Корреляционная таблица
Пример 1 . По данной корреляционной таблице построить прямые регрессии с X на Y и с Y на X . Найти соответствующие коэффициенты регрессии и коэффициент корреляции между X и Y .
| y/x | 15 | 20 | 25 | 30 | 35 | 40 |
| 100 | 2 | 2 | ||||
| 120 | 4 | 3 | 10 | 3 | ||
| 140 | 2 | 50 | 7 | 10 | ||
| 160 | 1 | 4 | 3 | |||
| 180 | 1 | 1 |
Решение:
Уравнение линейной регрессии с y на x будем искать по формуле
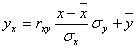
а уравнение регрессии с x на y, использовав формулу:
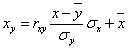
где x x , y — выборочные средние величин x и y, σx, σy — выборочные среднеквадратические отклонения.
Находим выборочные средние:
x = (15(1 + 1) + 20(2 + 4 + 1) + 25(4 + 50) + 30(3 + 7 + 3) + 35(2 + 10 + 10) + 40(2 + 3))/103 = 27.961
y = (100(2 + 2) + 120(4 + 3 + 10 + 3) + 140(2 + 50 + 7 + 10) + 160(1 + 4 + 3) + 180(1 + 1))/103 = 136.893
Выборочные дисперсии:
σ 2 x = (15 2 (1 + 1) + 20 2 (2 + 4 + 1) + 25 2 (4 + 50) + 30 2 (3 + 7 + 3) + 35 2 (2 + 10 + 10) + 40 2 (2 + 3))/103 — 27.961 2 = 30.31
σ 2 y = (100 2 (2 + 2) + 120 2 (4 + 3 + 10 + 3) + 140 2 (2 + 50 + 7 + 10) + 160 2 (1 + 4 + 3) + 180 2 (1 + 1))/103 — 136.893 2 = 192.29
Откуда получаем среднеквадратические отклонения:
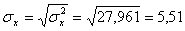 и
и 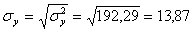
Определим коэффициент корреляции:
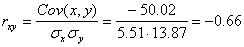
где ковариация равна:
Cov(x,y) = (35•100•2 + 40•100•2 + 25•120•4 + 30•120•3 + 35•120•10 + 40•120•3 + 20•140•2 + 25•140•50 + 30•140•7 + 35•140•10 + 15•160•1 + 20•160•4 + 30•160•3 + 15•180•1 + 20•180•1)/103 — 27.961 • 136.893 = -50.02
Запишем уравнение линий регрессии y(x):
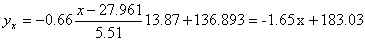
и уравнение x(y):
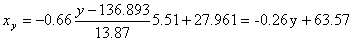
Построим найденные уравнения регрессии на чертеже, из которого сделаем следующие вывод:
1) обе линии проходят через точку с координатами (27.961; 136.893)
2) все точки расположены близко к линиям регрессии.

Пример 2 . По данным корреляционной таблицы найти условные средние y и x . Оценить тесноту линейной связи между признаками x и y и составить уравнения линейной регрессии y по x и x по y . Сделать чертеж, нанеся его на него условные средние и найденные прямые регрессии. Оценить силу связи между признаками с помощью корреляционного отношения.
Корреляционная таблица:
| X / Y | 2 | 4 | 6 | 8 | 10 |
| 1 | 5 | 4 | 2 | 0 | 0 |
| 2 | 0 | 6 | 3 | 3 | 0 |
| 3 | 0 | 0 | 1 | 2 | 3 |
| 5 | 0 | 0 | 0 | 0 | 1 |
Уравнение линейной регрессии с y на x имеет вид:
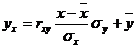
Уравнение линейной регрессии с x на y имеет вид:
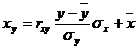
найдем необходимые числовые характеристики.
Выборочные средние:
x = (2(5) + 4(4 + 6) + 6(2 + 3 + 1) + 8(3 + 2) + 10(3 + 1) + )/30 = 5.53
y = (2(5) + 4(4 + 6) + 6(2 + 3 + 1) + 8(3 + 2) + 10(3 + 1) + )/30 = 1.93
Дисперсии:
σ 2 x = (2 2 (5) + 4 2 (4 + 6) + 6 2 (2 + 3 + 1) + 8 2 (3 + 2) + 10 2 (3 + 1))/30 — 5.53 2 = 6.58
σ 2 y = (1 2 (5 + 4 + 2) + 2 2 (6 + 3 + 3) + 3 2 (1 + 2 + 3) + 5 2 (1))/30 — 1.93 2 = 0.86
Откуда получаем среднеквадратические отклонения:
σx = 2.57 и σy = 0.93
и ковариация:
Cov(x,y) = (2•1•5 + 4•1•4 + 6•1•2 + 4•2•6 + 6•2•3 + 8•2•3 + 6•3•1 + 8•3•2 + 10•3•3 + 10•5•1)/30 — 5.53 • 1.93 = 1.84
Определим коэффициент корреляции:
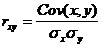
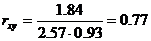
Запишем уравнения линий регрессии y(x):
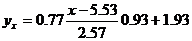
и вычисляя, получаем:
yx = 0.28 x + 0.39
Запишем уравнения линий регрессии x(y):
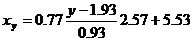
и вычисляя, получаем:
xy = 2.13 y + 1.42
Если построить точки, определяемые таблицей и линии регрессии, увидим, что обе линии проходят через точку с координатами (5.53; 1.93) и точки расположены близко к линиям регрессии.
Значимость коэффициента корреляции.
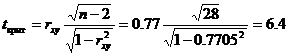
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=30-m-1 = 28 находим tкрит:
tкрит (n-m-1;α/2) = (28;0.025) = 2.048
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
Пример 3 . Распределение 50 предприятий пищевой промышленности по степени автоматизации производства Х (%) и росту производительности труда Y (%) представлено в таблице. Необходимо:
1. Вычислить групповые средние i и j x y, построить эмпирические линии регрессии.
2. Предполагая, что между переменными Х и Y существует линейная корреляционная зависимость:
а) найти уравнения прямых регрессии, построить их графики на одном чертеже с эмпирическими линиями регрессии и дать экономическую интерпретацию полученных уравнений;
б) вычислить коэффициент корреляции; на уровне значимости α= 0,05 оценить его значимость и сделать вывод о тесноте и направлении связи между переменными Х и Y;
в) используя соответствующее уравнение регрессии, оценить рост производительности труда при степени автоматизации производства 43%.
Скачать решение
Пример . По корреляционной таблице рассчитать ковариацию и коэффициент корреляции, построить прямые регрессии.
Пример 4 . Найти выборочное уравнение прямой Y регрессии Y на X по данной корреляционной таблице.
Решение находим с помощью калькулятора.
Скачать
Пример №4
Пример 5 . С целью анализа взаимного влияния прибыли предприятия и его издержек выборочно были проведены наблюдения за этими показателями в течение ряда месяцев: X — величина месячной прибыли в тыс. руб., Y — месячные издержки в процентах к объему продаж.
Результаты выборки сгруппированы и представлены в виде корреляционной таблицы, где указаны значения признаков X и Y и количество месяцев, за которые наблюдались соответствующие пары значений названных признаков.
Решение.
Пример №5
Пример №6
Пример №7
Пример 6 . Данные наблюдений над двумерной случайной величиной (X, Y) представлены в корреляционной таблице. Методом наименьших квадратов найти выборочное уравнение прямой регрессии Y на X. Построить график уравнения регрессии и показать точки (x;y)б рассчитанные по таблице данных.
Решение.
Скачать решение
Пример 7 . Дана корреляционная таблица для величин X и Y, X- срок службы колеса вагона в годах, а Y — усредненное значение износа по толщине обода колеса в миллиметрах. Определить коэффициент корреляции и уравнения регрессий.
| X / Y | 0 | 2 | 7 | 12 | 17 | 22 | 27 | 32 | 37 | 42 |
| 0 | 3 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 25 | 108 | 44 | 8 | 2 | 0 | 0 | 0 | 0 | 0 |
| 2 | 30 | 50 | 60 | 21 | 5 | 5 | 0 | 0 | 0 | 0 |
| 3 | 1 | 11 | 33 | 32 | 13 | 2 | 3 | 1 | 0 | 0 |
| 4 | 0 | 5 | 5 | 13 | 13 | 7 | 2 | 0 | 0 | 0 |
| 5 | 0 | 0 | 1 | 2 | 12 | 6 | 3 | 2 | 1 | 0 |
| 6 | 0 | 1 | 0 | 1 | 0 | 0 | 2 | 1 | 0 | 1 |
| 7 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
Решение.
Скачать решение
Пример 8 . По заданной корреляционной таблице определить групповые средние количественных признаков X и Y. Построить эмпирические и теоретические линии регрессии. Предполагая, что между переменными X и Y существует линейная зависимость:
- Вычислить выборочный коэффициент корреляции и проанализировать степень тесноты и направления связи между переменными.
- Определить линии регрессии и построить их графики.
Скачать
Задача по эконометрике 3
Задача 3. Определить выборочное уравнение прямой линии регрессии Y на Х по данным корреляционной таблицы. Найти интервал для истинного значения коэффициента корреляции.
Так как данные наблюдений между признаками Х и Y заданы в виде корреляционной таблицы с равноотстоящими вариантами, то для упрощения вычислений можем перейти к условным вариантам:
 ,
,
 ,
,
где С1, С2 – «ложные нули» вариант Х и Y соответственно (новые начала отсчета); h1, h2 – шаги (разности между двумя соседними вариантами).
С1=40; h1=10; 
С2=15; h2=5;
Итого
5
10
54
17
14
Итого nu
2
10
6
64
15
3
100
Вычислим групповые средние ūi и νi




Определяем теперь χ и ȳ по формулам:




Вычислим коэффициент корреляции.
При переходе к условным вариантам коэффициент корреляции вычисляется по формуле:







Так как коэффициент корреляции положителен, то делаем вывод о положительной связи между рассматриваемыми признаками, т.е. с увеличением значений признака Х значения признака Y тоже растут.
Найдем уравнение прямой регрессии Y на Х по формуле:




— искомое выборочное уравнение прямой линии регрессии Y на Х
Найдем доверительный интервал для коэффициента корреляции при доверительной вероятности 0,95 по формуле:

Для k=n-2=100-2=98 t=tтабл=1,984

С вероятностью 0,95 истинное значение коэффициента корреляции лежит в пределах от 0,566 до 0,734.
Корреляционно-регрессионный анализ в Excel: инструкция выполнения
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».

- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.
http://arkhangelsk.studzachet.ru/primeryi-uchebnyix-rabot/ekonometrika/zadacha-po-ekonometrike-3/
http://exceltable.com/otchety/korrelyacionno-regressionnyy-analiz