Выбор формы уравнения регрессии.
Для построения уравнения множественной регрессии чаще используются следующие функции
1. линейная: 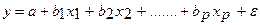
2. степенная: 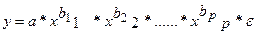
3. экспоненциальная: 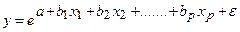
4. гипербола: 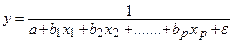
В виду четкой интерпретации параметров наиболее широко используются линейная и степенная функции. В линейной множественной регрессии параметры при Х называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменном значении других факторов, закрепленных на среднем уровне.
Пример. Предположим, что зависимость расходов на продукты питания по совокупности семей характеризуется следующим уравнением:
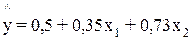
где у – расходы семьи за месяц на продукты питания, тыс.руб.;
х1 – месячный доход на одного члена семьи, тыс.руб.;
х2 – размер семьи, человек.
Анализ данного уравнения позволяет сделать выводы – с ростом дохода на одного члена семьи на 1 тыс. руб. расходы на питание возрастут в среднем на 350 руб. при том же среднем размере семьи. Иными словами, 35% дополнительных семейных расходов тратится на питание. Увеличение размера семьи при тех же ее доходах предполагает дополнительный рост расходов на питание на 730 руб. Параметр а не подлежит экономической интерпретации.
При изучении вопросов потребления коэффициенты регрессии рассматривают как характеристики предельной склонности к потреблению. Например, если функции потребления Сt имеет вид:
то потребление в период времени t зависит от дохода того же периода Rt и от дохода предшествующего периода Rt-1. Соответственно коэффициент b0 обычно называют краткосрочной предельной склонностью к потреблению. Общим эффектом возрастания как текущего, так и предыдущего дохода будет рост потребления на b= b0 + b1. Коэффициент b рассматривается здесь как долгосрочная склонность к потреблению. Так как коэффициенты b0 и b1 >0, то долгосрочная склонность к потреблению должна превосходить краткосрочную b0. Например, за период 1905 – 1951 гг. (за исключением военных лет) М.Фридман построил для США следующую функцию потребления: Сt = 53+0,58 Rt+0,32 Rt-1 с краткосрочной предельной склонностью к потреблению 0,58 и с долгосрочной склонностью к потреблению 0,9.
Функция потребления может рассматриваться также в зависимости от прошлых привычек потребления, т.е. от предыдущего уровня потребления
В этом уравнении параметр b0 также характеризует краткосрочную предельную склонность к потреблению, т.е. влияние на потребление единичного роста доходов того же периода Rt. Долгосрочную предельную склонность к потреблению здесь измеряет выражение b0/(1- b1).
Так, если уравнение регрессии составило:
то краткосрочная склонность к потреблению равна 0,46, а долгосрочная – 0,575 (0,46/0,8).
В степенной функции 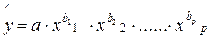 коэффициенты bj являются коэффициентами эластичности. Они показывают, на сколько процентов изменяется в среднем результат с изменением соответствующего фактора на 1% при неизменности действия других факторов. Этот вид уравнения регрессии получил наибольшее распространение в производственных функциях, в исследованиях спроса и потребления.
коэффициенты bj являются коэффициентами эластичности. Они показывают, на сколько процентов изменяется в среднем результат с изменением соответствующего фактора на 1% при неизменности действия других факторов. Этот вид уравнения регрессии получил наибольшее распространение в производственных функциях, в исследованиях спроса и потребления.
Предположим, что при исследовании спроса на мясо получено уравнение:
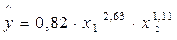
где у – количество спрашиваемого мяса
Следовательно, рост цен на 1% при том же доходе вызывает снижение спроса на мясо в среднем на 2.63%. Увеличение дохода на 1% обусловливает при неизменных ценах рост спроса на 1.11%.
В производственных функциях вида:
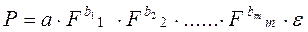
где P – количество продукта, изготавливаемого с помощью m производственных факторов (F1, F2, ……Fm).
b – параметр, являющийся эластичностью количества продукции по отношению к количеству соответствующих производственных факторов.
Экономический смысл имеют не только коэффициенты b каждого фактора, но и их сумма, т.е. сумма эластичностей: В = b1 +b2+……+bm. Эта величина фиксирует обобщенную характеристику эластичности производства. Производственная функция имеет вид
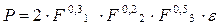
где Р – выпуск продукции
F1 – стоимость основных производственных фондов
F2 — отработано человеко-дней
F3 – затраты на производство
Эластичность выпуска по отдельным факторам производства составляет в среднем 0,3% с ростом F1 на 1% при неизменном уровне других факторов; 0,2% — с ростом F2 на 1% также при неизменности других факторов производства и 0,5% с ростом F3 на 1% при неизменном уровне факторов F1 и F2. Для данного уравнения В = b1 +b2+b3 = 1. Следовательно, в целом с ростом каждого фактора производства на 1% коэффициент эластичности выпуска продукции составляет 1%, т.е. выпуск продукции увеличивается на 1%, что в микроэкономике соответствует постоянной отдаче на масштаб.
При практических расчетах не всегда 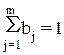 . Она может быть как больше, так и меньше 1. В этом случае величина В фиксирует приближенную оценку эластичности выпуска с ростом каждого фактора производства на 1% в условиях увеличивающейся (В>1) или уменьшающейся (В T ;
. Она может быть как больше, так и меньше 1. В этом случае величина В фиксирует приближенную оценку эластичности выпуска с ростом каждого фактора производства на 1% в условиях увеличивающейся (В>1) или уменьшающейся (В T ;
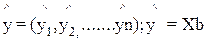
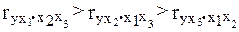
Для уравнения применили равенство:
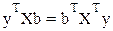
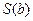 — скалярная функция
— скалярная функция
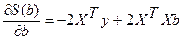
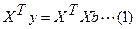
Система нормальных уравнений (1) содержит k линейных уравнений относительно k неизвестных i = 1,2,3……k
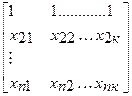
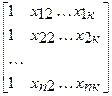
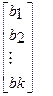 =
= 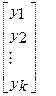 (2)
(2)
Перемножив (2) получим развернутую форму записи систем нормальных уравнений
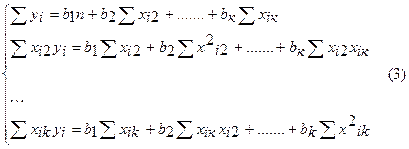
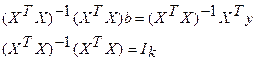
Оценка коэффициентов 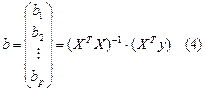
Стандартизированные коэффициенты регрессии, их интерпретация. Парные и частные коэффициенты корреляции. Множественный коэффициент корреляции. Множественный коэффициент корреляции и множественный коэффициент детерминации. Оценка надежности показателей корреляции.
Параметры уравнения множественной регрессии оцениваются, как и в парной регрессии, методом наименьших квадратов (МНК). При его применении строится система нормальных уравнений, решение которой и позволяет получить оценки параметров регрессии.
Так, для уравнения 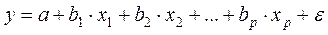 система нормальных уравнений составит:
система нормальных уравнений составит:

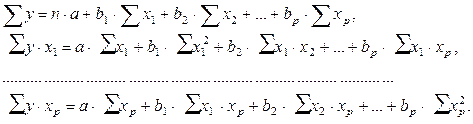
Ее решение может быть осуществлено методом определителей:
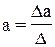 ,
, 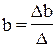 ,…,
,…, 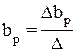 ,
,
где D – главный определитель системы;
Dа, Db1, …, Dbp – частные определители.
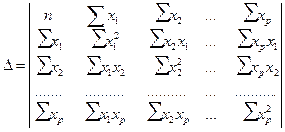
а Dа, Db1, …, Dbp получаются путем замены соответствующего столбца матрицы определителя системы данными левой части системы.
Возможен и иной подход в определении параметров множественной регрессии, когда на основе матрицы парных коэффициентов корреляции строится уравнение регрессии в стандартизованном масштабе:
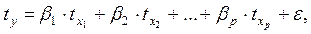
где 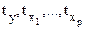 — стандартизованные переменные
— стандартизованные переменные 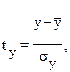
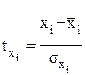 , для которых среднее значение равно нулю
, для которых среднее значение равно нулю 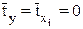 , а среднее квадратическое отклонение равно единице:
, а среднее квадратическое отклонение равно единице: 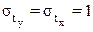 ;
;
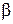 — стандартизованные коэффициенты регрессии.
— стандартизованные коэффициенты регрессии.
Применяя МНК к уравнению множественной регрессии в стандартизованном масштабе, после соответствующих преобразований получим систему нормальных вида

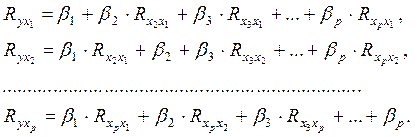
Решая ее методом определителей, найдем параметры – стандартизованные коэффициенты регрессии (b-коэффициенты).
Стандартизованные коэффициенты регрессии показывают, на сколько сигм изменится в среднем результат, если соответствующий фактор хi изменится на одну сигму при неизменном среднем уровне других факторов. В силу того, что все переменные заданы как центрированные и нормированные, стандартизованные коэффициенты регрессии bI сравнимы между собой. Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат. В этом основное достоинство стандартизованных коэффициентов регрессии в отличие от коэффициентов «чистой» регрессии, которые несравнимы между собой.
Пример. Пусть функция издержек производства у (тыс. руб.) характеризуется уравнением вида
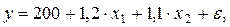
где х1 – основные производственные фонды;
х2 – численность занятых в производстве.
Анализируя его, мы видим, что при той же занятости дополнительный рост стоимости основных производственных фондов на 1 тыс. руб. влечет за собой увеличение затрат в среднем на 1,2 тыс. руб., а увеличение численности занятых на одного человека способствует при той же технической оснащенности предприятий росту затрат в среднем на 1,1 тыс. руб. Однако это не означает, что фактор х1 оказывает более сильное влияние на издержки производства по сравнению с фактором х2. Такое сравнение возможно, если обратиться к уравнению регрессии в стандартизованном масштабе. Предположим, оно выглядит так:
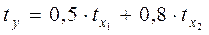
Это означает, что с ростом фактора х1 на одну сигму при неизменной численности занятых затрат на продукцию увеличиваются в среднем на 0,5 сигмы. Так как b1
Дата добавления: 2016-05-16 ; просмотров: 2403 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
5 видов регрессии и их свойства
Линейная и логистическая регрессии обычно являются первыми видами регрессии, которые изучают в таких областях, как машинное обучение и наука о данных. Оба метода считаются эффективными, так как их легко понять и использовать. Однако, такая простота также имеет несколько недостатков, и во многих случаях лучше выбирать другую регрессионную модель. Существует множество видов регрессии, каждый из которых имеет свои достоинства и недостатки.
Мы познакомимся с 7 наиболее распространенными алгоритмами регрессии и опишем их свойства. Также мы узнаем, в каких ситуация и с какими видами данных лучше использовать тот или иной алгоритм. В конце мы расскажем о некоторых инструментах для построения регрессии и поможем лучше разобраться в регрессионных моделях в целом!
Линейная регрессия
Регрессия — это метод, используемый для моделирования и анализа отношений между переменными, а также для того, чтобы увидеть, как эти переменные вместе влияют на получение определенного результата. Линейная регрессия относится к такому виду регрессионной модели, который состоит из взаимосвязанных переменных. Начнем с простого. Парная (простая) линейная регрессия — это модель, позволяющая моделировать взаимосвязь между значениями одной входной независимой и одной выходной зависимой переменными с помощью линейной модели, например, прямой.
Более распространенной моделью является множественная линейная регрессия, которая предполагает установление линейной зависимости между множеством входных независимых и одной выходной зависимой переменных. Такая модель остается линейной по той причине, что выход является линейной комбинацией входных переменных. Мы можем построить модель множественной линейной регрессии следующим образом:
Y = a_1*X_1 + a_2*X_2 + a_3*X_3 ……. a_n*X_n + b
Где a_n — это коэффициенты, X_n — переменные и b — смещение . Как видим, данная функция не содержит нелинейных коэффициентов и, таким образом, подходит только для моделирования линейных сепарабельных данных. Все очень просто: мы взвешиваем значение каждой переменной X_n с помощью весового коэффициента a_n. Данные весовые коэффициенты a_n, а также смещение b вычисляются с применением стохастического градиентного спуска. Посмотрите на график ниже в качестве иллюстрации!
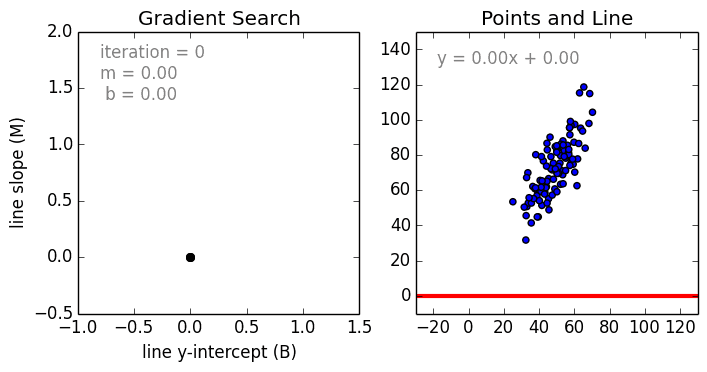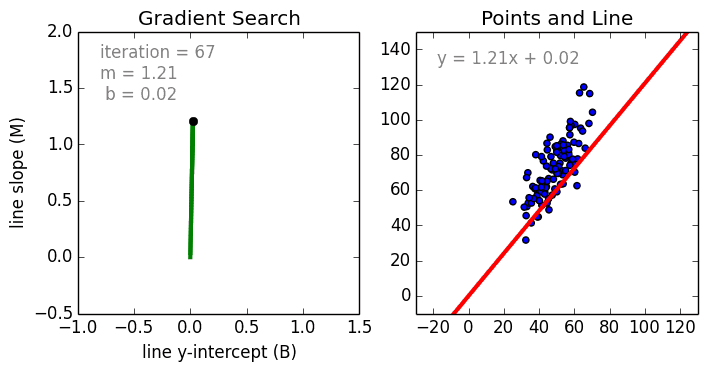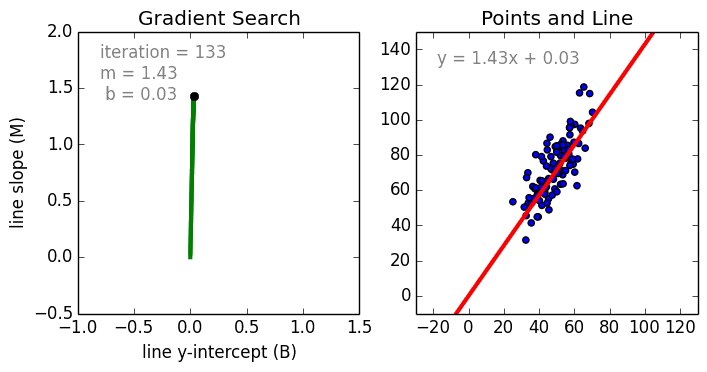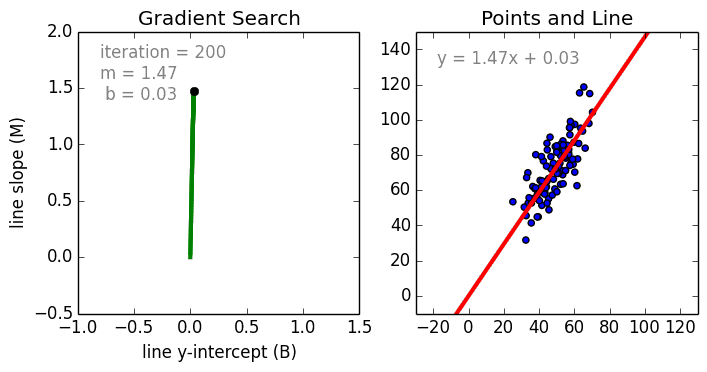
Несколько важных пунктов о линейной регрессии:
- Она легко моделируется и является особенно полезной при создании не очень сложной зависимости, а также при небольшом количестве данных.
- Обозначения интуитивно-понятны.
- Чувствительна к выбросам.
Полиномиальная регрессия
Для создания такой модели, которая подойдет для нелинейно разделяемых данных, можно использовать полиномиальную регрессию. В данном методе проводится кривая линия, зависимая от точек плоскости. В полиномиальной регрессии степень некоторых независимых переменных превышает 1. Например, получится что-то подобное:
Y = a_1*X_1 + (a_2)²*X_2 + (a_3)⁴*X_3 ……. a_n*X_n + b
У некоторых переменных есть степень, у других — нет. Также можно выбрать определенную степень для каждой переменной, но для этого необходимы определенные знания о том, как входные данные связаны с выходными. Сравните линейную и полиномиальную регрессии ниже.
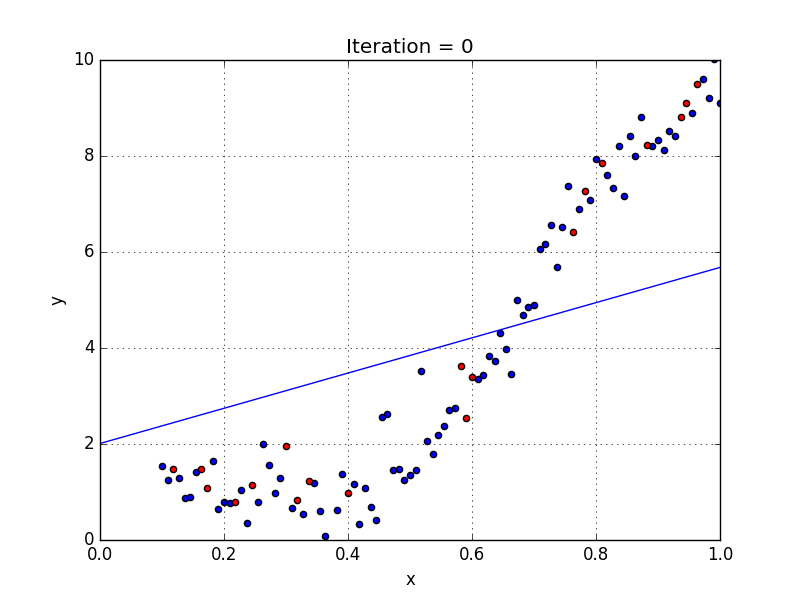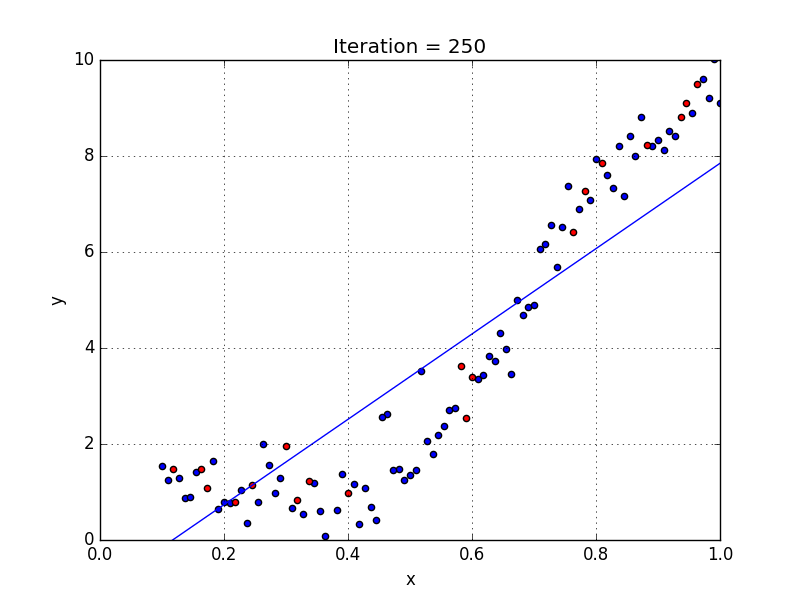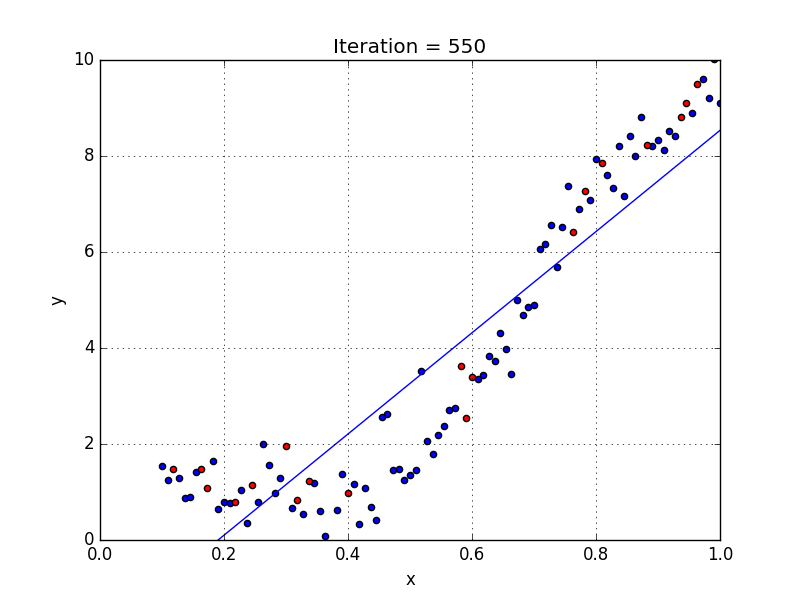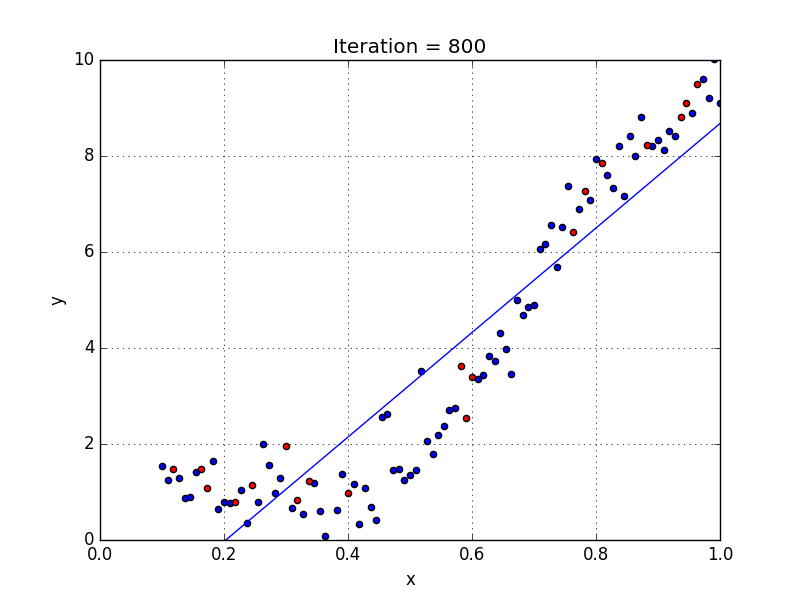

Несколько важных пунктов о полиномиальной регрессии:
- Моделирует нелинейно разделенные данные (чего не может линейная регрессия). Она более гибкая и может моделировать сложные взаимосвязи.
- Полный контроль над моделированием переменных объекта (выбор степени).
- Необходимо внимательно создавать модель. Необходимо обладать некоторыми знаниями о данных, для выбора наиболее подходящей степени.
- При неправильном выборе степени, данная модель может быть перенасыщена.
Гребневая (ридж) регрессия
В случае высокой коллинеарности переменных стандартная линейная и полиномиальная регрессии становятся неэффективными. Коллинеарность — это отношение независимых переменных, близкое к линейному. Наличие высокой коллинеарности можно определить несколькими путями:
- Коэффициент регрессии не важен, несмотря на то, что, теоретически, переменная должна иметь высокую корреляцию с Y.
- При добавлении или удалении переменной из матрицы X, коэффициент регрессии сильно изменяется.
- Переменные матрицы X имеют высокие попарные корреляции (посмотрите корреляционную матрицу).
Сначала можно посмотреть на функцию оптимизации стандартной линейной регрессии для лучшего понимания того, как может помочь гребневая регрессия:
Где X — это матрица переменных, w — веса, y — достоверные данные. Гребневая регрессия — это корректирующая мера для снижения коллинеарности среди предикторных переменных в регрессионной модели. Коллинеарность — это явление, в котором одна переменная во множественной регрессионной модели может быть предсказано линейно, исходя из остальных свойств со значительной степенью точности. Таким образом, из-за высокой корреляции переменных, конечная регрессионная модель сведена к минимальным пределам приближенного значения, то есть она обладает высокой дисперсией.
Гребневая регрессия добавляет небольшой фактор квадратичного смещения для уменьшения дисперсии:
min || Xw — y ||² + z|| w ||²
Такой фактор смещения выводит коэффициенты переменных из строгих ограничений, вводя в модель небольшое смещение, но при этом значительно снижая дисперсию.
Несколько важных пунктов о гребневой регрессии:
- Допущения данной регрессии такие же, как и в методе наименьших квадратов, кроме того факта, что нормальное распределение в гребневой регрессии не предполагается.
- Это уменьшает значение коэффициентов, оставляя их ненулевыми, что предполагает отсутствие отбора признаков.
Регрессия по методу «лассо»
В регрессии лассо, как и в гребневой, мы добавляем условие смещения в функцию оптимизации для того, чтобы уменьшить коллинеарность и, следовательно, дисперсию модели. Но вместо квадратичного смещения, мы используем смещение абсолютного значения:
min || Xw — y ||² + z|| w ||
Существует несколько различий между гребневой регрессией и лассо, которые восстанавливают различия в свойствах регуляризаций L2 и L1:
- Встроенный отбор признаков — считается полезным свойством, которое есть в норме L1, но отсутствует в норме L2. Отбор признаков является результатом нормы L1, которая производит разреженные коэффициенты. Например, предположим, что модель имеет 100 коэффициентов, но лишь 10 из них имеют коэффициенты отличные от нуля. Соответственно, «остальные 90 предикторов являются бесполезными в прогнозировании искомого значения». Норма L2 производит неразряженные коэффициенты и не может производить отбор признаков. Таким образом, можно сказать, что регрессия лассо производит «выбор параметров», так как не выбранные переменные будут иметь общий вес, равный 0.
- Разряженность означает, что незначительное количество входных данных в матрице (или векторе) имеют значение, отличное от нуля. Норма L1 производит большое количество коэффициентов с нулевым значением или очень малые значения с некоторыми большими коэффициентами. Это связано с предыдущим пунктом, в котором указано, что лассо исполняет выбор свойств.
- Вычислительная эффективность: норма L1 не имеет аналитического решения в отличие от нормы L2. Это позволяет эффективно вычислять решения нормы L2. Однако, решения нормы L1 не обладают свойствами разряженности, что позволяет использовать их с разряженными алгоритмами для более эффективных вычислений.
Регрессия «эластичная сеть»
Эластичная сеть — это гибрид методов регрессии лассо и гребневой регрессии. Она использует как L1, так и L2 регуляризации, учитывая эффективность обоих методов.
min || Xw — y ||² + z_1|| w || + z_2|| w ||²
Практическим преимуществом использования регрессии лассо и гребневой регрессии является то, что это позволяет эластичной сети наследовать некоторую стабильность гребневой регрессии при вращении.
Несколько важных пунктов о регрессии эластичной сети:
- Она создает условия для группового эффекта при высокой корреляции переменных, а не обнуляет некоторые из них, как метод лассо.
- Нет ограничений по количеству выбранных переменных.
Вывод
Вот и все! 5 распространенных видов регрессии и их свойства. Все данные методы регуляризации регрессии (лассо, гребневая и эластичной сети) хорошо функционирует при высокой размерности и мультиколлинеарности среди переменных в наборе данных.
R — значит регрессия
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.

Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.
Введение в регрессионный анализ
Если имеется корреляционная зависимость  между переменными y и x , возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения
между переменными y и x , возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения  называется регрессией y по x .
называется регрессией y по x .
Основу регрессионного анализа составляет метод наименьших квадратов (МНК), в соответствии с которым в качестве уравнения регресии берется функция  такая, что сумма квадратов разностей
такая, что сумма квадратов разностей  минимальна.
минимальна.

Карл Гаусс открыл, или точнее воссоздал, МНК в возрасте 18 лет, однако впервые результаты были опубликованы Лежандром в 1805 г. По непроверенным данным метод был известен еще в древнем Китае, откуда он перекочевал в Японию и только затем попал в Европу. Европейцы не стали делать из этого секрета и успешно запустили в производство, обнаружив с его помощью траекторию карликовой планеты Церес в 1801 г.
Вид функции , как правило, определен заранее, а с помощью МНК подбираются оптимальные значения неизвестных параметров. Метрикой рассеяния значений  вокруг регрессии
вокруг регрессии  является дисперсия.
является дисперсия.

- k — число коэффициентов в системе уравнений регрессии.
Чаще всего используется модель линейной регрессии, а все нелинейные зависимости приводят к линейному виду с помощью алгебраических ухищрений, различных преобразования переменных y и x .
Линейная регрессия
Уравнения линейной регрессии можно записать в виде

В матричном виде это выгладит

- y — зависимая переменная;
- x — независимая переменная;
- β — коэффициенты, которые необходимо найти с помощью МНК;
- ε — погрешность, необъяснимая ошибка и отклонение от линейной зависимости;

Случайная величина может быть интерпретирована как сумма из двух слагаемых:
 — полная дисперсия (TSS).
— полная дисперсия (TSS).- — объясненная часть дисперсии (ESS).
- — остаточная часть дисперсии (RSS).
 — объясненная часть дисперсии (ESS).
— объясненная часть дисперсии (ESS). — остаточная часть дисперсии (RSS).
— остаточная часть дисперсии (RSS).Еще одно ключевое понятие — коэффициент корреляции R 2 .

Ограничения линейной регрессии
Для того, чтобы использовать модель линейной регрессии необходимы некоторые допущения относительно распределения и свойств переменных.
- Линейность, собственно. Увеличение, или уменьшение вектора независимых переменных в k раз, приводит к изменению зависимой переменной также в k раз.
- Матрица коэффициентов обладает полным рангом, то есть векторы независимых переменных линейно независимы.
- Экзогенность независимых переменных — . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
- Однородность дисперсии и отсутствие автокорреляции. Каждая εi обладает одинаковой и конечной дисперсией σ 2 и не коррелирует с другой εi. Это ощутимо ограничивает применимость модели линейной регрессии, необходимо удостовериться в том, что условия соблюдены, иначе обнаруженная взаимосвязь переменных будет неверно интерпретирована.
 . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
. Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.Как обнаружить, что перечисленные выше условия не соблюдены? Ну, во первых довольно часто это видно невооруженным глазом на графике.
Неоднородность дисперсии 
При возрастании дисперсии с ростом независимой переменной имеем график в форме воронки.

Нелинейную регрессии в некоторых случая также модно увидеть на графике довольно наглядно.
Тем не менее есть и вполне строгие формальные способы определить соблюдены ли условия линейной регрессии, или нарушены.
- Автокорреляция проверяется статистикой Дарбина-Уотсона (0 ≤ d ≤ 4). Если автокорреляции нет, то значения критерия d≈2, при позитивной автокорреляции d≈0, при отрицательной — d≈4.
- Неоднородность дисперсии — Тест Уайта, , при \chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же можно еще применить тест Бройша-Пагана.
- Мультиколлинеарность — нарушения условия об отсутствии взаимной линейной зависимости между независимыми переменными. Для проверки часто используют VIF-ы (Variance Inflation Factor).
 , при
, при  \chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же
\chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же  можно еще применить тест Бройша-Пагана.
можно еще применить тест Бройша-Пагана.
В этой формуле  — коэффициент взаимной детерминации между
— коэффициент взаимной детерминации между  и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
Почему нам так важно соблюдение всех выше перечисленных условий? Все дело в Теореме Гаусса-Маркова, согласно которой оценка МНК является точной и эффективной лишь при соблюдении этих ограничений.
Как преодолеть эти ограничения
Нарушения одной или нескольких ограничений еще не приговор.
- Нелинейность регрессии может быть преодолена преобразованием переменных, например через функцию натурального логарифма ln .
- Таким же способом возможно решить проблему неоднородной дисперсии, с помощью ln , или sqrt преобразований зависимой переменной, либо же используя взвешенный МНК.
- Для устранения проблемы мультиколлинеарности применяется метод исключения переменных. Суть его в том, что высоко коррелированные объясняющие переменные устраняются из регрессии, и она заново оценивается. Критерием отбора переменных, подлежащих исключению, является коэффициент корреляции. Есть еще один способ решения данной проблемы, который заключается в замене переменных, которым присуща мультиколлинеарность, их линейной комбинацией. Этим весь список не исчерпывается, есть еще пошаговая регрессия и другие методы.
К сожалению, не все нарушения условий и дефекты линейной регрессии можно устранить с помощью натурального логарифма. Если имеет место автокорреляция возмущений к примеру, то лучше отступить на шаг назад и построить новую и лучшую модель.
Линейная регрессия плюсов на Хабре
Итак, довольно теоретического багажа и можно строить саму модель.
Мне давно было любопытно от чего зависит та самая зелененькая цифра, что указывает на рейтинг поста на Хабре. Собрав всю доступную статистику собственных постов, я решил прогнать ее через модель линейно регрессии.
Загружает данные из tsv файла.
- points — Рейтинг статьи
- reads — Число просмотров.
- comm — Число комментариев.
- faves — Добавлено в закладки.
- fb — Поделились в социальных сетях (fb + vk).
- bytes — Длина в байтах.
Вопреки моим ожиданиям наибольшая отдача не от количества просмотров статьи, а от комментариев и публикаций в социальных сетях. Я также полагал, что число просмотров и комментариев будет иметь более сильную корреляцию, однако зависимость вполне умеренная — нет надобности исключать ни одну из независимых переменных.
Теперь собственно сама модель, используем функцию lm .
В первой строке мы задаем параметры линейной регрессии. Строка points
. определяет зависимую переменную points и все остальные переменные в качестве регрессоров. Можно определить одну единственную независимую переменную через points
reads , набор переменных — points
Перейдем теперь к расшифровке полученных результатов.
- Intercept — Если у нас модель представлена в виде , то тогда — точка пересечения прямой с осью координат, или intercept .
- R-squared — Коэффициент детерминации указывает насколько тесной является связь между факторами регрессии и зависимой переменной, это соотношение объясненных сумм квадратов возмущений, к необъясненным. Чем ближе к 1, тем ярче выражена зависимость.
- Adjusted R-squared — Проблема с в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
- F-statistic — Используется для оценки значимости модели регрессии в целом, является соотношением объяснимой дисперсии, к необъяснимой. Если модель линейной регрессии построена удачно, то она объясняет значительную часть дисперсии, оставляя в знаменателе малую часть. Чем больше значение параметра — тем лучше.
- t value — Критерий, основанный на t распределении Стьюдента . Значение параметра в линейной регрессии указывает на значимость фактора, принято считать, что при t > 2 фактор является значимым для модели.
- p value — Это вероятность истинности нуль гипотезы, которая гласит, что независимые переменные не объясняют динамику зависимой переменной. Если значение p value ниже порогового уровня (.05 или .01 для самых взыскательных), то нуль гипотеза ложная. Чем ниже — тем лучше.
 , то тогда
, то тогда  — точка пересечения прямой с осью координат, или intercept .
— точка пересечения прямой с осью координат, или intercept . в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
Можно попытаться несколько улучшить модель, сглаживая нелинейные факторы: комментарии и посты в социальных сетях. Заменим значения переменных fb и comm их степенями.
Проверим значения параметров линейной регрессии.
Как видим в целом отзывчивость модели возросла, параметры подтянулись и стали более шелковистыми , F-статистика выросла, так же как и скорректированный коэффициент детерминации .
Проверим, соблюдены ли условия применимости модели линейной регрессии? Тест Дарбина-Уотсона проверяет наличие автокорреляции возмущений.
И напоследок проверка неоднородности дисперсии с помощью теста Бройша-Пагана.
В заключение
Конечно наша модель линейной регрессии рейтинга Хабра-топиков получилось не самой удачной. Нам удалось объяснить не более, чем половину вариативности данных. Факторы надо чинить, чтобы избавляться от неоднородной дисперсии, с автокорреляцией тоже непонятно. Вообще данных маловато для сколь-нибудь серьезной оценки.
Но с другой стороны, это и хорошо. Иначе любой наспех написанный тролль-пост на Хабре автоматически набирал бы высокий рейтинг, а это к счастью не так.
http://medium.com/nuances-of-programming/5-%D0%B2%D0%B8%D0%B4%D0%BE%D0%B2-%D1%80%D0%B5%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B8%D0%B8-%D0%B8-%D0%B8%D1%85-%D1%81%D0%B2%D0%BE%D0%B9%D1%81%D1%82%D0%B2%D0%B0-f1bb867aebcb
http://habr.com/ru/post/350668/