Задача №1 Построение уравнения регрессии
Имеются следующие данные разных стран об индексе розничных цен на продукты питания (х) и об индексе промышленного производства (у).
| Индекс розничных цен на продукты питания (х) | Индекс промышленного производства (у) | |
|---|---|---|
| 1 | 100 | 70 |
| 2 | 105 | 79 |
| 3 | 108 | 85 |
| 4 | 113 | 84 |
| 5 | 118 | 85 |
| 6 | 118 | 85 |
| 7 | 110 | 96 |
| 8 | 115 | 99 |
| 9 | 119 | 100 |
| 10 | 118 | 98 |
| 11 | 120 | 99 |
| 12 | 124 | 102 |
| 13 | 129 | 105 |
| 14 | 132 | 112 |
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
В) равносторонней гиперболы.
2. Для каждой модели рассчитать показатели: тесноты связи и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз значения индекса промышленного производства у при прогнозном значении индекса розничных цен на продукты питания х=138.
Решение:
1. Для расчёта параметров линейной регрессии
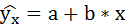
Решаем систему нормальных уравнений относительно a и b:
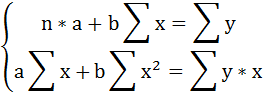
Построим таблицу расчётных данных, как показано в таблице 1.
Таблица 1 Расчетные данные для оценки линейной регрессии
| № п/п | х | у | ху | x 2 | y 2 | 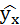 | 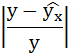 |
|---|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 7000 | 10000 | 4900 | 74,26340 | 0,060906 |
| 2 | 105 | 79 | 8295 | 11025 | 6241 | 79,92527 | 0,011712 |
| 3 | 108 | 85 | 9180 | 11664 | 7225 | 83,32238 | 0,019737 |
| 4 | 113 | 84 | 9492 | 12769 | 7056 | 88,98425 | 0,059336 |
| 5 | 118 | 85 | 10030 | 13924 | 7225 | 94,64611 | 0,113484 |
| 6 | 118 | 85 | 10030 | 13924 | 7225 | 94,64611 | 0,113484 |
| 7 | 110 | 96 | 10560 | 12100 | 9216 | 85,58713 | 0,108467 |
| 8 | 115 | 99 | 11385 | 13225 | 9801 | 91,24900 | 0,078293 |
| 9 | 119 | 100 | 11900 | 14161 | 10000 | 95,77849 | 0,042215 |
| 10 | 118 | 98 | 11564 | 13924 | 9604 | 94,64611 | 0,034223 |
| 11 | 120 | 99 | 11880 | 14400 | 9801 | 96,91086 | 0,021102 |
| 12 | 124 | 102 | 12648 | 15376 | 10404 | 101,4404 | 0,005487 |
| 13 | 129 | 105 | 13545 | 16641 | 11025 | 107,1022 | 0,020021 |
| 14 | 132 | 112 | 14784 | 17424 | 12544 | 110,4993 | 0,013399 |
| Итого: | 1629 | 1299 | 152293 | 190557 | 122267 | 1299,001 | 0,701866 |
| Среднее значение: | 116,3571 | 92,78571 | 10878,07 | 13611,21 | 8733,357 | х | х |
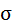 | 8,4988 | 11,1431 | х | х | х | х | х |
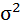 | 72,23 | 124,17 | х | х | х | х | х |
Среднее значение определим по формуле:
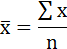
Cреднее квадратическое отклонение рассчитаем по формуле:
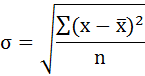
и занесём полученный результат в таблицу 1.
Возведя в квадрат полученное значение получим дисперсию:
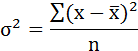
Параметры уравнения можно определить также и по формулам:
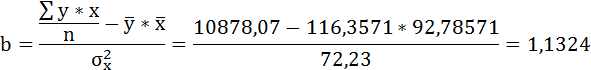
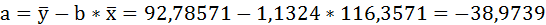
Таким образом, уравнение регрессии:
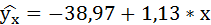
Следовательно, с увеличением индекса розничных цен на продукты питания на 1, индекс промышленного производства увеличивается в среднем на 1,13.
Рассчитаем линейный коэффициент парной корреляции:
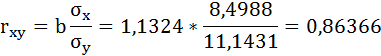
Связь прямая, достаточно тесная.
Определим коэффициент детерминации:
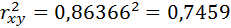
Вариация результата на 74,59% объясняется вариацией фактора х.
Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчётные) значения .
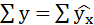 ,
,
следовательно, параметры уравнения определены правильно.
Рассчитаем среднюю ошибку аппроксимации – среднее отклонение расчётных значений от фактических:
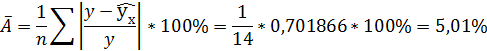
В среднем расчётные значения отклоняются от фактических на 5,01%.
Оценку качества уравнения регрессии проведём с помощью F-теста.
F-тест состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера.
Fфакт определяется по формуле:
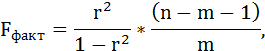
где n – число единиц совокупности;
m – число параметров при переменных х.
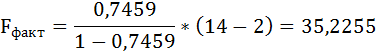
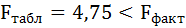
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза.
Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
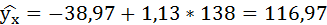
2. Степенная регрессия имеет вид:
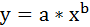
Для определения параметров производят логарифмирование степенной функции:
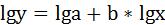
Для определения параметров логарифмической функции строят систему нормальных уравнений по способу наименьших квадратов:
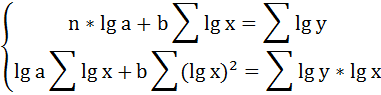
Построим таблицу расчётных данных, как показано в таблице 2.
Таблица 2 Расчетные данные для оценки степенной регрессии
| №п/п | х | у | lg x | lg y | lg x*lg y | (lg x) 2 | (lg y) 2 |
|---|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 2,000000 | 1,845098 | 3,690196 | 4,000000 | 3,404387 |
| 2 | 105 | 79 | 2,021189 | 1,897627 | 3,835464 | 4,085206 | 3,600989 |
| 3 | 108 | 85 | 2,033424 | 1,929419 | 3,923326 | 4,134812 | 3,722657 |
| 4 | 113 | 84 | 2,053078 | 1,924279 | 3,950696 | 4,215131 | 3,702851 |
| 5 | 118 | 85 | 2,071882 | 1,929419 | 3,997528 | 4,292695 | 3,722657 |
| 6 | 118 | 85 | 2,071882 | 1,929419 | 3,997528 | 4,292695 | 3,722657 |
| 7 | 110 | 96 | 2,041393 | 1,982271 | 4,046594 | 4,167284 | 3,929399 |
| 8 | 115 | 99 | 2,060698 | 1,995635 | 4,112401 | 4,246476 | 3,982560 |
| 9 | 119 | 100 | 2,075547 | 2,000000 | 4,151094 | 4,307895 | 4,000000 |
| 10 | 118 | 98 | 2,071882 | 1,991226 | 4,125585 | 4,292695 | 3,964981 |
| 11 | 120 | 99 | 2,079181 | 1,995635 | 4,149287 | 4,322995 | 3,982560 |
| 12 | 124 | 102 | 2,093422 | 2,008600 | 4,204847 | 4,382414 | 4,034475 |
| 13 | 129 | 105 | 2,110590 | 2,021189 | 4,265901 | 4,454589 | 4,085206 |
| 14 | 132 | 112 | 2,120574 | 2,049218 | 4,345518 | 4,496834 | 4,199295 |
| Итого | 1629 | 1299 | 28,90474 | 27,49904 | 56,79597 | 59,69172 | 54,05467 |
| Среднее значение | 116,3571 | 92,78571 | 2,064624 | 1,964217 | 4,056855 | 4,263694 | 3,861048 |
| 8,4988 | 11,1431 | 0,031945 | 0,053853 | х | х | х |
| 72,23 | 124,17 | 0,001021 | 0,0029 | х | х | х |
Продолжение таблицы 2 Расчетные данные для оценки степенной регрессии
| №п/п | х | у | | 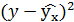 | | 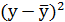 |
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 74,16448 | 17,34292 | 0,059493 | 519,1886 |
| 2 | 105 | 79 | 79,62057 | 0,385112 | 0,007855 | 190,0458 |
| 3 | 108 | 85 | 82,95180 | 4,195133 | 0,024096 | 60,61728 |
| 4 | 113 | 84 | 88,59768 | 21,13866 | 0,054734 | 77,1887 |
| 5 | 118 | 85 | 94,35840 | 87,57961 | 0,110099 | 60,61728 |
| 6 | 118 | 85 | 94,35840 | 87,57961 | 0,110099 | 60,61728 |
| 7 | 110 | 96 | 85,19619 | 116,7223 | 0,11254 | 10,33166 |
| 8 | 115 | 99 | 90,88834 | 65,79901 | 0,081936 | 38,6174 |
| 9 | 119 | 100 | 95,52408 | 20,03384 | 0,044759 | 52,04598 |
| 10 | 118 | 98 | 94,35840 | 13,26127 | 0,037159 | 27,18882 |
| 11 | 120 | 99 | 96,69423 | 5,316563 | 0,023291 | 38,6174 |
| 12 | 124 | 102 | 101,4191 | 0,337467 | 0,005695 | 84,90314 |
| 13 | 129 | 105 | 107,4232 | 5,872099 | 0,023078 | 149,1889 |
| 14 | 132 | 112 | 111,0772 | 0,85163 | 0,00824 | 369,1889 |
| Итого | 1629 | 1299 | 1296,632 | 446,4152 | 0,703074 | 1738,357 |
| Среднее значение | 116,3571 | 92,78571 | х | х | х | х |
| 8,4988 | 11,1431 | х | х | х | х |
| 72,23 | 124,17 | х | х | х | х |
Решая систему нормальных уравнений, определяем параметры логарифмической функции.
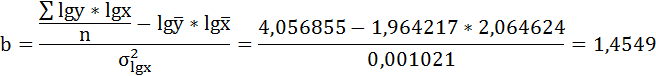
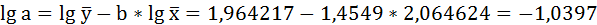
Получим линейное уравнение:
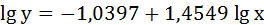
Выполнив его потенцирование, получим:
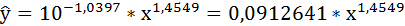
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата 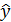 . По ним рассчитаем показатели: тесноты связи – индекс корреляции и среднюю ошибку аппроксимации.
. По ним рассчитаем показатели: тесноты связи – индекс корреляции и среднюю ошибку аппроксимации.
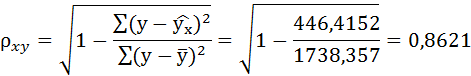
Связь достаточно тесная.
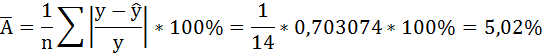
В среднем расчётные значения отклоняются от фактических на 5,02%.
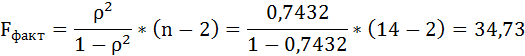
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
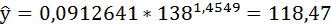
3. Уравнение равносторонней гиперболы
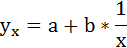
Для определения параметров этого уравнения используется система нормальных уравнений:
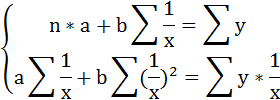
Произведем замену переменных
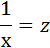
и получим следующую систему нормальных уравнений:
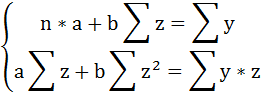
Решая систему нормальных уравнений, определяем параметры гиперболы.
Составим таблицу расчётных данных, как показано в таблице 3.
Таблица 3 Расчетные данные для оценки гиперболической зависимости
| №п/п | х | у | z | yz | 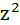 | 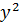 |
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 0,010000000 | 0,700000 | 0,0001000 | 4900 |
| 2 | 105 | 79 | 0,009523810 | 0,752381 | 0,0000907 | 6241 |
| 3 | 108 | 85 | 0,009259259 | 0,787037 | 0,0000857 | 7225 |
| 4 | 113 | 84 | 0,008849558 | 0,743363 | 0,0000783 | 7056 |
| 5 | 118 | 85 | 0,008474576 | 0,720339 | 0,0000718 | 7225 |
| 6 | 118 | 85 | 0,008474576 | 0,720339 | 0,0000718 | 7225 |
| 7 | 110 | 96 | 0,009090909 | 0,872727 | 0,0000826 | 9216 |
| 8 | 115 | 99 | 0,008695652 | 0,860870 | 0,0000756 | 9801 |
| 9 | 119 | 100 | 0,008403361 | 0,840336 | 0,0000706 | 10000 |
| 10 | 118 | 98 | 0,008474576 | 0,830508 | 0,0000718 | 9604 |
| 11 | 120 | 99 | 0,008333333 | 0,825000 | 0,0000694 | 9801 |
| 12 | 124 | 102 | 0,008064516 | 0,822581 | 0,0000650 | 10404 |
| 13 | 129 | 105 | 0,007751938 | 0,813953 | 0,0000601 | 11025 |
| 14 | 132 | 112 | 0,007575758 | 0,848485 | 0,0000574 | 12544 |
| Итого: | 1629 | 1299 | 0,120971823 | 11,13792 | 0,0010510 | 122267 |
| Среднее значение: | 116,3571 | 92,78571 | 0,008640844 | 0,795566 | 0,0000751 | 8733,357 |
| 8,4988 | 11,1431 | 0,000640820 | х | х | х |
| 72,23 | 124,17 | 0,000000411 | х | х | х |
Продолжение таблицы 3 Расчетные данные для оценки гиперболической зависимости
| №п/п | х | у | | | | |
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 72,3262 | 0,033231 | 5,411206 | 519,1886 |
| 2 | 105 | 79 | 79,49405 | 0,006254 | 0,244083 | 190,0458 |
| 3 | 108 | 85 | 83,47619 | 0,017927 | 2,322012 | 60,61728 |
| 4 | 113 | 84 | 89,64321 | 0,067181 | 31,84585 | 77,1887 |
| 5 | 118 | 85 | 95,28761 | 0,121031 | 105,8349 | 60,61728 |
| 6 | 118 | 85 | 95,28761 | 0,121031 | 105,8349 | 60,61728 |
| 7 | 110 | 96 | 86,01027 | 0,10406 | 99,79465 | 10,33166 |
| 8 | 115 | 99 | 91,95987 | 0,071112 | 49,56344 | 38,6174 |
| 9 | 119 | 100 | 96,35957 | 0,036404 | 13,25272 | 52,04598 |
| 10 | 118 | 98 | 95,28761 | 0,027677 | 7,357059 | 27,18882 |
| 11 | 120 | 99 | 97,41367 | 0,016024 | 2,516453 | 38,6174 |
| 12 | 124 | 102 | 101,46 | 0,005294 | 0,291565 | 84,90314 |
| 13 | 129 | 105 | 106,1651 | 0,011096 | 1,357478 | 149,1889 |
| 14 | 132 | 112 | 108,8171 | 0,028419 | 10,1311 | 369,1889 |
| Итого: | 1629 | 1299 | 1298,988 | 0,666742 | 435,7575 | 1738,357 |
| Среднее значение: | 116,3571 | 92,78571 | х | х | х | х |
| 8,4988 | 11,1431 | х | х | х | х |
| 72,23 | 124,17 | х | х | х | х |
Значения параметров регрессии a и b составили:
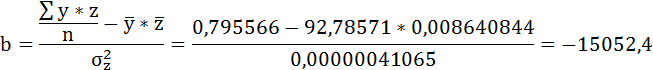
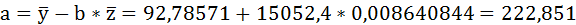
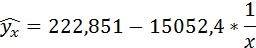
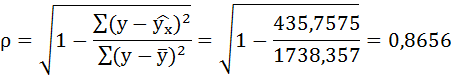
Связь достаточно тесная.
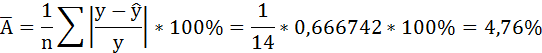
В среднем расчётные значения отклоняются от фактических на 4,76%.
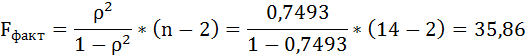
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
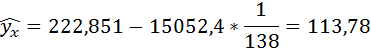
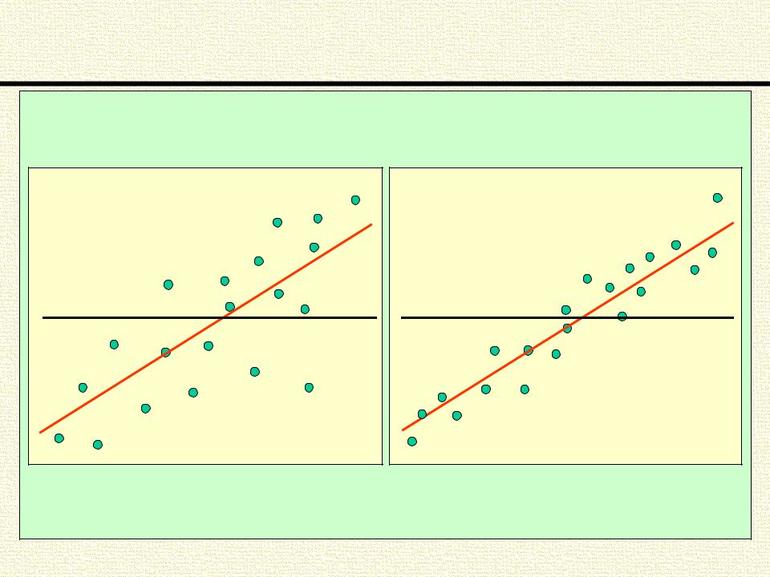
По уравнению равносторонней гиперболы получена наибольшая оценка тесноты связи по сравнению с линейной и степенной регрессиями. Средняя ошибка аппроксимации остаётся на допустимом уровне.
Регрессионный анализ — основы, этапы и примеры задач
Общая информация
Метод моделирования пар данных и исследования их свойств представляет собой раздел математической статистики, который используют для выявления статистических закономерностей, объединяющих ряд величин. При этом некоторые данные являются случайными. Анализируя зависимости, исследователь может построить модель регрессии.
Полученные данные — основа регрессионного анализа и база для дальнейшего изучения, которое основывается на том, что между числами всегда существуют известные или скрытые связи. Первые получаются путём вычислений с помощью формул, а вторые необходимо прогнозировать и объяснять, иначе не получится изменять их так, как нужно для решения различных задач. Корреляционно-регрессионный анализ позволяет обнаружить скрытые зависимости и представить их в виде математических выражений. Цели, для которых используются формулы:
С помощью аналитики выводят коэффициент корреляции, который означает силу связей. Чем она существеннее, тем легче создать регрессионную модель. В статистике этот метод является основным. Этапы регрессионного анализа располагаются в таком порядке:
- собирают данные;
- подвергают их предварительной обработке;
- выбирают вид уравнения;
- рассчитывают коэффициент;
- строят функцию;
- проверяют правильность расчётом с помощью наблюдений.
Метод проведения
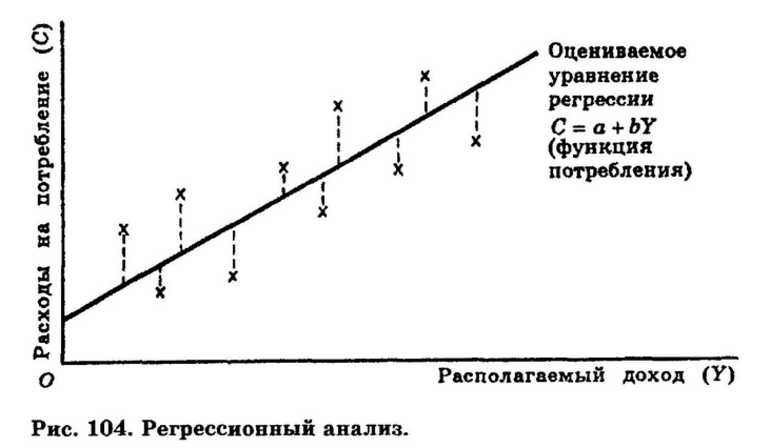
В теории описать уравнение регрессии можно только при условии, что известен закон, по которому распределяются результативные значения функции y при заданных параметрах аргумента x. На практике учёные не располагают знанием такой закономерности, поэтому приходится подбирать подходящие варианты аппроксимаций (близких значений) для неизвестной функции.
Взаимоотношение между истинной функцией, модельной регрессией и её оценкой можно рассмотреть на примере. Для этого нужно сделать допущение. Пусть показатель и аргумент связаны следующим образом: у=2х 1,5+o. В этой формуле o представляет собой случайное значение величины, распределяемой в соответствии с нормальным законом. Необходимо сделать ещё 2 допущения: d o- o 2 и M o= 0.
Тогда уравнение, описывающее функцию регрессии, примет такой вид: f (х) = М (у/х) = 2х i 1,5+ o. Чтобы при наличии исходных данных получить максимально точные значения функции регрессии и результирующего показателя, используют метод наименьших квадратов. При вычислениях минимизируют квадрат величины, на которую результативное значение отклоняется от модельного. Получают такое выражение: o (y i) — f (х i)2 > min. Это среднеквадратичная регрессия.
Дальнейшие действия проводят с использованием метода наименьших модулей. Получают следующее выражение: y-f (xj) — min. Оно описывает медианную регрессию.
Работа в таблицах Ms Excel
В информатике анализ данных позволяет разрабатывать и исследовать алгоритмы и методы, с помощью которых добывается информация из сведений, полученных экспериментальным путём. Исследования удобно проводить в Ms Excel, однако нужно учитывать, что работать в режиме онлайн с этим приложением не получится. Средства, которые можно использовать для анализа с помощью этого инструмента:
- построение сводных таблиц;
- объединение данных;
- частичное и полное суммирование;
- подведение итогов в автоматическом режиме;
- структуризация данных, представленных на отдельных листах;
- проверка значений в книгах и листах на ошибки;
- применение карт;
- создание диаграмм;
- обработка значений с использованием функций и формул;
- выборочный анализ разными способами, включая сценарии, поиск решения, выбор параметра и другие.
Инструменты, встроенные в Microsoft Excel, позволяют решать инженерные и статистические задачи высокого уровня сложности. Чтобы выполнить анализ, указывают входные данные и задают нужные параметры. Программа анализирует значения, применяя ту макрофункцию, которая подходит в этой ситуации. Результаты отображаются в специальных ячейках. Затем, применяя другие инструменты, данные можно вывести в виде графиков или диаграмм.
Графический вид удобен тем, что позволяет быстро обнаружить ошибки: они отображаются как нетипичные отклонения кривых. В таблицах найти неточности бывает сложно, так как списки бывают довольно большими. Кроме того, графики дают возможность не только проиллюстрировать информацию, но и проконтролировать корректность исходных данных. В некоторых случаях только графическое отображение позволяет правильно интерпретировать, обобщить и проанализировать информацию.
Множественный анализ

Общее назначение этого метода состоит в том, чтобы определить, как изменяется зависимая переменная, когда на неё воздействуют несколько факторов. Это легко понять на примере. Цена товара изменяется, подвергаясь влиянию ряда индикаторов. В виде равенства это можно представить так: изменение цены = a * RSI + b * MACD + с. Выражение будет корректным только в том случае, если между независимым и зависимыми значениями есть корреляция.
Компоненты выражения связаны между собой, поэтому при удалении одного значение остальных может измениться. Коэффициенты a и b применяются для демонстрации вклада каждого независимого значения.
Уравнение показывает, как взаимодействуют его части в идеале. На практике реальные показатели отличаются от прогнозируемых, а разницу между ними именуют остатком. С помощью множественного анализа исследуют количественные показатели, причём их может быть сколько угодно. Для определения и изучения качественных значений, у которых нет переходных параметров, применяют другие инструменты.
Этапы и виды
Множественный анализ выполняют в несколько этапов. Сначала формулируют задачу и разрабатывают гипотезы с учётом специфики анализируемых явлений. Дальнейшая работа ведётся в таком порядке:

- Определяют объясняющие и зависимые переменные.
- Собирают статистическую информацию отдельно для каждого компонента, участвующего в анализе.
- Формулируют гипотезу, допускающую, какой будет связь: линейной, множественной, простой, нелинейной.
- Рассчитывают числовые значения для тех компонентов уравнения, относительно которых это возможно.
- Оценивают степень точности анализа.
- Выполняют интерпретацию результатов и сравнивают их с гипотезой. Оценивают, насколько полученные значения являются правдоподобными и корректными.
- Прогнозируют, какие значения может принимать зависимый компонент.
Метод регрессионного анализа позволяет не только прогнозировать величины, но и классифицировать их. Предполагаемые значения вычисляются так: в уравнение на место независимых переменных подставляются числовые параметры, которые заведомо известны.
Классификация результатов
Для классификации результатов проводят линию регрессии. Она разделяет множество на 2 части: в одной находятся значения, которые больше нуля, в другой — меньше. Так данные на шкале распределяются по 2 классам. В свою очередь, регрессия подразделяется на несколько видов:
- Парная. Так называется регрессия, в которой, наряду с незначимыми, есть доминирующий фактор x. Пример регрессионного анализа: в каждом регионе есть некоторое количество занятых людей (x) и собирается некоторая сумма налогов (y). Y зависит от доминирующего компонента x. Присутствуют и другие факторы, но их значимость гораздо ниже.
- Обратная. Она заключается в том, что сначала составляют максимально полное уравнение, а затем последовательно исключают из него отдельные члены, каждый раз оценивая, насколько уменьшилась остаточная дисперсия. В итоговом уравнении останутся только те компоненты, которые оказали наиболее весомый вклад на её уменьшение.
- Нелинейная. Этот вид анализа применяется, когда зависимость одной переменной от других не является линейной. Пример: засолённость почвы до определённого предела не оказывает влияния на урожайность культур. После достижения определённых значений это влияние начинает проявляться нелинейно. Зависимость можно представить в виде функции. Их существует несколько видов: показательные, логарифмические, тригонометрические, степенные, гауссова и кривые Лоренца.
- Множественная. Бывает необходима, когда нужно рассчитать влияние множества независимых переменных на результативный признак. При этом присутствует фактор E — стохастический параметр, включающий влияние неучтённых компонентов.
- Линейная. Используется для анализа эластичности спроса, прогнозирования загруженности веб-сервисов, стоимости ценных бумаг, объёмов продаж и т. д.
- Логарифмически линейная. Применяется при моделировании реальных социально-экономических процессов, которые невозможно описать через линейную функцию.
- Гиперболическая. Она имеет вид у=b+а/х. В экономике её применяют для выявления зависимости объёма выпускаемой продукции от затрат топлива, сырья и материалов, а также для других целей. Классический пример — кривая Филлипса. График оказывает связь между приростом заработной платы и уровнем безработицы.
Регрессионный анализ позволяет с максимальной эффективностью и наименьшими усилиями использовать накопленный теоретико-прикладной потенциал, выдвигать и обосновывать идеи, ставить и решать задачи.
Регрессионный анализ — статистический метод исследования зависимости случайной величины от переменных
В статистическом моделировании регрессионный анализ представляет собой исследования, применяемые с целью оценки взаимосвязи между переменными. Этот математический метод включает в себя множество других методов для моделирования и анализа нескольких переменных, когда основное внимание уделяется взаимосвязи между зависимой переменной и одной или несколькими независимыми. Говоря более конкретно, регрессионный анализ помогает понять, как меняется типичное значение зависимой переменной, если одна из независимых переменных изменяется, в то время как другие независимые переменные остаются фиксированными.

Во всех случаях целевая оценка является функцией независимых переменных и называется функцией регрессии. В регрессионном анализе также представляет интерес характеристика изменения зависимой переменной как функции регрессии, которая может быть описана с помощью распределения вероятностей.
Задачи регрессионного анализа
Данный статистический метод исследования широко используется для прогнозирования, где его использование имеет существенное преимущество, но иногда это может приводить к иллюзии или ложным отношениям, поэтому рекомендуется аккуратно его использовать в указанном вопросе, поскольку, например, корреляция не означает причинно-следственной связи.
Разработано большое число методов для проведения регрессионного анализа, такие как линейная и обычная регрессии по методу наименьших квадратов, которые являются параметрическими. Их суть в том, что функция регрессии определяется в терминах конечного числа неизвестных параметров, которые оцениваются из данных. Непараметрическая регрессия позволяет ее функции лежать в определенном наборе функций, которые могут быть бесконечномерными.
Как статистический метод исследования, регрессионный анализ на практике зависит от формы процесса генерации данных и от того, как он относится к регрессионному подходу. Так как истинная форма процесса данных, генерирующих, как правило, неизвестное число, регрессионный анализ данных часто зависит в некоторой степени от предположений об этом процессе. Эти предположения иногда проверяемы, если имеется достаточное количество доступных данных. Регрессионные модели часто бывают полезны даже тогда, когда предположения умеренно нарушены, хотя они не могут работать с максимальной эффективностью.
В более узком смысле регрессия может относиться конкретно к оценке непрерывных переменных отклика, в отличие от дискретных переменных отклика, используемых в классификации. Случай непрерывной выходной переменной также называют метрической регрессией, чтобы отличить его от связанных с этим проблем.
История
Самая ранняя форма регрессии — это всем известный метод наименьших квадратов. Он был опубликован Лежандром в 1805 году и Гауссом в 1809. Лежандр и Гаусс применили метод к задаче определения из астрономических наблюдений орбиты тел вокруг Солнца (в основном кометы, но позже и вновь открытые малые планеты). Гаусс опубликовал дальнейшее развитие теории наименьших квадратов в 1821 году, включая вариант теоремы Гаусса-Маркова.

Термин «регресс» придумал Фрэнсис Гальтон в XIX веке, чтобы описать биологическое явление. Суть была в том, что рост потомков от роста предков, как правило, регрессирует вниз к нормальному среднему. Для Гальтона регрессия имела только этот биологический смысл, но позже его работа была продолжена Удни Йолей и Карлом Пирсоном и выведена к более общему статистическому контексту. В работе Йоля и Пирсона совместное распределение переменных отклика и пояснительных считается гауссовым. Это предположение было отвергнуто Фишером в работах 1922 и 1925 годов. Фишер предположил, что условное распределение переменной отклика является гауссовым, но совместное распределение не должны быть таковым. В связи с этим предположение Фишера ближе к формулировке Гаусса 1821 года. До 1970 года иногда уходило до 24 часов, чтобы получить результат регрессионного анализа.

Методы регрессионного анализа продолжают оставаться областью активных исследований. В последние десятилетия новые методы были разработаны для надежной регрессии; регрессии с участием коррелирующих откликов; методы регрессии, вмещающие различные типы недостающих данных; непараметрической регрессии; байесовские методов регрессии; регрессии, в которых переменные прогнозирующих измеряются с ошибкой; регрессии с большей частью предикторов, чем наблюдений, а также причинно-следственных умозаключений с регрессией.
Регрессионные модели
Модели регрессионного анализа включают следующие переменные:
- Неизвестные параметры, обозначенные как бета, которые могут представлять собой скаляр или вектор.
- Независимые переменные, X.
- Зависимые переменные, Y.
В различных областях науки, где осуществляется применение регрессионного анализа, используются различные термины вместо зависимых и независимых переменных, но во всех случаях регрессионная модель относит Y к функции X и β.
Приближение обычно оформляется в виде E (Y | X) = F (X, β). Для проведения регрессионного анализа должен быть определен вид функции f. Реже она основана на знаниях о взаимосвязи между Y и X, которые не полагаются на данные. Если такое знание недоступно, то выбрана гибкая или удобная форма F.
Зависимая переменная Y
Предположим теперь, что вектор неизвестных параметров β имеет длину k. Для выполнения регрессионного анализа пользователь должен предоставить информацию о зависимой переменной Y:
- Если наблюдаются точки N данных вида (Y, X), где N точки к данным. В этом случае имеется достаточно информации в данных, чтобы оценить уникальное значение для β, которое наилучшим образом соответствует данным, и модель регрессии, когда применение к данным можно рассматривать как переопределенную систему в β.
В последнем случае регрессионный анализ предоставляет инструменты для:
- Поиска решения для неизвестных параметров β, которые будут, например, минимизировать расстояние между измеренным и предсказанным значением Y.
- При определенных статистических предположениях, регрессионный анализ использует избыток информации для предоставления статистической информации о неизвестных параметрах β и предсказанные значения зависимой переменной Y.
Необходимое количество независимых измерений
Рассмотрим модель регрессии, которая имеет три неизвестных параметра: β0, β1 и β2. Предположим, что экспериментатор выполняет 10 измерений в одном и том же значении независимой переменной вектора X. В этом случае регрессионный анализ не дает уникальный набор значений. Лучшее, что можно сделать, оценить среднее значение и стандартное отклонение зависимой переменной Y. Аналогичным образом измеряя два различных значениях X, можно получить достаточно данных для регрессии с двумя неизвестными, но не для трех и более неизвестных.

Если измерения экспериментатора проводились при трех различных значениях независимой переменной вектора X, то регрессионный анализ обеспечит уникальный набор оценок для трех неизвестных параметров в β.
В случае общей линейной регрессии приведенное выше утверждение эквивалентно требованию, что матрица X Т X обратима.
Статистические допущения
Когда число измерений N больше, чем число неизвестных параметров k и погрешности измерений εi, то, как правило, распространяется затем избыток информации, содержащейся в измерениях, и используется для статистических прогнозов относительно неизвестных параметров. Этот избыток информации называется степенью свободы регрессии.
Основополагающие допущения
Классические предположения для регрессионного анализа включают в себя:
- Выборка является представителем прогнозирования логического вывода.
- Ошибка является случайной величиной со средним значением нуля, который является условным на объясняющих переменных.
- Независимые переменные измеряются без ошибок.
- В качестве независимых переменных (предикторов) они линейно независимы, то есть не представляется возможным выразить любой предсказатель в виде линейной комбинации остальных.
- Ошибки являются некоррелированными, то есть ковариационная матрица ошибок диагоналей и каждый ненулевой элемент являются дисперсией ошибки.
- Дисперсия ошибки постоянна по наблюдениям (гомоскедастичности). Если нет, то можно использовать метод взвешенных наименьших квадратов или другие методы.
Эти достаточные условия для оценки наименьших квадратов обладают требуемыми свойствами, в частности эти предположения означают, что оценки параметров будут объективными, последовательными и эффективными, в особенности при их учете в классе линейных оценок. Важно отметить, что фактические данные редко удовлетворяют условиям. То есть метод используется, даже если предположения не верны. Вариация из предположений иногда может быть использована в качестве меры, показывающей, насколько эта модель является полезной. Многие из этих допущений могут быть смягчены в более продвинутых методах. Отчеты статистического анализа, как правило, включают в себя анализ тестов по данным выборки и методологии для полезности модели.
Кроме того, переменные в некоторых случаях ссылаются на значения, измеренные в точечных местах. Там могут быть пространственные тенденции и пространственные автокорреляции в переменных, нарушающие статистические предположения. Географическая взвешенная регрессия — единственный метод, который имеет дело с такими данными.
Линейный регрессионный анализ
В линейной регрессии особенностью является то, что зависимая переменная, которой является Yi, представляет собой линейную комбинацию параметров. Например, в простой линейной регрессии для моделирования n-точек используется одна независимая переменная, xi, и два параметра, β0 и β1.
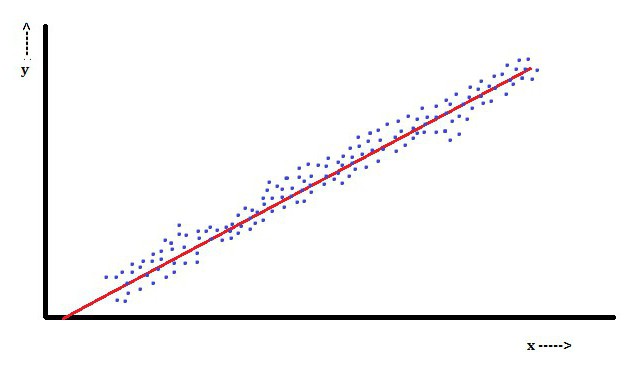
При множественной линейной регрессии существует несколько независимых переменных или их функций.
При случайной выборке из популяции ее параметры позволяют получить образец модели линейной регрессии.
В данном аспекте популярнейшим является метод наименьших квадратов. С помощью него получают оценки параметров, которые минимизируют сумму квадратов остатков. Такого рода минимизация (что характерно именно линейной регрессии) этой функции приводит к набору нормальных уравнений и набору линейных уравнений с параметрами, которые решаются с получением оценок параметров.
При дальнейшем предположении, что ошибка популяции обычно распространяется, исследователь может использовать эти оценки стандартных ошибок для создания доверительных интервалов и проведения проверки гипотез о ее параметрах.
Нелинейный регрессионный анализ
Пример, когда функция не является линейной относительно параметров, указывает на то, что сумма квадратов должна быть сведена к минимуму с помощью итерационной процедуры. Это вносит много осложнений, которые определяют различия между линейными и нелинейными методами наименьших квадратов. Следовательно, и результаты регрессионного анализа при использовании нелинейного метода порой непредсказуемы.
Расчет мощности и объема выборки
Здесь, как правило, нет согласованных методов, касающихся числа наблюдений по сравнению с числом независимых переменных в модели. Первое правило было предложено Доброй и Хардином и выглядит как N = t^n, где N является размер выборки, n — число независимых переменных, а t есть числом наблюдений, необходимых для достижения желаемой точности, если модель имела только одну независимую переменную. Например, исследователь строит модель линейной регрессии с использованием набора данных, который содержит 1000 пациентов (N). Если исследователь решает, что необходимо пять наблюдений, чтобы точно определить прямую (м), то максимальное число независимых переменных, которые модель может поддерживать, равно 4.
Другие методы
Несмотря на то что параметры регрессионной модели, как правило, оцениваются с использованием метода наименьших квадратов, существуют и другие методы, которые используются гораздо реже. К примеру, это следующие методы:
- Байесовские методы (например, байесовский метод линейной регрессии).
- Процентная регрессия, использующаяся для ситуаций, когда снижение процентных ошибок считается более целесообразным.
- Наименьшие абсолютные отклонения, что является более устойчивым в присутствии выбросов, приводящих к квантильной регрессии.
- Непараметрическая регрессия, требующая большого количества наблюдений и вычислений.
- Расстояние метрики обучения, которая изучается в поисках значимого расстояния метрики в заданном входном пространстве.
Программное обеспечение
Все основные статистические пакеты программного обеспечения выполняются с помощью наименьших квадратов регрессионного анализа. Простая линейная регрессия и множественный регрессионный анализ могут быть использованы в некоторых приложениях электронных таблиц, а также на некоторых калькуляторах. Хотя многие статистические пакеты программного обеспечения могут выполнять различные типы непараметрической и надежной регрессии, эти методы менее стандартизированы; различные программные пакеты реализуют различные методы. Специализированное регрессионное программное обеспечение было разработано для использования в таких областях как анализ обследования и нейровизуализации.
http://nauka.club/matematika/algebra/regressionnyi-analiz.html
http://businessman.ru/new-regressionnyj-analiz-statisticheskij-metod-issledovaniya-zavisimosti-sluchajnoj-velichiny-ot-peremennyx.html