Уравнение регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
В сервисе для нахождения параметров регрессии используется МНК. Система нормальных уравнений для линейной регрессии: 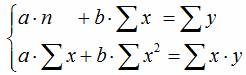 . Также можно получить ответ, используя матричный метод. см. также Статистические функции в Excel
. Также можно получить ответ, используя матричный метод. см. также Статистические функции в Excel
Уравнение парной регрессии относится к уравнению регрессии первого порядка. Если эконометрическая модель содержит только одну объясняющую переменную, то она имеет название парной регрессии. Уравнение регрессии второго порядка и уравнение регрессии третьего порядка относятся к нелинейным уравнениям регрессии.
Пример . Осуществите выбор зависимой (объясняемой) и объясняющей переменной для построения парной регрессионной модели. Дайте графическое изображение регрессионной зависимости. Определите теоретическое уравнение парной регрессии. Оцените адекватность построенной модели (интерпретируйте R-квадрат, показатели t-статистики, F-статистики).
Решение будем проводить на основе процесса эконометрического моделирования.
1-й этап (постановочный) – определение конечных целей моделирования, набора участвующих в модели факторов и показателей, их роли.
Спецификация модели — определение цели исследования и выбор экономических переменных модели.
Ситуационная (практическая) задача. По 10 предприятиям региона изучается зависимость выработки продукции на одного работника y (тыс. руб.) от удельного веса рабочих высокой квалификации в общей численности рабочих x (в %).
2-й этап (априорный) – предмодельный анализ экономической сущности изучаемого явления, формирование и формализация априорной информации и исходных допущений, в частности относящейся к природе и генезису исходных статистических данных и случайных остаточных составляющих в виде ряда гипотез.
Уже на этом этапе можно говорить о явной зависимости уровня квалификации рабочего и его выработкой, ведь чем опытней работник, тем выше его производительность. Но как эту зависимость оценить?
Парная регрессия представляет собой регрессию между двумя переменными – y и x , т. е. модель вида:
Парная линейная регрессия. Задачи регрессионного анализа
Будут и задачи для самостоятельного решения, к которым можно посмотреть ответы.
Понятие линейной регрессии. Парная линейная регрессия
Линейная регрессия — выраженная в виде прямой зависимость среднего значения какой-либо величины от некоторой другой величины. В отличие от функциональной зависимости y = f(x) , когда каждому значению независимой переменной x соответствует одно определённое значение величины y, при линейной регрессии одному и тому же значению x могут соответствовать в зависимости от случая различные значения величины y.
Если в результате наблюдения установлено, что при каждом определённом значении x существует сколько-то (n) значений переменной y, то зависимость средних арифметических значений y от x и является регрессией в статистическом понимании.
Если установленная зависимость может быть записана в виде уравнения прямой
то эта регрессионная зависимость называется линейной регрессией.
О парной линейной регрессии говорят, когда установлена зависимость между двумя переменными величинами (x и y). Парная линейная регрессия называется также однофакторной линейной регрессией, так как один фактор (независимая переменная x) влияет на результирующую переменную (зависимую переменную y).
В уроке о корреляционной зависимости были разобраны примеры того, как цена на квартиры зависит от общей площади квартиры и от площади кухни (две различные независимые переменные) и о том, что результаты наблюдений расположены в некотором приближении к прямой, хотя и не на самой прямой. Если точки корреляционной диаграммы соединить ломанной линией, то будет получена линия эмпирической регрессии. А если эта линия будет выровнена в прямую, то полученная прямая будет прямой теоретической регрессии. На рисунке ниже она красного цвета (для увеличения рисунка щёлкнуть по нему левой кнопкой мыши).

По этой прямой теоретической регрессии может быть сделан прогноз или восстановление неизвестных значений зависимой переменной по заданным значениям независимой переменной.
В случае парной линейной регрессии для данных генеральной совокупности связь между независимой переменной (факториальным признаком) X и зависимой переменной (результативным признаком) Y описывает модель
 ,
,
 — свободный член прямой парной линейной регрессии,
— свободный член прямой парной линейной регрессии,
 — коэффициент направления прямой парной линейной регрессии,
— коэффициент направления прямой парной линейной регрессии,
 — случайная погрешность,
— случайная погрешность,
N — число элементов генеральной совокупности.
Уравнение парной линейной регрессии для генеральной совокупности можно построить, если доступны данные обо всех элементах генеральной совокупности. На практике данные всей генеральной совокупности недоступны, но доступны данные об элементах некоторой выборки.
Поэтому параметры генеральной совокупности оценивают при помощи соответствующих параметров соответствующей выборки: свободный член прямой парной линейной регрессии генеральной совокупности заменяют на свободный член прямой парной линейной регрессии выборки  , а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки
, а коэффициент направления прямой парной линейной регрессии генеральной совокупности — на коэффициент направления прямой парной линейной регрессии выборки  .
.
В результате получаем уравнение парной линейной регрессии выборки


 — оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
— оценка полученной с помощью модели линейной регрессии зависимой переменной Y,
 — погрешность,
— погрешность,
n — размер выборки.
Чтобы уравнение парной линейной регрессии было более похоже на привычное уравнение прямой, его часто также записывают в виде
 .
.
Уравнение парной линейной регрессии и метод наименьших квадратов
Определение коэффициентов уравнения парной линейной регрессии
Если заранее известно, что зависимость между факториальным признаком x и результативным признаком y должна быть линейной, выражающейся в виде уравнения типа , задача сводится к нахождению по некоторой группе точек наилучшей прямой, называемой прямой парной линейной регрессии. Следует найти такие значения коэффициентов a и b , чтобы сумма квадратов отклонений  была наименьшей:
была наименьшей:
 .
.
Если через  и
и  обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
обозначить средние значения признаков X и Y,то полученная с помощью метода наименьших квадратов функция регрессии удовлетворяет следующим условиям:
- прямая парной линейной регрессии проходит через точку
 ;
; - среднее значение отклонений равна нулю: ;
- значения и не связаны: .
 ;
; ;
; и
и  не связаны:
не связаны:  .
.Условие метода наименьших квадратов выполняется, если значения коэффициентов равны:
 ,
,
 .
.
Пример 1. Найти уравнение парной линейной регрессии зависимости между валовым внутренним продуктом (ВВП) и частным потреблением на основе данных примера урока о корреляционной зависимости (эта ссылка, которая откроется в новом окне, потребуется и при разборе следующих примеров).
Решение. Используем рассчитанные в решении названного выше примера суммы:




Используя эти суммы, вычислим коэффициенты:


Таким образом получили уравнение прямой парной линейной регрессии:

Составить уравнение парной линейной регрессии самостоятельно, а затем посмотреть решение
Пример 2. Найти уравнение парной линейной регрессии для выборки из 6 наблюдений, если уже вычислены следующие промежуточные результаты:
 ;
;
 ;
;
 ;
;
 ;
;
Анализ качества модели линейной регрессии
Метод наименьших квадратов имеет по меньшей мере один существенный недостаток: с его помощью можно найти уравнение линейной регрессии и в тех случаях, когда данные наблюдений значительно рассеяны вокруг прямой регрессии, то есть находятся на значительном расстоянии от этой прямой. В таких случаях за точность прогноза значений зависимой переменной ручаться нельзя. Существуют показатели, которые позволяют оценить качество уравнения линейной регрессии прежде чем использовать модели линейной регрессии для практических целей. Разберём важнейшие из этих показателей.
Коэффициент детерминации
Коэффициент детерминации  принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
принимает значения от 0 до 1 и в случае качественной модели линейной регрессии стремится к единице. Коэффициент детерминации показывает, какую часть общего рассеяния зависимой переменной объясняет независимая переменная:
 ,
,
 — сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
— сумма квадратов отклонений, объясняемых моделью линейной регрессии, которая характеризует рассеяние точек прямой регрессии относительно арифметического среднего,
 — общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
— общая сумма квадратов отклонений, которая характеризует рассеяние зависимой переменной Y относительно арифметического среднего,
 — сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
— сумма квадратов отклонений ошибки (не объясняемых моделью линейной регрессии), которая характеризует рассеяние зависимой переменной Y относительно прямой регресии.
Пример 3. Даны сумма квадратов отклонений, объясняемых моделью линейной регрессии (3500), общая сумма квадратов отклонений (5000) и сумма квадратов отклонений ошибки (1500). Найти коэффициент детерминации двумя способами.
F-статистика (статистика Фишера) для проверки качества модели линейной регрессии
Минимальное возможное значение F-статистики — 0. Чем выше значение статистики Фишера, тем качественнее модель линейной регрессии. Этот показатель представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы):

где m — число объясняющих переменных.
Сумма квадратов остатков
Сумма квадратов остатков (RSS) измеряет необъясненную часть дисперсии зависимой переменной:

 —
—
остатки — разности между реальными значениями зависимой переменной и значениями, оценёнными уравнением линейной регрессии.
В случае качественной модели линейной регрессии сумма квадратов остатков стремится к нулю.
Стандартная ошибка регрессии
Стандартная ошибка регрессии (SEE) измеряет величину квадрата ошибки, приходящейся на одну степень свободы модели:

Чем меньше значение SEE, тем качественнее модель.
Пример 4. Рассчитать коэффициент детерминации для данных из примера 1.
Решение. На основании данных таблицы (она была приведена в примере урока о корреляционной зависимости) получаем, что SST = 63 770,593 , SSE = 10 459,587 , SSR = 53 311,007 .
Можем убедиться, что выполняется закономерность SSR = SST — SSE :
Получаем коэффициент детерминации:
 .
.
Таким образом, 83,6% изменений частного потребления можно объяснить моделью линейной регресии.
Интерпретация коэффициентов уравнения парной линейной регрессии и прогноз значений зависимой переменной
Итак, уравнение парной линейной регрессии:
 .
.
В этом уравнении a — свободный член, b — коэффициент при независимой переменной.
Интерпретация свободного члена: a показывает, на сколько единиц график регрессии смещён вверх при x=0, то есть значение переменной y при нулевом значении переменной x.
Интерпретация коэффициента при независимой переменной: b показывает, на сколько единиц изменится значение зависимой переменной y при изменении x на одну единицу.
Пример 5. Зависимость частного потребления граждан от ВВП (истолкуем это просто: от дохода) описывается уравнением парной линейной регрессии  . Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
. Сделать прогноз потребления при доходе в 20 000 у.е. Выяснить, на сколько увеливается потребление при увеличении дохода на 5000 у.е. Меняется ли потребление, если доход не меняется?
Решение. Подставляем в уравнение парной линейной регрессии x i = 20000 и получаем прогноз потребления при доходе в 20 000 у.е. y i = 17036,4662 .
Подставляем в уравнение парной линейной регрессии x i = 5000 и получаем прогноз увеличения потребления при увеличении дохода на 5000 у.е. y i = 4161,9662 .
Если доход не меняется, то x i = 0 и получаем, что потребление уменьшается на 129,5338 у.е.
Задачи регрессионного анализа
Регрессионный анализ — раздел математической статистики, объединяющий практические методы исследования регрессионной зависимости между величинами по статистическим данным.
Наиболее частые задачи регрессионного анализа:
- установление факта наличия или отсутствия статистических зависимостей между переменными величинами;
- выявление причинных связей между переменными величинами;
- прогноз или восстановление неизвестных значений зависимых переменных по заданным значениям независимых переменных.
Также делаются проверки статистических гипотез о регрессии. Кроме того, при изучении связи между двумя величинами по результатам наблюдений в соответствии с теорией регрессии предполагается, что зависимая переменная имеет некоторое распределение вероятностей при фиксированном значении независимой переменной.
В исследованиях поведения человека, чтобы они претендовали на объективность, важно не только установить зависимость между факторами, но и получить все необходимые статистические показатели для результата проверки соответствующей гипотезы.
Проверка гипотезы о равенстве нулю коэффициента направления прямой парной линейной регрессии
Одна из важнейших гипотез в регрессионном анализе — гипотеза о том, что коэффициент направления прямой регрессии генеральной совокупности равен нулю.
Если это предположение верно, то изменения независимой переменной X не влияют на изменения зависимой переменной Y: переменные X и Y не коррелированы, то есть линейной зависимости Y от X нет.

рассматривают во взаимосвязи с альтернативной гипотезой
 .
.
Статистика коэффициента направления

соответствует распределению Стьюдента с числом степеней свободы v = n — 2 ,
где  — стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
— стандартная погрешность коэффициента направления прямой линейной регресии b 1 .
Доверительный интервал коэффициента направления прямой линейной регрессии:
 .
.
Критическая область, в которой с вероятностью P = 1 — α отвергают нулевую гипотезу и принимают альтернативную гипотезу:

Пример 6. На основе данных из предыдущих примеров (о ВВП и частном потреблении) определить доверительный интервал коэффициента направления прямой линейной регресии 95% и проверить гипотезу о равенстве нулю коэффициента направления прямой парной линейной регрессии.
Можем рассчитать, что  , а стандартная погрешность регрессии
, а стандартная погрешность регрессии  .
.
Таким образом, стандартная погрешность коэффициента направления прямой линейной регресии b 1 :
 .
.
Так как  и
и  (находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
(находим по таблице в приложениях к учебникам по статистике), то доверительный интервал 95% коэффициента направления прямой парной линейной регрессии:
 .
.
Так как гипотетическое значение коэффициента — нуль — не принадлежит доверительному интервалу, с вероятностью 95% можем отвергнуть основную гипотезу и принять альтернативную гипотезу, то есть считать, что зависимая переменная Y линейно зависит от независимой переменной X.
Решаем уравнение простой линейной регрессии
В статье рассматривается несколько способов определения математического уравнения линии простой (парной) регрессии.
Все рассматриваемые здесь способы решения уравнения основаны на методе наименьших квадратов. Обозначим способы следующим образом:
- Аналитическое решение
- Градиентный спуск
- Стохастический градиентный спуск
Для каждого из способов решения уравнения прямой, в статье приведены различные функции, которые в основном делятся на те, которые написаны без использования библиотеки NumPy и те, которые для проведения расчетов применяют NumPy. Считается, что умелое использование NumPy позволит сократить затраты на вычисления.
Весь код, приведенный в статье, написан на языке python 2.7 с использованием Jupyter Notebook. Исходный код и файл с данными выборки выложен на гитхабе
Статья в большей степени ориентирована как на начинающих, так и на тех, кто уже понемногу начал осваивать изучение весьма обширного раздела в искусственном интеллекте — машинного обучения.
Для иллюстрации материала используем очень простой пример.
Условия примера
У нас есть пять значений, которые характеризуют зависимость Y от X (Таблица №1):
Таблица №1 «Условия примера»

Будем считать, что значения  — это месяц года, а
— это месяц года, а  — выручка в этом месяце. Другими словами, выручка зависит от месяца года, а — единственный признак, от которого зависит выручка.
— выручка в этом месяце. Другими словами, выручка зависит от месяца года, а — единственный признак, от которого зависит выручка.
Пример так себе, как с точки зрения условной зависимости выручки от месяца года, так и с точки зрения количества значений — их очень мало. Однако такое упрощение позволит, что называется на пальцах, объяснить, не всегда с легкостью, усваиваемый новичками материал. А также простота чисел позволит без весомых трудозатрат, желающим, порешать пример на «бумаге».
Предположим, что приведенная в примере зависимость, может быть достаточно хорошо аппроксимирована математическим уравнением линии простой (парной) регрессии вида:

где  — это месяц, в котором была получена выручка,
— это месяц, в котором была получена выручка,  — выручка, соответствующая месяцу,
— выручка, соответствующая месяцу,  и
и  — коэффициенты регрессии оцененной линии.
— коэффициенты регрессии оцененной линии.
Отметим, что коэффициент часто называют угловым коэффициентом или градиентом оцененной линии; представляет собой величину, на которую изменится при изменении .
Очевидно, что наша задача в примере — подобрать в уравнении такие коэффициенты и , при которых отклонения наших расчетных значений выручки по месяцам от истинных ответов, т.е. значений, представленных в выборке, будут минимальны.
Метод наименьших квадратов
В соответствии с методом наименьших квадратов, отклонение стоит рассчитывать, возводя его в квадрат. Подобный прием позволяет избежать взаимного погашения отклонений, в том случае, если они имеют противоположные знаки. Например, если в одном случае, отклонение составляет +5 (плюс пять), а в другом -5 (минус пять), то сумма отклонений взаимно погасится и составит 0 (ноль). Можно и не возводить отклонение в квадрат, а воспользоваться свойством модуля и тогда у нас все отклонения будут положительными и будут накапливаться. Мы не будем останавливаться на этом моменте подробно, а просто обозначим, что для удобства расчетов, принято возводить отклонение в квадрат.
Вот так выглядит формула, с помощью которой мы определим наименьшую сумму квадратов отклонений (ошибки):

где  — это функция аппроксимации истинных ответов (то есть посчитанная нами выручка),
— это функция аппроксимации истинных ответов (то есть посчитанная нами выручка),
— это истинные ответы (предоставленная в выборке выручка),
 — это индекс выборки (номер месяца, в котором происходит определение отклонения)
— это индекс выборки (номер месяца, в котором происходит определение отклонения)
Продифференцируем функцию, определим уравнения частных производных и будем готовы перейти к аналитическому решению. Но для начала проведем небольшой экскурс о том, что такое дифференцирование и вспомним геометрический смысл производной.
Дифференцирование
Дифференцированием называется операция по нахождению производной функции.
Для чего нужна производная? Производная функции характеризует скорость изменения функции и указывает нам ее направление. Если производная в заданной точке положительна, то функция возрастает, в обратном случае — функция убывает. И чем больше значение производной по модулю, тем выше скорость изменения значений функции, а также круче угол наклона графика функции.
Например, в условиях декартовой системы координат, значение производной в точке M(0,0) равное +25 означает, что в заданной точке, при смещении значения вправо на условную единицу, значение  возрастает на 25 условных единиц. На графике это выглядит, как достаточно крутой угол подъема значений с заданной точки.
возрастает на 25 условных единиц. На графике это выглядит, как достаточно крутой угол подъема значений с заданной точки.
Другой пример. Значение производной равное -0,1 означает, что при смещении на одну условную единицу, значение убывает всего лишь на 0,1 условную единицу. При этом, на графике функции, мы можем наблюдать едва заметный наклон вниз. Проводя аналогию с горой, то мы как будто очень медленно спускаемся по пологому склону с горы, в отличие от предыдущего примера, где нам приходилось брать очень крутые вершины:)
Таким образом, проведя дифференцирование функции  по коэффициентам и , определим уравнения частных производных 1-го порядка. После определения уравнений, мы получим систему из двух уравнений, решив которую мы сможем подобрать такие значения коэффициентов и , при которых значения соответствующих производных в заданных точках изменяются на очень и очень малую величину, а в случае с аналитическим решением не изменяются вовсе. Другими словами, функция ошибки при найденных коэффициентах достигнет минимума, так как значения частных производных в этих точках будут равны нулю.
по коэффициентам и , определим уравнения частных производных 1-го порядка. После определения уравнений, мы получим систему из двух уравнений, решив которую мы сможем подобрать такие значения коэффициентов и , при которых значения соответствующих производных в заданных точках изменяются на очень и очень малую величину, а в случае с аналитическим решением не изменяются вовсе. Другими словами, функция ошибки при найденных коэффициентах достигнет минимума, так как значения частных производных в этих точках будут равны нулю.
Итак, по правилам дифференцирования уравнение частной производной 1-го порядка по коэффициенту примет вид:

уравнение частной производной 1-го порядка по примет вид:

В итоге мы получили систему уравнений, которая имеет достаточно простое аналитическое решение:
\begin
\begin
na + b\sum\limits_
\\
\sum\limits_
\end
\end
Прежде чем решать уравнение, предварительно загрузим, проверим правильность загрузки и отформатируем данные.
Загрузка и форматирование данных
Необходимо отметить, что в связи с тем, что для аналитического решения, а в дальнейшем для градиентного и стохастического градиентного спуска, мы будем применять код в двух вариациях: с использованием библиотеки NumPy и без её использования, то нам потребуется соответствующее форматирование данных (см. код).
Визуализация
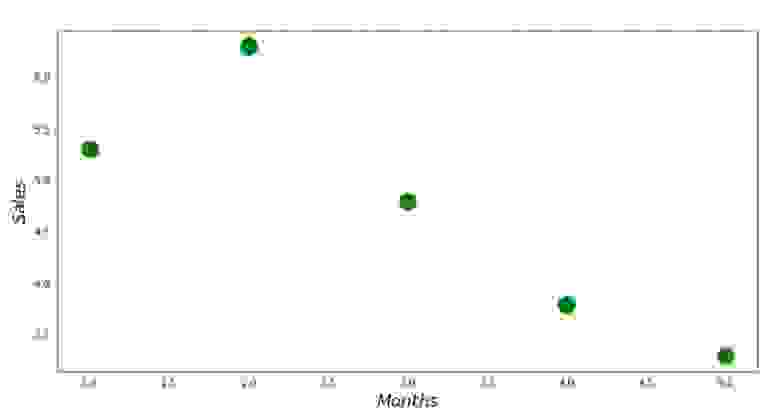
Теперь, после того, как мы, во-первых, загрузили данные, во-вторых, проверили правильность загрузки и наконец отформатировали данные, проведем первую визуализацию. Часто для этого используют метод pairplot библиотеки Seaborn. В нашем примере, ввиду ограниченности цифр нет смысла применять библиотеку Seaborn. Мы воспользуемся обычной библиотекой Matplotlib и посмотрим только на диаграмму рассеяния.
График №1 «Зависимость выручки от месяца года»
Аналитическое решение
Воспользуемся самыми обычными инструментами в python и решим систему уравнений:
\begin
\begin
na + b\sum\limits_
\\
\sum\limits_
\end
\end
По правилу Крамера найдем общий определитель, а также определители по и по , после чего, разделив определитель по на общий определитель — найдем коэффициент , аналогично найдем коэффициент .
Вот, что у нас получилось:

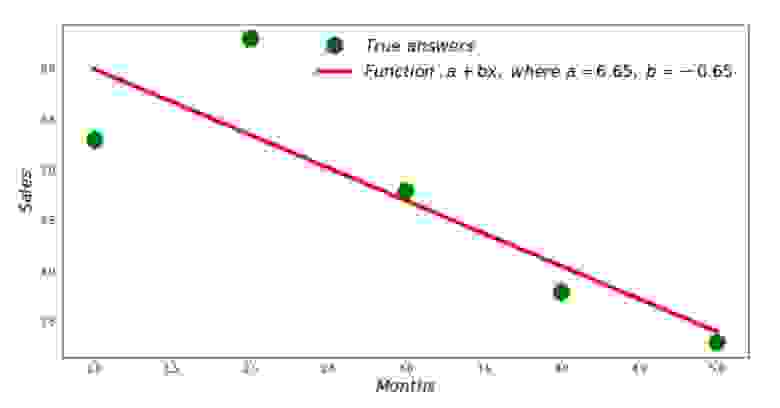
Итак, значения коэффициентов найдены, сумма квадратов отклонений установлена. Нарисуем на гистограмме рассеяния прямую линию в соответствии с найденными коэффициентами.
График №2 «Правильные и расчетные ответы»
Можно посмотреть на график отклонений за каждый месяц. В нашем случае, какой-либо значимой практической ценности мы из него не вынесем, но удовлетворим любопытство в том, насколько хорошо, уравнение простой линейной регрессии характеризует зависимость выручки от месяца года.
График №3 «Отклонения, %»
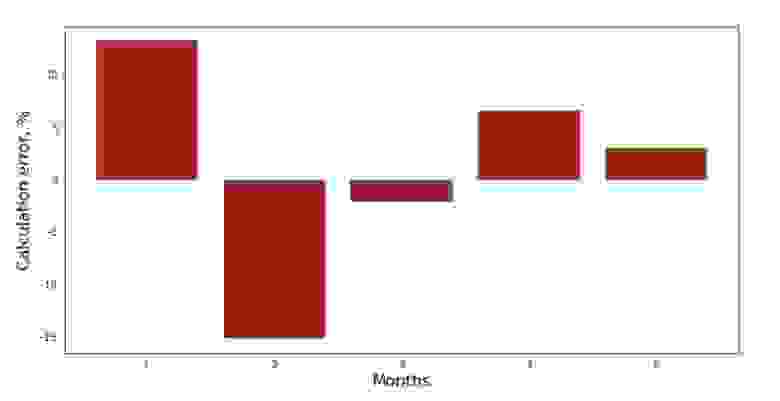
Не идеально, но нашу задачу мы выполнили.
Напишем функцию, которая для определения коэффициентов и использует библиотеку NumPy, точнее — напишем две функции: одну с использованием псевдообратной матрицы (не рекомендуется на практике, так как процесс вычислительно сложный и нестабильный), другую с использованием матричного уравнения.
Сравним время, которое было затрачено на определение коэффициентов и , в соответствии с 3-мя представленными способами.

На небольшом количестве данных, вперед выходит «самописная» функция, которая находит коэффициенты методом Крамера.
Теперь можно перейти к другим способам нахождения коэффициентов и .
Градиентный спуск
Для начала определим, что такое градиент. По-простому, градиент — это отрезок, который указывает направление максимального роста функции. По аналогии с подъемом в гору, то куда смотрит градиент, там и есть самый крутой подъем к вершине горы. Развивая пример с горой, вспоминаем, что на самом деле нам нужен самый крутой спуск, чтобы как можно быстрее достичь низины, то есть минимума — места где функция не возрастает и не убывает. В этом месте производная будет равна нулю. Следовательно, нам нужен не градиент, а антиградиент. Для нахождения антиградиента нужно всего лишь умножить градиент на -1 (минус один).
Обратим внимание на то, что функция может иметь несколько минимумов, и опустившись в один из них по предложенному далее алгоритму, мы не сможем найти другой минимум, который возможно находится ниже найденного. Расслабимся, нам это не грозит! В нашем случае мы имеем дело с единственным минимумом, так как наша функция  на графике представляет собой обычную параболу. А как мы все должны прекрасно знать из школьного курса математики — у параболы существует только один минимум.
на графике представляет собой обычную параболу. А как мы все должны прекрасно знать из школьного курса математики — у параболы существует только один минимум.
После того, как мы выяснили для чего нам потребовался градиент, а также то, что градиент — это отрезок, то есть вектор с заданными координатами, которые как раз являются теми самыми коэффициентами и мы можем реализовать градиентный спуск.
Перед запуском, предлагаю прочитать буквально несколько предложений об алгоритме спуска:
- Определяем псевдослучайным образом координаты коэффициентов и . В нашем примере, мы будем определять коэффициенты вблизи нуля. Это является распространённой практикой, однако для каждого случая может быть предусмотрена своя практика.
- От координаты вычитаем значение частной производной 1-го порядка в точке . Так, если производная будет положительная, то функция возрастает. Следовательно, отнимая значение производной, мы будем двигаться в обратную сторону роста, то есть в сторону спуска. Если производная отрицательна, значит функция в этой точке убывает и отнимая значение производной мы двигаемся в сторону спуска.
- Проводим аналогичную операцию с координатой : вычитаем значение частной производной в точке .
- Для того, чтобы не перескочить минимум и не улететь в далекий космос, необходимо установить размер шага в сторону спуска. В общем и целом, можно написать целую статью о том, как правильнее установить шаг и как его менять в процессе спуска, чтобы снизить затраты на вычисления. Но сейчас перед нами несколько иная задача, и мы научным методом «тыка» или как говорят в простонародье, эмпирическим путем, установим размер шага.
- После того, как мы из заданных координат и вычли значения производных, получаем новые координаты и . Делаем следующий шаг (вычитание), уже из рассчитанных координат. И так цикл запускается вновь и вновь, до тех пор, пока не будет достигнута требуемая сходимость.
Все! Теперь мы готовы отправиться на поиски самого глубокого ущелья Марианской впадины. Приступаем.

Мы погрузились на самое дно Марианской впадины и там обнаружили все те же значения коэффициентов и , что собственно и следовало ожидать.
Совершим еще одно погружение, только на этот раз, начинкой нашего глубоководного аппарата будут иные технологии, а именно библиотека NumPy.

Значения коэффициентов и неизменны.
Посмотрим на то, как изменялась ошибка при градиентном спуске, то есть как изменялась сумма квадратов отклонений с каждым шагом.
График №4 «Сумма квадратов отклонений при градиентном спуске»

На графике мы видим, что с каждым шагом ошибка уменьшается, а спустя какое-то количество итераций наблюдаем практически горизонтальную линию.
Напоследок оценим разницу во времени исполнения кода:
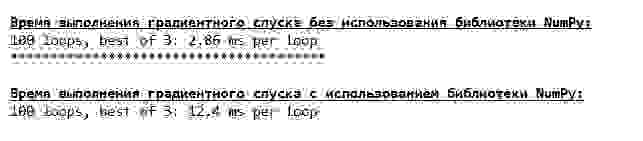
Возможно мы делаем что-то не то, но опять простая «самописная» функция, которая не использует библиотеку NumPy опережает по времени выполнения расчетов функцию, использующую библиотеку NumPy.
Но мы не стоим на месте, а двигаемся в сторону изучения еще одного увлекательного способа решения уравнения простой линейной регрессии. Встречайте!
Стохастический градиентный спуск
Для того, чтобы быстрее понять принцип работы стохастического градиентного спуска, лучше определить его отличия от обычного градиентного спуска. Мы, в случае с градиентным спуском, в уравнениях производных от и использовали суммы значений всех признаков и истинных ответов, имеющихся в выборке (то есть суммы всех и ). В стохастическом градиентном спуске мы не будем использовать все значения, имеющиеся в выборке, а вместо этого, псевдослучайным образом выберем так называемый индекс выборки и используем его значения.
Например, если индекс определился за номером 3 (три), то мы берем значения  и
и  , далее подставляем значения в уравнения производных и определяем новые координаты. Затем, определив координаты, мы опять псевдослучайным образом определяем индекс выборки, подставляем значения, соответствующие индексу в уравнения частных производных, по новому определяем координаты и и т.д. до
, далее подставляем значения в уравнения производных и определяем новые координаты. Затем, определив координаты, мы опять псевдослучайным образом определяем индекс выборки, подставляем значения, соответствующие индексу в уравнения частных производных, по новому определяем координаты и и т.д. до позеленения сходимости. На первый взгляд, может показаться, как это вообще может работать, однако работает. Правда стоит отметить, что не с каждым шагом уменьшается ошибка, но тенденция безусловно имеется.
Каковы преимущества стохастического градиентного спуска перед обычным? В случае, если у нас размер выборки очень велик и измеряется десятками тысяч значений, то значительно проще обработать, допустим случайную тысячу из них, нежели всю выборку. Вот в этом случае и запускается стохастический градиентный спуск. В нашем случае мы конечно же большой разницы не заметим.

Смотрим внимательно на коэффициенты и ловим себя на вопросе «Как же так?». У нас получились другие значения коэффициентов и . Может быть стохастический градиентный спуск нашел более оптимальные параметры уравнения? Увы, нет. Достаточно посмотреть на сумму квадратов отклонений и увидеть, что при новых значениях коэффициентов, ошибка больше. Не спешим отчаиваться. Построим график изменения ошибки.
График №5 «Сумма квадратов отклонений при стохастическом градиентном спуске»

Посмотрев на график, все становится на свои места и сейчас мы все исправим.
Итак, что же произошло? Произошло следующее. Когда мы выбираем случайным образом месяц, то именно для выбранного месяца наш алгоритм стремится уменьшить ошибку в расчете выручки. Затем выбираем другой месяц и повторяем расчет, но ошибку уменьшаем уже для второго выбранного месяца. А теперь вспомним, что у нас первые два месяца существенно отклоняются от линии уравнения простой линейной регрессии. Это значит, что когда выбирается любой из этих двух месяцев, то уменьшая ошибку каждого из них, наш алгоритм серьезно увеличивает ошибку по всей выборке. Так что же делать? Ответ простой: надо уменьшить шаг спуска. Ведь уменьшив шаг спуска, ошибка так же перестанет «скакать» то вверх, то вниз. Вернее, ошибка «скакать» не перестанет, но будет это делать не так прытко:) Проверим.

График №6 «Сумма квадратов отклонений при стохастическом градиентном спуске (80 тыс. шагов)»

Значения коэффициентов улучшились, но все равно не идеальны. Гипотетически это можно поправить таким образом. Выбираем, например, на последних 1000 итерациях значения коэффициентов, с которыми была допущена минимальная ошибка. Правда нам для этого придется записывать еще и сами значения коэффициентов. Мы не будем этого делать, а лучше обратим внимание на график. Он выглядит гладким, и ошибка как будто уменьшается равномерно. На самом деле это не так. Посмотрим на первые 1000 итераций и сравним их с последними.
График №7 «Сумма квадратов отклонений SGD (первые 1000 шагов)»
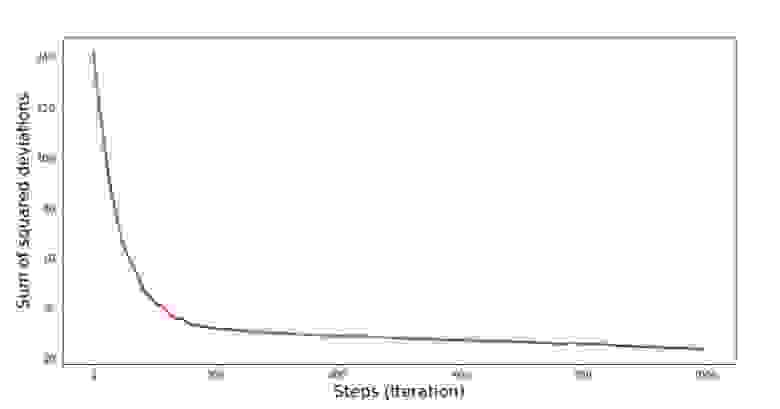
График №8 «Сумма квадратов отклонений SGD (последние 1000 шагов)»

В самом начале спуска мы наблюдаем достаточно равномерное и крутое уменьшение ошибки. На последних итерациях мы видим, что ошибка ходит вокруг да около значения в 1,475 и в некоторые моменты даже равняется этому оптимальному значению, но потом все равно уходит ввысь… Повторюсь, можно записывать значения коэффициентов и , а потом выбрать те, при которых ошибка минимальна. Однако у нас возникла проблема посерьезнее: нам пришлось сделать 80 тыс. шагов (см. код), чтобы получить значения, близкие к оптимальным. А это, уже противоречит идее об экономии времени вычислений при стохастическом градиентном спуске относительно градиентного. Что можно поправить и улучшить? Не трудно заметить, что на первых итерациях мы уверенно идем вниз и, следовательно, нам стоит оставить большой шаг на первых итерациях и по мере продвижения вперед шаг уменьшать. Мы не будем этого делать в этой статье — она и так уже затянулась. Желающие могут и сами подумать, как это сделать, это не сложно 🙂
Теперь выполним стохастический градиентный спуск, используя библиотеку NumPy (и не будем спотыкаться о камни, которые мы выявили раннее)

Значения получились почти такими же, как и при спуске без использования NumPy. Впрочем, это логично.
Узнаем сколько же времени занимали у нас стохастические градиентные спуски.

Чем дальше в лес, тем темнее тучи: опять «самописная» формула показывает лучший результат. Все это наводит на мысли о том, что должны существовать еще более тонкие способы использования библиотеки NumPy, которые действительно ускоряют операции вычислений. В этой статье мы о них уже не узнаем. Будет о чем подумать на досуге:)
Резюмируем
Перед тем как резюмировать, хотелось бы ответить на вопрос, который скорее всего, возник у нашего дорогого читателя. Для чего, собственно, такие «мучения» со спусками, зачем нам ходить по горе вверх и вниз (преимущественно вниз), чтобы найти заветную низину, если в наших руках такой мощный и простой прибор, в виде аналитического решения, который мгновенно телепортирует нас в нужное место?
Ответ на этот вопрос лежит на поверхности. Сейчас мы разбирали очень простой пример, в котором истинный ответ зависит от одного признака . В жизни такое встретишь не часто, поэтому представим, что у нас признаков 2, 30, 50 или более. Добавим к этому тысячи, а то и десятки тысяч значений для каждого признака. В этом случае аналитическое решение может не выдержать испытания и дать сбой. В свою очередь градиентный спуск и его вариации будут медленно, но верно приближать нас к цели — минимуму функции. А на счет скорости не волнуйтесь — мы наверняка еще разберем способы, которые позволят нам задавать и регулировать длину шага (то есть скорость).
А теперь собственно краткое резюме.
Во-первых, надеюсь, что изложенный в статье материал, поможет начинающим «дата сайнтистам» в понимании того, как решать уравнения простой (и не только) линейной регрессии.
Во-вторых, мы рассмотрели несколько способов решения уравнения. Теперь, в зависимости от ситуации, мы можем выбрать тот, который лучше всего подходит для решения поставленной задачи.
В-третьих, мы увидели силу дополнительных настроек, а именно длины шага градиентного спуска. Этим параметром нельзя пренебрегать. Как было подмечено выше, с целью сокращения затрат на проведение вычислений, длину шага стоит изменять по ходу спуска.
В-четвертых, в нашем случае, «самописные» функции показали лучший временной результат вычислений. Вероятно, это связано с не самым профессиональным применением возможностей библиотеки NumPy. Но как бы то ни было, вывод напрашивается следующий. С одной стороны, иногда стоит подвергать сомнению устоявшиеся мнения, а с другой — не всегда стоит все усложнять — наоборот иногда эффективнее оказывается более простой способ решения задачи. А так как цель у нас была разобрать три подхода в решении уравнения простой линейной регрессии, то использование «самописных» функций нам вполне хватило.
 Предыдущая работа автора — «Исследуем утверждение центральной предельной теоремы с помощью экспоненциального распределения»
Предыдущая работа автора — «Исследуем утверждение центральной предельной теоремы с помощью экспоненциального распределения»  Следующая работа автора — «Приводим уравнение линейной регрессии в матричный вид»
Следующая работа автора — «Приводим уравнение линейной регрессии в матричный вид»
http://function-x.ru/statistics_regression1.html
http://habr.com/ru/post/474602/