Задача №1 Построение уравнения регрессии
Имеются следующие данные разных стран об индексе розничных цен на продукты питания (х) и об индексе промышленного производства (у).
| Индекс розничных цен на продукты питания (х) | Индекс промышленного производства (у) | |
|---|---|---|
| 1 | 100 | 70 |
| 2 | 105 | 79 |
| 3 | 108 | 85 |
| 4 | 113 | 84 |
| 5 | 118 | 85 |
| 6 | 118 | 85 |
| 7 | 110 | 96 |
| 8 | 115 | 99 |
| 9 | 119 | 100 |
| 10 | 118 | 98 |
| 11 | 120 | 99 |
| 12 | 124 | 102 |
| 13 | 129 | 105 |
| 14 | 132 | 112 |
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
В) равносторонней гиперболы.
2. Для каждой модели рассчитать показатели: тесноты связи и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз значения индекса промышленного производства у при прогнозном значении индекса розничных цен на продукты питания х=138.
Решение:
1. Для расчёта параметров линейной регрессии
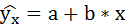
Решаем систему нормальных уравнений относительно a и b:
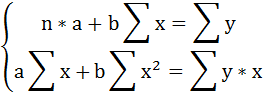
Построим таблицу расчётных данных, как показано в таблице 1.
Таблица 1 Расчетные данные для оценки линейной регрессии
| № п/п | х | у | ху | x 2 | y 2 | 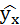 | 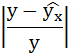 |
|---|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 7000 | 10000 | 4900 | 74,26340 | 0,060906 |
| 2 | 105 | 79 | 8295 | 11025 | 6241 | 79,92527 | 0,011712 |
| 3 | 108 | 85 | 9180 | 11664 | 7225 | 83,32238 | 0,019737 |
| 4 | 113 | 84 | 9492 | 12769 | 7056 | 88,98425 | 0,059336 |
| 5 | 118 | 85 | 10030 | 13924 | 7225 | 94,64611 | 0,113484 |
| 6 | 118 | 85 | 10030 | 13924 | 7225 | 94,64611 | 0,113484 |
| 7 | 110 | 96 | 10560 | 12100 | 9216 | 85,58713 | 0,108467 |
| 8 | 115 | 99 | 11385 | 13225 | 9801 | 91,24900 | 0,078293 |
| 9 | 119 | 100 | 11900 | 14161 | 10000 | 95,77849 | 0,042215 |
| 10 | 118 | 98 | 11564 | 13924 | 9604 | 94,64611 | 0,034223 |
| 11 | 120 | 99 | 11880 | 14400 | 9801 | 96,91086 | 0,021102 |
| 12 | 124 | 102 | 12648 | 15376 | 10404 | 101,4404 | 0,005487 |
| 13 | 129 | 105 | 13545 | 16641 | 11025 | 107,1022 | 0,020021 |
| 14 | 132 | 112 | 14784 | 17424 | 12544 | 110,4993 | 0,013399 |
| Итого: | 1629 | 1299 | 152293 | 190557 | 122267 | 1299,001 | 0,701866 |
| Среднее значение: | 116,3571 | 92,78571 | 10878,07 | 13611,21 | 8733,357 | х | х |
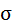 | 8,4988 | 11,1431 | х | х | х | х | х |
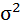 | 72,23 | 124,17 | х | х | х | х | х |
Среднее значение определим по формуле:
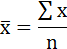
Cреднее квадратическое отклонение рассчитаем по формуле:
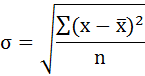
и занесём полученный результат в таблицу 1.
Возведя в квадрат полученное значение получим дисперсию:
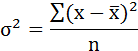
Параметры уравнения можно определить также и по формулам:
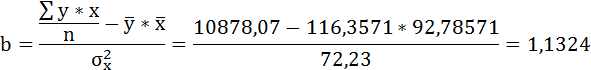
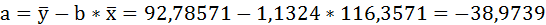
Таким образом, уравнение регрессии:
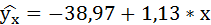
Следовательно, с увеличением индекса розничных цен на продукты питания на 1, индекс промышленного производства увеличивается в среднем на 1,13.
Рассчитаем линейный коэффициент парной корреляции:
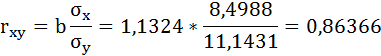
Связь прямая, достаточно тесная.
Определим коэффициент детерминации:
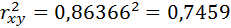
Вариация результата на 74,59% объясняется вариацией фактора х.
Подставляя в уравнение регрессии фактические значения х, определим теоретические (расчётные) значения .
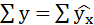 ,
,
следовательно, параметры уравнения определены правильно.
Рассчитаем среднюю ошибку аппроксимации – среднее отклонение расчётных значений от фактических:
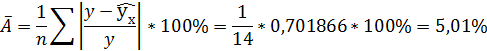
В среднем расчётные значения отклоняются от фактических на 5,01%.
Оценку качества уравнения регрессии проведём с помощью F-теста.
F-тест состоит в проверке гипотезы Н0 о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера.
Fфакт определяется по формуле:
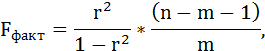
где n – число единиц совокупности;
m – число параметров при переменных х.
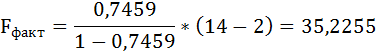
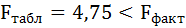
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза.
Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
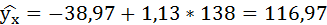
2. Степенная регрессия имеет вид:
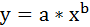
Для определения параметров производят логарифмирование степенной функции:
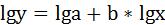
Для определения параметров логарифмической функции строят систему нормальных уравнений по способу наименьших квадратов:
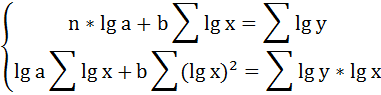
Построим таблицу расчётных данных, как показано в таблице 2.
Таблица 2 Расчетные данные для оценки степенной регрессии
| №п/п | х | у | lg x | lg y | lg x*lg y | (lg x) 2 | (lg y) 2 |
|---|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 2,000000 | 1,845098 | 3,690196 | 4,000000 | 3,404387 |
| 2 | 105 | 79 | 2,021189 | 1,897627 | 3,835464 | 4,085206 | 3,600989 |
| 3 | 108 | 85 | 2,033424 | 1,929419 | 3,923326 | 4,134812 | 3,722657 |
| 4 | 113 | 84 | 2,053078 | 1,924279 | 3,950696 | 4,215131 | 3,702851 |
| 5 | 118 | 85 | 2,071882 | 1,929419 | 3,997528 | 4,292695 | 3,722657 |
| 6 | 118 | 85 | 2,071882 | 1,929419 | 3,997528 | 4,292695 | 3,722657 |
| 7 | 110 | 96 | 2,041393 | 1,982271 | 4,046594 | 4,167284 | 3,929399 |
| 8 | 115 | 99 | 2,060698 | 1,995635 | 4,112401 | 4,246476 | 3,982560 |
| 9 | 119 | 100 | 2,075547 | 2,000000 | 4,151094 | 4,307895 | 4,000000 |
| 10 | 118 | 98 | 2,071882 | 1,991226 | 4,125585 | 4,292695 | 3,964981 |
| 11 | 120 | 99 | 2,079181 | 1,995635 | 4,149287 | 4,322995 | 3,982560 |
| 12 | 124 | 102 | 2,093422 | 2,008600 | 4,204847 | 4,382414 | 4,034475 |
| 13 | 129 | 105 | 2,110590 | 2,021189 | 4,265901 | 4,454589 | 4,085206 |
| 14 | 132 | 112 | 2,120574 | 2,049218 | 4,345518 | 4,496834 | 4,199295 |
| Итого | 1629 | 1299 | 28,90474 | 27,49904 | 56,79597 | 59,69172 | 54,05467 |
| Среднее значение | 116,3571 | 92,78571 | 2,064624 | 1,964217 | 4,056855 | 4,263694 | 3,861048 |
| 8,4988 | 11,1431 | 0,031945 | 0,053853 | х | х | х |
| 72,23 | 124,17 | 0,001021 | 0,0029 | х | х | х |
Продолжение таблицы 2 Расчетные данные для оценки степенной регрессии
| №п/п | х | у | |  | | 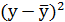 |
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 74,16448 | 17,34292 | 0,059493 | 519,1886 |
| 2 | 105 | 79 | 79,62057 | 0,385112 | 0,007855 | 190,0458 |
| 3 | 108 | 85 | 82,95180 | 4,195133 | 0,024096 | 60,61728 |
| 4 | 113 | 84 | 88,59768 | 21,13866 | 0,054734 | 77,1887 |
| 5 | 118 | 85 | 94,35840 | 87,57961 | 0,110099 | 60,61728 |
| 6 | 118 | 85 | 94,35840 | 87,57961 | 0,110099 | 60,61728 |
| 7 | 110 | 96 | 85,19619 | 116,7223 | 0,11254 | 10,33166 |
| 8 | 115 | 99 | 90,88834 | 65,79901 | 0,081936 | 38,6174 |
| 9 | 119 | 100 | 95,52408 | 20,03384 | 0,044759 | 52,04598 |
| 10 | 118 | 98 | 94,35840 | 13,26127 | 0,037159 | 27,18882 |
| 11 | 120 | 99 | 96,69423 | 5,316563 | 0,023291 | 38,6174 |
| 12 | 124 | 102 | 101,4191 | 0,337467 | 0,005695 | 84,90314 |
| 13 | 129 | 105 | 107,4232 | 5,872099 | 0,023078 | 149,1889 |
| 14 | 132 | 112 | 111,0772 | 0,85163 | 0,00824 | 369,1889 |
| Итого | 1629 | 1299 | 1296,632 | 446,4152 | 0,703074 | 1738,357 |
| Среднее значение | 116,3571 | 92,78571 | х | х | х | х |
| 8,4988 | 11,1431 | х | х | х | х |
| 72,23 | 124,17 | х | х | х | х |
Решая систему нормальных уравнений, определяем параметры логарифмической функции.
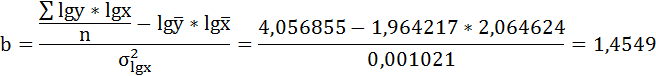
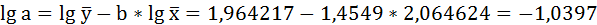
Получим линейное уравнение:
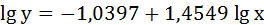
Выполнив его потенцирование, получим:
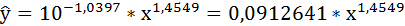
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата 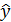 . По ним рассчитаем показатели: тесноты связи – индекс корреляции и среднюю ошибку аппроксимации.
. По ним рассчитаем показатели: тесноты связи – индекс корреляции и среднюю ошибку аппроксимации.
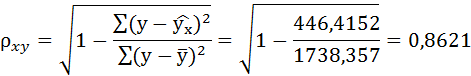
Связь достаточно тесная.
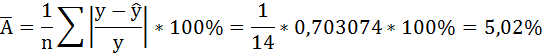
В среднем расчётные значения отклоняются от фактических на 5,02%.
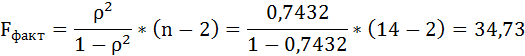
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
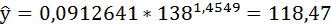
3. Уравнение равносторонней гиперболы
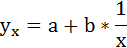
Для определения параметров этого уравнения используется система нормальных уравнений:
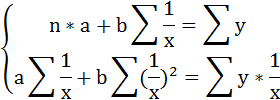
Произведем замену переменных
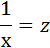
и получим следующую систему нормальных уравнений:
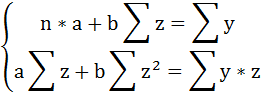
Решая систему нормальных уравнений, определяем параметры гиперболы.
Составим таблицу расчётных данных, как показано в таблице 3.
Таблица 3 Расчетные данные для оценки гиперболической зависимости
| №п/п | х | у | z | yz | 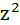 | 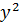 |
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 0,010000000 | 0,700000 | 0,0001000 | 4900 |
| 2 | 105 | 79 | 0,009523810 | 0,752381 | 0,0000907 | 6241 |
| 3 | 108 | 85 | 0,009259259 | 0,787037 | 0,0000857 | 7225 |
| 4 | 113 | 84 | 0,008849558 | 0,743363 | 0,0000783 | 7056 |
| 5 | 118 | 85 | 0,008474576 | 0,720339 | 0,0000718 | 7225 |
| 6 | 118 | 85 | 0,008474576 | 0,720339 | 0,0000718 | 7225 |
| 7 | 110 | 96 | 0,009090909 | 0,872727 | 0,0000826 | 9216 |
| 8 | 115 | 99 | 0,008695652 | 0,860870 | 0,0000756 | 9801 |
| 9 | 119 | 100 | 0,008403361 | 0,840336 | 0,0000706 | 10000 |
| 10 | 118 | 98 | 0,008474576 | 0,830508 | 0,0000718 | 9604 |
| 11 | 120 | 99 | 0,008333333 | 0,825000 | 0,0000694 | 9801 |
| 12 | 124 | 102 | 0,008064516 | 0,822581 | 0,0000650 | 10404 |
| 13 | 129 | 105 | 0,007751938 | 0,813953 | 0,0000601 | 11025 |
| 14 | 132 | 112 | 0,007575758 | 0,848485 | 0,0000574 | 12544 |
| Итого: | 1629 | 1299 | 0,120971823 | 11,13792 | 0,0010510 | 122267 |
| Среднее значение: | 116,3571 | 92,78571 | 0,008640844 | 0,795566 | 0,0000751 | 8733,357 |
| 8,4988 | 11,1431 | 0,000640820 | х | х | х |
| 72,23 | 124,17 | 0,000000411 | х | х | х |
Продолжение таблицы 3 Расчетные данные для оценки гиперболической зависимости
| №п/п | х | у | | | | |
|---|---|---|---|---|---|---|
| 1 | 100 | 70 | 72,3262 | 0,033231 | 5,411206 | 519,1886 |
| 2 | 105 | 79 | 79,49405 | 0,006254 | 0,244083 | 190,0458 |
| 3 | 108 | 85 | 83,47619 | 0,017927 | 2,322012 | 60,61728 |
| 4 | 113 | 84 | 89,64321 | 0,067181 | 31,84585 | 77,1887 |
| 5 | 118 | 85 | 95,28761 | 0,121031 | 105,8349 | 60,61728 |
| 6 | 118 | 85 | 95,28761 | 0,121031 | 105,8349 | 60,61728 |
| 7 | 110 | 96 | 86,01027 | 0,10406 | 99,79465 | 10,33166 |
| 8 | 115 | 99 | 91,95987 | 0,071112 | 49,56344 | 38,6174 |
| 9 | 119 | 100 | 96,35957 | 0,036404 | 13,25272 | 52,04598 |
| 10 | 118 | 98 | 95,28761 | 0,027677 | 7,357059 | 27,18882 |
| 11 | 120 | 99 | 97,41367 | 0,016024 | 2,516453 | 38,6174 |
| 12 | 124 | 102 | 101,46 | 0,005294 | 0,291565 | 84,90314 |
| 13 | 129 | 105 | 106,1651 | 0,011096 | 1,357478 | 149,1889 |
| 14 | 132 | 112 | 108,8171 | 0,028419 | 10,1311 | 369,1889 |
| Итого: | 1629 | 1299 | 1298,988 | 0,666742 | 435,7575 | 1738,357 |
| Среднее значение: | 116,3571 | 92,78571 | х | х | х | х |
| 8,4988 | 11,1431 | х | х | х | х |
| 72,23 | 124,17 | х | х | х | х |
Значения параметров регрессии a и b составили:
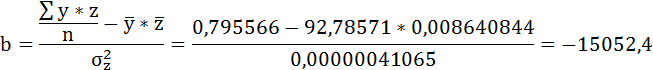
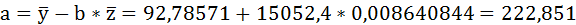
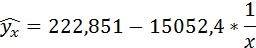
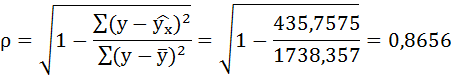
Связь достаточно тесная.
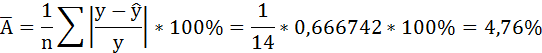
В среднем расчётные значения отклоняются от фактических на 4,76%.
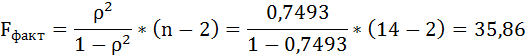
Таким образом, Н0 – гипотеза о случайной природе оцениваемых характеристик отклоняется и признаётся их статистическая значимость и надёжность.
Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение индекса розничных цен на продукты питания х = 138, тогда прогнозное значение индекса промышленного производства составит:
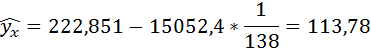
По уравнению равносторонней гиперболы получена наибольшая оценка тесноты связи по сравнению с линейной и степенной регрессиями. Средняя ошибка аппроксимации остаётся на допустимом уровне.
Простая линейная регрессия в EXCEL
history 26 января 2019 г.
- Группы статей
- Статистический анализ
Регрессия позволяет прогнозировать зависимую переменную на основании значений фактора. В MS EXCEL имеется множество функций, которые возвращают не только наклон и сдвиг линии регрессии, характеризующей линейную взаимосвязь между факторами, но и регрессионную статистику. Здесь рассмотрим простую линейную регрессию, т.е. прогнозирование на основе одного фактора.
Disclaimer : Данную статью не стоит рассматривать, как пересказ главы из учебника по статистике. Статья не обладает ни полнотой, ни строгостью изложения положений статистической науки. Эта статья – о применении MS EXCEL для целей Регрессионного анализа. Теоретические отступления приведены лишь из соображения логики изложения. Использование данной статьи для изучения Регрессии – плохая идея.
Статья про Регрессионный анализ получилась большая, поэтому ниже для удобства приведены ее разделы:
Примечание : Если прогнозирование переменной осуществляется на основе нескольких факторов, то имеет место множественная регрессия .
Чтобы разобраться, чем может помочь MS EXCEL при проведении регрессионного анализа, напомним вкратце теорию, введем термины и обозначения, которые могут отличаться в зависимости от различных источников.
Примечание : Для тех, кому некогда, незачем или просто не хочется разбираться в теоретических выкладках предлагается сразу перейти к вычислительной части — оценке неизвестных параметров линейной модели .
Немного теории и основные понятия
Пусть у нас есть массив данных, представляющий собой значения двух переменных Х и Y. Причем значения переменной Х мы можем произвольно задавать (контролировать) и использовать эту переменную для предсказания значений зависимой переменной Y. Таким образом, случайной величиной является только переменная Y.
Примером такой задачи может быть производственный процесс изготовления некого волокна, причем прочность этого волокна (Y) зависит только от рабочей температуры процесса в реакторе (Х), которая задается оператором.
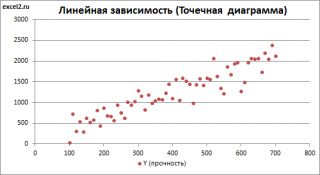
Построим диаграмму рассеяния (см. файл примера лист Линейный ), созданию которой посвящена отдельная статья . Вообще, построение диаграммы рассеяния для целей регрессионного анализа де-факто является стандартом.
СОВЕТ : Подробнее о построении различных типов диаграмм см. статьи Основы построения диаграмм и Основные типы диаграмм .
Приведенная выше диаграмма рассеяния свидетельствует о возможной линейной взаимосвязи между Y от Х: очевидно, что точки данных в основном располагаются вдоль прямой линии.
Примечание : Наличие даже такой очевидной линейной взаимосвязи не может являться доказательством о наличии причинной взаимосвязи переменных. Наличие причинной взаимосвязи не может быть доказано на основании только анализа имеющихся измерений, а должно быть обосновано с помощью других исследований, например теоретических выкладок.
Примечание : Как известно, уравнение прямой линии имеет вид Y = m * X + k , где коэффициент m отвечает за наклон линии ( slope ), k – за сдвиг линии по вертикали ( intercept ), k равно значению Y при Х=0.
Предположим, что мы можем зафиксировать переменную Х ( рабочую температуру процесса ) при некотором значении Х i и произвести несколько наблюдений переменной Y ( прочность нити ). Очевидно, что при одном и том же значении Хi мы получим различные значения Y. Это обусловлено влиянием других факторов на Y. Например, локальные колебания давления в реакторе, концентрации раствора, наличие ошибок измерения и др. Предполагается, что воздействие этих факторов имеет случайную природу и для каждого измерения имеются одинаковые условия проведения эксперимента (т.е. другие факторы не изменяются).
Полученные значения Y, при заданном Хi, будут колебаться вокруг некого значения . При увеличении количества измерений, среднее этих измерений, будет стремиться к математическому ожиданию случайной величины Y (при Х i ) равному μy(i)=Е(Y i ).
Подобные рассуждения можно привести для любого значения Хi.
Чтобы двинуться дальше, воспользуемся материалом из раздела Проверка статистических гипотез . В статье о проверке гипотезы о среднем значении генеральной совокупности в качестве нулевой гипотезы предполагалось равенство неизвестного значения μ заданному μ0.
В нашем случае простой линейной регрессии в качестве нулевой гипотезы предположим, что между переменными μy(i) и Хi существует линейная взаимосвязь μ y(i) =α* Х i +β. Уравнение μ y(i) =α* Х i +β можно переписать в обобщенном виде (для всех Х и μ y ) как μ y =α* Х +β.
Для наглядности проведем прямую линию соединяющую все μy(i).
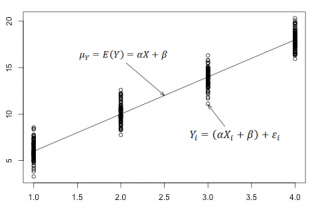
Данная линия называется регрессионной линией генеральной совокупности (population regression line), параметры которой ( наклон a и сдвиг β ) нам не известны (по аналогии с гипотезой о среднем значении генеральной совокупности , где нам было неизвестно истинное значение μ).
Теперь сделаем переход от нашего предположения, что μy=a* Х + β , к предсказанию значения случайной переменной Y в зависимости от значения контролируемой переменной Х. Для этого уравнение связи двух переменных запишем в виде Y=a*X+β+ε, где ε — случайная ошибка, которая отражает суммарный эффект влияния других факторов на Y (эти «другие» факторы не участвуют в нашей модели). Напомним, что т.к. переменная Х фиксирована, то ошибка ε определяется только свойствами переменной Y.
Уравнение Y=a*X+b+ε называют линейной регрессионной моделью . Часто Х еще называют независимой переменной (еще предиктором и регрессором , английский термин predictor , regressor ), а Y – зависимой (или объясняемой , response variable ). Так как регрессор у нас один, то такая модель называется простой линейной регрессионной моделью ( simple linear regression model ). α часто называют коэффициентом регрессии.
Предположения линейной регрессионной модели перечислены в следующем разделе.
Предположения линейной регрессионной модели
Чтобы модель линейной регрессии Yi=a*Xi+β+ε i была адекватной — требуется:
- Ошибки ε i должны быть независимыми переменными;
- При каждом значении Xi ошибки ε i должны быть иметь нормальное распределение (также предполагается равенство нулю математического ожидания, т.е. Е[ε i ]=0);
- При каждом значении Xi ошибки ε i должны иметь равные дисперсии (обозначим ее σ 2 ).
Примечание : Последнее условие называется гомоскедастичность — стабильность, гомогенность дисперсии случайной ошибки e. Т.е. дисперсия ошибки σ 2 не должна зависеть от значения Xi.
Используя предположение о равенстве математического ожидания Е[ε i ]=0 покажем, что μy(i)=Е[Yi]:
Е[Yi]= Е[a*Xi+β+ε i ]= Е[a*Xi+β]+ Е[ε i ]= a*Xi+β= μy(i), т.к. a, Xi и β постоянные значения.
Дисперсия случайной переменной Y равна дисперсии ошибки ε, т.е. VAR(Y)= VAR(ε)=σ 2 . Это является следствием, что все значения переменной Х являются const, а VAR(ε)=VAR(ε i ).
Задачи регрессионного анализа
Для проверки гипотезы о линейной взаимосвязи переменной Y от X делают выборку из генеральной совокупности (этой совокупности соответствует регрессионная линия генеральной совокупности , т.е. μy=a* Х +β). Выборка будет состоять из n точек, т.е. из n пар значений
На основании этой выборки мы можем вычислить оценки наклона a и сдвига β, которые обозначим соответственно a и b . Также часто используются обозначения â и b̂.
Далее, используя эти оценки, мы также можем проверить гипотезу: имеется ли линейная связь между X и Y статистически значимой?
Первая задача регрессионного анализа – оценка неизвестных параметров ( estimation of the unknown parameters ). Подробнее см. раздел Оценки неизвестных параметров модели .
Вторая задача регрессионного анализа – Проверка адекватности модели ( model adequacy checking ).
Примечание : Оценки параметров модели обычно вычисляются методом наименьших квадратов (МНК), которому посвящена отдельная статья .
Оценка неизвестных параметров линейной модели (используя функции MS EXCEL)
Неизвестные параметры простой линейной регрессионной модели Y=a*X+β+ε оценим с помощью метода наименьших квадратов (в статье про МНК подробно описано этот метод ).
Для вычисления параметров линейной модели методом МНК получены следующие выражения:
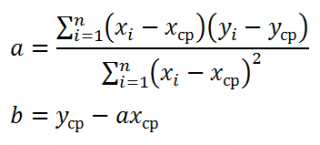
Таким образом, мы получим уравнение прямой линии Y= a *X+ b , которая наилучшим образом аппроксимирует имеющиеся данные.
Примечание : В статье про метод наименьших квадратов рассмотрены случаи аппроксимации линейной и квадратичной функцией , а также степенной , логарифмической и экспоненциальной функцией .
Оценку параметров в MS EXCEL можно выполнить различными способами:
Сначала рассмотрим функции НАКЛОН() , ОТРЕЗОК() и ЛИНЕЙН() .
Пусть значения Х и Y находятся соответственно в диапазонах C 23: C 83 и B 23: B 83 (см. файл примера внизу статьи).
Примечание : Значения двух переменных Х и Y можно сгенерировать, задав тренд и величину случайного разброса (см. статью Генерация данных для линейной регрессии в MS EXCEL ).
В MS EXCEL наклон прямой линии а ( оценку коэффициента регрессии ), можно найти по методу МНК с помощью функции НАКЛОН() , а сдвиг b ( оценку постоянного члена или константы регрессии ), с помощью функции ОТРЕЗОК() . В английской версии это функции SLOPE и INTERCEPT соответственно.
Аналогичный результат можно получить с помощью функции ЛИНЕЙН() , английская версия LINEST (см. статью об этой функции ).
Формула =ЛИНЕЙН(C23:C83;B23:B83) вернет наклон а . А формула = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2) — сдвиг b . Здесь требуются пояснения.
Функция ЛИНЕЙН() имеет 4 аргумента и возвращает целый массив значений:
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Если 4-й аргумент статистика имеет значение ЛОЖЬ или опущен, то функция ЛИНЕЙН() возвращает только оценки параметров модели: a и b .
Примечание : Остальные значения, возвращаемые функцией ЛИНЕЙН() , нам потребуются при вычислении стандартных ошибок и для проверки значимости регрессии . В этом случае аргумент статистика должен иметь значение ИСТИНА.
Чтобы вывести сразу обе оценки:
- в одной строке необходимо выделить 2 ячейки,
- ввести формулу в Строке формул
- нажать CTRL+SHIFT+ENTER (см. статью про формулы массива ).
Если в Строке формул выделить формулу = ЛИНЕЙН(C23:C83;B23:B83) и нажать клавишу F9 , то мы увидим что-то типа <3,01279389265416;154,240057900613>. Это как раз значения a и b . Как видно, оба значения разделены точкой с запятой «;», что свидетельствует, что функция вернула значения «в нескольких ячейках одной строки».
Если требуется вывести параметры линии не в одной строке, а одном столбце (ячейки друг под другом), то используйте формулу = ТРАНСП(ЛИНЕЙН(C23:C83;B23:B83)) . При этом выделять нужно 2 ячейки в одном столбце. Если теперь выделить новую формулу и нажать клавишу F9, то мы увидим что 2 значения разделены двоеточием «:», что означает, что значения выведены в столбец (функция ТРАНСП() транспонировала строку в столбец ).
Чтобы разобраться в этом подробнее необходимо ознакомиться с формулами массива .
Чтобы не связываться с вводом формул массива , можно использовать функцию ИНДЕКС() . Формула = ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);1) или просто ЛИНЕЙН(C23:C83;B23:B83) вернет параметр, отвечающий за наклон линии, т.е. а . Формула =ИНДЕКС(ЛИНЕЙН(C23:C83;B23:B83);2) вернет параметр b .
Оценка неизвестных параметров линейной модели (через статистики выборок)
Наклон линии, т.е. коэффициент а , можно также вычислить через коэффициент корреляции и стандартные отклонения выборок :
= КОРРЕЛ(B23:B83;C23:C83) *(СТАНДОТКЛОН.В(C23:C83)/ СТАНДОТКЛОН.В(B23:B83))
Вышеуказанная формула математически эквивалентна отношению ковариации выборок Х и Y и дисперсии выборки Х:
И, наконец, запишем еще одну формулу для нахождения сдвига b . Воспользуемся тем фактом, что линия регрессии проходит через точку средних значений переменных Х и Y.
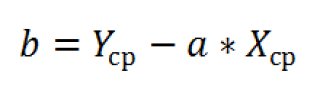
Вычислив средние значения и подставив в формулу ранее найденный наклон а , получим сдвиг b .
Оценка неизвестных параметров линейной модели (матричная форма)
Также параметры линии регрессии можно найти в матричной форме (см. файл примера лист Матричная форма ).
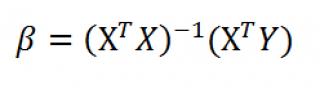
В формуле символом β обозначен столбец с искомыми параметрами модели: β0 (сдвиг b ), β1 (наклон a ).
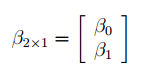
Матрица Х равна:
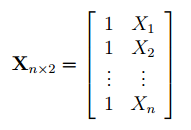
Матрица Х называется регрессионной матрицей или матрицей плана . Она состоит из 2-х столбцов и n строк, где n – количество точек данных. Первый столбец — столбец единиц, второй – значения переменной Х.
Матрица Х T – это транспонированная матрица Х . Она состоит соответственно из n столбцов и 2-х строк.
В формуле символом Y обозначен столбец значений переменной Y.
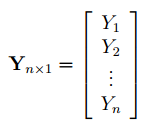
Чтобы перемножить матрицы используйте функцию МУМНОЖ() . Чтобы найти обратную матрицу используйте функцию МОБР() .
Пусть дан массив значений переменных Х и Y (n=10, т.е.10 точек).
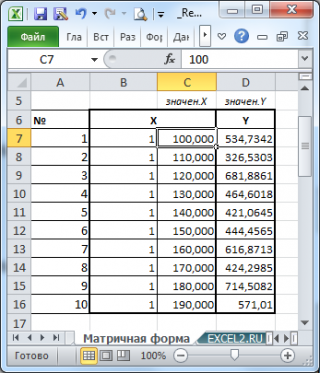
Слева от него достроим столбец с 1 для матрицы Х.
и введя ее как формулу массива в 2 ячейки, получим оценку параметров модели.
Красота применения матричной формы полностью раскрывается в случае множественной регрессии .
Построение линии регрессии
Для отображения линии регрессии построим сначала диаграмму рассеяния , на которой отобразим все точки (см. начало статьи ).
Для построения прямой линии используйте вычисленные выше оценки параметров модели a и b (т.е. вычислите у по формуле y = a * x + b ) или функцию ТЕНДЕНЦИЯ() .
Формула = ТЕНДЕНЦИЯ($C$23:$C$83;$B$23:$B$83;B23) возвращает расчетные (прогнозные) значения ŷi для заданного значения Хi из столбца В2 .
Примечание : Линию регрессии можно также построить с помощью функции ПРЕДСКАЗ() . Эта функция возвращает прогнозные значения ŷi, но, в отличие от функции ТЕНДЕНЦИЯ() работает только в случае одного регрессора. Функция ТЕНДЕНЦИЯ() может быть использована и в случае множественной регрессии (в этом случае 3-й аргумент функции должен быть ссылкой на диапазон, содержащий все значения Хi для выбранного наблюдения i).
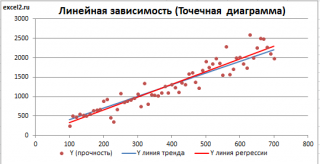
Как видно из диаграммы выше линия тренда и линия регрессии не обязательно совпадают: отклонения точек от линии тренда случайны, а МНК лишь подбирает линию наиболее точно аппроксимирующую случайные точки данных.
Линию регрессии можно построить и с помощью встроенных средств диаграммы, т.е. с помощью инструмента Линия тренда. Для этого выделите диаграмму, в меню выберите вкладку Макет , в группе Анализ нажмите Линия тренда , затем Линейное приближение. В диалоговом окне установите галочку Показывать уравнение на диаграмме (подробнее см. в статье про МНК ).
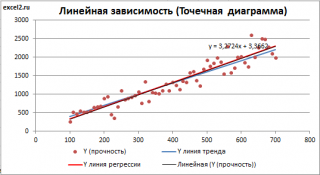
Построенная таким образом линия, разумеется, должна совпасть с ранее построенной нами линией регрессии, а параметры уравнения a и b должны совпасть с параметрами уравнения отображенными на диаграмме.
Примечание: Для того, чтобы вычисленные параметры уравнения a и b совпадали с параметрами уравнения на диаграмме, необходимо, чтобы тип у диаграммы был Точечная, а не График , т.к. тип диаграммы График не использует значения Х, а вместо значений Х используется последовательность 1; 2; 3; . Именно эти значения и берутся при расчете параметров линии тренда . Убедиться в этом можно если построить диаграмму График (см. файл примера ), а значения Хнач и Хшаг установить равным 1. Только в этом случае параметры уравнения на диаграмме совпадут с a и b .
Коэффициент детерминации R 2
Коэффициент детерминации R 2 показывает насколько полезна построенная нами линейная регрессионная модель .
Предположим, что у нас есть n значений переменной Y и мы хотим предсказать значение yi, но без использования значений переменной Х (т.е. без построения регрессионной модели ). Очевидно, что лучшей оценкой для yi будет среднее значение ȳ. Соответственно, ошибка предсказания будет равна (yi — ȳ).
Примечание : Далее будет использована терминология и обозначения дисперсионного анализа .
После построения регрессионной модели для предсказания значения yi мы будем использовать значение ŷi=a*xi+b. Ошибка предсказания теперь будет равна (yi — ŷi).
Теперь с помощью диаграммы сравним ошибки предсказания полученные без построения модели и с помощью модели.
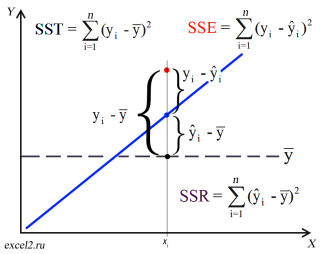
Очевидно, что используя регрессионную модель мы уменьшили первоначальную (полную) ошибку (yi — ȳ) на значение (ŷi — ȳ) до величины (yi — ŷi).
(yi — ŷi) – это оставшаяся, необъясненная ошибка.
Очевидно, что все три ошибки связаны выражением:
(yi — ȳ)= (ŷi — ȳ) + (yi — ŷi)
Можно показать, что в общем виде справедливо следующее выражение:
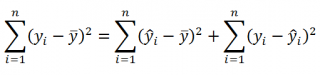
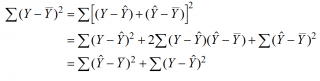
или в других, общепринятых в зарубежной литературе, обозначениях:
Total Sum of Squares = Regression Sum of Squares + Error Sum of Squares
Примечание : SS — Sum of Squares — Сумма Квадратов.
Как видно из формулы величины SST, SSR, SSE имеют размерность дисперсии (вариации) и соответственно описывают разброс (изменчивость): Общую изменчивость (Total variation), Изменчивость объясненную моделью (Explained variation) и Необъясненную изменчивость (Unexplained variation).
По определению коэффициент детерминации R 2 равен:
R 2 = Изменчивость объясненная моделью / Общая изменчивость.
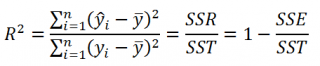
Этот показатель равен квадрату коэффициента корреляции и в MS EXCEL его можно вычислить с помощью функции КВПИРСОН() или ЛИНЕЙН() :
R 2 принимает значения от 0 до 1 (1 соответствует идеальной линейной зависимости Y от Х). Однако, на практике малые значения R2 вовсе не обязательно указывают, что переменную Х нельзя использовать для прогнозирования переменной Y. Малые значения R2 могут указывать на нелинейность связи или на то, что поведение переменной Y объясняется не только Х, но и другими факторами.
Стандартная ошибка регрессии
Стандартная ошибка регрессии ( Standard Error of a regression ) показывает насколько велика ошибка предсказания значений переменной Y на основании значений Х. Отдельные значения Yi мы можем предсказывать лишь с точностью +/- несколько значений (обычно 2-3, в зависимости от формы распределения ошибки ε).
Теперь вспомним уравнение линейной регрессионной модели Y=a*X+β+ε. Ошибка ε имеет случайную природу, т.е. является случайной величиной и поэтому имеет свою функцию распределения со средним значением μ и дисперсией σ 2 .
Оценив значение дисперсии σ 2 и вычислив из нее квадратный корень – получим Стандартную ошибку регрессии. Чем точки наблюдений на диаграмме рассеяния ближе находятся к прямой линии, тем меньше Стандартная ошибка.
Примечание : Вспомним , что при построении модели предполагается, что среднее значение ошибки ε равно 0, т.е. E[ε]=0.
Оценим дисперсию σ 2 . Помимо вычисления Стандартной ошибки регрессии эта оценка нам потребуется в дальнейшем еще и при построении доверительных интервалов для оценки параметров регрессии a и b .
Для оценки дисперсии ошибки ε используем остатки регрессии — разности между имеющимися значениями yi и значениями, предсказанными регрессионной моделью ŷ. Чем лучше регрессионная модель согласуется с данными (точки располагается близко к прямой линии), тем меньше величина остатков.
Для оценки дисперсии σ 2 используют следующую формулу:
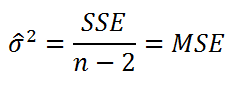
где SSE – сумма квадратов значений ошибок модели ε i =yi — ŷi ( Sum of Squared Errors ).
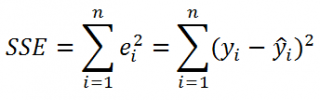
SSE часто обозначают и как SSres – сумма квадратов остатков ( Sum of Squared residuals ).
Оценка дисперсии s 2 также имеет общепринятое обозначение MSE (Mean Square of Errors), т.е. среднее квадратов ошибок или MSRES (Mean Square of Residuals), т.е. среднее квадратов остатков . Хотя правильнее говорить сумме квадратов остатков, т.к. ошибка чаще ассоциируется с ошибкой модели ε, которая является непрерывной случайной величиной. Но, здесь мы будем использовать термины SSE и MSE, предполагая, что речь идет об остатках.
Примечание : Напомним, что когда мы использовали МНК для нахождения параметров модели, то критерием оптимизации была минимизация именно SSE (SSres). Это выражение представляет собой сумму квадратов расстояний между наблюденными значениями yi и предсказанными моделью значениями ŷi, которые лежат на линии регрессии.
Математическое ожидание случайной величины MSE равно дисперсии ошибки ε, т.е. σ 2 .
Чтобы понять почему SSE выбрана в качестве основы для оценки дисперсии ошибки ε, вспомним, что σ 2 является также дисперсией случайной величины Y (относительно среднего значения μy, при заданном значении Хi). А т.к. оценкой μy является значение ŷi = a * Хi + b (значение уравнения регрессии при Х= Хi), то логично использовать именно SSE в качестве основы для оценки дисперсии σ 2 . Затем SSE усредняется на количество точек данных n за вычетом числа 2. Величина n-2 – это количество степеней свободы ( df – degrees of freedom ), т.е. число параметров системы, которые могут изменяться независимо (вспомним, что у нас в этом примере есть n независимых наблюдений переменной Y). В случае простой линейной регрессии число степеней свободы равно n-2, т.к. при построении линии регрессии было оценено 2 параметра модели (на это было «потрачено» 2 степени свободы ).
Итак, как сказано было выше, квадратный корень из s 2 имеет специальное название Стандартная ошибка регрессии ( Standard Error of a regression ) и обозначается SEy. SEy показывает насколько велика ошибка предсказания. Отдельные значения Y мы можем предсказывать с точностью +/- несколько значений SEy (см. этот раздел ). Если ошибки предсказания ε имеют нормальное распределение , то примерно 2/3 всех предсказанных значений будут на расстоянии не больше SEy от линии регрессии . SEy имеет размерность переменной Y и откладывается по вертикали. Часто на диаграмме рассеяния строят границы предсказания соответствующие +/- 2 SEy (т.е. 95% точек данных будут располагаться в пределах этих границ).
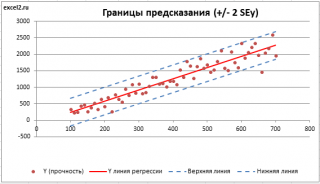
В MS EXCEL стандартную ошибку SEy можно вычислить непосредственно по формуле:
= КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))
или с помощью функции ЛИНЕЙН() :
Примечание : Подробнее о функции ЛИНЕЙН() см. эту статью .
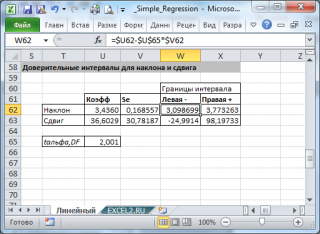
Стандартные ошибки и доверительные интервалы для наклона и сдвига
В разделе Оценка неизвестных параметров линейной модели мы получили точечные оценки наклона а и сдвига b . Так как эти оценки получены на основе случайных величин (значений переменных Х и Y), то эти оценки сами являются случайными величинами и соответственно имеют функцию распределения со средним значением и дисперсией . Но, чтобы перейти от точечных оценок к интервальным , необходимо вычислить соответствующие стандартные ошибки (т.е. стандартные отклонения ).
Стандартная ошибка коэффициента регрессии a вычисляется на основании стандартной ошибки регрессии по следующей формуле:
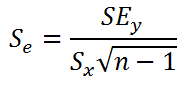
где Sx – стандартное отклонение величины х, вычисляемое по формуле:
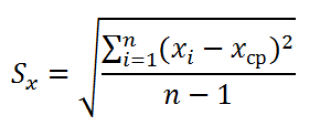
где Sey – стандартная ошибка регрессии, т.е. ошибка предсказания значения переменой Y ( см. выше ).
В MS EXCEL стандартную ошибку коэффициента регрессии Se можно вычислить впрямую по вышеуказанной формуле:
= КОРЕНЬ(СУММКВРАЗН(C23:C83; ТЕНДЕНЦИЯ(C23:C83;B23:B83;B23:B83)) /( СЧЁТ(B23:B83) -2))/ СТАНДОТКЛОН.В(B23:B83) /КОРЕНЬ(СЧЁТ(B23:B83) -1)
или с помощью функции ЛИНЕЙН() :
Формулы приведены в файле примера на листе Линейный в разделе Регрессионная статистика .
Примечание : Подробнее о функции ЛИНЕЙН() см. эту статью .
При построении двухстороннего доверительного интервала для коэффициента регрессии его границы определяются следующим образом:
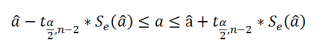
где — квантиль распределения Стьюдента с n-2 степенями свободы. Величина а с «крышкой» является другим обозначением наклона а .
Например для уровня значимости альфа=0,05, можно вычислить с помощью формулы =СТЬЮДЕНТ.ОБР.2Х(0,05;n-2)
Вышеуказанная формула следует из того факта, что если ошибки регрессии распределены нормально и независимо, то выборочное распределение случайной величины
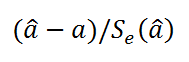
является t-распределением Стьюдента с n-2 степенью свободы (то же справедливо и для наклона b ).
Примечание : Подробнее о построении доверительных интервалов в MS EXCEL можно прочитать в этой статье Доверительные интервалы в MS EXCEL .
В результате получим, что найденный доверительный интервал с вероятностью 95% (1-0,05) накроет истинное значение коэффициента регрессии. Здесь мы считаем, что коэффициент регрессии a имеет распределение Стьюдента с n-2 степенями свободы (n – количество наблюдений, т.е. пар Х и Y).
Примечание : Подробнее о построении доверительных интервалов с использованием t-распределения см. статью про построение доверительных интервалов для среднего .
Стандартная ошибка сдвига b вычисляется по следующей формуле:
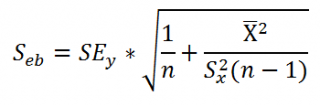
В MS EXCEL стандартную ошибку сдвига Seb можно вычислить с помощью функции ЛИНЕЙН() :
При построении двухстороннего доверительного интервала для сдвига его границы определяются аналогичным образом как для наклона : b +/- t*Seb.
Проверка значимости взаимосвязи переменных
Когда мы строим модель Y=αX+β+ε мы предполагаем, что между Y и X существует линейная взаимосвязь. Однако, как это иногда бывает в статистике, можно вычислять параметры связи даже тогда, когда в действительности она не существует, и обусловлена лишь случайностью.
Единственный вариант, когда Y не зависит X (в рамках модели Y=αX+β+ε), возможен, когда коэффициент регрессии a равен 0.
Чтобы убедиться, что вычисленная нами оценка наклона прямой линии не обусловлена лишь случайностью (не случайно отлична от 0), используют проверку гипотез . В качестве нулевой гипотезы Н 0 принимают, что связи нет, т.е. a=0. В качестве альтернативной гипотезы Н 1 принимают, что a <>0.
Ниже на рисунках показаны 2 ситуации, когда нулевую гипотезу Н 0 не удается отвергнуть.
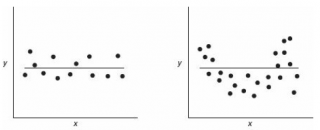
На левой картинке отсутствует любая зависимость между переменными, на правой – связь между ними нелинейная, но при этом коэффициент линейной корреляции равен 0.
Ниже — 2 ситуации, когда нулевая гипотеза Н 0 отвергается.
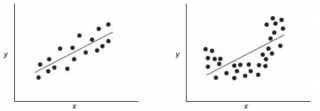
На левой картинке очевидна линейная зависимость, на правой — зависимость нелинейная, но коэффициент корреляции не равен 0 (метод МНК вычисляет показатели наклона и сдвига просто на основании значений выборки).
Для проверки гипотезы нам потребуется:
- Установить уровень значимости , пусть альфа=0,05;
- Рассчитать с помощью функции ЛИНЕЙН() стандартное отклонение Se для коэффициента регрессии (см. предыдущий раздел );
- Рассчитать число степеней свободы: DF=n-2 или по формуле = ИНДЕКС(ЛИНЕЙН(C24:C84;B24:B84;;ИСТИНА);4;2)
- Вычислить значение тестовой статистики t 0 =a/S e , которая имеет распределение Стьюдента с числом степеней свободы DF=n-2;
- Сравнить значение тестовой статистики |t0| с пороговым значением t альфа ,n-2. Если значение тестовой статистики больше порогового значения, то нулевая гипотеза отвергается ( наклон не может быть объяснен лишь случайностью при заданном уровне альфа) либо
- вычислить p-значение и сравнить его с уровнем значимости .
В файле примера приведен пример проверки гипотезы:
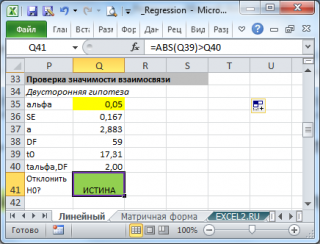
Изменяя наклон тренда k (ячейка В8 ) можно убедиться, что при малых углах тренда (например, 0,05) тест часто показывает, что связь между переменными случайна. При больших углах (k>1), тест практически всегда подтверждает значимость линейной связи между переменными.
Примечание : Проверка значимости взаимосвязи эквивалентна проверке статистической значимости коэффициента корреляции . В файле примера показана эквивалентность обоих подходов. Также проверку значимости можно провести с помощью процедуры F-тест .
Доверительные интервалы для нового наблюдения Y и среднего значения
Вычислив параметры простой линейной регрессионной модели Y=aX+β+ε мы получили точечную оценку значения нового наблюдения Y при заданном значении Хi, а именно: Ŷ= a * Хi + b
Ŷ также является точечной оценкой для среднего значения Yi при заданном Хi. Но, при построении доверительных интервалов используются различные стандартные ошибки .
Стандартная ошибка нового наблюдения Y при заданном Хi учитывает 2 источника неопределенности:
- неопределенность связанную со случайностью оценок параметров модели a и b ;
- случайность ошибки модели ε.
Учет этих неопределенностей приводит к стандартной ошибке S(Y|Xi), которая рассчитывается с учетом известного значения Xi.
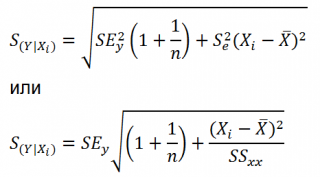
где SS xx – сумма квадратов отклонений от среднего значений переменной Х:
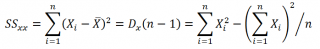
В MS EXCEL 2010 нет функции, которая бы рассчитывала эту стандартную ошибку , поэтому ее необходимо рассчитывать по вышеуказанным формулам.
Доверительный интервал или Интервал предсказания для нового наблюдения (Prediction Interval for a New Observation) построим по схеме показанной в разделе Проверка значимости взаимосвязи переменных (см. файл примера лист Интервалы ). Т.к. границы интервала зависят от значения Хi (точнее от расстояния Хi до среднего значения Х ср ), то интервал будет постепенно расширяться при удалении от Х ср .
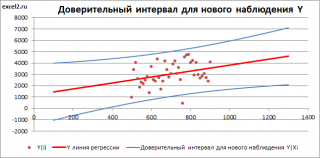
Границы доверительного интервала для нового наблюдения рассчитываются по формуле:
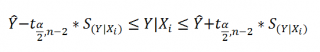
Аналогичным образом построим доверительный интервал для среднего значения Y при заданном Хi (Confidence Interval for the Mean of Y). В этом случае доверительный интервал будет уже, т.к. средние значения имеют меньшую изменчивость по сравнению с отдельными наблюдениями ( средние значения, в рамках нашей линейной модели Y=aX+β+ε, не включают ошибку ε).
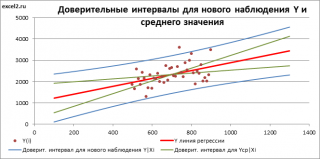
Стандартная ошибка S(Yср|Xi) вычисляется по практически аналогичным формулам как и стандартная ошибка для нового наблюдения:
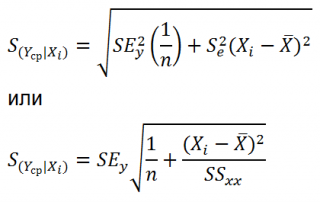
Как видно из формул, стандартная ошибка S(Yср|Xi) меньше стандартной ошибки S(Y|Xi) для индивидуального значения .
Границы доверительного интервала для среднего значения рассчитываются по формуле:
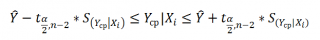
Проверка адекватности линейной регрессионной модели
Модель адекватна, когда все предположения, лежащие в ее основе, выполнены (см. раздел Предположения линейной регрессионной модели ).
Проверка адекватности модели в основном основана на исследовании остатков модели (model residuals), т.е. значений ei=yi – ŷi для каждого Хi. В рамках простой линейной модели n остатков имеют только n-2 связанных с ними степеней свободы . Следовательно, хотя, остатки не являются независимыми величинами, но при достаточно большом n это не оказывает какого-либо влияния на проверку адекватности модели.
Чтобы проверить предположение о нормальности распределения ошибок строят график проверки на нормальность (Normal probability Plot).
В файле примера на листе Адекватность построен график проверки на нормальность . В случае нормального распределения значения остатков должны быть близки к прямой линии.
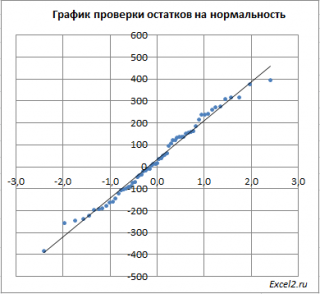
Так как значения переменной Y мы генерировали с помощью тренда , вокруг которого значения имели нормальный разброс, то ожидать сюрпризов не приходится – значения остатков располагаются вблизи прямой.
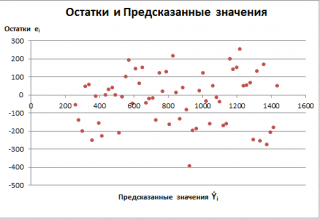
Также при проверке модели на адекватность часто строят график зависимости остатков от предсказанных значений Y. Если точки не демонстрируют характерных, так называемых «паттернов» (шаблонов) типа вор о нок или другого неравномерного распределения, в зависимости от значений Y, то у нас нет очевидных доказательств неадекватности модели.
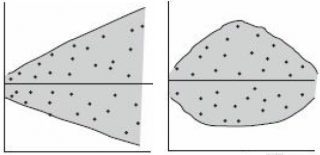
В нашем случае точки располагаются примерно равномерно.
Часто при проверке адекватности модели вместо остатков используют нормированные остатки. Как показано в разделе Стандартная ошибка регрессии оценкой стандартного отклонения ошибок является величина SEy равная квадратному корню из величины MSE. Поэтому логично нормирование остатков проводить именно на эту величину.
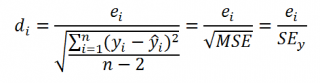
SEy можно вычислить с помощью функции ЛИНЕЙН() :
Иногда нормирование остатков производится на величину стандартного отклонения остатков (это мы увидим в статье об инструменте Регрессия , доступного в надстройке MS EXCEL Пакет анализа ), т.е. по формуле:
Вышеуказанное равенство приблизительное, т.к. среднее значение остатков близко, но не обязательно точно равно 0.
Решаем уравнение простой линейной регрессии
В статье рассматривается несколько способов определения математического уравнения линии простой (парной) регрессии.
Все рассматриваемые здесь способы решения уравнения основаны на методе наименьших квадратов. Обозначим способы следующим образом:
- Аналитическое решение
- Градиентный спуск
- Стохастический градиентный спуск
Для каждого из способов решения уравнения прямой, в статье приведены различные функции, которые в основном делятся на те, которые написаны без использования библиотеки NumPy и те, которые для проведения расчетов применяют NumPy. Считается, что умелое использование NumPy позволит сократить затраты на вычисления.
Весь код, приведенный в статье, написан на языке python 2.7 с использованием Jupyter Notebook. Исходный код и файл с данными выборки выложен на гитхабе
Статья в большей степени ориентирована как на начинающих, так и на тех, кто уже понемногу начал осваивать изучение весьма обширного раздела в искусственном интеллекте — машинного обучения.
Для иллюстрации материала используем очень простой пример.
Условия примера
У нас есть пять значений, которые характеризуют зависимость Y от X (Таблица №1):
Таблица №1 «Условия примера»

Будем считать, что значения  — это месяц года, а
— это месяц года, а  — выручка в этом месяце. Другими словами, выручка зависит от месяца года, а — единственный признак, от которого зависит выручка.
— выручка в этом месяце. Другими словами, выручка зависит от месяца года, а — единственный признак, от которого зависит выручка.
Пример так себе, как с точки зрения условной зависимости выручки от месяца года, так и с точки зрения количества значений — их очень мало. Однако такое упрощение позволит, что называется на пальцах, объяснить, не всегда с легкостью, усваиваемый новичками материал. А также простота чисел позволит без весомых трудозатрат, желающим, порешать пример на «бумаге».
Предположим, что приведенная в примере зависимость, может быть достаточно хорошо аппроксимирована математическим уравнением линии простой (парной) регрессии вида:

где  — это месяц, в котором была получена выручка,
— это месяц, в котором была получена выручка,  — выручка, соответствующая месяцу,
— выручка, соответствующая месяцу,  и
и  — коэффициенты регрессии оцененной линии.
— коэффициенты регрессии оцененной линии.
Отметим, что коэффициент часто называют угловым коэффициентом или градиентом оцененной линии; представляет собой величину, на которую изменится при изменении .
Очевидно, что наша задача в примере — подобрать в уравнении такие коэффициенты и , при которых отклонения наших расчетных значений выручки по месяцам от истинных ответов, т.е. значений, представленных в выборке, будут минимальны.
Метод наименьших квадратов
В соответствии с методом наименьших квадратов, отклонение стоит рассчитывать, возводя его в квадрат. Подобный прием позволяет избежать взаимного погашения отклонений, в том случае, если они имеют противоположные знаки. Например, если в одном случае, отклонение составляет +5 (плюс пять), а в другом -5 (минус пять), то сумма отклонений взаимно погасится и составит 0 (ноль). Можно и не возводить отклонение в квадрат, а воспользоваться свойством модуля и тогда у нас все отклонения будут положительными и будут накапливаться. Мы не будем останавливаться на этом моменте подробно, а просто обозначим, что для удобства расчетов, принято возводить отклонение в квадрат.
Вот так выглядит формула, с помощью которой мы определим наименьшую сумму квадратов отклонений (ошибки):

где  — это функция аппроксимации истинных ответов (то есть посчитанная нами выручка),
— это функция аппроксимации истинных ответов (то есть посчитанная нами выручка),
— это истинные ответы (предоставленная в выборке выручка),
 — это индекс выборки (номер месяца, в котором происходит определение отклонения)
— это индекс выборки (номер месяца, в котором происходит определение отклонения)
Продифференцируем функцию, определим уравнения частных производных и будем готовы перейти к аналитическому решению. Но для начала проведем небольшой экскурс о том, что такое дифференцирование и вспомним геометрический смысл производной.
Дифференцирование
Дифференцированием называется операция по нахождению производной функции.
Для чего нужна производная? Производная функции характеризует скорость изменения функции и указывает нам ее направление. Если производная в заданной точке положительна, то функция возрастает, в обратном случае — функция убывает. И чем больше значение производной по модулю, тем выше скорость изменения значений функции, а также круче угол наклона графика функции.
Например, в условиях декартовой системы координат, значение производной в точке M(0,0) равное +25 означает, что в заданной точке, при смещении значения вправо на условную единицу, значение  возрастает на 25 условных единиц. На графике это выглядит, как достаточно крутой угол подъема значений с заданной точки.
возрастает на 25 условных единиц. На графике это выглядит, как достаточно крутой угол подъема значений с заданной точки.
Другой пример. Значение производной равное -0,1 означает, что при смещении на одну условную единицу, значение убывает всего лишь на 0,1 условную единицу. При этом, на графике функции, мы можем наблюдать едва заметный наклон вниз. Проводя аналогию с горой, то мы как будто очень медленно спускаемся по пологому склону с горы, в отличие от предыдущего примера, где нам приходилось брать очень крутые вершины:)
Таким образом, проведя дифференцирование функции  по коэффициентам и , определим уравнения частных производных 1-го порядка. После определения уравнений, мы получим систему из двух уравнений, решив которую мы сможем подобрать такие значения коэффициентов и , при которых значения соответствующих производных в заданных точках изменяются на очень и очень малую величину, а в случае с аналитическим решением не изменяются вовсе. Другими словами, функция ошибки при найденных коэффициентах достигнет минимума, так как значения частных производных в этих точках будут равны нулю.
по коэффициентам и , определим уравнения частных производных 1-го порядка. После определения уравнений, мы получим систему из двух уравнений, решив которую мы сможем подобрать такие значения коэффициентов и , при которых значения соответствующих производных в заданных точках изменяются на очень и очень малую величину, а в случае с аналитическим решением не изменяются вовсе. Другими словами, функция ошибки при найденных коэффициентах достигнет минимума, так как значения частных производных в этих точках будут равны нулю.
Итак, по правилам дифференцирования уравнение частной производной 1-го порядка по коэффициенту примет вид:

уравнение частной производной 1-го порядка по примет вид:

В итоге мы получили систему уравнений, которая имеет достаточно простое аналитическое решение:
\begin
\begin
na + b\sum\limits_
\\
\sum\limits_
\end
\end
Прежде чем решать уравнение, предварительно загрузим, проверим правильность загрузки и отформатируем данные.
Загрузка и форматирование данных
Необходимо отметить, что в связи с тем, что для аналитического решения, а в дальнейшем для градиентного и стохастического градиентного спуска, мы будем применять код в двух вариациях: с использованием библиотеки NumPy и без её использования, то нам потребуется соответствующее форматирование данных (см. код).
Визуализация
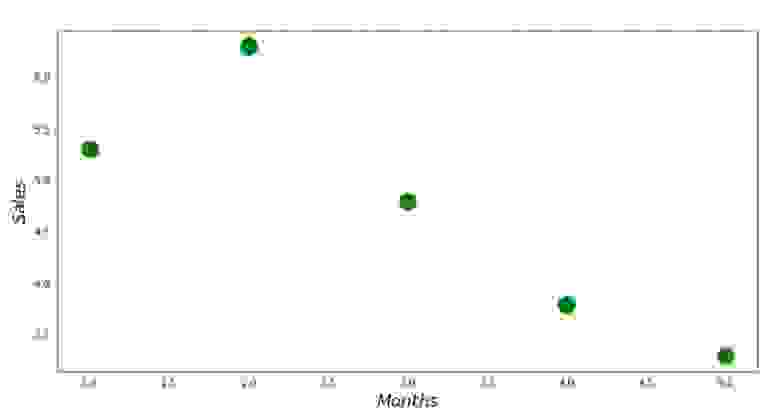
Теперь, после того, как мы, во-первых, загрузили данные, во-вторых, проверили правильность загрузки и наконец отформатировали данные, проведем первую визуализацию. Часто для этого используют метод pairplot библиотеки Seaborn. В нашем примере, ввиду ограниченности цифр нет смысла применять библиотеку Seaborn. Мы воспользуемся обычной библиотекой Matplotlib и посмотрим только на диаграмму рассеяния.
График №1 «Зависимость выручки от месяца года»
Аналитическое решение
Воспользуемся самыми обычными инструментами в python и решим систему уравнений:
\begin
\begin
na + b\sum\limits_
\\
\sum\limits_
\end
\end
По правилу Крамера найдем общий определитель, а также определители по и по , после чего, разделив определитель по на общий определитель — найдем коэффициент , аналогично найдем коэффициент .
Вот, что у нас получилось:

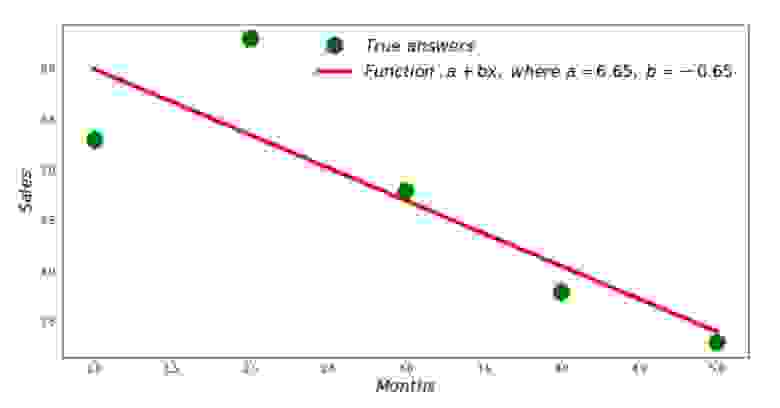
Итак, значения коэффициентов найдены, сумма квадратов отклонений установлена. Нарисуем на гистограмме рассеяния прямую линию в соответствии с найденными коэффициентами.
График №2 «Правильные и расчетные ответы»
Можно посмотреть на график отклонений за каждый месяц. В нашем случае, какой-либо значимой практической ценности мы из него не вынесем, но удовлетворим любопытство в том, насколько хорошо, уравнение простой линейной регрессии характеризует зависимость выручки от месяца года.
График №3 «Отклонения, %»
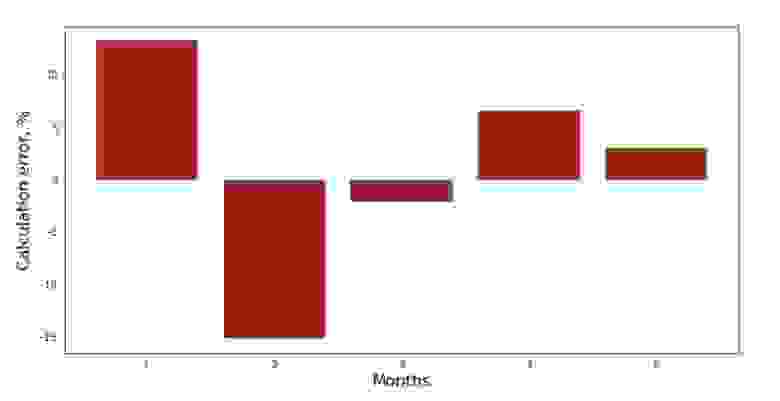
Не идеально, но нашу задачу мы выполнили.
Напишем функцию, которая для определения коэффициентов и использует библиотеку NumPy, точнее — напишем две функции: одну с использованием псевдообратной матрицы (не рекомендуется на практике, так как процесс вычислительно сложный и нестабильный), другую с использованием матричного уравнения.
Сравним время, которое было затрачено на определение коэффициентов и , в соответствии с 3-мя представленными способами.

На небольшом количестве данных, вперед выходит «самописная» функция, которая находит коэффициенты методом Крамера.
Теперь можно перейти к другим способам нахождения коэффициентов и .
Градиентный спуск
Для начала определим, что такое градиент. По-простому, градиент — это отрезок, который указывает направление максимального роста функции. По аналогии с подъемом в гору, то куда смотрит градиент, там и есть самый крутой подъем к вершине горы. Развивая пример с горой, вспоминаем, что на самом деле нам нужен самый крутой спуск, чтобы как можно быстрее достичь низины, то есть минимума — места где функция не возрастает и не убывает. В этом месте производная будет равна нулю. Следовательно, нам нужен не градиент, а антиградиент. Для нахождения антиградиента нужно всего лишь умножить градиент на -1 (минус один).
Обратим внимание на то, что функция может иметь несколько минимумов, и опустившись в один из них по предложенному далее алгоритму, мы не сможем найти другой минимум, который возможно находится ниже найденного. Расслабимся, нам это не грозит! В нашем случае мы имеем дело с единственным минимумом, так как наша функция  на графике представляет собой обычную параболу. А как мы все должны прекрасно знать из школьного курса математики — у параболы существует только один минимум.
на графике представляет собой обычную параболу. А как мы все должны прекрасно знать из школьного курса математики — у параболы существует только один минимум.
После того, как мы выяснили для чего нам потребовался градиент, а также то, что градиент — это отрезок, то есть вектор с заданными координатами, которые как раз являются теми самыми коэффициентами и мы можем реализовать градиентный спуск.
Перед запуском, предлагаю прочитать буквально несколько предложений об алгоритме спуска:
- Определяем псевдослучайным образом координаты коэффициентов
 и . В нашем примере, мы будем определять коэффициенты вблизи нуля. Это является распространённой практикой, однако для каждого случая может быть предусмотрена своя практика.
и . В нашем примере, мы будем определять коэффициенты вблизи нуля. Это является распространённой практикой, однако для каждого случая может быть предусмотрена своя практика. - От координаты вычитаем значение частной производной 1-го порядка в точке . Так, если производная будет положительная, то функция возрастает. Следовательно, отнимая значение производной, мы будем двигаться в обратную сторону роста, то есть в сторону спуска. Если производная отрицательна, значит функция в этой точке убывает и отнимая значение производной мы двигаемся в сторону спуска.
- Проводим аналогичную операцию с координатой : вычитаем значение частной производной в точке .
- Для того, чтобы не перескочить минимум и не улететь в далекий космос, необходимо установить размер шага в сторону спуска. В общем и целом, можно написать целую статью о том, как правильнее установить шаг и как его менять в процессе спуска, чтобы снизить затраты на вычисления. Но сейчас перед нами несколько иная задача, и мы научным методом «тыка» или как говорят в простонародье, эмпирическим путем, установим размер шага.
- После того, как мы из заданных координат и вычли значения производных, получаем новые координаты и . Делаем следующий шаг (вычитание), уже из рассчитанных координат. И так цикл запускается вновь и вновь, до тех пор, пока не будет достигнута требуемая сходимость.
Все! Теперь мы готовы отправиться на поиски самого глубокого ущелья Марианской впадины. Приступаем.

Мы погрузились на самое дно Марианской впадины и там обнаружили все те же значения коэффициентов и , что собственно и следовало ожидать.
Совершим еще одно погружение, только на этот раз, начинкой нашего глубоководного аппарата будут иные технологии, а именно библиотека NumPy.

Значения коэффициентов и неизменны.
Посмотрим на то, как изменялась ошибка при градиентном спуске, то есть как изменялась сумма квадратов отклонений с каждым шагом.
График №4 «Сумма квадратов отклонений при градиентном спуске»

На графике мы видим, что с каждым шагом ошибка уменьшается, а спустя какое-то количество итераций наблюдаем практически горизонтальную линию.
Напоследок оценим разницу во времени исполнения кода:
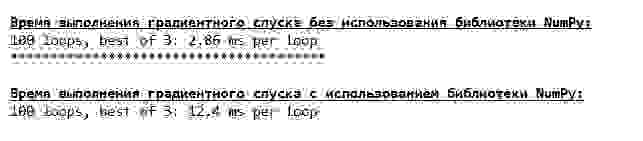
Возможно мы делаем что-то не то, но опять простая «самописная» функция, которая не использует библиотеку NumPy опережает по времени выполнения расчетов функцию, использующую библиотеку NumPy.
Но мы не стоим на месте, а двигаемся в сторону изучения еще одного увлекательного способа решения уравнения простой линейной регрессии. Встречайте!
Стохастический градиентный спуск
Для того, чтобы быстрее понять принцип работы стохастического градиентного спуска, лучше определить его отличия от обычного градиентного спуска. Мы, в случае с градиентным спуском, в уравнениях производных от и использовали суммы значений всех признаков и истинных ответов, имеющихся в выборке (то есть суммы всех и ). В стохастическом градиентном спуске мы не будем использовать все значения, имеющиеся в выборке, а вместо этого, псевдослучайным образом выберем так называемый индекс выборки и используем его значения.
Например, если индекс определился за номером 3 (три), то мы берем значения  и
и  , далее подставляем значения в уравнения производных и определяем новые координаты. Затем, определив координаты, мы опять псевдослучайным образом определяем индекс выборки, подставляем значения, соответствующие индексу в уравнения частных производных, по новому определяем координаты и и т.д. до
, далее подставляем значения в уравнения производных и определяем новые координаты. Затем, определив координаты, мы опять псевдослучайным образом определяем индекс выборки, подставляем значения, соответствующие индексу в уравнения частных производных, по новому определяем координаты и и т.д. до позеленения сходимости. На первый взгляд, может показаться, как это вообще может работать, однако работает. Правда стоит отметить, что не с каждым шагом уменьшается ошибка, но тенденция безусловно имеется.
Каковы преимущества стохастического градиентного спуска перед обычным? В случае, если у нас размер выборки очень велик и измеряется десятками тысяч значений, то значительно проще обработать, допустим случайную тысячу из них, нежели всю выборку. Вот в этом случае и запускается стохастический градиентный спуск. В нашем случае мы конечно же большой разницы не заметим.

Смотрим внимательно на коэффициенты и ловим себя на вопросе «Как же так?». У нас получились другие значения коэффициентов и . Может быть стохастический градиентный спуск нашел более оптимальные параметры уравнения? Увы, нет. Достаточно посмотреть на сумму квадратов отклонений и увидеть, что при новых значениях коэффициентов, ошибка больше. Не спешим отчаиваться. Построим график изменения ошибки.
График №5 «Сумма квадратов отклонений при стохастическом градиентном спуске»

Посмотрев на график, все становится на свои места и сейчас мы все исправим.
Итак, что же произошло? Произошло следующее. Когда мы выбираем случайным образом месяц, то именно для выбранного месяца наш алгоритм стремится уменьшить ошибку в расчете выручки. Затем выбираем другой месяц и повторяем расчет, но ошибку уменьшаем уже для второго выбранного месяца. А теперь вспомним, что у нас первые два месяца существенно отклоняются от линии уравнения простой линейной регрессии. Это значит, что когда выбирается любой из этих двух месяцев, то уменьшая ошибку каждого из них, наш алгоритм серьезно увеличивает ошибку по всей выборке. Так что же делать? Ответ простой: надо уменьшить шаг спуска. Ведь уменьшив шаг спуска, ошибка так же перестанет «скакать» то вверх, то вниз. Вернее, ошибка «скакать» не перестанет, но будет это делать не так прытко:) Проверим.

График №6 «Сумма квадратов отклонений при стохастическом градиентном спуске (80 тыс. шагов)»

Значения коэффициентов улучшились, но все равно не идеальны. Гипотетически это можно поправить таким образом. Выбираем, например, на последних 1000 итерациях значения коэффициентов, с которыми была допущена минимальная ошибка. Правда нам для этого придется записывать еще и сами значения коэффициентов. Мы не будем этого делать, а лучше обратим внимание на график. Он выглядит гладким, и ошибка как будто уменьшается равномерно. На самом деле это не так. Посмотрим на первые 1000 итераций и сравним их с последними.
График №7 «Сумма квадратов отклонений SGD (первые 1000 шагов)»
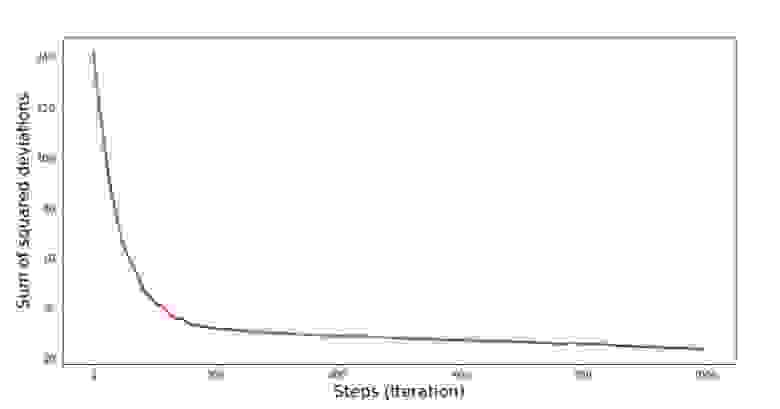
График №8 «Сумма квадратов отклонений SGD (последние 1000 шагов)»

В самом начале спуска мы наблюдаем достаточно равномерное и крутое уменьшение ошибки. На последних итерациях мы видим, что ошибка ходит вокруг да около значения в 1,475 и в некоторые моменты даже равняется этому оптимальному значению, но потом все равно уходит ввысь… Повторюсь, можно записывать значения коэффициентов и , а потом выбрать те, при которых ошибка минимальна. Однако у нас возникла проблема посерьезнее: нам пришлось сделать 80 тыс. шагов (см. код), чтобы получить значения, близкие к оптимальным. А это, уже противоречит идее об экономии времени вычислений при стохастическом градиентном спуске относительно градиентного. Что можно поправить и улучшить? Не трудно заметить, что на первых итерациях мы уверенно идем вниз и, следовательно, нам стоит оставить большой шаг на первых итерациях и по мере продвижения вперед шаг уменьшать. Мы не будем этого делать в этой статье — она и так уже затянулась. Желающие могут и сами подумать, как это сделать, это не сложно 🙂
Теперь выполним стохастический градиентный спуск, используя библиотеку NumPy (и не будем спотыкаться о камни, которые мы выявили раннее)

Значения получились почти такими же, как и при спуске без использования NumPy. Впрочем, это логично.
Узнаем сколько же времени занимали у нас стохастические градиентные спуски.

Чем дальше в лес, тем темнее тучи: опять «самописная» формула показывает лучший результат. Все это наводит на мысли о том, что должны существовать еще более тонкие способы использования библиотеки NumPy, которые действительно ускоряют операции вычислений. В этой статье мы о них уже не узнаем. Будет о чем подумать на досуге:)
Резюмируем
Перед тем как резюмировать, хотелось бы ответить на вопрос, который скорее всего, возник у нашего дорогого читателя. Для чего, собственно, такие «мучения» со спусками, зачем нам ходить по горе вверх и вниз (преимущественно вниз), чтобы найти заветную низину, если в наших руках такой мощный и простой прибор, в виде аналитического решения, который мгновенно телепортирует нас в нужное место?
Ответ на этот вопрос лежит на поверхности. Сейчас мы разбирали очень простой пример, в котором истинный ответ зависит от одного признака . В жизни такое встретишь не часто, поэтому представим, что у нас признаков 2, 30, 50 или более. Добавим к этому тысячи, а то и десятки тысяч значений для каждого признака. В этом случае аналитическое решение может не выдержать испытания и дать сбой. В свою очередь градиентный спуск и его вариации будут медленно, но верно приближать нас к цели — минимуму функции. А на счет скорости не волнуйтесь — мы наверняка еще разберем способы, которые позволят нам задавать и регулировать длину шага (то есть скорость).
А теперь собственно краткое резюме.
Во-первых, надеюсь, что изложенный в статье материал, поможет начинающим «дата сайнтистам» в понимании того, как решать уравнения простой (и не только) линейной регрессии.
Во-вторых, мы рассмотрели несколько способов решения уравнения. Теперь, в зависимости от ситуации, мы можем выбрать тот, который лучше всего подходит для решения поставленной задачи.
В-третьих, мы увидели силу дополнительных настроек, а именно длины шага градиентного спуска. Этим параметром нельзя пренебрегать. Как было подмечено выше, с целью сокращения затрат на проведение вычислений, длину шага стоит изменять по ходу спуска.
В-четвертых, в нашем случае, «самописные» функции показали лучший временной результат вычислений. Вероятно, это связано с не самым профессиональным применением возможностей библиотеки NumPy. Но как бы то ни было, вывод напрашивается следующий. С одной стороны, иногда стоит подвергать сомнению устоявшиеся мнения, а с другой — не всегда стоит все усложнять — наоборот иногда эффективнее оказывается более простой способ решения задачи. А так как цель у нас была разобрать три подхода в решении уравнения простой линейной регрессии, то использование «самописных» функций нам вполне хватило.
 Предыдущая работа автора — «Исследуем утверждение центральной предельной теоремы с помощью экспоненциального распределения»
Предыдущая работа автора — «Исследуем утверждение центральной предельной теоремы с помощью экспоненциального распределения»  Следующая работа автора — «Приводим уравнение линейной регрессии в матричный вид»
Следующая работа автора — «Приводим уравнение линейной регрессии в матричный вид»
http://excel2.ru/articles/prostaya-lineynaya-regressiya-v-ms-excel
http://habr.com/ru/post/474602/