Корреляция и регрессия
Линейное уравнение регрессии имеет вид y=bx+a+ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид:
10a + 356b = 49
356a + 2135b = 9485
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 68.16, a = 11.17
Уравнение регрессии:
y = 68.16 x — 11.17
1. Параметры уравнения регрессии.
Выборочные средние.
1.1. Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 Y фактором X весьма высокая и прямая.
1.2. Уравнение регрессии (оценка уравнения регрессии).
Линейное уравнение регрессии имеет вид y = 68.16 x -11.17
Коэффициентам уравнения линейной регрессии можно придать экономический смысл. Коэффициент уравнения регрессии показывает, на сколько ед. изменится результат при изменении фактора на 1 ед.
Коэффициент b = 68.16 показывает среднее изменение результативного показателя (в единицах измерения у ) с повышением или понижением величины фактора х на единицу его измерения. В данном примере с увеличением на 1 единицу y повышается в среднем на 68.16.
Коэффициент a = -11.17 формально показывает прогнозируемый уровень у , но только в том случае, если х=0 находится близко с выборочными значениями.
Но если х=0 находится далеко от выборочных значений x , то буквальная интерпретация может привести к неверным результатам, и даже если линия регрессии довольно точно описывает значения наблюдаемой выборки, нет гарантий, что также будет при экстраполяции влево или вправо.
Подставив в уравнение регрессии соответствующие значения x , можно определить выровненные (предсказанные) значения результативного показателя y(x) для каждого наблюдения.
Связь между у и x определяет знак коэффициента регрессии b (если > 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
1.3. Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
В нашем примере коэффициент эластичности больше 1. Следовательно, при изменении Х на 1%, Y изменится более чем на 1%. Другими словами — Х существенно влияет на Y.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению среднего Y на 0.9796 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве регрессии.
1.6. Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.98 2 = 0.9596, т.е. в 95.96 % случаев изменения x приводят к изменению у . Другими словами — точность подбора уравнения регрессии — высокая. Остальные 4.04 % изменения Y объясняются факторами, не учтенными в модели.
| x | y | x 2 | y 2 | x·y | y(x) | (yi— y ) 2 | (y-y(x)) 2 | (xi— x ) 2 | |y — yx|:y |
| 0.371 | 15.6 | 0.1376 | 243.36 | 5.79 | 14.11 | 780.89 | 2.21 | 0.1864 | 0.0953 |
| 0.399 | 19.9 | 0.1592 | 396.01 | 7.94 | 16.02 | 559.06 | 15.04 | 0.163 | 0.1949 |
| 0.502 | 22.7 | 0.252 | 515.29 | 11.4 | 23.04 | 434.49 | 0.1176 | 0.0905 | 0.0151 |
| 0.572 | 34.2 | 0.3272 | 1169.64 | 19.56 | 27.81 | 87.32 | 40.78 | 0.0533 | 0.1867 |
| 0.607 | 44.5 | .3684 | 1980.25 | 27.01 | 30.2 | 0.9131 | 204.49 | 0.0383 | 0.3214 |
| 0.655 | 26.8 | 0.429 | 718.24 | 17.55 | 33.47 | 280.38 | 44.51 | 0.0218 | 0.2489 |
| 0.763 | 35.7 | 0.5822 | 1274.49 | 27.24 | 40.83 | 61.54 | 26.35 | 0.0016 | 0.1438 |
| 0.873 | 30.6 | 0.7621 | 936.36 | 26.71 | 48.33 | 167.56 | 314.39 | 0.0049 | 0.5794 |
| 2.48 | 161.9 | 6.17 | 26211.61 | 402 | 158.07 | 14008.04 | 14.66 | 2.82 | 0.0236 |
| 7.23 | 391.9 | 9.18 | 33445.25 | 545.2 | 391.9 | 16380.18 | 662.54 | 3.38 | 1.81 |
2. Оценка параметров уравнения регрессии.
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=7 находим tкрит:
tкрит = (7;0.05) = 1.895
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 94.6484 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
Sy = 9.7287 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя. (a + bxp ± ε) где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 1 (-11.17 + 68.16*1 ± 6.4554)
(50.53;63.44)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
Индивидуальные доверительные интервалы для Y при данном значении X.
(a + bx i ± ε)
где
| xi | y = -11.17 + 68.16xi | εi | ymin | ymax |
| 0.371 | 14.11 | 19.91 | -5.8 | 34.02 |
| 0.399 | 16.02 | 19.85 | -3.83 | 35.87 |
| 0.502 | 23.04 | 19.67 | 3.38 | 42.71 |
| 0.572 | 27.81 | 19.57 | 8.24 | 47.38 |
| 0.607 | 30.2 | 19.53 | 10.67 | 49.73 |
| 0.655 | 33.47 | 19.49 | 13.98 | 52.96 |
| 0.763 | 40.83 | 19.44 | 21.4 | 60.27 |
| 0.873 | 48.33 | 19.45 | 28.88 | 67.78 |
| 2.48 | 158.07 | 25.72 | 132.36 | 183.79 |
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (7;0.05) = 1.895
Поскольку 12.8866 > 1.895, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 2.0914 > 1.895, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(68.1618 — 1.895 • 5.2894; 68.1618 + 1.895 • 5.2894)
(58.1385;78.1852)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a — ta)
(-11.1744 — 1.895 • 5.3429; -11.1744 + 1.895 • 5.3429)
(-21.2992;-1.0496)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с lang=EN-US>n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=7, Fkp = 5.59
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Проверка на наличие автокорреляции остатков.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция) определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция, нежели отрицательная автокорреляция. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения ei с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения ei (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скоре всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости ei от ei-1.
Пояснить смысл коэффициентов уравнения регрессии
Регрессионный анализ позволяет приближенно определить форму связи между результативным и факторными признаками, а также решить вопрос о том, значима ли эта связь. Вид функции, с помощью которой приближенно выражается форма связи, выбирают заранее, исходя из содержательных соображений или визуального анализа данных. Математическое решение задачи основано на методе наименьших квадратов.
Суть метода наименьших квадратов. Рассмотрим содержание метода на конкретном примере. Пусть имеются данные о сборе хлеба на душу населения по совокупности черноземных губерний. От каких факторов зависит величина этого сбора? Вероятно, определяющее влияние на величину сбора хлеба оказывает величина посева и уровень урожайности. Рассмотрим сначала зависимость величины сбора хлеба на душу населения от размера посева на душу ( столбцы 1 и 2 табл .4 ) Попытаемся представить интересующую нас зависимость с помощью прямой линии. Разумеется, такая линия может дать только приближенное представление о форме реальной статистической связи. Постараемся сделать это приближение наилучшим. Оно будет тем лучше, чем меньше исходные данные будут отличаться от соответствующих точек, лежащих на линии. Степень близости может быть выражена величиной суммы квадратов отклонении, реальных значений от, расположенных на прямой. Использование именно квадратов отклонений (не просто отклонений) позволяет суммировать отклонения различных знаков без их взаимного погашения и дополнительно обеспечивает сравнительно большее внимание, уделяемое большим отклонениям. Именно этот критерий (минимизация суммы квадратов отклонений) положен в основу метода наименьших квадратов.
В вычислительном аспекте метод наименьших квадратов сводится к составлению и решению системы так называемых нормальных уравнений. Исходным этапом для этого является подбор вида функции, отображающей статистическую связь.
Тип функции в каждом конкретном случае можно подобрать путем прикидки на графике исходных данных подходящей, т. е. достаточно хорошо приближающей эти данные, линии. В нашем случае связь между сбором хлеба на душу и величиной посева на душу может быть изображена с помощью прямой линии ( рис. 14 ) и записана в виде
где у—величина сбора хлеба на душу (результативный признак или зависимая переменная); x—величина посева на душу (факторный признак или независимая переменная); a o и a 1 — параметры уравнения, которые могут быть найдены методом наименьших квадратов.
Для нахождения искомых параметров нужно составить систему уравнений, которая в данном случае будет иметь вид
Полученная система может быть решена известным из школьного курса методом Гаусса. Искомые параметры системы из двух нормальных уравнений можно вычислить и непосредственно с помощью последовательного использования нижеприведенных формул:
где y i — i-e значение результативного признака; x i — i-e значение факторного признака; и — средние арифметические результативного и факторного признаков соответственно; n— число значений признака y i , или, что то же самое, число значений признака x i .
Пример 9. Найдем уравнение линейной связи между величиной сбора хлеба (у) и размером посева (х) по данным табл. 4. Проделав необходимые вычисления, получим из (6.17):
Таким образом, уравнение связи, или, как принято говорить, уравнение регрессии, выглядит следующим образом:
Интерпретация коэффициента регрессии. Уравнение регрессии не только определяет форму анализируемой связи, но и показывает, в какой степени изменение одного признака сопровождается изменением другого признака.
Коэффициент при х, называемый коэффициентом регрессии, показывает, на какую величину в среднем изменяется результативный признак у при изменении факторного признака х на единицу.
В примере 9 коэффициент регрессии получился равным 24,58. Следовательно, с увеличением посева, приходящегося на душу, на одну десятину сбор хлеба на душу населения в среднем увеличивается на 24,58 пуда.
Средняя и предельная ошибки коэффициента регрессии. Поскольку уравнения регрессии рассчитываются, как правило, для выборочных данных, обязательно встают вопросы точности и надежности полученных результатов. Вычисленный коэффициент регрессии, будучи выборочным, с некоторой точностью оценивает соответствующий коэффициент регрессии генеральной совокупности. Представление об этой точности дает средняя ошибка коэффициента регрессии ( ), рассчитываемая по формуле
у i , — i-e значение результативного признака; ŷ i — i-e выравненное значение, полученное из уравнения (6.15); x i —i-e значение факторного признака; σ x —среднее квадратическое отклонение х; n — число значений х или, что то же самое, значений у; m—число факгорных признаков (независимых переменных).
В формуле (6.18), в частности, формализовано очевидное положение: чем больше фактические значения отклоняются от выравненных, тем большую ошибку следует ожидать; чем меньше число наблюдений, на основе которых строится уравнение, тем больше будет ошибка.
Средняя ошибка коэффициента регрессии является основой для расчета предельной ошибки. Последняя показывает, в каких пределах находится истинное значение коэффициента регрессии при заданной надежности результатов. Предельная ошибка коэффициента регрессии вычисляется аналогично предельной ошибке средней арифметической (см. гл. 5), т. е. как t где t—величина, числовое значение которой определяется в зависимости от принятого уровня надежности.
Пример 10. Найти среднюю и предельную ошибки коэффициента регрессии, полученного в примере 9.
Для расчета прежде всего подсчитаем выравненные значения ŷ i для чего в уравнение регрессии, полученное в примере 9, подставим конкретные значения x i :
ŷ i = 17,6681 +24,5762*0,91 = 40,04 и т. д.
Затем вычислим отклонения фактических значений у i , от выравненных и их квадраты
Далее, подсчитав средний по черноземным губерниям посев на душу ( =0,98), отклонения фактических значений x i от этой средней, квадраты отклонений и среднее квадратическое отклонение , получим все необходимые составляющие формул (618) и (619):
Таким образом, средняя ошибка коэффициента регрессии равна 2,89, что составляет 12% от вычисленного коэффициента
Задавшись уровнем надежности, равным 0,95, найдем по табл. 1 приложения соответствующее ему значение t=1,96, рассчитаем предельную ошибку 1,96*2,89=5,66 и пределы коэффициента регрессии для принятого уровня надежности ( В случае малых выборок величина t находится из табл. 2 приложения. ). Нижняя граница коэффициента регрессии равна 24,58-5,66=18,92, а верхняя граница 24,58+5,66=30,24
Средняя квадратическая ошибка линии регрессии. Уравнение регрессии представляет собой функциональную связь, при которой по любому значению х можно однозначно определить значение у. Функциональная связь лишь приближенно отражает связь реальную, причем степень этого приближения может быть различной и зависит она как от свойств исходных данных, так и от выбора вида функции, по которой производится выравнивание.
На рис. 15 представлены два различных случая взаимоотношения между двумя признаками. В обоих случаях предполагаемая связь описывается одним и тем же уравнением, но во втором случае соотношение между признаками х и у достаточно четко выражено и уравнение, по-видимому, довольно хорошо описывает это соотношение, тогда как в первом случае сомнительно само наличие сколько-нибудь закономерного соотношения между признаками. И в том, и в другом случаях, несмотря на их существенное различие, метод наименьших квадратов дает одинаковое уравнение, поскольку этот метод нечувствителен к потенциальным возможностям исходного материала вписаться в ту или иную схему. Кроме того, метод наименьших квадратов применяется для расчета неизвестных параметров заранее выбранного вида функции, и вопрос о выборе наиболее подходящего для конкретных данных вида функции в рамках этого метода не ставится и не решается. Таким образом, при пользовании методом наименьших квадратов открытыми остаются два важных вопроса, а именно: существует ли связь и верен ли выбор вида функции, с помощью которой делается попытка описать форму связи.
Чтобы оценить, насколько точно уравнение регрессии описывает реальные соотношения между переменными, нужно ввести меру рассеяния фактических значений относительно вычисленных с помощью уравнения. Такой мерой служит средняя квадратическая ошибка регрессионного уравнения, вычисляемая по приведенной выше формуле (6.19).
Пример 11. Определить среднюю квадратическую ошибку уравнения, полученного в примере 9.
Промежуточные расчеты примера 10 дают нам среднюю квадратическую ошибку уравнения. Она равна 4,6 пуда.
Этот показатель аналогичен среднему квадратическому отклонению для средней. Подобно тому, как по величине среднего квадратического отклонения можно судить о представительности средней арифметической (см. гл. 5), по величине средней квадратической ошибки регрессионного уравнения можно сделать вывод о том, насколько показательна для соотношения между признаками та связь, которая выявлена уравнением. В каждом конкретном случае фактическая ошибка может оказаться либо больше, либо меньше средней. Средняя квадратическая ошибка уравнения показывает, насколько в среднем мы ошибемся, если будем пользоваться уравнением, и тем самым дает представление о точности уравнения. Чем меньше σ y.x , тем точнее предсказание линии регрессии, тем лучше уравнение регрессии описывает существующую связь. Показатель σ y.x позволяет различать случаи, представленные на рис. 15. В случае б) он окажется значительно меньше, чем в случае а). Величина σ y.x зависит как от выбора функции, так и от степени описываемой связи.
Варьируя виды функций для выравнивания и оценивая результаты с помощью средней квадратической ошибки, можно среди рассматриваемых выбрать лучшую функцию, функцию с наименьшей средней ошибкой. Но существует ли связь? Значимо ли уравнение регрессии, используемое для отображения предполагаемой связи? На эти вопросы отвечает определяемый ниже критерий значи-мости регрессии.
Мерой значимости линии регрессии может служить следующее соотношение:
где ŷ i —i-e выравненное значение; —средняя арифметическая значений y i ; σ y.x —средняя квадратическая ошибка регрессионного уравнения, вычисляемая по формуле (6.19); n—число сравниваемых пар значений признаков; m—число факторных признаков.
Действительно, связь тем больше, чем значительнее мера рассеяния признака, обусловленная регрессией, превосходит меру рассеяния отклонений фактических значений от выравненных.
Соотношение (6.20) позволяет решить вопрос о значимости регрессии. Регрессия значима, т. е. между признаками существует линейная связь, если для данного уровня значимости вычисленное значение F ф [m,n-(m+1)] превышает критическое значение F кр [m,n-(m+1)], стоящее на пересечении m-го столбца и [n—(m+1)]-й строки специальной таблицы ( см. табл. 4 приложения ).
Пример 12. Выясним, связаны ли сбор хлеба на душу населения и посев на душу населения линейной зависимостью.
Воспользуемся F-критерием значимости регрессии. Подставив в формулу (6.20) данные табл. 4 и результат примера 10, получим
Обращаясь к таблице F-распределения для Р=0,95 (α=1—Р=0,5) и учитывая, что n=23, m =1, в табл. 4А приложения на пересечения 1-го столбца и 21-й строки находим критическое значение F кр , равное 4,32 при степени надежности Р=0,95. Поскольку вычисленное значение F ф существенно превосходит по величине F кр , то обнаруженная линейная связь существенна, т. е. априорная гипотеза о наличии линейной связи подтвердилась. Вывод сделан при степени надежности P=0,95. Между прочим, вывод в данном случае останется прежним, если надежность повысить до Р=0,99 (соответствующее значение F кр =8,02 по табл. 4Б приложения для уровня значимости α=0,01).
Коэффициент детерминации. С помощью F-критерия мы Установили, что существует линейная зависимость между величиной сбора хлеба и величиной посева на душу. Следовательно, можно утверждать, что величина сбора хлеба, приходящегося на душу, линейно зависит от величины посева на душу. Теперь уместно поставить уточняющий вопрос — в какой степени величина посева на душу определяет величину сбора хлеба на душу? На этот вопрос можно ответить, рассчитав, какая часть вариации результативного признака может быть объяснена влиянием факторного признака.
Оно показывает долю разброса, учитываемого регрессией, в общем разбросе результативного признака и носит название коэффициента детерминации. Этот показатель, равный отношению факторной вариации к полной вариации признака, позволяет судить о том, насколько «удачно» выбран вид функции ( Отметим, что по смыслу коэффициент детерминации в регрессионном анализе соответствует квадрату корреляционного отношения для корреляционной таблицы (см. § 2). ). Проведя расчеты, основанные на одних и тех же исходных данных, для нескольких типов функций, мы можем из них выбрать такую, которая дает наибольшее значение R 2 и, следовательно, в большей степени, чем другие функции, объясняет вариацию результативного признака. Действительно, при расчете R 2 для одних и тех же данных, но разных функций знаменатель выражения (6.21) остается неизменным, а числитель показывает ту часть вариации результативного признака, которая учитывается выбранной функцией. Чем больше R 2 , т. е. чем больше числитель, тем больше изменение факторного признака объясняет изменение результативного признака и тем, следовательно, лучше уравнение регрессии, лучше выбор функции.
Наконец, отметим, что введенный ранее, при изложении методов корреляционного анализа, коэффициент детерминации совпадает с определенным здесь показателем, если выравнивание производится По прямой линии. Но последний показатель (R 2 ) имеет более широкий спектр применения и может использоваться в случае связи, отличной от линейной ( см. § 4 данной главы ).
Пример 13. Рассчитать коэффициент детерминации для уравнения, полученного в примере 9.
Вычислим R 2 , воспользовавшись формулой (6.21) и данными табл. 4:
Итак, уравнение регрессии почти на 78% объясняет колебания сбора хлеба на душу. Это немало, но, По-видимому, можно улучшить модель введением в нее еще одного фактора.
Случай двух независимых переменных. Простейший случай множественной регрессии. В предыдущем изложении регрессионного анализа мы имели дело с двумя признаками — результативным и факторным. Но на результат действует обычно не один фактор, а несколько, что необходимо учитывать для достаточно полного анализа связей.
В математической статистике разработаны методы множественной регрессии ( Регрессия называется множественной, если число независимых переменных, учтенных в ней, больше или равно двум. ), позволяющие анализировать влияние на результативный признак нескольких факторных. К рассмотрению этих методов мы и переходим.
Возвратимся к примеру 9. В нем была определена форма связи между величиной сбора хлеба на душу и размером посева на душу. Введем в анализ еще один фактор — уровень урожайности (см. столбец З табл. 4). Без сомнения, эта переменная влияет на сбор хлеба на душу. Но в какой степени влияет? Насколько обе независимые переменные определяют сбор хлеба на душу в черноземных губерниях? Какая из переменных — посев на душу или урожайность — оказывает определяющее влияние на сбор хлеба? Попытаемся ответить на эти вопросы.
После добавления второй независимой переменной уравнение регрессии будет выглядеть так:
где у—сбор хлеба на душу; х 1 —размер посева на душу; x 2 —урожай с десятины (в пудах); а 0 , а 1 , а 2 —параметры, подлежащие определению.
Для нахождения числовых значений искомых параметров, как и в случае одной независимой переменной, пользуются методом наименьших квадратов. Он сводится к составлению и решению системы нормальных уравнений, которая имеет вид
Когда система состоит из трех и более нормальных уравнений, решение ее усложняется. Существуют стандартные программы расчета неизвестных параметров регрессионного уравнения на ЭВМ. При ручном счете можно воспользоваться известным из школьного курса методом Гаусса.
Пример 14. По данным табл. 4 описанным способом найдем параметры a 0 , а 1 , а 2 уравнения (6.22). Получены следующие результаты: a 2 =0,3288, a 1 =28,7536, a 0 =-0,2495.
Таким образом, уравнение множественной регрессии между величиной сбора хлеба на душу населения (у), размером посева на душу (x 1 ) и уровнем урожайности (х 2 ) имеет вид:
у=-0,2495+28,7536x 1 +0,3288x 2 .
Интерпретация коэффициентов уравнения множественной регрессии. Коэффициент при х 1 в полученном уравнении отличается от аналогичного коэффициента в уравнении примера 9.
Коэффициент при независимой переменной в уравнении простой регрессии отличается от коэффициента при соответствующей переменной в уравнении множественной регрессии тем, что в последнем элиминировано влияние всех учтенных в данном уравнении признаков.
Коэффициенты уравнения множественной регрессии поэтому называются частными или чистыми коэффициентами регрессии.
Частный коэффициент множественной регрессии при х 1 показывает, что с увеличением посева на душу на 1 дес. и при фиксированной урожайности сбор хлеба на душу населения вырастает в среднем на 28,8 пуда. Частный коэффициент при x 2 показывает, что при фиксированном посеве на душу увеличение урожая на единицу, т. е. на 1 пуд с десятины, вызывает в среднем увеличение сбора хлеба на душу на 0,33 пуда. Отсюда можно сделать вывод, что увеличение сбора хлеба в черноземных губерниях России идет, в основном, за счет расширения посева и в значительно меньшей степени—за счет повышения урожайности, т. е. экстенсивная форма развития зернового хозяйства является господствующей.
Введение переменной х 2 в уравнение позволяет уточнить коэффициент при х 1 . Конкретно, коэффициент оказался выше (28,8 против 24,6), когда в изучаемой связи вычленилось влияние урожайности на сбор хлеба.
Однако выводы, полученные в результате анализа коэффициентов регрессии, не являются пока корректными, поскольку, во-первых, не учтена разная масштабность факторов, во-вторых, не выяснен вопрос о значимости коэффициента a 2 .
Величина коэффициентов регрессии изменяется в зависимости от единиц измерения, в которых представлены переменные. Если переменные выражены в разном масштабе измерения, то соответствующие им коэффициенты становятся несравнимыми. Для достижения сопоставимости коэффициенты регрессии исходного уравнения стандартизуют, взяв вместо исходных переменных их отношения к собственным средним квадратическим отклонениям. Тогда уравнение (6.22) приобретает вид
Сравнивая полученное уравнение с уравнением (6.22), определяем стандартизованные частные коэффициенты уравнения, так называемые бета-коэффициенты, по формулам:
где β 1 и β 2 —бета-коэффициенты; а 1 и а 2 —коэффициенты регрессии исходного уравнения; σ у , , и — средние квадратические отклонения переменных у, х 1 и х 2 соответственно.
Вычислив бета-коэффициенты для уравнения, полученного в примере 14:
видим, что вывод о преобладании в черноземной полосе россии экстенсивной формы развития хозяйства над интенсивной остается в силе, так как β 1 значительно больше, чем β 2 .
Оценка точности уравнения множественной регрессии.
Точность уравнения множественной регрессии, как и в случае уравнения с одной независимой переменной, оценивается средней квадратической ошибкой уравнения. Обозначим ее , где подстрочные индексы указывают, что результативным признаком в уравнении является у, а факторными признаками х 1 и x 2 . Для расчета средней квадратической ошибки уравнения множественной регрессии применяется приведенная выше формула (6.19).
Пример 15. Оценим точность полученного в примере 14 уравнения регрессии.
Воспользовавшись формулой (6.19) и данными табл. 4, вычислим среднюю квадратическую ошибку уравнения:
Оценка полезности введения дополнительной переменной. Точность уравнения регрессии тесно связана с вопросом ценности включения дополнительных членов в это уравнение.
Сравним средние квадратические ошибки, рассчитанные для уравнения с одной переменной х 1 (пример 11) и для уравнения с двумя независимыми переменными х 1 и х 2 . Включение в уравнение новой переменной (урожайности) уменьшило среднюю квадратическую ошибку почти вдвое.
Можно провести сравнение ошибок с помощью коэффициентов вариации
где σ f —средняя квадратическая ошибка регрессионного уравнения; —средняя арифметическая результативного признака.
Для уравнения, содержащего одну независимую переменную:
Для уравнения, содержащего две независимые переменные:
Итак, введение независимой переменной «урожайность» уменьшило среднюю квадратическую ошибку до величины порядка 7,95% среднего значения зависимой переменной.
Наконец, по формуле (6.21) рассчитаем коэффициент детерминации
Он показывает, что уравнение регрессии на 81,9% объясняет колебания сбора хлеба на душу населения. Сравнивая полученный результат (81,9%) с величиной R 2 для однофакторного уравнения (77,9%), видим, что включение переменной «урожайность» заметно увеличило точность уравнения.
Таким образом, сравнение средних квадратических ошибок уравнения, коэффициентов вариации, коэффициентов детерминации, рассчитанных до и после введения независимой переменной, позволяет судить о полезности включения этой переменной в уравнение. Однако следует быть осторожными в выводах при подобных сравнениях, поскольку увеличение R 2 или уменьшение σ и V σ не всегда имеют приписываемый им здесь смысл. Так, увеличение R 2 может объясняться тем фактом, что число рассматриваемых параметров в уравнении приближается к числу объектов наблюдения. Скажем, весьма сомнительными будут ссылки на увеличение R 2 или уменьшение σ, если в уравнение вводится третья или четвертая независимая переменная и уравнение строится на данных по шести, семи объектам.
Полезность включения дополнительного фактора можно оценить с помощью F-критерия.
Частный F-критерий показывает степень влияния дополнительной независимой переменной на результативный признак и может использоваться при решении вопроса о добавлении в уравнение или исключении из него этой независимой переменной.
Разброс признака, объясняемый уравнением регрессии (6.22), можно разложить на два вида: 1) разброс признака, обусловленный независимой переменной х 1 , и 2) разброс признака, обусловленный независимой переменной x 2 , когда х 1 уже включена в уравнение. Первой составляющей соответствует разброс признака, объясняемый уравнением (6.15), включающим только переменную х 1 . Разность между разбросом признака, обусловленным уравнением (6.22), и разбросом признака, обусловленным уравнением (6.15), определит ту часть разброса, которая объясняется дополнительной независимой переменной x 2 . Отношение указанной разности к разбросу признака, регрессией не объясняемому, представляет собой значение частного критерия. Частный F-критерий называется также последовательным, если статистические характеристики строятся при последовательном добавлении переменных в регрессионное уравнение.
Пример 16. Оценить полезность включения в уравнение регрессии дополнительной переменной «урожайность» (по данным и результатам примеров 12 и 15).
Разброс признака, объясняемый уравнением множественной регрессии и рассчитываемый как сумма квадратов разностей выравненных значений и их средней, равен 1623,8815. Разброс признака, объясняемый уравнением простой регрессии, составляет 1545,1331.
Разброс признака, регрессией не объясняемый, определяется квадратом средней квадратической ошибки уравнения и равен 10,9948 (см. пример 15).
Воспользовавшись этими характеристиками, рассчитаем частный F-критерий
С уровнем надежности 0,95 (α=0,05) табличное значение F (1,20), т. е. значение, стоящее на пересечении 1-го столбца и 20-й строки табл. 4А приложения, равно 4,35. Рассчитанное значение F ф значительно превосходит табличное, и, следовательно, включение в уравнение переменной «урожайность» имеет смысл.
Таким образом, выводы, сделанные ранее относительно коэффициентов регрессии, вполне правомерны.
Важным условием применения к обработке данных метода множественной регрессии является отсутствие сколько-нибудь значительной взаимосвязи между факторными признаками. При практическом использовании метода множественной регрессии, прежде чем включать факторы в уравнение, необходимо убедиться в том, что они независимы.
Если один из факторов зависит линейно от другого, то система нормальных уравнений, используемая для нахождения параметров уравнения, не разрешима. Содержательно этот факт можно толковать так: если факторы х 1 и x 2 связаны между собой, то они действуют на результативный признак у практически как один фактор, т. е. сливаются воедино и их влияние на изменение у разделить невозможно. Когда между независимыми переменными уравнения множественной регрессии имеется линейная связь, следствием которой является неразрешимость системы нормальных уравнений, то говорят о наличии мультиколлинеарности.
На практике вопрос о наличии или об отсутствии мультиколлинеарности решается с помощью показателей взаимосвязи. В случае двух факторных признаков используется парный коэффициент корреляции между ними: если этот коэффициент по абсолютной величине превышает 0,8, то признаки относят к числу мультиколлинеарных. Если число факторных признаков больше двух, то рассчитываются множественные коэффициенты корреляции. Фактор признается мультиколлинеарным, если множественный коэффициент корреляции, характеризующий совместное влияние на этот фактор остальных факторных признаков, превзойдет по величине коэффициент множественной корреляции между результативным признаком и совокупностью всех независимых переменных.
Самый естественный способ устранения мультиколлинеарности — исключение одного из двух линейно связанных факторных признаков. Этот способ прост, но не всегда приемлем, так как подлежащий исключению фактор может оказывать на зависимую переменную особое влияние. В такой ситуации применяются более сложные методы избавления от мультиколлинеарности ( См.: Мот Ж. Статистические предвидения и решения на предприятии. М., 1966; Ковалева Л. Н. Многофакторное прогнозирование на основе рядов динамики. М., 1980. ).
Выбор «наилучшего» уравнения регрессии. Эта проблема связана с двойственным отношением к вопросу о включении в регрессионное уравнение независимых переменных. С одной стороны, естественно стремление учесть все возможные влияния на результативный признак и, следовательно, включить в модель полный набор выявленных переменных. С другой стороны, возрастает сложность расчетов и затраты, связанные с получением максимума информации, могут оказаться неоправданными. Нельзя забывать и о том, что для построения уравнения регрессии число объектов должно в несколько раз превышать число независимых переменных. Эти противоречивые требования приводят к необходимости компромисса, результатом которого и является «наилучшее» уравнение регрессии. Существует несколько методов, приводящих к цели: метод всех возможных регрессий, метод исключения, метод включения, шаговый регрессионный и ступенчатый регрессионный методы.
Метод всех возможных регрессий заключается в переборе и сравнении всех потенциально возможных уравнений. В качестве критерия сравнения используется коэффициент детерминации R 2 . «Наилучшим» признается уравнение с наибольшей величиной R 2 . Метод весьма трудоемок и предполагает использование вычислительных машин.
Методы исключения и включения являются усовершенствованными вариантами предыдущего метода. В методе исключения в качестве исходного рассматривается регрессионное уравнение, включающее все возможные переменные. Рассчитывается частный F-критерий для каждой из переменных, как будто бы она была последней переменной, введенной в регрессионное уравнение. Минимальная величина частного F-критерия (F min ) сравнивается с критической величиной (F кр ), основанной на заданном исследователем уровне значимости. Если F min >F кр , то уравнение остается без изменения. Если F min кр , то переменная, для которой рассчитывался этот частный F-критерий, исключается. Производится перерасчет уравнения регрессии для оставшихся переменных, и процедура повторяется для нового уравнения регрессии. Исключение из рассмотрения уравнений с незначимыми переменными уменьшает объем вычислений, что является достоинством этого метода по сравнению с предыдущим.
Метод включения состоит в том, что в уравнение включаются переменные по степени их важности до тех пор, пока уравнение не станет достаточно «хорошим». Степень важности определяется линейным коэффициентом корреляции, показывающим тесноту связи между анализируемой независимой переменной и результативным признаком: чем теснее связь, тем больше информации о результирующем признаке содержит данный факторный признак и тем важнее, следовательно, введение этого признака в уравнение.
Процедура начинается с отбора факторного признака, наиболее тесно связанного с результативным признаком, т. е. такого факторного признака, которому соответствует максимальный по величине парный линейный коэффициент корреляции. Далее строится линейное уравнение регрессии, содержащее отобранную независимую переменную. Выбор следующих переменных осуществляется с помощью частных коэффициентов корреляции, в которых исключается влияние вошедших в модель факторов. Для каждой введенной переменной рассчитывается частный F-критерий, по величине которого судят о том, значим ли вклад этой переменной. Как только величина частного F-критерия, относящаяся к очередной переменной, оказывается незначимой, т. е. эффект от введения этой переменной становится малозаметным, процесс включения переменных заканчивается. Метод включения связан с меньшим объемом вычислений, чем предыдущие методы. Но при введении новой переменной нередко значимость включенных ранее переменных изменяется. Метод включения этого не учитывает, что является его недостатком. Модификацией метода включения, исправляющей этот недостаток, является шаговый регрессионный метод.
Шаговый регрессионный метод кроме процедуры метода включения содержит анализ переменных, включенных в уравнение на предыдущей стадии. Потребность в таком анализе возникает в связи с тем, что переменная, обоснованно введенная в уравнение на ранней стадии, может оказаться лишней из-за взаимосвязи ее с переменными, позднее включенными в уравнение. Анализ заключается в расчете на каждом этапе частных F-критериев для каждой переменной уравнения и сравнении их с величиной F кр , точкой F-распределения, соответствующей заданному исследователем уровню значимости. Частный F-критерий показывает вклад переменной в вариацию результативного признака в предположении, что она вошла в модель последней, а сравнение его с F кр позволяет судить о значимости рассматриваемой переменной с учетом влияния позднее включенных факторов. Незначимые переменные из уравнения исключаются.
Рассмотренные методы предполагают довольно большой объем вычислений и практически неосуществимы без ЭВМ. Для реализации ступенчатого регрессионного метода вполне достаточно малой вычислительной техники.
Ступенчатый регрессионный метод включает в себя такую последовательность действий. Сначала выбирается наиболее тесно связанная с результативным признаком переменная и составляется уравнение регрессии. Затем находят разности фактических и выравненных значений и эти разности (остатки) рассматриваются как значения результативной переменной. Для остатков подбирается одна из оставшихся независимых переменных и т. д. На каждой стадии проверяется значимость регрессии. Как только обнаружится незначимость, процесс прекращается и окончательное уравнение получается суммированием уравнений, полученных на каждой стадии за исключением последней.
Ступенчатый регрессионный метод менее точен, чем предыдущие, но не столь громоздок. Он оказывается полезным в случаях, когда необходимо внести содержательные правки в уравнение. Так, для изучения факторов, влияющих на цены угля в Санкт-Петербурге в конце XIX— начале XX в., было получено уравнение множественной регрессии. В него вошли следующие переменные: цены угля в Лондоне, добыча угля в России и экспорт из России. Здесь не обосновано появление в модели такого фактора, как добыча угля, поскольку Санкт-Петербург работал исключительно на импортном угле. Модели легко придать экономический смысл, если независимую переменную «добыча» заменить независимой переменной «импорт». Формально такая замена возможна, поскольку между импортом и добычей существует тесная связь. Пользуясь ступенчатым методом, исследователь может совершить эту замену, если предпочтет содержательно интерпретируемый фактор.
§ 4. Нелинейная регрессия и нелинейная корреляция
Построение уравнений нелинейной регрессии. До сих пор мы, в основном, изучали связи, предполагая их линейность. Но не всегда связь между признаками может быть достаточно хорошо представлена линейной функцией. Иногда для описания существующей связи более пригодными, а порой и единственно возможными являются более сложные нелинейные функции. Ограничимся рассмотрением наиболее простых из них.
Одним из простейших видов нелинейной зависимости является парабола, которая в общем виде может быть представлена функцией (6.2):
Неизвестные параметры а 0 , а 1 , а 2 находятся в результате решения следующей системы уравнений:
Дает ли преимущества описание связи с помощью параболы по сравнению с описанием, построенным по гипотезе линейности? Ответ на этот вопрос можно получить, рассчитав последовательный F-критерий, как это делалось в случае множественной регрессии (см. пример 16).
На практике для изучения связей используются полиномы более высоких порядков (3-го и 4-го порядков). Составление системы, ее решение, а также решение вопроса о полезности повышения порядка функции для этих случаев аналогичны описанным. При этом никаких принципиально новых моментов не возникает, но существенно увеличивается объем расчетов.
Кроме класса парабол для анализа нелинейных связей можно применять и другие виды функций. Для расчета неизвестных параметров этих функций рекомендуется использовать метод наименьших квадратов, как наиболее мощный и широко применяемый.
Однако метод наименьших квадратов не универсален, поскольку он может использоваться только при условии, что выбранные для выравнивания функции линейны по отношению к своим параметрам. Не все функции удовлетворяют этому условию, но большинство применяемых на практике с помощью специальных преобразований могут быть приведены к стандартной форме функции с линейными параметрами.
Рассмотрим некоторые простейшие способы приведения функций с нелинейными параметрами к виду, который позволяет применять к ним метод наименьших квадратов.
Функция не является линейной относительно своих параметров.
Прологарифмировав обе части приведенного равенства
получим функцию, линейную относительно своих новых параметров:
Кроме логарифмирования для приведения функций к нужному виду используют обратные величины.
с помощью следующих переобозначений:
может быть приведена к виду
Подобные преобразования расширяют возможности использования метода наименьших квадратов, увеличивая число функций, к которым этот метод применим.
Измерение тесноты связи при криволинейной зависимости. Рассмотренные ранее линейные коэффициенты корреляции оценивают тесноту взаимосвязи при линейной связи между признаками. При наличии криволинейной связи указанные меры связи не всегда приемлемы. Разберем подобную ситуацию на примере.
Пример 17. В 1-м и 2-м столбцах табл. 5 приведены значения результативного признака у и факторного признака х (данные условные). Поставив вопрос о тесноте связи между ними, рассчитаем парный линейный коэффициент корреляции по формуле (6.3). Он оказался равным нулю, что свидетельствует об отсутствии линейной связи. Тем не менее связь между признаками существует, более того, она является функциональной и имеет вид
Для измерения тесноты связи при криволинейной зависимости используется индекс корреляции, вычисляемый по формуле
где у i —i-e значение результативного признака; ŷ i —i-e выравненное значение этого признака; —среднее арифметическое значение результативного признака.
Числитель формулы (6.27) характеризует разброс выравненных значений результативного признака. Поскольку изменения выравненных, т. е. вычисленных по уравнению регрессии, значений признака происходят только в результате изменения факторного признака х. то числитель измеряет разброс результативного признака, обусловленный влиянием на него факторного признака. Знаменатель же измеряет разброс признака-результата, который определен влиянием на него всех факторов, в том числе и учтенного. Таким образом, индекс корреляции оценивает участие данного факторного признака в общем действии всего комплекса факторов, вызывающих колеблемость результативного признака, тем самым определяя тесноту зависимости признака у от признака х. При этом, если признак х не вызывает никаких изменений признака у, то числитель и, следовательно, индекс корреляции равны 0. Если же линия регрессии полностью совпадает с фактическими данными, т. е. признаки связаны функционально, как в примере 17, то индекс корреляции равен 1. В случае линейной зависимости между х и у индекс корреляции численно равен линейному коэффициенту корреляции г. Квадрат индекса корреляции совпадает с введенным ранее (6.21) коэффициентом детерминации. Если же вопрос о форме связи не ставится, то роль коэффициента детерминации играет квадрат корреляционного отношения η 2 y/x (6.12).
Таковы основные принципы и условия, методика и техника применения корреляционного и регрессионного анализа. Их подробное рассмотрение обусловлено тем, что они являются высокоэффективными и потому очень широко применяемыми методами анализа взаимосвязей в объективном мире природы и общества. Корреляционный и регрессионный анализ широко и успешно применяются и в исторических исследованиях.
Прогнозирование. Регрессионный анализ, его реализация и прогнозирование
МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ
Сущность метода регрессионного анализа
Одним из методов, используемых для прогнозирования, является регрессионный анализ.
Регрессия – это статистический метод, который позволяет найти уравнение, наилучшим образом описывающее совокупность данных, заданных таблицей.
| X | X1 | X2 | … | Xi | … | Xn |
|---|---|---|---|---|---|---|
| Y | Y1 | Y2 | … | Yi | … | Yn |

На графике данные отображаются точками. Регрессия позволяет подобрать к этим точкам кривую у=f(x), которая вычисляется по методу наименьших квадратов и даёт максимальное приближение к табличным данным.
По полученному уравнению можно вычислить (сделать прогноз) значение функции у для любого значения х , как внутри интервала изменения х из таблицы(интерполяция), так и вне его (экстраполяция).
Линейная регрессия
Линейная регрессия дает возможность наилучшим образом провести прямую линию через точки одномерного массива данных (рис.13.1 а). Уравнение с одной независимой переменной, описывающее прямую линию, имеет вид:
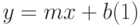
где:x – независимая переменная;
y – зависимая переменная;
m – характеристика наклона прямой;
b – точка пересечения прямой с осью у.
Например, имея данные о реализации товаров за год с помощью линейной регрессии можно получить коэффициенты прямой (1) и, предполагая дальнейший линейный рост, получить прогноз реализации на следующий год.
Нелинейная регрессия
Нелинейная регрессия позволяет подбирать к табличным данным нелинейное уравнение (рис. 13.1 рис. 13.1, б.) – параболу, гиперболу и др. Excel реализует нелинейность в виде экспоненты, т.е. подбирает кривую вида:
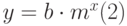 ,
,
которая позволяет наилучшим образом провести экспоненциальную кривую по точкам данных, которые изменяются нелинейно.
Так, например, данные о росте населения почти всегда лучше описываются не прямой линией, а экспоненциальной кривой. При этом нужно помнить, что достоверное прогнозирование возможно только на участках подъёма или спуска кривой (при отрицательных значениях х), т.к. сама кривая (2) изменяется монотонно, без точек перегиба. Например, делать экспоненциальный прогноз для функции, изменяющейся синусоидально, можно только на участках подъёма или спуска функции, для чего её разбивают на соответствующие интервалы.
Множественная регрессия
Множественная регрессия представляет собой анализ более одного набора данных аргумента х и даёт более реалистичные результаты.
Множественный регрессионный анализ также может быть как линейным, так и экспоненциальным. Уравнение регрессии (1) и (2) примут соответственно вид (3) и (4):
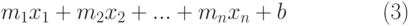 | ( 3) |
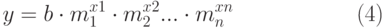 | ( 4) |
С помощью множественной регрессии, например, можно оценить стоимость дома в некотором районе, основываясь на данных его площади, размерах участка земли, этажности, вида из окон и т.д.
Использование функций регрессии
В Excel имеется 5 функций для линейной регрессии: ЛИНЕЙН(…)(LINEST), ТЕНДЕНЦИЯ(…), ПРЕДСКАЗ(…), НАКЛОН(…), СТОШУХ(…)) и 2 функции для экспоненциальной регрессии – ЛГРФПРИБЛ(…) и РОСТ(…).
Рассмотрим некоторые из них.
Функция ЛИНЕЙН((LINEST) вычисляет коэффициент m и постоянную b для уравнения прямой (1). Синтаксис функции:
Известные_значения_у и известные_значения_х – это множество значений у и необязательное множество значений х (их вводить необязательно), которые уже известны для соотношения (1).
Константа – это логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0. Если константа имеет значение ИСТИНА или опущено, то b вычисляется обычным образом.
Статистика – это логическое значение, которое указывает требуется ли вывести дополнительную статистику по регрессии.
Если статистика имеет значение ЛОЖЬ (или 0), то функция ЛИНЕЙН возвращает только значения коэффициентов m и b , в противном случае выводится дополнительная регрессионная статистика в виде табл. 13.1 таблица 13.1:
| mn | mn-1 | … | m2 | m1 | b |
|---|---|---|---|---|---|
| sen | sen-1 | … | se2 | se1 | seb |
| r 2 | sey | … | #Н/Д | #Н/Д | #Н/Д |
| F | df | … | #Н/Д | #Н/Д | #Н/Д |
| ssreg | ssresid | … | #Н/Д | #Н/Д | #Н/Д |
где: se1 , se2,…,sen – стандартные значения ошибок для коэффициентов m1 , m2,…, mn ;
seb – стандартное значение ошибки для постоянной b (seb равно #Н/Д, т.е. «нет допустимого значения», если конст. имеет значение ЛОЖЬ);
r 2 – коэффициент детерминированности. Сравниваются фактические значения у и значения, получаемые из уравнения прямой; по результатам сравнения вычисляется коэффициент детерминированности, нормированный от 0 до 1. Если он равен 1, то имеет место полная корреляция с моделью, т.е. нет различия между фактическим и оценочным значениями у. В противоположном случае, если коэффициент детерминированности равен 0, то уравнение регрессии неудачно для предсказания значений у;
sey – стандартная ошибка для оценки у (предельное отклонение для у);
F – F-cтатистика, или F-наблюдаемое значение. Она используется для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет;
df – степени свободы. Степени свободы полезны для нахождения F-критических значений в статистической таблице. Для определения уровня надёжности модели нужно сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН;
ssreg – регрессионная сумма квадратов;
ssresid – остаточная сумма квадратов;
#Н/Д – ошибка, означающая «нет доступного значения».
Любую прямую можно задать её наклоном m и у-пересечением:
Наклон ( m ). Для того, чтобы определить наклон прямой, обычно обозначаемый через m , нужно взять 2 точки прямой (х1,у1) и (х2,у2); тогда наклон равен m=(y2-y1)/(x2-x1 ).
у-пересечение ( b ) прямой, обычно обозначаемое через b , является значение у для точки, в которой прямая пересекает ось у.
Уравнение прямой имеет вид: у=mx+b. Если известны значения m и b , то можно вычислить любую точку на прямой, подставляя значения у или х в уравнение. Можно также использовать функцию ТЕНДЕНЦИЯ ( TREND ) (см. ниже).
Если для функции у имеется только одна независимая переменная х, можно получить наклон и у-пересечение непосредственно, используя следующие формулы:
Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точными являются модель, используемая функцией ЛИНЕЙН, и значения, получаемые из уравнения прямой.
В случае экспоненциальной регрессии аналогом функции (5) является функция ЛГРФПРИБЛ(LOGEST):
которая отличается лишь тем, что вычисляет коэффициенты m и b для экспоненциальной кривой (2).
Функция ТЕНДЕНЦИЯ(TREND) имеет вид:
возвращает числовые значения, лежащие на прямой линии, наилучшим образом аппроксимирующие известные табличные данные.
Новые_значения_х – это те, для которых необходимо вычислить соответствующие значения у.
Если параметр новые_значения_х пропущен, то считается, что он совпадает с известными х. Назначение остальных параметров функции ТЕНДЕНЦИЯ совпадает с описанными выше.
В случае экспоненциальной регрессии аналогом функции (7) является функция РОСТ(GROWTH):
возвращает стандартную погрешность регрессии – меру погрешности предсказываемого значения у для заданного значения х.
Правила ввода функций
Формулы(5)-(8) являются табличными, т.е. они заменяют собой несколько обычных формул и возвращают не один результат, а массив результатов. Поэтому необходимо соблюдать следующие правила:
- Перед вводом одной из формул (5)-(8) выведите блок ячеек, точно совпадающей по размеру с величиной возвращаемого формулой массива результатов. Например, при использовании функции ЛИНЕЙН с выводом статистики нужно выделить массив ячеек, равный табл. 13.1, если параметр статистики равен ЛОЖЬ, достаточно выделить одну строку табл. 13.1.
- Наберите функцию в строке формул. При этом слова на русском языке можно набирать строчными буквами, т.к. они являются ключевыми и при вводе Exсel автоматически переведет их в заглавные. Имена ячеек автоматически вводятся латинским шрифтом. Вместо слова ИСТИНА можно вводить числа от 1 до 9 (не 0), а вместо слова ЛОЖЬ – число 0. Если в результате, выполнения функции выводится одно число, можно вводить формулы не вручную, а использовать аппарат Мастера функций.
- Одновременно нажмите клавиши Shift+Ctrl+Enter . Результаты вычислений заполнят выделенные ячейки.
Линия тренда
Excel позволяет наглядно отображать тенденцию данных с помощью линии тренда, которая представляет собой интерполяционную кривую, описывающую отложенные на диаграмме данные.
Для того, чтобы дополнить диаграмму исходных данных линией тренда, необходимо выполнить следующие действия:
- выделить на диаграмме ряд данных, для которого требуется построить линию тренда;
- щелкнуть правой кнопкой мыши и выбрать команду Добавить линию тренда;
- в открывшемся окне задать метод интерполяции (линейный, полиномиальный, логарифмический и т. д.), а также через команду Параметры – другие параметры (например, вывод уравнения кривой тренда, коэффициента детерминированности r 2 , направление и количество периодов для экстраполяции (прогноза) и др.);
- нажать кнопку Закрыть.
Чтобы отобразить на графике (гистограмме и др.) новые, прогнозируемые в результате регрессионного анализа данные, нужно:
- определить их с помощью функции ТЕНДЕНЦИЯ, РОСТ или другим способом,
- выделить на диаграмме нужную кривую, щелкнув по ней правой кнопкой мыши,
- в появившемся окне выбрать команду Выбрать данные…, в появившемся окне выбрать диапазон ячеек с новыми данными вручную или протащив по ним курсор при нажатой левой клавише мыши, нажать ОК.
На диаграмме появится продолжение кривой, построенной по новым данным.
Простая линейная регрессия
Пример 1. Функция ТЕНДЕНЦИЯ(TREND)
а) Предположим, что фирма может приобрести земельный участок в июле. Фирма собирает информацию о ценах за последние 12 месяцев, начиная с марта, на типичный земельный участок. Название первого столбца «Месяц» с данными о номерах месяцев записано в ячейке А1, а второго столбца «Цена» – в ячейке В1. Номера месяцев с 1 по 12 (известные значения х) записаны в ячейки А2…А13. Известные значения у содержат множество известных значений (133 890 руб., 135 000 руб., 135 790 руб., 137 300 руб., 138 130 руб., 139 100 руб., 139 900 руб., 141 120 руб., 141 890 руб., 143 230 руб., 144 000 руб., 145 290 руб.), которые находятся в ячейках В2;В13 соответственно (данные условия). Новые значения х, т.е. числа 13, 14,15,16,17 введём в ячейки А14…А18. Для того чтобы определить ожидаемые значения цен на март, апрель, май, июнь, июль, выделим любой интервал ячеек, например, B14:B18 (по одной ячейке для каждого месяца) и в строке формул введем функцию:
После нажатия клавиш Ctrl+ Shift+Enter данная функция будет выделена как формула вертикального массива, а в ячейках B14:B18 появится результат: <146172;174190;148208;149226;150244>.
Таким образом, в июле фирма может ожидать цену около 150 244 руб.
б) Тот же результат будет получен, если вводить в формулу не все массивы переменных х и у, а использовать часть массивов, которые предусматриваются автоматически по умолчанию. Тогда формула (10) примет вид:
В формуле (11) используется массив по умолчанию (1:2:3:4:5:6:7:8:9:10:11:12) для аргумента «известные_значения_х», соответствующий 12 месяцам, для которых имеются данные по продажам. Он должен был бы быть помещен в формуле (11) между двумя знаками ;;. Массив (13:14:15:16:17) соответствует следующим 5 месяцам, для которых и получен массив результатов (146172:147190:148208:149226:150244).
Элементы массивов разделяет знак «:», который указывает на то, что они расположены по столбцам.
в) Аргумент «новые значения х» можно задать другим массивом ячеек, например, В14:В18, в которые предварительно записаны те же номера месяцев 13,14,15,16,17. Тогда вводимая в строку формул функция примет вид =ТЕНДЕНЦИЯ(В2:В13;;В14:В18).
Пример 2. Функция ЛИНЕЙН
а) Дана таблица изменения температуры в течение шести часов, введённая в ячейки D2 :E7 (табл. 13.2 таблица 13.2).
Требуется определить температуру во время восьмого часа.
| … | D | E |
|---|---|---|
| 1 | х-№часа | у-t о , град. |
| 2 | 1 | 2 |
| 3 | 2 | 3 |
| 4 | 3 | 4 |
| 5 | 4 | 7 |
| 6 | 5 | 12 |
| 7 | 6 | 18 |
Выделим ячейки D8:E12 для вывода результата, введем в строку ввода формулу =ЛИНЕЙН(Е2:Е7;D2:D7;1;1), нажмем клавиши Сtrl+Shift+Enter, в выделенных ячейках появится результат:
| 3,142857 | -3,3333333 |
| 0,540848 | 2,106302 |
| 0,894088 | 2,2625312 |
| 33,76744 | 4 |
| 172,8571 | 20,47619 |
Таким образом, коэффициент m=3,143 со стандартной ошибкой 0,541, а свободный член b=-3,333 со стандартной ошибкой 2,106, т.е. функция, описывающая данные табл. 13.2 таблица 13.2, имеет вид
Стандартные ошибки показывают максимально возможное отклонение параметра от рассчитанной величины. Для у оно составляет 2,263, т.е. реальное значение у может лежать в пределах 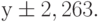 .
.
Точность приближения к табличным данным (коэффициент детерминированности r 2 ) составляет 0,894 или 89,4%, что является высоким показателем. При х=8 получим: у=3,143*8-3,333=21,81 град.
б) Тот же результат можно получить, использовав функцию =ТЕНДЕНЦИЯ(Е2:Е7;;G2:G5) для, например, следующих четырёх часов, предварительно введя в ячейки G2 :G5 числа с 7 до 10. Выделив ячейки Н2:Н5, введя в строку формул эту функцию и нажав Сtrl+Shift+Enter, получим в выделенных ячейках массив <18,667;21,80952;24,95238;28,09524>, т.е. для восьмого часа значение  град.
град.
в) Функция ПРЕДСКАЗ ( FORECAST ) – позволяет предсказать значение у для нового значения х по известным значениям х и у, используя линейное приближение зависимости у=f(x).
Для данных примера 2 ввод формулы =ПРЕДСКАЗ(8;Е2:Е7;D2:D7) выводит в заранее выделенной ячейке результат 21,809. Новое значение х может быть задано не числом, а ячейкой, в которую записано это число.
Отличие функции ПРЕДСКАЗ от функции ТЕНДЕНЦИЯ заключается в том, что ПРЕДСКАЗ прогнозирует значения функции линейного приближения только для одного нового значения х.
Экспоненциальная регрессия
Пример 3
а) Функция ЛГРФПРИБЛ.
Рассмотрим условие примера 2.
Поскольку функция в табл. 13.2 таблица 13.2 носит явно нелинейный характер, целесообразно искать ее приближение в виде не прямой линии, как в примере 2, а в виде нелинейной кривой. Из всех видов нелинейности (гипербола, парабола, и др.) Excel реализует только экспоненциальное приближение вида у=b*mx c помощью функции ЛГРФПРИБЛ, которая рассчитывает для этого уравнения значения b и m .
Выделим для результата блок ячеек F8:G12 , введём в строку формул Функцию =ЛГРФПРИБЛ(Е2:Е7;D2:D7;1;1), нажмем клавиши Сtrl+Shift+Enter, в выделенных ячейках появится результат:
| 1,56628015 | 1,196513 |
| 0,02038299 | 0,07938 |
| 0,99181334 | 0,085268 |
| 484,599687 | 4 |
| 3,52335921 | 0,029083 |
Таким образом, коэффициент m=1,566, а b=1,197, т.е. уравнение приближающей кривой имеет вид:
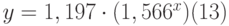
со стандартными ошибками для m, b , и у равными 0,02, 0,079 и 0,085 соответственно. Коэффициент детерминированности r 2 =0,992, т.е. полученное уравнение даёт совпадение с табличными данными с вероятностью 99,2%.
Поскольку интерполяция табл. 13.2 таблица 13.2 экспоненциальной кривой даёт более точное приближение (99,2%) и с меньшими стандартными ошибками для m, b и у, в качестве приближающего уравнения принимаем уравнение (13).
При х=8 получим у=1,197*34,363=41,131 град.
б) Функция РОСТ вычисляет прогнозируемое по экспоненциальному приближению значение у для новых значений х, имеет формат:
Выделим блок ячеек F14: F17 , введём формулу =РОСТ(Е2:Е7;D2:D7;G2:G5;ИСТИНА), в выделенных ячейках появится массив чисел <27,6696434;43,3384133;67,8800967;106,319248>, т.е. при х=8 значение функции у=43,34 град. Это значение немного отличается от вычисленного в п. а), поскольку функция РОСТ использует для расчетов линию экспонециального тренда.
Примечание. При выборе экспоненциальной приближающей кривой следует учитывать, что интерполировать ею можно только участки, где функция монотонно возрастает или убывает (при отрицательном аргументе х), т.е. функцию, имеющую точки перегиба (например, параболу, синусоиду, кривую рис. 2 – т. А и др.) следует разбить на участки монотонного изменения от одной точки перегиба до другой и каждый участок интерполировать отдельно. Для рисунка 2 функцию нужно разбить на 2 участка – от начала до т. А и от т. А до конца кривой.
Множественная линейная регрессия
Пример 4
Предположим, что коммерческий агент рассматривает возможность закупки небольших зданий под офисы в традиционном деловом районе. Агент может использовать множественный регрессионный анализ для оценки цены здания под офис на основе следующих переменных:
у – оценочная цена здания под офис;
х1 – общая площадь в квадратных метрах;
х2 – количество офисов;
х3 – количество входов;
х4 – время эксплуатации здания в годах.
Агент наугад выбирает 11 зданий из имеющихся 1500 и получает следующие данные:
| А | В | С | D | Е | |
|---|---|---|---|---|---|
| 1 | х1— площадь, м2 | х2 – офисы | х3 – входы | х4 – срок, лет | у – цена, у.е. |
| 2 | 2310 | 2 | 2 | 20 | 42000 |
| 3 | 2333 | 2 | 2 | 12 | 144000 |
| 4 | 2356 | 3 | 1,5 | 33 | 151000 |
| 5 | 2379 | 3 | 2 | 43 | 151000 |
| 6 | 2402 | 2 | 3 | 53 | 139000 |
| 7 | 2425 | 4 | 3 | 23 | 169000 |
| 8 | 2448 | 2 | 1,5 | 99 | 126000 |
| 9 | 2471 | 2 | 2 | 34 | 142000 |
| 10 | 2494 | 3 | 3 | 23 | 163000 |
| 11 | 2517 | 4 | 4 | 55 | 169000 |
| 12 | 2540 | 2 | 3 | 22 | 149000 |
«Пол-входа» означает вход только для доставки корреспонденции.
В этом примере предполагается, что существует линейная зависимость между каждой независимой переменной (х1,х2,х3,х4) и зависимой переменной (у), т.е. ценой зданий под офис в данном районе.
- выделим блок ячеек А14:Е18 (в соответствии с табл. 13.1 таблица 13.1),
- введём формулу =ЛИНЕЙН(Е2:Е12;А2:D12;ИСТИНА;ИСТИНА), —
- нажмём клавиши Ctrl+Shift+Enter ,
- в выделенных ячейках появится результат:
| А | В | С | D | E | |
|---|---|---|---|---|---|
| 14 | -234,237 | 2553,210 | 12529,7682 | 27,6413 | 52317,83 |
| 15 | 13,2680 | 530,6691 | 400,066838 | 5,42937 | 12237,36 |
| 16 | 0,99674 | 970,5784 | #Н/Д | #Н/Д | #Н/Д |
| 17 | 459,753 | 6 | #Н/Д | #Н/Д | #Н/Д |
| 18 | 1732393319 | 5652135 | #Н/Д | #Н/Д | #Н/Д |
Уравнение множественной регрессии  теперь может быть получено из строки 14:
теперь может быть получено из строки 14:
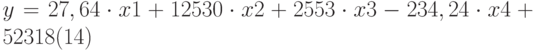
Теперь агент может определить оценочную стоимость здания под офис в том же районе, которое имеет площадь 2500 м 2 , три офиса, два входа, зданию 25 лет, используя следующее уравнение:
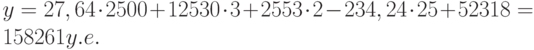
Это значение может быть вычислено с помощью функции ТЕНДЕНЦИЯ:
При интерполяции с помощью функции
для получения уравнения множественной экспоненциальной регрессии выводится результат:
| 0,99835752 | 1,0173792 | 1,0830186 | 1,0001704 | 81510,335 |
| 0,00014837 | 0,0065041 | 0,0048724 | 6,033Е-05 | 0,1365601 |
| 0,99158875 | 0,0105158 | #Н/Д | #Н/Д | #Н/Д |
| 176,832548 | 6 | #Н/Д | #Н/Д | #Н/Д |
| 0,07821851 | 0,0006635 | #Н/Д | #Н/Д | #Н/Д |
| #Н/Д | #Н/Д | #Н/Д | #Н/Д | #Н/Д |
Коэффициент детерминированности здесь составляет 0,992 (99,2%), т.е. меньше, чем при линейной интерполяции, поэтому в качестве основного следует оставить уравнение множественной регрессии (14).
Таким образом, функции ЛИНЕЙН, ЛГРФПРИБЛ, НАКЛОН определяют коэффициенты, свободные члены и статистические параметры для уравнений одномерной и множественной регрессии, а функции ТЕНДЕНЦИЯ, ПРЕДСКАЗ, РОСТ позволяют получить прогноз новых значений без составления уравнения регрессии по значениям тренда.
ЗАДАНИЕ
Вариант задания к данной лабораторной работе включает две задачи. Для каждой из них необходимо составить и определить:
- Таблицу исходных данных, а также значений, полученных методами линейной и экспоненциальной регрессии.
- Коэффициенты в уравнениях прямой и экспоненциальной кривой (функции ЛИНЕЙН и ЛГРФПРИБЛ), напишите уравнения прямой и экспоненциальной кривой для простой и множественной регрессии.
- Погрешности (ошибки) прямой и экспоненциальной кривой, вычислений для коэффициентов и функций, коэффициенты детерминированности. Оценить, какой тип регрессии наилучшим образом подходит для вашего варианта задания.
- Прогноз изменения данных, выполненный с использованием линейной и экспоненциальной регрессии (функции ТЕНДЕНЦИЯ, ПРЕДСКАЗ, РОСТ).
- Построить гистограмму (или график) исходных данных для задачи 1 (одномерная регрессия), отобразить на ней линию тренда, а также соответствующее ей уравнение и коэффициент детерминированности.
Варианты заданий (номер варианта соответствует номеру компьютера).
- На рынке наблюдается стойкое снижение цен на компьютеры. Сделать прогноз, на сколько необходимо будет снизить цену на компьютеры в следующем месяце в вашей фирме, чтобы как минимум сравнять её с ценой на аналогичные компьютеры в конкурирующей фирме, если известна динамика изменения цен на них в конкурирующей фирме за последние 12 месяцев.
Для выполнения задания нужно ввести ряд из 12 ячеек с ценами конкурирующей фирмы, сделать прогноз цены на следующий месяц и др. (см. Задание).
- Известна структура расходов фирмы на рекламу в газетах, на радио, в журналах, на телевидении, на наружную рекламу (в процентах от общей суммы), а также оборот фирмы в каждом за последние 6 месяцев. Какой оборот можно ожидать в следующем месяце, если предполагается следующая структура расходов на рекламу: газеты-40%, журналы-40%, радио-5%, телевидение-14%, наружная реклама-1%.
Для выполнения задания нужно составить таблицу со столбцами вида:
| Месяц | х1-газеты,% | х2-журн.,% | х3-рад.,% | х4-телев.,% | х5-нар. рекл.,% | Оборот, $ |
|---|---|---|---|---|---|---|
| 1 | 37 | 34 | 12 | 10 | 5 | 410000 |
| 2 | 38 | 37 | 10 | 11 | 6 | 411500 |
| 3 | 39 | 38 | 9 | 13 | 7 | 413700 |
| 4 | 40 | 39 | 8 | 15 | 8 | 417050 |
| 5 | 41 | 40 | 7 | 16 | 9 | 420000 |
| 6 | 42 | 42 | 5 | 17 | 10 | 425000 |
и сделать множественный регрессионный прогноз (см. Задание).
- Имеются данные об объеме продаж в расчете на душу населения по хлебу и молоку и данные по годовым доходам на душу за 10 лет. По каждому товару построить модели регрессии для объемов продаж и функции размера доходов. Сделать прогноз о продажах и доходах на следующий год.
Для выполнения задания нужно составить таблицу вида:
| Годы | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| х1-хлеб, кг | 23,5 | 26,7 | 27,9 | 30,1 | 31,5 | 35,7 | 38,3 | 40,1 | 41,5 | 42,8 | |
| х2-молоко, л | 20,45 | 22 | 23,8 | 25,9 | 27,4 | 29 | 33,5 | 36,8 | 38,1 | 39,5 | |
| У-доход, р. | 6600 | 7200 | 8400 | 10500 | 12750 | 14730 | 16240 | 17000 | 18050 | 18250 |
и получить два уравнения – у=f(x1) и у=f(x2), сделать прогноз на следующий год для рядов х1, х2, у и др. (см. Задание).
- Руководство фирмы провело оценку качеств пяти рекламных агентов по следующим признакам: х1 – эрудиция, х2 – знание предметной области. Полученные средние оценки, нормированные от 0 до 1, были сопоставлены с оценками эффективности деятельности агентов (% успешных сделок от количества возможных). Определить эффективность для агента с усреднёнными качествами. Сравнить её со средней эффективностью упомянутых 5 агентов.
Исходные данные нужно ввести в таблицу вида:
| А | В | С | D | E | F | G | |
|---|---|---|---|---|---|---|---|
| 1 | х1-эрудиция | х2-энергичность | х3-люди | х4-внешность | х5-знания | Эффективность | |
| 2 | Агент 1 | 0,8 | 0,2 | 0,4 | 0,6 | 1,0 | 76% |
| 3 | Агент 2 | 0,74 | 0,3 | 0,39 | 0,58 | 0,95 | 78% |
| 4 | Агент 3 | 0,67 | 0,41 | 0,35 | 0,5 | 0,83 | 79% |
| 5 | Агент 6 | 0,59 | 0,59 | 0,33 | 0,47 | 0,8 | 80% |
| 6 | Агент 5 | 0,5 | 0,7 | 0,3 | 0,4 | 0,74 | 81% |
| 7 | Средняя эффективность пяти агентов | ||||||
| 8 | Средний агент | 0,5 | 0,5 | 0,5 | 0,5 | 0,5 | |
Массив ячеек В2-F6 заполняется произвольными числами от 0 до 1, столбец G2 -G6 – процентами удачных сделок по принципу «Чем выше уровень качеств агента, тем выше эффективность его работы», в ячейке G7 должна быть формула для вычисления среднего значения ячеек G2:G6 , в ячейке G8 нужно вычислить значение эффективности для среднего агента по формуле, полученной в результате множественного регрессионного анализа работы пяти агентов. Остальные пункты – см. Задание.
- Автосалон имеет данные о количестве проданных автомобилей «Мерседес» и «БМВ» за последние 4 квартала. Учитывая тенденцию изменения объёма продаж, определить, каких автомобилей нужно закупить больше («Мерседес» или «БМВ») в следующем квартале?
Для выполнения задания нужно составить и заполнить таблицу вида:
| Х | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Мерседес ( Y1 ) | 10 | 12 | 15 | 18 | |
| БМВ ( Y2 ) | 9 | 10 | 14 | 17 |
сделать прогноз продаж на новый квартал и выполнить другие пункты задания.
- Известны следующие данные о 5 недавно проданных подержанных автомобилях: у – стоимость продажи, х1 – стоимость аналогичного нового автомобиля, х2 – год выпуска, х3 – пробег, х4 – количество капитальных ремонтов, х5 – экспертные заключения о состоянии кузова и техническом состоянии автомобилей (по 10-бальной шкале). Определить, сколько может стоить автомобиль с соответствующими характеристиками: 340 000, 1998г., 140000км., 1, 6 (см. пример 4).
- Определить минимально необходимый тираж журнала и возможный доход от размещения в нём рекламы в следующем месяце, если известны данные об объёмах продаж этого журнала и доходах от размещения рекламы за последние 12 месяцев (считать, что расценки на рекламу не менялись).
Для выполнения задания нужно составить таблицу вида:
| Месяц | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Тираж,тыс. | 100 | 120 | 121,7 | 124,2 | 128 | 130,1 | 133,45 | 136 | 141 | 142,1 | 143,8 | 145 |
| Доход,тыс. руб. | 128 | 135 | 138 | 142 | 147 | 154 | 159 | 161 | 163 | 168 | 170,5 | 172 |
и заполнить ячейки за 12 месяцев условными данными. По этим данным нужно сделать линейный и экспоненциальный прогноз и др. (см. Задание).
- В целях привлечения покупателей и увеличения оборота фирма проводит стратегию ежемесячного снижения цен на свой товар. На основании данных о динамике изменения цен, объемов продаж в данной фирме и ещё в 3 конкурирующих фирмах за последние 12 месяцев сделать прогноз о том, возрастает ли объём продаж у данной фирмы при очередном снижении цен в следующем месяце, если предположить, что цены и объёмы у конкурентов в следующем месяце будут средние за рассматриваемый период.
Для выполнения задания нужно составить таблицу вида:
| Мес. | Фирма | Конкурент 1 | Конкурент 2 | Конкурент 3 | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | У-объём | х1-цена | х2-объём | х3-цена | х4-объём | х5-цена | х6-объём | х7-цена |
| 2 | 10000 | 1875 | 12000 | 1720 | 12500 | 1740 | 11970 | 1700 |
| 3 | 11000 | 1850 | 12340 | 1705 | 12620 | 1735 | 12100 | 1690 |
| 4 | 11570 | 1810 | 12750 | 1675 | 12740 | 1710 | 12350 | 1645 |
| 5 | 11850 | 1750 | 12910 | 1630 | 12960 | 1695 | 12500 | 1615 |
| 6 | 12100 | 1685 | 13100 | 1615 | 13000 | 1674 | 12630 | 1580 |
| 7 | 12340 | 1630 | 13570 | 1600 | 13210 | 1625 | 12920 | 1545 |
| 8 | 12750 | 1615 | 13820 | 1575 | 13320 | 1610 | 13150 | 1520 |
| 9 | 12910 | 1600 | 13980 | 1515 | 13460 | 1560 | 13300 | 1500 |
| 10 | 13100 | 1575 | 14000 | 1500 | 13600 | 1525 | 13610 | 1490 |
| 11 | 13230 | 1530 | 14070 | 1495 | 13780 | 1500 | 13850 | 1485 |
| 12 | 13470 | 1510 | 14120 | 1488 | 13900 | 1460 | 14000 | 1475 |
| 13 | ||||||||
- На основании данных о курсе американского доллара и немецкой марки в первом полугодии сделать прогноз о соотношении данных валют на второе полугодие. Во что будет выгоднее вкладывать деньги в конце года?
Для выполнения задания нужно составить таблицу вида:
| Месяц | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Доллар | 24,5 | 24,9 | 25,7 | 26,9 | 28,0 | 28,8 | 29,3 | 29,7 | 30,5 | 30,9 | 31,8 | |
| Марка | 72,1 | 76,3 | 79,6 | 85,3 | 89,7 | 90,9 | 93,2 | 96,4 | 100,2 | 101,6 | 104,9 |
и сделать линейный прогноз на следующие 6 месяцев и др. (см. Задание).
- Известны данные за последние 6 месяцев о том, сколько раз выходила реклама фирмы, занимающейся недвижимостью, на телевидении – х1, радио – х2, в газетах и журналах – х3, а также количество звонков –у1 и количество совершённых сделок – у2. Какое соотношение количества совершённых сделок к количеству звонков у (в %) можно ожидать в следующем месяце, если известно, сколько раз выйдет реклама в каждом из перечисленных средств массовой информации.
Для выполнения задания нужно составить и заполнить таблицу вида:
| A | B | C | D | E | |
|---|---|---|---|---|---|
| 1 | месяц | х1 | х2 | х3 | y=у2/у1*100% |
| 2 | 1 | 15 | 10 | 24 | 78% |
| 3 | 2 | 16 | 11 | 23 | 80% |
| 4 | 3 | 18 | 12 | 22 | 81% |
| 5 | 4 | 19 | 12 | 22 | 84% |
| 6 | 5 | 21 | 13 | 21 | 85% |
| 7 | 6 | 22 | 14 | 20 | 89% |
| 8 | 7 |
и выполнить применительно к таблице пункты Задания.
- Для некоторого региона известен среднегодовой доход населения, а также данные о структуре расходов (тыс. руб. в год) за последние 5 лет по следующим статьям: питание – х1, жильё – х2, одежда – х3, здоровье – х4, транспорт – х5, отдых – х6, образование – х7. На основании известных данных провести анализ потребительского кредита (или накопления) в следующем 6 году.
Для выполнения задания нужно составить и заполнить таблицу вида
| Годы | х1 | х2 | х3 | х4 | х5 | х6 | х7 | Расход 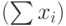 | Доход | Кредит(Y) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 2 | 1,3 | 1 | 0,3 | 5 | 4 | 18,6 | 21,4 | 3,1 |
| 2 | 5,2 | 2,2 | 1,2 | 1,2 | 0,4 | 4,8 | 4,5 | 19,5 | 22 | 2,5 |
| 3 | 5,5 | 2,5 | 1,1 | 1,4 | 0,6 | 4,6 | 4,9 | 20,6 | 23,4 | 2,8 |
| 4 | 5,8 | 2,7 | 0,9 | 1,6 | 1 | 4,2 | 5,6 | 21,8 | 25,8 | 4 |
| 5 | 7 | 3 | 0,8 | 2 | 1,2 | 4 | 6,5 | 24,7 | 26,2 | 1,5 |
| 6 | 7,5 | 3,3 | 0,7 | 2,2 | 1,5 | 3,8 | 7 | 26,5 | 27,5 |
В ячейках столбца 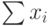 ) должны быть записаны формулы, вычисляющие суммы всех расходов х1+х2+…+х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбца Кредит – формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход- . Затем для столбца Кредит нужно выполнить регрессионный прогноз на следующий год и другие пункты Задания.
) должны быть записаны формулы, вычисляющие суммы всех расходов х1+х2+…+х7 в каждом году, в ячейках столбца Доход – соответствующие среднегодовые доходы, в ячейках столбца Кредит – формулы разности содержимого ячеек с ежегодными доходами и затратами, т.е. Кредит = Доход- . Затем для столбца Кредит нужно выполнить регрессионный прогноз на следующий год и другие пункты Задания.
- Для 10 однокомнатных квартир, расположенных в одном районе, известны следующие данные: общая площадь – х1, жилая площадь – х2, площадь кухни – х3, наличие балкона – х4, телефона – х5, этаж – х6, а также стоимость – y . Определить, сколько может стоить однокомнатная квартира в этом районе без балкона, без телефона, расположенная на 1-ом этаже, общей площадью 28 м 2 , жилой – 16 м 2 , с кухней 6 м 2 .
| Квартиры | X1 | X2 | X3 | X4 | X5 | Стоимость ( y ) |
|---|---|---|---|---|---|---|
| 1 | 41 | 33 | 7 | 1 | 2 | 42000 |
| 2 | 40 | 30 | 7,7 | 2 | 3 | 40000 |
| 3 | 45 | 37 | 8 | 0 | 5 | 47000 |
| 4 | 46,3 | 34 | 9 | 1 | 6 | 49500 |
| 5 | 50 | 36 | 9 | 1 | 4 | 51000 |
| 6 | 53 | 40 | 9,5 | 1 | 7 | 55000 |
| 7 | 56 | 41 | 10 | 0 | 9 | 62000 |
| 8 | 60 | 47 | 12 | 2 | 10 | 62300 |
| 9 | 65 | 49 | 14 | 2 | 12 | 69000 |
| 10 | 70 | 58 | 14,5 | 2 | 14 | 72000 |
| 11 | 28 | 16 | 6 | 0 | 1 |
- Определить возможный прирост населения (кол-во человек на 1000 населения) в 2011 году, если известны данные о кол-ве родившихся и умерших на 1000 населения в 1997-2006 годах.
| Годы | 1997 | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2011 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Родились | 100 | 110 | 130 | 155 | 170 | 174 | 180 | 185 | 190 | 200 | |
| Умерли | 108 | 115 | 135 | 160 | 178 | 180 | 186 | 190 | 197 | 205 |
- После некоторого спада наметился рост объёмов продаж матричных принтеров. Используя данные об объёмах продаж, ценах на матричные, струйные и лазерные принтеры, а также на их расходные материалы за последние 6 месяцев, определить возможный спрос на матричные принтеры в следующем месяце.
Проанализируйте, связано ли увеличение спроса на матричные принтеры с уменьшением спроса на струйные и лазерные.
| Матричные принтеры | Струйные принтеры | Лазерные принтеры | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Спрос у1 | Цена х1 | Рас.мат. z1 | Спрос у2 | Цена х2 | Рас.мат. z/2 | Спрос у3 | Цена х3 | Рас.мат. z3 | |
| 1 | 56 | 4172 | 174 | 26 | 2384 | 558 | 13 | 12517 | 1558 |
| 2 | 58 | 4250 | 179 | 24 | 2398 | 570 | 11 | 12984 | 1612 |
| 3 | 60 | 4289 | 182 | 23 | 2401 | 598 | 9 | 13259 | 1789 |
| 4 | 65 | 4297 | 194 | 20 | 2456 | 649 | 8 | 13687 | 1865 |
| 5 | 69 | 4305 | 205 | 19 | 2512 | 722 | 7 | 14013 | 1998 |
| 6 | 75 | 4318 | 213 | 18 | 2543 | 768 | 6 | 14587 | 2200 |
| 7 | 4456 | 220 | 17 | 2601 | 779 | 5 | 14789 | 2245 | |
Необходимо сделать прогноз на седьмой месяц по уравнению у1=f(x1,z1), получить уравнение y=(у2,x2, z2, у3, x3, z2 ) и проанализировать его. Если слагаемые у2 и у3 входят в регрессионное уравнение со знаком «-«, то уменьшение спросов у2 и у3 ведёт к увеличению спроса у1.
- Построить прогноз развития спроса населения на телевизоры, если известна динамика продаж телевизоров (тыс. шт.) и динамика численности населения (тыс. чел.) за 10 лет. По данным таблицы сделать прогноз по обоим рядам на следующий год. Выполнить другие пункты задания.
| Годы | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Динамика населения (тыс. чел) | 21,5 | 26,1 | 31,5 | 34,9 | 45,1 | 50,8 | 56 | 59,4 | 63,9 | 67,1 | |
| Динамика продаж (тыс. шт.) | 2,5 | 2,9 | 3,4 | 3,9 | 4,1 | 4,8 | 5 | 5,6 | 5,9 | 6,2 |
- Размещая рекламу в 4-х изданиях, фирма собрала сведения о поступивших на нее откликов – у и сопоставила их с данными об изданиях: х1 – стоимость издания, х2 – стоимость одного блока рекламы, х3 – тираж, х4 – объём аудитории, х5 – периодичность, х6 – наличие телепрограммы. Какое количество откликов можно ожидать на рекламу в издании со следующими характеристиками: 15000 руб., 10$, 1000 экз., 25000 чел., 4 раза в месяц, без телепрограммы.
Пользуясь данными таблицы
| Издания | х1 | х2 | х3 | х4 | х5 | х6 | Отклики, у |
|---|---|---|---|---|---|---|---|
| 1 | 10000 | 13 | 700 | 15000 | 4 | 1 | 108 |
| 2 | 12500 | 12 | 850 | 22000 | 8 | 1 | 115 |
| 3 | 15890 | 11,8 | 960 | 28000 | 10 | 0 | 120 |
| 4 | 17850 | 11 | 1200 | 32000 | 26 | 1 | 128 |
| 5 | 15000 | 10 | 1000 | 25000 | 4 | 0 |
необходимо сделать прогноз при заданных характеристиках.
- Размещая свою рекламу в 2-х печатных изданиях одновременно, фирма собрала сведения о количестве поступивших звонков и количестве заключенных сделок по объявлениям в каждом из указанных изданий за последние 12 месяцев. Определить, в каком из изданий и насколько эффективность размещения рекламы в следующем месяце будет больше?
| Месяцы | Издание 1 | Издание 2 | ||
|---|---|---|---|---|
| Звонки | Сделки | Звонки | Сделки | |
| 1 | 98 | 66 | 112 | 79 |
| 2 | 105 | 72 | 143 | 85 |
| 3 | 105 | 75 | 150 | 90 |
| 4 | 110 | 80 | 130 | 100 |
| 5 | 125 | 90 | 120 | 75 |
| 6 | 140 | 100 | 115 | 80 |
| 7 | 136 | 95 | 128 | 82 |
| 8 | 137 | 87 | 132 | 78 |
| 9 | 145 | 102 | 138 | 88 |
| 10 | 123 | 75 | 143 | 92 |
| 11 | 130 | 79 | 150 | 97 |
| 12 | 139 | 88 | 155 | 97 |
| 13 | ||||
Эффективность определяется как сделки/звонки. Сделать линейный и экспоненциальный прогнозы по обоим изданиям.
- Пусть комплект мягкой мебели (диван + 2 кресла) характеризуется стоимостью комплектующих: х1— деревянные подлокотники, х2 – велюровое покрытие, х3 – кресло-кровать, х4 – угловой диван, х5 – раскладывающийся диван, х6 – место для хранения белья. По данным о стоимости 5 комплектов сделать вывод о возможной стоимости комплекта с обычным раскладывающимся диваном, с местом для белья, без деревянных подлокотников и велюрового покрытия, с креслом кроватью.
Пользуясь данными таблицы
| Признаки | х1 | х2 | х3 | х4 | х5 | х6 | У -стоимость |
|---|---|---|---|---|---|---|---|
| Комплект 1 | 250 | 540 | 2500 | 4300 | 6400 | 800 | 13850 руб. |
| Комплект 2 | 320 | 650 | 3000 | 4800 | 7000 | 980 | 15770 руб. |
| Комплект 3 | 400 | 730 | 3900 | 6000 | 8500 | 1100 | 16730 руб. |
| Комплект 4 | 452 | 1300 | 4300 | 7500 | 9200 | 2050 | 24350 руб. |
| Комплект 5 | 550 | 1750 | 6400 | 12450 | 16700 | 4300 | 42150 руб. |
| Комплект 6 | 670 | 800 | 2750 | 6700 | 8800 | 1000 |
сделать прогноз и выполнить другие пункты задания.
- Для 2-х радиостанций известны данные об изменении объёма аудитории и динамике роста цен за 1 минуту эфирного времени за последние 12 месяцев. Определить, для какой радиостанции стоимость одного контакта со слушателем будет меньше?
| Месяц | Радиостанция 1 | Радиостанция 2 | ||
|---|---|---|---|---|
| Аудитория | Цена 1 мин. | Аудитория | Цена 1 мин. | |
| 1 | 250000 | 8000 | 300000 | 7560 |
| 2 | 540000 | 6500 | 450000 | 6340 |
| 3 | 580000 | 6460 | 490000 | 6250 |
| 4 | 650000 | 6300 | 550000 | 6000 |
| 5 | 730000 | 6060 | 610000 | 5730 |
| 6 | 750000 | 6000 | 690000 | 5300 |
| 7 | 800000 | 5400 | 750000 | 5100 |
| 8 | 840000 | 5320 | 780000 | 5000 |
| 9 | 890000 | 5130 | 870000 | 4700 |
| 10 | 950000 | 5000 | 900000 | 4650 |
| 11 | 1000000 | 4800 | 940000 | 4600 |
| 12 | 1108000 | 4700 | 1025000 | 4540 |
| 13 | ||||
| Контакт | ||||
В строке «Контакт» в ячейках С8 и D8 должны быть записаны формулы = С7/В7 и =Е7/D7 соответственно, вычисляющие стоимость 1 мин. Эфира для одного слушателя в прогнозируемом месяце. Прогноз нужно выполнить для линейного и экспоненциального приближений и выбрать более достоверный, а также сделать другие пункты Задания.
- На основании данных ежемесячных исследований известна динамика рейтинга банка (в условных единицах) за последние 6 месяцев в следующих сферах:
- менеджмент и технология – х1;
- менеджеры и персонал – х2;
- культура банковского обслуживания – х3;
- имидж банка на рынке финансовых услуг – х4;
- реклама банка – х5.
Определить возможное изменение количества вкладчиков данного банка в следующем месяце, если известны значения сфер рейтинга и количество вкладчиков в каждом из рассматриваемых 6 месяцев.
http://masters.donntu.org/2005/kita/tokarev/library/linreg.htm
http://intuit.ru/studies/courses/3659/901/lecture/32718