Пример нахождения статистической значимости коэффициентов регрессии
Числитель в этой формуле может быть рассчитан через коэффициент детерминации и общую дисперсию признака-результата:  .
.
Для параметра a критерий проверки гипотезы о незначимом отличии его от нуля имеет вид:
,
где — оценка параметра регрессии, полученная по наблюдаемым данным;
μa – стандартная ошибка параметра a.
Для линейного парного уравнения регрессии: .
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции в генеральной совокупности используют следующий критерий: , где ryx — оценка коэффициента корреляции, полученная по наблюдаемым данным; mr – стандартная ошибка коэффициента корреляции ryx.
Для линейного парного уравнения регрессии: .
В парной линейной регрессии между наблюдаемыми значениями критериев существует взаимосвязь: t ( b =0) = t (r=0).
Пример №1 . Уравнение имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.73 2 = 0.54, т.е. в 54% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — средняя.
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 69 | 124 | 4761 | 15376 | 8556 | 128.48 | 491.36 | 20.11 | 367.36 |
| 83 | 133 | 6889 | 17689 | 11039 | 141.4 | 173.36 | 70.56 | 26.69 |
| 92 | 146 | 8464 | 21316 | 13432 | 149.7 | 0.03 | 13.71 | 14.69 |
| 97 | 153 | 9409 | 23409 | 14841 | 154.32 | 46.69 | 1.73 | 78.03 |
| 88 | 138 | 7744 | 19044 | 12144 | 146.01 | 66.69 | 64.21 | 0.03 |
| 93 | 159 | 8649 | 25281 | 14787 | 150.63 | 164.69 | 70.13 | 23.36 |
| 74 | 145 | 5476 | 21025 | 10730 | 133.1 | 1.36 | 141.68 | 200.69 |
| 79 | 152 | 6241 | 23104 | 12008 | 137.71 | 34.03 | 204.21 | 84.03 |
| 105 | 168 | 11025 | 28224 | 17640 | 161.7 | 476.69 | 39.74 | 283.36 |
| 99 | 154 | 9801 | 23716 | 15246 | 156.16 | 61.36 | 4.67 | 117.36 |
| 85 | 127 | 7225 | 16129 | 10795 | 143.25 | 367.36 | 263.91 | 10.03 |
| 94 | 155 | 8836 | 24025 | 14570 | 151.55 | 78.03 | 11.91 | 34.03 |
| 1058 | 1754 | 94520 | 258338 | 155788 | 1754 | 1961.67 | 906.57 | 1239.67 |
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.2704
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 88,16
(128.06;163.97)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (3.41>1.812).
Статистическая значимость коэффициента регрессии b подтверждается (2.7>1.812).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.812):
(a — tтабл·S a; a + tтабл·Sa)
(0.4325;1.4126)
(b — tтабл·S b; b + tтабл·Sb)
(21.3389;108.3164)
2) F-статистики
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим.
Пример №2 . По территориям региона приводятся данные за 199Х г.;
| Среднедневная заработная плата, руб., у | ||
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х , составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение находим с помощью калькулятора.
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
12a+1027b=1869
1027a+89907b=161808
Из первого уравнения выражаем а и подставим во второе уравнение. Получаем b = 0.92, a = 76.98
Уравнение регрессии: y = 0.92 x + 76.98 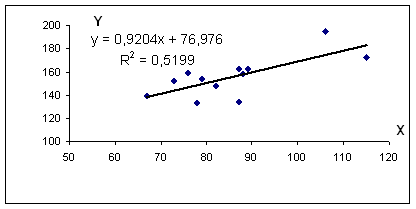
1. Параметры уравнения регрессии.
Выборочные средние.
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%, среднедневная заработная плата изменится менее чем на 1%. Другими словами — влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199, т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами — точность подбора уравнения регрессии — средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| y 2 | x·y | y(x) | (y i — y ) 2 | (y-y(x)) 2 | (x i — x ) 2 | |y-y x |:y | |||
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим tкрит:
tкрит = (10;0.05) = 1.812
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(0.9204 — 1.812·0.2797; 0.9204 + 1.812·0.2797)
(0.4136;1.4273)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a-ta)
(76.9765 — 1.812·24.2116; 76.9765 + 1.812·24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Показатели качества регрессии
Качество модели регрессии связывают с адекватностью модели наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным проводится на основе анализа остатков —  .
.
Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов. Согласно общим предположениям регрессионного анализа, остатки должны вести себя как независимые (в действительности, почти независимые) одинаково распределенные случайные величины.
Качество модели регрессии оценивается по следующим направлениям:
проверка качества всего уравнения регрессии;
проверка значимости всего уравнения регрессии;
проверка статистической значимости коэффициентов уравнения регрессии;
проверка выполнения предпосылок МНК.
При анализе качества модели регрессии, в первую очередь, используется коэффициент детерминации, который определяется следующим образом:

где 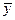 — среднее значение зависимой переменной,
— среднее значение зависимой переменной,
 — предсказанное (расчетное) значение зависимой переменной.
— предсказанное (расчетное) значение зависимой переменной.
Коэффициент детерминации показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, т. е. определяет, какая доля вариации признака Y учтена в модели и обусловлена влиянием на него факторов.
Чем ближе 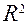 к 1, тем выше качество модели.
к 1, тем выше качество модели.
Для оценки качества регрессионных моделей целесообразно также использовать коэффициент множественной корреляции (индекс корреляции) R
R =  =
= 
Данный коэффициент является универсальным, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных.
Важным моментом является проверка значимости построенного уравнения в целом и отдельных параметров.
Оценить значимость уравнения регрессии – это означает установить, соответствует ли математическая модель, выражающая зависимость между Y и Х, фактическим данным и достаточно ли включенных в уравнение объясняющих переменных Х для описания зависимой переменной Y
Оценка значимости уравнения регрессии производится для того, чтобы узнать, пригодно уравнение регрессии для практического использования (например, для прогноза) или нет.
Для проверки значимости модели регрессии используется F-критерий Фишера. Если расчетное значение с n1= k и n2 = (n — k — 1) степенями свободы, где k – количество факторов, включенных в модель, больше табличного при заданном уровне значимости, то модель считается значимой.

В качестве меры точности применяют несмещенную оценку дисперсии остаточной компоненты, которая представляет собой отношение суммы квадратов уровней остаточной компоненты к величине (n- k -1), где k – количество факторов, включенных в модель. Квадратный корень из этой величины (  ) называется стандартной ошибкой:
) называется стандартной ошибкой:
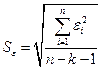
значимость отдельных коэффициентов регрессии проверяется по t-статистике путем проверки гипотезы о равенстве нулю j-го параметра уравнения (кроме свободного члена):
 ,
,
где Saj — это стандартное (среднеквадратическое) отклонение коэффициента уравнения регрессии aj. Величина Saj представляет собой квадратный корень из произведения несмещенной оценки дисперсии  и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.
и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.

где  — диагональный элемент матрицы
— диагональный элемент матрицы 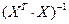 .
.
Если расчетное значение t-критерия с (n — k — 1) степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
Проверка выполнения предпосылок МНК.
Рассмотрим выполнение предпосылки гомоскедастичности, или равноизменчивости случайной составляющей (возмущения).
Невыполнение этой предпосылки, т.е. нарушение условия гомоскедастичности возмущений означает, что дисперсия возмущения зависит от значений факторов. Такие регрессионные модели называются моделями с гетероскедастичностью возмущений.
Обнаружение гетероскедастичности. Для обнаружения гетероскедастичности обычно используют тесты, в которых делаются различные предположения о зависимости между дисперсией случайного члена и объясняющей переменной: тест ранговой корреляции Спирмена, тест Голдфельда — Квандта, тест Глейзера, двусторонний критерий Фишера и другие [2].
При малом объеме выборки для оценки гетероскедастичности может использоваться метод Голдфельда — Квандта. Данный тест используется для проверки такого типа гетероскедастичности, когда дисперсия остатков возрастает пропорционально квадрату фактора. При этом делается предположение, что, случайная составляющая 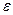 распределена нормально.
распределена нормально.
Чтобы оценить нарушение гомоскедастичности по тесту Голдфельда — Квандта необходимо выполнить следующие шаги.
Упорядочение п наблюдений по мере возрастания переменной х.
Исключение 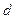 средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
Разделение совокупности на две группы (соответственно с малыми и большими значениями фактора  ) и определение по каждой из групп уравнений регрессии.
) и определение по каждой из групп уравнений регрессии.
Определение остаточной суммы квадратов для первой регрессии  и второй регрессии
и второй регрессии  .
.
Вычисление отношений  (или
(или 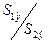 ). В числителе должна быть большая сумма квадратов.
). В числителе должна быть большая сумма квадратов.
Полученное отношение имеет F распределение со степенями свободы k1=n1-k и k2=n-n1-k, (k– число оцениваемых параметров в уравнении регрессии).
Если  , то гетероскедастичность имеет место.
, то гетероскедастичность имеет место.
Чем больше величина F превышает табличное значение F -критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
Оценка влияния отдельных факторов на зависимую переменную на основе модели (коэффициенты эластичности, b — коэффициенты).
Важную роль при оценке влияния факторов играют коэффициенты регрессионной модели. Однако непосредственно с их помощью нельзя сопоставить факторы по степени их влияния на зависимую переменную из-за различия единиц измерения и разной степени колеблемости. Для устранения таких различий при интерпретации применяются средние частные коэффициенты эластичности Э(j) и бета-коэффициенты b(j).
Эластичность Y по отношению к Х(j) определяется как процентное изменение Y, отнесенное к соответствующему процентному изменению Х. В общем случае эластичности не постоянны, они различаются, если измерены для различных точек на линии регрессии. По умолчанию стандартные программы, оценивающие эластичность, вычисляют ее в точках средних значений:
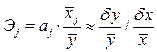
Эластичность ненормирована и может изменяться от —  до + . Важно, что она безразмерна, так что интерпретация эластичности
до + . Важно, что она безразмерна, так что интерпретация эластичности  =2.0 означает, что если
=2.0 означает, что если  изменится на 1%, то это приведет к изменению
изменится на 1%, то это приведет к изменению  на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
Высокий уровень эластичности означает сильное влияние независимой переменной на объясняемую переменную.

где Sxj — среднеквадратическое отклонение фактора j
где 
 .
.
Коэффициент эластичности показывает, на сколько процентов изменяется зависимая переменная при изменении фактора j на один процент. Однако он не учитывает степень колеблемости факторов.
Бета-коэффициент показывает, на какую часть величины среднего квадратического отклонения Sy изменится зависимая переменная Y с изменением соответствующей независимой переменной Хj на величину своего среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных.
Указанные коэффициенты позволяют упорядочить факторы по степени влияния факторов на зависимую переменную.
Долю влияния фактора в суммарном влиянии всех факторов можно оценить по величине дельта — коэффициентов D (j):

где  — коэффициент парной корреляции между фактором j (j = 1. m) и зависимой переменной.
— коэффициент парной корреляции между фактором j (j = 1. m) и зависимой переменной.
В качестве основного литературного источника рекомендуется использовать [4], в качестве дополнительного – [2].
Лекция по эконометрике. Лекция по эконометрике
| Название | Лекция по эконометрике |
| Дата | 21.06.2018 |
| Размер | 1.32 Mb. |
| Формат файла |  |
| Имя файла | Лекция по эконометрике.docx |
| Тип | Лекция #47509 |
| страница | 2 из 5 |
 С этим файлом связано 6 файл(ов). Среди них: ЭКОНО Задача.docx, СТАТ в жив. Лекция №9.docx, Вопросы по АВтоматике.docx, ЛЕКЦИЯ СОЦ.СТАТ..doc, доступность к прдовольствию.pdf, Лекция по эконометрике.docx. Показать все связанные файлы Подборка по базе: 1. Лекция Особенности макетирования и верстки длинных документов, Медицинская статистика Лекция проф.Виноградова К.А.(1).pptx, 6 лекция Отбасы.ppt, 9-10 Лекция дуниетану.ppt, такт 5 лекция.doc, Тест к лекциям.doc, 3 лекция. куиз.docx, 3 лекция.pptx, антибиотики лекция.docx, ТПЭФМ_Практическое занятие 1_между лекциями 11 и 12.doc С этим файлом связано 6 файл(ов). Среди них: ЭКОНО Задача.docx, СТАТ в жив. Лекция №9.docx, Вопросы по АВтоматике.docx, ЛЕКЦИЯ СОЦ.СТАТ..doc, доступность к прдовольствию.pdf, Лекция по эконометрике.docx. Показать все связанные файлы Подборка по базе: 1. Лекция Особенности макетирования и верстки длинных документов, Медицинская статистика Лекция проф.Виноградова К.А.(1).pptx, 6 лекция Отбасы.ppt, 9-10 Лекция дуниетану.ppt, такт 5 лекция.doc, Тест к лекциям.doc, 3 лекция. куиз.docx, 3 лекция.pptx, антибиотики лекция.docx, ТПЭФМ_Практическое занятие 1_между лекциями 11 и 12.doc2.1 Оценка общего качества уравнения регрессии
Коэффициент детерминации характеризует долю вариации (разброса) зависимой переменной, объяснённой с помощью данного уравнения. Замечание. В случае парной линейной регрессии коэффициент детерминации равен квадрату коэффициента линейной корреляции. Более точным является значение коэффициента детерминации с поправкой на число степеней свободы. Разделив каждую СКО на свое число степеней свободы, получим средний квадрат отклонений, или дисперсию на одну степень свободы: Учитывая приведённые выше обозначения, формула коэффициента детерминации с поправкой на число степеней свободы будет иметь вид: Близость коэффициента детерминации к +1 свидетельствует о том, что существует статистически значимая линейная связь между переменными, а уравнение имеет хорошее качество. Близость Самостоятельную важность коэффициент детерминации приобретает только в случае множественной регрессии. Проверить значимость уравнения регрессии – значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включённых в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной. Проверка значимости производится на основе дисперсионного анализа. Согласно идее дисперсионного анализа, общая сумма квадратов отклонений (СКО) y от среднего значения
В первом случае фактор х не оказывает влияния на результат, вся дисперсия y обусловлена воздействием прочих факторов, линия регрессии параллельна оси Ох и уравнение должно иметь вид Во втором случае прочие факторы не влияют на результат, y связан с x функционально, и остаточная СКО равна нулю. Однако на практике в правой части присутствуют оба слагаемых. Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации y приходится на объясненную вариацию. Если объясненная СКО будет больше остаточной СКО, то уравнение регрессии статистически значимо и фактор х оказывает существенное воздействие на результат y. Это равносильно тому, что коэффициент детерминации будет приближаться к единице. Число степеней свободы (df-degrees of freedom) – это число независимо варьируемых значений признака. Для общей СКО требуется (n-1) независимых отклонений, Из этого баланса определяем, что Разделив каждую СКО на свое число степеней свободы, получим средний квадрат отклонений, или дисперсию на одну степень свободы: Анализ статистической значимости коэффициентов линейной регрессии Хотя теоретические значения коэффициентов Дисперсии коэффициентов рассчитываются по формулам: Дисперсия коэффициента регрессии Дисперсия параметра Альтернативная гипотеза имеет вид: t – статистики имеют t – распределение Стьюдента с Если Если Интервальные оценки коэффициентов линейного уравнения регрессии: Доверительный интервал для а: Доверительный интервал для b: Это означает, что с заданной надёжностью Коэффициент регрессии имеет четкую экономическую интерпретацию, поэтому доверительные границы интервала не должны содержать противоречивых результатов, например, Анализ статистической значимости уравнения в целом. Распределение Фишера в регрессионном анализе Оценка значимости уравнения регрессии в целом дается с помощью F- критерия Фишера. При этом выдвигается нулевая гипотеза Величина F – критерия связана с коэффициентом детерминации. В случае множественной регрессии: В случае парной регрессии формула F – статистики принимает вид: Если Если Замечание. В парной линейной регрессии Распределение Фишера может быть использовано не только для проверки гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии, но и гипотезы о равенстве нулю части этих коэффициентов. Это важно при развитии линейной регрессионной модели, так как позволяет оценить обоснованность исключения отдельных переменных или их групп из числа объясняющих переменных, или же, наоборот, включения их в это число. Пусть, например, вначале была оценена множественная линейная регрессия Для того, чтобы проверить гипотезу об одновременном равенстве нулю всех коэффициентов при исключённых переменных, рассчитывается величина По таблицам распределения Фишера, при заданном уровне значимости, находят Аналогичные рассуждения могут быть проведены и по поводу обоснованности включения в уравнение регрессии одной или нескольких k новых объясняющих переменных. В этом случае рассчитывается F – статистика Замечания. 1. Включать новые переменные целесообразно по одной. 2. Для расчёта F – статистики при рассмотрении вопроса о включении объясняющих переменных в уравнение желательно рассматривать коэффициент детерминации с поправкой на число степеней свободы. F – статистика Фишера используется также для проверки гипотезы о совпадении уравнений регрессии для отдельных групп наблюдений. Пусть имеются 2 выборки, содержащие, соответственно, Проверяется нулевая гипотеза Пусть оценено уравнение регрессии того же вида сразу для всех Тогда рассчитывается F – статистика по формуле: Если же Предпосылками МНК являются: 1. случайный характер ошибок регрессии; 2. нулевая средняя величина ошибок регрессии, не зависящая от значения объясняющих переменных; 3. независимость распределения ошибок для различных наблюдений; в случае оценки уравнения на временных рядах – отсутствие автокорреляции ошибок; 4. постоянство дисперсии ошибок, её независимость от значений объясняющих переменных – гомоскедастичность (если эта предпосылка не выполняется, то имеет место гетероскедастичность ошибок); 5. нормальность распределения ошибок регрессии. Для проверки выполнения каждой из предпосылок применения МНК имеются специальные тесты. Реализация многих из этих тестов предполагает значительный объём исходных данных. Если распределение случайных ошибок Проверка первой предпосылки МНК Прежде всего, проверяется случайный характер остатков Рис. 1. Зависимость случайных остатков Рис. 2. Зависимость случайных остатков Проверка второй предпосылки МНК Вторая предпосылка МНК относительно нулевой средней величины остатков означает, что Вместе с тем, несмещенность оценок коэффициентов регрессии, полученных МНК, зависит от независимости случайных остатков и величин Рис. .3. Зависимость величины остатков от величины фактора Замечание. Предпосылка о нормальном распределении остатков (пятая предпосылка) позволяет проводить проверку параметров регрессии и корреляции с помощью Совершенно необходимым для получения по МНК состоятельных оценок параметров регрессии является соблюдение третьей и четвертой предпосылок. Автокорреляция ошибок. Статистика Дарбина-Уотсона Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений Автокорреляция (последовательная корреляция) остатков определяется как корреляция между соседними значениями случайных отклонений во времени (временные ряды) или в пространстве (перекрестные данные). Она обычно встречается во временных рядах и очень редко – в пространственных данных. Возможны следующие случаи: В экономических задачах значительно чаще встречается положительная автокорреляция, чем отрицательная автокорреляция. Если же характер отклонений случаен, то можно предположить, что в половине случаев знаки соседних отклонений совпадают, а в половине – различны. Автокорреляция в остатках может быть вызвана несколькими причинами, имеющими различную природу.
От истинной автокорреляции остатков следует отличать ситуации, когда причина автокорреляции заключается в неправильной спецификации функциональной формы модели. В этом случае следует изменить форму модели, а не использовать специальные методы расчета параметров уравнения регрессии при наличии автокорреляции в остатках. Для обнаружения автокорреляции используют либо графический метод. Либо статистические тесты. Графический метод заключается в построении графика зависимости ошибок от времени (в случае временных рядов) или от объясняющих переменных и визуальном определении наличия или отсутствия автокорреляции. Наиболее известный критерий обнаружения автокорреляции первого порядка – критерий Дарбина-Уотсона. Статистика DW Дарбина-Уотсона приводится во всех специальных компьютерных программах как одна из важнейших характеристик качества регрессионной модели. Сначала по построенному эмпирическому уравнению регрессии определяются значения отклонений
Можно показать, что статистика DW тесно связана с коэффициентом автокорреляции первого порядка: При отсутствии таблиц критических значений DW можно использовать следующее «грубое» правило: при достаточном числе наблюдений (12-15), при 1-3 объясняющих переменных, если Либо применить к данным уменьшающее автокорреляцию преобразование (например автокорреляционное преобразование или метод скользящих средних). Существует несколько ограничений на применение критерия Дарбина-Уотсона.
Для авторегрессионных моделей предлагается h – статистика Дарбина Обычно значение Методы устранения автокорреляции. Авторегрессионное преобразование В случае наличия автокорреляции остатков полученная формула регрессии обычно считается неудовлетворительной. Автокорреляция ошибок первого порядка говорит о неверной спецификации модели. Поэтому следует попытаться скорректировать саму модель. Посмотрев на график ошибок, можно поискать другую (нелинейную) формулу зависимости, включить неучтённые до этого факторы, уточнить период проведения расчётов или разбить его на части. Если все эти способы не помогают и автокорреляция вызвана какими–то внутренними свойствами ряда Формула AR(1) имеет вид: Рассмотрим AR(1) на примере парной регрессии: Сделаем замены переменных Поскольку случайные отклонения Т.о. если остатки по исходному уравнению регрессии автокоррелированы, то для оценки параметров уравнения используют следующие преобразования: 1) Преобразовать исходные переменные у и х к виду (3), (4). 2) Обычным МНК для уравнения (6) определить оценки а * и b. 3) Рассчитать параметр а исходного уравнения из соотношения (4) 4) Записать исходное уравнение (1) с параметрами а и b (где а — из п.3, а b берётся непосредственно из уравнения (6)). Авторегрессионное преобразование может быть обобщено на произвольное число объясняющих переменных, т.е. использовано для уравнения множественной регрессии. Для преобразования AR(1) важно оценить коэффициент автокорреляции ρ. Это делается несколькими способами. Самое простое – оценить ρ на основе статистики DW: В случае, когда есть основания считать, что положительная автокорреляция отклонений очень велика (
В случае полной отрицательной автокорреляции отклонений ( Вычисляются средние за 2 периода, а затем по ним рассчитывают а и b. Данная модель называется моделью регрессии по скользящим средним. Проверка гомоскедастичности дисперсии ошибок В соответствии с четвёртой предпосылкой МНК требуется, чтобы дисперсия остатков была гомоскедастичной. Это значит, что для каждого значения фактора В качестве примера реальной гетероскедастичности можно привести то, что люди с большим доходом не только тратят в среднем больше, чем люди с меньшим доходом, но и разброс в их потреблении также больше, поскольку они имеют больше простора для распределения дохода. Наличие гетероскедастичности можно наглядно видеть из поля корреляции (- графический метод обнаружения гетероскедастичности).
При нарушении гомоскедастичности имеем неравенства: Задача состоит в том, чтобы определить величину Чтобы убедиться в обоснованности использования обобщённого МНК проводят эмпирическое подтверждение наличия гетероскедастичности. При малом объёме выборки, что наиболее характерно для эмпирических исследований, для оценки гетероскедастичности может использоваться метод Гольдфельда-Квандта (в 1965 г. они рассмотрели модель парной линейной регрессии, в которой дисперсия ошибок пропорциональна квадрату фактора). Пусть рассматривается модель, в которой дисперсия Параметрический тест (критерий) Гольдфельда – Квандта: 1. Все n наблюдений в выборке упорядочиваются по величине x. 2. Вся упорядоченная выборка разбивается на три подвыборки (объёмом k, С, k.) 3. Оцениваются отдельные регрессии для первой подвыборки (k первых наблюдений) и для последней подвыборки (k последних наблюдений). 4. Определяются остаточные суммы квадратов 5. Выдвигается нулевая гипотеза Для проверки этой гипотезы рассчитывается отношение Если Этот же тест может быть использован и при предположении об обратной пропорциональности между дисперсией и значениями объясняющей переменной При нарушении гомоскедастичности и наличии автокорреляции ошибок рекомендуется традиционный метод наименьших квадратов заменять обобщенным методом наименьших квадратов (ОМНК). Обобщенный метод наименьших квадратов применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии. Остановимся на использовании ОМНК для корректировки гетероскедастичности. Рассмотрим ОМНК для корректировки гетероскедастичности. Будем предполагать, что среднее значение остаточных величин равно нулю
При этом предполагается, что В общем виде для уравнения Иными словами, от регрессии Оценка параметров нового уравнения с преобразованными переменными приводит к взвешенному методу наименьших квадратов, для которого необходимо минимизировать сумму квадратов отклонений вида
Если преобразованные переменные Аналогичный подход возможен не только для уравнения парной, но и для множественной регрессии. Для применения ОМНК необходимо знать фактические значения дисперсий отклонений Если предположить, что дисперсии пропорциональны значениям фактора x, т.е.
Если предположить, что дисперсии В полученной регрессии по сравнению с исходным уравнением параметры поменялись ролями: свободный член а стал коэффициентом, а коэффициент b – свободным членом. Применяя обычный МНК в преобразованных переменных
Пример. Рассматривая зависимость сбережений В случае множественной регрессии Если предположить Следует иметь в виду, что новые преобразованные переменные получают новое экономическое содержание и их регрессия имеет иной смысл, чем регрессия по исходным данным. Пример. Пусть Если предположить, что в модели с первоначальными переменными дисперсия остатков пропорциональна квадрату объема продукции, В заключение следует отметить, что обнаружении гетероскедастичности и её корректировка являются весьма серьёзной и трудоёмкой проблемой. В случае применения обобщённого (взвешенного) МНК необходима определённая информация или обоснованные предположения о величинах источники: http://zdamsam.ru/a2541.html http://topuch.ru/lekciya-po-ekonometrike/index2.html |
 . Он рассчитывается по формуле:
. Он рассчитывается по формуле: .
. . В знаменателе – СКО наблюдений зависимой переменной от среднего значения.
. В знаменателе – СКО наблюдений зависимой переменной от среднего значения. – дисперсия, характеризующая общий разброс;
– дисперсия, характеризующая общий разброс; – остаточная дисперсия, где m – число независимых (объясняющих) переменных, в случае парной регрессии m =1 и формула имеет вид:
– остаточная дисперсия, где m – число независимых (объясняющих) переменных, в случае парной регрессии m =1 и формула имеет вид:  .
. .
. является лучшей по сравнению с найденной регрессионной прямой.
является лучшей по сравнению с найденной регрессионной прямой. раскладывается на две части – объясненную и необъясненную:
раскладывается на две части – объясненную и необъясненную:





 = n–2.
= n–2. — факторная,
— факторная,  — остаточная.
— остаточная. уравнения линейной зависимости
уравнения линейной зависимости  предполагаются постоянными величинами, оценки а и b этих коэффициентов, получаемые в ходе построения уравнения по данным случайной выборки, являются случайными величинами. Если ошибки регрессии имеют нормальное распределение, то оценки коэффициентов также распределены нормально и могут характеризоваться своими средними значениями и дисперсией. Поэтому анализ коэффициентов начинается с расчёта этих характеристик.
предполагаются постоянными величинами, оценки а и b этих коэффициентов, получаемые в ходе построения уравнения по данным случайной выборки, являются случайными величинами. Если ошибки регрессии имеют нормальное распределение, то оценки коэффициентов также распределены нормально и могут характеризоваться своими средними значениями и дисперсией. Поэтому анализ коэффициентов начинается с расчёта этих характеристик. :
:  ,
, – остаточная дисперсия на одну степень свободы.
– остаточная дисперсия на одну степень свободы. :
:
 ,
, .
. ,
, 
 .
. .
. степенями свободы. По таблицам распределения Стьюдента при определённом уровне значимости α и
степенями свободы. По таблицам распределения Стьюдента при определённом уровне значимости α и  .
. , то нулевая гипотеза должна быть отклонена, коэффициенты считаются статистически значимыми.
, то нулевая гипотеза должна быть отклонена, коэффициенты считаются статистически значимыми. , то нулевая гипотеза не может быть отклонена. (В случае, если коэффициент b статистически незначим, уравнение должно иметь вид
, то нулевая гипотеза не может быть отклонена. (В случае, если коэффициент b статистически незначим, уравнение должно иметь вид  ).
). .
.
 (где
(где  — уровень значимости) истинные значения а, b находятся в указанных интервалах.
— уровень значимости) истинные значения а, b находятся в указанных интервалах. Они не должны включать нуль.
Они не должны включать нуль. о том, что все коэффициенты регрессии, за исключением свободного члена а, равны нулю и, следовательно, фактор х не оказывает влияния на результат y (
о том, что все коэффициенты регрессии, за исключением свободного члена а, равны нулю и, следовательно, фактор х не оказывает влияния на результат y ( или
или  ).
). ,
, .
. – в случае множественной регрессии,
– в случае множественной регрессии,  – для парной регрессии.
– для парной регрессии. , то
, то  отклоняется и делается вывод о существенности статистической связи между y и x.
отклоняется и делается вывод о существенности статистической связи между y и x. , то вероятность уравнение регрессии считается статистически незначимым,
, то вероятность уравнение регрессии считается статистически незначимым,  не отклоняется.
не отклоняется. . Кроме того,
. Кроме того,  , поэтому
, поэтому  . Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
. Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии. по п наблюдениям с т объясняющими переменными, и коэффициент детерминации равен
по п наблюдениям с т объясняющими переменными, и коэффициент детерминации равен  , затем последние k переменных исключены из числа объясняющих, и по тем же данным оценено уравнение
, затем последние k переменных исключены из числа объясняющих, и по тем же данным оценено уравнение  , для которого коэффициент детерминации равен
, для которого коэффициент детерминации равен  (
(
 ,
, степенями свободы.
степенями свободы. . И если
. И если  ,
, . И если она превышает критический уровень, то включение новых переменных объясняет существенную часть необъяснённой ранее дисперсии зависимой переменной (т.е. включение новых объясняющих переменных оправдано).
. И если она превышает критический уровень, то включение новых переменных объясняет существенную часть необъяснённой ранее дисперсии зависимой переменной (т.е. включение новых объясняющих переменных оправдано). наблюдений. Для каждой из этих выборок оценено уравнение регрессии вида
наблюдений. Для каждой из этих выборок оценено уравнение регрессии вида  от линии регрессии (т.е.
от линии регрессии (т.е.  ) равны для них, соответственно,
) равны для них, соответственно,  .
. : о том, что все соответствующие коэффициенты этих уравнений равны друг другу, т.е. уравнение регрессии для этих выборок одно и то же.
: о том, что все соответствующие коэффициенты этих уравнений равны друг другу, т.е. уравнение регрессии для этих выборок одно и то же. наблюдений, и СКО
наблюдений, и СКО  .
.
 степенями свободы. F – статистика будет близкой к нулю, если уравнение для обеих выборок одинаково, т.к. в этом случае
степенями свободы. F – статистика будет близкой к нулю, если уравнение для обеих выборок одинаково, т.к. в этом случае  . Т.е. если
. Т.е. если  не соответствует некоторым предпосылкам МНК, то следует корректировать модель.
не соответствует некоторым предпосылкам МНК, то следует корректировать модель. хорошо аппроксимируют фактические значения
хорошо аппроксимируют фактические значения  .
.
 от теоретических значений
от теоретических значений  .
.
 от теоретических значений
от теоретических значений  (или
(или  ). Это выполнимо для линейных моделей и моделей, нелинейных относительно включаемых переменных.
). Это выполнимо для линейных моделей и моделей, нелинейных относительно включаемых переменных. , что также исследуется в рамках соблюдения второй предпосылки МНК. С этой целью наряду с изложенным графиком зависимости остатков
, что также исследуется в рамках соблюдения второй предпосылки МНК. С этой целью наряду с изложенным графиком зависимости остатков  (рис. 3).
(рис. 3).
 . Скопление точек в определенных участках значений фактора
. Скопление точек в определенных участках значений фактора  — и
— и  -критериев. Вместе с тем, оценки регрессии, найденные с применением МНК, обладают хорошими свойствами даже при отсутствии нормального распределения остатков, т.е. при нарушении пятой предпосылки МНК.
-критериев. Вместе с тем, оценки регрессии, найденные с применением МНК, обладают хорошими свойствами даже при отсутствии нормального распределения остатков, т.е. при нарушении пятой предпосылки МНК. от значений отклонений во всех других наблюдениях. Отсутствие зависимости гарантирует отсутствие коррелированности между любыми отклонениями, т.е.
от значений отклонений во всех других наблюдениях. Отсутствие зависимости гарантирует отсутствие коррелированности между любыми отклонениями, т.е.  и, в частности, между соседними отклонениями
и, в частности, между соседними отклонениями  .
.
 .
. . А затем рассчитывается статистика Дарбина-Уотсона по формуле:
. А затем рассчитывается статистика Дарбина-Уотсона по формуле: .
. об отсутствии автокорреляции остатков. Альтернативные гипотезы
об отсутствии автокорреляции остатков. Альтернативные гипотезы  и
и  состоят, соответственно, в наличии положительной или отрицательной автокорреляции в остатках. Далее по специальным таблицам определяются критические значения критерия Дарбина-Уотсона
состоят, соответственно, в наличии положительной или отрицательной автокорреляции в остатках. Далее по специальным таблицам определяются критические значения критерия Дарбина-Уотсона  (- нижняя граница признания положительной автокорреляции) и
(- нижняя граница признания положительной автокорреляции) и  (-верхняя граница признания отсутствия положительной автокорреляции) для заданного числа наблюдений
(-верхняя граница признания отсутствия положительной автокорреляции) для заданного числа наблюдений  , числа независимых переменных модели
, числа независимых переменных модели  и уровня значимости
и уровня значимости  . По этим значениям числовой промежуток
. По этим значениям числовой промежуток  разбивают на пять отрезков. Принятие или отклонение каждой из гипотез с вероятностью
разбивают на пять отрезков. Принятие или отклонение каждой из гипотез с вероятностью  осуществляется следующим образом:
осуществляется следующим образом: – положительная автокорреляция, принимается
– положительная автокорреляция, принимается  – зона неопределенности;
– зона неопределенности; – автокорреляция отсутствует;
– автокорреляция отсутствует; – зона неопределенности;
– зона неопределенности; – отрицательная автокорреляция, принимается
– отрицательная автокорреляция, принимается 
 .
.
 .
. , то отклонения от линии регрессии можно считать взаимно независимыми.
, то отклонения от линии регрессии можно считать взаимно независимыми. ,
, – случайный член.
– случайный член. ,
, – оценка коэффициента автокорреляции первого порядка, D(c) – выборочная дисперсия коэффициента при лаговой переменной yt-1, n – число наблюдений.
– оценка коэффициента автокорреляции первого порядка, D(c) – выборочная дисперсия коэффициента при лаговой переменной yt-1, n – число наблюдений. , а D(c) равна квадрату стандартной ошибки Sc оценки коэффициента с.
, а D(c) равна квадрату стандартной ошибки Sc оценки коэффициента с. определяется значением той же самой величины, но с запаздыванием. Т.к. максимальное запаздывание равно 1, то это авторегрессия первого порядка).
определяется значением той же самой величины, но с запаздыванием. Т.к. максимальное запаздывание равно 1, то это авторегрессия первого порядка). .
. -коэффициент автокорреляции первого порядка ошибок регрессии.
-коэффициент автокорреляции первого порядка ошибок регрессии. .
. (1),
(1), (2).
(2). и вычтем из (1):
и вычтем из (1): .
.
 (6).
(6). .
. ,
, ), можно использовать метод первых разностей (метод исключения тенденции), уравнение принимает вид
), можно использовать метод первых разностей (метод исключения тенденции), уравнение принимает вид

 .
. .
. )
) ,
,
 .
. имеют одинаковую дисперсию
имеют одинаковую дисперсию  . Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность.
. Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность.

 , где
, где  наблюдении пропорциональна постоянной дисперсии:
наблюдении пропорциональна постоянной дисперсии: 
 .
. — коэффициент пропорциональности. Он меняется при переходе от одного значения фактора
— коэффициент пропорциональности. Он меняется при переходе от одного значения фактора  пропорциональна квадрату фактора:
пропорциональна квадрату фактора:  ,
,  . А также остатки имеют нормальное распределение и отсутствует автокорреляция остатков.
. А также остатки имеют нормальное распределение и отсутствует автокорреляция остатков. .
. для первой и второй
для первой и второй  групп. Если предположение о пропорциональности дисперсий отклонений значениям x верно, то
групп. Если предположение о пропорциональности дисперсий отклонений значениям x верно, то  .
. которая предполагает отсутствие гетероскедастичности.
которая предполагает отсутствие гетероскедастичности. ,
, степеней свободы (здесь m – число объясняющих переменных).
степеней свободы (здесь m – число объясняющих переменных). , то гипотеза об отсутствии гетероскедастичности отклоняется при уровне значимости α.
, то гипотеза об отсутствии гетероскедастичности отклоняется при уровне значимости α. . В этом случае статистика Фишера принимает вид:
. В этом случае статистика Фишера принимает вид: .
. . Обобщенный метод наименьших квадратов (ОМНК)
. Обобщенный метод наименьших квадратов (ОМНК) , а дисперсия пропорциональна величине
, а дисперсия пропорциональна величине  .
. – дисперсия ошибки при конкретном
– дисперсия ошибки при конкретном  -м значении фактора;
-м значении фактора;  – постоянная дисперсия ошибки при соблюдении предпосылки о гомоскедастичности остатков;
– постоянная дисперсия ошибки при соблюдении предпосылки о гомоскедастичности остатков;  модель примет вид:
модель примет вид: .
. . Тогда дисперсия остатков будет величиной постоянной, т. е.
. Тогда дисперсия остатков будет величиной постоянной, т. е.  .
. и
и  . Уравнение регрессии примет вид:
. Уравнение регрессии примет вид: ,
, ,
, .
. .
. .
.
 ,
, при использовании обобщенного МНК с целью корректировки гетероскедастичности представляет собой взвешенную величину по отношению к обычному МНК с весом
при использовании обобщенного МНК с целью корректировки гетероскедастичности представляет собой взвешенную величину по отношению к обычному МНК с весом  .
. .
. .
. . На практике такие значения известны крайне редко. Поэтому, чтобы применить ВНК, необходимо сделать реалистические предположения о значениях
. На практике такие значения известны крайне редко. Поэтому, чтобы применить ВНК, необходимо сделать реалистические предположения о значениях  , т.е
, т.е  или
или  .
. :
:
 .
. выполняется условие гомоскедастичности. Следовательно, для регрессии применим обычный МНК. Следует отметить, что новая регрессия не имеет свободного члена, но зависит от двух факторов. Оценив для неё по МНК коэффициенты а и b, возвращаемся к исходному уравнению регрессии.
выполняется условие гомоскедастичности. Следовательно, для регрессии применим обычный МНК. Следует отметить, что новая регрессия не имеет свободного члена, но зависит от двух факторов. Оценив для неё по МНК коэффициенты а и b, возвращаемся к исходному уравнению регрессии.
 :
: .
. ,
, .
. .
. ,
, (т.е. дисперсия ошибок пропорциональна квадрату первой объясняющей переменной), то в этом случае обобщенный МНК предполагает оценку параметров следующего трансформированного уравнения:
(т.е. дисперсия ошибок пропорциональна квадрату первой объясняющей переменной), то в этом случае обобщенный МНК предполагает оценку параметров следующего трансформированного уравнения: .
. – объем продукции,
– объем продукции,  – основные производственные фонды,
– основные производственные фонды,  – численность работников, тогда уравнение
– численность работников, тогда уравнение
 пропорциональна квадрату численности работников
пропорциональна квадрату численности работников  , а в качестве факторов следующие показатели: производительность труда
, а в качестве факторов следующие показатели: производительность труда  и фондовооруженность труда
и фондовооруженность труда  . Соответственно трансформированная модель примет вид
. Соответственно трансформированная модель примет вид ,
, ,
,  ,
,  численно не совпадают с аналогичными параметрами предыдущей модели. Кроме этого, коэффициенты регрессии меняют экономическое содержание: из показателей силы связи, характеризующих среднее абсолютное изменение издержек производства с изменением абсолютной величины соответствующего фактора на единицу, они фиксируют при обобщенном МНК среднее изменение затрат на работника; с изменением производительности труда на единицу при неизменном уровне фовдовооруженности труда; и с изменением фондовооруженности труда на единицу при неизменном уровне производительности труда.
численно не совпадают с аналогичными параметрами предыдущей модели. Кроме этого, коэффициенты регрессии меняют экономическое содержание: из показателей силы связи, характеризующих среднее абсолютное изменение издержек производства с изменением абсолютной величины соответствующего фактора на единицу, они фиксируют при обобщенном МНК среднее изменение затрат на работника; с изменением производительности труда на единицу при неизменном уровне фовдовооруженности труда; и с изменением фондовооруженности труда на единицу при неизменном уровне производительности труда. , можно перейти к уравнению регрессии вида
, можно перейти к уравнению регрессии вида .
. – затраты на единицу (или на 1 руб. продукции),
– затраты на единицу (или на 1 руб. продукции),  – фондоемкость продукции,
– фондоемкость продукции,  – трудоемкость продукции.
– трудоемкость продукции.