Пример нахождения коэффициента детерминации
Коэффициент детерминации рассчитывается для оценки качества подбора уравнения регрессии. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50%. Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими. Значение коэффициента детерминации R 2 = 1 означает функциональную зависимость между переменными.
Для линейной зависимости коэффициент детерминации равен квадрату коэффициента корреляции rxy: R 2 = rxy 2 .
2 «>Рассчитать свое значение
Например, значение R 2 = 0.83, означает, что в 83% случаев изменения х приводят к изменению y . Другими словами, точность подбора уравнения регрессии — высокая.
В общем случае, коэффициент детерминации находится по формуле: 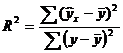 или
или 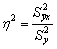
В этой формуле указаны дисперсии: 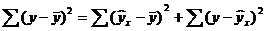 ,
,
где ∑(y- y ) 2 — общая сумма квадратов отклонений;
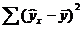 — сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
— сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»); 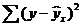 — остаточная сумма квадратов отклонений.
— остаточная сумма квадратов отклонений.
В случае нелинейной регрессии коэффициент детерминации рассчитывается через этот калькулятор. При множественной регрессии, коэффициент детемрминации можно найти через сервис Множественная регрессия
Пример . Дано:
- доля денежных доходов, направленных на прирост сбережений во вкладах, займах, сертификатах и в покупку валюты, в общей сумме среднедушевого денежного дохода, % (Y)
- среднемесячная начисленная заработная плата, тыс. руб. (X)
Следует выполнить: 1. построить поле корреляции и сформировать гипотезу о возможной форме и направлении связи; 2. рассчитать параметры уравнений линейной и A1; 3. выполнить расчет прогнозного значения результата, предполагая, что прогнозные значения факторов составят B2 % от их среднего уровня; 4. оценить тесноту связи с помощью показателей корреляции и детерминации, проанализировать их значения; 5. Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом; 6. Оценить с помощью средней ошибки аппроксимации качество уравнений; 7. Оценить надежность уравнений в целом через F-критерий Фишера для уровня значимости а = 0,05. По значениям характеристик, рассчитанных в пп. 5,6 и данном пункте, выберете лучшее уравнение регрессии и дайте его обоснование.
- Решение онлайн
- Видео решение
Уравнение имеет вид y = ax + b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая.
Уравнение регрессии
Коэффициент детерминации для линейной регрессии равен квадрату коэффициента корреляции.
R 2 = 0.91 2 = 0.83, т.е. в 83% случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — высокая
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 15.1 | 255 | 228.01 | 65025 | 3850.5 | 505.26 | 527451.17 | 62630.22 | 420.25 |
| 17 | 261 | 289 | 68121 | 4437 | 549.38 | 518772.07 | 83161.41 | 345.96 |
| 12 | 293 | 144 | 85849 | 3516 | 433.28 | 473699.53 | 19678.51 | 556.96 |
| 10 | 310 | 100 | 96100 | 3100 | 386.84 | 450587.75 | 5904.58 | 655.36 |
| 74 | 1425 | 5476 | 2030625 | 105450 | 1872.88 | 196906.67 | 200600 | 1474.56 |
| 83 | 1985 | 6889 | 3940225 | 164755 | 2081.86 | 1007497.33 | 9381.6 | 2246.76 |
| 85 | 2549 | 7225 | 6497401 | 216665 | 2128.3 | 2457813.93 | 176990.6 | 2440.36 |
| 81 | 2012 | 6561 | 4048144 | 162972 | 2035.42 | 1062428.38 | 548.49 | 2061.16 |
| 22 | 1562 | 484 | 2439844 | 34364 | 665.47 | 337260.88 | 803758.38 | 184.96 |
| 10 | 386 | 100 | 148996 | 3860 | 386.84 | 354332.48 | 0.71 | 655.36 |
| 4 | 383 | 16 | 146689 | 1532 | 247.52 | 357913.03 | 18353.53 | 998.56 |
| 14.1 | 354.1 | 198.81 | 125386.81 | 4992.81 | 482.04 | 393327.58 | 16368.87 | 462.25 |
| 427.2 | 11775.1 | 27710.82 | 19692405.81 | 709494.31 | 11775.1 | 8137990.81 | 1397376.9 | 12502.5 |
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим
Анализ точности определения оценок коэффициентов регрессии
S a = 3.3432
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 1
(-557.64;913.38)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (6.95>1.812).
Статистическая значимость коэффициента регрессии b не подтверждается (0.96 Fkp, то коэффициент детерминации статистически значим
Основы линейной регрессии
Что такое регрессия?
Разместим точки на двумерном графике рассеяния и скажем, что мы имеем линейное соотношение, если данные аппроксимируются прямой линией.
Если мы полагаем, что y зависит от x, причём изменения в y вызываются именно изменениями в x, мы можем определить линию регрессии (регрессия y на x), которая лучше всего описывает прямолинейное соотношение между этими двумя переменными.
Статистическое использование слова «регрессия» исходит из явления, известного как регрессия к среднему, приписываемого сэру Френсису Гальтону (1889).
Он показал, что, хотя высокие отцы имеют тенденцию иметь высоких сыновей, средний рост сыновей меньше, чем у их высоких отцов. Средний рост сыновей «регрессировал» и «двигался вспять» к среднему росту всех отцов в популяции. Таким образом, в среднем высокие отцы имеют более низких (но всё-таки высоких) сыновей, а низкие отцы имеют сыновей более высоких (но всё-таки довольно низких).
Линия регрессии
Математическое уравнение, которое оценивает линию простой (парной) линейной регрессии:
x называется независимой переменной или предиктором.
Y – зависимая переменная или переменная отклика. Это значение, которое мы ожидаем для y (в среднем), если мы знаем величину x, т.е. это «предсказанное значение y»
- a – свободный член (пересечение) линии оценки; это значение Y, когда x=0 (Рис.1).
- b – угловой коэффициент или градиент оценённой линии; она представляет собой величину, на которую Y увеличивается в среднем, если мы увеличиваем x на одну единицу.
- a и b называют коэффициентами регрессии оценённой линии, хотя этот термин часто используют только для b.
Парную линейную регрессию можно расширить, включив в нее более одной независимой переменной; в этом случае она известна как множественная регрессия.

Рис.1. Линия линейной регрессии, показывающая пересечение a и угловой коэффициент b (величину возрастания Y при увеличении x на одну единицу)
Метод наименьших квадратов
Мы выполняем регрессионный анализ, используя выборку наблюдений, где a и b – выборочные оценки истинных (генеральных) параметров, α и β , которые определяют линию линейной регрессии в популяции (генеральной совокупности).
Наиболее простым методом определения коэффициентов a и b является метод наименьших квадратов (МНК).
Подгонка оценивается, рассматривая остатки (вертикальное расстояние каждой точки от линии, например, остаток = наблюдаемому y – предсказанный y, Рис. 2).
Линию лучшей подгонки выбирают так, чтобы сумма квадратов остатков была минимальной.

Рис. 2. Линия линейной регрессии с изображенными остатками (вертикальные пунктирные линии) для каждой точки.
Предположения линейной регрессии
Итак, для каждой наблюдаемой величины  остаток равен разнице
остаток равен разнице  и соответствующего предсказанного
и соответствующего предсказанного  Каждый остаток может быть положительным или отрицательным.
Каждый остаток может быть положительным или отрицательным.
Можно использовать остатки для проверки следующих предположений, лежащих в основе линейной регрессии:
- Между
 и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
и существует линейное соотношение: для любых пар данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
 данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.
данные должны аппроксимировать прямую линию. Если нанести на двумерный график остатки, то мы должны наблюдать случайное рассеяние точек, а не какую-либо систематическую картину.- Остатки нормально распределены с нулевым средним значением;
- Остатки имеют одну и ту же вариабельность (постоянную дисперсию) для всех предсказанных величин Если нанести остатки против предсказанных величин от мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением то это допущение не выполняется;
 Если нанести остатки против предсказанных величин
Если нанести остатки против предсказанных величин  от
от  мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением
мы должны наблюдать случайное рассеяние точек. Если график рассеяния остатков увеличивается или уменьшается с увеличением  то это допущение не выполняется;
то это допущение не выполняется;Если допущения линейности, нормальности и/или постоянной дисперсии сомнительны, мы можем преобразовать или и рассчитать новую линию регрессии, для которой эти допущения удовлетворяются (например, использовать логарифмическое преобразование или др.).
Аномальные значения (выбросы) и точки влияния
«Влиятельное» наблюдение, если оно опущено, изменяет одну или больше оценок параметров модели (т.е. угловой коэффициент или свободный член).
Выброс (наблюдение, которое противоречит большинству значений в наборе данных) может быть «влиятельным» наблюдением и может хорошо обнаруживаться визуально, при осмотре двумерной диаграммы рассеяния или графика остатков.
И для выбросов, и для «влиятельных» наблюдений (точек) используют модели, как с их включением, так и без них, обращают внимание на изменение оценки (коэффициентов регрессии).
При проведении анализа не стоит отбрасывать выбросы или точки влияния автоматически, поскольку простое игнорирование может повлиять на полученные результаты. Всегда изучайте причины появления этих выбросов и анализируйте их.
Гипотеза линейной регрессии
При построении линейной регрессии проверяется нулевая гипотеза о том, что генеральный угловой коэффициент линии регрессии β равен нулю.
Если угловой коэффициент линии равен нулю, между и нет линейного соотношения: изменение не влияет на 
Для тестирования нулевой гипотезы о том, что истинный угловой коэффициент  равен нулю можно воспользоваться следующим алгоритмом:
равен нулю можно воспользоваться следующим алгоритмом:
Вычислить статистику критерия, равную отношению  , которая подчиняется
, которая подчиняется  распределению с
распределению с  степенями свободы, где
степенями свободы, где  стандартная ошибка коэффициента
стандартная ошибка коэффициента 

 ,
,
 — оценка дисперсии остатков.
— оценка дисперсии остатков.
Обычно если достигнутый уровень значимости  нулевая гипотеза отклоняется.
нулевая гипотеза отклоняется.
Можно рассчитать 95% доверительный интервал для генерального углового коэффициента :

где  процентная точка распределения со степенями свободы
процентная точка распределения со степенями свободы  что дает вероятность двустороннего критерия
что дает вероятность двустороннего критерия 
Это тот интервал, который содержит генеральный угловой коэффициент с вероятностью 95%.
Для больших выборок, скажем,  мы можем аппроксимировать
мы можем аппроксимировать  значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
значением 1,96 (то есть статистика критерия будет стремиться к нормальному распределению)
Оценка качества линейной регрессии: коэффициент детерминации R 2
Из-за линейного соотношения и мы ожидаем, что изменяется, по мере того как изменяется , и называем это вариацией, которая обусловлена или объясняется регрессией. Остаточная вариация должна быть как можно меньше.
Если это так, то большая часть вариации будет объясняться регрессией, а точки будут лежать близко к линии регрессии, т.е. линия хорошо соответствует данным.
Долю общей дисперсии , которая объясняется регрессией называют коэффициентом детерминации, обычно выражают через процентное соотношение и обозначают R 2 (в парной линейной регрессии это величина r 2 , квадрат коэффициента корреляции), позволяет субъективно оценить качество уравнения регрессии.
Разность  представляет собой процент дисперсии который нельзя объяснить регрессией.
представляет собой процент дисперсии который нельзя объяснить регрессией.
Нет формального теста для оценки  мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
мы вынуждены положиться на субъективное суждение, чтобы определить качество подгонки линии регрессии.
Применение линии регрессии для прогноза
Можно применять регрессионную линию для прогнозирования значения по значению в пределе наблюдаемого диапазона (никогда не экстраполируйте вне этих пределов).
Мы предсказываем среднюю величину для наблюдаемых, которые имеют определенное значение  путем подстановки этого значения в уравнение линии регрессии.
путем подстановки этого значения в уравнение линии регрессии.
Итак, если  прогнозируем как
прогнозируем как  Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Используем эту предсказанную величину и ее стандартную ошибку, чтобы оценить доверительный интервал для истинной средней величины в популяции.
Повторение этой процедуры для различных величин позволяет построить доверительные границы для этой линии. Это полоса или область, которая содержит истинную линию, например, с 95% доверительной вероятностью.
Подобным образом можно рассчитать более широкую область, внутри которой, как мы ожидаем, лежит наибольшее число (обычно 95%) наблюдений.
Простые регрессионные планы
Простые регрессионные планы содержат один непрерывный предиктор. Если существует 3 наблюдения со значениями предиктора P , например, 7, 4 и 9, а план включает эффект первого порядка P , то матрица плана X будет иметь вид

а регрессионное уравнение с использованием P для X1 выглядит как
Если простой регрессионный план содержит эффект высшего порядка для P , например квадратичный эффект, то значения в столбце X1 в матрице плана будут возведены во вторую степень:

а уравнение примет вид
Y = b 0 + b 1 P 2
Сигма -ограниченные и сверхпараметризованные методы кодирования не применяются по отношению к простым регрессионным планам и другим планам, содержащим только непрерывные предикторы (поскольку, просто не существует категориальных предикторов). Независимо от выбранного метода кодирования, значения непрерывных переменных увеличиваются в соответствующей степени и используются как значения для переменных X . При этом перекодировка не выполняется. Кроме того, при описании регрессионных планов можно опустить рассмотрение матрицы плана X , а работать только с регрессионным уравнением.
Пример: простой регрессионный анализ
Этот пример использует данные, представленные в таблице:

Рис. 3. Таблица исходных данных.
Данные составлены на основе сравнения переписей 1960 и 1970 в произвольно выбранных 30 округах. Названия округов представлены в виде имен наблюдений. Информация относительно каждой переменной представлена ниже:

Рис. 4. Таблица спецификаций переменных.
Задача исследования
Для этого примера будут анализироваться корреляция уровня бедности и степень, которая предсказывает процент семей, которые находятся за чертой бедности. Следовательно мы будем трактовать переменную 3 ( Pt_Poor ) как зависимую переменную.
Можно выдвинуть гипотезу: изменение численности населения и процент семей, которые находятся за чертой бедности, связаны между собой. Кажется разумным ожидать, что бедность ведет к оттоку населения, следовательно, здесь будет отрицательная корреляция между процентом людей за чертой бедности и изменением численности населения. Следовательно мы будем трактовать переменную 1 ( Pop_Chng ) как переменную-предиктор.
Просмотр результатов
Коэффициенты регрессии

Рис. 5. Коэффициенты регрессии Pt_Poor на Pop_Chng.
На пересечении строки Pop_Chng и столбца Парам. не стандартизованный коэффициент для регрессии Pt_Poor на Pop_Chng равен -0.40374 . Это означает, что для каждого уменьшения численности населения на единицу, имеется увеличение уровня бедности на .40374. Верхний и нижний (по умолчанию) 95% доверительные пределы для этого не стандартизованного коэффициента не включают ноль, так что коэффициент регрессии значим на уровне p . Обратите внимание на не стандартизованный коэффициент, который также является коэффициентом корреляции Пирсона для простых регрессионных планов, равен -.65, который означает, что для каждого уменьшения стандартного отклонения численности населения происходит увеличение стандартного отклонения уровня бедности на .65.
Распределение переменных
Коэффициенты корреляции могут стать существенно завышены или занижены, если в данных присутствуют большие выбросы. Изучим распределение зависимой переменной Pt_Poor по округам. Для этого построим гистограмму переменной Pt_Poor .

Рис. 6. Гистограмма переменной Pt_Poor.
Как вы можете заметить, распределение этой переменной заметно отличается от нормального распределения. Тем не менее, хотя даже два округа (два правых столбца) имеют высокий процент семей, которые находятся за чертой бедности, чем ожидалось в случае нормального распределения, кажется, что они находятся «внутри диапазона.»

Рис. 7. Гистограмма переменной Pt_Poor.
Это суждение в некоторой степени субъективно. Эмпирическое правило гласит, что выбросы необходимо учитывать, если наблюдение (или наблюдения) не попадают в интервал (среднее ± 3 умноженное на стандартное отклонение). В этом случае стоит повторить анализ с выбросами и без, чтобы убедиться, что они не оказывают серьезного эффекта на корреляцию между членами совокупности.
Диаграмма рассеяния
Если одна из гипотез априори о взаимосвязи между заданными переменными, то ее полезно проверить на графике соответствующей диаграммы рассеяния.

Рис. 8. Диаграмма рассеяния.
Диаграмма рассеяния показывает явную отрицательную корреляцию ( -.65 ) между двумя переменными. На ней также показан 95% доверительный интервал для линии регрессии, т.е., с 95% вероятностью линия регрессии проходит между двумя пунктирными кривыми.
Критерии значимости

Рис. 9. Таблица, содержащая критерии значимости.
Критерий для коэффициента регрессии Pop_Chng подтверждает, что Pop_Chng сильно связано с Pt_Poor , p .
На этом примере было показано, как проанализировать простой регрессионный план. Была также представлена интерпретация не стандартизованных и стандартизованных коэффициентов регрессии. Обсуждена важность изучения распределения откликов зависимой переменной, продемонстрирована техника определения направления и силы взаимосвязи между предиктором и зависимой переменной.
Коэффициент детерминации в excel
Коэффициент детерминации рассчитывается для оценки качества подбора уравнения регрессии. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50%. Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими. Значение коэффициента детерминации R 2 = 1 означает функциональную зависимость между переменными.
Для линейной зависимости коэффициент детерминации равен квадрату коэффициента корреляции rxy: R 2 = rxy 2 .
2 «>Рассчитать свое значение
Например, значение R 2 = 0.83, означает, что в 83% случаев изменения х приводят к изменению y . Другими словами, точность подбора уравнения регрессии — высокая.
В общем случае, коэффициент детерминации находится по формуле: или
В этой формуле указаны дисперсии:
,
где ∑(y- y ) — общая сумма квадратов отклонений;
— сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
— остаточная сумма квадратов отклонений.
В случае нелинейной регрессии коэффициент детерминации рассчитывается через этот калькулятор. При множественной регрессии, коэффициент детемрминации можно найти через сервис Множественная регрессия
- доля денежных доходов, направленных на прирост сбережений во вкладах, займах, сертификатах и в покупку валюты, в общей сумме среднедушевого денежного дохода, % (Y)
- среднемесячная начисленная заработная плата, тыс. руб. (X)
Следует выполнить: 1. построить поле корреляции и сформировать гипотезу о возможной форме и направлении связи; 2. рассчитать параметры уравнений линейной и A1; 3. выполнить расчет прогнозного значения результата, предполагая, что прогнозные значения факторов составят B2 % от их среднего уровня; 4. оценить тесноту связи с помощью показателей корреляции и детерминации, проанализировать их значения; 5. Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом; 6. Оценить с помощью средней ошибки аппроксимации качество уравнений; 7. Оценить надежность уравнений в целом через F-критерий Фишера для уровня значимости а = 0,05. По значениям характеристик, рассчитанных в пп. 5,6 и данном пункте, выберете лучшее уравнение регрессии и дайте его обоснование.
Уравнение имеет вид y = ax + b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая.
Уравнение регрессии
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим
Анализ точности определения оценок коэффициентов регрессии
S a = 3.3432
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 1
(-557.64;913.38)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается
Статистическая значимость коэффициента регрессии b не подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(a — t a S a; a + t aS a)
(17.1616;29.2772)
(b — t b S b; b + t bS b)
(-136.4585;445.7528)
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим
Коэффициент детерминации в Excel (Эксель)
Для статистических моделей во многих случаях необходимо определить точность прогноза. Это производится с помощью специальных расчётов в Microsoft Excel, а использоваться будет коэффициент детерминации. Он обозначается как R^2.
Статистические модели можно разделить на качественные уровни в зависимости от коэффициента. От 0.8 до 1 относятся модели хорошего качества, модели достаточного качества имеют уровень от 0.5 до 0.8, а плохое качество имеет диапазон от 0 до 0.5.
Способ определения точности с помощью функции КВПИРСОН
В линейной функции коэффициент детерминации будет равен квадрату корреляционного коэффициента. Рассчитать его можно с помощью специальной функции. Для начала создадим таблицу с данными.
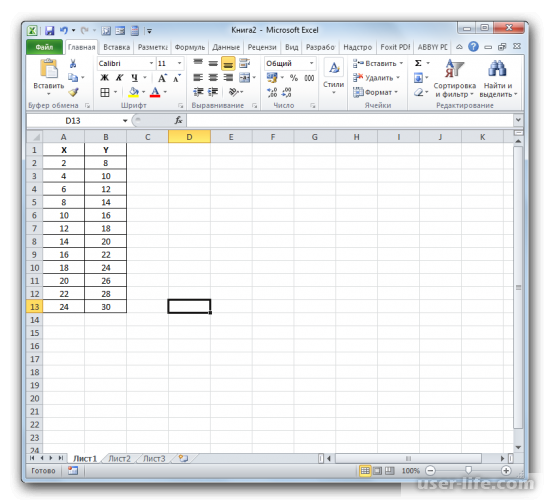
Потом нужно выбрать место, где будет показан результат расчёта и нажимаем на кнопку вставки функции.

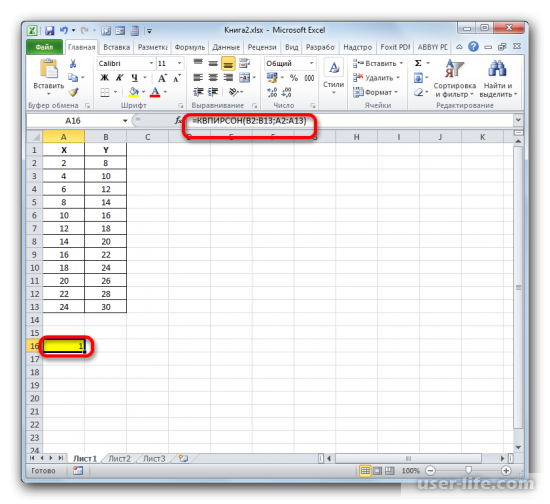
После этого откроется специальное окно. Категорию нужно выбрать «Статистические» и выбираем КВПИРСОН. Эта функция позволяет определить коэффициент корреляции касательно функции Пирсона, соответственно квадратное значение коэффициента корреляции = коэффициенту детерминации.
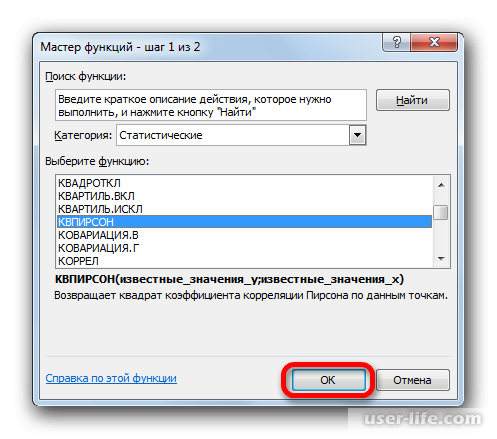
После подтверждения действия, появится окно в котором нужно в полях выставить «Известные значения Х» и «Известные значения Y». Нажимаем мышкой поле «Известные значения Y» и в рабочем окне выделяем данные столбца Y. Аналогичное действие делаем и с другим полем выбирая данные уже с таблицы Х.
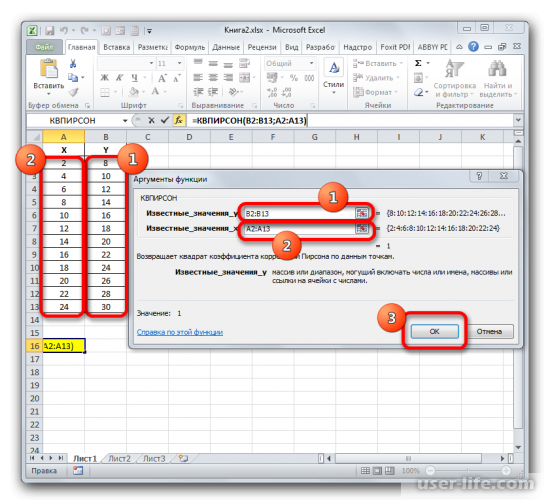
Как результат этих действий будет показано значение коэффициента детерминации в ячейке, которая ранее была выбрана для отображения результата.
Определение коэффициента детерминации если функция не является линейной.
Если функция нелинейная, то инструментарий Excel также позволяет рассчитать коэффициент с помощью инструмента «Регрессия». Его можно найти в пакете анализа данных. Но для начала нужно активировать этот пакет, перейдя в раздел «Файл» и в списке открыть «Параметры».
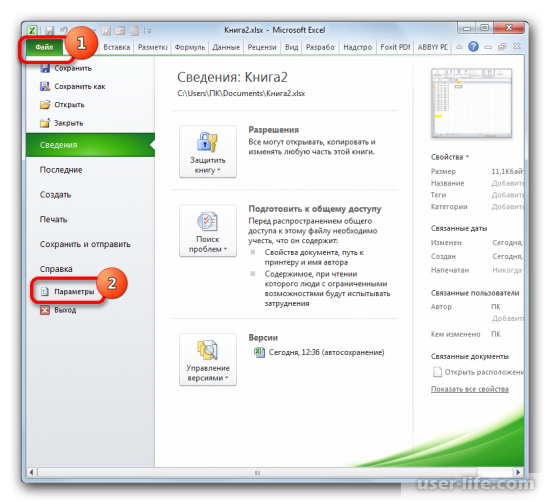
После этого можно увидеть новое окно, в котором нужно в меню выбрать «Надстройки», а в специальном поле по управлению надстройками выбираем «Надстройки Excel» и переходим к ним.
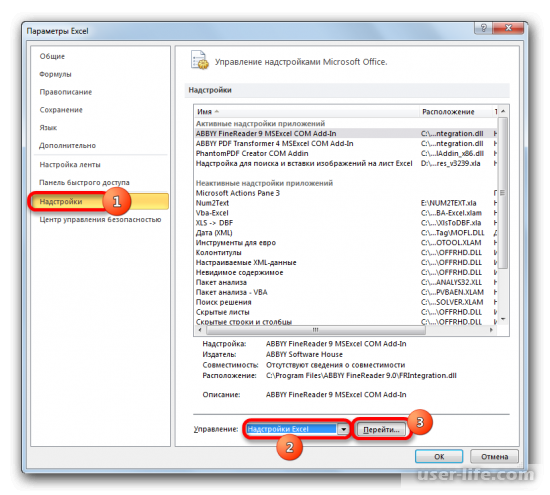
После перехода в надстройки Excel появится новое окно. В нём можно увидеть доступные для пользователя надстройки. Ставим галочку возле «Пакет анализа» и подтверждаем действие.
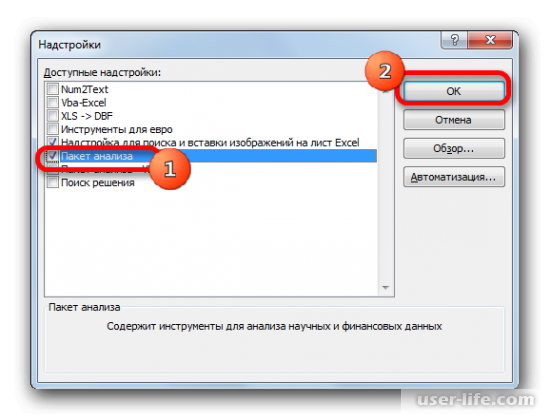
Найти его можно в разделе «Данные», после перехода в который нажимаем на «Анализ данных» в правой части экрана.
После его открытия, в списке выбираем «Регрессия»и подтверждаем действие.
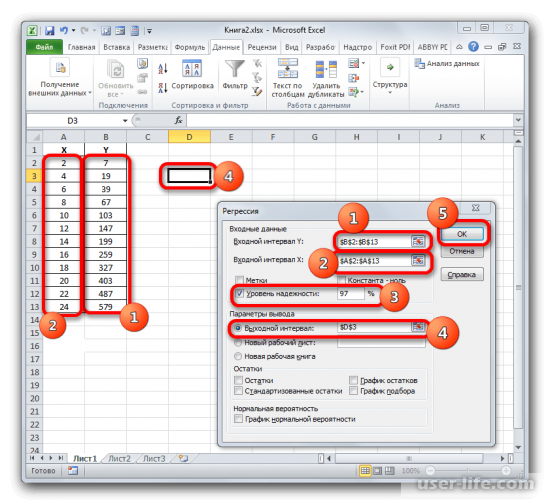
После этого появится новое окно в котором можно производить настройки. Входные данные позволяют настроить значение интервалов Х и Y, достаточно выделить соответствующие ячейки аргументов другого аргумента. В поле уровня надежности можно выставить нужный показатель. Параметры вывода позволяют задать где будет показан результат. Если к примеру выбрать показ на текущем листе, то для начала нужно выбрать пункт «Выходной интервал» — и нажать на области основного окна где будет в будущем отображаться результат и координаты ячейки будут показаны соответствующем поле. В конце подтверждаем действие.
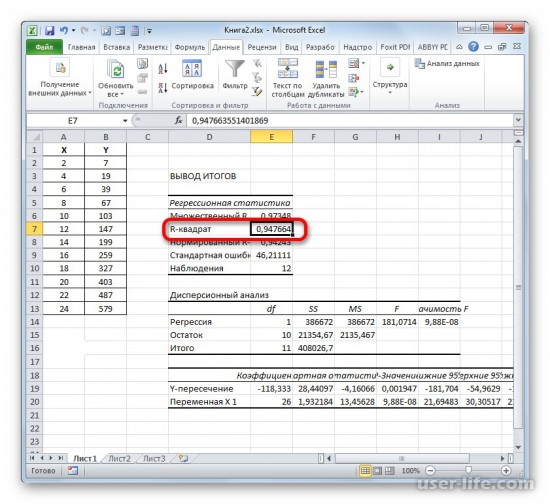
В рабочем окне появится результат. Так как мы вычисляем коэффициент детерминации, то в итогах нам нужен R-коэффициент. Если посмотреть на значение, то можно увидеть что оно относится к наилучшему качеству.
Способ определения коэффициента детерминации для линии тренда
Имея созданную таблицу с соответствующими значение, создаем график. Чтобы провести на нём линию тренда надо нажать на график, а именно на область где строится линия. Сверху в панели инструментов выбрать раздел «Макет», а в нём выбрать «Линия тренда». После этого в контексте данного примера в списке выбираем «Экспоненциальное приближение».
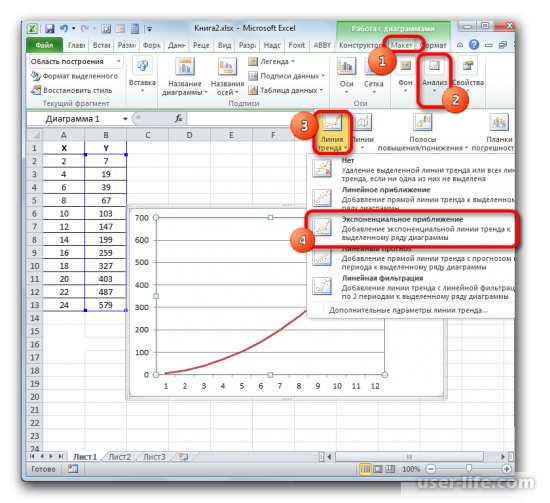
Линия тренда будет отображена на графике как кривая с черным цветом.
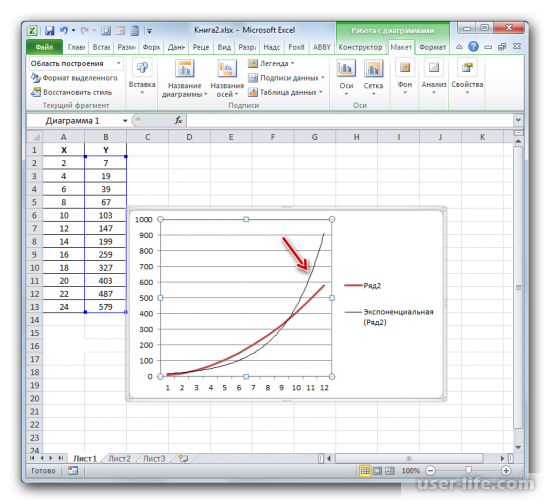
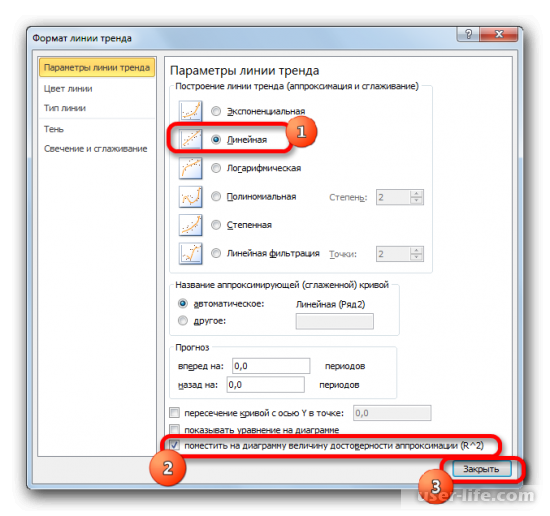
Для того чтобы показать коэффициент детерминации, нужно по черной кривой нажать правой кнопкой мыши и выбрать в списке «Формат линии тренда».
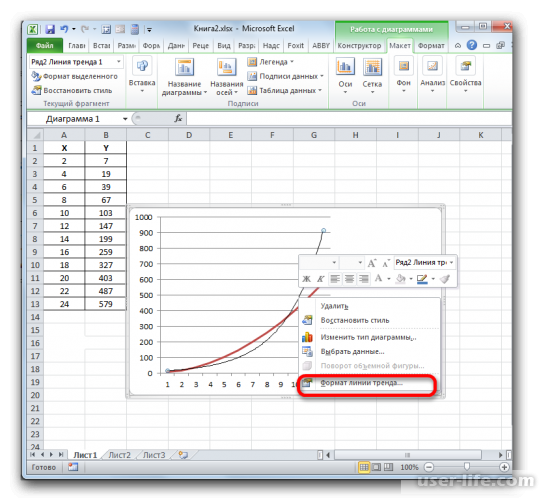
После этого появится новое окно. В нём нужно отметить флажком и выбрать нужное действие (показано на скриншоте). Благодаря этому коэффициент будет отображен на графике. После того как это было сделано, закрываем окно.
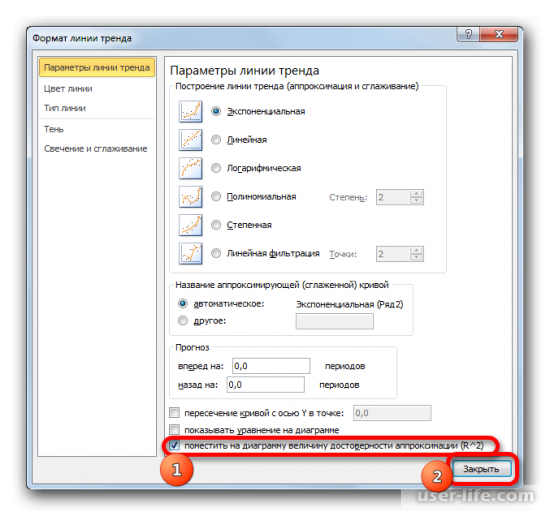
После закрытия окна формата линии тренда в рабочем окне можно увидеть значение коэффициента детерминации.
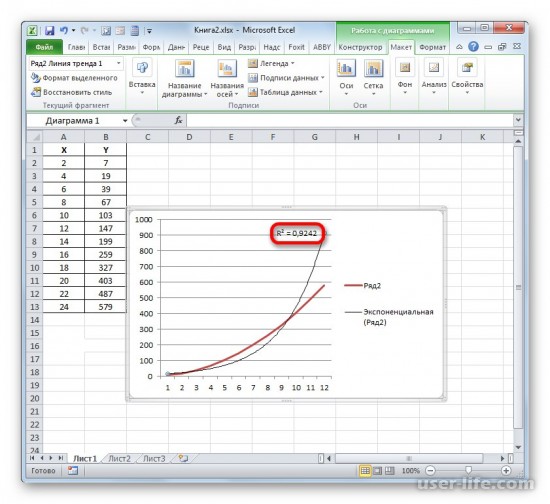
Если пользователю нужен другой типаж линии тренда, то в окне «Формат линии тренда» можно выбрать его. Не забыв задать его ранее при создании линии тренда в разделе «Макет» или в контекстном меню. Также не забываем ставить флажок для функции R^2.
Как результат можно увидеть изменение линии тренда и число достоверности.
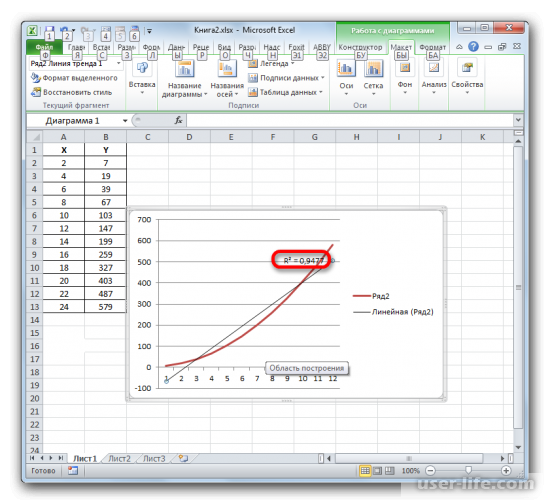
После просмотра разных вариаций линий тренда, пользователь может определить наиболее подходящую для себя так как показатель достоверности может меняться в зависимости от выбора линии. Максимальный коэффициент это единица, что означает максимальную достоверность, однако не всегда можно достигнуть этого значения.
Так было рассмотрено несколько способов по нахождению коэффициента детерминации. Пользователь может выбрать наиболее оптимальный для своих целей.
Алгоритм вычисления коэффициента выборочной детерминации в MS-Excel Текст научной статьи по специальности « Математика»
 CC BY
CC BY
Аннотация научной статьи по математике, автор научной работы — Красильников Дмитрий Евгеньевич
Рассматривается коэффициент выборочной детерминации как критерий однородности выборок в социально-экономических исследованиях. Приводится геометрическое доказательство закона разложения дисперсии , предлагается алгоритм вычисления коэффициента выборочной детерминации в MS-Excel, рассматривается случай, когда закон разложения дисперсии не выполняется, показана связь между коэффициентом выборочной детерминации и эмпирическим корреляционным отношением .
Похожие темы научных работ по математике , автор научной работы — Красильников Дмитрий Евгеньевич
Текст научной работы на тему «Алгоритм вычисления коэффициента выборочной детерминации в MS-Excel»
Д. Е. Красильников
АЛГОРИТМ ВЫЧИСЛЕНИЯ КОЭФФИЦИЕНТА ВЫБОРОЧНОЙ ДЕТЕРМИНАЦИИ
Нижегородский почтамт. Отделение почтовой связи №24
Рассматривается коэффициент выборочной детерминации как критерий однородности выборок в социально-экономических исследованиях. Приводится геометрическое доказательство закона разложения дисперсии, предлагается алгоритм вычисления коэффициента выборочной детерминации в MS-Excel, рассматривается случай, когда закон разложения дисперсии не выполняется, показана связь между коэффициентом выборочной детерминации и эмпирическим корреляционным отношением.
Ключевые слова: коэффициент выборочной детерминации, закон разложения дисперсии, MS-Excel, критерий однородности выборок, дисперсионный анализ, эмпирическое корреляционное отношение.
При проведении социологических, психологических, экономических и маркетинговых исследований почти всегда встает вопрос о репрезентативности исследуемой выборки. Под репрезентативностью выборки, чаще всего, понимается ее однородность. При этом в современной литературе по соответствующим дисциплинам не дается универсальный метод проверки гипотезы об однородности. Как правило, для такой проверки используют так называемый ¿-критерий, F-критерий или критерий «Хи-квадрат» (см., например, [1]), которые базируются на сравнении средних величин со значением функции Стьюдента, Фишера или Хи -квадрат. Однако эти критерии слабо чувствительны к социально-экономическим данным ввиду небольшого разброса значений таких данных, а применение указанных функций недостаточно обосновано, так как эти критерии были разработаны для биологических, а не социально-экономических исследований.
Другим распространенным подходом к оценке репрезентативности является обоснованность выборки с позиций той или иной задачи. Например, при изучении спроса на автомобили стоимостью от миллиона рублей выборка, сделанная из лиц с доходом 8-10 тыс. руб. , будет всегда нерепрезентативной.
Тем не менее, в Советском Союзе была разработана специальная статистика (функция от выборочной совокупности), позволяющая оценить однородность любой выборки при условии ее стратификации — коэффициент выборочной детерминации (^2выб). Его не следует путать с коэффициентом детерминации (R2 ), который характеризует качество аппроксимации с помощью линейной функции и не имеет отношения к выборочному методу.
Данная статистика основана на разложении дисперсии на межгрупповую и внутриг-рупповую. Это разложение также используется в дисперсионном анализе. «Первоначально (1918 г.) дисперсионный анализ был разработан английским математиком-статистиком Р.А. Фишером для обработки результатов агрономических опытов по выявлению условий получения максимального урожая различных сортов сельскохозяйственных культур. Сам термин «дисперсионный анализ» Фишер употребил позднее [2, с. 392].
Чтобы понять, на чем основано разложение дисперсии, рассмотрим так называемый «прямоугольный выборочный план», используемый в однофакторном дисперсионном анализе (табл. 1).
Этот план представляет собой таблицу, в которой каждый столбец является выборкой с n элементами. Всего делается m таких выборок. В литературе эти столбцы часто называют факторами, группами или стратами, а само расположение элементов выборок — стратификацией.
© Красильников Д. Е., 2016.
В этой статье при обозначении элемента таблицы символом у, первый индекс указывает номер строки, а второй — номер столбца, в соответствии с правилом обозначения элементов матриц, принятым в Советском Союзе. Замечу, что в английской традиции принята обратная запись, то есть сначала пишут столбец, а затем строку, а в современной российской литературе встречаются оба варианта.
Очевидно, что общее число элементов в таблице N есть
Прямоугольный выборочный план
1 у11 у12 уЦ у 1т
2 у21 у22 у 2 i у 2т
1 у,1 у 2 у, у гт
п уп1 уп 2 у п] у пт
Среднее у1 у 2 у, у т
По каждому столбцу вычисляется среднее арифметическое у. (внутригрупповая средняя), которое заносится в последнюю строку таблицы,
Матрица парных коэффициентов корреляции
Матрица парных коэффициентов корреляции представляет собой матрицу, элементами которой являются парные коэффициенты корреляции. Например, для трех переменных эта матрица имеет вид:
| — | y | x1 | x2 | x3 |
| y | 1 | ryx1 | ryx2 | ryx3 |
| x1 | rx1y | 1 | rx1x2 | rx1x3 |
| x2 | rx2y | rx2x1 | 1 | rx2x3 |
| x3 | rx3y | rx3x1 | rx3x2 | 1 |
Вставьте в поле матрицу парных коэффициентов.
Пример . По данным 154 сельскохозяйственных предприятий Кемеровской области 2003 г. изучить эффективность производства зерновых (табл. 13).
- Определите факторы, формирующие рентабельность зерновых в сельскохозяйственных предприятий в 2003 г.
- Постройте матрицу парных коэффициентов корреляции. Установите, какие факторы мультиколлинеарны.
- Постройте уравнение регрессии, характеризующее зависимость рентабельности зерновых от всех факторов.
- Оцените значимость полученного уравнения регрессии. Какие факторы значимо воздействуют на формирование рентабельности зерновых в этой модели?
- Оцените значение рентабельности производства зерновых в сельскохозяйственном предприятии № 3.
Решение получаем с помощью калькулятора Уравнение множественной регрессии :
Матрица X T
Умножаем матрицы, (X T X)
| 22 | 19.76 | 27.81 | 13.19 |
| 19.76 | 23.78 | 22.45 | 15.73 |
| 27.81 | 22.45 | 42.09 | 14.96 |
| 13.19 | 15.73 | 14.96 | 10.45 |
В матрице, (X T X) число 22, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
Умножаем матрицы, (X T Y)
| 14.17 |
| 15.91 |
| 16.58 |
| 10.56 |
Находим определитель det(X T X) T = 34.35
Находим обратную матрицу (X T X) -1
| 0.6821 | 0.3795 | -0.2934 | -1.0118 |
| 0.3795 | 9.4402 | -0.133 | -14.4949 |
| -0.2934 | -0.133 | 0.1746 | 0.3204 |
| -1.0118 | -14.4949 | 0.3204 | 22.7272 |
Вектор оценок коэффициентов регрессии равен
s = (X T X) -1 X T Y =
| 0.1565 |
| 0.3375 |
| 0.0043 |
| 0.2986 |
Уравнение регрессии (оценка уравнения регрессии): Y = 0.1565 + 0.3375X 1+ 0.0043X 2+ 0.2986X 3
Матрица парных коэффициентов корреляции
Для y и x2
Уравнение имеет вид y = ax + b
Средние значения
Для y и x3
Уравнение имеет вид y = ax + b
Средние значения
Для x1 и x2
Уравнение имеет вид y = ax + b
Средние значения
Для x1 и x3
Уравнение имеет вид y = ax + b
Средние значения
Для x2 и x3
Уравнение имеет вид y = ax + b
Средние значения
Оценка среднеквадратичного отклонения равна
Частные коэффициент эластичности E1 2 = 0.62 2 = 0.38, т.е. в 38.0855 % случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — средняя
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл(n-m-1;a) = (18;0.05) = 1.734
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим
Интервальная оценка для коэффициента корреляции (доверительный интервал)
Доверительный интервал для коэффициента корреляции
r(0.3882;0.846)
5. Проверка гипотез относительно коэффициентов уравнения регрессии (проверка значимости параметров множественного уравнения регрессии).
1) t-статистика
Статистическая значимость коэффициента регрессии b0не подтверждается
Статистическая значимость коэффициента регрессии b1не подтверждается
Статистическая значимость коэффициента регрессии b2не подтверждается
Статистическая значимость коэффициента регрессии b3не подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(bi— t iS i; bi+ t iS i)
b 0: (-0.7348;1.0478)
b 1: (-2.9781;3.6531)
b 2: (-0.4466;0.4553)
b 3: (-4.8459;5.4431)
Алгоритм вычисления коэффициента выборочной детерминации в MS-Excel Текст научной статьи по специальности « Математика»
CC BY
Аннотация научной статьи по математике, автор научной работы — Красильников Дмитрий Евгеньевич
Рассматривается коэффициент выборочной детерминации как критерий однородности выборок в социально-экономических исследованиях. Приводится геометрическое доказательство закона разложения дисперсии , предлагается алгоритм вычисления коэффициента выборочной детерминации в MS-Excel, рассматривается случай, когда закон разложения дисперсии не выполняется, показана связь между коэффициентом выборочной детерминации и эмпирическим корреляционным отношением .
Похожие темы научных работ по математике , автор научной работы — Красильников Дмитрий Евгеньевич
Текст научной работы на тему «Алгоритм вычисления коэффициента выборочной детерминации в MS-Excel»
Д. Е. Красильников
АЛГОРИТМ ВЫЧИСЛЕНИЯ КОЭФФИЦИЕНТА ВЫБОРОЧНОЙ ДЕТЕРМИНАЦИИ
Нижегородский почтамт. Отделение почтовой связи №24
Рассматривается коэффициент выборочной детерминации как критерий однородности выборок в социально-экономических исследованиях. Приводится геометрическое доказательство закона разложения дисперсии, предлагается алгоритм вычисления коэффициента выборочной детерминации в MS-Excel, рассматривается случай, когда закон разложения дисперсии не выполняется, показана связь между коэффициентом выборочной детерминации и эмпирическим корреляционным отношением.
Ключевые слова: коэффициент выборочной детерминации, закон разложения дисперсии, MS-Excel, критерий однородности выборок, дисперсионный анализ, эмпирическое корреляционное отношение.
При проведении социологических, психологических, экономических и маркетинговых исследований почти всегда встает вопрос о репрезентативности исследуемой выборки. Под репрезентативностью выборки, чаще всего, понимается ее однородность. При этом в современной литературе по соответствующим дисциплинам не дается универсальный метод проверки гипотезы об однородности. Как правило, для такой проверки используют так называемый ¿-критерий, F-критерий или критерий «Хи-квадрат» (см., например, [1]), которые базируются на сравнении средних величин со значением функции Стьюдента, Фишера или Хи -квадрат. Однако эти критерии слабо чувствительны к социально-экономическим данным ввиду небольшого разброса значений таких данных, а применение указанных функций недостаточно обосновано, так как эти критерии были разработаны для биологических, а не социально-экономических исследований.
Другим распространенным подходом к оценке репрезентативности является обоснованность выборки с позиций той или иной задачи. Например, при изучении спроса на автомобили стоимостью от миллиона рублей выборка, сделанная из лиц с доходом 8-10 тыс. руб. , будет всегда нерепрезентативной.
Тем не менее, в Советском Союзе была разработана специальная статистика (функция от выборочной совокупности), позволяющая оценить однородность любой выборки при условии ее стратификации — коэффициент выборочной детерминации (^2выб). Его не следует путать с коэффициентом детерминации (R2 ), который характеризует качество аппроксимации с помощью линейной функции и не имеет отношения к выборочному методу.
Данная статистика основана на разложении дисперсии на межгрупповую и внутриг-рупповую. Это разложение также используется в дисперсионном анализе. «Первоначально (1918 г.) дисперсионный анализ был разработан английским математиком-статистиком Р.А. Фишером для обработки результатов агрономических опытов по выявлению условий получения максимального урожая различных сортов сельскохозяйственных культур. Сам термин «дисперсионный анализ» Фишер употребил позднее [2, с. 392].
Чтобы понять, на чем основано разложение дисперсии, рассмотрим так называемый «прямоугольный выборочный план», используемый в однофакторном дисперсионном анализе (табл. 1).
Этот план представляет собой таблицу, в которой каждый столбец является выборкой с n элементами. Всего делается m таких выборок. В литературе эти столбцы часто называют факторами, группами или стратами, а само расположение элементов выборок — стратификацией.
© Красильников Д. Е., 2016.
В этой статье при обозначении элемента таблицы символом у, первый индекс указывает номер строки, а второй — номер столбца, в соответствии с правилом обозначения элементов матриц, принятым в Советском Союзе. Замечу, что в английской традиции принята обратная запись, то есть сначала пишут столбец, а затем строку, а в современной российской литературе встречаются оба варианта.
Очевидно, что общее число элементов в таблице N есть
Прямоугольный выборочный план
1 у11 у12 уЦ у 1т
2 у21 у22 у 2 i у 2т
1 у,1 у 2 у, у гт
п уп1 уп 2 у п] у пт
Среднее у1 у 2 у, у т
По каждому столбцу вычисляется среднее арифметическое у. (внутригрупповая средняя), которое заносится в последнюю строку таблицы,
Построение функции тренда в Excel. Быстрый прогноз без учета сезонности
Глядя на любой набор данных распределенных во времени (динамический ряд), мы можем визуально определить падения и подъемы показателей, которые он содержит. Закономерность подъемов и падений называется трендом, который может говорить о том, увеличиваются или уменьшаются наши данные.
Пожалуй, цикл статей о прогнозировании я начну с самого простого — построении функции тренда. Для примера возьмем данные о продажах и построим модель, которая опишет зависимость продаж от времени.
Базовые понятия
Думаю, еще со школы все знакомы с линейной функцией, она как раз и лежит в основе тренда:
Y — это объем продаж, та переменная, которую мы будем объяснять временем и от которого она зависит, то есть Y(t);
t — номер периода (порядковый номер месяца), который объясняет план продаж Y;
a0 — это нулевой коэффициент регрессии, который показывает значение Y(t), при отсутствии влияния объясняющего фактора (t=0);
a1 — коэффициент регрессии, который показывает, на сколько исследуемый показатель продаж Y зависит от влияющего фактора t;
E — случайные возмущения, которые отражают влияния других неучтенных в модели факторов, кроме времени t.
Построение модели
Итак, мы знаем объем продаж за прошедшие 9 месяцев. Вот, что из себя представляет наша табличка:

Следующее, что мы должны сделать — это определить коэффициенты a0 и a1 для прогнозирования объема продаж за 10-ый месяц.
Определение коэффициентов модели
Строим график. По горизонтали видим отложенные месяцы, по вертикали объем продаж:
В Google Sheets выбираем Редактор диаграмм -> Дополнительные и ставим галочку возле Линии тренда. В настройках выбираем Ярлык — Уравнение и Показать R^2.
Если вы делаете все в MS Excel, то правой кнопкой мыши кликаем на график и в выпадающем меню выбираем «Добавить линию тренда».
По умолчанию строится линейная функция. Справа выбираем «Показывать уравнение на диаграмме» и «Величину достоверности аппроксимации R^2».
Вот, что получилось:
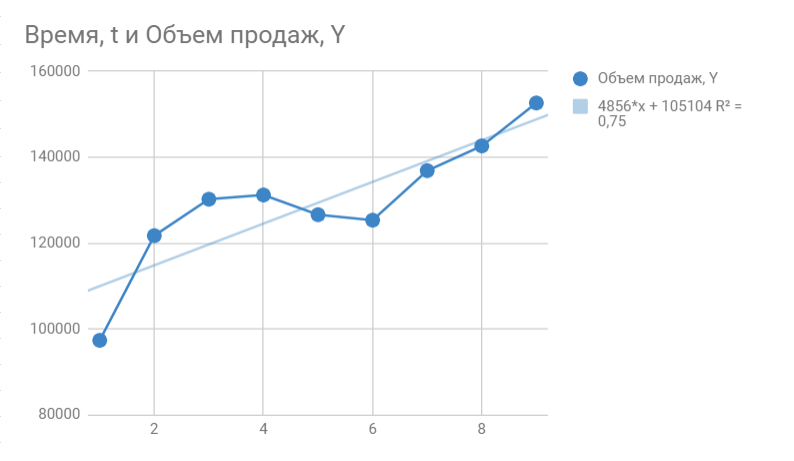
На графике мы видим уравнение функции:
y = 4856*x + 105104
Она описывает объем продаж в зависимости от номера месяца, на который мы хотим эти продажи спрогнозировать. Рядом видим коэффициент детерминации R^2, который говорит о качестве модели и на сколько хорошо она описывает наши продажи (Y). Чем ближе к 1, тем лучше.
У меня R^2 = 0,75. Это средний показатель, он говорит о том, что в модели не учтены какие-то другие значимые факторы помимо времени t, например, это может быть сезонность.
Прогнозируем
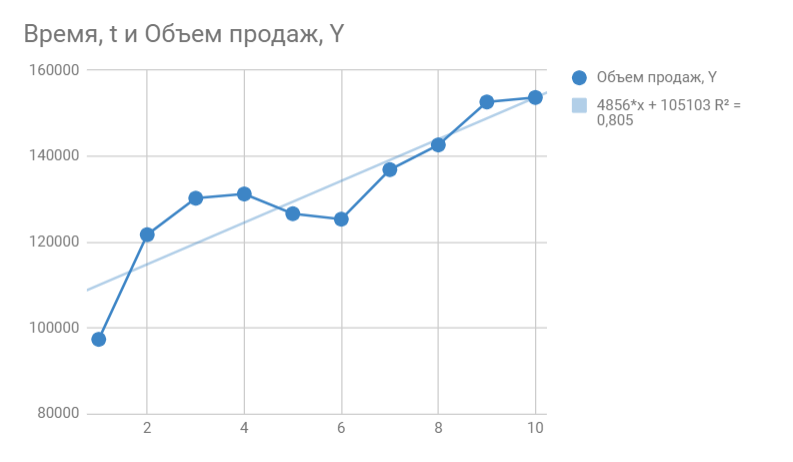
Чтобы рассчитать продажи за 10-ый месяц, подставляем в функцию тренда 10 вместо x. То есть,
y = 4856*10 + 105104
Получаем 153664 продажи в следующем месяце. Если добавим новую точку на график, то сразу видим, что R^2 улучшился.
Таким образом вы можете спрогнозировать данные на несколько месяцев вперед, но без учета других факторов ваш прогноз будет лежать на линии тренда и будет не таким информативным как хотелось бы. К тому же, долгосрочный прогноз, сделанный таким способом будет очень приблизительным.
Повысить точность модели можно добавлением сезонности к функции тренда, что мы и сделаем в следующей статье.
http://statistica.ru/theory/osnovy-lineynoy-regressii/
http://fobosworld.ru/koeffitsient-determinatsii-v-excel/