Линеаризация нелинейных моделей регрессии
Вы будете перенаправлены на Автор24
Понятие регрессии
Регрессия – это односторонняя зависимость, которая устанавливает соответствие между случайными величинам.
Сущность регрессии заключается в том, чтобы через математическое выражение установить связь между зависимой и независимыми переменными. Ее отличительной особенностью от функциональной зависимости является тот факт, что каждому значению независимой соответствует одно определенное значение зависимой. В регрессионной связи одной и той же величине могут соответствовать абсолютно разные величины.
Впервые регрессию стали использовать в конце девятнадцатого века. Она была применена для установления зависимости между параметрами человека. Регрессию смогли перенести на плоскость. Точки легли на одну прямую, поэтому ее назвали линейной.
Построение линейной регрессии подразумевает, что ошибок в ней нет. Тогда распределение величин происходит под влиянием нормального закона. То есть, среднее значение равно нулю, а отклонение постоянно.
Чтобы вычислить параметры модели часто применяют программное обеспечение. Оно позволяет обрабатывать большие массивы информации с минимальными ошибками. Существуют специальные методы, позволяющие проверить величину отклонения. Ошибки необходимы для того, чтобы находить доверительные интервалы и проверять выдвинутые в начале исследования гипотезы. Например, в статистике используется критерий Стьюдента, позволяющий сопоставить средние значения двух выборок.
Самое простое представление регрессии состоит из зависимости между соотношениями случайной и независимой величины. Этот подход необходим для установления функциональной связи, если величины не случайны. В практической деятельности коэффициенты неизвестны, поэтому их исследуют с помощью экспериментальных данных.
Нелинейные модели регрессии
Построение нелинейной регрессии осуществляется для того, чтобы провести анализ. В нем экспериментальные данные записываются в функциональную зависимость, описывающей нелинейную комбинацию, представляющую модель, которая зависит от одной или нескольких переменных. Чтобы приблизить полученные данные к практическим величинам используется метод последовательных приближений.
Готовые работы на аналогичную тему
Этот метод заключается в следующем. Исследователем определяются корни уравнения или системы уравнений для того, чтобы упростить решаемую задачу, либо определить неизвестные параметры.
Структура нелинейной регрессии состоит из независимых и зависимых переменных. Для каждой переменной устанавливается случайная величина со средним значением. Погрешность может появиться, но есть ее обрабатывать, то она выйдет за пределы модели. В случае, если переменные не свободны, то модель становится ошибочной, поэтому для исследования становится непригодной.
Вот некоторые примеры нелинейных функций:
- Показательные.
- Логарифмические.
- Тригонометрические.
- Степенные.
- Функция Гаусса.
- Кривые Лоуренца.
В некоторых случаях регрессионный анализ может быть сведен к линейному, но данный способ должен применяться с осторожностью. Чтобы получить наилучший вариант расчета применяются оптимизационные алгоритмы. На практике могут применяться оценочные значения совместно с методиками оптимизации. В результате надо найти глобальный минимум суммы квадратов.
Нелинейная регрессия чаще всего применяется, как статистика линейной. Это позволяет сместить статистику, поэтому полученные данные интерпретируются с осторожностью.
Линеаризация нелинейных моделей регрессии
Линеаризация – это преобразование. Оно осуществляется для того, чтобы упростить определенные модели и вычисления. Например, применение логарифма к обеим частям линейной регрессии позволяет оценить неизвестные параметры более простым способом.
Но использование нелинейного изменения уравнения требует осторожности. Это связано с тем, что данные будут изменяться. Поэтому появятся ошибки модели. Их интерпретация может привести к ошибочному суждению о гипотезе. Обычно в нелинейных уравнениях используется модель Гаусса для исследования ошибок, что необходимо учитывать при проверке.
В которых случаях применяется уравнение Лайнуивер – Берк, либо обобщенная линейная модель.
Чтобы уточнить построенную модель и снизить вероятность ошибок, независимая переменная разбивается на классы. Вследствие этого линейная регрессия разбивается посегментно. Она может дать результат, в котором будет видно, как ведет себя параметр в зависимом положении. Отображение изменений производится графически.
То есть сущность линеаризации заключается в том, что исследователь применяет особые методики для того, чтобы провести преобразования исходных данных. Это позволяет исследовать нелинейную зависимость. Переменные нелинейного уравнения преобразуются с помощью специальных методик в линейные. Это может привести к ошибкам, что необходимо учитывать в процессе преобразования уравнения. Метод может быть опасным, так как влияет на результат вычислений.
Сущность метода заключается в том, что нелинейные переменные заменяются линейными. Регрессия сводится к линейной. Такой подход часто используется для полиномов. Далее применяются известные и простые оценки исследования линейных регрессии. Но изменение полиномов должно так же проводиться с осторожностью. Чем выше порядок полинома, тем сложнее удержаться в рамках реалистичной интерпретации коэффициентов регрессии.
В логарифмических моделях составляется линейная модель с новыми переменными. Оценка результата происходит с помощью метода наименьших квадратов. Эта методика подходит для исследования кривых спроса и предложения, производственных функций, кривых освоения связи между трудоемкостью и производственными масштабами. Такой подход актуален при запуске новых видов продукции.
Лекция по эконометрике. Лекция по эконометрике
| Название | Лекция по эконометрике |
| Дата | 21.06.2018 |
| Размер | 1.32 Mb. |
| Формат файла |  |
| Имя файла | Лекция по эконометрике.docx |
| Тип | Лекция #47509 |
| страница | 3 из 5 |
 С этим файлом связано 6 файл(ов). Среди них: ЭКОНО Задача.docx, СТАТ в жив. Лекция №9.docx, Вопросы по АВтоматике.docx, ЛЕКЦИЯ СОЦ.СТАТ..doc, доступность к прдовольствию.pdf, Лекция по эконометрике.docx. Показать все связанные файлы Подборка по базе: 3 лекция биоэтика Сд-рус.pptx, Лукъянова лекция.docx, 3 ЛЕКЦИЯ (1).pptx, 2 лекция.docx, 3 лекция макет МЕНЕДЖМЕНТ.docx, 4 -5 лекция.pdf, 15. Лекция_92a5b97c72fd42c2c693a97fd507a780.pdf, 1 Лекция ГТУ.pdf, морфология лекция 1.docx, 1-ші сабақтың лекциясы (1).docx С этим файлом связано 6 файл(ов). Среди них: ЭКОНО Задача.docx, СТАТ в жив. Лекция №9.docx, Вопросы по АВтоматике.docx, ЛЕКЦИЯ СОЦ.СТАТ..doc, доступность к прдовольствию.pdf, Лекция по эконометрике.docx. Показать все связанные файлы Подборка по базе: 3 лекция биоэтика Сд-рус.pptx, Лукъянова лекция.docx, 3 ЛЕКЦИЯ (1).pptx, 2 лекция.docx, 3 лекция макет МЕНЕДЖМЕНТ.docx, 4 -5 лекция.pdf, 15. Лекция_92a5b97c72fd42c2c693a97fd507a780.pdf, 1 Лекция ГТУ.pdf, морфология лекция 1.docx, 1-ші сабақтың лекциясы (1).docx3. Множественная корреляция и линейная регрессия Множественная регрессия широко используется в решении проблем спроса, доходности акций, при изучении функции издержек производства, в макроэкономических расчетах и целом ряде других вопросов эконометрики. В настоящее время множественная регрессия – один из наиболее распространенных методов в эконометрике. Основная цель множественной регрессии – построить модель с большим числом факторов, определив при этом влияние каждого из них в отдельности, а также совокупное их воздействие на моделируемый показатель. Включение в уравнение множественной регрессии того или иного набора факторов связано прежде всего с представлением исследователя о природе взаимосвязи моделируемого показателя с другими экономическими явлениями. Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям.
Включение в модель факторов с высокой интеркорреляцией, может привести к нежелательным последствиям – система нормальных уравнений может оказаться плохо обусловленной и повлечь за собой неустойчивость и ненадежность оценок коэффициентов регрессии. Если между факторами существует высокая корреляция, то нельзя определить их изолированное влияние на результативный показатель и параметры уравнения регрессии оказываются неинтерпретируемыми. Включаемые во множественную регрессию факторы должны объяснить вариацию независимой переменной. Если строится модель с набором При дополнительном включении в регрессию Насыщение модели лишними факторами не только не снижает величину остаточной дисперсии и не увеличивает показатель детерминации, но и приводит к статистической незначимости параметров регрессии по критерию Стьюдента. Таким образом, хотя теоретически регрессионная модель позволяет учесть любое число факторов, практически в этом нет необходимости. Отбор факторов производится на основе качественного теоретико-экономического анализа. Однако теоретический анализ часто не позволяет однозначно ответить на вопрос о количественной взаимосвязи рассматриваемых признаков и целесообразности включения фактора в модель. Поэтому отбор факторов обычно осуществляется в две стадии: на первой подбираются факторы исходя из сущности проблемы; на второй – на основе матрицы показателей корреляции определяют статистики для параметров регрессии. Коэффициенты интеркорреляции позволяют исключать из модели дублирующие факторы. Считается, что две переменные явно коллинеарны, т.е. находятся между собой в линейной зависимости, если Пусть, например, при изучении зависимости |  |  |  |  |
| 1 | 0,8 | 0,7 | 0,6 |
| 0,8 | 1 | 0,8 | 0,5 |
| 0,7 | 0,8 | 1 | 0,2 |
| 0,6 | 0,5 | 0,2 | 1 |
 , где
, где  факторов, то для нее рассчитывается показатель детерминации
факторов, то для нее рассчитывается показатель детерминации  , который фиксирует долю объясненной вариации результативного признака за счет рассматриваемых в регрессии
, который фиксирует долю объясненной вариации результативного признака за счет рассматриваемых в регрессии  с соответствующей остаточной дисперсией
с соответствующей остаточной дисперсией  .
. и
и .
. не улучшает модель и практически является лишним фактором.
не улучшает модель и практически является лишним фактором. . Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга.
. Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга. матрица парных коэффициентов корреляции оказалась следующей:
матрица парных коэффициентов корреляции оказалась следующей:Очевидно, что факторы и дублируют друг друга. В анализ целесообразно включить фактор , а не , хотя корреляция с результатом слабее, чем корреляция фактора с  , но зато значительно слабее межфакторная корреляция
, но зато значительно слабее межфакторная корреляция  . Поэтому в данном случае в уравнение множественной регрессии включаются факторы , .
. Поэтому в данном случае в уравнение множественной регрессии включаются факторы , .
По величине парных коэффициентов корреляции обнаруживается лишь явная коллинеарность факторов. Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью, т.е. имеет место совокупное воздействие факторов друг на друга. Наличие мультиколлинеарности факторов может означать, что некоторые факторы будут всегда действовать в унисон. В результате вариация в исходных данных перестает быть полностью независимой и нельзя оценить воздействие каждого фактора в отдельности.
Включение в модель мультиколлинеарных факторов нежелательно в силу следующих последствий:
- Затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом» виде, ибо факторы коррелированы; параметры линейной регрессии теряют экономический смысл.
- Оценки параметров ненадежны, обнаруживают большие стандартные ошибки и меняются с изменением объема наблюдений (не только по величине, но и по знаку), что делает модель непригодной для анализа и прогнозирования.
Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных коэффициентов корреляции между факторами.
Если бы факторы не коррелировали между собой, то матрица парных коэффициентов корреляции между факторами была бы единичной матрицей, поскольку все недиагональные элементы 
 были бы равны нулю. Так, для уравнения, включающего три объясняющих переменных
были бы равны нулю. Так, для уравнения, включающего три объясняющих переменных
матрица коэффициентов корреляции между факторами имела бы определитель, равный единице: .
.
Если же, наоборот, между факторами существует полная линейная зависимость и все коэффициенты корреляции равны единице, то определитель такой матрицы равен нулю: .
.
Чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии. И, наоборот, чем ближе к единице определитель матрицы межфакторной корреляции, тем меньше мультиколлинеарность факторов.
Существует ряд подходов преодоления сильной межфакторной корреляции. Самый простой путь устранения мультиколлинеарности состоит в исключении из модели одного или нескольких факторов. Другой подход связан с преобразованием факторов, при котором уменьшается корреляция между ними.
Одним из путей учета внутренней корреляции факторов является переход к совмещенным уравнениям регрессии, т.е. к уравнениям, которые отражают не только влияние факторов, но и их взаимодействие. Так, если  , то возможно построение следующего совмещенного уравнения:
, то возможно построение следующего совмещенного уравнения: .
.
Рассматриваемое уравнение включает взаимодействие первого порядка (взаимодействие двух факторов). Возможно включение в модель и взаимодействий более высокого порядка, если будет доказана их статистическая значимость по  -критерию Фишера, но, как правило, взаимодействия третьего и более высоких порядков оказываются статистически незначимыми.
-критерию Фишера, но, как правило, взаимодействия третьего и более высоких порядков оказываются статистически незначимыми.
Отбор факторов, включаемых в регрессию, является одним из важнейших этапов практического использования методов регрессии. Подходы к отбору факторов на основе показателей корреляции могут быть разные. Они приводят построение уравнения множественной регрессии соответственно к разным методикам. В зависимости от того, какая методика построения уравнения регрессии принята, меняется алгоритм ее решения на ЭВМ.
Наиболее широкое применение получили следующие методы построения уравнения множественной регрессии:
- Метод исключения – отсев факторов из полного его набора.
- Метод включения – дополнительное введение фактора.
- Шаговый регрессионный анализ – исключение ранее введенного фактора.
При отборе факторов также рекомендуется пользоваться следующим правилом: число включаемых факторов обычно в 6–7 раз меньше объема совокупности, по которой строится регрессия. Если это соотношение нарушено, то число степеней свободы остаточной дисперсии очень мало. Это приводит к тому, что параметры уравнения регрессии оказываются статистически незначимыми, а -критерий меньше табличного значения.
3.2 Метод наименьших квадратов (МНК)
Возможны разные виды уравнений множественной регрессии: линейные и нелинейные.
Ввиду четкой интерпретации параметров наиболее широко используется линейная функция. Задача оценки статистической взаимосвязи переменных формулируется аналогично случаю парной регрессии.
Теоретическое уравнение множественной линейной регрессии имеет вид:
 ,
,
где  — случайная ошибка,
— случайная ошибка,  — вектор размерности
— вектор размерности  .
.
Для того, чтобы формально можно было решить задачу оценки параметров должно выполняться условие: объем выборки n должен быть не меньше количества параметров, т.е.  .
.
Если же это условие не выполняется, то можно найти бесконечно много различных коэффициентов.
Если  (например, 3 наблюдения и 2 объясняющие переменные), то оценки рассчитываются единственным образом без МНК путём решения системы:
(например, 3 наблюдения и 2 объясняющие переменные), то оценки рассчитываются единственным образом без МНК путём решения системы: .
.
Если же  , то необходима оптимизация, т.е. выбрать наилучшую формулу зависимости. В этом случае разность
, то необходима оптимизация, т.е. выбрать наилучшую формулу зависимости. В этом случае разность  называется числом степеней свободы. Для получения надежных оценок параметров уравнения объём выборки должен значительно превышать количество определяемых по нему параметров. Практически, как было сказано ранее, объём выборки должен превышать количество параметров при xj в уравнении в 6-7 раз.
называется числом степеней свободы. Для получения надежных оценок параметров уравнения объём выборки должен значительно превышать количество определяемых по нему параметров. Практически, как было сказано ранее, объём выборки должен превышать количество параметров при xj в уравнении в 6-7 раз.
Задача построения множественной линейной регрессии состоит в определении -мерного вектора  , элементы которого есть оценки соответствующих элементов вектора .
, элементы которого есть оценки соответствующих элементов вектора .
Уравнение с оценёнными параметрами имеет вид: ,
,
где е – оценка отклонения ε. Параметры при  называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизмененном значении других факторов, закрепленных на среднем уровне.
называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизмененном значении других факторов, закрепленных на среднем уровне.
Классический подход к оцениванию параметров линейной модели множественной регрессии основан на методе наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака от расчетных  минимальна:
минимальна: .
.
Как известно из курса математического анализа, для того чтобы найти экстремум функции нескольких переменных, надо вычислить частные производные первого порядка по каждому из параметров и приравнять их к нулю.
Итак, имеем функцию  аргумента:
аргумента:
Она является квадратичной относительно неизвестных величин. Она ограничена снизу, следовательно имеет минимум. Находим частные производные первого порядка, приравниваем их к нулю, и получаем систему () уравнения с () неизвестным. Обычно такая система имеет единственное решение. И называется системой нормальных уравнений:
Решение может быть осуществлено методом Крамера: , где
, где
 ,
,
а  — частные определители, которые получаются из
— частные определители, которые получаются из  заменой соответствующего j – го столбца столбцом свободных членов.
заменой соответствующего j – го столбца столбцом свободных членов.
Для двухфакторной модели (  данная система будет иметь вид:
данная система будет иметь вид:
Матричный метод.
Представим данные наблюдений и параметры модели в матричной форме.
 – n – мерный вектор – столбец наблюдений зависимой переменной;
– n – мерный вектор – столбец наблюдений зависимой переменной;
 – (m+1) – мерный вектор – столбец параметров уравнения регрессии;
– (m+1) – мерный вектор – столбец параметров уравнения регрессии;
 – n – мерный вектор – столбец отклонений выборочных значений yi от значений
– n – мерный вектор – столбец отклонений выборочных значений yi от значений  , получаемых по уравнению регрессии.
, получаемых по уравнению регрессии.
Для удобства записи столбцы записаны как строки и поэтому снабжены штрихом для обозначения операции транспонирования.
Наконец, значения независимых переменных запишем в виде прямоугольной матрицы размерности  :
:
Каждому столбцу этой матрицы отвечает набор из n значений одного из факторов, а первый столбец состоит из единиц, которые соответствуют значениям переменной при свободном члене.
В этих обозначениях эмпирическое уравнение регрессии выглядит так: .
.
Где  .
.
Здесь  – матрица, обратная к
– матрица, обратная к  .
.
На основе линейного уравнения множественной регрессии
могут быть найдены частные уравнения регрессии:

т.е. уравнения регрессии, которые связывают результативный признак с соответствующим фактором  при закреплении остальных факторов на среднем уровне. В развернутом виде систему можно переписать в виде:
при закреплении остальных факторов на среднем уровне. В развернутом виде систему можно переписать в виде:
При подстановке в эти уравнения средних значений соответствующих факторов они принимают вид парных уравнений линейной регрессии, т.е. имеем
В отличие от парной регрессии частные уравнения регрессии характеризуют изолированное влияние фактора на результат, ибо другие факторы закреплены на неизменном уровне. Эффекты влияния других факторов присоединены в них к свободному члену уравнения множественной регрессии. Это позволяет на основе частных уравнений регрессии определять частные коэффициенты эластичности:
 ,
,
где  – коэффициент регрессии для фактора в уравнении множественной регрессии,
– коэффициент регрессии для фактора в уравнении множественной регрессии,  – частное уравнение регрессии.
– частное уравнение регрессии.
Наряду с частными коэффициентами эластичности могут быть найдены средние по совокупности показатели эластичности:
 , которые показывают на сколько процентов в среднем изменится результат, при изменении соответствующего фактора на 1%. Средние показатели эластичности можно сравнивать друг с другом и соответственно ранжировать факторы по силе их воздействия на результат.
, которые показывают на сколько процентов в среднем изменится результат, при изменении соответствующего фактора на 1%. Средние показатели эластичности можно сравнивать друг с другом и соответственно ранжировать факторы по силе их воздействия на результат.
3.3 Анализ качества эмпирического уравнения множественной линейной регрессии
Проверка статистического качества оцененного уравнения регрессии проводится, с одной стороны, по статистической значимости параметров уравнения, а с другой стороны, по общему качеству уравнения регрессии. Кроме этого, проверяется выполнимость предпосылок МНК.
Как и в случае парной регрессии, для анализа статистической значимости параметров множественной линейной регрессии с m факторами, необходимо оценить дисперсию и стандартные отклонения параметров:
Обозначим матрицу:
и в этой матрице обозначим j – й диагональный элемент как  . Тогда выборочная дисперсия эмпирического параметра регрессии равна:
. Тогда выборочная дисперсия эмпирического параметра регрессии равна: ,
,
а для свободного члена выражение имеет вид: 
если считать, что в матрице  индексы изменяются от 0 до m.
индексы изменяются от 0 до m.
Здесь S 2 – несмещенная оценка дисперсии случайной ошибки ε (среднеквадратическая ошибка регрессии): .
.
Соответственно, стандартные ошибки (отклонения) параметров  регрессии равны
регрессии равны .
.
Для проверки значимости каждого коэффициента рассчитываются t – статистики: ,
,
Полученная t – статистика для соответствующего параметра имеет распределение Стьюдента с числом степеней свободы (n-т-1). При требуемом уровне значимости α эта статистика сравнивается с критической точкой распределения Стьюдента t(α; n-т-1) (двухсторонней).
Если  , то соответствующий параметр считается статистически значимым, и нуль – гипотеза в виде
, то соответствующий параметр считается статистически значимым, и нуль – гипотеза в виде  или
или  отвергается.
отвергается.
При  параметр считается статистически незначимым, и нуль – гипотеза не может быть отвергнута. Поскольку bj не отличается значимо от нуля, фактор хj линейно не связан с результатом. Его наличие среди объясняющих переменных не оправдано со статистической точки зрения. Не оказывая какого–либо серьёзного влияния на зависимую переменную, он лишь искажает реальную картину взаимосвязи. Поэтому после установления того факта, что коэффициент bj статистически незначим, переменную хj рекомендуется исключить из уравнения регрессии. Это не приведет к существенной потере качества модели, но сделает её более конкретной.
параметр считается статистически незначимым, и нуль – гипотеза не может быть отвергнута. Поскольку bj не отличается значимо от нуля, фактор хj линейно не связан с результатом. Его наличие среди объясняющих переменных не оправдано со статистической точки зрения. Не оказывая какого–либо серьёзного влияния на зависимую переменную, он лишь искажает реальную картину взаимосвязи. Поэтому после установления того факта, что коэффициент bj статистически незначим, переменную хj рекомендуется исключить из уравнения регрессии. Это не приведет к существенной потере качества модели, но сделает её более конкретной.
Строгую проверку значимости параметров можно заменить простым сравнительным анализом.
Если  , т.е.
, т.е.  , то коэффициент статистически незначим.
, то коэффициент статистически незначим.
Если  , т.е.
, т.е.  , то коэффициент относительно значим. В данном случае рекомендуется воспользоваться таблицей критических точек распределения Стьюдента.
, то коэффициент относительно значим. В данном случае рекомендуется воспользоваться таблицей критических точек распределения Стьюдента.
Если  , то коэффициент значим. Это утверждение является гарантированным при (n-т-1)>20 и
, то коэффициент значим. Это утверждение является гарантированным при (n-т-1)>20 и  .
.
Если  , то коэффициент считается сильно значимым. Вероятность ошибки в данном случае при достаточном числе наблюдений не превосходит 0,001.
, то коэффициент считается сильно значимым. Вероятность ошибки в данном случае при достаточном числе наблюдений не превосходит 0,001.
К анализу значимости коэффициента bj можно подойти по – другому. Для этого строится интервальная оценка соответствующего коэффициента. Если задать уровень значимости α, то доверительный интервал, в который с вероятностью (1-α) попадает неизвестное значение параметра  , определяется неравенством:
, определяется неравенством:
 .
.
Если доверительный интервал не содержит нулевого значения, то соответствующий параметр является статистически значимым, в противном случае гипотезу о нулевом значении параметра отвергать нельзя.
Для проверки общего качества уравнения регрессии используется коэффициент детерминации R 2 . Для множественной регрессии R 2 является неубывающей функцией числа объясняющих переменных. Добавление новой объясняющей переменной никогда не уменьшает значение R 2 . Действительно, каждая следующая объясняющая переменная может лишь дополнить, но никак не сократить информацию, объясняющую поведение зависимой переменной.
Анализ статистической значимости коэффициента детерминации проводится на основе проверки нуль-гипотезы Н0: R 2 =0 против альтернативной гипотезы Н1: R 2 >0. Для проверки данной гипотезы используется следующая F – статистика.
Задача 1. Бюджетное обследование пяти случайно выбранных семей дало следующие результаты (в тыс. руб.):
| Семья | Накопления, S | Доход, Y | Имущество, W |
| 1 | 3 | 40 | 60 |
| 2 | 6 | 55 | 36 |
| 3 | 5 | 45 | 36 |
| 4 | 3,5 | 30 | 15 |
| 5 | 1,5 | 30 | 90 |
А) Оценить регрессию S на Y и W.
Б) Спрогнозируйте накопления семьи, имеющей доход 40 тыс.руб.и имущество стоимостью 25 тыс.руб.
В) Предположим, что доход семьи вырос на 10 тыс.руб, в то время как стоимость имущества не изменилась. Оцените как возрастут её накопления.
Г) Оцените как возрастут накопления семьи, если её доход вырос на 5, а стоимость имущетва увеличилась на 15.
Задача 2. Для изучения жилья в городе по данным о 46 коттеджах было получено уравнение множественной регрессии:
Где у – цена объекта (тыс.дол),  — расстояние до центра города,
— расстояние до центра города,  — полезная площадь объекта (кв.м),
— полезная площадь объекта (кв.м),  — число этажей в доме (ед.).
— число этажей в доме (ед.).
А) Проверить гипотезы о равенстве нулю коэффициентов  в генеральной совокупности (т.е. проверить значимость коэффициентов регрессии).
в генеральной совокупности (т.е. проверить значимость коэффициентов регрессии).
Б) Проверить гипотезу об одновременном равенстве нулю коэффициентов множественной регрессии (или о том, что R 2 =0) в ген.совокупности.
- Нелинейные модели регрессии. Простейшие методы линеаризации
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций.
Различают два класса нелинейных регрессий:
1. Регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам.
– полиномы различных степеней –  ,
,  ,
,  ;
;
– равносторонняя гипербола –  ;
;
– полулогарифмическая функция –  .
.
2. Регрессии, нелинейные по оцениваемым параметрам.
– степенная –  ;
;
– показательная –  ;
;
– экспоненциальная –  .
.
1. Регрессии нелинейные по включенным переменным сводятся к линейному виду с помощью методов линеаризации простой заменой переменных, а дальнейшая оценка параметров производится с помощью метода наименьших квадратов. Рассмотрим некоторые функции.
Полином второй степени  приводится к линейному виду с помощью замены:
приводится к линейному виду с помощью замены:  . В результате приходим к двухфакторному уравнению
. В результате приходим к двухфакторному уравнению  , оценка параметров которого при помощи МНК, приводит к системе следующих нормальных уравнений:
, оценка параметров которого при помощи МНК, приводит к системе следующих нормальных уравнений:

А после обратной замены переменных получим
Полином второй степени обычно применяется в случаях, когда для определенного интервала значений фактора меняется характер связи рассматриваемых признаков: прямая связь меняется на обратную или обратная на прямую.
Аналогично, для полинома третьего порядка получим трёхфакторную модель.
Для полинома степени m, получим множественную регрессию с m объясняющими переменными .
.
Среди нелинейной полиномиальной модели чаще всего используется полином второй степени, реже – третьей.
Для равносторонней гиперболы  замена
замена  приводит к уравнению парной линейной регрессии
приводит к уравнению парной линейной регрессии  , для оценки параметров которого используется МНК. Система линейных уравнений при применении МНК будет выглядеть следующим образом:
, для оценки параметров которого используется МНК. Система линейных уравнений при применении МНК будет выглядеть следующим образом:

Такая модель может быть использована для характеристики связи удельных расходов сырья, материалов, топлива от объема выпускаемой продукции, времени обращения товаров от величины товарооборота, процента прироста заработной платы от уровня безработицы (например, кривая А.В. Филлипса), расходов на непродовольственные товары от доходов или общей суммы расходов (например, кривые Э. Энгеля) и в других случаях.
Аналогичным образом приводятся к линейному виду зависимости  ,
,  и другие.
и другие.
2. Регрессии, нелинейными по оцениваемым параметрам, делятся на два типа: нелинейные модели внутренне линейные (приводятся к линейному виду с помощью соответствующих преобразований, например, логарифмированием) и нелинейные модели внутренне нелинейные (к линейному виду не приводятся). К внутренне линейным моделям относятся, например, степенная функция –  , показательная –
, показательная –  , экспоненциальная –
, экспоненциальная –  , логистическая –
, логистическая –  , обратная –
, обратная –  . Среди нелинейных моделей наиболее часто используется степенная функция
. Среди нелинейных моделей наиболее часто используется степенная функция  , которая приводится к линейному виду логарифмированием:
, которая приводится к линейному виду логарифмированием: ;
;
 ;
;
 ,
,
где  . Т.е. МНК мы применяем для преобразованных данных:
. Т.е. МНК мы применяем для преобразованных данных:
а затем потенцированием находим искомое уравнение.
Широкое использование степенной функции связано с тем, что параметр  в ней имеет четкое экономическое истолкование – он является коэффициентом эластичности. ( Коэффициент эластичности показывает, на сколько процентов измениться в среднем результат, если фактор изменится на 1%.) Формула для расчета коэффициента эластичности имеет вид:
в ней имеет четкое экономическое истолкование – он является коэффициентом эластичности. ( Коэффициент эластичности показывает, на сколько процентов измениться в среднем результат, если фактор изменится на 1%.) Формула для расчета коэффициента эластичности имеет вид: .
.
Так как для остальных функций коэффициент эластичности не является постоянной величиной, а зависит от соответствующего значения фактора , то обычно рассчитывается средний коэффициент эластичности: .
.
Наконец, следует отметить зависимость логистического типа:  . Графиком функции является так называемая «кривая насыщения», которая имеет две горизонтальные асимптоты
. Графиком функции является так называемая «кривая насыщения», которая имеет две горизонтальные асимптоты  и точку перегиба
и точку перегиба  , а также точку пересечения с осью ординат
, а также точку пересечения с осью ординат  :
:
Уравнение приводится к линейному виду заменами переменных  .
.
К внутренне нелинейным моделям можно, например, отнести следующие модели:  ,
,  ,
,  .
.
В случае, когда функция не поддаётся непосредственной линейной линеаризации, можно разложить её в функциональный ряд и затем оценить регрессию с членами этого ряда.
При линеаризации функции или разложении её в ряд возникают и другие проблемы: искажение отклонений  и нарушение их первоначальных свойств, статистическая зависимость членов ряда между собой.
и нарушение их первоначальных свойств, статистическая зависимость членов ряда между собой.
Например, если оценивается формула  , полученная путём линеаризации или разложения в ряд, то независимые переменные
, полученная путём линеаризации или разложения в ряд, то независимые переменные  связаны между собой функционально.
связаны между собой функционально.
Поэтому во многих случаях актуальна непосредственная оценка нелинейной формулы регрессии. Для этого используется нелинейный МНК, идея которого основана на минимизации суммы квадратов отклонений расчётных значений от эмпирических, т.е. нужно оценить параметры вектора а функции  , так чтобы ошибки
, так чтобы ошибки  по совокупности были минимальны:
по совокупности были минимальны: .
.
Для решения этой задачи существуют два пути:
1) непосредственная минимизация функции F с помощью методов нелинейной оптимизации, позволяющих находить экстремум выпуклых линий (метод наискорейшего спуска).
2) решение системы нелинейных уравнений, которая получается из необходимого условия экстремума функции – равенство нулю частных производных по каждому из параметров:
 система уравнений:
система уравнений: .
.
Эта система может быть решена итерационными методами. Однако в общем случае решение такой системы не является более простым способом нахождения вектора а.
Существуют методы оценивания нелинейной регрессии, сочетающие непосредственную оптимизацию, использующую нахождение градиента, с разложением в ряд Тейлора для последующей оценки линейной регрессии (метод Марквардта).
При построении нелинейной регрессии более остро, чем в линейном случае, стоит проблема правильной оценки формы зависимости между переменными.
Неточности при выборе формы функции существенно сказываются на качестве отдельных параметров уравнения и соответственно, на адекватности всей модели в целом.
Любое уравнение нелинейной регрессии, как и линейной зависимости, дополняется показателем корреляции, который в данном случае называется индексом корреляции:
Здесь  — общая дисперсия результативного признака y,
— общая дисперсия результативного признака y,  — остаточная дисперсия, определяемая по уравнению нелинейной регрессии
— остаточная дисперсия, определяемая по уравнению нелинейной регрессии  . Следует обратить внимание на то, что разности в соответствующих суммах
. Следует обратить внимание на то, что разности в соответствующих суммах  и
и  берутся не в преобразованных, а в исходных значениях результативного признака. Иначе говоря, при вычислении этих сумм следует использовать не преобразованные (линеаризованные) зависимости, а именно исходные нелинейные уравнения регрессии. По-другому можно записать так:
берутся не в преобразованных, а в исходных значениях результативного признака. Иначе говоря, при вычислении этих сумм следует использовать не преобразованные (линеаризованные) зависимости, а именно исходные нелинейные уравнения регрессии. По-другому можно записать так:
Величина R находится в границах  , и чем ближе она к единице, тем теснее связь рассматриваемых признаков, тем более надежно найденное уравнение регрессии. При этом индекс корреляции совпадает с линейным коэффициентом корреляции в случае, когда преобразование переменных с целью линеаризации уравнения регрессии не проводится с величинами результативного признака. Так обстоит дело с полулогарифмической и полиномиальной регрессией, а также с равносторонней гиперболой. Определив линейный коэффициент корреляции для линеаризованных уравнений, например, в пакете Excel с помощью функции ЛИНЕЙН, можно использовать его и для нелинейной зависимости.
, и чем ближе она к единице, тем теснее связь рассматриваемых признаков, тем более надежно найденное уравнение регрессии. При этом индекс корреляции совпадает с линейным коэффициентом корреляции в случае, когда преобразование переменных с целью линеаризации уравнения регрессии не проводится с величинами результативного признака. Так обстоит дело с полулогарифмической и полиномиальной регрессией, а также с равносторонней гиперболой. Определив линейный коэффициент корреляции для линеаризованных уравнений, например, в пакете Excel с помощью функции ЛИНЕЙН, можно использовать его и для нелинейной зависимости.
Иначе обстоит дело в случае, когда преобразование проводится также с величиной y, например, взятие обратной величины или логарифмирование. Тогда значение R, вычисленное той же функцией ЛИНЕЙН, будет относиться к линеаризованному уравнению регрессии, а не к исходному нелинейному уравнению, и величины разностей под суммами будут относиться к преобразованным величинам, а не к исходным, что не одно и то же. При этом, как было сказано выше, для расчета R следует воспользоваться выражением, вычисленным по исходному нелинейному уравнению.
Поскольку в расчете индекса корреляции используется соотношение факторной и общей СКО, то R 2 имеет тот же смысл, что и коэффициент детерминации. В специальных исследованиях величину R 2 для нелинейных связей называют индексом детерминации.
Оценка существенности индекса корреляции проводится так же, как и оценка надежности коэффициента корреляции.
Индекс детерминации используется для проверки существенности в целом уравнения нелинейной регрессии по F-критерию Фишера: ,
,
где n-число наблюдений, m-число параметров при переменных х. Во всех рассмотренных нами случаях, кроме полиномиальной регрессии, m=1, для полиномов число параметров равно m, т.е. степени полинома. Величина m характеризует число степеней свободы для факторной СКО, а (n-m-1) – число степеней свободы для остаточной СКО.
Индекс детерминации R 2 можно сравнивать с коэффициентом детерминации r 2 для обоснования возможности применения линейной функции. Чем больше кривизна линии регрессии, тем больше разница между R 2 и r 2 . Близость этих показателей означает, что усложнять форму уравнения регрессии не следует и можно использовать линейную функцию. Практически, если величина (R 2 -r 2 ) не превышает 0,1, то линейная зависимость считается оправданной. В противном случае проводится оценка существенности различия показателей детерминации, вычисленных по одним и тем же данным, через t-критерий Стьюдента: .
.
Здесь в знаменателе находится ошибка разности (R 2 -r 2 ), определяемая по формуле:

Если  , то различия между показателями корреляции существенны и замена нелинейной регрессии линейной нецелесообразна.
, то различия между показателями корреляции существенны и замена нелинейной регрессии линейной нецелесообразна.
В заключение приведем формулы расчета коэффициентов эластичности для наиболее распространенных уравнений регрессии:
Тема 11. Нелинейные регрессии и их линеаризация
Аннотация.Данная тема раскрывает особенности построения нелинейных моделей регрессии.
Ключевые слова.Нелинейная регрессия, индекс корреляции, коэффициент эластичности, подход Бокса-Кокса.
Методические рекомендации по изучению темы
· Тема содержит лекционную часть, где даются общие представления по теме.
· В качестве самостоятельной работы предлагается ознакомиться с решениями типовых задач, выполнить практические задания и ответить на вопросы для самоконтроля.
· Для проверки усвоения темы имеется тест для самоконтроля.
· Для подготовки к экзамену имеется контрольный тест.
Рекомендуемые информационные ресурсы:
2. Эконометрика: [Электронный ресурс] Учеб. пособие / А.И. Новиков. — 3-e изд., испр. и доп. — М.: ИНФРА-М, 2014. — 272 с.: (http://znanium.com/catalog.php?item=booksearch&code=%D1%8D%D0%BA%D0%BE%D0%BD%D0%BE%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D0%BA%D0%B0&page=1#none) С. 41-45.
3.Уткин, В. Б. Эконометрика [Электронный ресурс] : Учебник / В. Б. Уткин; Под ред. проф. В. Б. Уткина. — 2-е изд. — М.: Издательско-торговая корпорация «Дашков и К°», 2012. — 564 с.
(http://znanium.com/catalog.php?item=booksearch&code=%D1%8D%D0%BA%D0%BE%D0%BD%D0%BE%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D0%BA%D0%B0&page=4#none) С. 383-399.
4. Эконометрика. Практикум: [Электронный ресурс] Учебное пособие / С.А. Бородич. — М.: НИЦ ИНФРА-М; Мн.: Нов. знание, 2014. — 329 с. (http://znanium.com/catalog.php?item=booksearch&code=%D1%8D%D0%BA%D0%BE%D0%BD%D0%BE%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D0%BA%D0%B0&page=4#none) С.172-174.
Глоссарий
Бокса-Кокса подход – способ подбора линеаризующего преобразования.
Индекс корреляции—показатель корреляции, который определяется для нелинейных регрессий.
Коэффициент эластичности показывает, на сколько процентов изменится результативный признак Y, если факторный признак изменится на 1 процент.
Линеаризация нелинейных моделей – процедура, которая заключается в преобразовании или переменных, или параметров модели, или в комбинации этих преобразований.
Нелинейная модель, внутренне линейная, с помощью преобразований может быть приведена к линейному виду.
Нелинейная модель, внутренне нелинейная, не может быть сведена к линейной функции.
Вопросы для изучения
1. Классы и виды нелинейных регрессий.
2. Линеаризация нелинейных моделей. Выбор формы модели.
3. Индекс корреляции. Подбор линеаризующего преобразования (подход Бокса-Кокса).
Классы и виды нелинейных регрессий. Различают два класса нелинейных регрессий: регрессии, нелинейные относительно включенных в анализ объясняющих переменных; регрессии, нелинейные по оцениваемым параметрам. Нелинейная модель, внутренне линейная, с помощью преобразований может быть приведена к линейному виду. Нелинейная модель, внутренне нелинейная, не может быть сведена к линейной функции. При анализе нелинейных регрессионных зависимостей наиболее важным вопросом применения классического МНК является способ их линеаризации.
Линеаризация нелинейных моделей. Выбор формы модели. В нелинейных зависимостях, не являющихся классическими полиномами, обязательно проводится предварительная линеаризация, которая заключается в преобразовании или переменных, или параметров модели, или в комбинации этих преобразований. Рассмотрим некоторые классы таких зависимостей.

Рис. 11.1. Способы линеаризации
Замена переменных заключается в замене нелинейных объясняющих переменных новыми линейными переменными и сведении нелинейной регрессии к линейной. Логарифмирование обеих частей уравнения применяется обычно, когда мультипликативную модель необходимо привести к линейному виду. К классу степенных функций относятся: кривые спроса и предложения, производственная функция Кобба-Дугласа, кривые освоения для характеристики связи между трудоемкостью продукции и масштабами производства в период освоения и выпуска нового вида изделий, зависимость валового национального дохода от уровня занятости.
Индекс корреляции. Подбор линеаризующего преобразования (подход Бокса-Кокса). Любое уравнение нелинейной регрессии, как и линейной зависимости, дополняется показателем корреляции, который в данном случае называется индексом корреляции:

Здесь  — общая дисперсия результативного признака y,
— общая дисперсия результативного признака y, 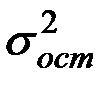 — остаточная дисперсия, определяемая по уравнению нелинейной регрессии
— остаточная дисперсия, определяемая по уравнению нелинейной регрессии  . По-другому можно записать так:
. По-другому можно записать так:

Следует обратить внимание на то, что разности в соответствующих суммах  и
и  берутся не в преобразованных, а в исходных значениях результативного признака. Иначе говоря, при вычислении этих сумм следует использовать не преобразованные (линеаризованные) зависимости, а именно исходные нелинейные уравнения регрессии. Величина R находится в границах
берутся не в преобразованных, а в исходных значениях результативного признака. Иначе говоря, при вычислении этих сумм следует использовать не преобразованные (линеаризованные) зависимости, а именно исходные нелинейные уравнения регрессии. Величина R находится в границах  , и чем ближе она к единице, тем теснее связь рассматриваемых признаков, тем более надежно найденное уравнение регрессии.
, и чем ближе она к единице, тем теснее связь рассматриваемых признаков, тем более надежно найденное уравнение регрессии.
Если разные модели используют разные функциональные формы для зависимой переменной, то проблема выбора модели становится более сложной, так как нельзя непосредственно сравнивать коэффициенты R 2 или суммы квадратов отклонений. Например, нельзя сравнивать эти статистики для линейного и логарифмического вариантов. Пусть в линейной модели в качестве зависимой переменной используется заработок, а в нелинейной – логарифм заработка. Тогда R 2 в одном уравнении измеряет объясненную регрессией долю дисперсии заработка, а в другом — объясненную регрессией долю дисперсии логарифма заработка. В случае, если значения R 2 для двух моделей близки друг к другу, проблема выбора усложняется. Здесь следует использовать тест Бокса – Кокса. При сравнении моделей с использованием в качестве зависимой переменной y и lny проводится такое преобразование масштаба наблюдений y, при котором можно непосредственно сравнивать суммы квадратов отклонений в линейной и логарифмической моделях. Здесь выполняются следующие шаги. Вычисляется среднее геометрическое значений y в выборке. Оно совпадает с экспонентой среднего арифметического логарифмов y. Все значения y пересчитываются делением на среднее геометрическое, получаем значения y*. Оцениваются две регрессии: для линейной модели с использованием y* в качестве зависимой переменной и для логарифмической модели с использованием ln y* вместо ln y. Во всех других отношениях модели должны оставаться неизменными. Теперь значения СКО для двух регрессий сравнимы, и модель с меньшей остаточной СКО обеспечивает лучшее соответствие исходным данным. Для проверки, обеспечивает ли одна из моделей значимо лучшее соответствие, можно вычислить величину (n/2)lnz, где z – отношение значений остаточной СКО в перечисленных регрессиях. Эта статистика имеет распределение хи – квадрат с одной степенью свободы. Если она превышает критическое значение при выбранном уровне значимости α, то делается вывод о наличии значимой разницы в качестве оценивания.
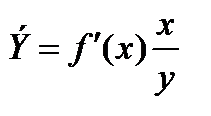 Величина коэффициента эластичности показывает, на сколько процентов изменится результативный признак Y, если факторный признак изменится на 1 %:
Величина коэффициента эластичности показывает, на сколько процентов изменится результативный признак Y, если факторный признак изменится на 1 %:
В заключение приведем формулы расчета коэффициентов эластичности для наиболее распространенных уравнений регрессии:
| Вид уравнения регрессии | Коэффициент эластичности |
 |  |
 |  |
 |  |
 |  |
 |  |
 | 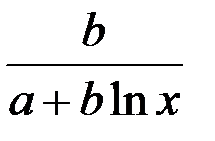 |
  |  |
 |
Вопросы и задания для самоконтроля
1. Какие модели являются нелинейными относительно: а) включаемых переменных; б) оцениваемых параметров?
2. Какие преобразования используются для линеаризации нелинейных моделей?
3. Чем отличается применение МНК к моделям, нелинейным относительно включаемых переменных, от применения к моделям, нелинейным по оцениваемым параметрам?
4. Как определяются коэффициенты эластичности по разным видам регрессионных моделей?
5. Какие показатели корреляции используются при нелинейных соотношениях рассматриваемых признаков?
6. В каких случаях используют обратные и степенные модели?
Задача 1.По группе предприятий, производящих однородную продукцию известно, как зависит себестоимость единицы продукции (Y) от факторов, приведенных в таблице:
| Признак-фактор | Уравнение парной регрессии | Среднее значение фактора |
Объем производства,  млн. руб. млн. руб. |  |  |
Трудоемкость единицы продукции,  чел/час чел/час |  |  |
Оптовая цена за 1т энергоносителя,  , млн. руб. , млн. руб. |  |  |
Доля прибыли, изымаемая государством,  ,% ,% |  |  |
1) определить с помощью коэффициентов эластичности силу влияния каждого фактора на результат;
2) ранжировать факторы по силе влияния на результат.
Задача 2. По группе из 10 заводов, производящих однородную продукцию, получено уравнение регрессии себестоимости единицы продукции  (тыс. руб) от уровня технической оснащенности
(тыс. руб) от уровня технической оснащенности  (тыс. руб.)
(тыс. руб.)
 .
.
Доля остаточной дисперсии в общей составила 0,19.
1) определить коэффициент эластичности, предполагая, что стоимость активных производственных фондов составляет 200 тыс. руб.;
2) вычислить индекс корреляции;
3) оценить значимость уравнения регрессии с помощью  критерия.
критерия.
http://topuch.ru/lekciya-po-ekonometrike/index3.html
http://poisk-ru.ru/s16268t6.html