Регрессионный анализ

Методы корреляционного анализа, позволяющего решать задачи определения тесноты и направления связи, существующей между изучаемыми величинами. Регрессионный анализ представляет собой следующий этап статистического анализа и позволяет предсказать значения случайной величины на основании значений одной или нескольких независимых случайных величин. Достижение этой цели оказывается возможным за счет определения вида аналитического выражения, описывающего связь зависимой случайной величины Y (которую в этом случае называют результативным признаком) с независимыми случайными величинами Х1 ,Х2 , . Хm (которые называют факторами).
Основной задачей регрессионного анализа является установление формы линии регрессии и изучение зависимости между переменными. Основной задачей корреляционного анализа — выявление связи между случайными переменными и оценка ее тесноты.
Форма связи результативного признака Y с факторами Х1 ,Х2 , . Хm называется уравнением регрессии. В зависимости от типа выбранного уравнения различают линейную и нелинейную регрессию (например, квадратичную, логарифмическую, экспоненциальную и т. д.).
Регрессия может быть парная (простая) и множественная, что определяется числом взаимосвязанных признаков. Если исследуется связь между двумя признаками (результативным и факторным), то регрессия называется парной (простой); к этому типу относится, например, исследование зависимости между продажами и затратами на рекламу. Если исследуется связь между тремя и более признаками, то регрессия называется множественной (многофакторной) — например, если исследуется связь между уровнем потребления, доходом, финансовым состоянием и размером семьи.
На этапе регрессионного анализа решаются следующие основные задачи.
1. Выбор общего вида уравнения регрессии и определение параметров регрессии.
2. Определение в регрессии степени взаимосвязи результативного признака и факторов, проверка общего качества уравнения регрессии.
3. Проверка статистической значимости каждого коэффициента уравнения регрессии и определение их доверительных интервалов.
Простая линейная регрессия
Выбор общего вида уравнения регрессии является важной задачей, поскольку форма связи выявляет механизм получения значений зависимой случайной переменной Y. Форма связи может быть линейной или нелинейной. Линейная связь описывается линейным уравнением. Уравнение простой линейной регрессии имеет вид:

График этой функции называется линией регрессии. Линия регрессии точнее всего отражает распределение экспериментальных значений на диаграмме рассеяния, а угол ее наклона характеризует степень зависимости между двумя переменными.
Параметры уравнения регрессии могут быть определены с помощью метода наименьших квадратов (именно этот метод и используется в Microsoft Excel). При определении параметров модели методом наименьших квадратов минимизируется сумма квадратов остатков.

Для нахождения оценок параметров b0 и b1 доставляющих минимум функции Qocm, вычисляются и приравниваются к нулю частные производные этой функции, откуда система нормальных уравнении принимает следующий вид:

После простых преобразований имеем:

Тогда коэффициент наклона прямой регрессии равен:

а свободный член регрессии:

Для свободного члена последнее равенство можно переписать следующим образом:

откуда  . Это означает, что средняя точка (
. Это означает, что средняя точка ( ,
, ) совместного распределения величин X, Y всегда лежит на линии регрессии. Поэтому при замене х на х- получается b0 = , т. е. среднее
) совместного распределения величин X, Y всегда лежит на линии регрессии. Поэтому при замене х на х- получается b0 = , т. е. среднее  заменяет
заменяет
Отсюда следует, что для определения линии регрессии достаточно знать лишь ее коэффициент наклона b1. Равенство для b1. можно упростить, если использовать найденное значение выборочного коэффициента корреляции г:

где  — оценки стандартных отклонений наблюдений
— оценки стандартных отклонений наблюдений
Из последнего выражения для b1, ясно виден общий смысл коэффициента корреляции: чем меньше г, тем ближе линия регрессии к горизонтальному положению, т. е. тем ближе будут средние значения уi,- к состоянию неизменяемости.
Для анализа общего качества уравнения линейной регрессии используется обычно коэффициент детерминации R2, который получается посредством простого возведения в квадрат коэффициента корреляции. Коэффициент детерминации показывает, в какой мере изменчивость величины Y объясняется поведением величины X. Например, если коэффициент корреляции совокупных данных, относящихся к производственным затратам, равняется 0,8, то коэффициент детерминации R2 = 0,82 = 0,64 или 64%. Это значение говорит о том, что 64% вариации (изменчивости) недельных затрат объясняется количеством изделий, выпущенных за неделю. Остальная часть (36%) вариации общих затрат объясняется другими причинами.
Так как в большинстве случаев уравнение регрессии приходится строить на основе выборочных данных, то возникает вопрос об адекватности построения уравнения данным генеральной совокупности. Для этого проводится проверка статистической значимости коэффициента детерминации R2 на основе F-критерия Фишера:

где n — число наблюдений, a m — число факторов в уравнении регрессии.
В математической статистике доказывается, что если гипотеза Н0: R2 = 0 выполняется, то величина F имеет F-распределение с k = m и l=п-ш-1 степенями свободы, т. е.

Гипотеза Н0: R2 = 0 о незначимости коэффициента детерминации R2 отвергается, если FP > Fкр, а принимается альтернативная гипотеза — о значимости R2 .При значениях  считается, что вариация результативного признака Y обусловлена, в основном, влиянием включенных в регрессионную модель факторов X.
считается, что вариация результативного признака Y обусловлена, в основном, влиянием включенных в регрессионную модель факторов X.
Возможна ситуация, когда часть вычисленных коэффициентов регрессии не обладает необходимой степенью значимости, т. е. значения данных коэффициентов будут меньше их стандартной ошибки. В этом случае такие коэффициенты должны быть исключены из уравнения регрессии. Поэтому проверка адекватности построенного уравнения регрессии наряду с проверкой значимости коэффициента детерминации R2 включает в себя также и проверку значимости каждого коэффициента регрессии.
Значимость коэффициентов регрессии проверяется с помощью t-критерия Стьюдента:
 (10.11)
(10.11)
где  — стандартное значение ошибки для коэффициента регрессии
— стандартное значение ошибки для коэффициента регрессии
В математической статистике доказывается, что если гипотеза  выполняется, то величина t имеет распределение Стьюдента k = п-m
выполняется, то величина t имеет распределение Стьюдента k = п-m
1 степенями свободы, т. е.

Гипотеза Н0: Ь1 = 0 о незначимости коэффициента регрессии отвергается, если │tp│> │tкр│, а принимается альтернативная о значимости Ь1. Кроме того, зная значение tкр можно найти границы доверительных интервалов для коэффициентов регрессии.

Пусть имеется корреляционное поле производства пшеницы (обозначено точками на графике) для 50-ти сельхоз предприятий. Здесь Y-годовой сбор пшеницы, X-площади посевов.

Регрессионный анализ позволяет определить аналитическое выражение для уравнения линии регрессии оценить значимость коэффициентов этого уравнения.
Задача. На рис. 2 представлены данные о суточном объеме производства и количестве занятых работников для некоторой совокупности дней. По представленным данным необходимо определить параметры уравнения линейной регрессии и выполнить его анализ.
Для расчета параметров уравнения линейной регрессии и проверки его адекватности исследуемому процессу, Microsoft Excel располагает функцией Регрессия. Для вызова этой функций необходимо выбрать команду меню Сервис→Анализ данных (Tools→Data Analysis). На экране раскроется диалоговое окно Анализ данных (Data Analysis), в котором следует выбрать значение Regression, в результате чего на экране появится диалоговое окно Regression, представленное на рис. 1
В диалоговом окне Regression задаются следующие параметры.
1. В поле Input Y Range (Входные данные У) вводится диапазон ячеек, содержащих исходные данные по результативному признаку. Диапазон должен состоять из одного столбца.
2. В поле Input X Range (Входные данные X) вводится диапазон ячеек, содержащих исходные данные факторного признака. Максимальное число входных диапазонов (столбцов) равно 16.
3. Флажок опции Labels (Метки) устанавливается в том случае, если первая строка/столбец во входном диапазоне содержит заголовок. Если заголовок отсутствует, этот флажок следует сбросить. В последнем случае для данных выходного диапазона будут автоматически созданы стандартные названия.
4. Флажок опции Confidence Level (Уровень надежности) устанавливается в том случае, если в расположенное рядом с флажком поле необходимо ввести уровень надежности, отличный от уровня 95%, применяемого по умолчанию. Установленный в данном поле уровень надежности используется для проверки значимости коэффициента детерминации и коэффициентов регрессии. Если данный флажок опции сброшен, в таблице параметров уравнения регрессии генерируются две одинаковые пары столбцов для границ доверительных интервалов.
5. Флажок опции Константа — нуль (Constant is Zero) устанавливается в том случае, когда требуется, чтобы линия регрессии прошла через начало координат (т. е. Ь0 = 0).
6. Переключатель в группе Output options (Режимы вывода) может быть установлен в одно из трех положений, определяющих, где должны быть размещены результаты расчета: Output Range (Выходной интервал), New Worksheet Ply (Новый рабочий лист) или New Workbook (Новая рабочая книга).
7. Флажок опции Residuals (Остатки) устанавливается в том случае, если в диапазон ячеек с выходными данными требуется включить столбец остатков.
8. Флажок опции Standardized Residuals (Стандартизованные остатки) устанавливается в том случае, если в диапазон ячеек с выходными данными требуется включить столбец стандартизованных остатков.
9. Флажок опции Residual Plots (График остатков) должен быть установлен, если на рабочий лист требуется вывести точечные графики зависимости остатков от факторных признаков xt.
10. Флажок опции Line Fit Plots (График подбора) должен быть установлен, если на рабочий лист требуется вывести точечные графики зависимости теоретических результативных значений у от факторных признаков х.
11. Флажок опции Normal Probability Plots (График вероятности нормального распределения) должен быть установлен, если на рабочий лист требуется вывести точечный график зависимости наблюдаемых значений у от автоматически формируемых интервалов персентелей.
Результаты решения данной задачи с помощью функции Regression представлены на рисунках 3-7.
На рисунке 3 представлены результаты расчета регрессионной статистики. Эти результаты соответствуют следующим статистическим показателям:
• Множественный R — коэффициент корреляции R;
• R-квадрат — коэффициент детерминации R2 (квадрат коэффициента корреляции);
• Нормированный R — нормированное значение коэффициента корреляции; •Стандартная ошибка — стандартное отклонение для остатков;
• Наблюдения — это число исходных наблюдений.


На рисунке 4 представлены результаты дисперсионного анализа, которые используются для проверки значимости коэффициента детерминации R2.
Значения в столбцах на рисунке. 4 имеют следующую интерпретацию.
• Столбец df — это число степеней свободы. Для строки Регрессия число степеней свободы определяется количеством факторных признаков m, для строки Остаток — числом наблюдений n и количеством переменных в уравнении регрессии m+1: п -(m + 1), а для строки Итого — суммой степеней свободы для строк Регрессия и Остаток и, следовательно, равно п — 1.

• Столбец SS — это сумма квадратов отклонений. Для строки Регрессия значение определяется как сумма квадратов отклонений теоретических данных от среднего:

Для строки Остаток это сумма квадратов отклонений эмпирических данных от теоретических:


•Для строки Итого это сумма квадратов отклонений эмпирических данных от среднего:

• Столбец MS содержит значения дисперсии, которые рассчитываются по формуле:
 •
•
Для строки Регрессия это факторная дисперсия 
•Для строки Остаток это остаточная дисперсия 
• Столбец F содержит расчетное значение F-критерия Фишера Fp вычисляемое по формуле:

• Столбец Значимость F содержит значение уровня значимости, соответствующее вычисленному значению Fр.
На рисунке 5 представлены полученные значения коэффициентов регрессии Ь1, и их статистические оценки.
Столбцы на рисунке 5 содержат следующие значения.
• Стандартная ошибка — стандартные ошибки коэффициентов Ь1 и и b0 .

Погрешность линейного коэффициента уравнения равная 7,44 и ошибка свободного члена равная 59,5 вполне приемлемы по отношению к величинам данных коэффициентов. уравнения 23 статистически велика, так как превосходит значение свободного члена. Поэтому ошибки не должны значительно влиять на эффективность описания входных данных полученным регрессионным уравнением.
• t-статистика — расчетные значения t-критерия, вычисляемые по формуле:
 .
.
Чем больше отличается от нуля величина t-статистики, тем статистически лучше.
• Р-значение — значения уровней значимости, соответствующие вычисленным значениям tp . Оно характеризует насколько стандартную погрешность можно считать статистически значимой
• Нижние 95% и Верхние 95% — нижние и верхние границы доверительных интервалов для коэффициентов регрессии Ь1. и b0.
На рисунке 6 представлены теоретические значения  , результативного признака Y и значения остатков. Остатки вычисляются как разность между эмпирическими значениями величины у и теоретически вычисленными значениями . результативного признака Y.
, результативного признака Y и значения остатков. Остатки вычисляются как разность между эмпирическими значениями величины у и теоретически вычисленными значениями . результативного признака Y.
Наконец, на рисунке 7 показаны вычисленные интервалы перцентилей и соответствующие им эмпирические значения у.
 Перцентиль обобщает информацию о рангах, характеризуя значение, достигаемое заданным процентом общего количества данных, после того, как данные упорядочиваются (ранжируются) по возрастанию.
Перцентиль обобщает информацию о рангах, характеризуя значение, достигаемое заданным процентом общего количества данных, после того, как данные упорядочиваются (ранжируются) по возрастанию.
Перцентили — это характеристики набора данных, которые выражают ранги элементов в виде процентов от 0 до 100%, а не в виде чисел от 1 до n, таким образом, что наименьшему значению соответствует нулевой перцентиль, наибольшему — 100-й, медиане — 50-й и т. д.
Перцентили можно рассматривать как показатели, разбивающие наборы количественных и порядковых данных на определенные части. Например, 70-й перцентиль эффективности продаж может быть равен 60  тыс. руб. (измерен не в процентах, а в рублях, как и элементы набора данных). Если этот 70-й перцентиль, равный 60 тыс. руб., характеризует деятельность определенного агента по продажам (например, Александра), то это означает, что приблизительно 70% других агентов имеют результаты ниже, чем у Александра, а 40% имеют более высокие результаты.
тыс. руб. (измерен не в процентах, а в рублях, как и элементы набора данных). Если этот 70-й перцентиль, равный 60 тыс. руб., характеризует деятельность определенного агента по продажам (например, Александра), то это означает, что приблизительно 70% других агентов имеют результаты ниже, чем у Александра, а 40% имеют более высокие результаты.
Под рангом (R) понимают номер (порядковое место) значения случайной величины в наборе данных
Переходя к анализу полученных расчетных данных, можно построить уравнение регрессии с вычисленными коэффициентами, которое будет выражать зависимость объема производства от количества работников.

Значение множественного коэффициента детерминации R2= 0,79 (рис. 10.3) показывает, что 79% общей вариации результативного признака объясняется вариацией факторного признака X. Значит, выбранный фактор существенно влияет на объем производства, что подтверждает правильность включения его в построенную модель.
Рассчитанный уровень значимости (показатель Значимость F на рисунке 4)  подтверждает значимость величины R2. Следующим этапом является проверка значимости коэффициентов регрессии Ь0 и b1, При парном сравнении коэффициентов и их стандартных ошибок (см. рисунок 5) можно сделать вывод, что вычисленные коэффициенты являются значимыми. Этот вывод подтверждается величиной Р-значения, которое меньше уровня значимости α = 0,05.
подтверждает значимость величины R2. Следующим этапом является проверка значимости коэффициентов регрессии Ь0 и b1, При парном сравнении коэффициентов и их стандартных ошибок (см. рисунок 5) можно сделать вывод, что вычисленные коэффициенты являются значимыми. Этот вывод подтверждается величиной Р-значения, которое меньше уровня значимости α = 0,05.
Проверка значимости коэффициента детерминации R2 и коэффициентов регрессии Ь0 и b1, при факторном признаке подтверждает адекватность полученного уравнения.
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Между
 и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
 данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.- Остатки нормально распределены с нулевым средним значением;
- Остатки имеют одну и ту же вариабельность (постоянную дисперсию) для всех предсказанных величин Если нанести остатки против предсказанных величин от мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением то это допущение не выполняется;
 Если нанести остатки против предсказанных величин
Если нанести остатки против предсказанных величин  от
от  мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением
мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением  то это допущение не выполняется;
то это допущение не выполняется;Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
5 видов регрессии и их свойства

Линейная и логистическая регрессии обычно являются первыми видами регрессии, которые изучают в таких областях, как машинное обучение и наука о данных. Оба метода считаются эффективными, так как их легко понять и использовать. Однако, такая простота также имеет несколько недостатков, и во многих случаях лучше выбирать другую регрессионную модель. Существует множество видов регрессии, каждый из которых имеет свои достоинства и недостатки.
Мы познакомимся с 7 наиболее распространенными алгоритмами регрессии и опишем их свойства. Также мы узнаем, в каких ситуация и с какими видами данных лучше использовать тот или иной алгоритм. В конце мы расскажем о некоторых инструментах для построения регрессии и поможем лучше разобраться в регрессионных моделях в целом!
Линейная регрессия
Регрессия — это метод, используемый для моделирования и анализа отношений между переменными, а также для того, чтобы увидеть, как эти переменные вместе влияют на получение определенного результата. Линейная регрессия относится к такому виду регрессионной модели, который состоит из взаимосвязанных переменных. Начнем с простого. Парная (простая) линейная регрессия — это модель, позволяющая моделировать взаимосвязь между значениями одной входной независимой и одной выходной зависимой переменными с помощью линейной модели, например, прямой.
Более распространенной моделью является множественная линейная регрессия, которая предполагает установление линейной зависимости между множеством входных независимых и одной выходной зависимой переменных. Такая модель остается линейной по той причине, что выход является линейной комбинацией входных переменных. Мы можем построить модель множественной линейной регрессии следующим образом:
Y = a_1*X_1 + a_2*X_2 + a_3*X_3 ……. a_n*X_n + b
Где a_n — это коэффициенты, X_n — переменные и b — смещение . Как видим, данная функция не содержит нелинейных коэффициентов и, таким образом, подходит только для моделирования линейных сепарабельных данных. Все очень просто: мы взвешиваем значение каждой переменной X_n с помощью весового коэффициента a_n. Данные весовые коэффициенты a_n, а также смещение b вычисляются с применением стохастического градиентного спуска. Посмотрите на график ниже в качестве иллюстрации!
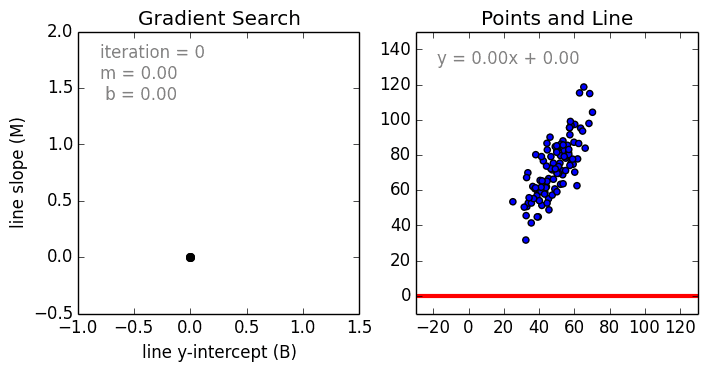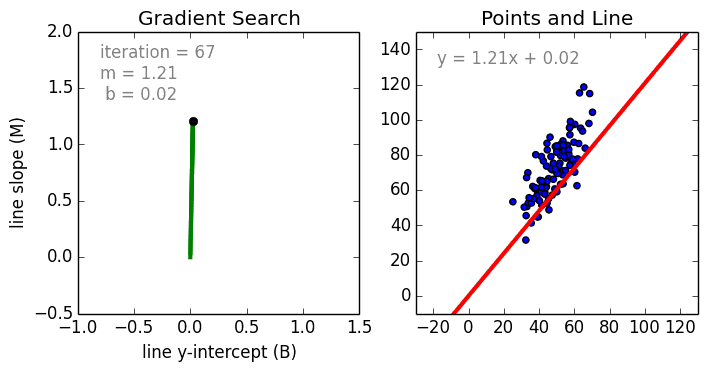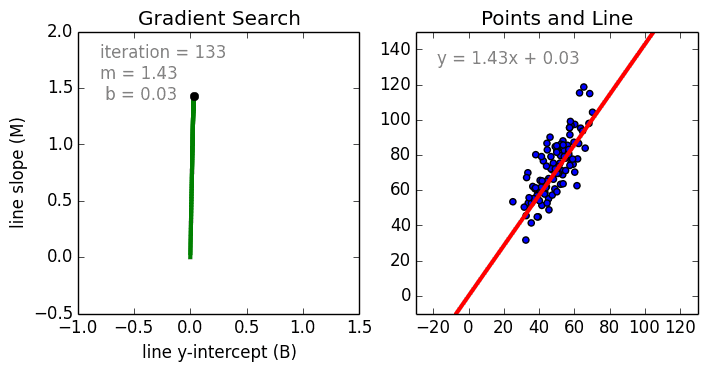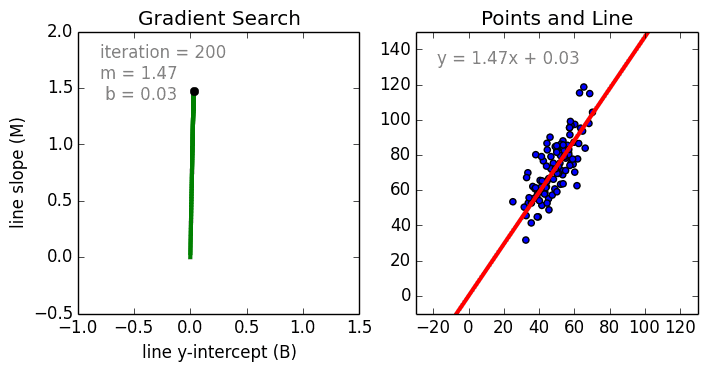
Несколько важных пунктов о линейной регрессии:
- Она легко моделируется и является особенно полезной при создании не очень сложной зависимости, а также при небольшом количестве данных.
- Обозначения интуитивно-понятны.
- Чувствительна к выбросам.
Полиномиальная регрессия
Для создания такой модели, которая подойдет для нелинейно разделяемых данных, можно использовать полиномиальную регрессию. В данном методе проводится кривая линия, зависимая от точек плоскости. В полиномиальной регрессии степень некоторых независимых переменных превышает 1. Например, получится что-то подобное:
Y = a_1*X_1 + (a_2)²*X_2 + (a_3)⁴*X_3 ……. a_n*X_n + b
У некоторых переменных есть степень, у других — нет. Также можно выбрать определенную степень для каждой переменной, но для этого необходимы определенные знания о том, как входные данные связаны с выходными. Сравните линейную и полиномиальную регрессии ниже.
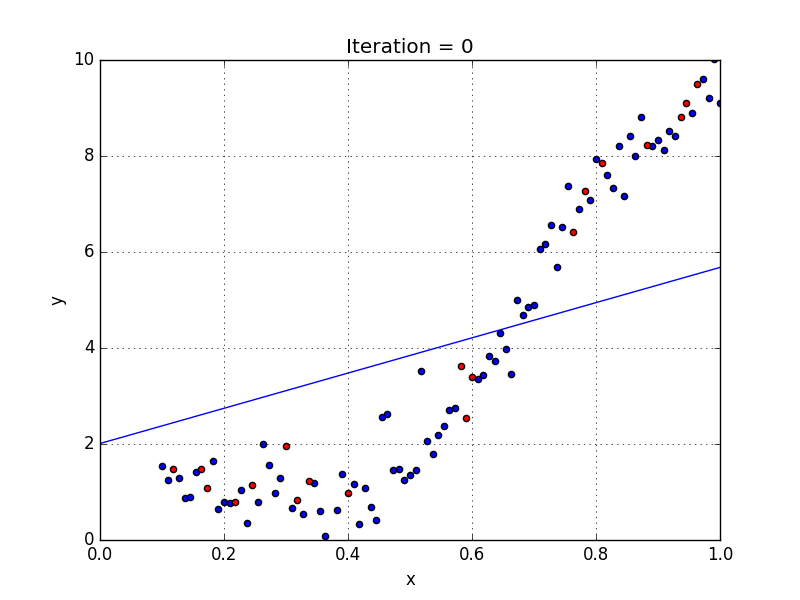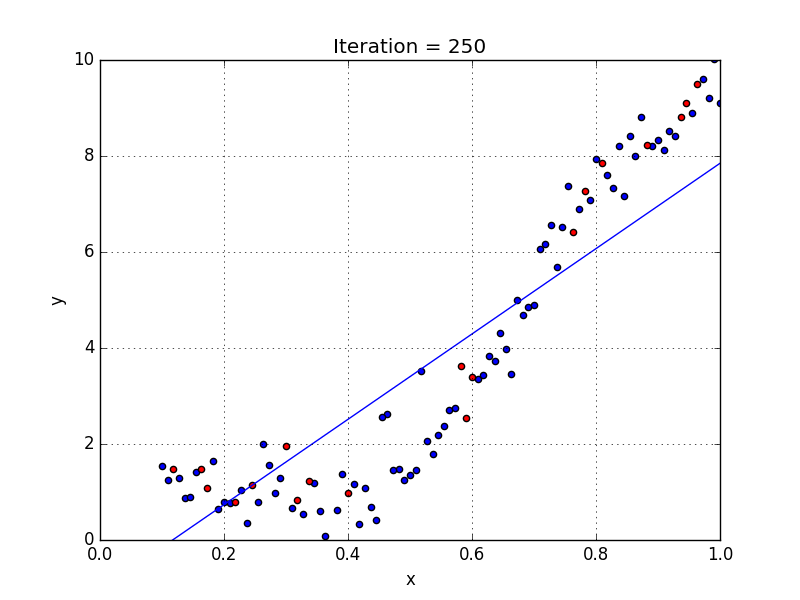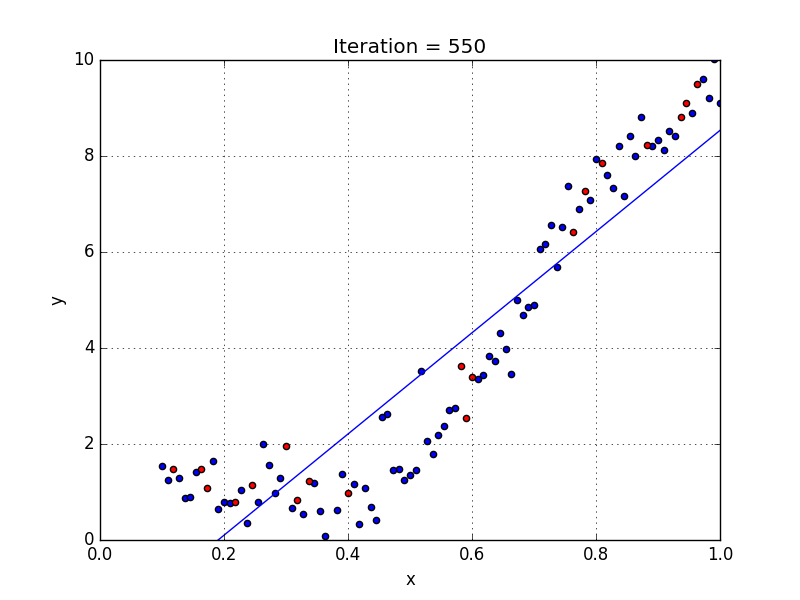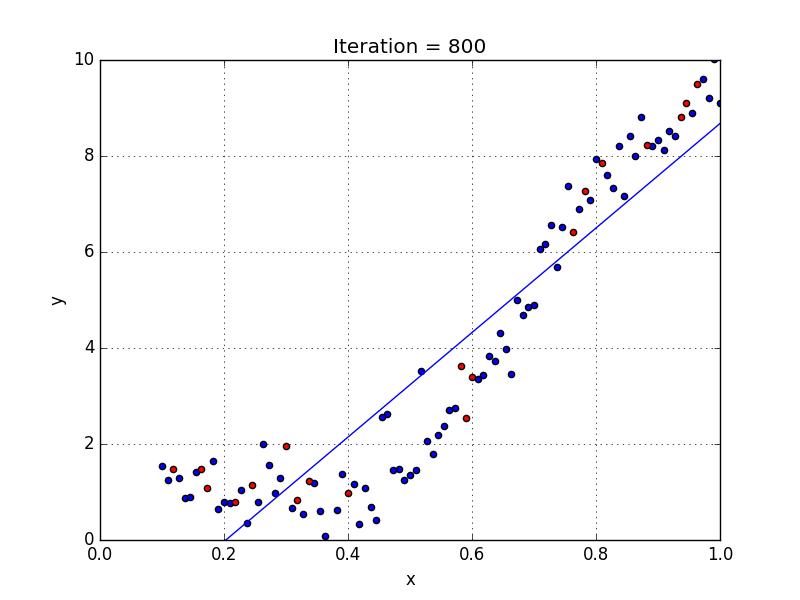
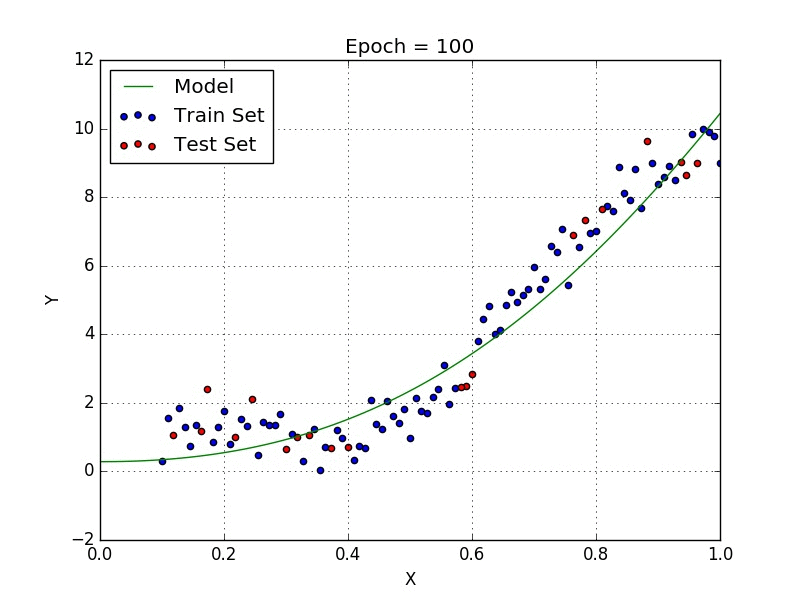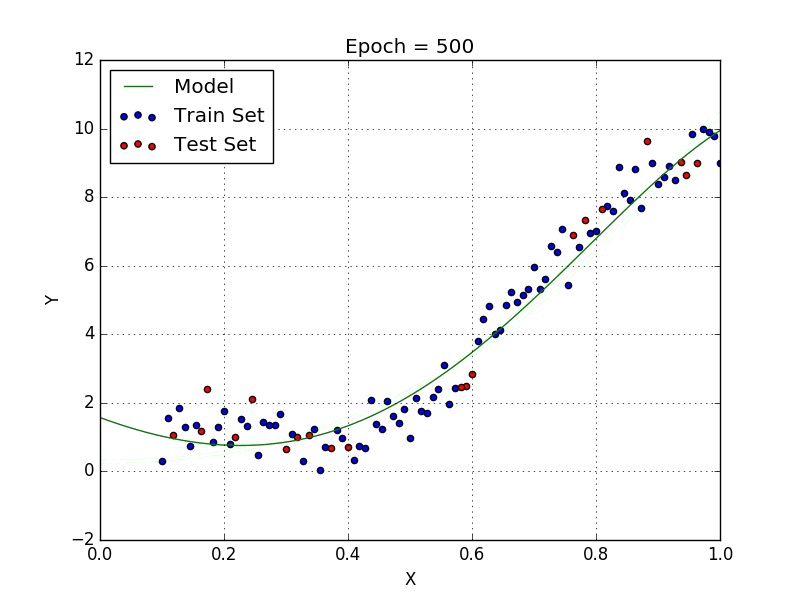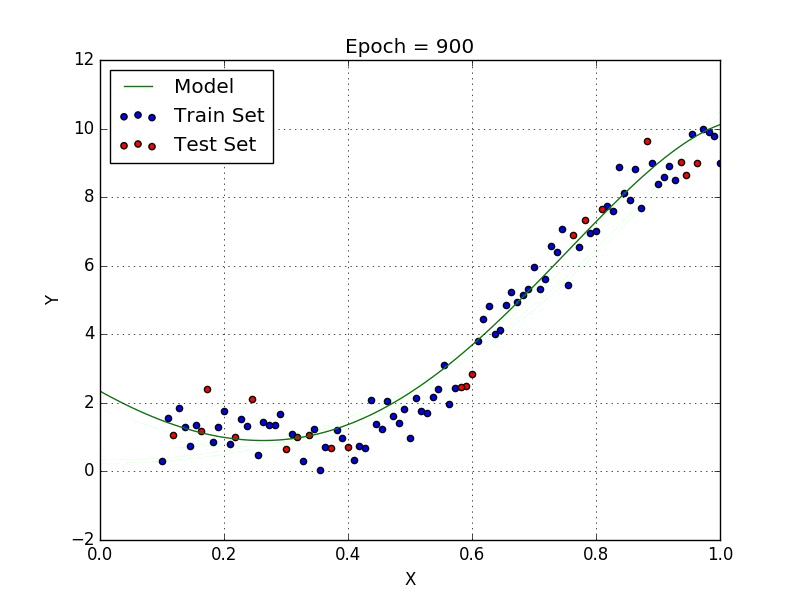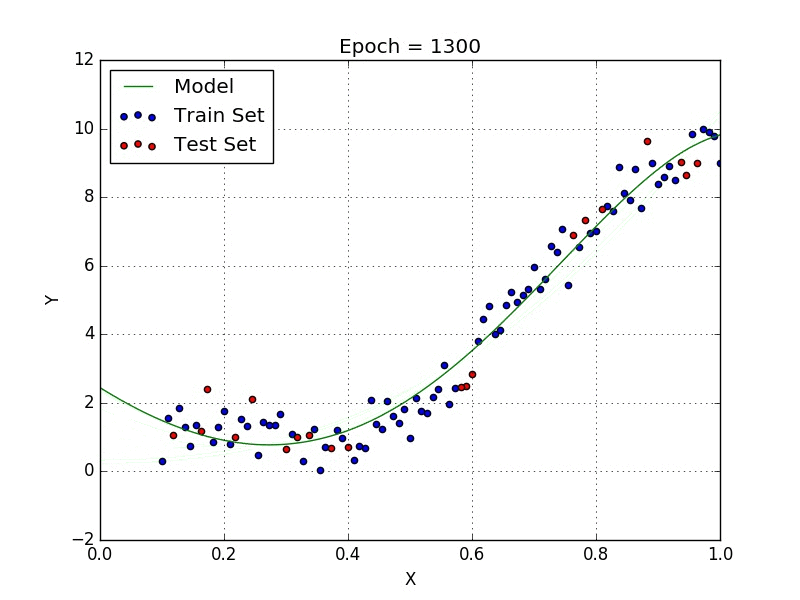
Несколько важных пунктов о полиномиальной регрессии:
- Моделирует нелинейно разделенные данные (чего не может линейная регрессия). Она более гибкая и может моделировать сложные взаимосвязи.
- Полный контроль над моделированием переменных объекта (выбор степени).
- Необходимо внимательно создавать модель. Необходимо обладать некоторыми знаниями о данных, для выбора наиболее подходящей степени.
- При неправильном выборе степени, данная модель может быть перенасыщена.
Гребневая (ридж) регрессия
В случае высокой коллинеарности переменных стандартная линейная и полиномиальная регрессии становятся неэффективными. Коллинеарность — это отношение независимых переменных, близкое к линейному. Наличие высокой коллинеарности можно определить несколькими путями:
- Коэффициент регрессии не важен, несмотря на то, что, теоретически, переменная должна иметь высокую корреляцию с Y.
- При добавлении или удалении переменной из матрицы X, коэффициент регрессии сильно изменяется.
- Переменные матрицы X имеют высокие попарные корреляции (посмотрите корреляционную матрицу).
Сначала можно посмотреть на функцию оптимизации стандартной линейной регрессии для лучшего понимания того, как может помочь гребневая регрессия:
Где X — это матрица переменных, w — веса, y — достоверные данные. Гребневая регрессия — это корректирующая мера для снижения коллинеарности среди предикторных переменных в регрессионной модели. Коллинеарность — это явление, в котором одна переменная во множественной регрессионной модели может быть предсказано линейно, исходя из остальных свойств со значительной степенью точности. Таким образом, из-за высокой корреляции переменных, конечная регрессионная модель сведена к минимальным пределам приближенного значения, то есть она обладает высокой дисперсией.
Гребневая регрессия добавляет небольшой фактор квадратичного смещения для уменьшения дисперсии:
min || Xw — y ||² + z|| w ||²
Такой фактор смещения выводит коэффициенты переменных из строгих ограничений, вводя в модель небольшое смещение, но при этом значительно снижая дисперсию.
Несколько важных пунктов о гребневой регрессии:
- Допущения данной регрессии такие же, как и в методе наименьших квадратов, кроме того факта, что нормальное распределение в гребневой регрессии не предполагается.
- Это уменьшает значение коэффициентов, оставляя их ненулевыми, что предполагает отсутствие отбора признаков.
Регрессия по методу «лассо»
В регрессии лассо, как и в гребневой, мы добавляем условие смещения в функцию оптимизации для того, чтобы уменьшить коллинеарность и, следовательно, дисперсию модели. Но вместо квадратичного смещения, мы используем смещение абсолютного значения:
min || Xw — y ||² + z|| w ||
Существует несколько различий между гребневой регрессией и лассо, которые восстанавливают различия в свойствах регуляризаций L2 и L1:
- Встроенный отбор признаков — считается полезным свойством, которое есть в норме L1, но отсутствует в норме L2. Отбор признаков является результатом нормы L1, которая производит разреженные коэффициенты. Например, предположим, что модель имеет 100 коэффициентов, но лишь 10 из них имеют коэффициенты отличные от нуля. Соответственно, «остальные 90 предикторов являются бесполезными в прогнозировании искомого значения». Норма L2 производит неразряженные коэффициенты и не может производить отбор признаков. Таким образом, можно сказать, что регрессия лассо производит «выбор параметров», так как не выбранные переменные будут иметь общий вес, равный 0.
- Разряженность означает, что незначительное количество входных данных в матрице (или векторе) имеют значение, отличное от нуля. Норма L1 производит большое количество коэффициентов с нулевым значением или очень малые значения с некоторыми большими коэффициентами. Это связано с предыдущим пунктом, в котором указано, что лассо исполняет выбор свойств.
- Вычислительная эффективность: норма L1 не имеет аналитического решения в отличие от нормы L2. Это позволяет эффективно вычислять решения нормы L2. Однако, решения нормы L1 не обладают свойствами разряженности, что позволяет использовать их с разряженными алгоритмами для более эффективных вычислений.
Регрессия «эластичная сеть»
Эластичная сеть — это гибрид методов регрессии лассо и гребневой регрессии. Она использует как L1, так и L2 регуляризации, учитывая эффективность обоих методов.
min || Xw — y ||² + z_1|| w || + z_2|| w ||²
Практическим преимуществом использования регрессии лассо и гребневой регрессии является то, что это позволяет эластичной сети наследовать некоторую стабильность гребневой регрессии при вращении.
Несколько важных пунктов о регрессии эластичной сети:
- Она создает условия для группового эффекта при высокой корреляции переменных, а не обнуляет некоторые из них, как метод лассо.
- Нет ограничений по количеству выбранных переменных.
Вывод
Вот и все! 5 распространенных видов регрессии и их свойства. Все данные методы регуляризации регрессии (лассо, гребневая и эластичной сети) хорошо функционирует при высокой размерности и мультиколлинеарности среди переменных в наборе данных.
http://statistica.ru/theory/osnovy-lineynoy-regressii/
http://nuancesprog.ru/p/2922/