Уравнение нелинейной регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Виды нелинейной регрессии
| Вид | Класс нелинейных моделей |
| Нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам |
| Нелинейные по оцениваемым параметрам |
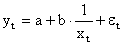
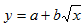
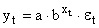
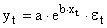

Здесь ε — случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.
Уравнению регрессии первого порядка — это уравнение парной линейной регрессии.
Уравнение регрессии второго порядка это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
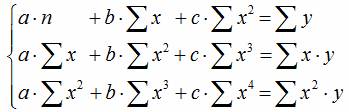
Уравнение регрессии третьего порядка соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
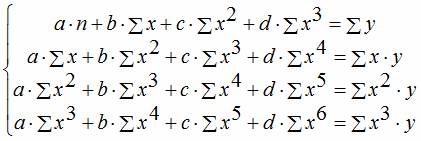
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания):
- Замена переменных.
- Логарифмирование обеих частей уравнения.
- Комбинированный.
| y = f(x) | Преобразование | Метод линеаризации |
| y = b x a | Y = ln(y); X = ln(x) | Логарифмирование |
| y = b e ax | Y = ln(y); X = x | Комбинированный |
| y = 1/(ax+b) | Y = 1/y; X = x | Замена переменных |
| y = x/(ax+b) | Y = x/y; X = x | Замена переменных. Пример |
| y = aln(x)+b | Y = y; X = ln(x) | Комбинированный |
| y = a + bx + cx 2 | x1 = x; x2 = x 2 | Замена переменных |
| y = a + bx + cx 2 + dx 3 | x1 = x; x2 = x 2 ; x3 = x 3 | Замена переменных |
| y = a + b/x | x1 = 1/x | Замена переменных |
| y = a + sqrt(x)b | x1 = sqrt(x) | Замена переменных |
Пример . По данным, взятым из соответствующей таблицы, выполнить следующие действия:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессии.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью F-критерия Фишера статистическую надежность результатов регрессионного моделирования. По значениям характеристик, рассчитанных в пп. 4, 5 и данном пункте, выбрать лучшее уравнение регрессии и дать его обоснование.
- Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 15% от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости α=0,05 .
- Оценить полученные результаты, выводы оформить в аналитической записке.
| Год | Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. — трлн. руб.), y | Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. — тыс. руб.), х |
| 1995 | 872 | 515,9 |
| 2000 | 3813 | 2281,1 |
| 2001 | 5014 | 3062 |
| 2002 | 6400 | 3947,2 |
| 2003 | 7708 | 5170,4 |
| 2004 | 9848 | 6410,3 |
| 2005 | 12455 | 8111,9 |
| 2006 | 15284 | 10196 |
| 2007 | 18928 | 12602,7 |
| 2008 | 23695 | 14940,6 |
| 2009 | 25151 | 16856,9 |
Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии. Получим таблицу следующего вида.
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
Степенное уравнение регрессии имеет вид y = a x b
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) — 49694.9535
Эконометрика

ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
ВСЕРОССИЙСКИЙ ЗАОЧНЫЙ ФИНАНСОВО-ЭКОНОМИЧЕСКИЙ
Кафедра экономико-метематических моделей
Тема 4. Множественная регрессия.
Вопросы
1. Нелинейная регрессия. Нелинейные модели и их линеаризация.
Нелинейная регрессия
При рассмотрении зависимости экономических показателей на основе реальных статистических данных с использованием аппарата теории вероятности и математической статистики можно сделать выводы, что линейные зависимости встречаются не так часто. Линейные зависимости рассматриваются лишь как частный случай для удобства и наглядности рассмотрения протекаемого экономического процесса. Чаще встречаются модели которые отражают экономические процессы в виде нелинейной зависимости.
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций.
Различают два класса нелинейных регрессий:
- регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам: регрессии, нелинейные по оцениваемым параметрам.
Нелинейные регрессии по включаемым в нее объясняющим переменным, но линейные по оцениваемым параметрам
Данный класс нелинейных регрессий включает уравнения, в которых зависимая переменная линейно связана с параметрами. Примером могут служить:
полиномы разных степеней
 (полином k-й степени)
(полином k-й степени)
 и равносторонняя гипербола
и равносторонняя гипербола
 .
.
При оценке параметров регрессий нелинейных по объясняющим переменным используется подход, именуемый «замена переменных». Суть его состоит в замене «нелинейных» объясняющих переменных новыми «линейными» переменными и сведение нелинейной регрессии к линейной регрессии. К новой «преобразованной» регрессии может быть применен обычный метод наименьших квадратов (МНК).
Полином любого порядка сводится к линейной регрессии с ее методами оценивания параметров и проверки гипотез.
Среди нелинейной полиноминальной регрессии чаще всего используется парабола второй степени; в отдельных случаях — полином третьего порядка. Ограничение в использовании полиномов более высоких степеней связаны с требованием однородности исследуемой совокупности: чем выше порядок полинома, тем больше изгибов имеет кривая и, соответственно, менее однородна совокупность по результативному признаку.
Равносторонняя гипербола, для оценки параметров которой используется тот же подход «замены переменных» (1/x заменяют на переменную z) хорошо известна в эконометрике.
Она может быть использована, например, для характеристики связи удельных расходов сырья, материалов и топлива с объемом выпускаемой продукции. Также примером использования равносторонней гиперболы являются кривые Филлипса и Энгеля..
Регрессии нелинейные по оцениваемым параметрам
К данному классу регрессий относятся уравнения, в которых зависимая переменная нелинейно связана с параметрами. Примером таких нелинейных регрессий являются функции:
• степенная —  ;
;
• показательная —  ;
;
• экспоненциальная — 
Если нелинейная модель внутренне линейна, то она с помощью соответствующих преобразований может быть приведена к линейному виду (например, логарифмированием и заменой переменных). Если же нелинейная модель внутренне нелинейна, то она не может быть сведена к линейной функции и для оценки её параметров используются итеративные процедуры, успешность которых зависит от вида уравнений и особенностей применяемого итеративного подхода.
Примером нелинейной по параметрам регрессии внутренне линейной является степенная функция, которая широко используется в эконометрических исследованиях при изучении спроса от цен:  , где у — спрашиваемое количество; х — цена;
, где у — спрашиваемое количество; х — цена;
Данная модель нелинейна относительно оцениваемых параметров, т. к. включает параметры а и b неаддитивно. Однако ее можно считать внутренне линейной, ибо логарифмирование данного уравнения по основанию е приводит его к линейному виду  . Заменив переменные и параметры, получим линейную регрессию, оценки параметров которой а и b могут быть найдены МНК.
. Заменив переменные и параметры, получим линейную регрессию, оценки параметров которой а и b могут быть найдены МНК.
Широкое использование степенной функции связано это с тем, что параметр b в ней имеет четкое экономическое истолкование, т. е. он является коэффициентом эластичности. Это значит, что величина коэффициента b показывает, на сколько процентов изменится в среднем результат, если фактор изменится на 1 %.
Коэффициент эластичности можно определять и при наличии других форм связи, но только для степенной функции он представляет собой постоянную величину, равную параметру b.
По семи предприятиям легкой промышленности региона получена информация, характеризующая зависимость объема выпуска продукции (Y, млн. руб.) от объема капиталовложений ( Х, млн. руб. ).
R — значит регрессия
Статистика в последнее время получила мощную PR поддержку со стороны более новых и шумных дисциплин — Машинного Обучения и Больших Данных. Тем, кто стремится оседлать эту волну необходимо подружится с уравнениями регрессии. Желательно при этом не только усвоить 2-3 приемчика и сдать экзамен, а уметь решать проблемы из повседневной жизни: найти зависимость между переменными, а в идеале — уметь отличить сигнал от шума.

Для этой цели мы будем использовать язык программирования и среду разработки R, который как нельзя лучше приспособлен к таким задачам. Заодно, проверим от чего зависят рейтинг Хабрапоста на статистике собственных статей.
Введение в регрессионный анализ
Если имеется корреляционная зависимость  между переменными y и x , возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения
между переменными y и x , возникает необходимость определить функциональную связь между двумя величинами. Зависимость среднего значения  называется регрессией y по x .
называется регрессией y по x .
Основу регрессионного анализа составляет метод наименьших квадратов (МНК), в соответствии с которым в качестве уравнения регресии берется функция  такая, что сумма квадратов разностей
такая, что сумма квадратов разностей  минимальна.
минимальна.

Карл Гаусс открыл, или точнее воссоздал, МНК в возрасте 18 лет, однако впервые результаты были опубликованы Лежандром в 1805 г. По непроверенным данным метод был известен еще в древнем Китае, откуда он перекочевал в Японию и только затем попал в Европу. Европейцы не стали делать из этого секрета и успешно запустили в производство, обнаружив с его помощью траекторию карликовой планеты Церес в 1801 г.
Вид функции , как правило, определен заранее, а с помощью МНК подбираются оптимальные значения неизвестных параметров. Метрикой рассеяния значений  вокруг регрессии
вокруг регрессии  является дисперсия.
является дисперсия.

- k — число коэффициентов в системе уравнений регрессии.
Чаще всего используется модель линейной регрессии, а все нелинейные зависимости приводят к линейному виду с помощью алгебраических ухищрений, различных преобразования переменных y и x .
Линейная регрессия
Уравнения линейной регрессии можно записать в виде

В матричном виде это выгладит

- y — зависимая переменная;
- x — независимая переменная;
- β — коэффициенты, которые необходимо найти с помощью МНК;
- ε — погрешность, необъяснимая ошибка и отклонение от линейной зависимости;

Случайная величина может быть интерпретирована как сумма из двух слагаемых:
 — полная дисперсия (TSS).
— полная дисперсия (TSS).- — объясненная часть дисперсии (ESS).
- — остаточная часть дисперсии (RSS).
 — объясненная часть дисперсии (ESS).
— объясненная часть дисперсии (ESS). — остаточная часть дисперсии (RSS).
— остаточная часть дисперсии (RSS).Еще одно ключевое понятие — коэффициент корреляции R 2 .

Ограничения линейной регрессии
Для того, чтобы использовать модель линейной регрессии необходимы некоторые допущения относительно распределения и свойств переменных.
- Линейность, собственно. Увеличение, или уменьшение вектора независимых переменных в k раз, приводит к изменению зависимой переменной также в k раз.
- Матрица коэффициентов обладает полным рангом, то есть векторы независимых переменных линейно независимы.
- Экзогенность независимых переменных — . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
- Однородность дисперсии и отсутствие автокорреляции. Каждая εi обладает одинаковой и конечной дисперсией σ 2 и не коррелирует с другой εi. Это ощутимо ограничивает применимость модели линейной регрессии, необходимо удостовериться в том, что условия соблюдены, иначе обнаруженная взаимосвязь переменных будет неверно интерпретирована.
 . Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.
. Это требование означает, что математическое ожидание погрешности никоим образом нельзя объяснить с помощью независимых переменных.Как обнаружить, что перечисленные выше условия не соблюдены? Ну, во первых довольно часто это видно невооруженным глазом на графике.
Неоднородность дисперсии 
При возрастании дисперсии с ростом независимой переменной имеем график в форме воронки.

Нелинейную регрессии в некоторых случая также модно увидеть на графике довольно наглядно.
Тем не менее есть и вполне строгие формальные способы определить соблюдены ли условия линейной регрессии, или нарушены.
- Автокорреляция проверяется статистикой Дарбина-Уотсона (0 ≤ d ≤ 4). Если автокорреляции нет, то значения критерия d≈2, при позитивной автокорреляции d≈0, при отрицательной — d≈4.
- Неоднородность дисперсии — Тест Уайта, , при \chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же можно еще применить тест Бройша-Пагана.
- Мультиколлинеарность — нарушения условия об отсутствии взаимной линейной зависимости между независимыми переменными. Для проверки часто используют VIF-ы (Variance Inflation Factor).
 , при
, при  \chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же
\chi<^2>_<\alpha;m-1>$» data-tex=»inline»/> нулевая гипотеза отвергается и констатируется наличие неоднородной дисперсии. Используя ту же  можно еще применить тест Бройша-Пагана.
можно еще применить тест Бройша-Пагана.
В этой формуле  — коэффициент взаимной детерминации между
— коэффициент взаимной детерминации между  и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
и остальными факторами. Если хотя бы один из VIF-ов > 10, вполне резонно предположить наличие мультиколлинеарности.
Почему нам так важно соблюдение всех выше перечисленных условий? Все дело в Теореме Гаусса-Маркова, согласно которой оценка МНК является точной и эффективной лишь при соблюдении этих ограничений.
Как преодолеть эти ограничения
Нарушения одной или нескольких ограничений еще не приговор.
- Нелинейность регрессии может быть преодолена преобразованием переменных, например через функцию натурального логарифма ln .
- Таким же способом возможно решить проблему неоднородной дисперсии, с помощью ln , или sqrt преобразований зависимой переменной, либо же используя взвешенный МНК.
- Для устранения проблемы мультиколлинеарности применяется метод исключения переменных. Суть его в том, что высоко коррелированные объясняющие переменные устраняются из регрессии, и она заново оценивается. Критерием отбора переменных, подлежащих исключению, является коэффициент корреляции. Есть еще один способ решения данной проблемы, который заключается в замене переменных, которым присуща мультиколлинеарность, их линейной комбинацией. Этим весь список не исчерпывается, есть еще пошаговая регрессия и другие методы.
К сожалению, не все нарушения условий и дефекты линейной регрессии можно устранить с помощью натурального логарифма. Если имеет место автокорреляция возмущений к примеру, то лучше отступить на шаг назад и построить новую и лучшую модель.
Линейная регрессия плюсов на Хабре
Итак, довольно теоретического багажа и можно строить саму модель.
Мне давно было любопытно от чего зависит та самая зелененькая цифра, что указывает на рейтинг поста на Хабре. Собрав всю доступную статистику собственных постов, я решил прогнать ее через модель линейно регрессии.
Загружает данные из tsv файла.
- points — Рейтинг статьи
- reads — Число просмотров.
- comm — Число комментариев.
- faves — Добавлено в закладки.
- fb — Поделились в социальных сетях (fb + vk).
- bytes — Длина в байтах.
Вопреки моим ожиданиям наибольшая отдача не от количества просмотров статьи, а от комментариев и публикаций в социальных сетях. Я также полагал, что число просмотров и комментариев будет иметь более сильную корреляцию, однако зависимость вполне умеренная — нет надобности исключать ни одну из независимых переменных.
Теперь собственно сама модель, используем функцию lm .
В первой строке мы задаем параметры линейной регрессии. Строка points
. определяет зависимую переменную points и все остальные переменные в качестве регрессоров. Можно определить одну единственную независимую переменную через points
reads , набор переменных — points
Перейдем теперь к расшифровке полученных результатов.
- Intercept — Если у нас модель представлена в виде , то тогда — точка пересечения прямой с осью координат, или intercept .
- R-squared — Коэффициент детерминации указывает насколько тесной является связь между факторами регрессии и зависимой переменной, это соотношение объясненных сумм квадратов возмущений, к необъясненным. Чем ближе к 1, тем ярче выражена зависимость.
- Adjusted R-squared — Проблема с в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
- F-statistic — Используется для оценки значимости модели регрессии в целом, является соотношением объяснимой дисперсии, к необъяснимой. Если модель линейной регрессии построена удачно, то она объясняет значительную часть дисперсии, оставляя в знаменателе малую часть. Чем больше значение параметра — тем лучше.
- t value — Критерий, основанный на t распределении Стьюдента . Значение параметра в линейной регрессии указывает на значимость фактора, принято считать, что при t > 2 фактор является значимым для модели.
- p value — Это вероятность истинности нуль гипотезы, которая гласит, что независимые переменные не объясняют динамику зависимой переменной. Если значение p value ниже порогового уровня (.05 или .01 для самых взыскательных), то нуль гипотеза ложная. Чем ниже — тем лучше.
 , то тогда
, то тогда  — точка пересечения прямой с осью координат, или intercept .
— точка пересечения прямой с осью координат, или intercept . в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
в том, что он по любому растет с числом факторов, поэтому высокое значение данного коэффициента может быть обманчивым, когда в модели присутствует множество факторов. Для того, чтобы изъять из коэффициента корреляции данное свойство был придуман скорректированный коэффициент детерминации .
Можно попытаться несколько улучшить модель, сглаживая нелинейные факторы: комментарии и посты в социальных сетях. Заменим значения переменных fb и comm их степенями.
Проверим значения параметров линейной регрессии.
Как видим в целом отзывчивость модели возросла, параметры подтянулись и стали более шелковистыми , F-статистика выросла, так же как и скорректированный коэффициент детерминации .
Проверим, соблюдены ли условия применимости модели линейной регрессии? Тест Дарбина-Уотсона проверяет наличие автокорреляции возмущений.
И напоследок проверка неоднородности дисперсии с помощью теста Бройша-Пагана.
В заключение
Конечно наша модель линейной регрессии рейтинга Хабра-топиков получилось не самой удачной. Нам удалось объяснить не более, чем половину вариативности данных. Факторы надо чинить, чтобы избавляться от неоднородной дисперсии, с автокорреляцией тоже непонятно. Вообще данных маловато для сколь-нибудь серьезной оценки.
Но с другой стороны, это и хорошо. Иначе любой наспех написанный тролль-пост на Хабре автоматически набирал бы высокий рейтинг, а это к счастью не так.
http://pandia.ru/text/77/203/77731.php
http://habr.com/ru/post/350668/