Пример нахождения статистической значимости коэффициентов регрессии
Числитель в этой формуле может быть рассчитан через коэффициент детерминации и общую дисперсию признака-результата:  .
.
Для параметра a критерий проверки гипотезы о незначимом отличии его от нуля имеет вид:
,
где — оценка параметра регрессии, полученная по наблюдаемым данным;
μa – стандартная ошибка параметра a.
Для линейного парного уравнения регрессии: .
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции в генеральной совокупности используют следующий критерий: , где ryx — оценка коэффициента корреляции, полученная по наблюдаемым данным; mr – стандартная ошибка коэффициента корреляции ryx.
Для линейного парного уравнения регрессии: .
В парной линейной регрессии между наблюдаемыми значениями критериев существует взаимосвязь: t ( b =0) = t (r=0).
Пример №1 . Уравнение имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.73 2 = 0.54, т.е. в 54% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — средняя.
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 69 | 124 | 4761 | 15376 | 8556 | 128.48 | 491.36 | 20.11 | 367.36 |
| 83 | 133 | 6889 | 17689 | 11039 | 141.4 | 173.36 | 70.56 | 26.69 |
| 92 | 146 | 8464 | 21316 | 13432 | 149.7 | 0.03 | 13.71 | 14.69 |
| 97 | 153 | 9409 | 23409 | 14841 | 154.32 | 46.69 | 1.73 | 78.03 |
| 88 | 138 | 7744 | 19044 | 12144 | 146.01 | 66.69 | 64.21 | 0.03 |
| 93 | 159 | 8649 | 25281 | 14787 | 150.63 | 164.69 | 70.13 | 23.36 |
| 74 | 145 | 5476 | 21025 | 10730 | 133.1 | 1.36 | 141.68 | 200.69 |
| 79 | 152 | 6241 | 23104 | 12008 | 137.71 | 34.03 | 204.21 | 84.03 |
| 105 | 168 | 11025 | 28224 | 17640 | 161.7 | 476.69 | 39.74 | 283.36 |
| 99 | 154 | 9801 | 23716 | 15246 | 156.16 | 61.36 | 4.67 | 117.36 |
| 85 | 127 | 7225 | 16129 | 10795 | 143.25 | 367.36 | 263.91 | 10.03 |
| 94 | 155 | 8836 | 24025 | 14570 | 151.55 | 78.03 | 11.91 | 34.03 |
| 1058 | 1754 | 94520 | 258338 | 155788 | 1754 | 1961.67 | 906.57 | 1239.67 |
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.2704
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 88,16
(128.06;163.97)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (3.41>1.812).
Статистическая значимость коэффициента регрессии b подтверждается (2.7>1.812).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.812):
(a — tтабл·S a; a + tтабл·Sa)
(0.4325;1.4126)
(b — tтабл·S b; b + tтабл·Sb)
(21.3389;108.3164)
2) F-статистики
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим.
Пример №2 . По территориям региона приводятся данные за 199Х г.;
| Среднедневная заработная плата, руб., у | ||
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х , составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение находим с помощью калькулятора.
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
12a+1027b=1869
1027a+89907b=161808
Из первого уравнения выражаем а и подставим во второе уравнение. Получаем b = 0.92, a = 76.98
Уравнение регрессии: y = 0.92 x + 76.98 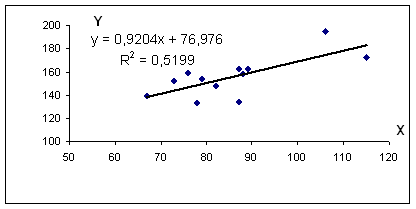
1. Параметры уравнения регрессии.
Выборочные средние.
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%, среднедневная заработная плата изменится менее чем на 1%. Другими словами — влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199, т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами — точность подбора уравнения регрессии — средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| y 2 | x·y | y(x) | (y i — y ) 2 | (y-y(x)) 2 | (x i — x ) 2 | |y-y x |:y | |||
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим tкрит:
tкрит = (10;0.05) = 1.812
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(0.9204 — 1.812·0.2797; 0.9204 + 1.812·0.2797)
(0.4136;1.4273)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a-ta)
(76.9765 — 1.812·24.2116; 76.9765 + 1.812·24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Оценка значимости параметров уравнения парной линейной регрессии
Парная регрессия представляет собой регрессию между двумя переменными
—у и х, т.е. модель вида 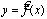 + Е
+ Е
, где у — результативный признак,т.е зависимая переменная; х — признак-фактор.
Линейная регрессия сводится к нахождению уравнения вида  или
или 
Уравнение вида  позволяет по заданным значениям фактора x иметь теоретические значения результативного признака, подставляя в него фактические значения фактора х.
позволяет по заданным значениям фактора x иметь теоретические значения результативного признака, подставляя в него фактические значения фактора х.
Построение линейной регрессии сводится к оценке ее параметров а и в.
Оценки параметров линейной регрессии могут быть найдены разными методами.
1. 
2. 
Параметр b называется коэффициентом регрессии. Его величина показывает
среднее изменение результата с изменением фактора на одну единицу.
Формально а — значение у при х = 0. Если признак-фактор
не имеет и не может иметь нулевого значения, то вышеуказанная
трактовка свободного члена, а не имеет смысла. Параметр, а может
не иметь экономического содержания. Попытки экономически
интерпретировать параметр, а могут привести к абсурду, особенно при а 0,
то относительное изменение результата происходит медленнее, чем изменение
проверка качества найденных параметров и всей модели в целом:
-Оценка значимости коэффициента регрессии (b) и коэффициента корреляции
-Оценка значимости всего уравнения регрессии. Коэффициент детерминации
Уравнение регрессии всегда дополняется показателем тесноты связи. При
использовании линейной регрессии в качестве такого показателя выступает
линейный коэффициент корреляции rxy. Существуют разные
модификации формулы линейного коэффициента корреляции.

Линейный коэффициент корреляции находится и границах: -1≤.rxy
≤ 1. При этом чем ближе r к 0 тем слабее корреляция и наоборот чем
ближе r к 1 или -1, тем сильнее корреляция, т.е. зависимость х и у близка к
линейной. Если r в точности =1или -1 все точки лежат на одной прямой.
Если коэф. регрессии b>0 то 0 ≤.rxy ≤ 1 и
в модели факторов.
МНК позволяет получить такие оценки параметров а и b, которых
сумма квадратов отклонений фактических значений результативного признака
(у) от расчетных (теоретических) 
 Иными словами, из
Иными словами, из
всего множества линий линия регрессии на графике выбирается так, чтобы сумма
квадратов расстояний по вертикали между точками и этой линией была бы
минимальной. 
Решается система нормальных уравнений

ОЦЕНКА СУЩЕСТВЕННОСТИ ПАРАМЕТРОВ ЛИНЕЙНОЙ РЕГРЕССИИ.
Оценка значимости уравнения регрессии в целом дается с помощью F-критерия
Фишера. При этом выдвигается нулевая гипотеза, что коэффициент регрессии равен
нулю, т. е. b = 0, и следовательно, фактор х не оказывает
влияния на результат у.
Непосредственному расчету F-критерия предшествует анализ дисперсии.
Центральное место в нем занимает разложение общей суммы квадратов отклонений
переменной у от средне го значения у на две части —
«объясненную» и «необъясненную»:

 — общая сумма квадратов отклонений
— общая сумма квадратов отклонений
 — сумма квадратов
— сумма квадратов
отклонения объясненная регрессией 
— остаточная сумма квадратов отклонения.
Любая сумма квадратов отклонений связана с числом степеней свободы, т.
е. с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности nис числом определяемых по ней констант. Применительно к исследуемой проблеме число cтепеней свободы должно показать, сколько независимых отклонений из п возможных требуется для
образования данной суммы квадратов.
Дисперсия на одну степень свободы D.

F-отношения (F-критерий): 

Ecли нулевая гипотеза справедлива, то факторная и остаточная дисперсии не
отличаются друг от друга. Для Н0 необходимо опровержение, чтобы
факторная дисперсия превышала остаточную в несколько раз. Английским
статистиком Снедекором разработаны таблицы критических значений F-отношений
при разных уровнях существенности нулевой гипотезы и различном числе степеней
свободы. Табличное значение F-критерия — это максимальная величина отношения
дисперсий, которая может иметь место при случайном их расхождении для данного
уровня вероятности наличия нулевой гипотезы. Вычисленное значение F-отношения
признается достоверным, если о больше табличного. В этом случае нулевая
гипотеза об отсутствии связи признаков отклоняется и делается вывод о
существенности этой связи: Fфакт > Fтабл Н0
Если же величина окажется меньше табличной Fфакт ‹, Fтабл
, то вероятность нулевой гипотезы выше заданного уровня и она не может быть
отклонена без серьезного риска сделать неправильный вывод о наличии связи. В
этом случае уравнение регрессии считается статистически незначимым. Но
Парная регрессия и корреляция

1. Парная регрессия и корреляция
1.1. Понятие регрессии
Парной регрессией называется уравнение связи двух переменных у и х
где у – зависимая переменная (результативный признак); х – независимая, объясняющая переменная (признак-фактор).
Различают линейные и нелинейные регрессии.
Линейная регрессия описывается уравнением: y = a + b × x +e .
Нелинейные регрессии делятся на два класса: регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, и регрессии, нелинейные по оцениваемым параметрам.
Примеры регрессий, нелинейных по объясняющим переменным, но ли-
нейных по оцениваемым параметрам:
· полиномы разных степеней 
· равносторонняя гипербола: 
Примеры регрессий, нелинейных по оцениваемым параметрам:
· степенная 
· показательная 
· экспоненциальная 
Наиболее часто применяются следующие модели регрессий:
– прямой 
– гиперболы 
– параболы 
– показательной функции 
– степенная функция 
1.2. Построение уравнения регрессии
Постановка задачи. По имеющимся данным n наблюдений за совместным
изменением двух параметров x и y <(xi,yi), i=1,2. n> необходимо определить
аналитическую зависимость ŷ=f(x), наилучшим образом описывающую данные наблюдений.
Построение уравнения регрессии осуществляется в два этапа (предполагает решение двух задач):
– спецификация модели (определение вида аналитической зависимости
– оценка параметров выбранной модели.
1.2.1. Спецификация модели
Парная регрессия применяется, если имеется доминирующий фактор, который и используется в качестве объясняющей переменной.
Применяется три основных метода выбора вида аналитической зависимости:
– графический (на основе анализа поля корреляций);
– аналитический, т. е. исходя из теории изучаемой взаимосвязи;
– экспериментальный, т. е. путем сравнения величины остаточной дисперсии Dост или средней ошибки аппроксимации , рассчитанных для различных
моделей регрессии (метод перебора).
1.2.2. Оценка параметров модели
Для оценки параметров регрессий, линейных по этим параметрам, используется метод наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических значений ŷx при тех же значениях фактора x минимальна, т. е.

В случае линейной регрессии параметры а и b находятся из следующей
системы нормальных уравнений метода МНК:
 (1.1)
(1.1)
Можно воспользоваться готовыми формулами, которые вытекают из этой
 (1.2)
(1.2)
Для нелинейных уравнений регрессии, приводимых к линейным с помощью преобразования (x, y) → (x’, y’), система нормальных уравнений имеет
вид (1.1) в преобразованных переменных x’, y’.
Коэффициент b при факторной переменной x имеет следующую интерпретацию: он показывает, на сколько изменится в среднем величина y при изменении фактора x на 1 единицу измерения.
Линеаризующее преобразование: x’ = 1/x; y’ = y.
Уравнения (1.1) и формулы (1.2) принимают вид


Линеаризующее преобразование: x’ = x; y’ = lny.

Модифицированная экспонента:  , (0 K и со знаком «–» в противном случае.
, (0 K и со знаком «–» в противном случае.
Степенная функция: 
Линеаризующее преобразование: x’ = ln x; y’ = ln y.

Показательная функция: 
Линеаризующее преобразование: x’ = x; y’ = lny.
 Логарифмическая функция:
Логарифмическая функция:
Линеаризующее преобразование: x’ = ln x; y’ = y.

Парабола второго порядка: 
Парабола второго порядка имеет 3 параметра a0, a1, a2, которые определяются из системы трех уравнений

1.3. Оценка тесноты связи
Тесноту связи изучаемых явлений оценивает линейный коэффициент
парной корреляции rxy для линейной регрессии (–1 ≤ r xy ≤ 1)
и индекс корреляции ρxy для нелинейной регрессии 
 Имеет место соотношение
Имеет место соотношение

Долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака у характеризует коэффициент детерминации r2xy (для линейной регрессии) или индекс детерминации (для нелинейной регрессии).
Коэффициент детерминации – квадрат коэффициента или индекса корреляции.
Для оценки качества построенной модели регрессии можно использовать
показатель (коэффициент, индекс) детерминации R2 либо среднюю ошибку аппроксимации.
Чем выше показатель детерминации или чем ниже средняя ошибка аппроксимации, тем лучше модель описывает исходные данные.
Средняя ошибка аппроксимации – среднее относительное отклонение
расчетных значений от фактических

Построенное уравнение регрессии считается удовлетворительным, если
значение не превышает 10–12 %.
1.4. Оценка значимости уравнения регрессии, его коэффициентов,
Оценка значимости всего уравнения регрессии в целом осуществляется с
помощью F-критерия Фишера.
F-критерий Фишера заключается в проверке гипотезы Но о статистической незначимости уравнения регрессии. Для этого выполняется сравнение
фактического Fфакт и критического (табличного) Fтабл значений F-критерия
Fфакт определяется из соотношения значений факторной и остаточной
дисперсий, рассчитанных на одну степень свободы

где n – число единиц совокупности; m – число параметров при переменных.
Для линейной регрессии m = 1 .
Для нелинейной регрессии вместо r 2 xy используется R2.
Fтабл – максимально возможное значение критерия под влиянием случайных факторов при степенях свободы k1 = m, k2 = n – m – 1 (для линейной регрессии m = 1) и уровне значимости α.
Уровень значимости α – вероятность отвергнуть правильную гипотезу
при условии, что она верна. Обычно величина α принимается равной 0,05 или
Если Fтабл Fфакт, то гипотеза Но не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Для оценки статистической значимости коэффициентов линейной регрессии и линейного коэффициента парной корреляции применяется
t-критерий Стьюдента и рассчитываются доверительные интервалы каждого
Согласно t-критерию выдвигается гипотеза Н0 о случайной природе показателей, т. е. о незначимом их отличии от нуля. Далее рассчитываются фактические значения критерия tфакт для оцениваемых коэффициентов регрессии и коэффициента корреляции путем сопоставления их значений с величиной стандартной ошибки

Стандартные ошибки параметров линейной регрессии и коэффициента
корреляции определяются по формулам
 Сравнивая фактическое и критическое (табличное) значения t-статистики
Сравнивая фактическое и критическое (табличное) значения t-статистики
tтабл и tфакт принимают или отвергают гипотезу Но.
tтабл – максимально возможное значение критерия под влиянием случайных факторов при данной степени свободы k = n–2 и уровне значимости α.
Связь между F-критерием Фишера (при k1 = 1; m =1) и t-критерием Стьюдента выражается равенством
Если tтабл tфакт, то гипотеза Но не отклоняется и признается случайная природа формирования а, b или  .
.
Значимость коэффициента детерминации R2 (индекса корреляции) определяется с помощью F-критерия Фишера. Фактическое значение критерия Fфакт определяется по формуле

Fтабл определяется из таблицы при степенях свободы k1 = 1, k2 = n–2 и при
заданном уровне значимости α. Если Fтабл
http://lektsii.org/6-29199.html
http://pandia.ru/text/78/146/82802.php