Показатели качества регрессии
Качество модели регрессии связывают с адекватностью модели наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным проводится на основе анализа остатков —  .
.
Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов. Согласно общим предположениям регрессионного анализа, остатки должны вести себя как независимые (в действительности, почти независимые) одинаково распределенные случайные величины.
Качество модели регрессии оценивается по следующим направлениям:
проверка качества всего уравнения регрессии;
проверка значимости всего уравнения регрессии;
проверка статистической значимости коэффициентов уравнения регрессии;
проверка выполнения предпосылок МНК.
При анализе качества модели регрессии, в первую очередь, используется коэффициент детерминации, который определяется следующим образом:

где 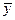 — среднее значение зависимой переменной,
— среднее значение зависимой переменной,
 — предсказанное (расчетное) значение зависимой переменной.
— предсказанное (расчетное) значение зависимой переменной.
Коэффициент детерминации показывает долю вариации результативного признака, находящегося под воздействием изучаемых факторов, т. е. определяет, какая доля вариации признака Y учтена в модели и обусловлена влиянием на него факторов.
Чем ближе 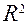 к 1, тем выше качество модели.
к 1, тем выше качество модели.
Для оценки качества регрессионных моделей целесообразно также использовать коэффициент множественной корреляции (индекс корреляции) R
R =  =
= 
Данный коэффициент является универсальным, так как он отражает тесноту связи и точность модели, а также может использоваться при любой форме связи переменных.
Важным моментом является проверка значимости построенного уравнения в целом и отдельных параметров.
Оценить значимость уравнения регрессии – это означает установить, соответствует ли математическая модель, выражающая зависимость между Y и Х, фактическим данным и достаточно ли включенных в уравнение объясняющих переменных Х для описания зависимой переменной Y
Оценка значимости уравнения регрессии производится для того, чтобы узнать, пригодно уравнение регрессии для практического использования (например, для прогноза) или нет.
Для проверки значимости модели регрессии используется F-критерий Фишера. Если расчетное значение с n1= k и n2 = (n — k — 1) степенями свободы, где k – количество факторов, включенных в модель, больше табличного при заданном уровне значимости, то модель считается значимой.

В качестве меры точности применяют несмещенную оценку дисперсии остаточной компоненты, которая представляет собой отношение суммы квадратов уровней остаточной компоненты к величине (n- k -1), где k – количество факторов, включенных в модель. Квадратный корень из этой величины (  ) называется стандартной ошибкой:
) называется стандартной ошибкой:
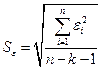
значимость отдельных коэффициентов регрессии проверяется по t-статистике путем проверки гипотезы о равенстве нулю j-го параметра уравнения (кроме свободного члена):
 ,
,
где Saj — это стандартное (среднеквадратическое) отклонение коэффициента уравнения регрессии aj. Величина Saj представляет собой квадратный корень из произведения несмещенной оценки дисперсии  и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.
и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.

где  — диагональный элемент матрицы
— диагональный элемент матрицы 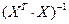 .
.
Если расчетное значение t-критерия с (n — k — 1) степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
Проверка выполнения предпосылок МНК.
Рассмотрим выполнение предпосылки гомоскедастичности, или равноизменчивости случайной составляющей (возмущения).
Невыполнение этой предпосылки, т.е. нарушение условия гомоскедастичности возмущений означает, что дисперсия возмущения зависит от значений факторов. Такие регрессионные модели называются моделями с гетероскедастичностью возмущений.
Обнаружение гетероскедастичности. Для обнаружения гетероскедастичности обычно используют тесты, в которых делаются различные предположения о зависимости между дисперсией случайного члена и объясняющей переменной: тест ранговой корреляции Спирмена, тест Голдфельда — Квандта, тест Глейзера, двусторонний критерий Фишера и другие [2].
При малом объеме выборки для оценки гетероскедастичности может использоваться метод Голдфельда — Квандта. Данный тест используется для проверки такого типа гетероскедастичности, когда дисперсия остатков возрастает пропорционально квадрату фактора. При этом делается предположение, что, случайная составляющая 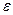 распределена нормально.
распределена нормально.
Чтобы оценить нарушение гомоскедастичности по тесту Голдфельда — Квандта необходимо выполнить следующие шаги.
Упорядочение п наблюдений по мере возрастания переменной х.
Исключение 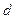 средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
средних наблюдений ( должно быть примерно равно четверти общего количества наблюдений).
Разделение совокупности на две группы (соответственно с малыми и большими значениями фактора  ) и определение по каждой из групп уравнений регрессии.
) и определение по каждой из групп уравнений регрессии.
Определение остаточной суммы квадратов для первой регрессии  и второй регрессии
и второй регрессии  .
.
Вычисление отношений  (или
(или 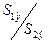 ). В числителе должна быть большая сумма квадратов.
). В числителе должна быть большая сумма квадратов.
Полученное отношение имеет F распределение со степенями свободы k1=n1-k и k2=n-n1-k, (k– число оцениваемых параметров в уравнении регрессии).
Если  , то гетероскедастичность имеет место.
, то гетероскедастичность имеет место.
Чем больше величина F превышает табличное значение F -критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
Оценка влияния отдельных факторов на зависимую переменную на основе модели (коэффициенты эластичности, b — коэффициенты).
Важную роль при оценке влияния факторов играют коэффициенты регрессионной модели. Однако непосредственно с их помощью нельзя сопоставить факторы по степени их влияния на зависимую переменную из-за различия единиц измерения и разной степени колеблемости. Для устранения таких различий при интерпретации применяются средние частные коэффициенты эластичности Э(j) и бета-коэффициенты b(j).
Эластичность Y по отношению к Х(j) определяется как процентное изменение Y, отнесенное к соответствующему процентному изменению Х. В общем случае эластичности не постоянны, они различаются, если измерены для различных точек на линии регрессии. По умолчанию стандартные программы, оценивающие эластичность, вычисляют ее в точках средних значений:
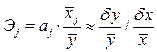
Эластичность ненормирована и может изменяться от —  до + . Важно, что она безразмерна, так что интерпретация эластичности
до + . Важно, что она безразмерна, так что интерпретация эластичности  =2.0 означает, что если
=2.0 означает, что если  изменится на 1%, то это приведет к изменению
изменится на 1%, то это приведет к изменению  на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
на 2%. Если =-0.5, то это означает, что увеличение на 1% приведет к уменьшению на 0.5%.
Высокий уровень эластичности означает сильное влияние независимой переменной на объясняемую переменную.

где Sxj — среднеквадратическое отклонение фактора j
где 
 .
.
Коэффициент эластичности показывает, на сколько процентов изменяется зависимая переменная при изменении фактора j на один процент. Однако он не учитывает степень колеблемости факторов.
Бета-коэффициент показывает, на какую часть величины среднего квадратического отклонения Sy изменится зависимая переменная Y с изменением соответствующей независимой переменной Хj на величину своего среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных.
Указанные коэффициенты позволяют упорядочить факторы по степени влияния факторов на зависимую переменную.
Долю влияния фактора в суммарном влиянии всех факторов можно оценить по величине дельта — коэффициентов D (j):

где  — коэффициент парной корреляции между фактором j (j = 1. m) и зависимой переменной.
— коэффициент парной корреляции между фактором j (j = 1. m) и зависимой переменной.
В качестве основного литературного источника рекомендуется использовать [4], в качестве дополнительного – [2].
Проверка общего качества уравнения
Множественной регрессии
Для проверки общего качества уравнения регрессии обычно используется коэффициент детерминации R 2 , который характеризует долю дисперсии зависимой переменной Y, объясняемую регрессионной моделью, и определяется по формуле:
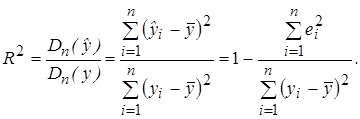 (3.27)
(3.27)
Свойства коэффициента R 2 подробно рассмотрены в разделе 2.4.
Для множественной регрессии коэффициент детерминации (или множественный коэффициент детерминации) является неубывающей функцией числа объясняющих переменных, т. е. добавление новой объясняющей переменной (фактора-аргумента Х) в модель никогда не уменьшает значение R 2 . Действительно, каждая новая объясняющая переменная может лишь дополнить информацию, объясняющую поведение зависимой переменной. В целом это уменьшает неопределенность в поведении исследуемой величины Y. Однако увеличение R 2 при добавлении новых переменных далеко не всегда приводит к улучшению качества регрессионной модели, так как эти переменные могут не оказывать существенного влияния на результативный признак. Поэтому, наряду с коэффициентом R 2 , для анализа используется скорректированный коэффициент детерминации 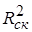 , определяемый соотношением:
, определяемый соотношением:
 (3.28)
(3.28)
или с учетом (3.27)
 . (3.29)
. (3.29)
Можно заметить, что знаменатель в (3.29) является несмещенной оценкой общей дисперсии зависимой переменной Y, а числитель – несмещенной оценкой остаточной дисперсии (дисперсии случайных отклонений).
Скорректированный коэффициент детерминации устраняет (корректирует) неоправданный эффект, связанный с ростом R 2 при увеличении числа объясняющих переменных. Из (3.28) следует, что 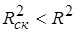 при m > 1 Можно показать, что увеличивается при добавлении новой объясняющей переменной только тогда, когда t-статистика для этой переменной по модулю больше единицы, т. е. когда ее коэффициент регрессии (параметр модели) считается относительно значимым. Таким образом, в определенной степени использование скорректированного коэффициента детерминации более предпочтительно для сравнения регрессионных моделей при изменении количества объясняющих переменных (регрессоров). Добавление в модель новых регрессоров может осуществляться до тех пор, пока растет .
при m > 1 Можно показать, что увеличивается при добавлении новой объясняющей переменной только тогда, когда t-статистика для этой переменной по модулю больше единицы, т. е. когда ее коэффициент регрессии (параметр модели) считается относительно значимым. Таким образом, в определенной степени использование скорректированного коэффициента детерминации более предпочтительно для сравнения регрессионных моделей при изменении количества объясняющих переменных (регрессоров). Добавление в модель новых регрессоров может осуществляться до тех пор, пока растет .
В компьютерных пакетах приводятся данные как по R 2 , так и по , которые используются на практике для оценки суммарной меры общего качества построенной регрессионной модели.
В общем случае качество модели считается удовлетворительным, если R 2 > 0,5. Однако не следует рассматривать коэффициент детерминации как абсолютный показатель качества модели. Можно привести ряд примеров, когда неправильно специфицированные модели имели сравнительно высокие коэффициенты детерминации. Поэтому коэффициент детерминации в современной эконометрике следует рассматривать лишь как один из показателей, который необходим для анализа строящейся модели.
Анализ общей (совокупной) статистической значимости уравнения множественной регрессии осуществляется на основе проверки основной гипотезы об одновременном равенстве нулю всех коэффициентов при объясняющих переменных:
Если данная гипотеза не отклоняется, то естественно считать уравнение модели статистически незначимым, т. е. не выражающим существенную линейную связь между Y и Х1, Х2, …, Хm.
Напомним (см. раздел 2.4.3), что общая дисперсия зависимой переменной Dn(y) может быть представлена в виде суммы двух составляющих:

где  Dn(y) – соответственно, дисперсия, объясняемая уравнением множественной регрессии, и необъясняемая (остаточная) дисперсия, характеризующая влияние неучтенных факторов.
Dn(y) – соответственно, дисперсия, объясняемая уравнением множественной регрессии, и необъясняемая (остаточная) дисперсия, характеризующая влияние неучтенных факторов.
Исходя из этого проводится дисперсионный анализ для проверки гипотезы Н0 (F-тест).
Строится проверочная F-статистика:
 (3.30)
(3.30)
где  – объясняемая дисперсия (в уравнении множественной регрессии вместе со свободным членом оценивается k = m + 1 параметров);
– объясняемая дисперсия (в уравнении множественной регрессии вместе со свободным членом оценивается k = m + 1 параметров);  – остаточная дисперсия. При выполнении предпосылок МНК построенная статистика имеет распределение Фишера с числами степеней свободы v1 = m, v2 = n — m — 1. Поэтому гипотеза Н0 отклоняется, если при заданном уровне значимости a значение Fнабл, рассчитанное по формуле (3.30), больше, чем критическое значение Fкр = Fa; m; n — 1 — m (Fнабл > Fкр), и делается вывод о статистической значимости уравнения множественной регрессии. В противном случае (Fнабл > Fкр) нет оснований для отклонения Н0. Это означает, что объясняемая построенной моделью дисперсия соизмерима с дисперсией, вызванной неучтенными факторами, а следовательно, общее качество модели невысоко.
– остаточная дисперсия. При выполнении предпосылок МНК построенная статистика имеет распределение Фишера с числами степеней свободы v1 = m, v2 = n — m — 1. Поэтому гипотеза Н0 отклоняется, если при заданном уровне значимости a значение Fнабл, рассчитанное по формуле (3.30), больше, чем критическое значение Fкр = Fa; m; n — 1 — m (Fнабл > Fкр), и делается вывод о статистической значимости уравнения множественной регрессии. В противном случае (Fнабл > Fкр) нет оснований для отклонения Н0. Это означает, что объясняемая построенной моделью дисперсия соизмерима с дисперсией, вызванной неучтенными факторами, а следовательно, общее качество модели невысоко.
Если рассчитан коэффициент детерминации R 2 , то критерий значимости уравнения регрессии (3.30) может быть представлен в следующем виде:
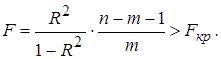 (3.31)
(3.31)
Критерий (3.31) обычно используется на практике для тестирования гипотезы о статистической значимости коэффициента детерминации (Н0 : R 2 = 0; Н1 : R 2 > 0) которая эквивалентна гипотезе об общей статистической значимости уравнения множественной регрессии.
Отметим, что в отличие от парной регрессии, где t-тест и F-тест равносильны, в случае множественной регрессии коэффициент R 2 приобретает самостоятельную значимость.
Пример 3.2. Оценим статистическую значимость построенной модели.
Пусть при оценке регрессии с тремя объясняющими переменными (  по 30 наблюдениям получено значение коэффициента детерминации R 2 = 0,7. Тогда, наблюдаемое значение F-статистики
по 30 наблюдениям получено значение коэффициента детерминации R 2 = 0,7. Тогда, наблюдаемое значение F-статистики 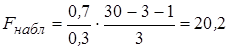 . По таблице критических точек распределения Фишера найдем F0,05; 3; 26 = 2,98 при заданном уровне значимости a = 0,05. Поскольку Fнабл = 20,2 > Fкр = 2,98, то нулевая гипотеза отклоняется, т. е. отвергается предположение о незначимости линейной связи.
. По таблице критических точек распределения Фишера найдем F0,05; 3; 26 = 2,98 при заданном уровне значимости a = 0,05. Поскольку Fнабл = 20,2 > Fкр = 2,98, то нулевая гипотеза отклоняется, т. е. отвергается предположение о незначимости линейной связи.
Мультиколлинеарность
Весьма нежелательным эффектом, который может проявляться при построении моделей множественной регрессии и искажать статистическую информацию, полученную по модели, является мультиколлинеарность [1,28,33]– линейная взаимосвязь двух или нескольких объясняющих переменных. Различают функциональную и корреляционную формы мультиколлинеарности.
При функциональной форме мультиколлинеарности по крайней мере два регрессора связаны между собой линейной функциональной зависимостью. В этом случае определитель матрицы Х Т Х равен нулю в силу присутствия линейно зависимых вектор-столбцов (нарушается предпосылка 5 МНК), что приводит к невозможности решения соответствующий системы уравнений и получения оценок параметров регрессионной модели.
Однако в эконометрических исследованиях мультиколлинеарность чаще всего проявляется в более сложной корреляционной форме, когда между хотя бы двумя объясняющими переменными существует тесная корреляционная связь. Ниже рассмотрены некоторые способы обнаружения, а также уменьшения и устранения мультиколлинеарности.
Один из таких способов заключается в исследовании матрицы Х Т Х. Если ее определитель близок к нулю, то это может свидетельствовать о наличии мультиколлинеарности. В этом случае наблюдаются значительные стандартные ошибки коэффициентов регрессии и их статистическая незначимость по t-критерию, хотя в целом регрессионная модель может оказаться значимой по F-тесту.
Другой подход состоит в анализе матрицы парных коэффициентов корреляции между объясняющими переменными (факторами). Если бы факторы не коррелировали между собой, то корреляционная матрица R была бы единичной матрицей, поскольку все недиагональные элементы (хi ¹ xj) равны нулю. Определитель такой матрицы равен единице [Тимофеев, 2013]. Например, для модели, включающей три объясняющих переменных  , в этом случае имеем:
, в этом случае имеем:
 . (3.32)
. (3.32)
Если же, наоборот, между факторами-аргументами существует полная линейная зависимость и все коэффициенты корреляции равны 1 (|rij| = 1), то определитель матрицы межфакторной корреляции равен нулю
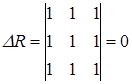 . (3.33)
. (3.33)
Таким образом, чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность объясняющих переменных и ненадежнее оценки множественной регрессии, полученные с использованием МНК.
Если в модели больше двух объясняющих переменных, то для обнаружения мультиколлинеарности полезно находить частные коэффициенты корреляции, поскольку парные коэффициенты корреляции определяют силу линейной зависимости между двумя факторами без учета влияния на них других объясняющих переменных. Например, между двумя экономическими переменными может наблюдаться высокий положительный коэффициент корреляции совсем не потому, что одна из них стимулирует изменение другой, а вследствие того, что обе эти переменные изменяются в одном направлении под влиянием других факторов, присутствующих в модели. Поэтому возникает необходимость оценки действительной тесноты (силы) линейной связи между двумя факторами, очищенной от влияния других переменных. Параметр, определяющий степень корреляции между двумя факторами Хi и Xj при исключении влияния остальных переменных называется частным коэффициентом корреляции.
Например, в случае модели с тремя объясняющими переменными Х1, Х2, Х3 частный коэффициент корреляции между Х1 и Х2 рассчитывается по формуле:
 (3.34)
(3.34)
Частный коэффициент корреляции может существенно отличаться от «обычного» парного коэффициента корреляции r12. Пусть, например, r12 = 0,5; r13 = 0,5; r23 = -0,5. Тогда частный коэффициент корреляции r12.3 = 1 (3.34), т. е. при относительно невысоком коэффициенте корреляции r12 частный коэффициент корреляции указывает на высокую зависимость (коллинеарность) между переменными Хi и Xj.
Таким образом, для обоснованного вывода о корреляции между объясняющими переменными множественной регрессии необходимо рассчитывать частные коэффициенты корреляции.
Частный коэффициент корреляции rij.1, 2, …, m, как и парный коэффициент rij, может принимать значения от -1 до 1. Присутствие в модели пар переменных, имеющих высокие коэффициенты частной корреляции (обычно больше 0,8), свидетельствует о наличии мультиколлинеарности.
Для устранения или уменьшения мультиколлинеарности используется ряд методов, простейшим из которых является исключение из модели одной или нескольких коррелированных переменных. Обычно решение об исключении какой-либо переменной принимается на основании экономических соображений. Следует заметить, что при удалении из анализа объясняющей переменной можно допустить ошибку спецификации. Например, при изучении спроса на некоторый товар в качестве объясняющих переменных целесообразно использовать цену данного товара и цены товаров-заменителей, которые зачастую коррелируют друг с другом. Исключив из модели цены заменителей, мы, вероятнее всего, допустим ошибку спецификации. Вследствие этого можно получить смещенные оценки и сделать ненадежные выводы.
Иногда для уменьшения мультиколлинеарности достаточно (если это возможно) увеличить объем выборки. Например, при использовании ежегодных показателей можно перейти к поквартальным данным. Увеличение количества данных сокращает дисперсии коэффициентов регрессионной модели и тем самым увеличивает их статистическую значимость.
В ряде случаев минимизировать либо вообще устранить мультиколлинеарность можно с помощью преобразования переменных, в результате которого осуществляется переход к новым переменным, представляющим собой линейные или относительные комбинации исходных [11].
Например, построенная регрессионная модель имеет вид:
 (3.35)
(3.35)
причем Х1 и Х2 – коррелированные переменные. В этом случае целесообразно оценивать регрессионные уравнения относительных величин:
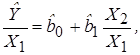
 .
.
Следует ожидать, что в моделях, построенных аналогично (3.36), эффект мультиколлинеарности не будет проявляться.
Существуют также другие, более теоретически разработанные способы обнаружения и подавления мультиколлинеарности, подробное описание которых выходит за рамки данной книги. Одним из таких методов является факторный анализ. Сущностью факторного анализа является процедура вращения факторов, т.е. перераспределение дисперсии по определённому методу с целью получения максимально простой и наглядной структуры факторов (выделение главных компонент) [23,35]. В результате проведения факторного анализа можно соответствующим образом сократить число переменных, тем самым избежать проявления мультиколлинеарности. При этом в один фактор объединяются сильно коррелирующие между собой переменные, что позволяет проводить регрессионный анализ на главных компонентах.
Факторный анализ играет большую самостоятельную роль в экономике и, прежде всего, разработан для поиска ненаблюдаемых, латентных переменных (факторов), имеющих определённый социально-экономический смысл [23].
Следует заметить, что если основная задача, решаемая с помощью эконометрической модели – прогнозирование поведения реального экономического объекта, то при общем удовлетворительном качестве модели проявление мультиколлинеарности не является слишком серьезной проблемой, требующей приложения больших усилий по ее выявлению и устранению, т. к. в данном случае наличие мультиколлинеарности не будет существенно сказываться на прогнозных качествах модели. Таким образом, вопрос о том – следует ли серьезно заниматься проблемой мультиколлинеарности или «смириться» с ее проявлением – решается исходя из целей и задач эконометрического анализа.
Вопросы и упражнения для самопроверки
1. Какова общая структура модели множественной линейной регрессии?
2. Опишите алгоритм определения коэффициентов множественной линейной регрессии (параметров модели) по МНК в матричной форме.
3. Как определяется статистическая значимость коэффициентов регрессии?
4. В чем суть скорректированного коэффициента детерминации и его отличие от обычного R 2 ?
5. Как используется F-статистика во множественном регрессионном анализе?
6. Вычислите величину стандартной ошибки регрессионной модели со свободным членом и без него, если 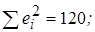 n = 30; m = 3.
n = 30; m = 3.
7. На основе n = 30 наблюдений оценена модель с тремя объясняющими переменными. Получены следующие результаты:

Стандартные ошибки (2,5) (1,6) (2,8) (0,07)
Проведите необходимые расчеты и занесите данные в скобки. Сделайте выводы о существенности коэффициентов регрессии на уровне значимости a =0,05.
8. Имеются данные о ставках месячных доходов по трем акциям за шестимесячный период:
| Акция | Доходы по месяцам, % | |||||
| А | 5,4 | 5,3 | 4,9 | 4,9 | 5,4 | 6,0 |
| В | 6,3 | 6,2 | 6,1 | 5,8 | 5,7 | 5,7 |
| С | 9,2 | 9,2 | 9,1 | 9,0 | 8,7 | 8,6 |
Есть основания предполагать, что доходы по акции С(Y) зависят от доходов по акциям А(X1) и В(X2). Необходимо:
а) составить уравнение регрессии Y по X1 и X2 с использованием МНК (указание: для удобства вычислений сумм первых степеней, квадратов и попарных произведений переменных составьте вспомогательную таблицу);
б) найти множественный коэффициент детерминации R 2 и оценить общее качество построенной модели;
в) проверить значимость полученного уравнения регрессионной модели на уровне a = 0,05.
9. Объясните суть матрицы ковариаций случайных отклонений.
10. Дайте определение и объясните смысл мультиколлинеарности факторов-аргументов.
11. Каковы основные последствия мультиколлинеарности?
12. Какие вы знаете способы обнаружения мультиколлинеарности?
13. Как оценивается степень коррелированности между двумя объясняющими переменными?
14. Перечислите основные методы устранения мультиколлинеарности.
15. В чем заключается сущность факторного анализа?
16. Как определяются парный и частный коэффициенты корреляции для независимых переменных.
17. Для модели с тремя независимыми переменными X1, X2, X3 построенной по n = 50 наблюдениям, определена следующая корреляционная матрица:
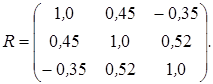
б) определить, имеет ли место мультиколлинеарность для уравнения регрессии.
Пример нахождения статистической значимости коэффициентов регрессии
Числитель в этой формуле может быть рассчитан через коэффициент детерминации и общую дисперсию признака-результата:  .
.
Для параметра a критерий проверки гипотезы о незначимом отличии его от нуля имеет вид:
,
где — оценка параметра регрессии, полученная по наблюдаемым данным;
μa – стандартная ошибка параметра a.
Для линейного парного уравнения регрессии: .
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции в генеральной совокупности используют следующий критерий: , где ryx — оценка коэффициента корреляции, полученная по наблюдаемым данным; mr – стандартная ошибка коэффициента корреляции ryx.
Для линейного парного уравнения регрессии: .
В парной линейной регрессии между наблюдаемыми значениями критериев существует взаимосвязь: t ( b =0) = t (r=0).
Пример №1 . Уравнение имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.73 2 = 0.54, т.е. в 54% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — средняя.
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 69 | 124 | 4761 | 15376 | 8556 | 128.48 | 491.36 | 20.11 | 367.36 |
| 83 | 133 | 6889 | 17689 | 11039 | 141.4 | 173.36 | 70.56 | 26.69 |
| 92 | 146 | 8464 | 21316 | 13432 | 149.7 | 0.03 | 13.71 | 14.69 |
| 97 | 153 | 9409 | 23409 | 14841 | 154.32 | 46.69 | 1.73 | 78.03 |
| 88 | 138 | 7744 | 19044 | 12144 | 146.01 | 66.69 | 64.21 | 0.03 |
| 93 | 159 | 8649 | 25281 | 14787 | 150.63 | 164.69 | 70.13 | 23.36 |
| 74 | 145 | 5476 | 21025 | 10730 | 133.1 | 1.36 | 141.68 | 200.69 |
| 79 | 152 | 6241 | 23104 | 12008 | 137.71 | 34.03 | 204.21 | 84.03 |
| 105 | 168 | 11025 | 28224 | 17640 | 161.7 | 476.69 | 39.74 | 283.36 |
| 99 | 154 | 9801 | 23716 | 15246 | 156.16 | 61.36 | 4.67 | 117.36 |
| 85 | 127 | 7225 | 16129 | 10795 | 143.25 | 367.36 | 263.91 | 10.03 |
| 94 | 155 | 8836 | 24025 | 14570 | 151.55 | 78.03 | 11.91 | 34.03 |
| 1058 | 1754 | 94520 | 258338 | 155788 | 1754 | 1961.67 | 906.57 | 1239.67 |
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.2704
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 88,16
(128.06;163.97)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (3.41>1.812).
Статистическая значимость коэффициента регрессии b подтверждается (2.7>1.812).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.812):
(a — tтабл·S a; a + tтабл·Sa)
(0.4325;1.4126)
(b — tтабл·S b; b + tтабл·Sb)
(21.3389;108.3164)
2) F-статистики
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим.
Пример №2 . По территориям региона приводятся данные за 199Х г.;
| Среднедневная заработная плата, руб., у | ||
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х , составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение находим с помощью калькулятора.
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
12a+1027b=1869
1027a+89907b=161808
Из первого уравнения выражаем а и подставим во второе уравнение. Получаем b = 0.92, a = 76.98
Уравнение регрессии: y = 0.92 x + 76.98 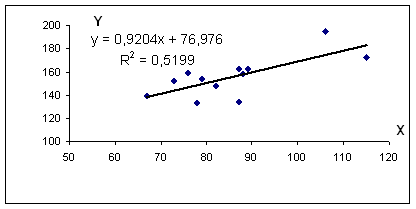
1. Параметры уравнения регрессии.
Выборочные средние.
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%, среднедневная заработная плата изменится менее чем на 1%. Другими словами — влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199, т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами — точность подбора уравнения регрессии — средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| y 2 | x·y | y(x) | (y i — y ) 2 | (y-y(x)) 2 | (x i — x ) 2 | |y-y x |:y | |||
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим tкрит:
tкрит = (10;0.05) = 1.812
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(0.9204 — 1.812·0.2797; 0.9204 + 1.812·0.2797)
(0.4136;1.4273)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a-ta)
(76.9765 — 1.812·24.2116; 76.9765 + 1.812·24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
http://poisk-ru.ru/s53522t2.html
http://math.semestr.ru/corel/prim3.php