей решения этой проблемы состоит в применении обобщенного МНК.
Для устранения тенденции используются две группы методов:
Методы, основанные на преобразовании уровней исходного ряда в новые переменные, не содержащие тенденции (метод последовательных разностей и метод отклонения от трендов);
Методы, основанные на изучении взаимосвязи исходных уровней временных рядов при элиминировании воздействия фактора времени на зависимую и независимую переменные модели (включение в модель регрессии по временным рядам фактора времени).
Пусть имеются два временных ряда и , каждый из которых содержит трендовую компоненту Т и случайную составляющую . Аналитическое выравнивание каждого из этих рядов позволяет найти параметры соответствующих уравнений трендов и определить расчетные по тренду уровни и соответственное. Эти расчетные значения можно принять за оценку трендовой компоненты Т каждого ряда. Поэтому влияние тенденции можно устранить путем вычитания расчетных значений уровней ряда из фактических. Эту процедуру проделывают для каждого временного ряда в модели. Дальнейший анализ взаимосвязи рядов проводят с использованием не исходных уровней, а отклонений от тренда и . Именно в этом и заключается метод отклонений от тренда.
В ряде случаев вместо аналитического выравнивания временного ряда с целью устранения тенденции можно применить более простой метод – метод последовательных разностей. Если временной ряд содержит ярко выраженную линейную тенденцию, ее можно устранить путем замены исходных уровней ряда цепными абсолютными приростами (первыми разностями).
Коэффициент b – константа, которая не зависит от времени. При наличии сильной линейной тенденции отставки достаточно малы и в соответствии с предпосылками МНК носят случайный характер. Поэтому первые разности уровней ряда не зависят от переменной времени, их можно использовать для дальнейшего анализа.
Если временной ряд содержит тенденцию в форме параболы второго порядка, то для ее устранения можно заменить исходные уровни ряда на вторые разности: .
Если тенденции временного ряда соответствует экспоненциальной, или степенной, тренд, метод последовательных разностей следует применять не к исходным уровням ряда, а к их логарифмам.
Модель вида:  также относится к группе моделей, включающих фактор времени. Преимущество данной модели перед методами отклонений от трендов и последовательных разностей состоит в том, что она позволяет учесть всю информацию, содержащуюся в исходных данных, поскольку значения и – это уровни исходных временных рядов. Кроме того, модель строится по всей совокупности данных за рассматриваемый период в отличие от метода последовательных разностей, который приводит к потере числа наблюдений. Параметры этой модели определяются обычным МНК.
также относится к группе моделей, включающих фактор времени. Преимущество данной модели перед методами отклонений от трендов и последовательных разностей состоит в том, что она позволяет учесть всю информацию, содержащуюся в исходных данных, поскольку значения и – это уровни исходных временных рядов. Кроме того, модель строится по всей совокупности данных за рассматриваемый период в отличие от метода последовательных разностей, который приводит к потере числа наблюдений. Параметры этой модели определяются обычным МНК.
Пример. Построим уравнение тренда по исходным данным таблицы 4.4.
Расходы на конечное потребление и совокупный доход (усл. ед.)
Система нормальных уравнений имеет вид:

По исходным данным рассчитаем необходимые величины и подставим в систему:

Уравнение регрессии имеет вид: .
Интерпретация параметров уравнения следующая: характеризует, что при увеличении совокупного дохода на 1 д.е. расходы на конечное потребление возрастут в среднем на 0,49 д.е в условиях существования неизменной тенденции. Параметр означает, что воздействие всех факторов, кроме совокупного дохода, на расходы на конечное потребление приведет к его среднегодовому абсолютному приросту на 0,63 д.е.
Рассмотрим уравнение регрессии вида:  . Для каждого момента времени значение компоненты определяются как или . Рассматривая последовательность остатков как временной ряд, можно построить график их зависимости от времени. В соответствии с предпосылками МНК остатки должны быть случайными (рис. 4.4).
. Для каждого момента времени значение компоненты определяются как или . Рассматривая последовательность остатков как временной ряд, можно построить график их зависимости от времени. В соответствии с предпосылками МНК остатки должны быть случайными (рис. 4.4).
Рис. 4.4 Случайные остатки
Однако при моделировании временных рядов нередко встречаются ситуации, когда остатки содержат тенденцию или циклические колебания (рис. 4.5). Это говорит о том, что каждое следующее значение остатков зависит от предшествующих. В этом случае говорят о наличии автокорреляции в остатках.
Рис. 4.5 Убывающая тенденция (а ) и циклические колебания (б )
Автокорреляция случайной составляющей — корреляционная зависимость текущих и предыдущих значений случайной составляющей. Последствия автокорреляции случайной составляющей:
Коэффициенты регрессии становятся неэффективными;
Стандартные ошибки коэффициентов регрессии становятся заниженными, а значения t –критерия завышенными.
Для определения автокорреляции остатков известны два наиболее распространенных метода определения автокорреляции остатков. Первый метод – это построение графика зависимости остатков от времени и визуальное определение наличия или отсутствия автокорреляции. Второй метод – это использование критерия Дарбина-Уотсона, который сводится к проверке гипотезы:
Н0 (основная гипотеза): автокорреляция отсутствует;
Н1 и Н2 (альтернативные гипотезы): присутствует положительная или отрицательная автокорреляция в остатках соответственно.
Для проверки основной гипотезы используется статистика критерия Дарбина-Уотсона:
 где .
где .
На больших выборках d≈2(1- ), где — коэффициент автокорреляции 1-го порядка.
 .
.
Если в остатках существует полная положительная автокорреляция и =1, то d=0; если в остатках есть полная отрицательная автокорреляция, то = -1 и d=4; если автокорреляция остатков отсутствует, то = 0, то d=2. Следовательно, 0 .
Существуют специальные статистические таблицы для определения нижней и верхней критических границ d -статистики – d L и d U . Они определяются в зависимости от n, числа независимых переменных k и уровня значимости .
Если d набл ‹d L , то принимается гипотеза Н1: положительная автокорреляция.
Если d и ‹d набл ‹2,
Если 2‹d набл ‹4-d и, то принимается гипотеза Н0: автокорреляции нет.
Если d набл ›4-d L , то принимается гипотеза Н2: отрицательная автокорреляция.
Если 4-d и ‹d набл ‹4-d L , и d L ‹d набл ‹d и, то имеет место случай неопределенности.
 |
0 d L d U 2 4- d U 4- d L 4
Рис. 4.6 Алгоритм проверки гипотезы о наличии автокорреляции остатков
Для применения критерия Дарбина-Уотсона есть ограничения. Он неприменим для моделей, включающих в качестве независимых переменных лаговые значения результативного признака, т.е. к моделям авторегрессии. Методика направлена только на выявление автокорреляции остатков первого порядка. Результаты являются более достоверными при работе с большими выборками.
В тех случаях, когда имеет место автокорреляция остатков, для определения оценок параметров a, b используют обобщенный методМНК, который заключается в последовательности следующих шагов:
1. Преобразовать исходные переменные y t и x t к виду

2. Применив обычный МНК к уравнению  , где
, где  определить оценки параметров и b.
определить оценки параметров и b.
4. Выписать исходное уравнение .
Среди эконометрических моделей, построенных по временным данным, выделяют динамические модели.
Эконометрическая модель является динамической , если в данный момент времени t она учитывает значения входящих в нее переменных, относящихся как к текущему, так и к предыдущим моментам времени, т.е. эта модель отражает динамику исследуемых переменных в каждый момент времени.
Существует два основных типа динамических эконометрических моделей. К моделям первого типа относятся модели авторегрессии и модели с распределенным лагом, в которых значение переменной за прошлые периоды времени (лаговые переменные) непосредственно включены в модель. Модели второго типа учитывают динамическую информацию в неявном виде. В эти модели включены переменные, характеризующие ожидаемый и желаемый уровень результата, или один из факторов в момент времени t.
Модель с распределенным лагом имеет вид:
Построение моделей с распределенным лагом и моделей авторегрессии имеет свою специфику. Во-первых, оценка параметров моделей авторегрессии, а в большинстве случаев и моделей распределенным лагом не может быть проведена с помощью обычного МНК ввиду нарушения его предпосылок и требует специальных статистических методов. Во-вторых, исследователям приходится решать проблемы выбора оптимальной величины лага и определения его структуры. Наконец, в третьих, между моделями с распределенным лагом и моделями авторегрессии имеется определенная взаимосвязь, и в некоторых случаях необходимо осуществить переход от одноного типа моделей к другому.
Рассмотрим модель с распределенным лагом в предположении, что максимальная величина лага конечна:
Даная модель говорит о том, что если в некоторый момент времени t происходит изменение независимой переменной x , то это изменение будет влиять на значения переменной y в течение l следующих моментов времени.
Коэффициент регрессии b 0 при переменной x t характеризует среднее абсолютное изменение y t при изменении x t на 1 ед. своего измерения в некоторый фиксированный момент времени t , без учета воздействия лаговых значений фактора x. Этот коэффициент называется краткосрочным мультипликатором.
В момент t+1 воздействие факторной переменной x t на результат y t составит (b 0 +b 1) условных единиц; в момент времени t+2 это воздействие можно охарактеризовать суммой (b 0 +b 1 +b 2) и т.д. Полученные таким образом суммы называются промежуточными мультипликаторами .
С учетом конечной величины лага можно сказать, что изменение переменной x t в момент времени t на 1 условную единицу приведет к общему изменению результата через l моментов времени (b 0 +b 1 +b 2 +…+b l ).
Введем следующее обозначение: b=(b 0 +b 1 +b 2 +…+b l ). Величину b называется долгосрочным мультипликатором , который показывает абсолютное изменение в долгосрочном периоде t+l результата y под влиянием изменения на 1 ед. фактора x .
Величины  называются относительными коэффициентами модели с распределенным лагом. Если все коэффициенты b j имеют одинаковые знаки,то . Относительные коэффициенты являются весами для соответствующих коэффициентов b j . Каждый из них измеряет долю общего изменения результативного признака в момент времени t+j .
называются относительными коэффициентами модели с распределенным лагом. Если все коэффициенты b j имеют одинаковые знаки,то . Относительные коэффициенты являются весами для соответствующих коэффициентов b j . Каждый из них измеряет долю общего изменения результативного признака в момент времени t+j .
Зная величины , с помощью стандартных формул можно определить еще две важные характеристики модели множественной регрессии: величину среднего и медианного лагов.
Средний лаг рассчитывается по формуле средней арифметической взвешенной:
и представляет собой средний период, в течение которого будет происходить изменение результата под воздействием изменения фактора x в момент t. Если значение среднего лага небольшое, то это говорит о довольно быстром реагировании y на изменение x. Высокое значение среднего лага говорит о том, что воздействие фактора на результат будет сказываться в течение длительного периода времени.
Медианный лаг (L Me) – это величина лага, для которого период, в течение которого . Это тот период времени, в течение которого с момента времени t будет реализована половина общего воздействия фактора на результат.
Изложенные выше приемы анализа параметров модели с распределенным лагом действительны только в предположении, что все коэффициенты при текущем и лаговых значениях исследуемого фактора имеют одинаковые знаки. Это предположение вполне оправдано с экономической точки зрения: воздействие одного и того же фактора на результат должно быть однонаправленным независимо от того, с каким временным лагом измеряется сила или теснота связи между этими признаками. Однако на практике получить статистически значимую модель, параметры которой имели бы одинаковые знаки, особенно при большой величине лага l , чрезвычайно сложно.
Применение обычного МНК к таким моделям в большинстве случаев затруднительно по следующим причинам:
Текущие и лаговые значения независимой переменной, как правило, тесно связаны друг с другом, тем самым оценка параметров модели проводится в условиях высокой мультиколлинеарности;
При большой величине лага снижается число наблюдений, по которому строится модель, и увеличивается число ее факторных признаков, что ведет к потере числа степеней свободы в модели;
В моделях с распределенным лагом часто возникает проблема автокорреляции остатков.
Как и в модели с распределенным лагом, b 0 в этой модели характеризует краткосрочное изменение y t под воздействием изменения x t на 1 ед. Однако промежуточные и долгосрочный мультипликаторы в модели авторегрессии несколько иные. К моменту времени t+1 результат y t изменился под воздействием изменения изучаемого фактора в момент времени t на b 0 единиц, а y t +1 – под воздействием своего изменения в непосредственно предшествующим момент времени на с 1 единиц. Таким образом, общее абсолютное изменение результата в момент t+1 составит b 0 с 1 . Аналогично в момент времени t+2 абсолютное изменение результатасоставит b 0 с 1 2 единиц и т.д. Следовательно, долгосрочный мультипликатор в модели авторегрессии можно рассчитать как сумму краткосрочного и промежуточного мультипликаторов:
Такая интерпретация коэффициентов модели авторегрессии и расчет долгосрочного мультипликатора основаны на предпосылке о наличии бесконечного лага в воздействии текущего значения зависимой переменной на ее будущие значения.
Пример. Предположим, по данным о динамике показателей потребления и дохода в регионе была получена модель авторегрессии, описывающая зависимость среднедушевого объема потребления за год (С, млн. руб.) от среднедушевого совокупного годового дохода (Y, млн. руб.) и объема потребления предшествующего года:
 .
.
Краткосрочный мультипликатор равен 0,85. В этой модели он представляет собой предельную склонность к потреблению в краткосрочном периоде. Следовательно, увеличение среднедушевого совокупного дохода на 1 млн. руб. приводит к росту объема потребления в тот же год в среднем на 850 тыс. руб. Долгосрочную предельную склонность к потреблению в данной модели можно определить как
 .
.
В долгосрочной перспективе рост среднедушевого совокупного дохода на 1 млн. руб. приведет к росту объема потребления в среднем на 944 тыс. руб. Промежуточные показатели предельной склонности к потреблению можно определить, рассчитав необходимые частные суммы за соответствующие периоды времени. Например, для момента времени t+1
http://exceltut.ru/5-sposobov-rascheta-znachenij-linejnogo-trenda-v-ms-excel/
http://platya-valentina.ru/s-kakoi-celyu-ispolzuetsya-uravnenie-trenda-postroenie-lineinogo/