Анализ временных рядов, тренд ряда динамики, точечная оценка прогноза
МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ
Анализ временных рядов
Временной ряд (или ряд динамики) – это упорядоченная по времени последовательность значений некоторой произвольной переменной величины. Тем самым, временной ряд существенным образом отличается от простой выборки данных. Каждое отдельное значение данной переменной называется отсчётом (уровнем элементов) временного ряда.
Временные ряды состоят из двух элементов:
- периода времени, за который или по состоянию на который приводятся числовые значения;
- числовых значений того или иного показателя, называемых уровнями ряда.
Временные ряды классифицируются по следующим признакам:
- по форме представления уровней: ряды абсолютных показателей, относительных показателей, средних величин;
- по количеству показателей, когда определяются уровни в каждый момент времени: одномерные и многомерные временные ряды;
- по характеру временного параметра: моментные и интервальные временные ряды. В моментных временных рядах уровни характеризуют значения показателя по состоянию на определенные моменты времени. В интервальных рядах уровни характеризуют значение показателя за определенные периоды времени. Важная особенность интервальных временных рядов абсолютных величин заключается в возможности суммирования их уровней. Отдельные же уровни моментного ряда абсолютных величин содержат элементы повторного счета. Это делает бессмысленным суммирование уровней моментных рядов;
- по расстоянию между датами и интервалами времени выделяют равноотстоящие – когда даты регистрации или окончания периодов следуют друг за другом с равными интервалами и неполные (неравноотстоящие) – когда принцип равных интервалов не соблюдается;
- по наличию пропущенных значений: полные и неполные временные ряды. Временные ряды бывают детерминированными и случайными: первые получают на основе значений некоторой неслучайной функции (ряд последовательных данных о количестве дней в месяцах); вторые есть результат реализации некоторой случайной величины;
- в зависимости от наличия основной тенденции выделяют стационарные ряды – в которых среднее значение и дисперсия постоянны и нестационарные – содержащие основную тенденцию развития.
Временные ряды, как правило, возникают в результате измерения некоторого показателя. Это могут быть как показатели (характеристики) технических систем, так и показатели природных, социальных, экономических и других систем (например, погодные данные). Типичным примером временного ряда можно назвать биржевой курс, при анализе которого пытаются определить основное направление развития (тенденцию или тренда).
Анализ временных рядов – совокупность математико-статистических методов анализа, предназначенных для выявления структуры временных рядов и для их прогнозирования. Сюда относятся, в частности, методы регрессионного анализа. Выявление структуры временного ряда необходимо для того, чтобы построить математическую модель того явления, которое является источником анализируемого временного ряда. Прогноз будущих значений временного ряда используется для эффективного принятия решений.
Прогноз, характеристики и параметры прогнозирования
Прогноз (от греч. 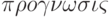 – предвидение, предсказание) – предсказание будущего с помощью научных методов, а также сам результат предсказания. Прогноз – это научная модель будущего события, явлений и т.п.
– предвидение, предсказание) – предсказание будущего с помощью научных методов, а также сам результат предсказания. Прогноз – это научная модель будущего события, явлений и т.п.
Прогнозирование, разработка прогноза; в узком значении – специальное научное исследование конкретных перспектив развития какого-либо процесса.
- по срокам: краткосрочные, среднесрочные, долгосрочные;
- по масштабу: личные, на уровне предприятия (организации), местные, региональные, отраслевые, мировые (глобальные).
К основным методам прогнозирования относятся:
- статистические методы;
- экспертные оценки (метод Дельфи);
- моделирование.
Прогноз – обоснованное суждение о возможном состоянии объекта в будущем или альтернативных путях и сроках достижения этих состояний. Прогнозирование – процесс разработки прогноза. Этап прогнозирования – часть процесса разработки прогнозов, характеризующаяся своими задачами, методами и результатами. Деление на этапы связано со спецификой построения систематизированного описания объекта прогнозирования, сбора данных, с построением модели, верификацией прогноза.
Прием прогнозирования – одна или несколько математических или логических операций, направленных на получение конкретного результата в процессе разработки прогноза. В качестве приема могут выступать сглаживание динамического ряда, определение компетентности эксперта, вычисление средневзвешенного значения оценок экспертов и т. д.
Модель прогнозирования – модель объекта прогнозирования, исследование которой позволяет получить информацию о возможных состояниях объекта прогнозирования в будущем и (или) путях и сроках их осуществления.
Метод прогнозирования – способ исследования объекта прогнозирования, направленный на разработку прогноза. Методы прогнозирования являются основанием для методик прогнозирования.
Методика прогнозирования – совокупность специальных правил и приемов (одного или нескольких методов) разработки прогнозов.
Прогнозирующая система – система методов и средств их реализации, функционирующая в соответствии с основными принципами прогнозирования. Средствами реализации являются экспертная группа, совокупность программ и т. д. Прогнозирующие системы могут быть автоматизированными и неавтоматизированными.
Прогнозный вариант – один из прогнозов, составляющих группу возможных прогнозов.
Объект прогнозирования – процесс, система, или явление, о состоянии которого даётся прогноз.
Характеристика объекта прогнозирования – качественное или количественное отражение какого-либо свойства объекта прогнозирования.
Переменная объекта прогнозирования – количественная характеристика объекта прогнозирования, которая является или принимается за изменяемую в течение периода основания и (или) периода упреждения прогноза.
Период основания прогноза – промежуток времени, за который используют информацию для разработки прогноза. Этот промежуток времени называют также периодом предыстории.
Период упреждения прогноза – промежуток времени, на который разрабатывается прогноз.
Прогнозный горизонт – максимально возможный период упреждения прогноза заданной точности.
Точность прогноза – оценка доверительного интервала прогноза для заданной вероятности его осуществления.
Достоверность прогноза – оценка вероятности осуществления прогноза для заданного доверительного интервала.
Ошибка прогноза – апостериорная величина отклонения прогноза от действительного состояния объекта.
Источник ошибки прогноза – фактор, способный привести к появлению ошибки прогноза. Различают источники регулярных и нерегулярных ошибок.
Верификация прогноза – оценка достоверности и точности или обоснованности прогноза.
Статистические методы прогнозирования – научная и учебная дисциплина, к основным задачам которой относятся разработка, изучение и применение современных математико-статистических методов прогнозирования на основе объективных данных; развитие теории и практики вероятностно-статистического моделирования экспертных методов прогнозирования; методов прогнозирования в условиях риска и комбинированных методов прогнозирования с использованием совместно экономико-математических и эконометрических (как математико-статистических, так и экспертных) моделей. Научной базой статистических методов прогнозирования является прикладная статистика и теория принятия решений.
Простейшие методы восстановления используемых для прогнозирования зависимостей исходят из заданного временного ряда, т. е. функции, определённой в конечном числе точек на оси времени. Временной ряд при этом часто рассматривается в рамках той или иной вероятностной модели, вводятся другие факторы (независимые переменные), помимо времени, например, объем денежной массы. Временной ряд может быть многомерным. Основные решаемые задачи – интерполяция и экстраполяция. Метод наименьших квадратов в простейшем случае (линейная функция от одного фактора) был разработан К. Гауссом в 1794–1795 гг. Могут оказаться полезными предварительные преобразования переменных, например, логарифмирование. Наиболее часто используется метод наименьших квадратов при нескольких факторах.
Оценивание точности прогноза (в частности, с помощью доверительных интервалов) – необходимая часть процедуры прогнозирования. Обычно используют вероятностно-статистические модели восстановления зависимости, например, строят наилучший прогноз по методу максимального правдоподобия. Разработаны параметрические (обычно на основе модели нормальных ошибок) и непараметрические оценки точности прогноза и доверительные границы для него (на основе Центральной Предельной Теоремы теории вероятностей). Применяются также эвристические приемы, не основанные на вероятностно-статистической теории: метод скользящих средних, метод экспоненциального сглаживания.
Многомерная регрессия, в том числе с использованием непараметрических оценок плотности распределения – основной на настоящий момент статистический аппарат прогнозирования. Нереалистическое предположение о нормальности погрешностей измерений и отклонений от линии (поверхности) регрессии использовать не обязательно; однако для отказа от предположения нормальности необходимо опереться на иной математический аппарат, основанный на многомерной Центральной Предельной Теореме теории вероятностей, технологии линеаризации и наследования сходимости. Он позволяет проводить точечное и интервальное оценивание параметров, проверять значимость их отличия от 0 в непараметрической постановке, строить доверительные границы для прогноза.
Уравнение тренда временного ряда
Рассматривая временной ряд как множество результатов наблюдений изучаемого процесса, проводимых последовательно во времени, в качестве основных целей исследования временных рядов можно выделить: выявление и анализ характерного изменения параметра у, оценка возможного изменения параметра в будущем (прогноз).
Значения временного ряда можно представить в виде: 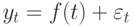 , где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем,
, где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем, 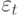 – случайная величина, характеризующая отклонение уровня от f(t ).
– случайная величина, характеризующая отклонение уровня от f(t ).
Неслучайная функция f (t) называется трендом. Тренд отражает характерное изменение (тенденцию) yt за некоторый промежуток времени. На практике в качестве тренда выбирают несколько возможных теоретических или эмпирических моделей. Могут быть выбраны, например, линейная, параболическая, логарифмическая, показательная функции. Для выявления типа модели на координатную плоскость наносят точки с координатами ( t, yt ) и по характеру расположения точек делают вывод о виде уравнения тренда. Для получения уравнения тренда применяют различные методы: сглаживание с помощью скользящей средней, метод наименьших квадратов и другие.
Уравнение тренда линейного вида будем искать в виде yt=f(t ), где f (t) = a0+a1(t ).
Пример 1. Имеется временной ряд:
| ti | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| xti | 2 | 1 | 4 | 4 | 6 | 8 | 7 | 9 | 12 | 11 |
Построим график xti во времени. Добавим на графике линию тренда исходных значений ряда. При этом, щелкнув правой кнопкой мыши по линии тренда, можно вызвать контекстное меню «Формат линии тренда», а в нем поставить флажок «показывать уравнение на диаграмме», тогда на диаграмме высветится уравнение линии тренда, вычисленное встроенными возможностями Excel .

Чтобы определить уравнение тренда, необходимо найти значения коэффициентов а0 и а1. Эти коэффициенты следует определять, исходя из условия минимального отклонения значений функции f (t) в точках ti от значений исходного временного ряда в тех же точках ti . Это условие можно записать в виде (на основе метода наименьших квадратов):
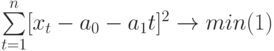
где n – количество значений временного ряда.
Для того, чтобы найти значения а0 и а1, необходимо иметь систему из двух уравнений. Эти уравнения можно получить, используя условие равенства нулю производной функции в точках её экстремума. В нашем случае эта функция имеет вид 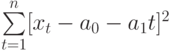 . Обозначим её через Q . Найдем производные функции Q(а0, а1) по переменным а0 и а1. Получим систему уравнений:
. Обозначим её через Q . Найдем производные функции Q(а0, а1) по переменным а0 и а1. Получим систему уравнений:
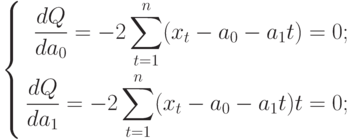
Полученная система может быть преобразована (математически) в систему так называемых нормальных уравнений. При этом уравнения примут вид:
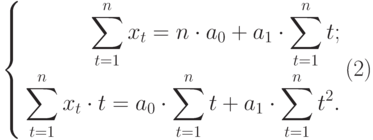
Теперь необходимо решить преобразованную систему уравнений относительно а0 и а1. Однако предварительно следует составить и заполнить вспомогательную таблицу:
| t | t 2 | хt | хtt |
|---|---|---|---|
| 1 | 1 | 2 | 2 |
| 2 | 4 | 1 | 2 |
| 3 | 9 | 4 | 12 |
| 4 | 16 | 4 | 16 |
| 5 | 25 | 6 | 30 |
| 6 | 36 | 8 | 48 |
| 7 | 49 | 7 | 49 |
| 8 | 64 | 9 | 72 |
| 9 | 81 | 12 | 108 |
| 10 | 100 | 11 | 110 |
 | 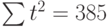 | 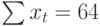 | 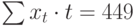 |
Подставив значения n = 10 в систему уравнений (2), получим
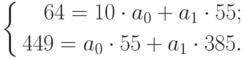
Решив систему уравнений относительно а0 и а1, получим а0 = -0,035, а1 = 1,17. Тогда функция тренда заданного временного ряда f (t) имеет вид:
f (t) = -0,035 + 1,17t.
Изобразим полученную функцию на графике.

Временной ряд приведен в таблице. Используя средства MS Excel :
- построить график временного ряда;
- добавить линию тренда и ее уравнение;
- найти уравнение тренда методом наименьших квадратов, сравнить уравнения (выше на графике и полученное);
- построить график временного ряда и полученной функции тренда в одной системе координат.
1. Реализация аспирина по аптеке (у.е.) за последние 7 недель приведена в таблице:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| хti | 3,2 | 3,3 | 2,9 | 2,2 | 1,6 | 1,5 | 1,2 |
2. Динамика потребления молочных продуктов (у.е.) по району за последние 7 месяцев:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| хti | 30 | 29 | 27 | 24 | 25 | 24 | 23 |
3. Динамика числа работников, занятых в одной из торговых сетей города за последние 8 лет приведена в таблице:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 280 | 361 | 384 | 452 | 433 | 401 | 512 | 497 |
4. Динамика потребления сульфаниламидных препаратов в клинике по годам (тыс. упаковок):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 14 | 21 | 29 | 33 | 38 | 44 | 46 | 50 |
5. Динамика продаж однокомнатных квартир в городе за последние 8 лет (тыс. ед.):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| уt | 39 | 40 | 36 | 34 | 36 | 37 | 33 | 35 |
6. Динамика потребления антибиотиков в клинике (тыс. упаковок):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 10 | 17 | 18 | 13 | 17 | 21 | 25 | 29 |
7. Динамика производства хлебобулочных изделий на хлебозаводе (тонн):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 510 | 502 | 564 | 680 | 523 | 642 | 728 | 665 |
8. Динамика потребления противовирусных препаратов по аптечной сети в начале эпидемии гриппа (тыс. единиц):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 36 | 42 | 34 | 38 | 12 | 32 | 26 | 20 |
9. Динамика потребления противовирусных препаратов по аптечной сети в конце эпидемии гриппа (тыс. единиц):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 46 | 52 | 44 | 48 | 32 | 42 | 36 | 30 |
10. Динамика потребления витаминов по аптечной сети в весенний период (с марта по апрель) в разные годы (у.е.):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 0,9 | 1,7 | 1,5 | 1,7 | 1,5 | 2,1 | 2,5 | 3,6 |
Пример 2. Используя данные примера 1, приведенного выше, вычислить точечный прогноз исходного временного ряда на 5 шагов вперед.
Исходя из условия задачи, необходимо определить точечную оценку прогноза для t = 11, 12, 13, 14, 15, где t в данном случае – шаг упреждения.
Рассмотрим решение этой задачи средствами Microsoft Excel . При решении данной задачи следует так же, как и в примере 1, ввести исходные данные. Выделив данные, построить точечный график, щелкнув правой кнопкой мыши по ряду данных, вызвать контекстное меню и выбрать «Добавить линию тренда».
Щелкнув правой кнопкой мыши по линии тренда, вызвать контекстное меню, выбрать «Формат линии тренда», в окне Параметры линии тренда указать прогноз на 5 периодов и поставить флажок в окошке «Показывать уравнение на диаграмме (рис. 14.3 рис. 14.3.). В версии Excel ранее 2007 окно диалога представлено на рисунке 14.4 рис. 14.4.


Итоговый график представлен на рисунке 14.5 рис. 14.5.

Значения прогноза для 11, 12, 13, 14 и 15 уровней получим, используя функцию ПРЕДСКАЗ( ). Данная функция позволяет получить значения прогноза линейного тренда. Вычисленные значения: 12,87, 14,04, 15,22, 16,39, 17,57.
Значения точечного прогноза для исходного временного ряда на 5 шагов вперед можно вычислить и с помощью уравнения функции тренда f(t ), найденного по методу наименьших квадратов. Для этого в полученное для f (t) выражение необходимо подставить значения t = 11, 12, 13, 14, 15. В результате получим (эти значения следует рассчитать, сформировав формулу в табличном процессоре MS Excel ):
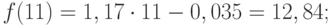
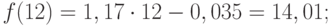
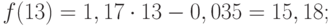
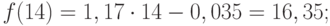
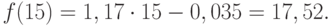
Сравнивая результаты точечных прогнозных оценок, полученных разными способами, выявляем, что данные отличаются незначительно, таким образом, в любом из способов расчета присутствует определенная погрешность (ошибка) прогноза ().
Используя значения временного ряда Задания 1 согласно вашего варианта, вычислить точечный прогноз на 4 шага вперед. Продлить линию тренда на 4 прогнозных значения, вывести уравнение тренда, определить эти значения с помощью функции ПРЕДСКАЗ() или ТЕНДЕНЦИЯ(), а также по выражению функции тренда f(t ), полученному по методу наименьших квадратов в Задании 1. Сравнить полученные результаты.
Анализ временных рядов
Составляющие временного ряда
При анализе временного ряда выделяют три составляющие: тренд, сезонность и шум. Тренд — это общая тенденция, сезонность, как следует из названия — влияния периодичности (день недели, время года и т.д.) и, наконец, шум — это случайные факторы.
Что бы понять отличие этих трёх величин, смоделируем функцию расстояния от земли до луны. Известно, что в среднем луна каждый год отдаляется на 4 см — это тренд, в течение дня луна совершает оборот вокруг земли и расстояние колеблется от
405400 км — это сезонность. Шум — это «случайные» факторы, например, влияние других планет. Если мы изобразим сумму этих трёх графиков, то мы получим временной ряд — функцию, показывающую изменение расстояния от земли до луны во времени.
Тренд. Методы сглаживания
Методы сглаживания необходимы для удаления шума из временного ряда. Существуют различные способы сглаживания, основные — это метод скользящей средней и метод экспоненциального сглаживания.
Метод скользящей средней
Идея метода скользящего среднего заключается в смещении точки графика на среднее значение некоторого интервала. В качестве интервала берут нечётное количество участков, например, три — предыдущий, текущий и следующий периоды, находится среднее и принимается в качестве сглаженного значения:
У данного метода есть проблема: случайное высокое или низкое значение сильно влияют на скользящую линию. В качестве решения были введены веса. Для распределение веса используют оконные функции, основные оконные функции — это окно Дирихле (прямоугольная функция), В-сплайны, полиномы, синусоидальные и косинусоидальные:
Минусы использования скользящей средней — это сложность вычислений и некорректные данные на концах графика.
| Исходные данные | Скользящая средняя | Взвешенная скользящая средняя (синусоидальное окно, n=5) | Взвешенная скользящая средняя (окно Ганна, n=5) |
| 800 | 879 | 283 | 0 |
| 957 | 960 | 492 | 400 |
| 1122 | 1038 | 579 | 479 |
| 1274 | 1191 | 675 | 561 |
| 1412 | 1317 | 766 | 637 |
| 1460 | 1427 | 836 | 706 |
| 1562 | 1545 | 891 | 730 |
| 1745 | 1734 | 957 | 781 |
| 2168 | 1627 | 1096 | 873 |
| 1034 | 1914 | 1033 | 1084 |
| 2710 | 1909 | 1121 | 517 |
| 1724 | 1921 | 1165 | 1355 |
| 2216 | 2204 | 1302 | 862 |
| 2165 | 2087 | 1241 | 1108 |
| 2242 | 1950 | 1329 | 1083 |
| 1175 | 1796 | 1151 | 1121 |
| 1600 | 2054 | 973 | 588 |
| 3197 | 2278 | 1173 | 800 |
| 3140 | 2783 | 1637 | 1599 |
| 3194 | 3177 | 2553 | 1570 |
| Таблица 1. Сглаживание методом скользящей средней | |||
Как видно из графика, увеличение n выдаёт более плавную функцию, таким образом нивелируя более мелкие колебания во временном ряду. Обратите внимание, что при сглаживании не имеет значения, совпадает график среднего с графиком данных или нет, целью является построение правильной формы.
Метод экспоненциального сглаживания
Метод экспоненциального сглаживания получил своё название потому, что в сглаженной функции экспоненциально убывает влияние предыдущего периода с неким коэффициентом чувствительности α. Сглаженное значение находится как разница между предыдущим действительным значением и рассчитанным значением:
Коэффициент чувствительности, α, выбирается между 0 и 1, в качестве базиса используют значение 0,3. Если есть достаточная выборка, то коэффициент подбирается путём оптимизации.
| Исходные данные | Экспоненциальное сглаживание, α=0,1 | Экспоненциальное сглаживание, α=0,6 | |
| 800 | 800 | 800 | |
| 957 | -640 | 160 | |
| 1122 | 672 | 510 | |
| 1274 | -493 | 469 | |
| 1412 | 571 | 577 | |
| 1460 | -373 | 616 | |
| 1562 | 482 | 630 | |
| 1745 | -278 | 685 | |
| 2168 | 425 | 773 | |
| 1034 | -166 | 992 | |
| 2710 | 253 | 224 | |
| 1724 | 43 | 1536 | |
| 2216 | 134 | 420 | |
| 2165 | 101 | 1162 | |
| 2242 | 126 | 834 | |
| 1175 | 111 | 1012 | |
| 1600 | 18 | 300 | |
| 3197 | 144 | 840 | |
| 3140 | 190 | 1582 | |
| 3194 | 143 | 1251 | |
| Таблица 2. Экспоненциальное сглаживание | |||
Методы прогнозирования
Методы прогнозирования основываются на выявлении тенденции во временном ряду и последующем использовании найденного значения для предсказания будущих значений. В методах прогнозирования выделяют тренд и сезонность, в общем случае, все типы сезонности могут быть найдены последовательными итерациями. Например, при анализе данных за год, можно выделить сезонность времени года, а в оставшемся тренде найти сезонность по дням недели и так далее.
Двойное экспоненциальное сглаживание
Двойное экспоненциальное сглаживание выдаёт сглаженное значение уровня и тенденции.
Внимание! Может возникнуть путаница, метод Хольт-Винтерса отличается терминами: тренд, сезонность и шум соответственно называются уровень, тренд и сезонность.
Smooth — сглаживание, сглаженный уровень на период τ, sτ, зависит от значения уровня на текущий период (Dτ), тренда за предыдущий период (tτ-1) и рассчитанного сглаженного значения на предыдущий период (sτ-1):
sτ = αDτ + (1 — α)(sτ-1 + tτ-1)
Trend — тенденция, тренд на период τ, tτ, зависит от рассчитанного сглаженного значения за предыдущий и текущий периоды (sτ и sτ-1) и от предыдущей тенденции:
tτ = β(sτ-sτ-1) + (1-β)tτ-1
Рассчитанные по данным формулам уровень и тренд могут быть использованы в прогнозировании:
D’τ+h = sτ + h·tτ
При расчёте, значения s и t для первого периода назначают s1 = D1 и t=0
Метод Хольт-Винтерса
Метод Хольт-Винтерса включает в себя сезонную составляющую, т.е. периодичность. Существуют две разновидности метода — мультипликативный и аддитивный. В отличие от двойного экспоненциального сглаживания, метод Хольт-Винтерса изучает также влияние периодичности.
Общая идея нахождения значений сглаженного уровня, тренда и периодичности заключается в следующем: сглаженный уровень (s — smooth, иногда используют l — level) — это базовый уровень значений, тренд (t — trend) — это показатель скорости роста, разница между сглаженными значениями текущего и предыдущего периода. Для изучения периодичности (p — period), мы разбиваем данные на периоды размером k и выделяем влияние каждого элемента (1,2. k) периода на сглаженный уровень.
Для более точных расчётов вводится показатель обратной связи.
В общем понимании, обратная связь — это влияние предыдущих значений на новые: например, когда Вы начинаете говорить, Вы регулируете громкость своего голоса в зависимости от того, что слышат Ваши уши — это и есть обратная связь.
Для начала расчётов, значения s, t и k, в самом простом виде, могут быть выбраны как sτ = Dτ, t = 0, p = 0.
Для прогнозирования используется следующая формула:
Мультипликативный метод Хольт-Винтерса
Мультипликативный метод отличается от аддитивного тем, что параметры, влияющие на периодичность и сглаженный уровень рассчитываются отношением:
Для прогнозирования используется следующая формула:
Метод Хольт-Винтерса в excel
Таблица для скачивания в форматах ods и xls.
Качество прогнозирования
Проверка качества прогнозирования возможна в случае наличия достаточной выборки и является важной проверкой на достоверность прогноза, для проверки и оптимизации значений α, β и γ необходимо построить прогноз на существующие данные, например, если у нас в наличии данные за пять лет и мы хотим предсказать следующий год, то необходимо построить модель на первых четырёх годах, проверить и оптимизировать коэффициенты для минимизации ошибки между прогнозом и данными на 5й год. После оптимизации модель может быть перестроена с учётом последнего периода для повышения точности, далее следует построение прогноза.
Методы оптимизации будут описаны в отдельной статье, ниже представлен пример прогнозирования методом Хольт Винтерса.
Полное руководство по анализу и прогнозированию временных рядов
Дата публикации Aug 7, 2019

Желаем ли мы предсказать тенденцию на финансовых рынках или потребление электроэнергии, время является важным фактором, который теперь необходимо учитывать в наших моделях. Например, было бы интересно предсказать, в какое время в течение дня будет наблюдаться пиковое потребление электроэнергии, например, для корректировки цены или производства электроэнергии.
Войтивременная последовательность, Временной ряд — это просто ряд точек данных, упорядоченных во времени. Во временных рядах время часто является независимой переменной, и цель обычно состоит в том, чтобы сделать прогноз на будущее.
Однако при работе с временными рядами возникают другие аспекты.
Этостационарный?
Есть лисезонность?
Целевая переменнаяавтокоррелированные?
В этом посте я представлю различные характеристики временных рядов и то, как мы можем смоделировать их для получения точных (насколько это возможно) прогнозов.
Предсказывать будущее сложно.
автокорреляция
Неформально,автокорреляцияэто сходство между наблюдениями как функция временного интервала между ними.

Выше приведен пример автокорреляционного графика. При внимательном рассмотрении вы понимаете, что первое значение и 24-е значение имеют высокую автокорреляцию. Точно так же 12-е и 36-е наблюдения сильно коррелируют. Это означает, что мы будем находить очень похожие значения в каждые 24 единицы времени.
Обратите внимание, как график выглядит как синусоидальная функция. Это подсказка длясезонности,и вы можете найти его значение, найдя период на графике выше, который даст 24 часа.
Сезонность
Сезонностьотносится к периодическим колебаниям. Например, потребление электроэнергии высокое в течение дня и низкое в ночное время, или продажи в Интернете увеличиваются в течение Рождества, прежде чем снова замедляться.

Как вы можете видеть выше, существует четкая ежедневная сезонность. Каждый день вы видите пик к вечеру, а самые низкие точки — начало и конец каждого дня.
Помните, что сезонность также может быть получена из графика автокорреляции, если он имеет синусоидальную форму. Просто посмотрите на период, и он дает продолжительность сезона.
стационарность
стационарностьявляется важной характеристикой временных рядов. Временной ряд называется стационарным, если его статистические свойства не изменяются со временем. Другими словами, это имеетпостоянное среднее и дисперсияи ковариация не зависит от времени.

Глядя снова на тот же сюжет, мы видим, что процесс выше является стационарным. Среднее значение и дисперсия не меняются со временем.
Зачастую цены на акции не являются стационарным процессом, поскольку мы можем наблюдать растущую тенденцию или ее волатильность со временем может возрасти (это означает, что дисперсия меняется).
В идеале мы хотим иметь стационарные временные ряды для моделирования. Конечно, не все они являются стационарными, но мы можем сделать различные преобразования, чтобы сделать их стационарными.
Как проверить, если процесс является стационарным
Возможно, вы заметили в заголовке сюжета вышеДики-Фуллера.Это статистический тест, который мы проводим, чтобы определить, является ли временной ряд стационарным или нет.
Не вдаваясь в технические подробности теста Дики-Фуллера, он проверяет нулевую гипотезу о наличии единичного корня.
Если это так, тор>0, а процесс не стационарный.
Иначе,р =0, нулевая гипотеза отклоняется, и процесс считается стационарным.
Как пример, процесс ниже не является стационарным. Обратите внимание, что среднее значение не является постоянным во времени.

Моделирование временных рядов
Есть много способов смоделировать временной ряд, чтобы делать прогнозы. Здесь я представлю:
- скользящее среднее
- экспоненциальное сглаживание
- ARIMA
Скользящая средняя
Модель скользящего среднего — это, вероятно, самый наивный подход к моделированию временных рядов. Эта модель просто утверждает, что следующее наблюдение является средним значением всех прошлых наблюдений.
Несмотря на простоту, эта модель может быть на удивление хорошей и представляет собой хорошую отправную точку.
В противном случае скользящее среднее можно использовать для определения интересных тенденций в данных. Мы можем определитьокноприменить модель скользящего среднего кгладкий; плавныйВременные ряды и выделить различные тенденции.

На графике выше мы применили модель скользящего среднего к 24-часовому окну. Зеленая линиясглаженныйвременной ряд, и мы можем видеть, что есть 2 пика в 24-часовой период.
Конечно, чем длиннее окно, темгладкойтенденция будет. Ниже приведен пример скользящей средней в меньшем окне

Экспоненциальное сглаживание
Экспоненциальное сглаживание использует логику, аналогичную скользящей средней, но на этот разуменьшение весаприсваивается каждому наблюдению. Другими словами,меньшее значениедается наблюдениям по мере продвижения от настоящего.
Математически экспоненциальное сглаживание выражается как:

Вот,альфаэтокоэффициент сглаживаниякоторый принимает значения от 0 до 1. Он определяет, какбыстровес уменьшается для предыдущих наблюдений.

Из приведенного выше графика темно-синяя линия представляет экспоненциальное сглаживание временного ряда с использованием коэффициента сглаживания 0,3, в то время как оранжевая линия использует коэффициент сглаживания 0,05.
Как видите, чем меньше коэффициент сглаживания, тем более плавным будет временной ряд. Это имеет смысл, потому что когда коэффициент сглаживания приближается к 0, мы приближаемся к модели скользящего среднего.
Двойное экспоненциальное сглаживание
Двойное экспоненциальное сглаживание используется при наличии тенденции во временном ряду. В этом случае мы используем эту технику, которая является просто рекурсивным использованием экспоненциального сглаживания дважды.

Вот,бетаэтокоэффициент сглаживания трендаи принимает значения от 0 до 1.
Ниже вы можете увидеть, как разные значенияальфаа такжебетавлияет на форму временного ряда.

Трип экспоненциальное сглаживание
Этот метод расширяет двойное экспоненциальное сглаживание, добавляякоэффициент сезонного сглаживания, Конечно, это полезно, если вы заметили сезонность в своих временных рядах.
Математически тройное экспоненциальное сглаживание выражается как:

гдегаммаявляется фактором сезонного сглаживания иLэто длина сезона.
Сезонная авторегрессионная интегрированная модель скользящего среднего (SARIMA)
SARIMA на самом деле является комбинацией более простых моделей для создания сложной модели, которая может моделировать временные ряды, демонстрирующие нестационарные свойства и сезонность.
Во-первых, у нас естьМодель авторегрессии AR (p), Это в основном регрессия временного ряда на себя. Здесь мы предполагаем, что текущее значение зависит от предыдущих значений с некоторой задержкой. Принимает параметрпкоторый представляет собой максимальное отставание. Чтобы найти его, мы смотрим на график частичной автокорреляции и выявляем лаг, после которого большинство лагов не являются значимыми.
В приведенном ниже примерепбудет 4.

Затем мы добавляеммодель скользящего среднего MA (q), Это принимает параметрQкоторая представляет собой наибольшее отставание, после которого другие лаги не имеют существенного значения на графике автокорреляции.
Ниже,Qбудет 4.

После мы добавляемпорядок интеграцииМне бы), Параметрdпредставляет количество различий, необходимых для того, чтобы сделать серию стационарной.
Наконец, мы добавляем последний компонент:сезонность S (P, D, Q, s), гдеsпросто длина сезона. Кроме того, этот компонент требует параметровпа такжеQкоторые так же, какпа такжеQ, но для сезонной составляющей. В заключение,Dпорядок сезонной интеграции, представляющий количество различий, необходимых для удаления сезонности из ряда.
Объединяя все, мы получаемСАРИМА (p, d, q) (P, D, Q, s)модель.
Основной вывод: перед моделированием с помощью SARIMA мы должны применить преобразования к нашему временному ряду, чтобы устранить сезонность и любое нестационарное поведение.
Это было много теории, чтобы обернуть нашу голову вокруг! Давайте применим методы, обсужденные выше, в нашем первом проекте.
Мы попытаемся предсказать цену акций конкретной компании. Теперь прогнозировать цену акций практически невозможно. Тем не менее, это остается забавным упражнением, и это будет хороший способ практиковать то, что мы узнали.
Проект 1 — Прогнозирование цены акций
Мы будем использовать историческую цену акций Фонда Новой Германии (GF), чтобы попытаться предсказать цену закрытия в следующие пять торговых дней.
Вы можете взять набор данных и блокнотВот,
Как всегда, я настоятельно рекомендую вам написать код! Начни свой блокнот и пойдем!
Вы точно не разбогатеете, пытаясь предсказать фондовый рынок
Импортировать данные
Во-первых, мы импортируем некоторые библиотеки, которые будут полезны на протяжении всего нашего анализа. Также мы определяемсредняя средняя процентная ошибка (MAPE), так как это будет нашей метрикой ошибки.
Затем мы импортируем наш набор данных, и мы предшествуем первым десяти записям, и вы должны получить:

Как видите, у нас есть несколько записей, касающихся акций, отличных от фонда Новой Германии (GF). Кроме того, у нас есть запись, касающаяся внутридневной информации, но нам нужна только информация на конец дня (EOD).
Очистить данные
Сначала мы удаляем ненужные записи.
Затем мы удаляем ненужные столбцы, поскольку исключительно хотим сосредоточиться на цене закрытия акций.
Если вы просматриваете набор данных, вы должны увидеть:

Потрясающе! Мы готовы к поисковому анализу данных!
Исследовательский анализ данных (EDA)
Мы строим цену закрытия за весь период времени нашего набора данных.
Вы должны получить:

Очевидно, вы видите, что это нестационарныйпроцесс, и трудно сказать, есть ли какая-тосезонность,
Скользящая средняя
Давайте использоватьскользящее среднеемодель, чтобы сгладить наш временной ряд. Для этого мы будем использовать вспомогательную функцию, которая будет запускать модель скользящего среднего в заданном временном окне и строить график сглаженной кривой результата:
Используя временное окно 5 дней, мы получаем:

Как видите, мы едва можем увидеть тренд, потому что он слишком близок к реальной кривой. Давайте посмотрим на результат сглаживания за предыдущий месяц и за предыдущий квартал.


Тенденции легче определить сейчас. Обратите внимание, как 30-дневный и 90-дневный тренд показывают нисходящую кривую в конце. Это может означать, что акции могут понизиться в следующие дни.
Экспоненциальное сглаживание
Теперь давайте использоватьэкспоненциальное сглаживаниечтобы увидеть, может ли он поднять лучшую тенденцию.
Здесь мы используем 0,05 и 0,3 в качестве значений длякоэффициент сглаживания, Не стесняйтесь попробовать другие значения и посмотреть, каков результат.

Как вы можете видеть,альфазначение 0,05 сглаживало кривую, одновременно улавливая большинство восходящих и нисходящих трендов.
Теперь давайте использоватьдвойное экспоненциальное сглаживание.
Двойное экспоненциальное сглаживание

Опять же, экспериментируйте с разнымиальфаа такжебетакомбинации, чтобы получить лучше выглядящие кривые.
моделирование
Как было указано выше, мы должны превратить нашу серию в стационарный процесс, чтобы смоделировать ее. Поэтому давайте применим тест Дики-Фуллера, чтобы проверить, является ли это стационарным процессом:
Тебе следует увидеть:

По критерию Дики-Фуллера временной ряд, что неудивительно, нестационарен. Также, глядя на график автокорреляции, мы видим, что он очень высокий, и кажется, что нет явной сезонности.
Поэтому, чтобы избавиться от высокой автокорреляции и сделать процесс стационарным, давайте возьмем первое отличие (строка 23 в блоке кода). Мы просто вычитаем временной ряд из себя с задержкой в один день, и мы получаем:

Потрясающе! Наша серия теперь стационарная, и мы можем начать моделирование!
Sarima
Теперь для SARIMA мы сначала определим несколько параметров и диапазон значений для других параметров, чтобы сгенерировать список всех возможных комбинаций p, q, d, P, Q, D, s.
Теперь в приведенной выше ячейке кода у нас есть 625 различных комбинаций! Мы попробуем каждую комбинацию и обучим SARIMA каждой, чтобы найти лучшую модель. Это может занять некоторое время в зависимости от вычислительной мощности вашего компьютера.
Как только это будет сделано, мы распечатаем краткую информацию о лучшей модели, и вы должны увидеть:

Потрясающе! Наконец, мы прогнозируем цену закрытия следующих пяти торговых дней и оцениваем MAPE модели.
В этом случае у нас MAPE 0,79%, что очень хорошо!
Сравните прогнозируемую цену с фактическими данными
Теперь, чтобы сравнить наш прогноз с фактическими данными, мы берем финансовые данные изYahoo Financeи создайте фрейм данных.
Затем мы строим график, чтобы увидеть, насколько мы далеки от фактических цен закрытия:

Кажется, мы немного ошиблись в наших прогнозах. На самом деле, прогнозируемая цена по существу плоская, что означает, что наша модель, вероятно, не работает хорошо.
Опять же, это не из-за нашей процедуры, а из-за того, что прогнозировать цены на акции практически невозможно.
Из первого проекта мы изучили всю процедуру создания временного ряда, прежде чем использовать SARIMA для моделирования. Это долгий и утомительный процесс, с множеством ручных настроек.
Теперь давайте представим Пророка в Facebook. Это инструмент прогнозирования, доступный как на Python, так и на языке R. Этот инструмент позволяет как экспертам, так и не экспертам производить высококачественные прогнозы с минимальными усилиями.
Давайте посмотрим, как мы можем использовать его во втором проекте!
Проект 2 — Предсказать качество воздуха с Пророком
Название говорит само за себя: мы будем использовать Prophet, чтобы помочь нам предсказать качество воздуха!
Полный блокнот и набор данных можно найтиВот,
Давайте сделаем некоторые прогнозы!
Импортировать данные
Как всегда, мы начинаем с импорта некоторых полезных библиотек Затем мы печатаем первые пять строк:

Как видите, набор данных содержит информацию о концентрациях различных газов. Они были записаны в каждый час для каждого дня. Вы можете найти описание всех функцийВот,
Если вы исследуете набор данных немного подробнее, вы заметите, что существует множество экземпляров значения -200. Конечно, не имеет смысла иметь отрицательную концентрацию, поэтому нам нужно будет очистить данные перед моделированием.
Поэтому нам нужно очистить данные.
Очистка данных и разработка функций
Здесь мы начнем с анализа нашего столбца даты, чтобы превратить его в «даты».
Затем мы превращаем все измерения в поплавки.
После этого мы агрегируем данные по дням, беря среднее значение каждого измерения.
На данный момент у нас еще есть некоторыеNaNот которого мы должны избавиться. Поэтому мы удаляем столбцы, которые имеют более 8NaN, Таким образом, мы можем затем удалить строки, содержащиеNaNзначения без потери слишком большого количества данных.
Наконец, мы агрегируем данные по неделям, потому что это даст более плавную тенденцию для анализа.
Мы можем построить тенденции каждого химического вещества. Здесь мы показываем, что NOx.

Оксиды азота очень вредны, так как они реагируют на смог и кислотные дожди, а также отвечают за образование мелких частиц и озона на уровне земли. Они оказывают неблагоприятное воздействие на здоровье, поэтому концентрация NOx является ключевой характеристикой качества воздуха.
моделирование
Мы сосредоточимся исключительно на моделировании концентрации NOx. Поэтому мы удалим все остальные несоответствующие столбцы.
Затем мы импортируем Пророка.
Пророк требует, чтобы столбец даты был названД.С.и особенность столбца, который будет названYпоэтому мы вносим соответствующие изменения.
На данный момент наши данные выглядят так:

Затем мы определяем тренировочный набор. Для этого мы продержимся последние 30 записей для прогнозирования и проверки.
После этого мы просто инициализируем Prophet, подгоняем модель к данным и делаем прогнозы!
Вы должны увидеть следующее:

Вот,yhatпредставляет прогноз, в то время какyhat_lowerа такжеyhat_upperпредставляют нижнюю и верхнюю границу прогноза соответственно.
Пророк позволяет легко составить прогноз и мы получим:

Как вы можете видеть, Пророк просто использовал прямую нисходящую линию, чтобы предсказать концентрацию NOx в будущем.
Затем мы проверяем, есть ли у временного ряда какие-либо интересные особенности, такие как сезонность:

Здесь Пророк выявил только тенденцию к снижению без сезонности.
Оценивая производительность модели путем вычисления ее средней абсолютной процентной ошибки (MAPE) и средней абсолютной ошибки (MAE), мы видим, что MAPE составляет 13,86%, а MAE — 109,32, что не так уж и плохо! Помните, что мы не настроили модель вообще.
Наконец, мы просто строим прогноз с его верхней и нижней границами:

Поздравляю с завершением! Это была очень длинная, но информативная статья. Вы узнали, как надежно анализировать и моделировать временные ряды, и применили свои знания в двух разных проектах.
Я надеюсь, что вы нашли эту статью полезной, и я надеюсь, что вы вернетесь к ней.
Ссылка: Большое спасибо за этостатьяза удивительное введение в анализ временных рядов!
http://k-tree.ru/articles/statistika/prognozirovanie/analiz_vremennih_ryadov
http://www.machinelearningmastery.ru/the-complete-guide-to-time-series-analysis-and-forecasting-70d476bfe775/