показатели качества регрессии.
Качеством модели регрессии называется адекватность построенной модели исходным (наблюдаемым) данным.
Для оценки качества модели регрессии используются специальные показатели.
Качество линейной модели парной регрессии характеризуется с помощью следующих показателей:
1) парной линейный коэффициент корреляции, который рассчитывается по формуле:

где G(x) – среднеквадратическое отклонение независимой переменной;
G(y) – среднеквадратическое отклонение зависимой переменной.
Также парный линейный коэффициент корреляции можно рассчитать через МНК-оценку коэффициента модели регрессии


Парный линейный коэффициент корреляции характеризует степень тесноты связи между исследуемыми переменными. Он рассчитывается только для количественных переменных. Чем ближе модуль значения коэффициента корреляции к единице, тем более тесной является связь между исследуемыми переменными. Данный коэффициент изменяется в пределах [-1; +1]. Если значение коэффициента корреляции находится в пределах от нуля до единицы, то связь между переменными прямая, т. е. с увеличением независимой переменной увеличивается и зависимая переменная, и наборот. Если коэффициент корреляции находится в пределах отминусеиницы до нуля, то связь между переменными обратная, т. е. с увеличением независимой переменной уменьшается зависимая переменная, и наоборот. Если коэффициент корреляции равен нулю, то связь между переменными отсутствует. Если коэффициент корреляции равен единице или минус единице, то связь между переменными существует функциональная связь, т. е. изменения независимой и зависимой переменных полностью соответствуют друг другу.
2) коэффициент детерминации рассчитывается как вадрат парного линейного коэффициента корреляции и обозначается как ryx2. Данный коэффициент характеризует в процентном отношении вариацию зависимой переменной, объяснённой вариацией независимой переменной, в общем объёме вариации.
Качество линейной модели множественной регрессии характеризуется с помощью показателей, построенных на основе теоремы о разложении дисперсий.
Теорема. Общая дисперсия зависимой переменной может быть разложена на объяснённую и необъяснённую построенной моделью регрессии дисперсии:

где G2(y) – это общая дисперсия зависимой переменной;
σ2(y) – это объяснённая с помощью построенной модели регрессии дисперсия переменной у, которая рассчитывается по формуле:

δ2(y) – необъяснённая или остаточная дисперсия переменной у, которая рассчитывается по формуле:
С использованием теоремы о разложении дисперсий рассчитываются следующие показатели качества линейной модели множественной регрессии:
1) множественный коэффициент корреляции между зависимой переменной у и несколькими независимыми переменными хi:

Данный коэффициент характеризует степень тесноты связи между зависимой и независимыми переменными. Свойства множественного коэффициента корреляции аналогичны свойствам линейнойго парного коэффициента корреляции.
2) теоретический коэффициент детерминации рассчитывается как квадрат множественного коэффициента корреляции:

Данный коэффициент характеризует в процентном отношении вариацию зависимой переменной, объяснённой вариацией независимых переменных;

характеризует в процентном отношении ту долю вариации зависимой переменной, которая не учитывается а построенной модели регрессии;
4) среднеквадратическая ошибка модели регрессии (Meansquareerror – MSE):

где h– это количество параметров, входящих в модель регрессии.
Если показатель среднеквадратической ошибки окажется меньше показателя среднеквадратического отклонения наблюдаемых значений зависимой переменной от модельных значений β(у), то модель регрессии можно считать качественной.
Показатель среднеквадратического отклонения наблюдаемых значений зависимой переменной от модельных значений рассчитывается по формуле:

5) показатель средней ошибки аппроксимации рассчитывается по формуле:

Если величина данного показателя составляет менее 6-7%, то качество построенной модели регрессии считается хорошим. Максимально допустимым значением показателя средней ошибки аппроксимации считается 12-15 %.
13 .
Свойства дисперсии определяются свойствами МО. Напомним, дисперсия является центральным моментом второго порядка:
Дисперсия любой случайной величины независимо от вида распределения, которому она подчиняется обладает следующими свойствами.
1.ДИСПЕРСИЯ НЕСЛУЧАЙНОЙ ВЕЛИЧИНЫ РАВНО НУЛЮ.
Пусть а — неслучайная величина. Тогда D(a)=M[(a-M(a))2]=M[0]=0.
2. ДИСПЕРСИЯ СУММЫ НЕСЛУЧАЙНОЙ И СЛУЧАЙНОЙ ВЕЛИЧИН РАВНА ДИСПЕРСИИ СЛУЧАЙНОЙ ВЕЛИЧИНЫ (ДИСПЕРСИЯ ИНВАРИАНТНА СДВИГУ).
Пусть а — неслучайная величина. Тогда D(a+x)=M[(a+x-M(a+x))2]= M[(x-M(x))2]=D(x).
3.ДИСПЕРСИЯ ПРОИЗВЕДЕНИЯ НЕСЛУЧАЙНОЙ ВЕЛИЧИНЫ НА СЛУЧАЙНУЮ РАВНА ПРОИЗВЕДЕНИЮ СЛУЧАЙНОЙ ВЕЛИЧИНЫ НА КВАДРАТ НЕСЛУЧАЙНОЙ ВЕЛИЧИНЫ.
Пусть а — неслучайная величина. Тогда D(a*x)=M[(a*x-M(a*x))2]=M[(a*(x-M(x))2]=
4. ДИСПЕРСИЯ СУММЫ ДВУХ СЛУЧАЙНЫХ ВЕЛИЧИН РАВНА СУММЕ ДИСПЕРСИЙ ЭТИХ ВЕЛИЧИН И УДВОЕННОЙ КОВАРИАЦИИ ЭТИХ ВЕЛИЧИН.
Пусть x и у — случайные величины. Тогда D(x+y)=M[((x+y)-M(x+y))2]= =M[((x-Mx)+(y-My))2]=M[(x-Mx)2+(y-My)2+2*(x-Mx)*(y-My)]=M[(x-Mx)2]+ +M[(y-My)]+2*M[(x-Mx)*(y-My)]=D(x)+D(y)+2*COV(x,y).
Величина COV(x,y)=M[(x-Mx)*(y-My)] называется ковариацией и обладает свойством: ДЛЯ НЕЗАВИСИМЫХ СЛУЧАЙНЫХ ВЕЛИЧИН КОВАРИАЦИЯ ВСЕГДА РАВНА НУЛЮ. Отсюда, следует: ДИСПЕРСИЯ СУММЫ ДВУХ НЕЗАВИСИМЫХ (И ТОЛЬКО НЕЗАВИСИМЫХ) СЛУЧАЙНЫХ ВЕЛИЧИН РАВНА СУММЕ ДИСПЕРСИЙ ЭТИХ ВЕЛИЧИН.
Для оценки параметров нелинейных моделей используются два подхода. Первый подход основан на линеаризации модели и заключается в том, что с помощью подходящих преобразований исходных переменных исследуемую зависимость представляют в виде линейного соотношения между преобразованными переменными. Второй подход обычно применяется в случае, когда подобрать соответствующее линеаризующее преобразование не удается. В этом случае применяются методы нелинейной оптимизации на основе исходных переменных. Таким образом, функции, которые показывают изменение одной переменной от другой в процентах или в несколько раз являются функциями, отражающими эластичность.
10.
Обобщенный метод наименьших квадратов, теорема Айткена
Применение обычного метода наименьших квадратов при нарушении условия гомоскедастичности приводит к следующим отрицательным последствиям:
1. оценки неизвестных коэффициентов β неэффективны, то есть существуют другие оценки, которые являются несмещенными и имеют меньшую дисперсию.
2. стандартные ошибки коэффициентов регрессии будут занижены, а, следовательно, t -статистики – завышены, и будет получено неправильное представление о точности уравнения регрессии.
Обобщенный метод наименьших квадратов
Рассмотрим метод оценивания при нарушении условия гомоскедастичности, матрица имеет вид β= (ХТ Ω-1 Х)-1 ХТ Ω-1у
Расчёт неизвестных коэффициентов регрессии по данной формуле называют обобщённым методом наименьших квадратов (ОМНК).
Теорема Айткена: при нарушении предположения гомоскедастичности оценки, полученные обобщенным методом наименьших квадратов, являются несмещенными и наиболее эффективными (имеющими наименьшую вариацию). На практике матрица Ω практически никогда не известна. Поэтому часто пытаются каким-либо методом оценить оценки матрицы Ω и использовать их для оценивания. Этот метод носит название доступного обобщенного метода наименьших квадратов.
Показатели качества уравнения парной регрессии
Уравнение регрессии всегда дополняется показателем тесноты связи. При использовании линейной регрессии в качестве такого показателя выступает линейный коэффициент корреляции 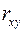 , который рассчитывается по следующей формуле:
, который рассчитывается по следующей формуле:
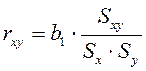 (1.6)
(1.6)
Линейный коэффициент корреляции находится в пределах:  . Чем ближе абсолютное значение к единице, тем сильнее линейная связь между факторами (при
. Чем ближе абсолютное значение к единице, тем сильнее линейная связь между факторами (при  имеем строгую функциональную зависимость). Но следует иметь в виду, что близость абсолютной величины линейного коэффициента корреляции к нулю еще не означает отсутствия связи между признаками. При другой (нелинейной) спецификации модели связь между признаками может оказаться достаточно тесной.
имеем строгую функциональную зависимость). Но следует иметь в виду, что близость абсолютной величины линейного коэффициента корреляции к нулю еще не означает отсутствия связи между признаками. При другой (нелинейной) спецификации модели связь между признаками может оказаться достаточно тесной.
Для оценки качества подбора линейной функции рассчитывается квадрат линейного коэффициента корреляции  , называемый коэффициентом детерминации. Коэффициент детерминации характеризует долю дисперсии результативного признака
, называемый коэффициентом детерминации. Коэффициент детерминации характеризует долю дисперсии результативного признака  , объясняемую уравнением регрессии, в общей дисперсии результативного признака:
, объясняемую уравнением регрессии, в общей дисперсии результативного признака:
 (1.7)
(1.7)
где 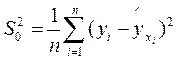 ,
, 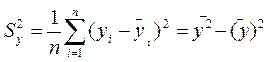 .
.
Соответственно величина  характеризует долю дисперсии , вызванную влиянием остальных, не учтенных в модели, факторов.
характеризует долю дисперсии , вызванную влиянием остальных, не учтенных в модели, факторов.
После того как оценено уравнение линейной регрессии, проводится проверка значимости как уравнения в целом, так и отдельных его параметров.
Проверить значимость уравнения регрессии – значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
Чтобы иметь общее суждение о качестве модели из относительных отклонений по каждому наблюдению, определяют среднюю ошибку аппроксимации:
 . (1.8)
. (1.8)
Средняя ошибка аппроксимации не должна превышать 8–10%.
Оценка значимости уравнения регрессии в целом производится на основе  -критерия Фишера, которому предшествует дисперсионный анализ. В математической статистике дисперсионный анализ рассматривается как самостоятельный инструмент статистического анализа. В эконометрике он применяется как вспомогательное средство для изучения качества регрессионной модели.
-критерия Фишера, которому предшествует дисперсионный анализ. В математической статистике дисперсионный анализ рассматривается как самостоятельный инструмент статистического анализа. В эконометрике он применяется как вспомогательное средство для изучения качества регрессионной модели.
Согласно основной идее дисперсионного анализа, общая сумма квадратов отклонений переменной от среднего значения  раскладывается на две части – «объясненную» и «необъясненную»:
раскладывается на две части – «объясненную» и «необъясненную»:
 ,
,
где 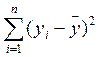 – общая сумма квадратов отклонений;
– общая сумма квадратов отклонений;  – сумма квадратов отклонений, объясненная регрессией (или факторная сумма квадратов отклонений);
– сумма квадратов отклонений, объясненная регрессией (или факторная сумма квадратов отклонений);  – остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов.
– остаточная сумма квадратов отклонений, характеризующая влияние неучтенных в модели факторов.
Схема дисперсионного анализа имеет вид, представленный в таблице 1.1 (  – число наблюдений,
– число наблюдений, 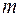 – число параметров при переменной
– число параметров при переменной  ).
).
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Дисперсия на одну степень свободы |
| Общая | |  | 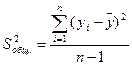 |
| Факторная | | | 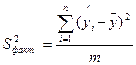 |
| Остаточная | |  |  |
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину -критерия Фишера:
 . (1.9)
. (1.9)
Расчетное значение – критерия Фишера (1.9) сравнивается с табличным значением  при уровне значимости α (зафиксированное значение ошибки I рода, состоящей в том, чтобы на основании данных выборочного исследования принять альтернативную гипотезу) и степенях свободы
при уровне значимости α (зафиксированное значение ошибки I рода, состоящей в том, чтобы на основании данных выборочного исследования принять альтернативную гипотезу) и степенях свободы  и
и  . При этом, если фактическое значение – критерия больше табличного, то признается статистическая значимость уравнения в целом.
. При этом, если фактическое значение – критерия больше табличного, то признается статистическая значимость уравнения в целом.
Для парной линейной регрессии  , поэтому
, поэтому
 . (1.10)
. (1.10)
Величина -критерия связана с коэффициентом детерминации , и ее можно рассчитать по следующей формуле:
 . (1.11)
. (1.11)
Оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка: Sb0, Sb1.
Стандартная ошибка коэффициента регрессии определяется по формуле:
 =
=  , (1.12)
, (1.12)
где  – остаточная дисперсия на одну степень свободы.
– остаточная дисперсия на одну степень свободы.
Для оценки существенности коэффициента регрессии его величина сравнивается с его стандартной ошибкой, т.е. определяется фактическое значение 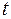 -критерия Стьюдента:
-критерия Стьюдента:  , которое затем сравнивается с табличным значением при определенном уровне значимости
, которое затем сравнивается с табличным значением при определенном уровне значимости 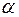 и числе степеней свободы
и числе степеней свободы 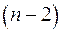 . Доверительный интервал для коэффициента регрессии определяется как
. Доверительный интервал для коэффициента регрессии определяется как  . Поскольку знак коэффициента регрессии указывает или на рост результативного признака при увеличении признака-фактора (
. Поскольку знак коэффициента регрессии указывает или на рост результативного признака при увеличении признака-фактора ( 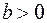 ), или на уменьшение результативного признака при увеличении признака-фактора (
), или на уменьшение результативного признака при увеличении признака-фактора (  ), или его независимость от объясняющей переменной (
), или его независимость от объясняющей переменной (  ) (рис. 1.3), то границы доверительного интервала для коэффициента регрессии не должны содержать противоречивых результатов, например,
) (рис. 1.3), то границы доверительного интервала для коэффициента регрессии не должны содержать противоречивых результатов, например,  . Такого рода запись указывает, что истинное значение коэффициента регрессии одновременно содержит положительные и отрицательные величины и даже ноль, чего не может быть.
. Такого рода запись указывает, что истинное значение коэффициента регрессии одновременно содержит положительные и отрицательные величины и даже ноль, чего не может быть.

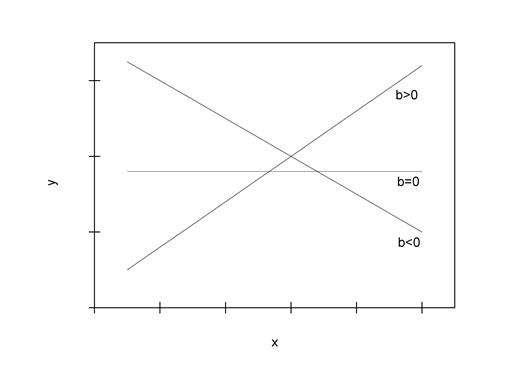
Рис. 1.3. Наклон линии регрессии в зависимости от значения параметра b1
Стандартная ошибка параметра определяется по формуле:
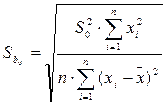 =
= 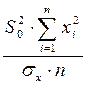 . (1.13)
. (1.13)
Процедура оценивания существенности данного параметра не отличается от рассмотренной выше для коэффициента регрессии. Вычисляется -критерий:  , его величина сравнивается с табличным значением при
, его величина сравнивается с табличным значением при  степенях свободы.
степенях свободы.
Значимость линейного коэффициента корреляции проверяется на основе величины ошибки коэффициента корреляции Sr:
 . (1.14)
. (1.14)
Фактическое значение – критерия Стьюдента определяется как  .
.
Существует связь между – критерием Стьюдента и -критерием Фишера:
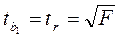 . (1.15)
. (1.15)
В прогнозных расчетах по уравнению регрессии определяется предсказываемое  значение как точечный прогноз
значение как точечный прогноз  при
при  , т.е. путем подстановки в уравнение регрессии
, т.е. путем подстановки в уравнение регрессии  соответствующего значения . Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки , т.е.
соответствующего значения . Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки , т.е.  , и соответственно интервальной оценкой прогнозного значения :
, и соответственно интервальной оценкой прогнозного значения :
 ,
,
где  – средняя ошибка прогнозируемого индивидуального значения:
– средняя ошибка прогнозируемого индивидуального значения:
 . (1.16)
. (1.16)
Доверительный интервал для условного математического ожидания рассчитывается по формуле:
 ,
,
где средняя ошибка прогнозируемого индивидуального значения определяется следующим образом:
 .
.
Решение типовых задач
Для данных из таблицы методом наименьших квадратов вычислить уравнение линейной регрессии:
| Xi |
| Yi |
Решение: для расчета параметров b0 и b1 линейной регрессии рассчитаем следующую таблицу (используя возможности MS Excel):

Затем, используя формулы расчета коэффициентов уравнения регрессии, определяем соответствующие их значения:

 .
.
Таким образом, уравнение линейной регрессии = —0,68+1,54xi.
Рассчитайте коэффициент корреляции, если уравнение регрессии
Решение: тесноту линейной связи уравнения регрессии оценивает коэффициент корреляции
 .
.
Получено уравнение регрессии y = 3 +3x. Известны σx = 2, σy = 8 и F = 36. На основании скольких наблюдений (n) получено уравнение?
Решение: количество наблюдений мы можем определить исходя из формулы:
 .
.
Для этого нам необходимо определить значение параметра  :
:
 ;
;
 ;
;
 .
.
По данным проведенного опроса восьми групп семей известны расходы населения на продукты питания и уровни доходов семей.
| Расходы на продукты питания, , тыс. руб. | 0,9 | 1,2 | 1,8 | 2,2 | 2,6 | 2,9 | 3,3 | 3,8 |
| Доходы семьи, , тыс. руб. | 1,2 | 3,1 | 5,3 | 7,4 | 9,6 | 11,8 | 14,5 | 18,7 |
1. Построить линейное уравнение парной регрессии y(x);
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить качество уравнения регрессии в целом с помощью -критерия Фишера.
4. Оценить статистическую значимость параметров регрессии и корреляции.
5. Выполнить прогноз расходов на продукты питания при прогнозном значении признака-фактора доходов семьи, составляющем 110% от среднего уровня.
6. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение: для удобства дальнейших вычислений составим таблицу.
 |  |  | 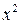 |  |  | 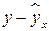 |  |  , % , % | |
| 1,2 | 0,9 | 1,08 | 1,44 | 0,81 | 1,038 | –0,138 | 0,0190 | 15,33 | |
| 3,1 | 1,2 | 3,72 | 9,61 | 1,44 | 1,357 | –0,157 | 0,0246 | 13,08 | |
| 5,3 | 1,8 | 9,54 | 28,09 | 3,24 | 1,726 | 0,074 | 0,0055 | 4,11 | |
| 7,4 | 2,2 | 16,28 | 54,76 | 4,84 | 2,079 | 0,121 | 0,0146 | 5,50 | |
| 9,6 | 2,6 | 24,96 | 92,16 | 6,76 | 2,449 | 0,151 | 0,0228 | 5,81 | |
| 11,8 | 2,9 | 34,22 | 139,24 | 8,41 | 2,818 | 0,082 | 0,0067 | 2,83 | |
| 14,5 | 3,3 | 47,85 | 210,25 | 10,89 | 3,272 | 0,028 | 0,0008 | 0,85 | |
| 18,7 | 3,8 | 71,06 | 349,69 | 14,44 | 3,978 | –0,178 | 0,0317 | 4,68 | |
| Итого | 71,6 | 18,7 | 208,71 | 885,24 | 50,83 | 18,717 | –0,017 | 0,1257 | 52,19 |
| Среднее значение | 8,95 | 2,34 | 26,09 | 110,66 | 6,35 | 2,34 | – | 0,0157 | 6,52 |
 | 5,5345 | 0,9352 | – | – | – | – | – | – | – |
 | 30,5612 | 0,8741 | – | – | – | – | – | – | – |
1. Рассчитаем параметры линейного уравнения парной регрессии . Для этого воспользуемся формулами (1.5):
 ,
,
 . (1.5)
. (1.5)
 .
.
т.е. с увеличением дохода семьи на 1000 руб. расходы на питание увеличиваются на 168 руб.
2. Как было указано выше, уравнение линейной регрессии всегда дополняется показателем тесноты связи – линейным коэффициентом корреляции :
 .
.
Близость коэффициента корреляции к 1 указывает на тесную линейную связь между признаками.
Средняя ошибка аппроксимации (находим с помощью столбца 10 таблицы 1.3;  ;
;  говорит о хорошем качестве уравнения регрессии, т.е. свидетельствует о хорошем подборе модели к исходным данным.
говорит о хорошем качестве уравнения регрессии, т.е. свидетельствует о хорошем подборе модели к исходным данным.
3. Коэффициент детерминации  (тот же результат получим, если воспользуемся формулой (1.7)) показывает, что уравнением регрессии объясняется 98,7% дисперсии результативного признака, а на долю прочих факторов приходится лишь 1,3%.
(тот же результат получим, если воспользуемся формулой (1.7)) показывает, что уравнением регрессии объясняется 98,7% дисперсии результативного признака, а на долю прочих факторов приходится лишь 1,3%.
Оценим качество уравнения регрессии в целом с помощью -критерия Фишера. Сосчитаем фактическое значение -критерия:
 .
.
Табличное значение ( 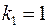 ,
,  ,
,  ): Fтабл. = 23. Так как
): Fтабл. = 23. Так как  , то признается статистическая значимость уравнения в целом.
, то признается статистическая значимость уравнения в целом.
4. Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитаем -критерий Стьюдента и доверительные интервалы каждого из показателей. Рассчитаем случайные ошибки параметров линейной регрессии и коэффициента корреляции
 .
.
=  ,
,
= 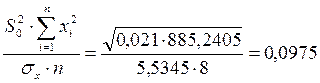 ,
,

Фактические значения -статистик:
 ,
,
 ,
,
 . Табличное значение -критерия Стьюдента при и числе степеней свободы
. Табличное значение -критерия Стьюдента при и числе степеней свободы 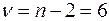 есть
есть  . Так как
. Так как 
 и
и  , то признаем статистическую значимость параметров регрессии и показателя тесноты связи. Рассчитаем доверительные интервалы для параметров регрессии b0 и b1:
, то признаем статистическую значимость параметров регрессии и показателя тесноты связи. Рассчитаем доверительные интервалы для параметров регрессии b0 и b1:  и . Получим, что
и . Получим, что  и
и 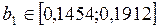 .
.
5. И, наконец, найдем прогнозное значение результативного фактора  при значении признака-фактора, составляющем 110% от среднего уровня
при значении признака-фактора, составляющем 110% от среднего уровня  , т.е. найдем расходы на питание, если доходы семьи составят 9,85 тыс. руб.
, т.е. найдем расходы на питание, если доходы семьи составят 9,85 тыс. руб.
 (тыс. руб.)
(тыс. руб.)
Значит, если доходы семьи составят 9,845 тыс. руб., то расходы на питание будут 2,490 тыс. руб.
Найдем доверительный интервал прогноза. Ошибка прогноза
 ,
,
а доверительный интервал (  ):
):
 .
.
Прогноз является статистически надежным.
Теперь на одном графике изобразим исходные данные и линию регрессии:

Упражнения и задачи
Так называемая кривая Филипса описывает связь темпа роста заработной платы и уровня безработицы. А именно,
 ,
,
где  – уровень заработной платы,
– уровень заработной платы,  — темп роста заработной платы (в процентах) и
— темп роста заработной платы (в процентах) и  – процент безработных в год t. Теория предполагает, что
– процент безработных в год t. Теория предполагает, что  0.
0.
Используя данные для некоторой страны из таблицы
a) найдите оценки коэффициентов уравнения и проверьте наличие значимой связи между  и ;
и ;
b) найдите «естественный уровень безработицы», т.е. такой уровень безработицы, при котором = 0;
c) когда изменения в уровне безработицы оказывали наибольшее (наименьшее) влияние на темп изменения заработной платы;
d) найдите 95% – доверительные интервалы для и  .
.
| Год |  |  | Год | | |
| 1,62 | 1,0 | 2,66 | 1,8 | ||
| 1,65 | 1,4 | 1,73 | 1,9 | ||
| 1,79 | 1,1 | 2,80 | 1,5 | ||
| 1,94 | 1,5 | 2,92 | 1,4 | ||
| 2,03 | 1,5 | 3,02 | 1,8 | ||
| 2,12 | 1,2 | 3,13 | 1,1 | ||
| 2,26 | 1,0 | 3,28 | 1,5 | ||
| 2,44 | 1,1 | 3,43 | 1,3 | ||
| 2,57 | 1,3 | 3,58 | 1,4 |
Для 14 однотипных предприятий (i – номер предприятия) имеются данные за год (см. табл.)
| i |
| yi |
| xi |
yi – производительность труда, т/ч;
xi – уровень механизации работ, %.
1. Построить выборочное уравнение линейной парной регрессии (найти значения b1 и b0);
2. Рассчитать значение выборочного коэффициента корреляции rxy., среднюю ошибку аппроксимации, выборочный коэффициент детерминации R2 и стандартные отклонения коэффициентов регрессии;
3. На уровне значимости α=0,05 оценить значимость коэффициентов и уравнения регрессии, проверить значимость линейной функции регрессии Найти доверительные интервалы для значимых коэффициентов регрессии и значений yi;
4. Оформить выводы в виде аналитической записки.
Имеются следующие статистические данные по Республике Татарстан:
| Год |
| Зарегистрировано преступлений, yi |
| Общая численность безработных, xi |
5. Определить по МНК оценки коэффициентов уравнения регрессии.
6. Проверить статистическую значимость коэффициентов, входящих в уравнение регрессии.
7. Найти доверительные интервалы для коэффициентов регрессии при уровне значимости a= 0,05.
8. Рассчитать коэффициент детерминации и на уровне значимости 0,05 проверить значимость линейной функции регрессии с помощью F-критерия Фишера.
9. Найти точечное (с надёжностью 0,95) предсказание зависимой переменной при значении объясняющей переменной, равном максимальному наблюдённому её значению, увеличенному на 10%.
Множественная регрессия
Множественная регрессия представляет собой модель вида
 ,
, 
где у — результативный признак, а х1, х2, х,…,xm — независимые или объясняющие переменные (признаки-факторы), ei – случайная ошибка отклонения.
Цель множественной регрессии — определить степень влияния каждого из факторов в отдельности и их совместное воздействие на результативный признак.
Включаемые в модель множественной регрессии факторы должны объяснять вариацию независимой переменной. Как и в случае парной регрессии, для модели множественной регрессии с некоторым набором факторов рассчитывается множественный коэффициент детерминации, определяющий долю объясненной вариации результативного признака за счет факторов, входящих в модель.
Остановимся на теоретической линейной модели множественной регрессии:

где bi — коэффициенты регрессии, каждый из которых показывает, насколько единиц изменится у с изменением соответствующего признака х на единицу при условии, что остальные признаки не изменятся;
 — теоретическое значение, представляющее собой оценку ожидаемого значения у при фиксированных значениях переменных хm
— теоретическое значение, представляющее собой оценку ожидаемого значения у при фиксированных значениях переменных хm
Как и в случае парной регрессии по любой конечной выборке нельзя точно получить вектор коэффициентов уравнения  . Мы можем только рассчитать эмпирическое уравнение регрессии в форме:
. Мы можем только рассчитать эмпирическое уравнение регрессии в форме:
 .
.
В этом случае вектор  является вектором оценки теоретического вектора b, ei – оценка теоретического отклонения ei.
является вектором оценки теоретического вектора b, ei – оценка теоретического отклонения ei.
Показатели качества модели парной регрессии
Основным показателем качества модели является коэффициент детерминации
Он показывает долю изменений результата Y, обусловленную изменениями фактора X. R 2 принимает значения от 0 до 1. Чем ближе R 2 к единице, тем лучше модель объясняет формирование Y. Для линейной парной регрессии коэффициент детерминации равен квадрату коэффициента корреляции: .
Точность модели, т. е. близость расчетных значений к фактическим, характеризует стандартная ошибка регрессии
Для оценки относительной точности модели используется средняя относительная ошибка аппроксимации
Если , то точность модели высокая, при — хорошая, при — удовлетворительная, а при — неудовлетворительная.
Продолжение примера 1. Коэффициент детерминации был определен с помощью функции «КВПИРСОН»: R 2 0,869. Он показывает, что 86,9 % изменений выручки от продаж Y обусловлено изменением стоимости активов X.
Стандартная ошибка регрессии была определена с помощью функции «СТОШYX»: Sрег3,92 млн. руб.
Средняя относительная ошибка аппроксимации
Рассчитанные по уравнению регрессии значения выручки от продаж Y отклоняются от фактических в среднем на 3,92 млн. руб. или на 7,1%. Модель имеет хорошую точность.
http://lektsia.com/4x4dbf.html
http://einsteins.ru/subjects/ekonometrika/teoriya-ekonometrika/pokazateli-kachestva-modeli