Проверка общего качества уравнения
Множественной регрессии
Для проверки общего качества уравнения регрессии обычно используется коэффициент детерминации R 2 , который характеризует долю дисперсии зависимой переменной Y, объясняемую регрессионной моделью, и определяется по формуле:
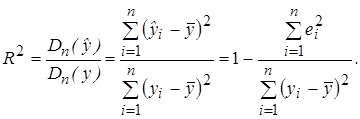 (3.27)
(3.27)
Свойства коэффициента R 2 подробно рассмотрены в разделе 2.4.
Для множественной регрессии коэффициент детерминации (или множественный коэффициент детерминации) является неубывающей функцией числа объясняющих переменных, т. е. добавление новой объясняющей переменной (фактора-аргумента Х) в модель никогда не уменьшает значение R 2 . Действительно, каждая новая объясняющая переменная может лишь дополнить информацию, объясняющую поведение зависимой переменной. В целом это уменьшает неопределенность в поведении исследуемой величины Y. Однако увеличение R 2 при добавлении новых переменных далеко не всегда приводит к улучшению качества регрессионной модели, так как эти переменные могут не оказывать существенного влияния на результативный признак. Поэтому, наряду с коэффициентом R 2 , для анализа используется скорректированный коэффициент детерминации 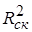 , определяемый соотношением:
, определяемый соотношением:
 (3.28)
(3.28)
или с учетом (3.27)
 . (3.29)
. (3.29)
Можно заметить, что знаменатель в (3.29) является несмещенной оценкой общей дисперсии зависимой переменной Y, а числитель – несмещенной оценкой остаточной дисперсии (дисперсии случайных отклонений).
Скорректированный коэффициент детерминации устраняет (корректирует) неоправданный эффект, связанный с ростом R 2 при увеличении числа объясняющих переменных. Из (3.28) следует, что 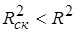 при m > 1 Можно показать, что увеличивается при добавлении новой объясняющей переменной только тогда, когда t-статистика для этой переменной по модулю больше единицы, т. е. когда ее коэффициент регрессии (параметр модели) считается относительно значимым. Таким образом, в определенной степени использование скорректированного коэффициента детерминации более предпочтительно для сравнения регрессионных моделей при изменении количества объясняющих переменных (регрессоров). Добавление в модель новых регрессоров может осуществляться до тех пор, пока растет .
при m > 1 Можно показать, что увеличивается при добавлении новой объясняющей переменной только тогда, когда t-статистика для этой переменной по модулю больше единицы, т. е. когда ее коэффициент регрессии (параметр модели) считается относительно значимым. Таким образом, в определенной степени использование скорректированного коэффициента детерминации более предпочтительно для сравнения регрессионных моделей при изменении количества объясняющих переменных (регрессоров). Добавление в модель новых регрессоров может осуществляться до тех пор, пока растет .
В компьютерных пакетах приводятся данные как по R 2 , так и по , которые используются на практике для оценки суммарной меры общего качества построенной регрессионной модели.
В общем случае качество модели считается удовлетворительным, если R 2 > 0,5. Однако не следует рассматривать коэффициент детерминации как абсолютный показатель качества модели. Можно привести ряд примеров, когда неправильно специфицированные модели имели сравнительно высокие коэффициенты детерминации. Поэтому коэффициент детерминации в современной эконометрике следует рассматривать лишь как один из показателей, который необходим для анализа строящейся модели.
Анализ общей (совокупной) статистической значимости уравнения множественной регрессии осуществляется на основе проверки основной гипотезы об одновременном равенстве нулю всех коэффициентов при объясняющих переменных:
Если данная гипотеза не отклоняется, то естественно считать уравнение модели статистически незначимым, т. е. не выражающим существенную линейную связь между Y и Х1, Х2, …, Хm.
Напомним (см. раздел 2.4.3), что общая дисперсия зависимой переменной Dn(y) может быть представлена в виде суммы двух составляющих:

где  Dn(y) – соответственно, дисперсия, объясняемая уравнением множественной регрессии, и необъясняемая (остаточная) дисперсия, характеризующая влияние неучтенных факторов.
Dn(y) – соответственно, дисперсия, объясняемая уравнением множественной регрессии, и необъясняемая (остаточная) дисперсия, характеризующая влияние неучтенных факторов.
Исходя из этого проводится дисперсионный анализ для проверки гипотезы Н0 (F-тест).
Строится проверочная F-статистика:
 (3.30)
(3.30)
где  – объясняемая дисперсия (в уравнении множественной регрессии вместе со свободным членом оценивается k = m + 1 параметров);
– объясняемая дисперсия (в уравнении множественной регрессии вместе со свободным членом оценивается k = m + 1 параметров);  – остаточная дисперсия. При выполнении предпосылок МНК построенная статистика имеет распределение Фишера с числами степеней свободы v1 = m, v2 = n — m — 1. Поэтому гипотеза Н0 отклоняется, если при заданном уровне значимости a значение Fнабл, рассчитанное по формуле (3.30), больше, чем критическое значение Fкр = Fa; m; n — 1 — m (Fнабл > Fкр), и делается вывод о статистической значимости уравнения множественной регрессии. В противном случае (Fнабл > Fкр) нет оснований для отклонения Н0. Это означает, что объясняемая построенной моделью дисперсия соизмерима с дисперсией, вызванной неучтенными факторами, а следовательно, общее качество модели невысоко.
– остаточная дисперсия. При выполнении предпосылок МНК построенная статистика имеет распределение Фишера с числами степеней свободы v1 = m, v2 = n — m — 1. Поэтому гипотеза Н0 отклоняется, если при заданном уровне значимости a значение Fнабл, рассчитанное по формуле (3.30), больше, чем критическое значение Fкр = Fa; m; n — 1 — m (Fнабл > Fкр), и делается вывод о статистической значимости уравнения множественной регрессии. В противном случае (Fнабл > Fкр) нет оснований для отклонения Н0. Это означает, что объясняемая построенной моделью дисперсия соизмерима с дисперсией, вызванной неучтенными факторами, а следовательно, общее качество модели невысоко.
Если рассчитан коэффициент детерминации R 2 , то критерий значимости уравнения регрессии (3.30) может быть представлен в следующем виде:
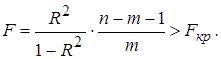 (3.31)
(3.31)
Критерий (3.31) обычно используется на практике для тестирования гипотезы о статистической значимости коэффициента детерминации (Н0 : R 2 = 0; Н1 : R 2 > 0) которая эквивалентна гипотезе об общей статистической значимости уравнения множественной регрессии.
Отметим, что в отличие от парной регрессии, где t-тест и F-тест равносильны, в случае множественной регрессии коэффициент R 2 приобретает самостоятельную значимость.
Пример 3.2. Оценим статистическую значимость построенной модели.
Пусть при оценке регрессии с тремя объясняющими переменными (  по 30 наблюдениям получено значение коэффициента детерминации R 2 = 0,7. Тогда, наблюдаемое значение F-статистики
по 30 наблюдениям получено значение коэффициента детерминации R 2 = 0,7. Тогда, наблюдаемое значение F-статистики 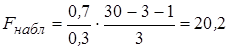 . По таблице критических точек распределения Фишера найдем F0,05; 3; 26 = 2,98 при заданном уровне значимости a = 0,05. Поскольку Fнабл = 20,2 > Fкр = 2,98, то нулевая гипотеза отклоняется, т. е. отвергается предположение о незначимости линейной связи.
. По таблице критических точек распределения Фишера найдем F0,05; 3; 26 = 2,98 при заданном уровне значимости a = 0,05. Поскольку Fнабл = 20,2 > Fкр = 2,98, то нулевая гипотеза отклоняется, т. е. отвергается предположение о незначимости линейной связи.
Мультиколлинеарность
Весьма нежелательным эффектом, который может проявляться при построении моделей множественной регрессии и искажать статистическую информацию, полученную по модели, является мультиколлинеарность [1,28,33]– линейная взаимосвязь двух или нескольких объясняющих переменных. Различают функциональную и корреляционную формы мультиколлинеарности.
При функциональной форме мультиколлинеарности по крайней мере два регрессора связаны между собой линейной функциональной зависимостью. В этом случае определитель матрицы Х Т Х равен нулю в силу присутствия линейно зависимых вектор-столбцов (нарушается предпосылка 5 МНК), что приводит к невозможности решения соответствующий системы уравнений и получения оценок параметров регрессионной модели.
Однако в эконометрических исследованиях мультиколлинеарность чаще всего проявляется в более сложной корреляционной форме, когда между хотя бы двумя объясняющими переменными существует тесная корреляционная связь. Ниже рассмотрены некоторые способы обнаружения, а также уменьшения и устранения мультиколлинеарности.
Один из таких способов заключается в исследовании матрицы Х Т Х. Если ее определитель близок к нулю, то это может свидетельствовать о наличии мультиколлинеарности. В этом случае наблюдаются значительные стандартные ошибки коэффициентов регрессии и их статистическая незначимость по t-критерию, хотя в целом регрессионная модель может оказаться значимой по F-тесту.
Другой подход состоит в анализе матрицы парных коэффициентов корреляции между объясняющими переменными (факторами). Если бы факторы не коррелировали между собой, то корреляционная матрица R была бы единичной матрицей, поскольку все недиагональные элементы (хi ¹ xj) равны нулю. Определитель такой матрицы равен единице [Тимофеев, 2013]. Например, для модели, включающей три объясняющих переменных  , в этом случае имеем:
, в этом случае имеем:
 . (3.32)
. (3.32)
Если же, наоборот, между факторами-аргументами существует полная линейная зависимость и все коэффициенты корреляции равны 1 (|rij| = 1), то определитель матрицы межфакторной корреляции равен нулю
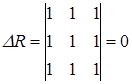 . (3.33)
. (3.33)
Таким образом, чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность объясняющих переменных и ненадежнее оценки множественной регрессии, полученные с использованием МНК.
Если в модели больше двух объясняющих переменных, то для обнаружения мультиколлинеарности полезно находить частные коэффициенты корреляции, поскольку парные коэффициенты корреляции определяют силу линейной зависимости между двумя факторами без учета влияния на них других объясняющих переменных. Например, между двумя экономическими переменными может наблюдаться высокий положительный коэффициент корреляции совсем не потому, что одна из них стимулирует изменение другой, а вследствие того, что обе эти переменные изменяются в одном направлении под влиянием других факторов, присутствующих в модели. Поэтому возникает необходимость оценки действительной тесноты (силы) линейной связи между двумя факторами, очищенной от влияния других переменных. Параметр, определяющий степень корреляции между двумя факторами Хi и Xj при исключении влияния остальных переменных называется частным коэффициентом корреляции.
Например, в случае модели с тремя объясняющими переменными Х1, Х2, Х3 частный коэффициент корреляции между Х1 и Х2 рассчитывается по формуле:
 (3.34)
(3.34)
Частный коэффициент корреляции может существенно отличаться от «обычного» парного коэффициента корреляции r12. Пусть, например, r12 = 0,5; r13 = 0,5; r23 = -0,5. Тогда частный коэффициент корреляции r12.3 = 1 (3.34), т. е. при относительно невысоком коэффициенте корреляции r12 частный коэффициент корреляции указывает на высокую зависимость (коллинеарность) между переменными Хi и Xj.
Таким образом, для обоснованного вывода о корреляции между объясняющими переменными множественной регрессии необходимо рассчитывать частные коэффициенты корреляции.
Частный коэффициент корреляции rij.1, 2, …, m, как и парный коэффициент rij, может принимать значения от -1 до 1. Присутствие в модели пар переменных, имеющих высокие коэффициенты частной корреляции (обычно больше 0,8), свидетельствует о наличии мультиколлинеарности.
Для устранения или уменьшения мультиколлинеарности используется ряд методов, простейшим из которых является исключение из модели одной или нескольких коррелированных переменных. Обычно решение об исключении какой-либо переменной принимается на основании экономических соображений. Следует заметить, что при удалении из анализа объясняющей переменной можно допустить ошибку спецификации. Например, при изучении спроса на некоторый товар в качестве объясняющих переменных целесообразно использовать цену данного товара и цены товаров-заменителей, которые зачастую коррелируют друг с другом. Исключив из модели цены заменителей, мы, вероятнее всего, допустим ошибку спецификации. Вследствие этого можно получить смещенные оценки и сделать ненадежные выводы.
Иногда для уменьшения мультиколлинеарности достаточно (если это возможно) увеличить объем выборки. Например, при использовании ежегодных показателей можно перейти к поквартальным данным. Увеличение количества данных сокращает дисперсии коэффициентов регрессионной модели и тем самым увеличивает их статистическую значимость.
В ряде случаев минимизировать либо вообще устранить мультиколлинеарность можно с помощью преобразования переменных, в результате которого осуществляется переход к новым переменным, представляющим собой линейные или относительные комбинации исходных [11].
Например, построенная регрессионная модель имеет вид:
 (3.35)
(3.35)
причем Х1 и Х2 – коррелированные переменные. В этом случае целесообразно оценивать регрессионные уравнения относительных величин:
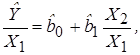
 .
.
Следует ожидать, что в моделях, построенных аналогично (3.36), эффект мультиколлинеарности не будет проявляться.
Существуют также другие, более теоретически разработанные способы обнаружения и подавления мультиколлинеарности, подробное описание которых выходит за рамки данной книги. Одним из таких методов является факторный анализ. Сущностью факторного анализа является процедура вращения факторов, т.е. перераспределение дисперсии по определённому методу с целью получения максимально простой и наглядной структуры факторов (выделение главных компонент) [23,35]. В результате проведения факторного анализа можно соответствующим образом сократить число переменных, тем самым избежать проявления мультиколлинеарности. При этом в один фактор объединяются сильно коррелирующие между собой переменные, что позволяет проводить регрессионный анализ на главных компонентах.
Факторный анализ играет большую самостоятельную роль в экономике и, прежде всего, разработан для поиска ненаблюдаемых, латентных переменных (факторов), имеющих определённый социально-экономический смысл [23].
Следует заметить, что если основная задача, решаемая с помощью эконометрической модели – прогнозирование поведения реального экономического объекта, то при общем удовлетворительном качестве модели проявление мультиколлинеарности не является слишком серьезной проблемой, требующей приложения больших усилий по ее выявлению и устранению, т. к. в данном случае наличие мультиколлинеарности не будет существенно сказываться на прогнозных качествах модели. Таким образом, вопрос о том – следует ли серьезно заниматься проблемой мультиколлинеарности или «смириться» с ее проявлением – решается исходя из целей и задач эконометрического анализа.
Вопросы и упражнения для самопроверки
1. Какова общая структура модели множественной линейной регрессии?
2. Опишите алгоритм определения коэффициентов множественной линейной регрессии (параметров модели) по МНК в матричной форме.
3. Как определяется статистическая значимость коэффициентов регрессии?
4. В чем суть скорректированного коэффициента детерминации и его отличие от обычного R 2 ?
5. Как используется F-статистика во множественном регрессионном анализе?
6. Вычислите величину стандартной ошибки регрессионной модели со свободным членом и без него, если 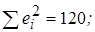 n = 30; m = 3.
n = 30; m = 3.
7. На основе n = 30 наблюдений оценена модель с тремя объясняющими переменными. Получены следующие результаты:

Стандартные ошибки (2,5) (1,6) (2,8) (0,07)
Проведите необходимые расчеты и занесите данные в скобки. Сделайте выводы о существенности коэффициентов регрессии на уровне значимости a =0,05.
8. Имеются данные о ставках месячных доходов по трем акциям за шестимесячный период:
| Акция | Доходы по месяцам, % | |||||
| А | 5,4 | 5,3 | 4,9 | 4,9 | 5,4 | 6,0 |
| В | 6,3 | 6,2 | 6,1 | 5,8 | 5,7 | 5,7 |
| С | 9,2 | 9,2 | 9,1 | 9,0 | 8,7 | 8,6 |
Есть основания предполагать, что доходы по акции С(Y) зависят от доходов по акциям А(X1) и В(X2). Необходимо:
а) составить уравнение регрессии Y по X1 и X2 с использованием МНК (указание: для удобства вычислений сумм первых степеней, квадратов и попарных произведений переменных составьте вспомогательную таблицу);
б) найти множественный коэффициент детерминации R 2 и оценить общее качество построенной модели;
в) проверить значимость полученного уравнения регрессионной модели на уровне a = 0,05.
9. Объясните суть матрицы ковариаций случайных отклонений.
10. Дайте определение и объясните смысл мультиколлинеарности факторов-аргументов.
11. Каковы основные последствия мультиколлинеарности?
12. Какие вы знаете способы обнаружения мультиколлинеарности?
13. Как оценивается степень коррелированности между двумя объясняющими переменными?
14. Перечислите основные методы устранения мультиколлинеарности.
15. В чем заключается сущность факторного анализа?
16. Как определяются парный и частный коэффициенты корреляции для независимых переменных.
17. Для модели с тремя независимыми переменными X1, X2, X3 построенной по n = 50 наблюдениям, определена следующая корреляционная матрица:
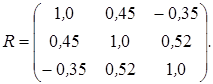
б) определить, имеет ли место мультиколлинеарность для уравнения регрессии.
Проверка общего качества уравнения множественной регрессии
Проверка статистической значимости коэффициентов уравнения множественной регрессии
Как и в случае множественной регрессии, статистическая значимость коэффициентов множественной регрессии с m объясняющими переменными проверяется на основе t-статистики:

имеющей в данном случае распределение Стьюдента с числом степеней свободы v = n- m-1. При требуемом уровне значимости наблюдаемое значение t-статистики сравнивается с критической точной  распределения Стьюдента.
распределения Стьюдента.
В случае, если 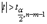 , то статистическая значимость соответствующего коэффициента множественной регрессии подтверждается. Это означает, что фактор Xj линейно связан с зависимой переменной Y. Если же установлен факт незначимости коэффициента bj, то рекомендуется исключить из уравнения переменную Xj. Это не приведет к существенной потере качества модели, но сделает ее более конкретной.
, то статистическая значимость соответствующего коэффициента множественной регрессии подтверждается. Это означает, что фактор Xj линейно связан с зависимой переменной Y. Если же установлен факт незначимости коэффициента bj, то рекомендуется исключить из уравнения переменную Xj. Это не приведет к существенной потере качества модели, но сделает ее более конкретной.
29.Прогнозирование с помощью модели множественной регрессии.
Уравнение регрессии применяют для расчета значений показателя в заданном диапазоне изменения параметров. Оно ограниченно пригодно для расчета вне этого диапазона, т.е. его можно применять для решения задач интерполяции и в ограниченной степени для экстраполяции.
Прогноз, полученный подстановкой в уравнение регрессии ожидаемого значения параметра, является точечным. Вероятность реализации такого прогноза ничтожна мала. Целесообразно определить доверительный интервал прогноза.
Для того чтобы определить область возможных значений результативного показателя, при рассчитанных значениях факторов следует учитывать два возможных источника ошибок: рассеивание наблюдений относительно линии регрессии и ошибки, обусловленные математическим аппаратом построения самой линии регрессии. Ошибки первого рода измеряются с помощью характеристик точности, в частности, величиной 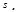 . Ошибки второго рода обусловлены фиксацией численного значения коэффициентов регрессии, в то время как они в действительности являются случайными, нормально распределенными.
. Ошибки второго рода обусловлены фиксацией численного значения коэффициентов регрессии, в то время как они в действительности являются случайными, нормально распределенными.
Для линейной модели регрессии доверительный интервал рассчитывается следующим образом. Оценивается величина отклонения от линии регрессии (обозначим ее U):.
 где
где

Проверка общего качества уравнения множественной регрессии
Для этой цели, как и в случае множественной регрессии, используется коэффициент детерминации R 2 :

Справедливо соотношение 0 2 , так как каждая последующая переменная может лишь дополнить, но никак не сократить информацию, объясняющую поведение зависимой переменной.
Иногда при расчете коэффициента детерминации для получения несмещенных оценок в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы, т.е. вводится так называемый скорректированный (исправленный) коэффициент детерминации:

Соотношение может быть представлено в следующем виде:
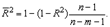
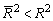 для m>1. С ростом значения m скорректированный коэффициент детерминации растет медленнее, чем обычный. Очевидно, что
для m>1. С ростом значения m скорректированный коэффициент детерминации растет медленнее, чем обычный. Очевидно, что  только при R 2 = 1.
только при R 2 = 1.  может принимать отрицательные значения.
может принимать отрицательные значения.
Доказано, что увеличивается при добавлении новой объясняющей переменной тогда и только тогда, когда t-статистика для этой переменной по модулю больше единицы. Поэтому добавление в модель новых объясняющих переменных осуществляется до тех пор, пока растет скорректированный коэффициент детерминации.
Рекомендуется после проверки общего качества уравнения регрессии провести анализ его статистической значимости. Для этого используется F-статистика:

Показатели F и R2 равны или не равен нулю одновременно. Если F=0, то R 2 =0, следовательно, величина Y линейно не зависит от X1,X2,…,Xm.. Расчетное значение F сравнивается с критическим Fкр. Fкр, исходя из требуемого уровня значимости α и чисел степеней свободы v1 = m и v2 = n — m — 1, определяется на основе распределения Фишера. Если F>Fкр, то R 2 статистически значим.
Для случая наличия в такой регрессии свободного члена коэффициент детерминации обладает следующими свойствами: [2]
1. принимает значения из интервала (отрезка) [0;1].
2. в случае парной линейной регрессионной МНК модели коэффициент детерминации равен квадрату коэффициента корреляции, то есть R 2 = r 2 . А в случае множественной МНК регрессии R 2 = r(y;f) 2 . Также это квадрат корреляции Пирсона между двумя переменными. Он выражает количество дисперсии, общей между двумя переменными.[3]
3. R 2 можно разложить по вкладу каждого фактора в значение R 2 , причём вклад каждого такого фактора будет положительным. Используется разложение:  , где r0j — выборочный коэффициент корреляции зависимой и соответствующей второму индексу объясняющей переменной.
, где r0j — выборочный коэффициент корреляции зависимой и соответствующей второму индексу объясняющей переменной.
4. R 2 связан с проверкой гипотезы о том, что истинные значения коэффициентов при объясняющих переменных равны нулю, в сравнении с альтернативной гипотезой, что не все истинные значения коэффициентов равны нулю. Тогда случайная величина  имеет F-распределение с (k-1) и (n-k) степенями свободы.
имеет F-распределение с (k-1) и (n-k) степенями свободы.
33.
После проверки адекватности, установления точности и надежности построенной модели её необходимо проанализировать. Для этого используют след показатели: 1. Частные коэффициенты эластичности , где а1 – коэффициент регрессии при соответствующем факторном признаке; — среднее значение соответствующего факторного признака; — среднее значение результативного признака. Коэффициент эластичности показывает на сколько процентов в среднем изменится значение результативного признака при изменении факторного признака на 1%. 2. Для определения тесноты связи между признаками при линейной форме связи используется показатель линейный коэффициент корреляции. Линейный коэффициент корреляции изменяется в пределах от -1 до 1. По этому показателю можно сделать след выводы: а) о направлении связи (если -1
Матрица Гессе и асимптотические стандартные ошибки для параметров вычисляются отдельно методом конечных разностей. Эта процедура возвращает очень точные асимптотические стандартные ошибки для всех методов оценивания.
34.Матрица парных коэффициентов корреляции
Более эффективным инструментом оценки мультиколлинеарности факторов является определитель матрицы парных коэффициентов корреляции между факторами  . При полном отсутствии корреляции между факторами матрица парных коэффициентов корреляции между факторами — просто единичная матрица, ведь все недиагональные элементы в этом случае равны нулю. Напротив, если между факторами имеется полная линейная зависимость и все коэффициенты корреляции равны 1, то определитель такой матрицы равен 0. Следовательно, можно сделать вывод, что чем ближе к нулю определитель матрицы межфакторной корреляции , тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии . Чем ближе к 1 этот определитель, тем меньше мультиколлинеарность факторов.
. При полном отсутствии корреляции между факторами матрица парных коэффициентов корреляции между факторами — просто единичная матрица, ведь все недиагональные элементы в этом случае равны нулю. Напротив, если между факторами имеется полная линейная зависимость и все коэффициенты корреляции равны 1, то определитель такой матрицы равен 0. Следовательно, можно сделать вывод, что чем ближе к нулю определитель матрицы межфакторной корреляции , тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии . Чем ближе к 1 этот определитель, тем меньше мультиколлинеарность факторов.
Если известно, что параметры уравнения множественной регрессии линейно зависимы, то число объясняющих переменных в уравнении регрессии можно уменьшить на единицу. Если действительно использовать подобный прием, то можно повысить эффективность оценок регрессии. Тогда имевшаяся ранее мультиколлинеарность может быть смягчена. Даже если такая проблема и отсутствовала в исходной модели, то все равно выигрыш в эффективности может привести к улучшению точности оценок. Естественно, такое улучшение точности оценок отражается их стандартными ошибками. Сама линейная зависимость параметров называется также линейным ограничением .
Помимо уже рассмотренных вопросов нужно иметь в виду, что при использовании данных временного ряда необязательно требовать выполнения условия, что на текущее значение зависимой переменной влияют только текущие же значения объясняющих переменных. Можно ослабить это требование и исследовать, в какой степени проявляется запаздывание соответствующих зависимостей и такое влияние его. Спецификация запаздываний для конкретных переменных в данной модели называется лаговой структурой (от слова «лаг» — запаздывание). Такая структура бывает важным аспектом модели и сама может выступать в роли спецификации переменных модели. Поясним сказанное простым примером. Можно считать, что люди склонны соотносить свои расходы на жилье не с текущими расходами или ценами, а с предшествующими, например, за прошлый год.
Проверка общего качества уравнения множественной линейной регрессии
Вид множественной линейной модели регрессионного анализа: Y = b0 + b1xi1 + . + bjxij + . + bkxik + ei где ei — случайные ошибки наблюдения, независимые между собой, имеют нулевую среднюю и дисперсию s.
Назначение множественной регрессии : анализ связи между несколькими независимыми переменными и зависимой переменной.
Экономический смысл параметров множественной регрессии
Коэффициент множественной регрессии bj показывает, на какую величину в среднем изменится результативный признак Y, если переменную Xj увеличить на единицу измерения, т. е. является нормативным коэффициентом.
Матричная запись множественной линейной модели регрессионного анализа: Y = Xb + e где Y — случайный вектор — столбец размерности (n x 1) наблюдаемых значений результативного признака (y1, y2. yn);
X — матрица размерности [n x (k+1)] наблюдаемых значений аргументов;
b — вектор — столбец размерности [(k+1) x 1] неизвестных, подлежащих оценке параметров (коэффициентов регрессии) модели;
e — случайный вектор — столбец размерности (n x 1) ошибок наблюдений (остатков).
На практике рекомендуется, чтобы n превышало k не менее, чем в три раза.
Задачи регрессионного анализа
Основная задача регрессионного анализа заключается в нахождении по выборке объемом n оценки неизвестных коэффициентов регрессии b0, b1. bk. Задачи регрессионного анализа состоят в том, чтобы по имеющимся статистическим данным для переменных Xi и Y:
- получить наилучшие оценки неизвестных параметров b0, b1. bk;
- проверить статистические гипотезы о параметрах модели;
- проверить, достаточно ли хорошо модель согласуется со статистическими данными (адекватность модели данным наблюдений).
Построение моделей множественной регрессии состоит из следующих этапов:
- выбор формы связи (уравнения регрессии);
- определение параметров выбранного уравнения;
- анализ качества уравнения и поверка адекватности уравнения эмпирическим данным, совершенствование уравнения.
Множественная регрессия:
- Множественная регрессия с одной переменной
- Множественная регрессия с двумя переменными
- Множественная регрессия с тремя переменными
Пример решения нахождения модели множественной регрессии
Модель множественной регрессии вида Y = b 0 +b 1 X 1 + b 2 X 2 ;
1) Найтинеизвестные b 0 , b 1 ,b 2 можно, решим систему трехлинейных уравнений с тремя неизвестными b 0 ,b 1 ,b 2 : 
Для решения системы можете воспользоваться решение системы методом Крамера
2) Или использовав формулы
Для этого строим таблицу вида:
| Y | x 1 | x 2 | (y-y ср ) 2 | (x 1 -x 1ср ) 2 | (x 2 -x 2ср ) 2 | (y-y ср )(x 1 -x 1ср ) | (y-y ср )(x 2 -x 2ср ) | (x 1 -x 1ср )(x 2 -x 2ср ) |
Выборочные дисперсии эмпирических коэффициентов множественной регрессии можно определить следующим образом: 
Здесь z’ jj — j-тый диагональный элемент матрицы Z -1 =(X T X) -1 .

Приэтом:

где m — количество объясняющихпеременных модели.
В частности, для уравнения множественной регрессии Y = b 0 + b 1 X 1 + b 2 X 2 с двумя объясняющими переменными используются следующие формулы:

Или 

или 
 ,
, ,
, .
.
Здесьr 12 — выборочный коэффициент корреляции между объясняющимипеременными X 1 и X 2 ; Sb j — стандартная ошибкакоэффициента регрессии; S — стандартная ошибка множественной регрессии (несмещенная оценка).
По аналогии с парной регрессией после определения точечных оценокb j коэффициентов β j (j=1,2,…,m) теоретического уравнения множественной регрессии могут быть рассчитаны интервальные оценки указанных коэффициентов.
Доверительный интервал, накрывающий с надежностью (1- α ) неизвестное значение параметра β j, определяется как 
http://lektsii.org/10-46326.html
http://www.semestr.ru/ks306