Прогнозирование показателей внешней торговли по уравнению регрессии
Автор работы: Пользователь скрыл имя, 18 Января 2015 в 19:48, курсовая работа
Краткое описание
В настоящее время ни одна сфера жизни общества не может обойтись без прогнозов как средства познания будущего. Особенно важное значение имеют прогнозы внешней торговли, обоснование основных направлений экономической политики, предвидение последствий принимаемых решений.
Внешнеторговое предвидение предполагает использование специальных вычислительных и логических приемов, позволяющих определить параметры функционирования отдельных элементов производительных сил в их взаимосвязи и взаимозависимости.
Вложенные файлы: 1 файл
Kursovaya_po_statistike_Mironov.docx
Главной причиной неточности прогноза является не столько неопределенность экстраполяции линии регрессии, сколько значительная вариация показателя за счет неучтенных в модели факторов. Ограничением возможности прогнозирования служит условие стабильности неучтенных в модели параметров и характера влияния учтенных факторов модели. Если резко меняется внешняя среда, то составленное уравнение регрессии потеряет свой смысл. 5
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения параметра, является точечным. Вероятность реализации такого прогноза ничтожна мала. Целесообразно определить доверительный интервал прогноза. Для индивидуальных значений показателя интервал должен учитывать ошибки в положении линии регрессии и отклонения индивидуальных значений от этой линии.
Для проведения регрессионного анализа необходимо следующее:
• Выбор одного блока, из которого берется координатный интервал, чьи данные (переменная значения) дают зависимую переменную регрессии. Например, в качестве переменной Y из блока заболеваемости берется обращаемость в координатном интервале «пневмония» координаты «диагноз».
• Выбор одного или нескольких блоков, из которых аналогично берутся факторы в качестве независимых переменных регрессии. Например, данные в координатном интервале «концентрация SO2» берутся в качестве X1, а в координатном интервале «скорость ветра» — в качестве X2. При этом необходимо, чтобы блок, дающий зависимую переменную, и все блоки, дающие независимые переменные, имели какие-либо общие координаты (обычно пространство и время), которые служат переменными развертки и дают точки, по которым проводится регрессионная кривая или поверхность.
• Выбор типа и «степени» функций от независимых переменных, которые включаются в регрессию. Например, при выборе полиномиальных функций с максимальной степенью 2 и при двух независимых переменных X1 и X2 регрессия ищется в виде
Y = a + bX1 + cX2 + dX12 + eX22 + fX1X2
(a — f -регрессионные коэффициенты).
• Задание координатных интервалов переменных сравнения, внутри которых регрессионная функция не должна значимо изменяться. Так, в вышеописанном случае можно потребовать, чтобы регрессионная функция вообще не зависела от половозрастной группы, или была одной для всех мужчин и другой — для всех женщин, или своей в каждой половозрастной группе. Эта информация используется для регуляризации регрессии гребневым или энтропийным методом.
• Регрессия проводится последовательно с увеличением числа независимых переменных и степени регрессионной функции. При этом общесистемным оптимизатором находится минимум среднеквадратичного отклонения точек данных от регрессионной кривой. 6
Для регрессионной кривой вычисляются характеристики неопределенности — показатели тесноты регрессии: кривые доверительного интервала и коэффициент детерминации. Последний может вычисляться сразу для всех комбинаций «зависимая переменная — независимая переменная» и представляться в виде цветокодированной таблицы. Такое представление близко к цветокодированию коэффициента корреляции. Разница между ними связана с возможностью выбора типа и степени регрессионной функции при регрессионном анализе.
Аналогично построению таблицы условных корреляций, в регрессионном анализе может строиться таблица «условных» коэффициентов детерминации. При этом в регрессию для каждой пары факторов дополнительно включается еще несколько факторов, выбранных пользователем. Например, строятся регрессии данных обращаемости по каждому диагнозу на концентрацию каждого загрязнителя, и при этом в регрессию дополнительно включается в качестве независимой переменной скорость ветра. Сравнение таких таблиц с аналогичными «безусловными» позволяет определить, в какие регрессии нужно дополнительно включить факторы, выбранные пользователем в качестве условных.
Как и для коэффициентов корреляции, для коэффициентов детерминации можно строить дерево вкладов координатных интервалов переменных развертки. Оно позволяет скорректировать выборку для достижения более тесной регрессии. Кроме того, выбрав координатный интервал в дереве, можно построить отдельные регрессионные функции во всех его подынтервалах и по результатам расслоить выборку на части с более устойчивой регрессией. В частности, можно построить «иерархическую регрессию», при которой коэффициенты регрессии внутри каждого координатного интервала рассчитываются как поправки к коэффициентам регрессии координатного интервала, следующего вверх по иерархии. При использовании такой регрессии в качестве эмпирической модели, разные коэффициенты выступают как варианты модели. 7
Как и корреляция, регрессия рассчитывается для фиксированных координатных интервалов каждой переменной сравнения. Как указано выше, проверяется устойчивость регрессии к смене координатного интервала на том же уровне иерархии. Строится также дерево вкладов подынтервалов для выбранных пользователем переменной сравнения и координатного интервала. Возможно также построение иерархической регрессии по дереву выбранной переменной сравнения. При этом, в отличие от иерархической регрессии по дереву переменной значения, разные регрессии в дереве выступают не как варианты, а применяются соответственно значениям переменных сравнения, подаваемым на вход модели. Возможно также построение отдельной регрессии для каждого диапазона значений независимой или зависимой переменной. В первом случае получаются сплайны с числом узлов, задаваемым пользователем. Во втором случае различные регрессии образуют пакет вариантов, так что выбор подходящего диапазона при использовании такой регрессии в качестве эмпирической модели осуществляется в рамках общей идеологии выбора оптимального варианта. 8
Для визуализации многофакторной регрессии пользователь выбирает тот фактор, который представляется как абсцисса регрессионной кривой, и фиксирует значения прочих независимых факторов. На коэффициенты регрессии это не влияет.
2. ПРОГНОЗИРОВАНИЕ ПОКАЗАТЕЛЕЙ ВНЕШНЕЙ ТОРГОВЛИ ПО УРАВНЕНИЮ РЕГРЕССИИ
Непременным элементом системы долгосрочных, среднесрочных и краткосрочных прогнозов социально-экономического развития, являются прогнозы внешней торговли. Динамика объема и структуры экспорта, импорта, внешнеторговых цен оказывают непосредственное влияние на отраслевые и территориальные пропорции, объемы ВВП, доходы федерального и регионального бюджетов, поступление таможенных платежей, рентабельность предприятий, уровень розничных цен, реальные доходы населения. Годин, А.М. Статистика: учебник / А.М. Годин. — Москва: Дашков 2012. — С. 88
По данным таможенной статистики в январе-апреле 2014 года внешнеторговый оборот России составил 262,7 млрд. долларов США и по сравнению с январем-апрелем 2013 года снизился на 2,8%.
Импорт составил 92,5 млрд. долларов США и уменьшился и по сравнению с январем-апрелем 2013 года, но уже значительнее — на 6,8%.(см рис. 1)
Рис. 1. Статистика внешней торговли России
Как же составить прогноз внешней торговли?
Чтобы получить прогнозное значение показателя внешней торговли, необходимо в построенное уравнение связи подставить ожидаемое, предполагаемое, ранее спрогнозированное или нормативное значение факторного признака. В результате будет получен точечный прогноз, который будет содержать ошибки. Поэтому прогноз показателя внешней торговли следует давать в виде доверительного интервала с заданной вероятностью. Для получения доверительного интервала прогноза рассчитываются ошибки прогноза. Средняя ошибка прогноза определяется по формуле:
Где — прогнозное значение факторного признака.
Затем рассчитывается предельная ошибка прогноза по формуле:
Значение t-критерия Стьюдента определяется по таблице с учетом числа степеней свободы системы (n-m) и с заданной вероятностью (см. рис. 2). При этом n- число единиц совокупности, а m- число параметров уравнения регрессии. При оценке прогноза, как правило, задаются вероятностью 95% или 90%. Зная предельную ошибку можно определить доверительный интервал прогноза:
Рис. 2. Значения t-критерия Стьюдента
Доверительный интервал показывает, что фактическая реализация прогноза будет заключена в данном интервале с заданной вероятностью.
Регрессионый анализ с целью прогнозирования цен на фондовой бирже. История эксперимента, рабочий пример, результаты
Как всегда, все началось с идеи: а что если поискать корреляцию между индексом ММВБ и ценами акций, входящими в данный индекс, но только использовать цены следующего дня? Например, искать корреляцию между ценой закрытия индекса ММВБ на дату Х и ценой закрытия акции Газпрома на дату (X+1)? Зачем? Затем чтобы, зная цену закрытия индекса ММВБ сегодня, прогнозировать цену закрытия любой акции завтра.
Что получилось, читайте далее…
Статья не является инвестиционной рекомендацией, а скорей результатом индивидуального околоматематического исследования. Не судите строго, мне просто интересно этим заниматься, это мое хобби.
Думаю, следует кратко написать о регрессионном анализе. Википедия конечно дает ответ, но для тех, кто математику подзабыл, читается сложновато. На самом деле все проще, более того, уверен что вы используете регрессию почти ежедневно. Допустим вы любите кофе, часто его пьете и знаете сколько стоит чашечка кофе рядом с вашим домом, офисом и также местах в городе, которые вы посещали. И если вас спросят «сколько может стоить чашечка кофе в центре города?» — вы сможете спрогнозировать цену с определенной точностью. Те, кто занимаются недвижимостью — могут спрогнозировать примерную цену на недвижимость на которой специализируются. Ну и так далее. Причем, чем больше опыт — тем выше ваша точность. Во всех подобных ситуациях наше сознание выполняет функцию регрессионного анализа. Конечно, это достаточно сильное упрощение.
Свою задачу разбил на этапы:
- Получение массива цен закрытия индекса ММВБ и цен акций, входящих в индекс.
- По каждой паре «Акция, Индекс» считаем коэффициент корреляции Пирсона, индексы b0 и b1 уравнения регрессионной прямой, рисуем регрессионную прямую.
- Если коэффициент корреляции больше 0.5, т.е. если данные будут коррелировать, то я могу подставить в полученное уравнение цену закрытия индекса ММВБ на сегодня и спрогнозировать цену интересущей меня акции на завтра… Еще раз акцентирую Ваше внимание, я считаю корреляцию между значением индекса на сегодня и ценой актива(акции) на завтра.
- Вступаю в клуб анонимных финансовых гуру.
Теперь подробнее о реализации и результатах
Конечно можно было бы воспользоваться услугами брокера и просто выгрузить этот небольшой массив напрямую из торгового терминала (например из Quik). Однако, данные я хочу получать ежедневно и в автоматическом режиме, независимо от того, включаю я терминал или нет. Поэтому самый простой способ, это забирать данные из первоисточника, точнее напрямую с биржы ММВБ. У них есть классное API, вот описание:
Есть небольшое ограничение на количество выдаваемых сервером записей, но я это заметил только на момент получения исторических данных за период с начала года. Обошел посредством деления периода на более короткие промежутки времени. Как говорится, python в помощь.
Как реализован процесс получения и обработки итогов торгов на текущий момент:
- Каждую ночь, с помощью cron, запускается скрипт который запрашивает данные за прошедший торговый день с сервера биржи ММВБ
- Полученные данные загружаются в таблицу MySQL на сервере
- После сохранения данных запускается скрипт пересчета всех коэффициентов
В реализации использовал Flask+MySQL+Requests+Jinja. Графики вывожу с помощью Chart.js Нет, не использовал sklearn для подсчета коэффициентов регрессии, т.к. расчетов по минимуму и требования по производительности не высоки.
Расчеты
По полученным данным считал коэффициент корреляции Пирсона, далее обсчитывал коэффициенты b0 и b1 уравнения регрессионной прямой, используя метод наименьших квадратов. Что не сделано: не считал коэффициент детерминации с целью проверки гипотезы о значимости, а также не проводил расчеты полиноминальной регрессии, только линейной. «Почему так небрежно ?», спросите Вы? Отвечаю: не удовлетворен результатами расчетов, в частности большой величиной среднеквадратичного отклонения, что делает все расчеты весьма приблизительными.
Тем не менее, результаты этой неудачной, но все же работы, Вы можете увидеть вот здесь. Ресурс в публичном доступе, расчеты проводятся автоматически также каждую ночь, без моего участия.
Как это выглядит, хочу показать на примере:
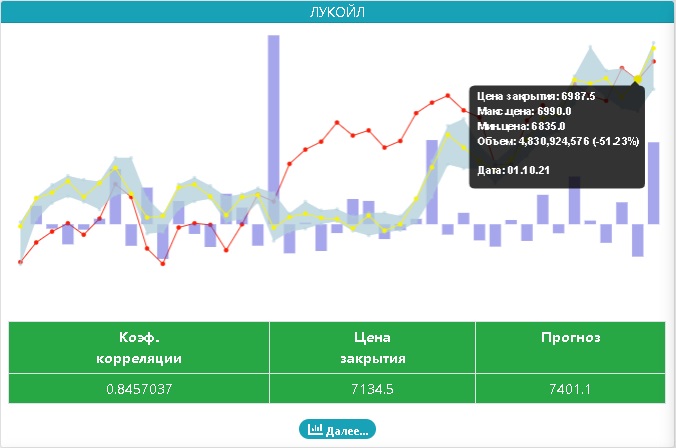
- красная кривая — график цен закрытия индекса ММВБ (IMOEX)
- желтая кривая — график цен закрытия актива (в данном примере «Лукойл»)
Чуть ниже приведена таблица в результатами прогнозирования, причем цветом таблицы выделяется результат прогноза:
- Серый цвет — нет вменяемой корреляции (коэффициент корреляции в диапазоне [-0.5; +0.5])
- Красный цвет, корреляция есть, прогноз на понижение
- Зеленый цвет, корреляция есть, прогноз на рост цены актива
Жмем кнопку «Далее» и видим результаты расчетов и график разброса цен индекса ММВБ к ценам закрытия (на следующий день)

Все здорово, красиво, прямо как по учебнику статистики. Уверен, если постараться, можно даже «добиться» графика нормального распределения остатков. Но, что не так? Ниже графика я привел все расчеты, смотрим на последнюю строку:
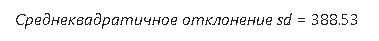
Ага, а прогноз у нас 7401.10 руб исходя из текущей цены в 7134.5руб. Простыми словами это звучит так: «прогнозирую рост на 3.7% при точности в плюс/минус 5.4%»

Вот такая вот история неудачи 🙂
Что еще хотелось бы добавить к описанному:
- Через свою модель считал регрессию не только по отношению к индексу ММВБ, но и к фьючерсам, в том числе и по фьючерсам на конкретный актив. Корреляции особо не увидел;
- Для себя удалось разрушить некоторые стереотипы аналитиков. В частности о обратной корреляции золота к рынку (когда рынок растет, золото падает и наоборот). Посмотрите на графики золотодобывающих компаний и поймете что это не так;
- Что касается газпрома и сбербанка — несмотря на хорошую корреляцию, расчеты не объективны, т.к. данные активы занимают существенную долю в индексе (более 30%);
- Поэтому, в своих расчетах, склонен придерживаться своей «старой позиции»: следовать за большими объемами, крупными сделками (или сериями сделок) на покупку/продажу
http://econ.bobrodobro.ru/86904
http://habr.com/ru/post/581822/