ПРИВЕДЕНИЕ ИСХОДНОГО НЕЛИНЕЙНОГО УРАВНЕНИЯ РЕГРЕССИИ К ЛИНЕЙНОМУ
О лабораторной работе № 2
на тему:
«Определение параметров нестационарного нелинейного уравнения регрессии»
2 курса 221 группы
Содержание
2.ПРИВЕДЕНИЕ ИСХОДНОГО НЕЛИНЕЙНОГО УРАВНЕНИЯ РЕГРЕССИИ К ЛИНЕЙНОМУ………………………………………………………………………………………7 3.ПРОВЕРКА НАЛИЧИЯ МУЛЬТИКОЛЛИНЕАРНОСТИ МЕЖДУ ФАКТОРАМИ МОДЕЛИ……………………………………………………………………………………………8
4.ОПРЕДЕЛЕНИЕ ПАРАМЕТРОВ УРАВНЕНИЯ РЕГРЕССИИ. ПОСТРОЕНИЕ УРАВНЕНИЯ РЕГРЕССИИ………………………………………………………………………11
5.ПРОВЕРКА СТАТИСТИЧЕСКОЙ ЗНАЧИМОСТИ УРАВНЕНИЯ РЕГРЕССИИ ………. 13
5.1.Проверка случайности колебаний уровней статочной последовательности………. 13
5.2. Проверка соответствия распределения случайной компоненты нормальному закону распределения……………………………………………………………………………………15
5.3.Проверка равенства математического ожидания случайной компоненты нулю………..16
5.4.Проверка независимости значений уровней случайной компоненты……………………17
5.5.Определение точности модели………………………………………………………………18
5.6. Тест ранговой корреляции Спирмена ……………………………………………………….19
6. ПРОВЕРКА НАЛИЧИЯ АНОМАЛЬНЫХ КОЛЕБАНИЙ ИССЛЕДУЕМОЙ МОДЕЛИ..21
7.ОПРЕДЕЛЕНИЕ ОПТИМАЛЬНОГО ВИДА ЛИНИИ ТРЕНДА. ПРОГНОЗ ПОКАЗАТЕЛЕЙ…………………………………………………………………………………..22
Список использованной литературы………………………………………………25
ВВЕДЕНИЕ
Специфической особенностью деятельности экономиста является работа в условиях недостатка информации и неполноты исходных данных. Анализ такой информации требует специальных методов, которые составляют один из аспектов эконометрики. Центральной проблемой эконометрики является построение эконометрической модели и определение возможностей ее использования для описания, анализа и прогнозирования реальных экономических процессов.
Становление и развитие эконометрического метода происходили на основе так называемой высшей статистики — на методах парной и множественной регрессии, парной, частной и множественной корреляции, выделения тренда и других компонент временного ряда, на статистическом основании.
Множественная регрессия широко используется в решении проблем спроса, доходности акций, при изучении функции издержек производства, в макроэкономических расчетах и целого ряда других вопросов эконометрики. В настоящее время множественная регрессия — один из наиболее распространенных методов в эконометрике. Основная цель множественной регрессии — построить модель с большим числом факторов, определив при этом влияние каждого из них в отдельности, а также совокупное их воздействие на моделируемый показатель.
Задачей данной работы является оценка адекватности и точности нелинейной нестационарной модели уравнения регрессии с использованием персональных компьютеров.
Данная работа состоит из семи глав и трех приложении. Первая глава – постановка задачи.
Во второй главе осуществляется приведение исходного нелинейного уравнения регрессии к линейному по средствам замены переменных.
В третьей главе проверяется наличие мультиколлинеарности между факторами модели.
В главе 4 определяются параметры уравнения регрессии и строится искомое уравнение регрессии.
В пятой главе проверяется статистическая значимость уравнения регрессии. В пункте 5.1. осуществляется проверка колебаний уровней остаточной последовательности при помощи критерия серий, основанного на медиане выборки. В пункте 5.2. проводится проверка соответствия распределения случайной компоненты нормальному закону распределения при помощи показателей ассиметрии и эксцесса. В пункте 5.3. показана проверка равенства математического ожидания случайной компоненты нулю с использованием t-критерия Стьюдента. В пункте 5.4. проверяется независимость значений уровней случайной компоненты с целью выявления существующей автокорреляции остаточной последовательности. В данной работе эта проверка производится при помощи d-критерия Дарбина — Уотсона. В пункте 5.5. определяется точность модели. В качестве статистических показателей точности в данной работе используются следующие: среднеквадратичное отклонение, средняя относительная ошибка аппроксимации, коэффициент сходимости, коэффициент детерминации. В пункте 5.6 проверяется наличие или отсутствие гетероскедастичности исследуемой модели при помощи теста ранговой корреляции Спирмена.
В шестой главе осуществляется проверка на наличие аномальных колебании исследуемой модели с помощью метода Ирвина.
В восьмой главе определяется оптимальный вид линии тренда, которые отражены в приложениях, и прогнозируются показатели.
ПОСТАНОВКА ЗАДАЧИ
В данной работе необходимо рассмотреть нелинейную нестационарную модель изучаемого экономического объекта. В качестве объекта исследования представлен экономический процесс, о котором известны следующие статистические данные:
1. Y(t) — ставка % рефинансирования Центробанка;
2. X1(t) — уровень безработицы, %
3. X2(t) — уровень инфляции, %
Требуется найти коэффициенты нелинейной нестационарной модели уравнения множественной регрессии вида:


Y(t) — ставка % рефинансирования Центробанка;
X1(t) — уровень безработицы, %
X2(t) — уровень инфляции, %
Значения величин Y(t), X1(t), Х2(t) даны в Таблице №1 «Исходные данные». Данное нелинейное уравнение требуется привести к линейному уравнению вида:
 (2)
(2)
Ø определить параметры уравнения регрессии, используя замену переменной;
Ø проверить наличие мультиколлинеарности между факторами;
Ø проверить статистическую значимость уравнения в целом и отдельных коэффициентов уравнения. Это позволит оценить адекватность полученной модели исследуемому процессу и возможность её использования для осуществления анализа и проектирования;
Ø проверить отсутствие гетероскедастичности и автокорреляции остатков исследуемой модели, установить адекватность и точность уравнения регрессии;
Ø проверить наличие аномальных наблюдений, используя метод Ирвина.
Таблица №1
ИСХОДНЫЕ ДАННЫЕ
| T | X1 | X2 | Y |
| 25,22 | |||
| 21,52 | |||
| 22,32 | |||
| 21,77 | |||
| 20,66 | |||
| 20,14 | |||
| 17,66 | |||
| 17,08 | |||
| 16,87 | |||
| 18,63 | |||
| 16,51 | |||
| 16,95 | |||
| 19,38 | |||
| 18,14 | |||
| 17,94 | |||
| 19,69 | |||
| 19,38 | |||
| 15,88 | |||
| 16,58 | |||
| 14,64 |
ПРИВЕДЕНИЕ ИСХОДНОГО НЕЛИНЕЙНОГО УРАВНЕНИЯ РЕГРЕССИИ К ЛИНЕЙНОМУ
Многие экономические процессы наилучшим образом описываются нелинейными уравнениями регрессии. Например, функции спроса и производственные функции. И в этом случае мы не можем применить к ним обычный метод наименьших квадратов и использовать стандартные подходы к оценке статистической надежности.
В связи с этим встает задача о возможности привести нелинейное уравнение к линейному виду.
В тех случаях, когда нелинейность касается факториальных переменных, но не связано с коэффициентами уравнения регрессии, нелинейность обычно устраняется путем замены переменной.
Рассмотрим нелинейное нестационарное уравнение:

Y(t) — ставка % рефинансирования Центробанка;
X1(t) — уровень безработицы, %
X2(t) — уровень инфляции, %
В данном случае нелинейность касается факторных переменных, но не связано с коэффициентами уравнения.
Вводим новые переменные:



Полученное уравнение является линейным как по переменным, так и по параметрам.
Уравнение нелинейной регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Виды нелинейной регрессии
| Вид | Класс нелинейных моделей |
| Нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам |
| Нелинейные по оцениваемым параметрам |
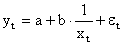
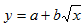
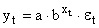
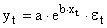

Здесь ε — случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.
Уравнению регрессии первого порядка — это уравнение парной линейной регрессии.
Уравнение регрессии второго порядка это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
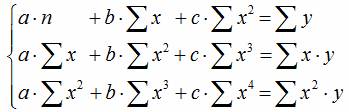
Уравнение регрессии третьего порядка соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
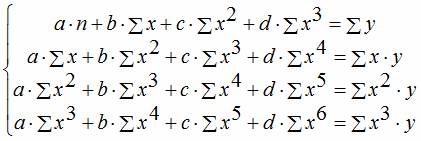
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания):
- Замена переменных.
- Логарифмирование обеих частей уравнения.
- Комбинированный.
| y = f(x) | Преобразование | Метод линеаризации |
| y = b x a | Y = ln(y); X = ln(x) | Логарифмирование |
| y = b e ax | Y = ln(y); X = x | Комбинированный |
| y = 1/(ax+b) | Y = 1/y; X = x | Замена переменных |
| y = x/(ax+b) | Y = x/y; X = x | Замена переменных. Пример |
| y = aln(x)+b | Y = y; X = ln(x) | Комбинированный |
| y = a + bx + cx 2 | x1 = x; x2 = x 2 | Замена переменных |
| y = a + bx + cx 2 + dx 3 | x1 = x; x2 = x 2 ; x3 = x 3 | Замена переменных |
| y = a + b/x | x1 = 1/x | Замена переменных |
| y = a + sqrt(x)b | x1 = sqrt(x) | Замена переменных |
Пример . По данным, взятым из соответствующей таблицы, выполнить следующие действия:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессии.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью F-критерия Фишера статистическую надежность результатов регрессионного моделирования. По значениям характеристик, рассчитанных в пп. 4, 5 и данном пункте, выбрать лучшее уравнение регрессии и дать его обоснование.
- Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 15% от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости α=0,05 .
- Оценить полученные результаты, выводы оформить в аналитической записке.
| Год | Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. — трлн. руб.), y | Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. — тыс. руб.), х |
| 1995 | 872 | 515,9 |
| 2000 | 3813 | 2281,1 |
| 2001 | 5014 | 3062 |
| 2002 | 6400 | 3947,2 |
| 2003 | 7708 | 5170,4 |
| 2004 | 9848 | 6410,3 |
| 2005 | 12455 | 8111,9 |
| 2006 | 15284 | 10196 |
| 2007 | 18928 | 12602,7 |
| 2008 | 23695 | 14940,6 |
| 2009 | 25151 | 16856,9 |
Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии. Получим таблицу следующего вида.
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
Степенное уравнение регрессии имеет вид y = a x b
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) — 49694.9535
Определение уравнения нелинейной регрессии

Лабораторная работа 7
Определение уравнения нелинейной регрессии
При проведении регрессионного анализа характеристикой достоверности аппроксимации служит коэффициент корреляции 0 £ R2 £ 1. Чем ближе R2 к единице, тем ближе аппроксимирующая кривая к экспериментальной зависимости. Выбор характера аппроксимирующей функции ‑ процесс творческий, основанный на априорном знании исследуемого процесса и анализе экспериментальной зависимости. Не всегда с первого раза удается получить достаточную достоверность аппроксимации.
Если при проведении линейного регрессионного анализа получился недостаточно высокий коэффициент корреляции, это свидетельствует, прежде всего, о том, что неправильно выбран вид уравнения регрессии. Очевидно, экспериментальная зависимость имеет более сложный характер, чем линейный.
В Excel имеется функция ЛГРФПРИБЛ( ), обеспечивающая получение уравнения регрессии в виде Y = b×a X. Однако такой вид уравнения регрессии также не всегда дает достаточно высокую степень достоверности аппроксимации. В этом случае следует определять уравнение регрессии в форме пользователя. Это может быть логарифмическая, экспоненциальная, полиномиальная аппроксимации.
Как ни странно, но параметры всех этих нелинейных уравнений регрессии определяются при помощи функции ЛИНЕЙН( ).
В настоящей работе необходимо определить параметры уравнения нелинейной регрессии в форме Y = b×a X, а также R2 для этого уравнения. Затем, независимо от получившегося R2, подобрать другой вид зависимости и определить параметры этого уравнения регрессии.
1. Ввести исходные данные.
2. Построить диаграмму функции Y = F(X).
3. При помощи функции ЛГРФПРИБЛ( ) определить параметры и R2 уравнения регрессии в виде Y = b×aX.
4. Построить на диаграмме линии тренда различного вида и определить по ним вид аппроксимирующей кривой, наилучшим образом описывающий экспериментальную зависимость.
5. Провести регрессионный анализ, определить параметры уравнения регрессии в виде, выбранном по линиям тренда, используя функцию ЛИНЕЙН( ).
6. Сравнить полученные результаты и сделать выводы.
Независимая переменная Х
Зависимая переменная Y
Выполнение работы в среде Excel
Как и в предыдущей работе, исходные данные вносятся в виде столбцов и для независимой переменной Х определяются минимальное и максимальное значения. Строится график экспериментальной зависимости.
Затем выделяется массив, состоящий из пяти строк по вертикали и двух (n+1) столбцов по горизонтали. В массив вводится формула массива ЛГРФПРИБЛ(блок значений Y; блок значений X; ИСТИНА; ИСТИНА). Формула массива реализуется после нажатия комбинации клавиш Shift + Ctrl + Enter.
Результаты вычислений представлены в выделенном массиве. Значения величин, используемых нами в дальнейшем, такое же, как в предыдущей работе. Так же, как в предыдущей работе, можно определить достоверность полученной величины R2.
Для построения линий тренда следует скопировать диаграмму экспериментальной зависимости столько раз, сколько разновидностей линий тренда будет построено. Лучше строить на каждой диаграмме одну линию тренда, чтобы не загромождать диаграмму. Не забудьте вывести на диаграмму уравнение аппроксимирующей функции и достоверность аппроксимации R2.
Сравнив величины R2, выберем вид уравнения регрессии, имеющий максимальное значение R2. Далее будем определять параметры уравнения регрессии такого вида при помощи функции ЛИНЕЙН( ).
Предположим, что максимальное значение R2 получено для полинома второй степени. Следовательно, будем определять параметры квадратного уравнения вида Y = a1×X2+a2×X+b. Можно представить, что это линейное уравнение с двумя неизвестными, одно из которых ‑ Х2, второе ‑ Х.
Прежде чем вводить формулу массива ЛИНЕЙН( ), преобразуем блок исходных данных. Чтобы функцию Y = F(X) можно было рассматривать как функцию двух переменных, добавим в исходные данные столбец Х2.
Далее следует выделить массив размером пять строк по вертикали и три (n+1) столбца по горизонтали. При введении аргументов функции ЛИНЕЙН следует в качестве блока значений Х выделить столбцы Х и Х2.
Результаты вычислений будут представлены в выделенном блоке. Смысл полученных числовых значений приведен в табл.7.3.
Далее необходимо определить достоверность величины R2.
В случае, если R2 имеет недостаточную величину, следует использовать для аппроксимации полином третьей степени.
Следует помнить, что процесс моделирования ‑ постоянный компромисс между сложностью математической модели и точностью описания ею моделируемого процесса. Чем выше степень полинома, тем лучше он будет описывать экспериментальную зависимость. Однако получение математической модели ‑ не самоцель процесса моделирования. Далее эта модель будет использоваться для исследования моделируемого процесса. В любом случае с уравнением будут производиться некие математические операции, и чем модель сложнее, тем сложнее будет дальнейшая работа с ней. Об этом следует помнить при выборе вида аппроксимирующей функции.
Рассмотрим случай, когда уравнение регрессии представляет собой логарифмическую функцию вида Y = a×LN(X) + b. В этом случае в качестве аргументов функции ЛИНЕЙН следует использовать блок значений Y и блок значений LN(X). Значения LN(X) необходимо предварительно подсчитать.
Аналогично, при использовании в качестве уравнения регрессии функции вида Y = a×EXP(b×X) аргументами функции ЛИНЕЙН будут блок значений Y и блок значений EXP(X).
1. В каком виде может быть получено уравнение нелинейной регрессии?
2. Какие функции Excel служат для проведения нелинейной регрессии?
Курицкий оптимальных решений средствами Excel 7.0. – BHV‑Санкт-Петербург, 1997, – С.342–349.
Пример оформления работы 7 представлен в приложении.
http://math.semestr.ru/corel/noncorel.php
http://pandia.ru/text/78/083/16633.php