Гетероскедастичность остатков модели регрессии
Случайной ошибкой называется отклонение в линейной модели множественной регрессии:
В связи с тем, что величина случайной ошибки модели регрессии является неизвестной величиной, рассчитывается выборочная оценка случайной ошибки модели регрессии по формуле:
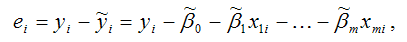
где ei – остатки модели регрессии.
Термин гетероскедастичность в широком смысле понимается как предположение о дисперсии случайных ошибок модели регрессии.
При построении нормальной линейной модели регрессии учитываются следующие условия, касающиеся случайной ошибки модели регрессии:
6) математическое ожидание случайной ошибки модели регрессии равно нулю во всех наблюдениях:
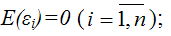
7) дисперсия случайной ошибки модели регрессии постоянна для всех наблюдений:
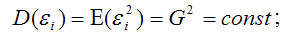
8) между значениями случайных ошибок модели регрессии в любых двух наблюдениях отсутствует систематическая взаимосвязь, т. е. случайные ошибки модели регрессии не коррелированны между собой (ковариация случайных ошибок любых двух разных наблюдений равна нулю):
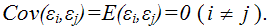
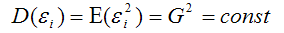
означает гомоскедастичность (homoscedasticity – однородный разброс) дисперсий случайных ошибок модели регрессии.
Под гомоскедастичностью понимается предположение о том, что дисперсия случайной ошибки βi является известной постоянной величиной для всех наблюдений.
Но на практике предположение о гомоскедастичности случайной ошибки βi или остатков модели регрессии ei выполняется не всегда.
Под гетероскедастичностью (heteroscedasticity – неоднородный разброс) понимается предположение о том, что дисперсии случайных ошибок являются разными величинами для всех наблюдений, что означает нарушение второго условия нормальной линейной модели множественной регрессии:
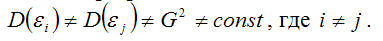
Гетероскедастичность можно записать через ковариационную матрицу случайных ошибок модели регрессии:
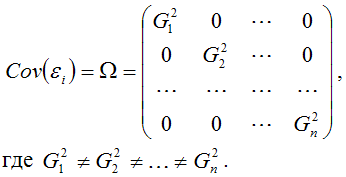
Тогда можно утверждать, что случайная ошибка модели регрессии βi подчиняется нормальному закону распределения с нулевым математическим ожиданием и дисперсией G2Ω:
где Ω – матрица ковариаций случайной ошибки.
Если дисперсии случайных ошибок 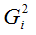 модели регрессии известны заранее, то проблема гетероскедастичности легко устраняется. Однако в большинстве случаев неизвестными являются не только дисперсии случайных ошибок, но и сама функция регрессионной зависимости y=f(x), которую предстоит построить и оценить.
модели регрессии известны заранее, то проблема гетероскедастичности легко устраняется. Однако в большинстве случаев неизвестными являются не только дисперсии случайных ошибок, но и сама функция регрессионной зависимости y=f(x), которую предстоит построить и оценить.
Для обнаружения гетероскедастичности остатков модели регрессии необходимо провести их анализ. При этом проверяются следующие гипотезы.
Основная гипотеза H0 предполагает постоянство дисперсий случайных ошибок модели регрессии, т. е. присутствие в модели условия гомоскедастичности:
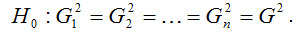
Альтернативная гипотеза H1 предполагает непостоянство дисперсиий случайных ошибок в различных наблюдениях, т. е. присутствие в модели условия гетероскедастичности:
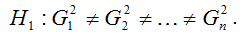
Гетероскедастичность остатков модели регрессии может привести к негативным последствиям:
1) оценки неизвестных коэффициентов нормальной линейной модели регрессии являются несмещёнными и состоятельными, но при этом теряется свойство эффективности;
2) существует большая вероятность того, что оценки стандартных ошибок коэффициентов модели регрессии будут рассчитаны неверно, что конечном итоге может привести к утверждению неверной гипотезы о значимости коэффициентов регрессии и значимости модели регрессии в целом.
Тест ранговой корреляции Спирмена
Обнаружение гетероскедастичности
Одной из предпосылок регрессионного анализа является предположение о постоянстведисперсии случайного члена для всех наблюдений (гомоскедастичность). Это значит, что для каждого значения объясняющей переменной случайные члены имеют одинаковые дисперсии. Если это условие не соблюдается, то имеет место гетероскедастичность.
При отсутствии гетероскедастичности коэффициенты регрессии имеют наименьшую дисперсию среди всех несмещенных оценок, являющихся линейными функциями от наблюдений y.
Если наблюдается гетероскедастичность, то МНК-оценки будут неэффективными(они не будут иметь наименьшую дисперсию по сравнению с другими оценками этого параметра).
Оценки стандартных ошибок коэффициентов регрессии вычисляются в предположении, что распределение случайного члена гомоскедастично; если это не так, то они неверны (занижены), а, следовательно, t-статистика – завышена. Это может привести к статистически значимым коэффициентам регрессии, тогда как в действительности это не так.
Проблема гетероскедастичности характерна для пространственных данных, полученных от неоднородных объектов. Например, если исследуется зависимость прибыли предприятий от размера основного фонда, то можно ожидать, что для больших предприятий колебание прибыли будет выше, чем для малых.
Предложено большое число тестов для обнаружения гетероскедастичности, в которых делаются различные предположения о зависимости между дисперсией случайного члена и величиной объясняющей переменной (или объясняющих переменных), например, тест ранговой корреляции Спирмена, тест Голдфелда-Квандта и тест Глейзера.
Тест ранговой корреляции Спирмена
Выдвигается нулевая гипотеза об отсутствии гетероскедастичности случайного члена. При выполнении теста ранговой корреляции Спирмена предполагается, что дисперсия случайного члена будет либо увеличиваться, либо уменьшаться по мере увеличения x, и поэтому в регрессии, оцениваемой с помощью МНК, абсолютные величины остатков |e| и значения x будут коррелированы.
Данные по x и остатки |e| ранжируются по переменной x,и определяются их ранги.
Ранг – это порядковый номер значений переменной в ранжированном ряду.
Коэффициент ранговой корреляции Спирмена определяется по формуле:
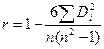 ,
,
где Di – разность между рангами x и |e|.
Если предположить, что коэффициент корреляции для генеральной совокупности равен нулю, то коэффициент ранговой корреляции имеет нормальное распределение с нулевым математическим ожиданием и дисперсией 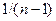 в больших выборках. Соответствующая тестовая статистика
в больших выборках. Соответствующая тестовая статистика  сравнивается с критическим значением tкр при заданном уровне значимости (tкр =1,96 при a = 5%, tкр = 2,58 при a = 1 %).
сравнивается с критическим значением tкр при заданном уровне значимости (tкр =1,96 при a = 5%, tкр = 2,58 при a = 1 %).
Если > tкр, то нулевая гипотеза об отсутствии гетероскедастичности будет отклонена.
Если в модели регрессии имеется более одной объясняющей переменной, то проверка гипотезы может выполняться с использованием любой из них.
Пример 1.1. Оценим регрессионную зависимость выпуска продукции обрабатывающей промышленности на душу населения y от валового внутреннего продукта на душу населения x в том же году для 17 стран.
Исходные данные (усл. ед.):
| n | y | x | n | y | x |
В таблице наблюдения расположены в порядке возрастания независимой переменной x.
Пусть модель описывается выражением y = a + bx + e.
По исходным данным с помощью МНК получена следующая регрессионная зависимость:
 (1.1)
(1.1)
(в скобках указаны стандартные ошибки).

Рис. А. Результаты инструмента Регрессия пакета Анализа данных

Рис. 1. График остатков ei, полученный инструментом Регрессия
Из рисунка видно, что с увеличением переменной x размах колебаний остатков e тоже возрастает, поэтому есть предположение о зависимости ошибки регрессии от независимой переменной (гетероскедастичность).
Для установления гетероскедастичности применим тест Спирмена.
Выдвигается нулевая гипотеза об отсутствии гетероскедастичности.
Отклонения от линии регрессии (остатки e) и данные по x в порядке возрастания приведены в следующей таблице:
| X | Ранг | |ei| | Ранг | Di | Di 2 | X | ранг | |ei| | Ранг | Di | Di 2 |
| 3,6 | -1 | 17,1 | |||||||||
| 3,3 | 22,8 | ||||||||||
| 15,2 | -6 | 41,2 | -3 | ||||||||
| 5,9 | 43,3 | -3 | |||||||||
| 4,2 | 34,5 | ||||||||||
| 11,4 | -1 | 45,0 | -2 | ||||||||
| 14,4 | -1 | 40,8 | |||||||||
| 9.8 | 38,7 | ||||||||||
| 7,9 | Итого |
Здесь значения |ei| взяты из результата инструмента Регрессия (рис. Б).

Чтобы ранжировать остатки, необходимо выполнить следующие действия.
Скопировать остатки. Рассчитать их модули (функция ABS из категории Математические). Выполнить сортировку. Использовать функцию Ранг из категории Статистические (рис. В).

На основе этих данных вычислен коэффициент ранговой корреляции:
 0,865196078
0,865196078
Тестовая статистика составляет  . Это выше, чем t0,05;15 = 2,13 (СТЬЮДРАСПОБР) и, следовательно, нулевая гипотеза об отсутствии гетероскедастичности отклоняется.
. Это выше, чем t0,05;15 = 2,13 (СТЬЮДРАСПОБР) и, следовательно, нулевая гипотеза об отсутствии гетероскедастичности отклоняется.
Тест Голфельда-Квандта
При проведении проверки по этому тесту предполагается, что стандартное отклонение s случайного члена пропорционально значению независимой переменной x.
Тест включает следующие шаги:
1) Все n наблюдений в выборке упорядочиваются по возрастанию переменной x.
2) Оцениваются отдельные регрессии для первых n0 и для последних n0наблюдений. Средние (n – 2n0) наблюдений отбрасываются.
3) Составляется статистика: F = RSS2 /RSS1, где RSS1, RSS2 – суммы квадратов остатков для первых и последних n0 наблюдений соответственно.
Если верна гипотеза H0 об отсутствии гетероскедастичности, то F имеет распределение Фишера с v1 = k, v2= n0 – k – 1 степенями свободы, где k – число объясняющих переменных.
По таблице определяется критическое значение критерия Fкр.
Если F > Fкр, то нулевая гипотеза об отсутствии гетероскедастичности отклоняется.
Замечание. Тест Голфельда-Квандта можно также использовать для проверки на гетероскедастичность при предположении, что si обратно пропорционально xi. В этом случае тестовой статистикой является величина F = RSS1 /RSS2.
Пример 1.2.На основе данных примера 1.1 с помощью обычного МНК оценим регрессии для шести стран с наименьшими значениями показателя x и для шести стран с наибольшими значениями этого показателя.
Получены, соответственно, уравнения:

Суммы квадратов отклонений составляют RSS1 = 229, RSS2 = 9804, при этом F = 9804/229 = 42,8. Критическое значение Fкр = 6,39 при 5%-ном (FРАСПОБР(0,05;1;4))[1] уровне значимости. Поскольку F = 42,8 > Fкр = 7,7086, то нулевая гипотеза об отсутствии гетероскедастичности отклоняется.




На рис. Г-Ж – результаты расчетов в MS Excel.
Тест Глейзера
Тест Глейзера основывается на более общих представлениях о зависимости стандартной ошибки случайного члена от значений объясняющей переменной. Например, зависимость может быть представлена в виде:
Используя абсолютные значения остатков в качестве оценкиsi, данная регрессионная зависимость оценивается при различных значениях g и выбирается наилучшая из них.
Таким образом, гетероскедастичность аппроксимируется уравнением:
Нулевая гипотеза об отсутствии гетероскедастичности отклоняется, если оценка b значимо отличается от нуля.
Пример 1.3. На основании данных |ei| и x примера 1.1 с использованием различных значений g были оценены уравнения (1.2):
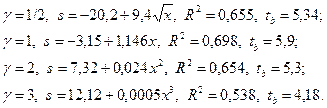
Наилучший результат (по R 2 ) соответствует значению g =1, при этом оценкой s является величина:
 (1.3)
(1.3)
Коэффициент b = 1,146значимо отличается от нуля, следовательно, имеет место гетероскедастичность.
Реферат: Методы обнаружение гетероскедастичности
| Название: Методы обнаружение гетероскедастичности Раздел: Рефераты по экономике Тип: реферат Добавлен 15:52:38 09 июля 2011 Похожие работы Просмотров: 2163 Комментариев: 19 Оценило: 2 человек Средний балл: 5 Оценка: неизвестно Скачать | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 постоянна.
постоянна.  для любых наблюдений i и j.
для любых наблюдений i и j. . Откуда же появляется разброс? Дело в том, что при рассмотрении выборочных данных имеется дело с конкретными реализациями зависимой переменной
. Откуда же появляется разброс? Дело в том, что при рассмотрении выборочных данных имеется дело с конкретными реализациями зависимой переменной  и соответственно с определенными случайными отклонениями
и соответственно с определенными случайными отклонениями  Но до осуществления выборки эти показатели априори могли принимать произвольные значения на основе некоторых вероятностных распределений. Одним из требований к этим распределениям является равенство дисперсий. Данное условие подразумевает, что несмотря на то что при каждом конкретном наблюдении случайное отклонение может быть большим либо маленьким, положительным либо отрицательным, не должно быть некой априорной причины, вызывающей большую ошибку (отклонение) при одних наблюдениях и меньшую – при других.
Но до осуществления выборки эти показатели априори могли принимать произвольные значения на основе некоторых вероятностных распределений. Одним из требований к этим распределениям является равенство дисперсий. Данное условие подразумевает, что несмотря на то что при каждом конкретном наблюдении случайное отклонение может быть большим либо маленьким, положительным либо отрицательным, не должно быть некой априорной причины, вызывающей большую ошибку (отклонение) при одних наблюдениях и меньшую – при других.
 для всех наблюдений i, i = 1, 2,…, n.
для всех наблюдений i, i = 1, 2,…, n. будут коррелированы. Значения
будут коррелированы. Значения 
 — разность между рангами значений
— разность между рангами значений  и
и  ).
). .
.
 пропорционально значению
пропорционально значению 
 и значениями объясняющей переменной. При этом F-статистика примет вид: (если X убывает).
и значениями объясняющей переменной. При этом F-статистика примет вид: (если X убывает).

 – случайный член.
– случайный член.| N | Год | Текущие расходы по газу (x) | Совокупные личные расходы (y) |
| 1 | 1959 | 74,9 | 70,6 |
| 2 | 1960 | 79,8 | 71,9 |
| 3 | 1961 | 80,9 | 72,6 |
| 4 | 1962 | 80,8 | 73,7 |
| 5 | 1963 | 80,8 | 74,8 |
| 6 | 1964 | 81,1 | 75,9 |
| 7 | 1965 | 81,4 | 77,2 |
| 8 | 1966 | 81,9 | 79,4 |
| 9 | 1967 | 81,7 | 81,4 |
| 10 | 1968 | 82,5 | 84,6 |
| 11 | 1969 | 84 | 88,4 |
| 12 | 1970 | 88,6 | 92,5 |
| 13 | 1971 | 95 | 96,5 |
| 14 | 1972 | 100 | 100 |
| 15 | 1973 | 104,5 | 105,7 |
| 16 | 1974 | 117,7 | 116,3 |
| 17 | 1975 | 140,9 | 125,2 |
| 18 | 1976 | 164,8 | 131,7 |
| 19 | 1977 | 195,6 | 139,3 |
| 20 | 1978 | 214,9 | 149,1 |
| 21 | 1979 | 249,2 | 162,5 |
| 22 | 1980 | 297 | 179 |
| 23 | 1981 | 336,8 | 194,5 |
| 24 | 1982 | 404,2 | 206 |
| 25 | 1983 | 473,4 | 213,6 |
1. Найдем линейную модель в виде  . Оценки для α и β определяем с помощью метода наименьших квадратов по формулам:
. Оценки для α и β определяем с помощью метода наименьших квадратов по формулам:


Для этого найдем:
Среднее значение x:

Среднее значение y:

Ковариацию x и y:





Полученная мною линейная модель имеет вид:

В результате выполнения регрессионного анализа мною получено:
TSS –полная сумма квадратов:

RSS – остаточная сумма квадратов:

ESS – оцененная модель суммы квадратов:

Условия правильности моих вычислений на данном этапе проверим по формуле:
49901,17 = 46820,32 + 3080,849
Вычислим коэффициент корреляции и коэффициент детерминации:


Критерием правильности решения задачи является:

Данные параметры характеризуют хорошую линейную зависимость между текущими расходами и совокупными личными расходами на имеющихся статистических данных.
Найдем среднюю ошибку аппроксимации:

где 
Для наглядности представим результаты графически.

Примечание. Прямая линия – уравнение регрессии, а точки – статистические данные.
Определим доверительный интервал для параметров α и β:


Здесь  – квантиль t-распределения Стьюдента с (N – p) степенями свободы; p – число параметров, в моем случае он равен 2;
– квантиль t-распределения Стьюдента с (N – p) степенями свободы; p – число параметров, в моем случае он равен 2;  и
и  – оценки исследуемых параметров, полученные ранее с использованием метода наименьших квадратов;
– оценки исследуемых параметров, полученные ранее с использованием метода наименьших квадратов;  и
и  – несмещенные оценки для дисперсий случайных величин α и β; γ – уровень значимости.
– несмещенные оценки для дисперсий случайных величин α и β; γ – уровень значимости.


Квантиль t–распределения Стьюдента с 23 степенями свободы находим из таблицы:
Для γ = 1%, = 2,807
Для γ = 5%, = 2,069
Доверительный интервал для 1% уровня значимости:
42,787 2 (εi ) необходимо знать распределение Y, соответствующее выбранному значению xi . На практике зачастую для каждого конкретного значения xi определяется единственное значение yi , что не позволяет оценить дисперсию Y для данного xi .
В заключение отметим, что наличие гетероскедастичности не позволяет получить эффективные оценки, что зачастую приводит к необоснованным выводам по их качеству. Обнаружение гетероскедастичности – достаточно трудоемкая проблема и для ее решения разработано несколько методов.
Все они используют в качестве нулевой гипотезы H0 гипотезу об отсутствии гетероскедастичности.
В ходе исследований я получила, что наилучшей моделью является гиперболическая функция, т. к. ей соответствует наименьшая средняя ошибка аппроксимации равная  = 5,2%. При проверке полученной модели на возможную гетероскедастичность данных я воспользовалась тестом ранговой корреляции Спирмена и тестом Голдфелда – Квандта. В результате обоих вычислений нулевая гипотеза об отсутствии гетероскедастичности принимается, следовательно мои данные гомоскедастичны.
= 5,2%. При проверке полученной модели на возможную гетероскедастичность данных я воспользовалась тестом ранговой корреляции Спирмена и тестом Голдфелда – Квандта. В результате обоих вычислений нулевая гипотеза об отсутствии гетероскедастичности принимается, следовательно мои данные гомоскедастичны.
1. Бородич С.А. Эконометрика. – Мн.: Новое знание, 2004.
2. Доугерти К. Введение в эконометрику. – М.: ИНФРА-М, 1999.
3. Кремер Н.Ш., Путко Б.А. Эконометрика: Учебник для вузов. – М.: ЮНИТИ, 2002.
4. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс. – М.: Дело, 2004.
5. Орлов А.И. Эконометрика. – М.: Экзамен, 2002.
6. Суслов В.И., Ибрагимов Н.М., Талышева Л.П. Эконометрия. – Новосибирск.: СО РАН, 2005.
7. Харин Ю.С., Малюгин В.И., Харин А.Ю. Эконометрическое моделирование. – Мн.: БГУ, 2003.
http://poisk-ru.ru/s34368t11.html
http://www.bestreferat.ru/referat-320535.html