Корреляционно-регрессионный анализ: пример, задачи, применение. Метод корреляционно-регрессионного анализа
Корреляционно-регрессионный анализ – это один из самых распространенных методов изучения отношений между численными величинами. Его основная цель состоит в нахождении зависимости между двумя параметрами и ее степени с последующим выведением уравнения. Например, у нас есть студенты, которые сдали экзамен по математике и английскому языку. Мы можем использовать корреляцию для того, чтобы определить, влияет ли успешность сдачи одного теста на результаты по другому предмету. Что касается регрессионного анализа, то он помогает предсказать оценки по математике, исходя из баллов, набранных на экзамене по английскому языку, и наоборот.

Что такое корреляционная диаграмма?
Любой анализ начинается со сбора информации. Чем ее больше, тем точнее полученный в конечном итоге результат. В вышеприведенном примере у нас есть две дисциплины, по которым школьникам нужно сдать экзамен. Показатель успешности на них – это оценка. Корреляционно-регрессионный анализ показывает, влияет ли результат по одному предмету на баллы, набранные на втором экзамене. Для того чтобы ответить на этот вопрос, необходимо проанализировать оценки всех учеников на параллели. Но для начала нужно определиться с зависимой переменной. В данном случае это не так важно. Допустим, экзамен по математике проходил раньше. Баллы по нему – это независимая переменная (откладываются по оси абсцисс). Английский язык стоит в расписании позже. Поэтому оценки по нему – это зависимая переменная (откладываются по оси ординат). Чем больше полученный таким образом график похож на прямую линию, тем сильнее линейная корреляция между двумя избранными величинами. Это означает, что отличники в математике с большой долей вероятности получат пятерки на экзамене по английскому.
Допущения и упрощения
Метод корреляционно-регрессионного анализа предполагает нахождение причинно-следственной связи. Однако на первом этапе нужно понимать, что изменения обеих величин могут быть обусловлены какой-нибудь третьей, пока не учтенной исследователем. Также между переменными могут быть нелинейные отношения, поэтому получение коэффициента, равного нулю, это еще не конец эксперимента.
Линейная корреляция Пирсона
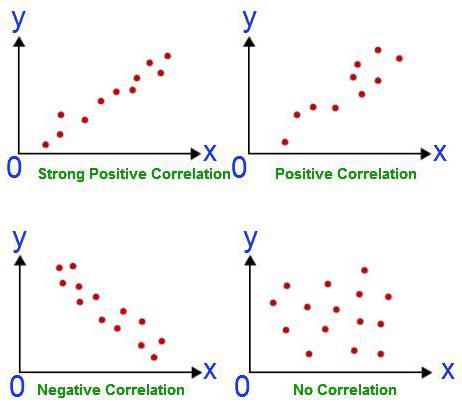
Данный коэффициент может использоваться при соблюдении двух условий. Первое – все значения переменных являются рациональными числами, второе – ожидается, что величины изменяются пропорционально. Данный коэффициент всегда находится в пределах между -1 и 1. Если он больше нуля, то имеет место быть прямо пропорциональная зависимость, меньше – обратно, равен – данные величины никак не влияют одна на другую. Умение вычислить данный показатель – это основы корреляционно-регрессионного анализа. Впервые данный коэффициент был разработан Карлом Пирсоном на основе идеи Френсиса Гальтона.
Свойства и предостережения
Коэффициент корреляции Пирсона является мощным инструментом, но его также нужно использовать с осторожностью. Существуют следующие предостережения в его применении:
- Коэффициент Пирсона показывает наличие или отсутствие линейной зависимости. Корреляционно-регрессионный анализ на этом не заканчивается, может оказаться, что переменные все-таки связаны между собой.
- Нужно быть осторожным в интерпретировании значения коэффициента. Можно найти корреляцию между размером ноги и уровнем IQ. Но это не означает, что один показатель определяет другой.
- Коэффициент Пирсона не говорит ничего о причинно-следственной связи между показателями.

Коэффициент ранговой корреляции Спирмана
Если изменение величины одного показателя приводит к увеличению или уменьшению значения другого, то это означает, что они являются связанными. Корреляционно-регрессионный анализ, пример которого будет приведен ниже, как раз и связан с такими параметрами. Ранговый коэффициент позволяет упростить расчеты.
Корреляционно-регрессионный анализ: пример
Предположим, происходит оценка эффективности деятельности десяти предприятий. У нас есть двое судей, которые выставляют им баллы. Корреляционно-регрессионный анализ предприятия в этом случае не может быть проведен на основе линейного коэффициента Пирсона. Нас не интересует взаимосвязь между оценками судей. Важны ранги предприятий по оценке судей.
Данный тип анализа имеет следующие преимущества:
- Непараметрическая форма отношений между исследуемыми величинами.
- Простота использования, поскольку ранги могут приписываться как в порядке возрастания значений, так и убывания.
Единственное требование данного типа анализа – это необходимость конвертации исходных данных.
Проблемы применения
В основе корреляционно-регрессионного анализа лежат следующие предположения:
- Наблюдения считаются независимыми (пятикратное выпадение «орла» никак не влияет на результат следующего подбрасывания монетки).
- В корреляционном анализе обе переменные рассматриваются как случайные. В регрессионном – только одна (зависимая).
- При проверке гипотезы должно соблюдаться нормальное распределение. Изменение зависимой переменной должно быть одинаковым для каждой величины на оси абсцисс.
- Корреляционная диаграмма – это только первая проверка гипотезы о взаимоотношениях между двумя рядами параметров, а не конечный результат анализа.
Зависимость и причинно-следственная связь
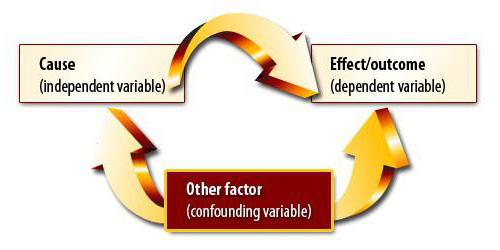
Предположим, мы вычислили коэффициент корреляции объема экспорта и ВВП. Он оказался равным единице по модулю. Провели ли мы корреляционно-регрессионный анализ до конца? Конечно же нет. Полученный результат вовсе не означает, что ВВП можно выразить через экспорт. Мы еще не доказали причинно-следственную связь между показателями. Корреляционно-регрессионный анализ – прогнозирование значений одной переменной на основе другой. Однако нужно понимать, что зачастую на параметр влияет множество факторов. Экспорт обуславливает ВВП, но не только он. Есть и другие факторы. Здесь имеет место быть и корреляция, и причинно-следственная связь, хотя и с поправкой на другие составляющие валового внутреннего продукта.
Гораздо опаснее другая ситуация. В Великобритании был проведен опрос, который показал, что дети, родители которых курили, чаще являются правонарушителями. Такой вывод сделан на основе сильной корреляции между показателя. Однако правилен ли он? Во-первых, зависимость могла быть обратной. Родители могли начать курить из-за стресса от того, что их дети постоянно попадают в переделки и нарушают закон. Во-вторых, оба параметра могут быть обусловлены третьим. Такие семьи принадлежат к низким социальным классам, для которых характерны обе проблемы. Поэтому на основе корреляции нельзя сделать вывод о наличии причинно-следственной связи.
Зачем использовать регрессионный анализ?
Корреляционная зависимость предполагает нахождение отношений между величинами. Причинно-следственная связь в этом случае остается за кадром. Задачи корреляционного и регрессионного анализа совпадают только в плане подтверждения наличия зависимости между значениями двух величин. Однако первоначально исследователь не обращает внимания на возможность причинно-следственной связи. В регрессионном анализе всегда есть две переменные, одна и которых является зависимой. Он проходит в несколько этапов:
- Выбор правильной модели с помощью метода наименьших квадратов.
- Выведение уравнения, описывающего влияние изменения независимой переменной на другую.
Например, если мы изучаем влияние возраста на рост человека, то регрессионный анализ может помочь предсказать изменения с течением лет.
Линейная и множественная регрессия
Предположим, что X и Y – это две связанные переменные. Регрессионный анализ позволяет предсказать величину одной из них на основе значений другой. Например, зрелость и возраст – это зависимые признаки. Зависимость между ними отражается с помощью линейной регрессии. Фактически можно выразить X через Y или наоборот. Но зачастую только одна из линий регрессии оказывается правильной. Успех анализа во многом зависит от правильности определения независимой переменной. Например, у нас есть два показателя: урожайность и объем выпавших осадков. Из житейского опыта становится ясно, что первое зависит от второго, а не наоборот.
Множественная регрессия позволяет рассчитать неизвестную величину на основе значений трех и более переменных. Например, урожайность риса на акр земли зависит от качества зерна, плодородности почвы, удобрений, температуры, количества осадков. Все эти параметры влияют на совокупный результат. Для упрощения модели используются следующие допущения:
- Зависимость между независимой и влияющими на нее характеристиками является линейной.
- Мультиколлинеарность исключена. Это означает, что зависимые переменные не связаны между собой.
- Гомоскедастичность и нормальность рядов чисел.
Применение корреляционно-регрессионного анализа
Существует три основных случая использования данного метода:
- Тестирование казуальных отношений между величинами. В этом случае исследователь определяет значения переменной и выясняет, влияют ли они на изменение зависимой переменной. Например, можно дать людям разные дозы алкоголя и измерить их артериальное давление. В этом случае исследователь точно знает, что первое является причиной второго, а не наоборот. Корреляционно-регрессионный анализ позволяет обнаружить прямо-пропорциональную линейную зависимость между данными двумя переменными и вывести формулу, ее описывающую. При этом сравниваться могут величины, выраженные в совершенно различных единицах измерения.
- Нахождение зависимости между двумя переменными без распространения на них причинно-следственной связи. В этом случае нет разницы, какую величину исследователь назовет зависимой. При этом в реальности может оказаться, что на их обе влияет третья переменная, поэтому они и изменяются пропорционально.
- Расчет значений одной величины на основе другой. Он осуществляется на основе уравнения, в которое подставляются известные числа.
Таким образом корреляционный анализ предполагает нахождение связи (не причинно-следственной) между переменными, а регрессионный – ее объяснение, зачастую с помощью математической функции.
Корреляционно-регрессионный анализ в Excel: инструкция выполнения
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
- линейной (у = а + bx);
- параболической (y = a + bx + cx 2 );
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».

- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.
Уравнение множественной регрессии
Назначение сервиса . С помощью онлайн-калькулятора можно найти следующие показатели:
- уравнение множественной регрессии, матрица парных коэффициентов корреляции, средние коэффициенты эластичности для линейной регрессии;
- множественный коэффициент детерминации, доверительные интервалы для индивидуального и среднего значения результативного признака;
Кроме этого проводится проверка на автокорреляцию остатков и гетероскедастичность.
- Шаг №1
- Шаг №2
- Видеоинструкция
- Оформление Word
Отбор факторов обычно осуществляется в два этапа:
- теоретический анализ взаимосвязи результата и круга факторов, которые оказывают на него существенное влияние;
- количественная оценка взаимосвязи факторов с результатом. При линейной форме связи между признаками данный этап сводится к анализу корреляционной матрицы (матрицы парных линейных коэффициентов корреляции). Научно обоснованное решение задач подобного вида также осуществляется с помощью дисперсионного анализа — однофакторного, если проверяется существенность влияния того или иного фактора на рассматриваемый признак, или многофакторного в случае изучения влияния на него комбинации факторов.
Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям:
- Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность.
- Каждый фактор должен быть достаточно тесно связан с результатом (т.е. коэффициент парной линейной корреляции между фактором и результатом должен быть существенным).
- Факторы не должны быть сильно коррелированы друг с другом, тем более находиться в строгой функциональной связи (т.е. они не должны быть интеркоррелированы). Разновидностью интеркоррелированности факторов является мультиколлинеарность — тесная линейная связь между факторами.
Пример . Постройте регрессионную модель с 2-мя объясняющими переменными (множественная регрессия). Определите теоретическое уравнение множественной регрессии. Оцените адекватность построенной модели.
Решение.
К исходной матрице X добавим единичный столбец, получив новую матрицу X
| 1 | 5 | 14.5 |
| 1 | 12 | 18 |
| 1 | 6 | 12 |
| 1 | 7 | 13 |
| 1 | 8 | 14 |
Матрица Y
| 9 |
| 13 |
| 16 |
| 14 |
| 21 |
Транспонируем матрицу X, получаем X T :
| 1 | 1 | 1 | 1 | 1 |
| 5 | 12 | 6 | 7 | 8 |
| 14.5 | 18 | 12 | 13 | 14 |
| Умножаем матрицы, X T X = |
|
В матрице, (X T X) число 5, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы X T и 1-го столбца матрицы X
| Умножаем матрицы, X T Y = |
|
Находим обратную матрицу (X T X) -1
| 13.99 | 0.64 | -1.3 |
| 0.64 | 0.1 | -0.0988 |
| -1.3 | -0.0988 | 0.14 |
Вектор оценок коэффициентов регрессии равен
| (X T X) -1 X T Y = y(x) = |
| * |
| = |
|
Получили оценку уравнения регрессии: Y = 34.66 + 1.97X1-2.45X2
Оценка значимости уравнения множественной регрессии осуществляется путем проверки гипотезы о равенстве нулю коэффициент детерминации рассчитанного по данным генеральной совокупности. Для ее проверки используют F-критерий Фишера.
R 2 = 1 — s 2 e/∑(yi — yср) 2 = 1 — 33.18/77.2 = 0.57
F = R 2 /(1 — R 2 )*(n — m -1)/m = 0.57/(1 — 0.57)*(5-2-1)/2 = 1.33
Табличное значение при степенях свободы k1 = 2 и k2 = n-m-1 = 5 — 2 -1 = 2, Fkp(2;2) = 19
Поскольку фактическое значение F = 1.33 Пример №2 . Приведены данные за 15 лет по темпам прироста заработной платы Y (%), производительности труда X1 (%), а также по уровню инфляции X2 (%).
| Год | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X1 | 3,5 | 2,8 | 6,3 | 4,5 | 3,1 | 1,5 | 7,6 | 6,7 | 4,2 | 2,7 | 4,5 | 3,5 | 5,0 | 2,3 | 2,8 |
| X2 | 4,5 | 3,0 | 3,1 | 3,8 | 3,8 | 1,1 | 2,3 | 3,6 | 7,5 | 8,0 | 3,9 | 4,7 | 6,1 | 6,9 | 3,5 |
| Y | 9,0 | 6,0 | 8,9 | 9,0 | 7,1 | 3,2 | 6,5 | 9,1 | 14,6 | 11,9 | 9,2 | 8,8 | 12,0 | 12,5 | 5,7 |
Решение. Подготовим данные для вставки из MS Excel (как транспонировать таблицу для сервиса см. Задание №2) .

Включаем в отчет: Проверка общего качества уравнения множественной регрессии (F-статистика. Критерий Фишера, Проверка на наличие автокорреляции),
После нажатия на кнопку Дале получаем готовое решение.
Уравнение регрессии (оценка уравнения регрессии):
Y = 0.2706 + 0.5257X1 + 1.4798X2
Скачать.
Качество построенного уравнения регрессии проверяется с помощью критерия Фишера (п. 6 отчета).
Пример №3 .
В таблице представлены данные о ВВП, объемах потребления и инвестициях некоторых стран.
| ВВП | 16331,97 | 16763,35 | 17492,22 | 18473,83 | 19187,64 | 20066,25 | 21281,78 | 22326,86 | 23125,90 |
| Потребление в текущих ценах | 771,92 | 814,28 | 735,60 | 788,54 | 853,62 | 900,39 | 999,55 | 1076,37 | 1117,51 |
| Инвестиции в текущих ценах | 176,64 | 173,15 | 151,96 | 171,62 | 192,26 | 198,71 | 227,17 | 259,07 | 259,85 |
Решение:
Для проверки полученных расчетов используем инструменты Microsoft Excel «Анализ данных» (см. пример).
Пример №4 . На основе данных, приведенных в Приложении и соответствующих Вашему варианту (таблица 2), требуется:
- Построить уравнение множественной регрессии. При этом признак-результат и один из факторов остаются теми же, что и в первом задании. Выберите дополнительно еще один фактор из приложения 1 (границы наблюдения должны совпадать с границами наблюдения признака-результата, соответствующего Вашему варианту). При выборе фактора нужно руководствоваться его экономическим содержанием или другими подходами. Пояснить смысл параметров уравнения.
- Рассчитать частные коэффициенты эластичности. Сделать вывод.
- Определить стандартизованные коэффициенты регрессии (b-коэффициенты). Сделать вывод.
- Определить парные и частные коэффициенты корреляции, а также множественный коэффициент корреляции; сделать выводы.
- Оценить значимость параметров уравнения регрессии с помощью t-критерия Стьюдента, а также значимость уравнения регрессии в целом с помощью общего F-критерия Фишера. Предложить окончательную модель (уравнение регрессии). Сделать выводы.
Решение. Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор получается из выражения:
s = (X T X) -1 X T Y
Матрица X
| 1 | 3.9 | 10 |
| 1 | 3.9 | 14 |
| 1 | 3.7 | 15 |
| 1 | 4 | 16 |
| 1 | 3.8 | 17 |
| 1 | 4.8 | 19 |
| 1 | 5.4 | 19 |
| 1 | 4.4 | 20 |
| 1 | 5.3 | 20 |
| 1 | 6.8 | 20 |
| 1 | 6 | 21 |
| 1 | 6.4 | 22 |
| 1 | 6.8 | 22 |
| 1 | 7.2 | 25 |
| 1 | 8 | 28 |
| 1 | 8.2 | 29 |
| 1 | 8.1 | 30 |
| 1 | 8.5 | 31 |
| 1 | 9.6 | 32 |
| 1 | 9 | 36 |
Матрица Y
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 8 |
| 8 |
| 8 |
| 10 |
| 9 |
| 11 |
| 9 |
| 11 |
| 12 |
| 12 |
| 12 |
| 12 |
| 14 |
| 14 |
Матрица X T
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3.9 | 3.9 | 3.7 | 4 | 3.8 | 4.8 | 5.4 | 4.4 | 5.3 | 6.8 | 6 | 6.4 | 6.8 | 7.2 | 8 | 8.2 | 8.1 | 8.5 | 9.6 | 9 |
| 10 | 14 | 15 | 16 | 17 | 19 | 19 | 20 | 20 | 20 | 21 | 22 | 22 | 25 | 28 | 29 | 30 | 31 | 32 | 36 |
Умножаем матрицы, (X T X)
Умножаем матрицы, (X T Y)
Находим определитель det(X T X) T = 139940.08
Находим обратную матрицу (X T X) -1
Уравнение регрессии
Y = 1.8353 + 0.9459X 1 + 0.0856X 2
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка e = Y — X*s
| 0.62 |
| 0.28 |
| 0.38 |
| 0.01 |
| 0.11 |
| -1 |
| -0.57 |
| 0.29 |
| -0.56 |
| 0.02 |
| -0.31 |
| 1.23 |
| -1.15 |
| 0.21 |
| 0.2 |
| -0.07 |
| -0.07 |
| -0.53 |
| 0.34 |
| 0.57 |
se 2 = (Y — X*s) T (Y — X*s)
Несмещенная оценка дисперсии равна
Оценка среднеквадратичного отклонения равна
Найдем оценку ковариационной матрицы вектора k = σ*(X T X) -1
| k(x) = 0.36 |
| = |
|
Дисперсии параметров модели определяются соотношением S 2 i = Kii, т.е. это элементы, лежащие на главной диагонали
С целью расширения возможностей содержательного анализа модели регрессии используются частные коэффициенты эластичности, которые определяются по формуле
Тесноту совместного влияния факторов на результат оценивает индекс множественной корреляции (от 0 до 1)
Связь между признаком Y факторами X сильная
Частные коэффициенты (или индексы) корреляции, измеряющие влияние на у фактора хi при неизменном уровне других факторов определяются по стандартной формуле линейного коэффициента корреляции — последовательно берутся пары yx1,yx2. , x1x2, x1x3.. и так далее и для каждой пары находится коэффициент корреляции
Коэффициент детерминации
R 2 = 0.97 2 = 0.95, т.е. в 95% случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — высокая
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл: Tтабл (n-m-1;a) = (17;0.05) = 1.74
Поскольку Tнабл Fkp, то коэффициент детерминации статистически значим и уравнение регрессии статистически надежно
Построение парной регрессионной модели
Рекомендации к решению контрольной работы.
Статистические данные по экономике можно получить на странице Россия в цифрах.
После определения зависимой и объясняющих переменных можно воспользоваться сервисом Множественная регрессия. Регрессионную модель с 2-мя объясняющими переменными можно построить используя матричный метод нахождения параметров уравнения регрессии или метод Крамера для нахождения параметров уравнения регрессии.
Пример №3 . Исследуется зависимость размера дивидендов y акций группы компаний от доходности акций x1, дохода компании x2 и объема инвестиций в расширение и модернизацию производства x3. Исходные данные представлены выборкой объема n=50.
Тема I. Парная линейная регрессия
Постройте парные линейные регрессии — зависимости признака y от факторов x1, x2, x3 взятых по отдельности. Для каждой объясняющей переменной:
- Постройте диаграмму рассеяния (поле корреляции). При построении выберите тип диаграммы «Точечная» (без отрезков, соединяющих точки).
- Вычислите коэффициенты уравнения выборочной парной линейной регрессии (для вычисления коэффициентов регрессии воспользуйтесь встроенной функцией ЛИНЕЙН (функция находится в категории «Статистические») или надстройкой Пакет Анализа), коэффициент детерминации, коэффициент корреляции (функция КОРЕЛЛ), среднюю ошибку аппроксимации.
- Запишите полученное уравнение выборочной регрессии. Дайте интерпретацию найденным в предыдущем пункте значениям.
- Постройте на поле корреляции прямую линию выборочной регрессии по точкам .
- Постройте диаграмму остатков.
- Проверьте статистическую значимость коэффициентов регрессии по критерию Стьюдента (табличное значение определите с помощью функции СТЬЮДРАСПОБР) и всего уравнения в целом по критерию Фишера (табличное значение Fтабл определите с помощью функции FРАСПОБР).
- Постройте доверительные интервалы для коэффициентов регрессии. Дайте им интерпретацию.
- Постройте прогноз для значения фактора, на 50% превышающего его среднее значение.
- Постройте доверительный интервал прогноза. Дайте ему экономическую интерпретацию.
- Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемого фактора на показатель.
Тема II. Множественная линейная регрессия
1. Постройте выборочную множественную линейную регрессию показателя на все указанные факторы. Запишите полученное уравнение, дайте ему экономическую интерпретацию.
2. Определите коэффициент детерминации, дайте ему интерпретацию. Вычислите среднюю абсолютную ошибку аппроксимации и дайте ей интерпретацию.
3. Проверьте статистическую значимость каждого из коэффициентов и всего уравнения в целом.
4. Постройте диаграмму остатков.
5. Постройте доверительные интервалы коэффициентов. Для статистически значимых коэффициентов дайте интерпретации доверительных интервалов.
6. Постройте точечный прогноз значения показателя y при значениях факторов, на 50% превышающих их средние значения.
7. Постройте доверительный интервал прогноза, дайте ему экономическую интерпретацию.
8. Постройте матрицу коэффициентов выборочной корреляции между показателем и факторами. Сделайте вывод о наличии проблемы мультиколлинеарности.
9. Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемых факторов на показатель.
http://exceltable.com/otchety/korrelyacionno-regressionnyy-analiz
http://math.semestr.ru/regress/corel.php